title: Kimi K2.5 Thinking 模式接入指南:开启深度推理,享受超值 API 价格
description: 详解如何通过 APIYI 平台调用 Kimi K2.5 并开启 enable_thinking 参数,享受低于官网八折的稳定价格,附完整调用示例。
作者注:详解如何通过 APIYI 平台调用 kimi-k2.5 并开启 enable_thinking 参数,享受低于官网八折的稳定价格,附 curl、Python、JavaScript 完整示例代码

Kimi K2.5 の thinking(思考)モードは、現在オープンソースモデルの中でもトップクラスの推論能力を誇る機能の一つで、AIME 2025 数学ベンチマークでは 96.1% という驚異的なスコアを記録しています。しかし、多くの開発者が API 接続時に「モデルが思考プロセスを出力してくれない」という問題に直面します。
これは、APIYI プラットフォームにおいて思考モードを有効にするには、手動で "enable_thinking": true パラメータを渡す必要があるためです。本記事では、ゼロから Kimi K2.5 思考モードの接続設定を完了させる手順を解説します。
🎯 核心価値: 本記事を読めば、kimi-k2.5 thinking モードの完全な呼び出し方法を習得でき、さらに APIYI を通じて公式サイトより 20% 以上安い価格で安定的にこの能力を利用する方法がわかります。
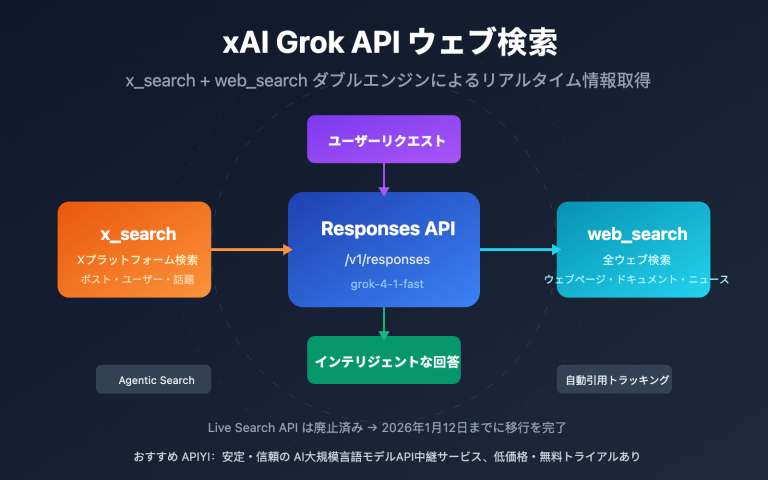
Kimi K2.5 Thinking モードの重要ポイント
| ポイント | 説明 | 価値 |
|---|---|---|
| 有効化パラメータ | "enable_thinking": true を渡す必要あり |
高度な推論能力を解放 |
| 推奨 temperature | 1.0 に設定(固定値) |
思考品質の安定化 |
| 推奨 max_tokens | 16000 以上 | 思考内容の完全な出力を確保 |
| 価格メリット | グループ価格 0.88、公式サイトの 8 割以下 | 推論コストを大幅削減 |
| 安定性 | Alibaba Cloud 公式転送レベル | 企業レベルの信頼性を保証 |
💡 クイックスタート: APIYI アカウント(apiyi.com)を作成し、チャージするだけで kimi-k2.5 を呼び出せます。OpenAI 互換インターフェースに対応しているため、既存のコードフレームワークを変更する必要はありません。
title: "Kimi K2.5 とは:1兆パラメータを誇るオープンソース推論の旗艦モデル"
description: "2026年1月27日にMoonshot AIが発表したKimi K2.5について解説。1兆パラメータの規模と高度な推論能力、APIYIでの利用方法を詳しく紹介します。"
Kimi K2.5 とは:1兆パラメータを誇るオープンソース推論の旗艦モデル
Kimi K2.5 は、Moonshot AI によって 2026 年 1 月 27 日に発表された、現在のオープンソースコミュニティにおいて最も強力な推論能力を持つマルチモーダル大規模言語モデルの一つです。
Kimi K2.5 の主要スペック
| スペック | 数値 | 説明 |
|---|---|---|
| 総パラメータ数 | 1兆(1T) | MoE(混合エキスパート)アーキテクチャ |
| アクティブパラメータ数 | 320億(32B) | 推論時に実際に使用される数 |
| コンテキストウィンドウ | 256K トークン | 超長文ドキュメント処理能力 |
| エキスパート数 | 384 エキスパート層 | MLA + MoE デュアルアーキテクチャ |
| 学習データ | 約15兆トークン | テキスト + 画像の混合データ |
| オープンソース状況 | 完全オープンソース | HuggingFace からダウンロード可能 |
Kimi K2.5 は、**マルチヘッド潜在アテンション(MLA)**と 384 エキスパートの MoE 構造を採用しています。総パラメータ数 1 兆を維持しながら、推論時には 320 億パラメータのみをアクティブにすることで、パフォーマンスとコストの最適なバランスを実現しました。
