Nota do autor: Análise profunda das 5 principais causas do consumo excessivo de tokens no OpenClaw (Open WebUI), incluindo chamadas de API ocultas em segundo plano, acúmulo de histórico de conversa e outros fatores, além de oferecer soluções de configuração imediatas.
"Eu só perguntei 'qual é o seu modelo?', por que o consumo de tokens de entrada (Prompt Tokens) passou de 10.000?" Essa é uma dúvida real de muitos usuários do OpenClaw. Neste artigo, vamos analisar tecnicamente as causas raiz do alto consumo de tokens no OpenClaw e apresentar 5 soluções práticas para otimização.
Valor central: Ao ler este artigo, você entenderá por que o OpenClaw consome muito mais tokens do que o esperado e aprenderá métodos de configuração específicos para reduzir os custos de tokens em 60-80%.
Pontos Chave do Consumo de Tokens no OpenClaw
| Ponto Chave | Descrição | Nível de Impacto |
|---|---|---|
| Chamadas ocultas em segundo plano | Cada mensagem dispara de 4 a 5 invocações de API independentes | ⭐⭐⭐⭐⭐ Máximo |
| Acúmulo de histórico de conversa | Cada rodada de conversa reenvia todo o histórico de mensagens | ⭐⭐⭐⭐ Alto |
| Modelos de tarefa não segregados | Tarefas de segundo plano usam o modelo principal por padrão | ⭐⭐⭐⭐ Alto |
| Injeção de comando do sistema | Descrições de ferramentas e contexto RAG são injetados automaticamente | ⭐⭐⭐ Médio |
| Bug de repetição de comando do sistema | Sobreposição de comandos do sistema em chamadas de ferramentas Agentic | ⭐⭐⭐ Médio |
A Causa Raiz do Alto Consumo de Tokens no OpenClaw
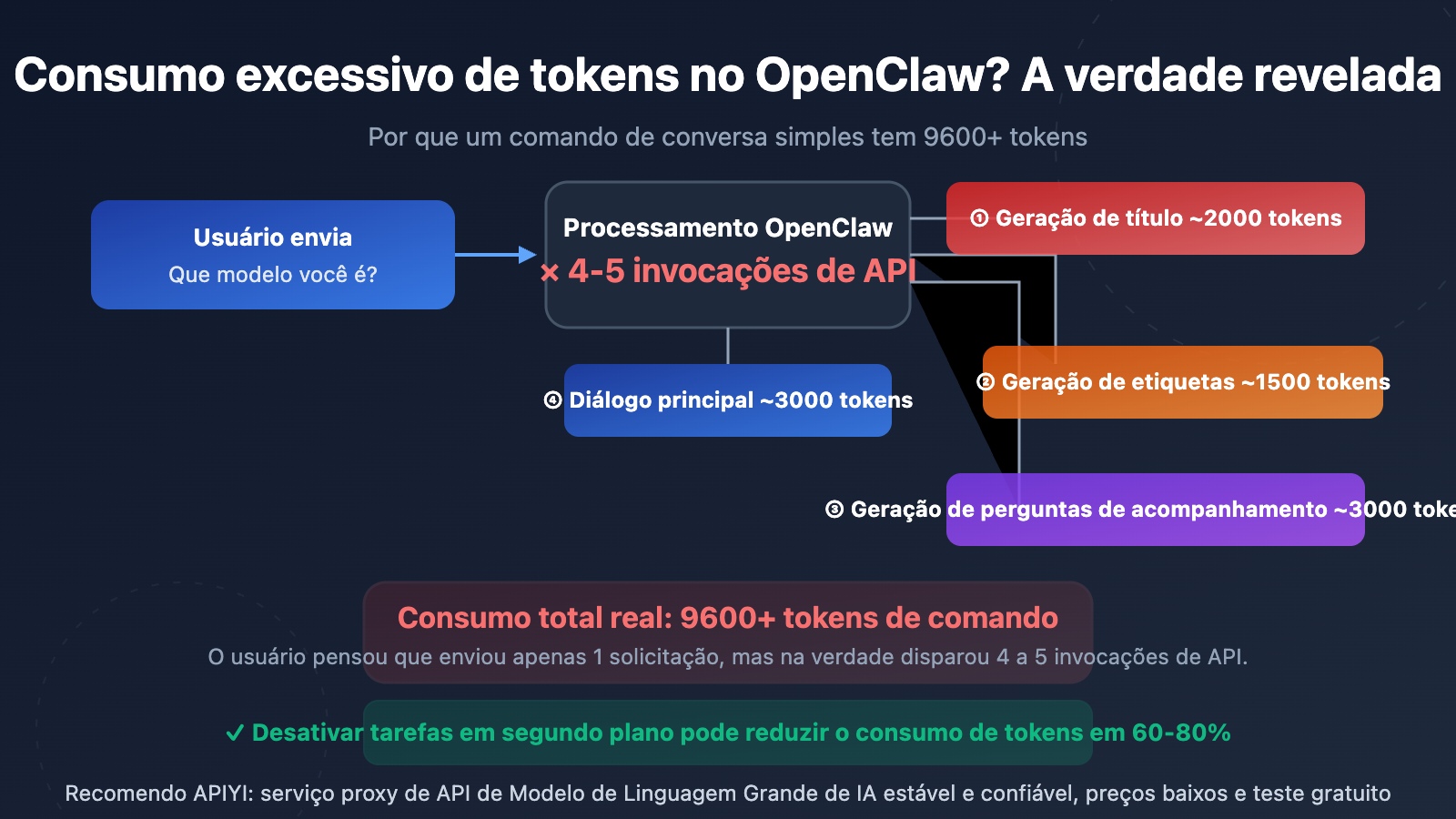
