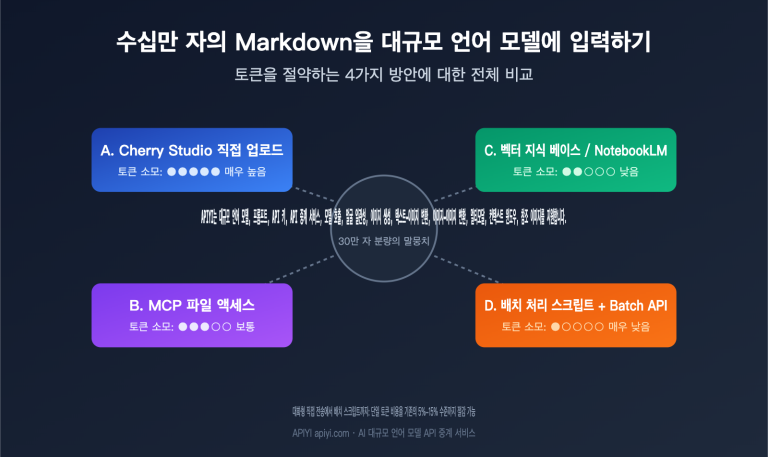
수만 개의 상품 설명, 데이터 라벨링, 콘텐츠 검토 또는 벡터화 작업을 하룻밤 사이에 처리해야 할 때, 표준 API를 동기식으로 호출하는 것은 느리고 비용도 많이 듭니다. **OpenAI의 /v1/batches**와 Google Gemini Batch Mode는 동일한 해답을 제시합니다. JSONL 파일을 업로드하면 24시간 이내에 모든 결과를 비동기식으로 반환하며, **가격은 절반(50% 할인)**으로 낮춰줍니다.
하지만 실제 현장에서는 API 중계 서비스(API 애그리게이터)가 공식 배치 처리 인터페이스의 비동기 토큰 정산 메커니즘과 호환되지 않아, 보통 /v1/batches 직렬 연결을 지원하지 않습니다. 즉, 공식 50% 할인과 수억 토큰 규모의 고성능 동시 처리를 활용하려면 반드시 공식 계정 + 공식 API 키를 사용하여 호출해야 합니다. 국내 개발자에게 가장 편리한 방법은 전문적인 공식 API 대리 결제 서비스를 통해 한 번에 주문하는 것입니다. 주문 주소: api-sparkle-charge.lovable.app, 혹은 AI 대리 결제 사이트 ai.daishengji.com에서 전체 가격표를 확인하세요.
본 글은 OpenAI와 Google AI 공식 영문 문서를 바탕으로 두 배치 처리 API의 기술 규격, 과금 메커니즘, 실제 연동 사례를 체계적으로 정리하고, 대리 결제 서비스의 시나리오별 선택 가이드를 제공합니다.
배치 처리 API의 핵심 가치: 왜 공식 계정을 사용하는 것이 좋은가
배치 처리 API(Batch API)는 OpenAI와 Google이 실시간성이 필요 없는 대량 처리 시나리오를 위해 설계한 전용 인터페이스입니다. 핵심 교환 로직은 이렇습니다. 실시간 응답이라는 확정성을 포기하는 대신, 공식 50% 가격 할인과 더 높은 처리량 제한을 얻는 것입니다.
배치 처리와 동기식 API의 본질적 차이
다음 표는 두 가지 호출 방식의 핵심 파라미터를 비교한 것입니다.
| 차원 | 동기식 API | 배치 처리 API |
|---|---|---|
| 응답 지연 | 초 단위 | 최대 24시간 |
| 토큰당 가격 | 표준 가격 | 50% 할인(-50%) |
| 1회 요청 제한 | 1건 | OpenAI 5만 건 / Gemini 2GB JSONL |
| 속도 제한 | RPM/TPM 엄격 제한 | 별도의 더 높은 할당량 |
| 실패 재시도 | 호출자가 직접 처리 | 인터페이스 수준에서 자동 재시도 |
| 프롬프트 캐싱 | 5~10분 윈도우 | 배치 내 시스템 프롬프트 공유로 절감 가능 |
💡 연동 제언: 배치 처리 API는 반드시 공식 원본 계정과 키를 사용해 호출해야 합니다. API 중계 플랫폼은
/v1/batches비동기 작업을 전달할 수 없습니다. 공식 대리 결제 서비스 api-sparkle-charge.lovable.app을 통해 공식 크레딧을 직접 주문하여 즉시 50% 배치 처리 할인 혜택을 누리시는 것을 권장합니다. AI 대리 결제 사이트 ai.daishengji.com의 다중 통화 결제 기능을 활용하면 1분 안에 계정 충전이 완료됩니다.
