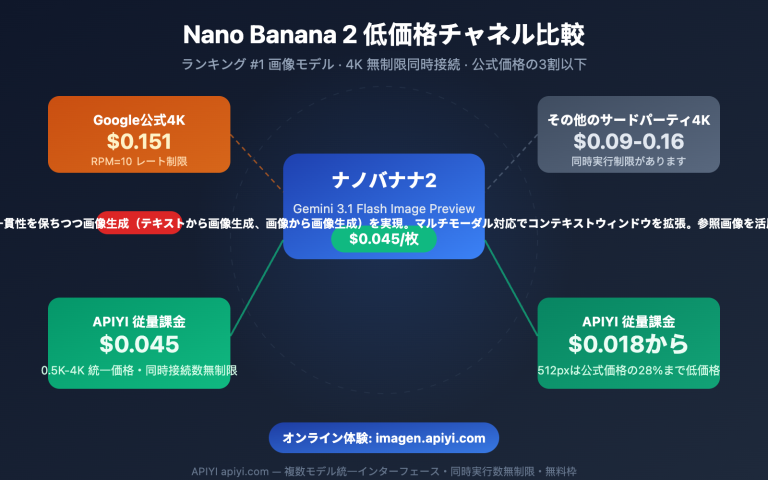
作者注:APIYIにて gpt-image-2-all 官逆(公式リバースエンジニアリング)モデルをリリースしました。1回あたり0.03ドル、並列数制限なしの従量課金制で、テキストから画像生成、複数画像の統合、自然言語による画像編集をサポートしています。ChatGPT Web版の最新画像生成能力をそのまま利用可能で、本記事ではAPIの接続方法を詳しく解説します。
2026年4月、ChatGPT Web版では次世代の画像生成能力のA/Bテストが開始されています。ユーザーインターフェース上では「GPT Image 1.5」と表示されますが、一部のリクエストはすでに新しいモデルによって処理されています。OpenAI公式APIではまだ gpt-image-2 モデルIDは公開されていません。そのため、「直接APIで gpt-image-2 を呼び出せる」と謳うサービスには十分注意してください。
APIYIでは、公式リバースエンジニアリング手法を通じて gpt-image-2-all を正式にリリースしました。ChatGPT Web版の最新の画像生成能力と完全に同期しており、1回あたり0.03ドル、並列数制限なしで利用可能です。これは単なる約束ではなく、標準的なHTTPリクエストで呼び出し可能なプロダクションレベルのインターフェースです。
コアバリュー: 本記事を読めば、gpt-image-2-all の3つのAPIエンドポイント、複数画像統合のテクニック、自然言語による画像編集の使い方が理解でき、10分以内に接続を完了できます。

gpt-image-2-all の重要ポイント
| 機能 | 説明 | メリット |
|---|---|---|
| ChatGPT Web版と同等 | 公式リバースエンジニアリングにより能力を同期 | OpenAIのAPI公開を待つ必要なし |
| 従量課金 | 1回0.03ドル、解像度/品質/プロンプト制限なし | コストが透明で予測可能 |
| 並列数制限なし | リクエスト数制限なし | バッチ処理に最適 |
| 複数画像統合 | プロンプト内で「画像1/画像2/画像3」と参照 | 複数主体の一貫性生成が可能 |
| 自然言語による編集 | マスク不要の対話型編集 | 反復作業のハードルを大幅に低減 |
gpt-image-2-all の位置付け
「官逆(公式リバースエンジニアリング)」とは何か。これは、ChatGPT Web版の最新画像生成能力をリバースエンジニアリングによってAPI中継する手法です。OpenAIが将来公開する公式の gpt-image-2 とは異なるインターフェースですが、モデルの能力は同一です。公式APIが正式に公開されるまで、ChatGPTの最新画像生成能力を安定して呼び出せる唯一のプロダクションレベルのソリューションです。
なぜ今すぐ導入すべきか。3つの現実的な理由があります。(1) OpenAI公式の gpt-image-2 リリース時期が未定(2026年4月下旬〜5月中旬と予想)であること。(2) リリース初期は必ずクォータ制限やコールドスタートの問題が発生すること。(3) 今から gpt-image-2-all で業務フローを構築しておけば、公式版が公開された際にモデル名を切り替えるだけでシームレスに移行できるためです。
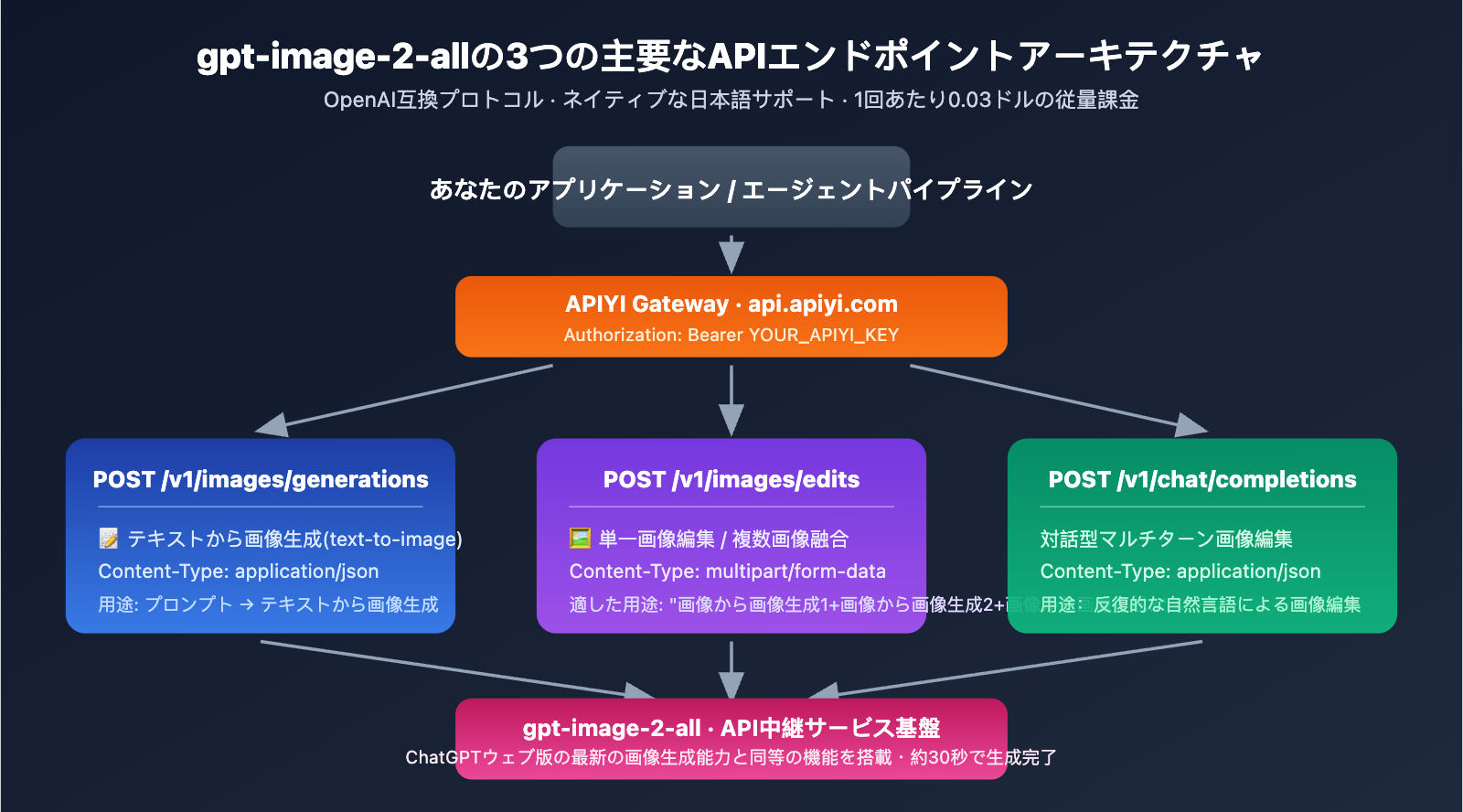