Muitos usuários ficam chocados ao ver as estatísticas de uso da API — uma pergunta simples como "qual é o seu modelo?" resulta em 9.600 a 10.000+ Prompt Tokens. Isso não é um erro de faturamento do provedor de API, mas sim uma consequência do design da arquitetura do OpenClaw (Open WebUI).
O motivo central é: o OpenClaw dispara automaticamente várias invocações de API independentes em segundo plano cada vez que o usuário envia uma mensagem. Essas chamadas são completamente invisíveis para o usuário, mas cada uma consome tokens reais.
Detalhamento das 5 Principais Origens de Consumo de Tokens no OpenClaw
Origem 1: Geração Automática de Título (Title Generation)
Após o usuário enviar a primeira mensagem, o OpenClaw chama automaticamente a API para gerar um título de 3 a 5 palavras para a conversa. Essa chamada envia o conteúdo da mensagem do usuário, consumindo cerca de 1.500 a 2.000 Prompt Tokens.
Origem 2: Geração Automática de Tags (Tag Generation)
Simultaneamente, o OpenClaw chama a API para gerar de 1 a 3 tags de categoria para a conversa. Esta é mais uma invocação de API independente, consumindo cerca de 1.000 a 1.500 Prompt Tokens.
Origem 3: Sugestões de Perguntas (Follow-up Generation)
Por padrão, o OpenClaw gera de 3 a 5 sugestões de perguntas de acompanhamento. Essa chamada usa o modelo {{MESSAGES:END:6}}, que puxa as últimas 6 mensagens da conversa como contexto, consumindo cerca de 2.000 a 3.000 Prompt Tokens.
Origem 4: Preenchimento Automático (Autocomplete Generation)
Algumas versões do OpenClaw também habilitam a função de preenchimento automático de entrada, prevendo o que o usuário pode digitar a seguir.
Origem 5: A Requisição do Chat Principal
Por fim, temos a requisição principal do chat que o usuário realmente vê, contendo o comando do sistema, o histórico da conversa e a entrada do usuário.