배치 처리에 가장 적합한 시나리오
공식 문서와 주요 개발자들의 실무 경험을 바탕으로, 다음과 같은 시나리오에서 가장 큰 비용 절감 효과를 볼 수 있습니다.
- 데이터 라벨링/분류: 10만 건의 리뷰 감성 분석 시, 동기식 호출은 약 $500이나 배치 처리는 약 $250 수준입니다.
- 상품 설명 생성: 쇼핑몰 SKU 일괄 확장 생성, 보통 야간에 한 배치로 처리하면 충분합니다.
- 문서 요약/벡터화: 대규모 지식 베이스 처리.
- 모델 평가 (eval): 시의성이 중요하지 않은 테스트 세트 실행.
- 콘텐츠 검토: UGC 일괄 필터링.
- 임베딩 일괄 생성: 벡터 데이터베이스 구축.
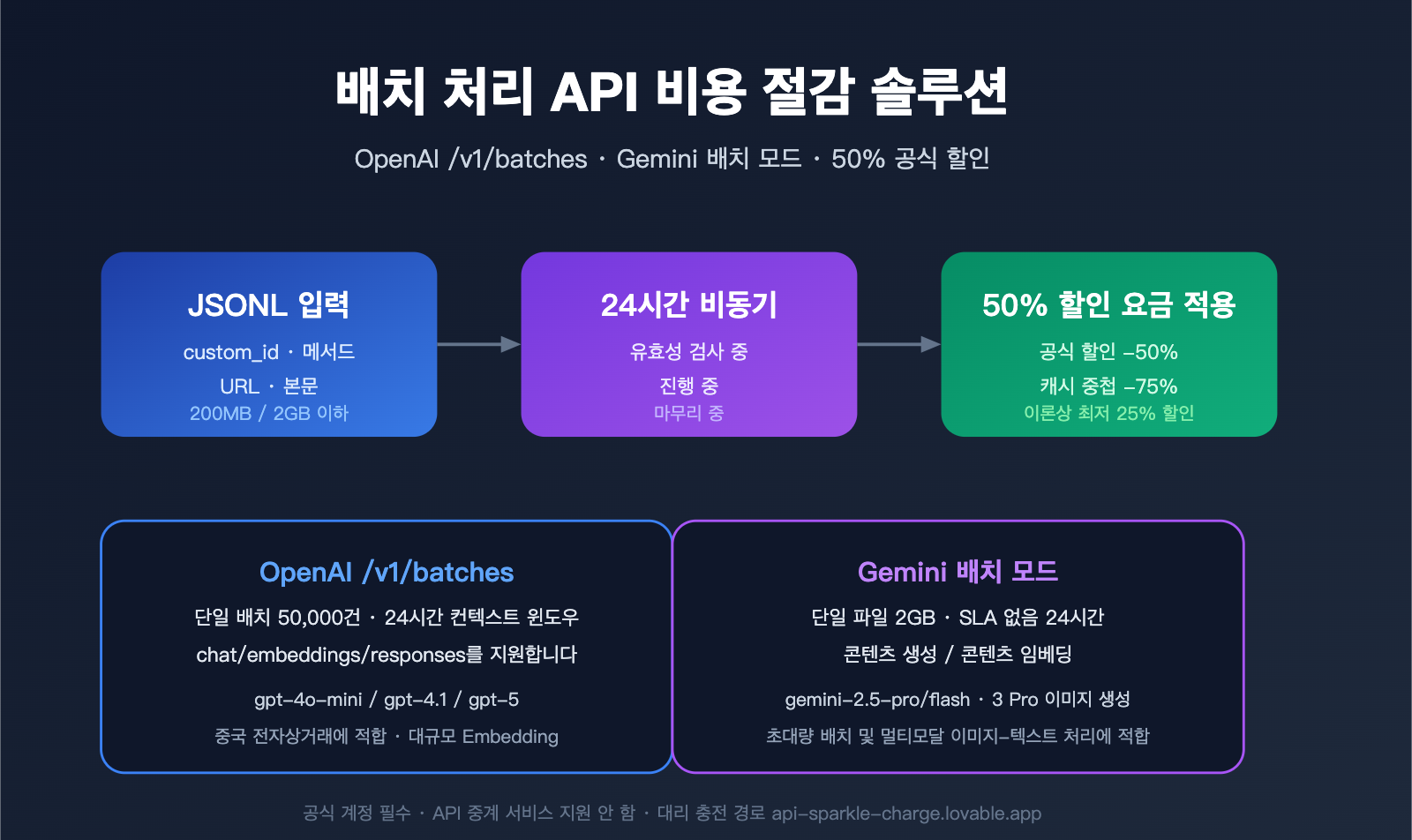
OpenAI Batch API 기술 규격 (/v1/batches)
OpenAI의 /v1/batches 엔드포인트는 업계 표준으로 자리 잡았으며, 2024년 출시 이후 안정적으로 운영되고 있습니다. 이 API의 설계 철학은 동기식 인터페이스의 요청 본문을 그대로 재사용하는 것으로, 개발자가 동기식에서 배치 처리 방식으로 전환할 때 드는 비용을 최소화했습니다.