gpt-image-2-all クイックスタート
3つの主要 API エンドポイント
gpt-image-2-all は、あらゆる画像生成シナリオをカバーする3つのエンドポイントを提供します。
| エンドポイント | 用途 | Content-Type |
|---|---|---|
POST /v1/images/generations |
テキストから画像生成 | application/json |
POST /v1/images/edits |
単一画像の編集/複数画像の融合 | multipart/form-data |
POST /v1/chat/completions |
対話形式による複数回の画像修正 | application/json |
ベースURL: https://api.apiyi.com (予備: b.apiyi.com, vip.apiyi.com)
シンプルなテキストから画像生成の例
import requests
response = requests.post(
"https://api.apiyi.com/v1/images/generations",
headers={
"Authorization": "Bearer YOUR_APIYI_KEY",
"Content-Type": "application/json"
},
json={
"model": "gpt-image-2-all",
"prompt": "横長 16:9 カフェラテ1杯、テーブルの上のラベルに 'Morning Blend $4.50' と書かれている、カフェの窓から差し込む朝の光",
},
timeout=120
)
result = response.json()
print(result["data"][0]["url"])
完全な実装コードを表示(エラー処理、並行処理、複数画像融合、対話式修正を含む)
import requests
import time
from typing import Optional, List
API_KEY = "YOUR_APIYI_KEY"
BASE_URL = "https://api.apiyi.com"
def text_to_image(prompt: str, timeout: int = 120) -> Optional[str]:
"""テキストから画像生成: /v1/images/generations エンドポイントを使用"""
for attempt in range(3):
try:
r = requests.post(
f"{BASE_URL}/v1/images/generations",
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
json={"model": "gpt-image-2-all", "prompt": prompt},
timeout=timeout
)
if r.status_code == 200:
return r.json()["data"][0]["url"]
if r.status_code == 429:
time.sleep(2 ** attempt)
continue
except requests.Timeout:
continue
return None
def multi_image_fusion(prompt: str, image_paths: List[str]) -> Optional[str]:
"""複数画像の融合: /v1/images/edits エンドポイントを使用"""
files = [
("image[]", (f"img{i}.png", open(p, "rb"), "image/png"))
for i, p in enumerate(image_paths)
]
data = {"model": "gpt-image-2-all", "prompt": prompt}
r = requests.post(
f"{BASE_URL}/v1/images/edits",
headers={"Authorization": f"Bearer {API_KEY}"},
data=data,
files=files,
timeout=120
)
return r.json()["data"][0]["url"] if r.status_code == 200 else None
def conversational_edit(messages: List[dict]) -> Optional[str]:
"""対話式画像修正: /v1/chat/completions エンドポイントを使用"""
r = requests.post(
f"{BASE_URL}/v1/chat/completions",
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
json={"model": "gpt-image-2-all", "messages": messages},
timeout=120
)
return r.json()["choices"][0]["message"]["content"] if r.status_code == 200 else None
# 使用例
url = text_to_image("縦長 9:16 スマホ用ポスター、アイスラテ1杯、上部に大きな文字で 'Summer Sale 50% OFF'")
print(f"生成結果: {url}")
fusion_url = multi_image_fusion(
"画像1の人物を画像2のビーチの風景に配置し、人物の服装はそのまま維持する",
["person.png", "beach.png"]
)
print(f"融合結果: {fusion_url}")
導入のアドバイス: APIYI (apiyi.com) に登録するとテスト用クレジットが取得できます。1つのAPIキーで gpt-image-2-all、GPT-4o、Claude などのすべてのモデルをサポートしているため、複数のベンダーアカウントを管理する手間を省けます。
gpt-image-2-all の主要機能詳細
特徴1:高精度なテキストレンダリング
gpt-image-2-all にとって、日本語および英語のテキストレンダリングの安定性は、公式 ChatGPT の最新画像生成能力における核心的な強みです。看板、ポスター、インフォグラフィック内の文字を一度の生成で正確に描写できます。これは gpt-image-1.5 では困難だったことです。
実証シナリオ:
- カフェのメニューボード:
"Americano $4.00, Latte $4.50"を文字単位で正確に描写 - 製品パッケージ: 日本語と英語が混在する成分表も鮮明に読み取り可能
