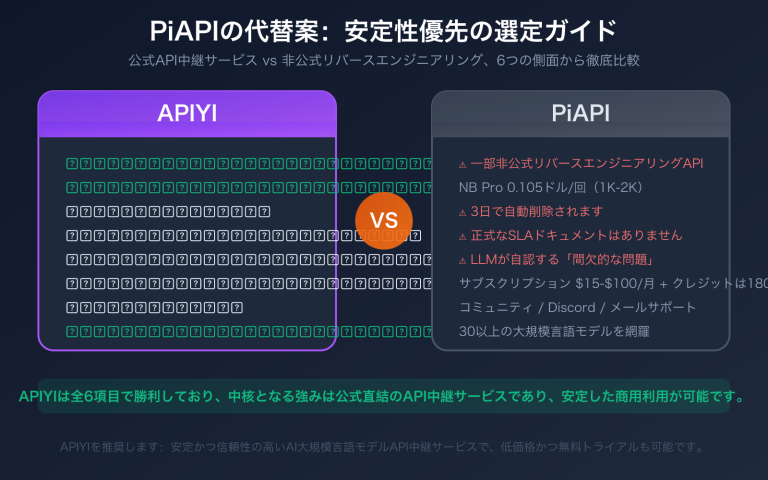
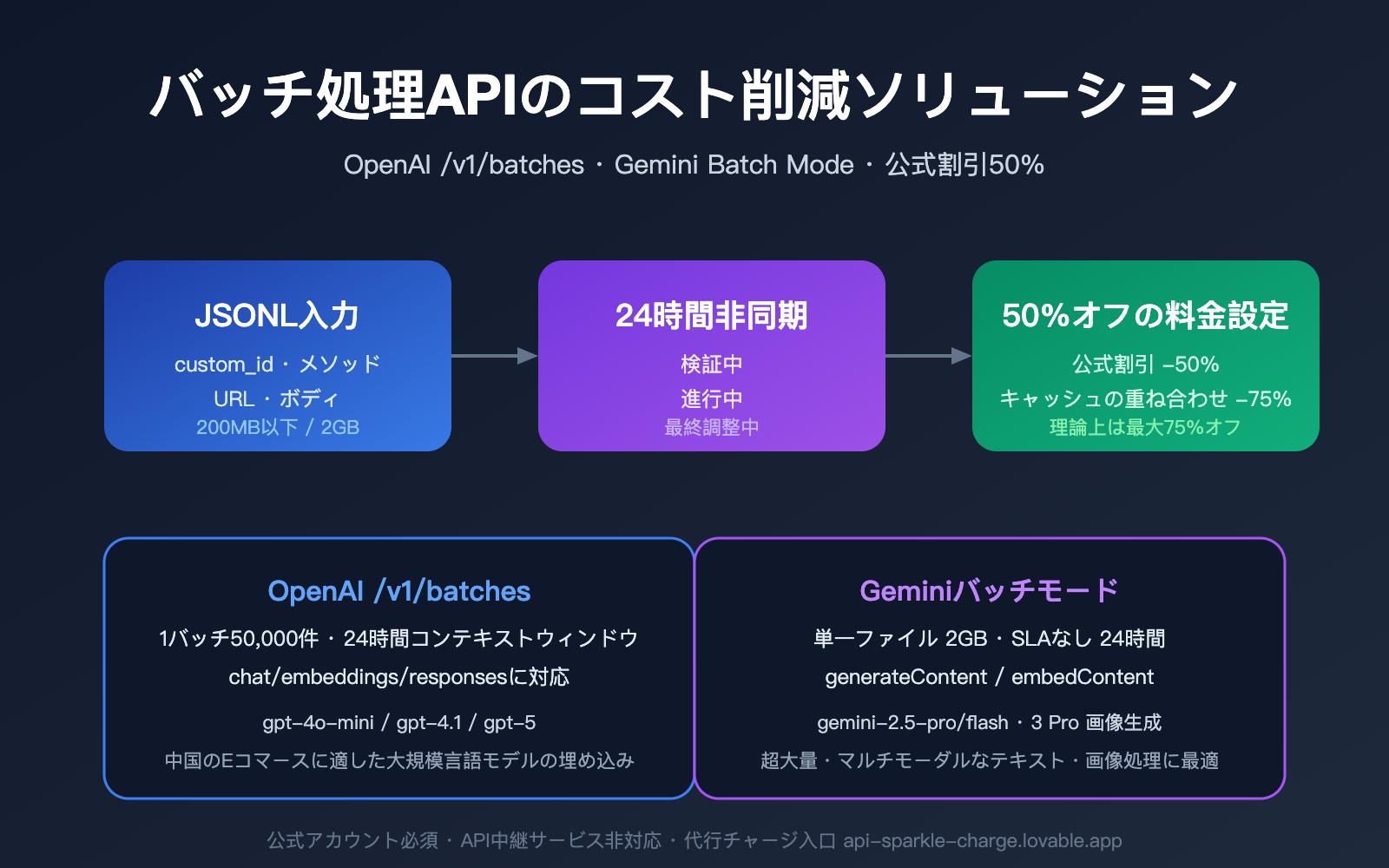
数万件の商品説明、データアノテーション、コンテンツ審査、あるいはベクトル化タスクを一晩で処理する必要がある場合、標準的なAPIを同期的に呼び出すのは時間もコストもかかります。OpenAIの /v1/batches と Google Gemini Batch Mode は、同じ解決策を提示しています。それは、JSONLファイルをアップロードし、24時間以内にすべての結果を非同期で受け取ることで、価格を直接50%オフにするというものです。
しかし、実際の運用において、API中継サービス(APIアグリゲーションプラットフォーム)は、その課金モデルが公式バッチ処理インターフェースの非同期トークン決済メカニズムと互換性がないため、通常は /v1/batches の直結をサポートしていません。つまり、公式の50%割引と数億トークン規模の高並列処理能力を享受したいのであれば、公式アカウント + 公式APIキーを使用して呼び出す必要があります。国内の開発者にとって最も便利なルートは、専門の公式APIチャージサービスを通じてワンクリックで注文することです。注文先は api-sparkle-charge.lovable.app、または AI代充網:ai.daishengji.com で詳細な料金表を確認できます。
本記事では、OpenAIとGoogle AIの公式英語ドキュメントに基づき、2つのバッチ処理APIの技術仕様、課金メカニズム、導入の実践を体系的にまとめ、チャージサービスを活用したシナリオ別の選択ガイドを提供します。
バッチ処理APIの核心的価値:なぜ公式アカウントを開設する価値があるのか
バッチ処理API (Batch API) は、OpenAIとGoogleが非リアルタイムかつ大量のスループットを必要とするシナリオのために設計した専用インターフェースです。その核心的な交換ロジックは、**「リアルタイム応答の確実性を放棄する代わりに、公式の50%の価格割引とより高いレート制限を獲得する」**というものです。
バッチ処理と同期APIの根本的な違い
以下の表は、2つの呼び出しモードの主要なパラメータを比較したものです。
| 項目 | 同期API | バッチ処理API |
|---|---|---|
| 応答遅延 | 秒単位 | 最大24時間 |
| トークン単価 | 標準価格 | 50%オフ |
| 1回のリクエスト上限 | 1件 | OpenAI 5万件 / Gemini 2GB JSONL |
| レート制限 | RPM/TPM制限が厳格 | 独立した高いクォータ |
| 失敗時のリトライ | 呼び出し側で管理 | インターフェース層で自動リトライ |
| プロンプトキャッシュ | 5〜10分のウィンドウ | バッチ内でシステムプロンプトを共有し大幅な節約が可能 |
💡 導入のアドバイス:バッチ処理APIは、公式のネイティブアカウントとAPIキーを使用して呼び出す必要があります。中継アグリゲーションプラットフォームでは
/v1/batchesの非同期タスクを透過的に転送することはできません。公式の代金チャージサービス api-sparkle-charge.lovable.app を通じて直接公式のクォータを購入することをお勧めします。そうすれば、すぐに50%オフのバッチ処理割引が適用され、AI代充網 ai.daishengji.com の多通貨決済機能と組み合わせることで、1分でアカウントへのチャージが完了します。
バッチ処理が最も適しているシナリオ
公式ドキュメントとトップ開発者の実践に基づくと、以下のシナリオで最もコスト削減効果が高くなります。
- データアノテーション/分類:10万件のレビューの感情分析(同期呼び出しで約500ドルかかる場合、バッチ処理なら約250ドル)