핵심 제약 사항 및 할당량
| 항목 | 값 | 설명 |
|---|---|---|
| 완료 윈도우 | 24시간 | 현재 24h만 지원 |
| 배치당 요청 상한 | 50,000건 | 초과 시 여러 배치로 분할 필요 |
| 파일당 크기 상한 | 200 MB | UTF-8 JSONL 기준 |
| 지원 엔드포인트 | /v1/chat/completions / /v1/embeddings / /v1/completions / /v1/responses |
이미지/오디오 제외 |
| 가격 할인 | -50% | 지원되는 모든 모델 50% 할인 |
| 별도 속도 제한 | 독립적 | 동기식 TPM 미점유 |
JSONL 파일 형식 예시
OpenAI는 업로드하는 파일의 각 행이 독립적인 JSON 객체여야 하며, custom_id, method, url, body 네 가지 필드를 포함하도록 요구합니다.
{"custom_id": "req-001", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "gpt-4o-mini", "messages": [{"role": "system", "content": "당신은 상품 분류 전문가입니다"}, {"role": "user", "content": "iPhone 17 Pro 256GB"}]}}
{"custom_id": "req-002", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "gpt-4o-mini", "messages": [{"role": "system", "content": "당신은 상품 분류 전문가입니다"}, {"role": "user", "content": "소니 WH-1000XM6"}]}}
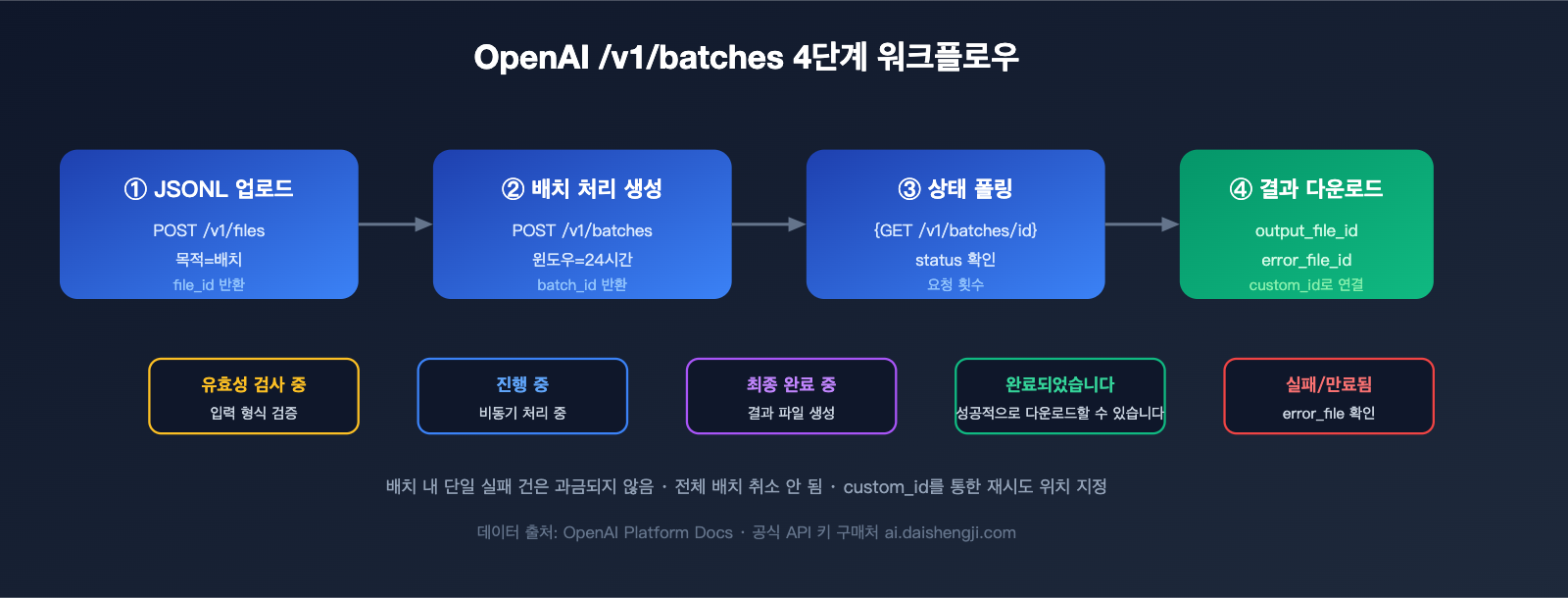
OpenAI 배치 호출 4단계
1단계: JSONL 파일 업로드
from openai import OpenAI
client = OpenAI(api_key="sk-공식키") # 대행 충전으로 획득한 공식 키
batch_file = client.files.create(
file=open("requests.jsonl", "rb"),
purpose="batch"
)
2단계: 배치 작업 생성
batch = client.batches.create(
input_file_id=batch_file.id,
endpoint="/v1/chat/completions",
completion_window="24h",
metadata={"project": "sku-classification-2026q2"}
)
print(batch.id) # batch_abc123
3단계: 상태 폴링(Polling)
import time
while True:
b = client.batches.retrieve(batch.id)
print(b.status, b.request_counts)
if b.status in ("completed", "failed", "expired", "cancelled"):
break
time.sleep(60)
4단계: 결과 다운로드
if b.status == "completed":
result_text = client.files.content(b.output_file_id).text
with open("results.jsonl", "w") as f:
f.write(result_text)