Kimi K2.5 の 4 つの実行モード
K2.5 Instant → 超高速レスポンス、思考プロセスなし、単純なタスク向け
K2.5 Thinking → 深層推論、reasoning_content を出力、複雑な問題向け
K2.5 Agent → 自律的なタスク実行、ツール呼び出し能力
K2.5 Agent Swarm → マルチエージェント連携、最大 100 個のサブエージェントを並列実行
APIYI プラットフォームは現在、K2.5 Thinking モードをサポートしており、enable_thinking: true パラメータを有効にすることで、完全な推論チェーンを出力可能です。
💡 利用アドバイス: 安定した Alibaba Cloud 公式中継リンクを利用できる APIYI (apiyi.com) 経由での kimi-k2.5 接続を推奨します。サービス中断の心配がありません。
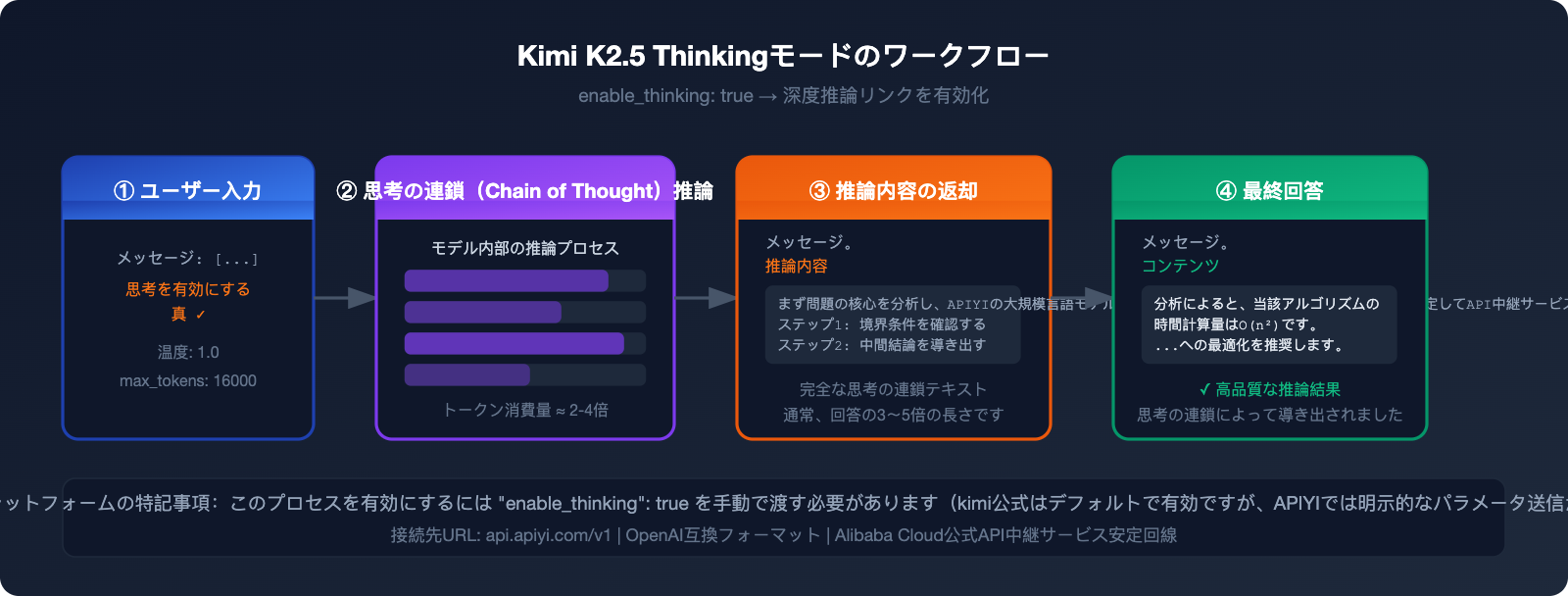
Kimi K2.5 パフォーマンスベンチマーク:思考モードの実測データ
「思考(Thinking)モード」を有効にすることで、kimi-k2.5 の推論パフォーマンスは大幅に向上しました。主要なベンチマークデータは以下の通りです。
主要なベンチマーク結果
| ベンチマーク | Kimi K2.5 スコア | 比較・解説 |
|---|---|---|
| AIME 2025(数学的推論) | 96.1% | 満点に近いレベル、トップクラスの数学能力 |
| SWE-Bench Verified(コード) | 76.8% | オープンソースモデルの中でトップレベル |
| HLE-Full w/ tools(エージェント) | 4.7ポイントリード | ツール呼び出しタスクで第1位 |
| BrowseComp(Webブラウジング) | 60.6% / 78.4%* | *Agent Swarm モード時 |
| 総合インテリジェンス指数 | 47 ポイント | 業界平均は 27 ポイント |
注: 上記データは Artificial Analysis Intelligence Index による 2026 年 1 月の評価結果です。
思考モード(Thinking mode)は標準モードと比較して、複雑な数学、多段階推論、コード生成などのタスクにおいて 30〜50% の大幅な向上が見られます。その代償として、トークン消費量は標準モードの 2〜4 倍程度になるため、max_tokens を適切に制御することがコスト削減の鍵となります。
APIYI で Kimi K2.5 思考モードを有効にする 3 ステップ
ステップ 1:APIキーの取得
APIYI 公式サイト apiyi.com にアクセスしてアカウントを登録し、以下の手順を進めてください。
- アカウント登録およびメール認証を完了する
- 「コンソール」→「APIキー管理」へ移動
- 新しい APIキーを作成し、保存する
🎯 価格のメリット: 100 ドルチャージで 10 ドルのボーナスが付与されます。グループ価格は 0.88(入力トークン)で、実質的な利用コストは Kimi 公式の 8 割以下です。APIYI は Alibaba Cloud 公式転送レベルの安定した回線を提供しており、企業レベルの信頼性を備えています。
ステップ 2:リクエストパラメータの設定
kimi-k2.5 の思考モードを有効にするには、以下の 3 つのパラメータ設定が重要です。
{
"model": "kimi-k2.5",
"enable_thinking": true,
"temperature": 1.0,
"max_tokens": 16000
}
⚠️ 重要: APIYI プラットフォームと Kimi 公式 API ではパラメータのロジックが異なります:
- Kimi 公式: 思考モードはデフォルトで有効であり、無効にするにはパラメータ指定が必要です。
- APIYI プラットフォーム:
"enable_thinking": trueを明示的に渡すことでアクティブ化されます。
ステップ 3:リクエストの送信と思考内容の解析