- 商品説明生成:ECサイトのSKU一括拡張(通常、夜間にバッチ処理で完了すれば十分な場合)
- ドキュメント要約/ベクトル化:大規模なナレッジベースの処理
- モデル評価 (eval):テストセットの実行(即時性が求められない場合)
- コンテンツ審査:UGCの一括フィルタリング
- Embedding一括生成:ベクトルデータベースの構築
description: OpenAI Batch API と Gemini Batch Mode の技術仕様、実装手順、および公式APIキーの活用方法を解説します。コスト削減のためのベストプラクティスを網羅。
OpenAI Batch API 技術仕様 (/v1/batches)
OpenAI の /v1/batches エンドポイントは業界標準となっており、2024 年のリリース以来、安定して稼働しています。その設計思想は、同期インターフェースのリクエストボディを完全に再利用するという点にあり、開発者が同期処理からバッチ処理へ移行する際の改修コストは極めて低く抑えられています。
核心的な制約とクォータ
| 項目 | 値 | 説明 |
|---|---|---|
| 完了ウィンドウ | 24 時間 | 現在は 24h のみサポート |
| 1バッチあたりの上限 | 50,000 件 | 超過する場合は複数バッチに分割が必要 |
| 1ファイルあたりの上限 | 200 MB | UTF-8 JSONL 形式に基づく |
| サポートエンドポイント | /v1/chat/completions / /v1/embeddings / /v1/completions / /v1/responses |
画像/音声は含まず |
| 価格割引 | -50% | サポート対象の全モデルで一律 50% OFF |
| 特殊レート制限 | 独立 | 同期処理の TPM を消費しません |
JSONL ファイル形式の例
OpenAI では、アップロードするファイルの各行を独立した JSON オブジェクトにする必要があります。これには custom_id、method、url、body の 4 つのフィールドを含めます。
{"custom_id": "req-001", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "gpt-4o-mini", "messages": [{"role": "system", "content": "あなたは商品分類の専門家です"}, {"role": "user", "content": "iPhone 17 Pro 256GB"}]}}
{"custom_id": "req-002", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "gpt-4o-mini", "messages": [{"role": "system", "content": "あなたは商品分類の専門家です"}, {"role": "user", "content": "ソニー WH-1000XM6"}]}}
OpenAI バッチ呼び出しを完了する 4 つのステップ
ステップ 1:JSONL ファイルのアップロード
from openai import OpenAI
client = OpenAI(api_key="sk-公式キー") # 代行チャージで取得した公式キー
batch_file = client.files.create(
file=open("requests.jsonl", "rb"),
purpose="batch"
)
ステップ 2:バッチ処理タスクの作成
batch = client.batches.create(
input_file_id=batch_file.id,
endpoint="/v1/chat/completions",
completion_window="24h",