🎯 API 키 획득 제언: OpenAI 배치 처리는 반드시 공식 네이티브 sk-* 키를 사용해야 합니다. API 중계 서비스의 hub-* 또는 sk-proxy-* 키로는
/v1/batches를 호출할 수 없습니다. 공식 할당량이 필요하다면 대행 충전 서비스를 통해 주문하세요. api-sparkle-charge.lovable.app은 OpenAI/Anthropic/Google 3대 공식 계정 대행 충전을 지원하며 5~30분 내로 완료됩니다. AI 대행 충전 사이트 ai.daishengji.com에서 다양한 금액대의 할인 조합도 확인해 보세요.
Gemini Batch Mode 기술 규격
Google이 2025년에 출시한 Gemini Batch Mode는 OpenAI와 접근 방식은 비슷하지만, 파일 크기와 모델 적합성 측면에서 더 공격적입니다.
핵심 제약 사항 및 할당량
| 항목 | 값 | 설명 |
|---|---|---|
| 완료 윈도우 | 최대 24시간 | 엄격한 SLA 없음 |
| 파일당 크기 상한 | 2 GB | OpenAI의 약 10배 |
| 지원 모델 | gemini-2.5-pro / flash / flash-lite | Gemini 3 Pro Image 포함 |
| 가격 할인 | -50% | 입력 + 출력 토큰 모두 50% 할인 |
| 적용 엔드포인트 | generateContent / embedContent |
동기식 인터페이스와 동일 |
| Vertex AI 버전 | 지역별 배포 지원 | 기업 규정 준수 환경 |
Gemini JSONL 형식 예시
{"key": "req-001", "request": {"contents": [{"parts": [{"text": "다음 상품에 대한 30자 판매 문구를 작성하세요: iPhone 17 Pro 256GB"}]}]}}
{"key": "req-002", "request": {"contents": [{"parts": [{"text": "다음 상품에 대한 30자 판매 문구를 작성하세요: Sony WH-1000XM6"}]}]}}
Gemini 배치 호출 예시
from google import genai
client = genai.Client(api_key="AIza-공식키")
# 파일 업로드
uploaded = client.files.upload(file="requests.jsonl", config={"mime_type": "jsonl"})
# 배치 작업 생성
batch_job = client.batches.create(
model="gemini-2.5-flash",
src=uploaded.name,
config={"display_name": "sku-cn-2026q2"}
)
# 결과 가져오기
final = client.batches.get(name=batch_job.name)
if final.state.name == "JOB_STATE_SUCCEEDED":
result_file = client.files.download(file=final.dest.file_name)
📌 Gemini 대행 충전 팁: Gemini 배치 처리 기능은 Google AI Studio 또는 Vertex AI의 공식 유료 계정에서만 개방되며, 무료 할당량 내에서는 사용할 수 없습니다. 거주 지역에서 해외 신용카드 등록이 어렵다면 AI 대행 충전 사이트 ai.daishengji.com의 Gemini 공식 대행 충전 채널을 통해 빠르게 유료 할당량을 확보하거나, api-sparkle-charge.lovable.app에서 전용 대행 주문을 진행하세요.