- UIモックアップ: ボタンのテキストやナビゲーションラベルを正確にレンダリング
- インフォグラフィック: タイトル、サブタイトル、データラベルの階層が明確
特徴2:複数画像の融合能力
/v1/images/edits エンドポイントを通じて、複数の参照画像を同時にアップロードし、プロンプト内で 「画像1」、「画像2」、「画像3」 と直接参照できます。
prompt = """
画像1の製品を画像2の風景に配置し、
画像3の色彩スタイルを適用してください。
カメラアングルは少し見下ろす視点で、
4K高精細なディテールで出力してください。
"""
適用シナリオ:
| シナリオ | 活用方法 |
|---|---|
| EC向けシーン画像 | 製品画像 + 背景画像 → 生活感のある合成 |
| キャラクターの一貫性 | キャラクターの元画像 + 新しいシーン → マルチアングル生成 |
| スタイル変換 | コンテンツ画像 + スタイル画像 → スタイライズ出力 |
| ブランドビジュアル | 製品 + ロゴ + カラーパレット → ビジュアルの統一 |
特徴3:自然言語による画像修正(マスク不要)
最大の効率化のブレイクスルーは対話形式の画像修正です。マスクを描いたり領域を選択したりする必要はなく、自然言語で修正の要望を伝えるだけです。
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "カフェの外観を生成して。午後の日差しが斜めに差し込んでいる様子で。"},
]
},
{
"role": "assistant",
"content": "[生成された画像リンク]"
},
{
"role": "user",
"content": "天気を雨に変更して。建物はそのまま維持して。"
}
]
このワークフローが意味すること: 以前の「生成 → Photoshopで修正 → 再生成」というサイクルが、対話による反復に変わりました。調整のたびに詳細なプロンプトを書き直す必要はありません。
特徴4:ネイティブな日本語サポート
プロンプトは直接日本語で記述でき、英語に翻訳してから呼び出す必要はありません。日本の開発チームやローカライズ業務において、非常に自然で使いやすい体験を提供します。
prompt = "縦長 9:16 小紅書(RED)風の表紙、コーヒーを飲む東洋系の女性、タイトル '週末のカフェ巡り · 路地裏の秘密のカフェ'、柔らかな光の写実的なスタイル"
gpt-image-2-all のサイズとアスペクト比の制御
重要な注意事項
gpt-image-2-all は、size、n、quality、aspect_ratio といったパラメータを受け付けません。これらを指定すると検証エラーが発生します。サイズやアスペクト比の制御は、必ず プロンプト内のテキスト記述 で行う必要があります。
推奨されるプロンプトの書き方
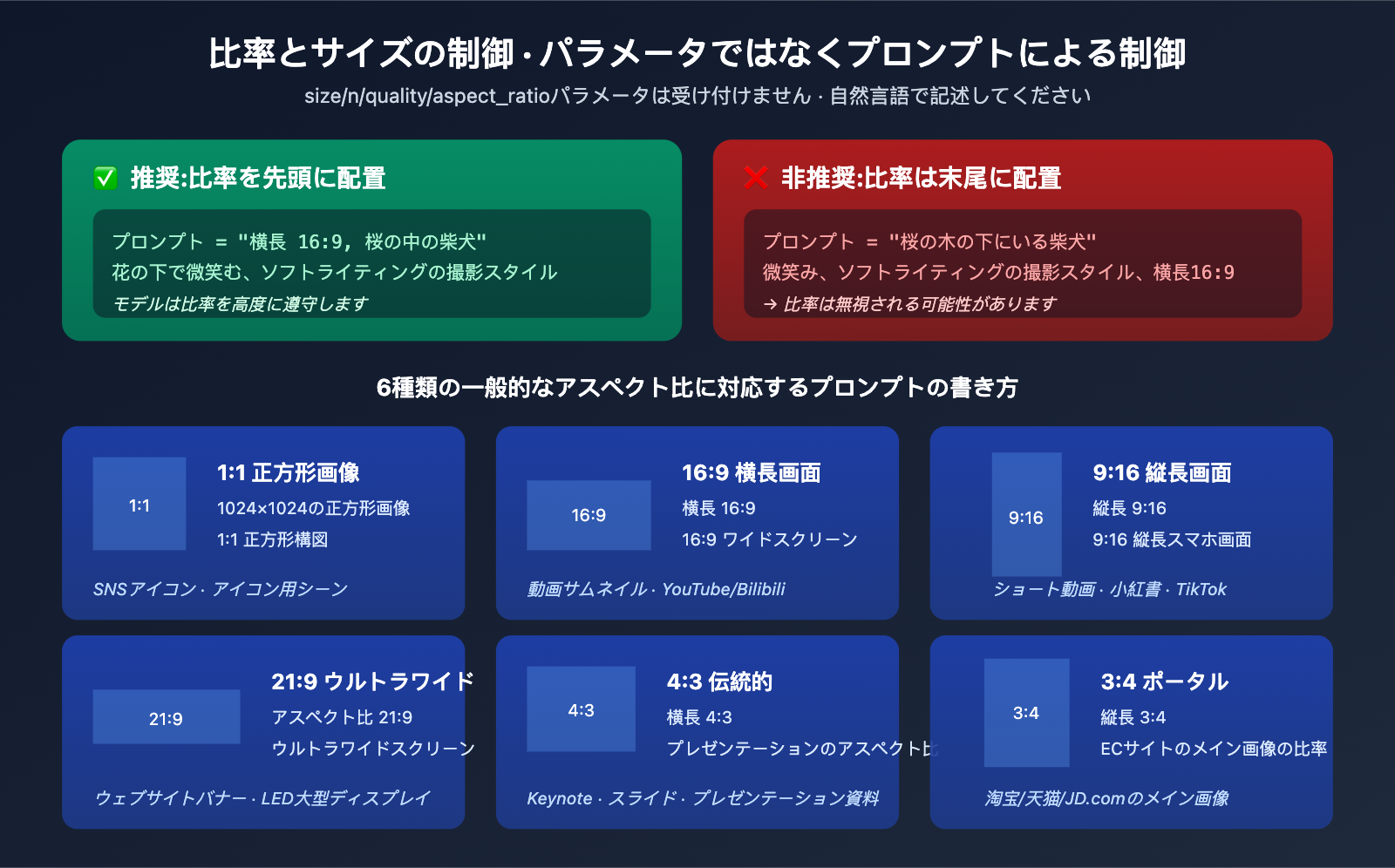
| ターゲット比率 | 推奨される書き方 | 説明 |
|---|---|---|
| 1:1 正方形 | "1024×1024 正方形" または "1:1 正方形構図" | SNSアイコンなど |
| 16:9 横長 | "横長 16:9" または "16:9 ワイドスクリーン" | 動画サムネイル |
| 9:16 縦長 | "縦長 9:16" または "9:16 スマホ縦画面" | ショート動画/SNS投稿 |