metadata={"project": "sku-classification-2026q2"}
)
print(batch.id) # batch_abc123
ステップ 3:ステータスのポーリング
import time
while True:
b = client.batches.retrieve(batch.id)
print(b.status, b.request_counts)
if b.status in ("completed", "failed", "expired", "cancelled"):
break
time.sleep(60)
ステップ 4:結果のダウンロード
if b.status == "completed":
result_text = client.files.content(b.output_file_id).text
with open("results.jsonl", "w") as f:
f.write(result_text)

🎯 APIキー取得のアドバイス:OpenAI のバッチ処理には、公式のネイティブな
sk-*キーが必要です。API中継サービスのhub-*やsk-proxy-*キーでは/v1/batchesを呼び出すことはできません。公式のクォータを迅速に取得したい場合は、代行チャージサービスをご利用ください。api-sparkle-charge.lovable.app は OpenAI/Anthropic/Google の三大公式アカウントの代行チャージに対応しており、5〜30 分で反映されます。また、AI 代行チャージサイト ai.daishengji.com では、さまざまな金額の割引プランも確認できます。
Gemini Batch Mode 技術仕様
Google が 2025 年にリリースした Gemini Batch Mode は、OpenAI と同様のアプローチですが、ファイルサイズとモデルの適応性においてより先進的です。
核心的な制約とクォータ
| 項目 | 値 | 説明 |
|---|---|---|
| 完了ウィンドウ | 最長 24 時間 | 厳格な SLA はなし |
| 1ファイルあたりの上限 | 2 GB | OpenAI の約 10 倍 |
| サポートモデル | gemini-2.5-pro / flash / flash-lite | Gemini 3 Pro Image を含む |
| 価格割引 | -50% | 入力・出力トークンともに 50% OFF |
| 対応エンドポイント | generateContent / embedContent |
同期インターフェースと同一 |
| Vertex AI バージョン | リージョン展開をサポート | 企業のコンプライアンス要件に対応 |
Gemini JSONL 形式の例
{"key": "req-001", "request": {"contents": [{"parts": [{"text": "以下の商品について30文字のセールスポイントを書いてください:iPhone 17 Pro 256GB"}]}]}}
{"key": "req-002", "request": {"contents": [{"parts": [{"text": "以下の商品について30文字のセールスポイントを書いてください:Sony WH-1000XM6"}]}]}}
Gemini バッチ呼び出しの例
from google import genai
client = genai.Client(api_key="AIza-公式キー")
# ファイルのアップロード
uploaded = client.files.upload(file="requests.jsonl", config={"mime_type": "jsonl"})
# バッチ処理ジョブの作成
batch_job = client.batches.create(