OpenAI와 Gemini 배치 API 비교 및 의사결정
실제 프로젝트를 진행할 때 개발자들은 종종 두 서비스 사이에서 고민하게 됩니다. 다음 표는 주요 항목별 비교 결과입니다.
| 비교 항목 | OpenAI Batch | Gemini Batch | 추천 시나리오 |
|---|---|---|---|
| 배치당 요청 상한 | 50,000건 | 2GB JSONL(약 10만 건 이상) | 초대량 처리는 Gemini |
| 파일당 최대 용량 | 200 MB | 2 GB | 초대량 처리는 Gemini |
| 응답 품질 (한국어) | gpt-4o/4.1 시리즈 우세 | gemini-2.5-pro 종합적 균형 | 한국어 추론은 GPT |
| 멀티모달 지원 | 텍스트/임베딩 | 텍스트/이미지 생성 | 이미지 배치는 Gemini |
| 캐시 재사용 | 프롬프트 캐싱 | 암시적 컨텍스트 캐싱 | 동일 시스템 프롬프트는 OpenAI |
| 과금 복잡도 | 단순하고 명확함 | 모델 등급별 구분 필요 | 재무 감사는 OpenAI |
| API 문서 성숙도 | 가장 성숙함 | 지속적으로 개선 중 | 빠른 도입은 OpenAI |

시나리오별 선택 가이드
- 한국어 이커머스 SKU 배치 처리: gpt-4o-mini Batch, 가성비 최고
- 멀티모달 이미지-텍스트 혼합: Gemini 2.5 Pro Batch, 통합 파이프라인
- 대규모 임베딩 구축: OpenAI text-embedding-3-small Batch
- 기업 규정 준수 및 다중 지역: Vertex AI Gemini Batch
시스템 프롬프트 재사용 및 캐싱 최적화
사용자분들이 자주 묻는 질문 중 하나는 "배치 처리 시 모든 요청에 동일한 시스템 프롬프트가 포함되는데, 한 번만 과금할 수 없나요?"입니다. 이는 매우 빈번하지만 오해하기 쉬운 부분입니다.
OpenAI 배치 처리 프롬프트 과금의 진실
OpenAI /v1/batches 자체는 동일한 시스템 프롬프트를 자동으로 중복 제거하지 않습니다. 하지만 프롬프트 캐싱(Prompt Caching) 메커니즘을 활용하면, 배치 내 동일한 대화 접두사가 연속으로 적중할 경우 캐시된 입력 토큰에 50% 추가 할인이 적용됩니다. 배치 처리 할인(50%)과 결합하면 이론상 최대 75%까지 비용 절감이 가능합니다.
적용 조건:
- 요청 본문의 접두사가 엄격히 일치해야 함 (역할, 도구 정의, 텍스트 포함)
- 접두사 길이가 1024 토큰 이상 (일부 모델은 512 토큰)
- 동일한 24시간 윈도우 내 캐시 적중 임계값 도달
Gemini의 암시적 컨텍스트 캐싱
Gemini Batch Mode는 **암시적 컨텍스트 캐싱(Implicit Context Caching)**을 기본 지원합니다. 요청 접두사가 반복되면 시스템이 자동으로 캐시를 생성하므로 cached_content를 수동으로 관리할 필요가 없습니다. 캐시 적중 부분은 Gemini 캐시 가격(원가의 약 25%)으로 계산되며, 여기에 배치의 50% 할인이 더해져 최대 87.5%까지 절감할 수 있습니다.