| 21:9 超ワイド | "横長 21:9" または "超ワイドスクリーン" | Webバナー |
| 4:3 標準 | "横長 4:3" | スライド資料 |
| 3:4 ポートレート | "縦長 3:4" | ECサイト商品画像 |
重要なテクニック
比率の記述はプロンプトの先頭に配置してください。モデルはプロンプトの冒頭の内容をより重視するため、後ろに配置すると無視される可能性があります。
# ✅ 推奨
prompt = "横長 16:9, 桜の木の下で微笑む柴犬, 柔らかな写真スタイル"
# ❌ 非推奨
prompt = "桜の木の下で微笑む柴犬, 柔らかな写真スタイル, 横長 16:9"
gpt-image-2-all の価格設定と同時実行ポリシー
料金ルール
| 項目 | ルール |
|---|---|
| 単価 | $0.03 / 回 |
| 課金単位 | 生成成功回数に基づき課金 |
| 失敗時の課金 | 401/4xx/5xx エラーは課金対象外 |
| パラメータの影響 | なし(解像度や品質による変動なし) |
| 同時実行制限 | なし(アカウント残高による自然制限のみ) |
コスト試算例
| ビジネスシナリオ | 月間呼び出し回数 | 月間コスト |
|---|---|---|
| 個人プロジェクト | 500 回 | $15 |
| 小規模チーム | 5,000 回 | $150 |
| ECサイト大量生成 | 50,000 回 | $1,500 |
| 大規模パイプライン | 500,000 回 | $15,000 |
コスト最適化のヒント: APIYI (apiyi.com) の統合アカウント管理を活用することで、タスクの種類に応じて gpt-image-2-all、gpt-image-1.5、Nano Banana Pro の間で最適なモデルへルーティングできます。これにより、すべてのシーンで最高単価を支払う必要がなくなります。
gpt-image-2-all のエラー処理とベストプラクティス
一般的なエラーコードと対処法
| ステータスコード | 対処法 |
|---|---|
| 401 | Authorization Bearer Token が正しいか確認してください |
| 429 | 指数バックオフによる再試行(2秒 → 4秒 → 8秒)を行ってください |
| 5xx | 1〜2回再試行し、解決しない場合はアラートを出してください |
| タイムアウト | クライアント側のタイムアウト設定は 120 秒以上を推奨します |
トラブルシューティングのヒント
すべてのレスポンスには request-id ヘッダーが含まれています。問題が発生した際は、この ID を記録して APIYI テクニカルサポートへ提出してください。 サーバー側のログを迅速に特定できます。
サポートされていない機能
- ストリーミング出力:
stream=trueは無効です。単一のレスポンスのみサポートしています。 - 複数画像出力: 1 回のリクエストにつき 1 枚の画像のみ返されます。複数枚必要な場合は、並列で複数回呼び出してください。
- OpenAI SDK のデフォルトパラメータ: 公式 SDK のデフォルトパラメータである
sizeやnを含めると検証エラーが発生します。requests を使用した直接送信を推奨します。
よくある質問 (FAQ)
Q1: gpt-image-2-all とは何ですか?