model="gemini-2.5-flash",
src=uploaded.name,
config={"display_name": "sku-cn-2026q2"}
)
# 結果の取得
final = client.batches.get(name=batch_job.name)
if final.state.name == "JOB_STATE_SUCCEEDED":
result_file = client.files.download(file=final.dest.file_name)
📌 Gemini 代行チャージのヒント:Gemini のバッチ処理機能は、Google AI Studio または Vertex AI の公式有料アカウントでのみ利用可能です(無料枠では利用できません)。お住まいの地域で国際クレジットカードの登録が難しい場合は、AI 代行チャージサイト ai.daishengji.com の Gemini 公式代行チャージチャンネルから有料クォータを迅速に開通させるか、api-sparkle-charge.lovable.app で専用の代行チャージ注文を行ってください。
OpenAI と Gemini のバッチ処理API:比較と選定のポイント
実際のプロジェクトでどちらを採用すべきか、開発者はよく頭を悩ませます。以下の表に主要な比較項目をまとめました。
| 比較項目 | OpenAI Batch | Gemini Batch | 推奨シナリオ |
|---|---|---|---|
| 1バッチあたりの上限 | 50,000件 | 2GB JSONL(約10万件以上) | 超大量処理にはGemini |
| 1ファイルあたりの容量 | 200 MB | 2 GB | 超大量処理にはGemini |
| 応答品質(中国語) | gpt-4o/4.1系が強力 | gemini-2.5-proが総合的に均衡 | 中国語の推論重視ならGPT |
| マルチモーダル対応 | テキスト/埋め込み | テキスト/画像生成 | 画像のバッチ処理ならGemini |
| キャッシュの再利用 | プロンプトキャッシング | 暗黙的なコンテキストキャッシング | 同じシステムプロンプトならOpenAI |
| 料金の複雑さ | シンプルで明快 | モデル階層ごとに異なる | 財務監査ならOpenAI |
| APIドキュメントの成熟度 | 最も成熟 | 継続的に改善中 | 迅速な導入ならOpenAI |

シーン別の選定アドバイス
- 中国語ECサイトのSKUバッチ処理: gpt-4o-mini Batch(コストパフォーマンスが最高)
- マルチモーダル・図文混合: Gemini 2.5 Pro Batch(統一されたパイプライン)
- 大量の埋め込み(Embedding)作成: OpenAI text-embedding-3-small Batch
- 企業のマルチリージョン対応: Vertex AI Gemini Batch
システムプロンプトの再利用とキャッシュの深度最適化
ユーザーから「バッチ処理内の各リクエストに同じシステムプロンプトが含まれている場合、一度だけ課金されるのか?」という質問をよく受けます。これは非常に頻度が高く、誤解されやすいトピックです。
OpenAIバッチ処理におけるプロンプト課金の真実
OpenAIの /v1/batches 自体は、同じシステムプロンプトを自動的に重複排除しません。しかし、Prompt Caching(プロンプトキャッシング) メカニズムを組み合わせることで、バッチ内の同一会話の接頭辞が連続してヒットした場合、キャッシュされた入力トークンはさらに50%割引となります。バッチ処理の50%割引と組み合わせれば、理論上、最大で通常価格の25%(4分の1)までコストを抑えられます。
適用条件:
- リクエストボディの接頭辞が厳密に一致していること(ロール、ツール定義、テキストを含む)