배치 처리 + 캐싱 결합 비용 산정
10만 건의 요청(각 요청당 시스템 프롬프트 2000 토큰, 사용자 입력 500 토큰, 출력 300 토큰)을 가정할 때:
| 방식 | 건당 비용 | 총 비용 추정 | 절감 폭 |
|---|---|---|---|
| 동기 호출 (캐시 없음) | $0.0028 | $280 | 기준 |
| 동기 + 프롬프트 캐싱 | $0.0018 | $180 | -36% |
| 배치 처리 (50% 할인) | $0.0014 | $140 | -50% |
| 배치 + 캐싱 | $0.0009 | $90 | -68% |
⚡ 비용 절감 팁: 동일한 시스템 프롬프트, 동일한 모델, 야간 작업이라는 세 가지 조건이 충족된다면 반드시 '배치 처리 + 프롬프트 캐싱' 조합을 사용하세요. 공식 계정에서 이러한 최적화를 활성화하려면 과금 정책 확인이 필요합니다. 대리 충전 서비스인 api-sparkle-charge.lovable.app에서 주문 시 "배치 + 캐시 할인 필요"라고 메모를 남겨주시면, 최적의 가격 등급으로 자동 연결해 드립니다.
왜 API 중계 서비스는 배치 처리를 지원하지 않을까: 기술적 이유 분석
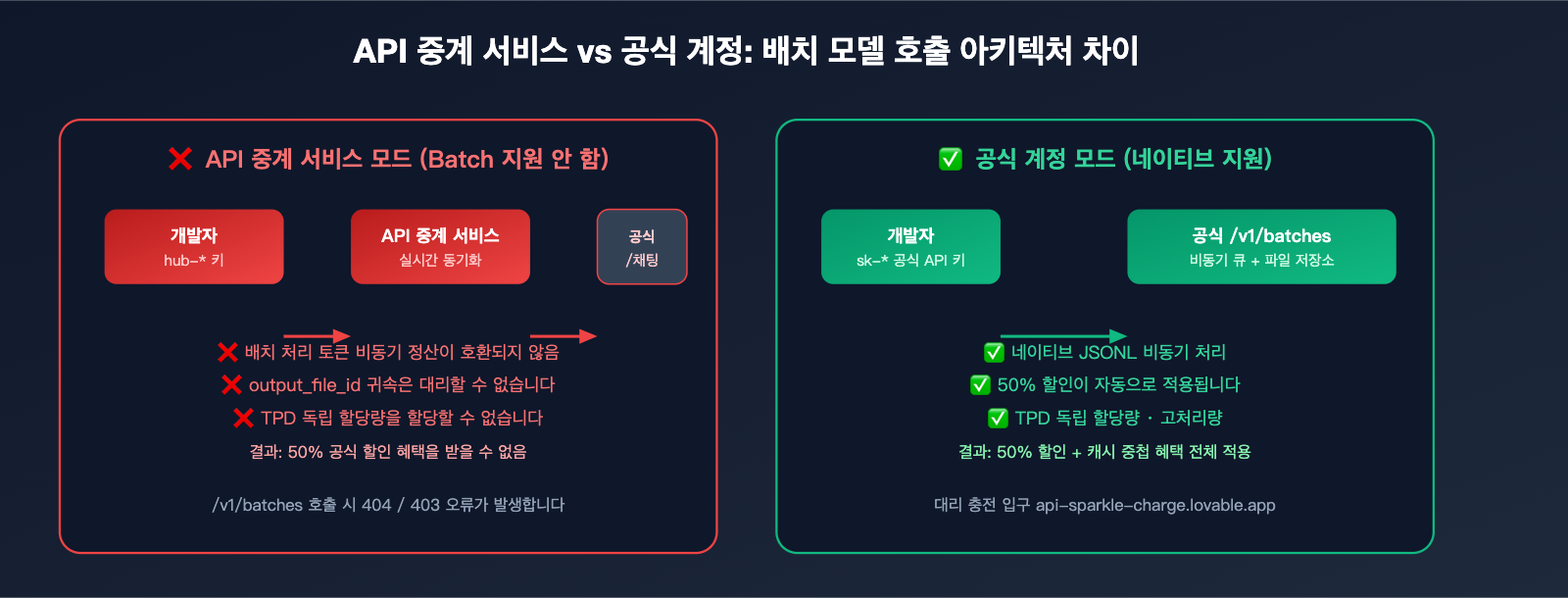
많은 사용자가 왜 API 중계 서비스들이 /v1/batches를 지원하지 않는지 궁금해합니다. 기술 아키텍처 관점에서 그 이유를 설명해 드릴게요.