gpt-image-2-all は、APIYI が公式リバースエンジニアリング手法を通じて、ChatGPT Web版の最新画像生成能力を接続した中継モデルです。OpenAI が正式に gpt-image-2 API を公開するまでの間、ChatGPT の最新機能と同等のプロダクションレベルの呼び出しチャネルを提供します。テキストから画像生成、複数画像の融合、自然言語による画像編集の3つの主要なシナリオをサポートしています。
Q2: gpt-image-2-all と公式の gpt-image-2 に違いはありますか?
基盤となるモデル能力は同じですが、インターフェースの方式が異なります。OpenAI 公式 API では現在 gpt-image-2 モデル ID は公開されていません(直接 API 呼び出しが可能と謳うサービスには注意が必要です)。ChatGPT Web版では、新しいモデルの A/B テストが実施されています。gpt-image-2-all は、リバースエンジニアリング手法を通じて安定した呼び出しチャネルを提供します。公式版が公開された後は、model フィールドを切り替えるだけで公式インターフェースへシームレスに移行可能です。
Q3: 1回あたり $0.03 という価格設定はどう理解すればよいですか?
生成成功回数に基づいた課金であり、解像度、品質、プロンプトの長さによる制限はありません。OpenAI 公式の gpt-image-2 の推定価格($0.15-$0.20)と比較すると、gpt-image-2-all は約 1/5 から 1/6 のコストです。失敗したリクエスト(認証エラー、パラメータエラーなど)は課金対象外となり、同時実行数に強制的な上限はありません(アカウント残高による自然な制限のみです)。
Q4: なぜ画像生成に 30 秒かかるのですか?
30 秒は現在のリバースエンジニアリング手法における平均応答時間であり、ChatGPT Web版の速度に近い数値です。公式の gpt-image-2 が将来公開されれば、より高速(約 3 秒)になると予想されますが、公式 API がリリースされるまでは、gpt-image-2-all が最新機能を安定して呼び出せる唯一のソリューションです。誤ったタイムアウトを防ぐため、クライアント側のタイムアウト設定を 120 秒以上にすることを推奨します。
Q5: gpt-image-2-all を利用するにはどうすればよいですか?
以下の3ステップで利用を開始できます:
- APIYI (apiyi.com) でアカウントを登録し、APIキーを取得する
- Base URL を
https://api.apiyi.comに設定する requestsライブラリを使用して/v1/images/generationsエンドポイントを呼び出す(公式 SDK を使用する場合は、sizeパラメータの問題を避けるため HTTP リクエストのカスタマイズが必要です)
詳細ドキュメント: docs.apiyi.com/api-capabilities/gpt-image-2-all/overview · オンライン試用: imagen.apiyi.com
Q6: 複数画像の融合では、最大何枚の参照画像に対応していますか?
1回の /v1/images/edits リクエストで複数の参照画像をサポートしています。1枚あたりのサイズは 10MB 以下、形式は PNG/JPG/WebP に対応しています。プロンプト内で「画像1」、「画像2」、「画像3」のように参照してください。実測では 3〜5 枚の参照画像の融合が最も安定しており、10 枚を超えると要素が欠落する可能性があります。
Q7: なぜ OpenAI 公式 SDK で直接呼び出せないのですか?
OpenAI 公式 SDK の images.generate() メソッドは、デフォルトで size や n などのパラメータを送信しますが、gpt-image-2-all はこれらのパラメータを受け付けません(検証エラーが発生します)。推奨される解決策は以下の通りです:(1) requests を使用して直接 HTTP リクエストを送信する、(2) SDK のリクエストボディを上書きしてこれらのパラメータを除外する。公式版が公開されれば、SDK との互換性が確保されます。
Q8: gpt-image-2-all にはどのような制限がありますか?