- 接頭辞の長さが1024トークン以上であること(モデルによっては512トークン)
- 同一の24時間枠内でキャッシュヒットのしきい値に達すること
Geminiの暗黙的なコンテキストキャッシュ
Gemini Batch Modeは、Implicit Context Caching(暗黙的なコンテキストキャッシング) をネイティブでサポートしています。リクエストの接頭辞が繰り返されると、システムが自動的にキャッシュを作成するため、手動で cached_content を管理する必要はありません。キャッシュヒット部分はGeminiのキャッシュ料金(通常価格の約25%)で決済され、さらにバッチ処理の50%割引が適用されるため、理論上、最大で通常価格の12.5%(8分の1)まで削減可能です。
バッチ処理+キャッシュを組み合わせたコスト試算
10万件のリクエスト、各リクエストが2000トークンのシステムプロンプト+500トークンのユーザー入力+300トークンの出力を共有すると仮定します:
| 方案 | 単価 | 総コスト試算 | 削減率 |
|---|---|---|---|
| 同期呼び出し (キャッシュなし) | $0.0028 | $280 | 基準 |
| 同期 + Prompt Caching | $0.0018 | $180 | -36% |
| バッチ処理 (50% off) | $0.0014 | $140 | -50% |
| バッチ処理 + Caching | $0.0009 | $90 | -68% |
⚡ コスト削減のアドバイス: 同一のシステムプロンプト、同一モデル、夜間処理という3つの条件が揃う場合は、「バッチ処理+Prompt Caching」の組み合わせを強く推奨します。公式アカウントで上記の最適化を有効にする際は、課金ポリシーを確認してください。APIYIのチャージサービス(api-sparkle-charge.lovable.app)で注文する際は「batch + cacheの割引を有効化」と備考欄に記載いただければ、自動的に最適な料金プランを適用いたします。
description: API中継サービスがなぜバッチ処理(Batch API)をサポートできないのか、その技術的背景と解決策を解説します。
なぜAPI中継サービスはバッチ処理をサポートできないのか:技術的背景の分析
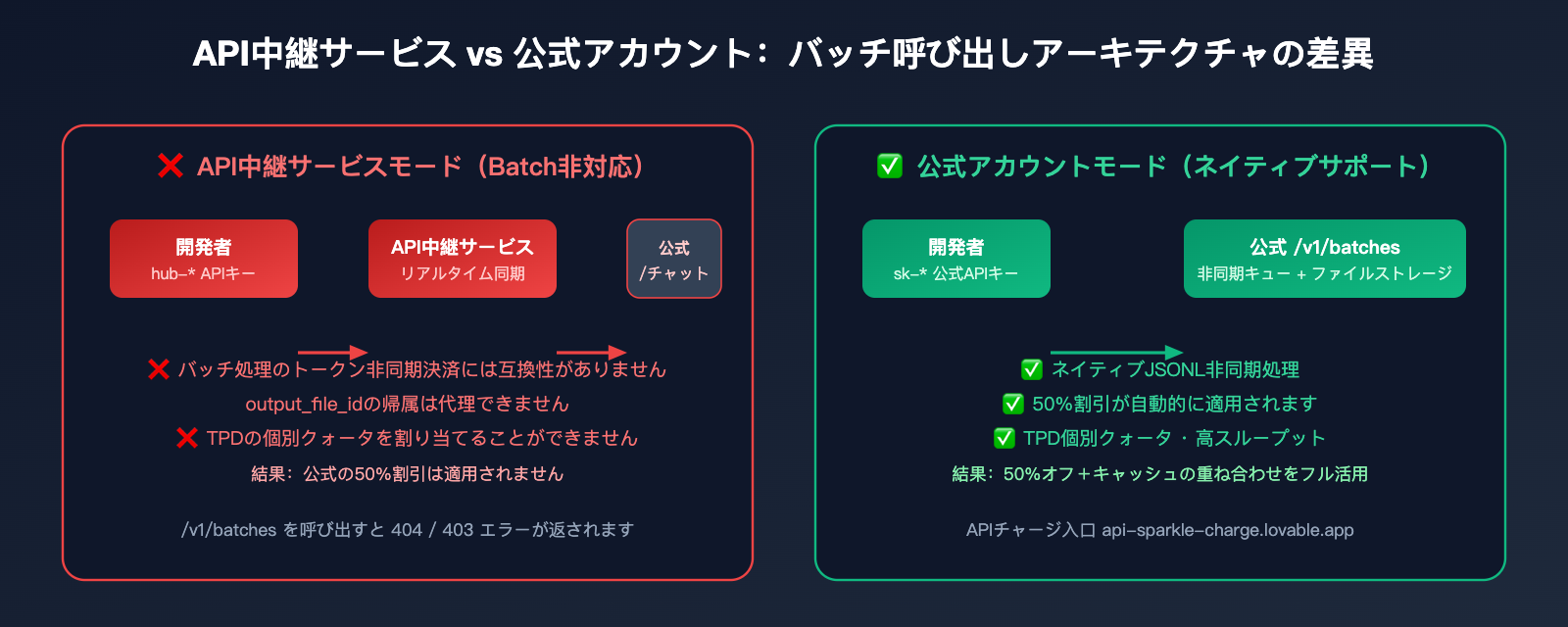
多くのユーザーが疑問に思う「なぜAPI中継サービスは /v1/batches をサポートしないのか?」という点について、技術アーキテクチャの観点から解説します。
根本原因1:課金モデルの非互換性
中継サービスはリアルタイム呼び出しに基づいた差額課金(公式コスト × 1.x の上乗せ)を行っています。一方、バッチ処理は24時間後の一括決済であるため、中継サービス側が先に立て替えを行い、後から回収するという大きな資金リスクと為替リスクを負う必要があります。
根本原因2:トークン返却経路の不透明さ
バッチ処理インターフェースが返す output_file_id は公式ファイルシステムのオブジェクトです。中継サービスがこれを代理で行うには、ファイルストレージと帯域幅のシステム全体を複製する必要があり、ダウンロードリンクの帰属先を切り替えることも困難です。
根本原因3:レート制限の独立性
バッチ処理インターフェースには、同期型のTPM/RPMとは完全に分離された、独立した TPD (Tokens Per Day) クォータが設定されています。中継サービス側では各エンドユーザーの1日あたりの平均的な利用量を予測できず、合理的な二次割り当てを行うことが困難です。
解決策:代行チャージによる公式アカウントの開設
最もクリーンな解決策は、ユーザー自身が公式アカウントを直接保有することです。
- 技術面:すべての中継制限を回避し、