Guia Rápido de Otimização de Consumo de Tokens no OpenClaw
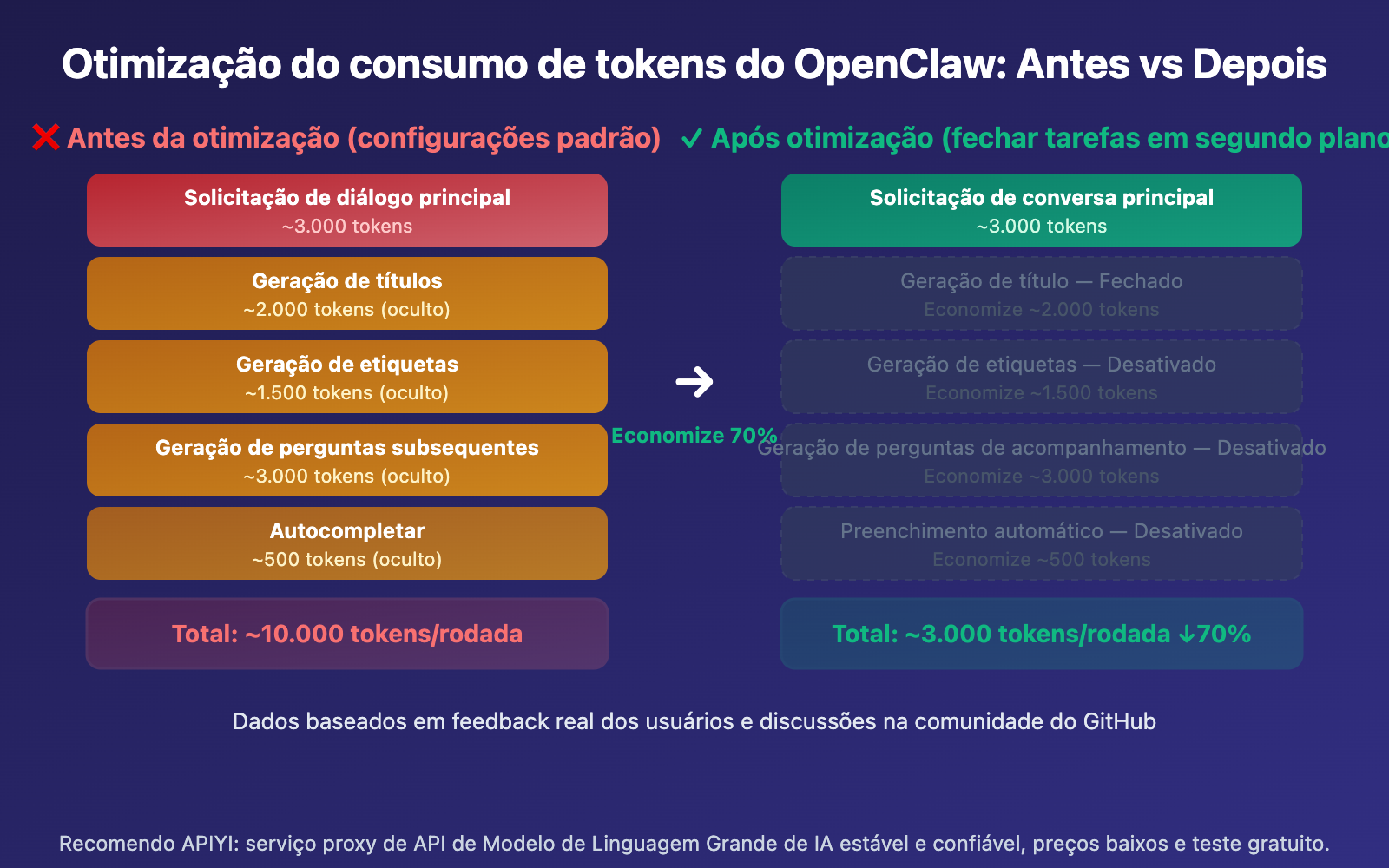
Configuração Minimalista: Desativando Tarefas em Segundo Plano
Aqui está a maneira mais rápida de otimizar — desativando chamadas de API desnecessárias em segundo plano através de variáveis de ambiente:
# Adicione as variáveis de ambiente no seu docker-compose.yml
environment:
- ENABLE_TITLE_GENERATION=false
- ENABLE_TAGS_GENERATION=false
- ENABLE_FOLLOW_UP_GENERATION=false
- ENABLE_AUTOCOMPLETE_GENERATION=false
Veja os passos completos para configurar via painel de administração
Se você não puder modificar as variáveis de ambiente, também pode realizar a configuração através do painel administrativo do OpenClaw:
- Faça login no painel administrativo do OpenClaw
- Vá em Settings → Tasks
- Desative as seguintes opções uma a uma:
- Title Generation → Desativado
- Tags Generation → Desativado
- Follow-up Generation → Desativado
- Autocomplete Generation → Desativado
- Se não quiser desativar completamente, você pode definir o Task Model para um modelo mais barato (como o
gpt-4o-mini) - Salve as configurações e atualize a página
# Opção 2: Não desativar as funções, mas usar um modelo barato para processar tarefas em segundo plano
environment:
- TASK_MODEL_EXTERNAL=gpt-4o-mini
Dessa forma, as tarefas em segundo plano continuarão funcionando normalmente (títulos, tags e perguntas de acompanhamento serão gerados automaticamente), mas utilizando um modelo de custo menor em vez do seu modelo de chat principal.