思考モードのアクティブ化とレスポンス解析を含む、呼び出しの完全なサンプルです。
curl サンプル(最も素早い検証方法)
curl --location 'https://api.apiyi.com/v1/chat/completions' \
--header "Authorization: Bearer sk-あなたのAPI_KEY" \
--header 'Content-Type: application/json' \
--data '{
"model": "kimi-k2.5",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "0.1 + 0.2 がコンピュータ上で 0.3 にならない理由を、ステップバイステップで説明してください。"
}
],
"enable_thinking": true,
"temperature": 1.0,
"max_tokens": 16000
}'
Python サンプル(本番環境での利用を推奨)
from openai import OpenAI
client = OpenAI(
api_key="sk-あなたのAPI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "以下のコードの時間計算量を分析し、最適化の提案をしてください:\n\ndef find_duplicates(arr):\n result = []\n for i in range(len(arr)):\n for j in range(i+1, len(arr)):\n if arr[i] == arr[j] and arr[i] not in result:\n result.append(arr[i])\n return result"
}
],
extra_body={
"enable_thinking": True
},
temperature=1.0,
max_tokens=16000
)
# 思考内容の解析(存在する場合)
message = response.choices[0].message
# 思考プロセスの出力(reasoning_content フィールド)
if hasattr(message, 'reasoning_content') and message.reasoning_content:
print("=== 思考プロセス ===")
print(message.reasoning_content)
print()
# 最終回答の出力
print("=== 最終回答 ===")
print(message.content)
JavaScript / Node.js の完全なサンプルを展開
import OpenAI from 'openai';
const client = new OpenAI({
apiKey: 'sk-あなたのAPI_KEY',
baseURL: 'https://api.apiyi.com/v1',
});
async function callKimiThinking(userMessage) {
const response = await client.chat.completions.create({
model: 'kimi-k2.5',
messages: [
{
role: 'system',
content: 'You are a helpful assistant.',
},
{
role: 'user',
content: userMessage,
},
],
// extra_body を通じて enable_thinking パラメータを渡します
// @ts-ignore
enable_thinking: true,
temperature: 1.0,
max_tokens: 16000,
});
const message = response.choices[0].message;
// 思考プロセスの抽出
const reasoningContent = message.reasoning_content;
if (reasoningContent) {
console.log('=== Thinking Process ===');