/v1/batchesの全機能をネイティブに利用可能。 - コンプライアンス面:請求、コンプライアンス、返金は公式ルートで行われる。
- 効率面:バッチ処理のために同期/非同期の振り分けを行う必要がない。
- コスト面:代行チャージサービスは合理的な手数料のみを徴収するため、バッチ処理本来の50%割引というメリットをそのまま享受できる。
これこそが、api-sparkle-charge.lovable.app や AI代行チャージサイト ai.daishengji.com が提供する核心的な価値です。公式アカウントとAPIキーを直接取得することで、バッチ処理によるコスト削減の恩恵を最大限に引き出せます。
実践:10万件のカスタマーサポートQ&Aのバッチ分類(完全サンプル)
以下に、そのまま活用できるエンジニアリングサンプルを紹介します。10万件の過去のカスタマーサポートQ&Aを意図別に分類する例です。
ステップ1:JSONL入力の構築
import json
with open("requests.jsonl", "w") as f:
for idx, q in enumerate(questions): # questions は10万件のリスト
payload = {
"custom_id": f"q-{idx:06d}",
"method": "POST",
"url": "/v1/chat/completions",
"body": {
"model": "gpt-4o-mini",
"messages": [
{"role": "system", "content": "ユーザーの質問を billing/tech/sales/other に分類し、カテゴリ名のみを返してください"},
{"role": "user", "content": q}
],
"max_tokens": 8,
"temperature": 0
}
}
f.write(json.dumps(payload, ensure_ascii=False) + "\n")
ステップ2:200MB制限への分割
# 10万件で200MBを超える可能性がある場合、4万件ごとにファイルを分割します
# Geminiを使用する場合は分割不要で、2GBの上限まで対応可能です
ステップ3:送信とモニタリング
batches = []
for path in ["part1.jsonl", "part2.jsonl", "part3.jsonl"]:
fobj = client.files.create(file=open(path, "rb"), purpose="batch")
b = client.batches.create(
input_file_id=fobj.id,
endpoint="/v1/chat/completions",
completion_window="24h"
)
batches.append(b.id)
ステップ4:結果の集計
results = {}
for bid in batches:
b = client.batches.retrieve(bid)
if b.status == "completed":
content = client.files.content(b.output_file_id).text
for line in content.splitlines():
item = json.loads(line)
results[item["custom_id"]] = item["response"]["body"]["choices"][0]["message"]["content"]
コスト試算:10万件 × 約600トークン × gpt-4o-miniのバッチ価格 ≈ $6-9。同期呼び出しと比較して、$6-9の節約になります。
よくある質問 (FAQ)
Q1:API中継サービスのAPIキーで /v1/batches は呼び出せますか?