🎯 Sugestão de Otimização: Desativar tarefas em segundo plano é o método mais direto para reduzir o consumo de tokens no OpenClaw. Se você utiliza APIs através da APIYI (apiyi.com), essas otimizações podem reduzir significativamente seus custos de uso. A APIYI oferece uma interface unificada para múltiplos modelos, facilitando a configuração de diferentes Task Models.
Análise de Dados Reais de Consumo de Tokens no OpenClaw
Abaixo estão os dados reais de consumo de tokens relatados por usuários, onde é possível ver claramente a gravidade do problema:
| Cenário de Uso | Consumo de Tokens Esperado | Consumo de Tokens Real | Multiplicador |
|---|---|---|---|
| Pergunta simples: "Qual modelo você é?" | ~200 | 9.600-10.269 | 50x |
| 5 rodadas de conversa cotidiana | ~3.000 | ~45.000 | 15x |
| 30 rodadas de conversa sobre programação | ~12.000 | 1.860.000 | 155x |
| Conversa após upload de documento | ~5.000 | 600.000+ | 120x |
Os dados na tabela acima vêm de feedbacks reais de usuários na comunidade do Open WebUI no GitHub. O caso extremo de 155x em 30 rodadas de programação ocorre principalmente porque o modelo de geração de perguntas de acompanhamento {{MESSAGES:END:6}} puxa as últimas 6 mensagens, e mensagens de programação costumam conter grandes blocos de código.
Efeito Acumulativo de Rodadas de Conversa no Consumo de Tokens do OpenClaw
| Rodadas de Conversa | Consumo com Configuração Padrão | Consumo após Otimização | Proporção de Economia |
|---|---|---|---|
| 1ª Rodada | ~10.000 | ~3.000 | 70% |
| 5ª Rodada | ~50.000 | ~15.000 | 70% |
| 10ª Rodada | ~150.000 | ~45.000 | 70% |
| 20ª Rodada | ~500.000 | ~150.000 | 70% |
| 30ª Rodada | ~1.200.000 | ~360.000 | 70% |
Conforme o número de rodadas aumenta, o consumo de tokens cresce exponencialmente. Isso acontece porque cada rodada de conversa reenvia o histórico completo da conversa. Nas configurações padrão, esse histórico não é enviado apenas uma vez no chat principal, mas também para a geração de título, tags e perguntas de acompanhamento.
🎯 Sugestão de Controle de Custos: Em cenários de conversas longas, o crescimento do consumo de tokens é surpreendente. Recomendamos realizar suas invocações de modelo através da APIYI (apiyi.com); a plataforma oferece um painel detalhado de estatísticas de uso, facilitando o monitoramento e a otimização do seu consumo de tokens.
Comparação de Planos de Otimização de Consumo de Tokens no OpenClaw

| Plano de Otimização | Dificuldade | Economia de Tokens | Impacto na Funcionalidade | Recomendação |
|---|---|---|---|---|
| Desativar geração de perguntas de acompanhamento | Simples | ~30% | Não mostra mais perguntas sugeridas | ⭐⭐⭐⭐⭐ |
| Configurar modelo de tarefa de baixo custo | Simples | Custo da tarefa cai 90% | Funcionalidade totalmente mantida | ⭐⭐⭐⭐⭐ |
| Desativar geração de títulos/tags | Simples | ~25% | Requer nomear chats manualmente | ⭐⭐⭐⭐ |
| Mover RAG para o comando do sistema | Médio | Ativa cache | Sem impacto negativo | ⭐⭐⭐⭐ |
| Filtro de comprimento de contexto | Médio | Controla custo de chats longos | Pode perder contexto inicial | ⭐⭐⭐ |
🎯 Melhor Prática: Se você não quer perder nenhuma funcionalidade, a Opção 2 (Configurar modelo de tarefa de baixo custo) é a escolha ideal — as tarefas em segundo plano continuam rodando, mas usam modelos de baixo custo como o
gpt-4o-mini. Através da APIYI apiyi.com, você pode gerenciar facilmente as chaves API de vários modelos; uma única chave permite a invocação de todos os principais modelos do mercado.