근본 원인 1: 과금 모델의 불일치
중계 서비스는 실시간 호출을 기준으로 비용을 정산(공식 비용 × 1.x 프리미엄)하지만, 배치 처리는 24시간 후 일괄 정산되는 방식입니다. 이 경우 중계 서비스 측에서 비용을 선지불하고 나중에 회수해야 하므로, 막대한 자금 리스크와 환율 변동 리스크를 떠안아야 합니다.
근본 원인 2: 토큰 반환 경로의 불투명성
배치 처리 인터페이스가 반환하는 output_file_id는 공식 파일 시스템의 객체입니다. 중계 서비스가 이를 대행하려면 전체 파일 저장소와 대역폭 체계를 복제해야 하며, 다운로드 링크의 소유권을 전환하기도 매우 어렵습니다.
근본 원인 3: 독립적인 속도 제한(Rate Limit)
배치 처리 인터페이스는 동기식 TPM/RPM과는 완전히 분리된 TPD (Tokens Per Day) 할당량을 가집니다. 중계 서비스는 각 사용자의 일일 평균 할당량 수요를 예측하기 어렵기 때문에, 이를 합리적으로 재분배하는 것이 불가능합니다.
해결책: 대리 충전을 통한 공식 계정 개설
가장 깔끔한 방법은 사용자가 직접 공식 계정을 보유하는 것입니다:
- 기술적 측면: 모든 중계 제한을 우회하여
/v1/batches의 모든 기능을 네이티브하게 사용 가능 - 규정 준수: 청구서, 규정 준수, 환불 등이 공식 채널을 통해 처리됨
- 효율성: 배치 처리를 위해 동기/비동기 처리를 분리할 필요가 없음
- 비용 측면: 대리 충전 서비스는 합리적인 수수료만 부과하며, 배치 처리 본연의 50% 할인 혜택을 온전히 누릴 수 있음
이것이 바로 api-sparkle-charge.lovable.app과 AI 대리 충전 사이트 ai.daishengji.com이 추구하는 핵심 가치입니다: 공식 계정과 API 키를 직접 확보하여 배치 처리의 비용 절감 혜택을 온전히 누리도록 돕는 것이죠.
실전: 10만 건의 고객 문의 자동 분류 (전체 예시)
바로 활용 가능한 엔지니어링 예시를 소개합니다. 10만 건의 과거 고객 문의 데이터를 의도별로 분류하는 작업입니다.
1단계: JSONL 입력 데이터 구성
import json
# 10만 건의 질문 리스트가 있다고 가정
with open("requests.jsonl", "w") as f:
for idx, q in enumerate(questions):
payload = {
"custom_id": f"q-{idx:06d}",
"method": "POST",
"url": "/v1/chat/completions",
"body": {
"model": "gpt-4o-mini",
"messages": [
{"role": "system", "content": "사용자 질문을 billing/tech/sales/other 중 하나로 분류하고, 카테고리 단어만 반환하세요."},
{"role": "user", "content": q}
],
"max_tokens": 8,
"temperature": 0
}
}
f.write(json.dumps(payload, ensure_ascii=False) + "\n")
2단계: 200MB 제한에 따른 파일 분할
# 10만 건이 200MB를 초과할 가능성이 있다면 4만 건 단위로 파일을 분할하세요.
# Gemini를 사용한다면 2GB 제한이므로 분할할 필요가 없습니다.
3단계: 제출 및 모니터링
batches = []
for path in ["part1.jsonl", "part2.jsonl", "part3.jsonl"]:
fobj = client.files.create(file=open(path, "rb"), purpose="batch")
b = client.batches.create(
input_file_id=fobj.id,
endpoint="/v1/chat/completions",
completion_window="24h"
)
batches.append(b.id)
4단계: 결과 취합
results = {}
for bid in batches:
b = client.batches.retrieve(bid)
if b.status == "completed":
content = client.files.content(b.output_file_id).text
for line in content.splitlines():
item = json.loads(line)
results[item["custom_id"]] = item["response"]["body"]["choices"][0]["message"]["content"]
비용 추산: 10만 건 × 약 600 토큰 × gpt-4o-mini 배치 가격 ≈ $6-9, 동기식 호출 대비 $6-9 절감 효과.
자주 묻는 질문 (FAQ)
Q1:API 중계 서비스의 API 키로 /v1/batches를 호출할 수 있나요?