呼び出せません。 API中継サービスが発行するキー(通常 hub-、sk-proxy-、またはカスタムプレフィックスで始まるもの)は、/v1/chat/completions などの同期エンドポイントのみをサポートしています。バッチ処理インターフェースは、公式アカウント体系のファイルシステムと非同期タスクキューに依存しているため、必ず公式のネイティブな sk-* キーを使用する必要があります。公式キーが必要な場合は、api-sparkle-charge.lovable.app から代理チャージを申し込むか、AI代充網(ai.daishengji.com)で各種プランをご確認ください。
Q2:Gemini Batch の 50% 割引はすべてのモデルに適用されますか?
現在、Gemini 2.5 Pro、2.5 Flash、2.5 Flash-Lite、Gemini 3 Pro Image はすべてバッチ処理の 50% 割引の対象となっており、入力および出力トークン料金が半額になります。無料プラン(Free Tier)のアカウントではバッチ処理は利用できず、有料アカウントである必要があります。代理チャージを通じて開設された公式有料アカウントであれば、すぐに利用可能です。
Q3:バッチ処理タスクが失敗した場合、どうすればいいですか?料金は返金されますか?
OpenAIとGeminiのポリシーは共通です。失敗した個別のリクエストについては課金されず、バッチ全体がキャンセルされるわけではありません。 OpenAIから返される output_file には、error フィールドを含む失敗項目が含まれており、error_file_id で全てのエラーが集約されます。Geminiの場合、state=JOB_STATE_FAILED の際にエラーの詳細が提供されます。custom_id を基にして、失敗した項目を直接再実行(リトライ)することが可能です。
Q4:バッチ処理でプロンプトキャッシュ(Prompt Caching)は機能しますか?
機能します。 OpenAIのドキュメントでは、バッチリクエストがキャッシュされた入力トークン(Cached Input Tokens)と一致した場合、バッチ処理の 50% 割引が適用された上で、さらにキャッシュ済みトークンの料金が 50%(つまり元の価格の 25%)になると明記されています。実際に適用するには、バッチ内のリクエストのプレフィックスが厳密に一致していること、および最低キャッシュ長に達していることを確認してください。
Q5:代理チャージサービスの公式アカウントは安全ですか?後から自分でチャージできますか?
正規の代理チャージサービス(例:api-sparkle-charge.lovable.app)が提供するのは、完全な権限を持つ公式アカウントです。ログイン情報や支払い設定はご自身で変更可能であり、後から国際クレジットカードやApple Payを使用してご自身で継続チャージを行うことができます。AI代充網(ai.daishengji.com)では複数の料金プランを提供しており、請求書発行や経費精算にも対応しているため、コンプライアンスのニーズを満たすことが可能です。
まとめ
バッチ処理APIは、2026年のAIエンジニアリングにおいて最も過小評価されているコスト削減のレバレッジです。completion_window="24h" を指定するだけで、コスト構造全体を半減させることができます。しかし、呼び出し元に対しては「公式のネイティブアカウントおよびキーを使用すること」という厳しい条件があります。API中継サービスは、課金アーキテクチャの制限上、これらを代理することはできません。
大規模なオフラインタスクを持つチームにとって、最も経済的な道は、直接公式アカウントを開設し、プロンプトキャッシュを活用して最適化を深めることです。公式API代理チャージサービスは、国内の開発者がこの恩恵を受けるための最も便利な入り口です。申し込みは api-sparkle-charge.lovable.app から、完全な価格表は AI代充網(ai.daishengji.com)をご覧ください。5分で申し込み、30分で反映され、バッチ処理の 50% 割引を今すぐ活用できます。
📌 執筆者: 本記事は APIYI (apiyi.com) 技術チームがまとめました。内容は OpenAI Platform Docs および Google AI for Developers の公式英文ドキュメントに基づいており、価格やクォータは 2026年4月14日時点の公式ポリシーに準拠します。代理チャージ申し込み入口: api-sparkle-charge.lovable.app / ai.daishengji.com