Perguntas Frequentes
P1: Por que o consumo de Tokens no OpenClaw é tão diferente do ChatGPT oficial?
O ChatGPT oficial funciona com um sistema de assinatura e não cobra por Token, por isso você não percebe o consumo. Já o OpenClaw utiliza chamadas de API, onde cada Token é faturado. Além disso, as tarefas de segundo plano do OpenClaw vêm ativadas por padrão, fazendo com que o consumo real seja de 3 a 5 vezes maior do que as solicitações visíveis do usuário.
P2: O consumo de Tokens no OpenClaw voltará ao normal após desativar as tarefas de segundo plano?
Sim. Ao desativar a geração de títulos, tags, perguntas de acompanhamento e o preenchimento automático, cada mensagem disparará apenas uma invocação do modelo (o chat principal), reduzindo o consumo de Tokens em 60-80%. Se ainda quiser manter essas funções, você pode configurar um modelo barato (como o gpt-4o-mini) especificamente para essas tarefas através da plataforma APIYI apiyi.com.
P3: Como monitorar o consumo real de Tokens no OpenClaw?
Recomendamos as seguintes formas de monitoramento:
- Verifique os dados detalhados de Tokens de cada chamada de API no painel de estatísticas de uso da APIYI apiyi.com.
- Consulte as estatísticas na página "Usage" do painel de administração do OpenClaw.
- Fique atento à proporção entre Prompt Token e Completion Token — se o Prompt for muito maior que o Completion, significa que as tarefas de segundo plano estão consumindo demais.
Resumo
Pontos principais sobre o alto consumo de Tokens no OpenClaw:
- Chamadas ocultas em segundo plano são a causa principal: Cada mensagem dispara de 4 a 5 chamadas de API independentes, mas o usuário visualiza apenas 1.
- Configurar um modelo de tarefa barato é a melhor solução: Definir
TASK_MODEL_EXTERNAL=gpt-4o-minipode reduzir os custos de tarefas em segundo plano em 90%, mantendo todas as funcionalidades. - Atenção especial a conversas longas: O histórico do chat é reenviado em cada uma dessas chamadas; uma conversa de 30 rodadas pode chegar a consumir mais de 1 milhão de Tokens.
Ao dominar essas técnicas de otimização, você pode reduzir o custo de Tokens do OpenClaw entre 60% e 80%, tornando o uso da API muito mais econômico e eficiente.
Recomendamos gerenciar suas invocações de modelo através da APIYI (apiyi.com). A plataforma oferece uma interface unificada e estatísticas detalhadas de uso, ajudando você a controlar com precisão o consumo de Tokens e os seus custos.
📚 Referências
-
Discussão sobre consumo de Tokens no Open WebUI: Discussão na comunidade do GitHub sobre o alto consumo de Tokens.
- Link:
github.com/open-webui/open-webui/discussions/7281 - Descrição: Vários usuários compartilharam dados reais de consumo e experiências de otimização.
- Link:
-
Documentação de configuração de variáveis de ambiente do Open WebUI: Referência oficial para configuração de variáveis de ambiente.
- Link:
docs.openwebui.com/reference/env-configuration - Descrição: Contém todas as variáveis configuráveis e seus valores padrão.
- Link:
-
Problema de consumo de Tokens na geração de Follow-up: A geração de perguntas de acompanhamento consome todo o contexto.
- Link:
github.com/open-webui/open-webui/issues/15081 - Descrição: Análise detalhada de como os templates de perguntas de acompanhamento podem consumir grandes volumes de Tokens.
- Link:
-
Bug de duplicação de comando do sistema: Chamadas de ferramentas (Agentic tools) causam sobreposição de comandos do sistema.
- Link:
github.com/open-webui/open-webui/issues/19169 - Descrição: Um problema conhecido que requer atenção especial ao utilizar funções de chamada de ferramentas.
- Link:
Autor: Equipe Técnica APIYI
Troca de Conhecimento: Sinta-se à vontade para discutir na seção de comentários. Para mais materiais, acesse a Central de Documentação da APIYI em docs.apiyi.com.