불가능합니다. 중계 서비스에서 발급받은 키(보통 hub-, sk-proxy- 또는 사용자 지정 접두사로 시작)는 /v1/chat/completions와 같은 동기식 엔드포인트만 지원합니다. 배치 처리 인터페이스는 공식 계정 시스템의 파일 시스템과 비동기 작업 큐에 의존하므로, 반드시 공식 네이티브 sk-* 키를 사용해야 합니다. 공식 키가 필요하시다면 api-sparkle-charge.lovable.app을 통해 대리 결제 주문을 하시거나, AI 대리 결제 사이트 ai.daishengji.com에서 다양한 사양의 공식 계정 플랜을 확인해 보세요.
Q2:Gemini Batch의 50% 할인은 모든 모델에 적용되나요?
현재 Gemini 2.5 Pro, 2.5 Flash, 2.5 Flash-Lite, Gemini 3 Pro Image 모두 배치 처리 시 50% 할인이 적용되며, 입력 및 출력 토큰 비용이 절반으로 줄어듭니다. 무료 티어(Free Tier) 계정은 배치 처리를 사용할 수 없으며, 반드시 유료 계정이어야 합니다. 대리 결제를 통해 개통한 공식 유료 계정은 즉시 사용 가능합니다.
Q3:배치 처리 작업이 실패하면 어떻게 하나요? 비용은 환불되나요?
두 업체 모두 정책이 동일합니다. 실패한 개별 요청은 과금되지 않으며, 전체 배치가 취소되지는 않습니다. OpenAI는 output_file 내에 error 필드가 포함된 실패 항목을 반환하며, error_file_id를 통해 모든 오류를 집계합니다. Gemini는 state=JOB_STATE_FAILED 상태일 때 error 세부 정보를 제공합니다. custom_id를 기반으로 실패한 항목만 바로 재시도할 수 있습니다.
Q4:배치 처리에서도 프롬프트 캐싱(Prompt Caching)이 작동하나요?
작동합니다. OpenAI 문서에 따르면 배치 요청이 캐시된 입력 토큰(Cached Input Tokens)을 적중할 경우, 배치 50% 할인에 더해 캐시된 입력 토큰에 대해 추가로 50% 할인(즉, 원가의 25%)이 적용됩니다. 실제로 적용하려면 배치 내 요청의 접두사가 엄격하게 일치해야 하며 최소 캐시 길이를 충족해야 합니다.
Q5:대리 결제 서비스의 공식 계정은 안전한가요? 나중에 직접 충전할 수 있나요?
정식 대리 결제 서비스(예: api-sparkle-charge.lovable.app)는 완전한 소유권이 보장된 공식 계정을 제공합니다. 로그인 정보나 결제 수단은 사용자가 직접 변경할 수 있으며, 이후 해외 신용카드나 Apple Pay를 사용하여 직접 갱신할 수 있습니다. AI 대리 결제 사이트 ai.daishengji.com은 다양한 패키지를 제공하며, 세금 계산서 발행 및 기업 비용 처리를 지원하여 규정 준수 요구 사항을 충족합니다.
요약
배치 처리 API는 2026년 AI 엔지니어링 도입 시 가장 저평가된 비용 절감 수단입니다. completion_window="24h" 한 줄이면 전체 비용 구조를 절반으로 줄일 수 있습니다. 단, 호출자에게는 한 가지 엄격한 요구 사항이 있습니다. 반드시 공식 네이티브 계정과 키를 사용해야 하며, API 중계 플랫폼은 과금 아키텍처의 제한으로 인해 이를 대리할 수 없습니다.
대규모 오프라인 작업을 수행하는 팀에게 가장 경제적인 경로는 공식 계정을 직접 개통하고 프롬프트 캐싱을 통해 최적화하는 것입니다. 공식 API 대리 결제 서비스는 국내 개발자가 이러한 혜택을 누릴 수 있는 가장 편리한 통로입니다. 주문 주소는 api-sparkle-charge.lovable.app이며, 전체 가격표는 AI 대리 결제 사이트 ai.daishengji.com에서 확인하세요. 5분 만에 주문하고 30분 내에 입금 확인이 완료되어, 50% 배치 처리 할인을 즉시 누릴 수 있습니다.
📌 작성자: 본 문서는 APIYI(apiyi.com) 기술 팀에서 정리하였으며, 내용은 OpenAI Platform Docs 및 Google AI for Developers 공식 영문 문서를 기반으로 합니다. 가격 및 할당량은 2026년 4월 14일 공식 정책을 기준으로 합니다. 대리 결제 주문 링크: api-sparkle-charge.lovable.app / ai.daishengji.com