現在の制限事項は以下の通りです:
- 1回あたりの出力は 1 枚: 複数枚必要な場合は並列呼び出しを行ってください
- ストリーミング非対応: 単発でのレスポンスとなり、stream には対応していません
- ベータ段階: 安定性は継続的に最適化中であり、稀に不安定になることがあります
- リバースエンジニアリングへの依存: ChatGPT Web版の仕様変更により、一時的にサービスに影響が出る可能性があります
- 安定モデルとの併用推奨: 重要な業務では、gpt-image-1.5 や Nano Banana Pro を予備のフォールバックとして設定することを推奨します
gpt-image-2-all の重要ポイント
- リバースエンジニアリングによる最新機能の提供: 公式 API 公開前の唯一のプロダクションレベルのチャネル
- 1回 $0.03・同時実行制限なし: 成功課金制でコストが透明、バッチ処理にも最適
- 3つのエンドポイントで全シナリオを網羅: テキストから画像生成 / 複数画像融合 / 対話式画像編集
- ネイティブな日本語対応 + 高精度な文字描画: 日本語・英語の文字レンダリングが安定しており、プロンプトの翻訳が不要
- 導入手順: APIYI (apiyi.com) で登録 → 120 秒のタイムアウト設定 →
requestsで直接呼び出し
まとめ
gpt-image-2-all のコアバリューは以下の通りです:
- 公式の空白期間を補完: OpenAI が
gpt-image-2API を正式公開する前に、ChatGPT の最新画像生成能力を呼び出せる、安定したプロダクションレベルのインターフェースを提供します。 - 予想を大幅に下回るコスト: 1回あたり $0.03(公式予想 $0.15〜$0.20 に対して)。大量処理が必要なシーンで圧倒的なコスト優位性を発揮します。
- シームレスな移行設計: OpenAI 互換プロトコルに基づいているため、公式版がリリースされた際はモデル名を置き換えるだけで即座に切り替えが可能です。
チームの意思決定として、今すぐ APIYI (apiyi.com) を通じて gpt-image-2-all を導入し、業務フローを構築することをお勧めします。現在、1回あたり $0.03 という価格設定により、大量の検証をほぼゼロコストで行えます。公式の gpt-image-2 が公開されたら必要に応じて切り替えればよいため、先行して導入したチームは新モデルのリリース直後から大きなプロダクト優位性を築くことができます。
オンライン体験: imagen.apiyi.com · 日本語ドキュメント: docs.apiyi.com/api-capabilities/gpt-image-2-all/overview
関連資料 Related Articles
gpt-image-2-all に興味をお持ちの方は、ぜひ以下の記事も併せてお読みください:
- 📘 gpt-image-2 vs gpt-image-1.5 8つのアップグレード全解説 – 能力飛躍の根本的な理由を理解する
- 📊 gpt-image-2 6つの応用シーン全解説 – 具体的なビジネス導入の道筋を把握する
- 🚀 gpt-image-2 vs Nano Banana Pro 詳細比較 – 最適なモデルを合理的に選択する
📚 参考資料
-
APIYI 公式ドキュメント: gpt-image-2-all 完全技術仕様
- リンク:
docs.apiyi.com/api-capabilities/gpt-image-2-all/overview - 説明: パラメータ、エラーコード、ベストプラクティスを含む公式の接続ドキュメント
- リンク:
-
APIYI オンライン Playground: imagen.apiyi.com
- リンク:
imagen.apiyi.com - 説明: コードを書かずに gpt-image-2-all の画像生成効果をテスト可能
- リンク:
-
OpenAI 公式画像 API ドキュメント: 最新画像モデル API
- リンク:
openai.com/index/image-generation-api - 説明: OpenAI 公式 gpt-image-1.5 API 仕様との比較用
- リンク:
-
LM Arena グレースケールテスト観測: GPT Image 2 リーク情報
- リンク:
mindstudio.ai/blog/what-is-gpt-image-2 - 説明: 次世代画像モデルの能力プレビュー情報
- リンク:
著者: APIYI 技術チーム
技術交流: コメント欄での議論を歓迎します。その他の資料は APIYI ドキュメントセンター(docs.apiyi.com)をご覧ください。