console.log(reasoningContent);
console.log();
}
// 最終回答の抽出
console.log('=== Final Answer ===');
console.log(message.content);
return {
thinking: reasoningContent,
answer: message.content,
};
}
// 使用例
callKimiThinking('素数が無限に存在することをステップバイステップで証明してください(ユークリッドの証明)');
💡 接続のヒント: 上記コードの
base_urlをhttps://api.apiyi.com/v1に置き換えるだけで、その他のパラメータは OpenAI SDK と完全に互換性があり、追加の学習コストは不要です。APIYI apiyi.com は、1 つのキーですべての主要モデルを呼び出すことができます。
主要なパラメータの詳解:正しく設定してトラブルを回避しよう
パラメータ設定対照表
| パラメータ | 推奨値 | 説明 | 誤った例 |
|---|---|---|---|
model |
"kimi-k2.5" |
モデル識別子 | kimi-k2 や kimi-k2.5-thinking は使用不可 |
enable_thinking |
true |
思考モードを有効化(APIYI専用) | このパラメータがないと推論内容が出力されません |
temperature |
1.0 |
公式推奨の固定値 | 0.7 などを設定すると品質が安定しません |
max_tokens |
≥ 16000 |
完全な出力を確保 | 値が小さすぎると思考内容が途切れます |
stream |
false(初期テスト時) |
ストリーミング/非ストリーミング両対応 | ストリーミング時は reasoning フィールドの処理が別途必要 |
APIレスポンス構造の解説
{
"choices": [
{
"message": {
"role": "assistant",
"content": "最終的な回答内容...",
"reasoning_content": "モデルの思考プロセス、段階的な推論を含む..."
}
}
],
"usage": {
"prompt_tokens": 150,
"completion_tokens": 3200,
"total_tokens": 3350
}
}
reasoning_content フィールドには完全な思考の連鎖が含まれています。通常、content フィールドの3〜5倍の長さになり、モデルの意思決定プロセスを理解するための核心となるデータです。
🎯 コスト管理のアドバイス: thinkingモードでは、トークンの消費量が通常モードの2〜4倍になります。APIYI(apiyi.com)経由での接続を推奨します。グループ価格が0.88であるため、推論コストを大幅に削減可能です。また、100ドル分チャージすると10ドル分のボーナスが付与されます。

description: "APIYIと公式サイトの価格・安定性を徹底比較。Kimi K2.5 Thinkingモードのコスト削減術や、最適な活用シーンを分かりやすく解説します。"
APIYI vs 公式サイト:価格と安定性の比較
プラットフォーム比較概要
| 比較項目 | APIYI (apiyi.com) | Kimi 公式 API | その他API中継サービス |
|---|---|---|---|
| 価格水準 | 公式の約8割(0.88倍のグループ価格) | 公式定価 | バラつきあり |
| 安定性 | Alibaba Cloud公式中継レベル | 直結、レート制限の影響あり | 不安定 |
| チャージ特典 | $100チャージで$10プレゼント | 特典なし | 各社異なる |
| インターフェース互換性 | OpenAI形式、100%互換 | Kimi SDKへの対応が必要 | 大半が互換あり |
| モデル対応数 | 100種類以上の主要モデル | Kimiシリーズのみ | 限定的 |
| 企業サポート | 専用カスタマーサポート + 領収書発行 | 標準サポート | 限定的 |
APIYI 価格優位性の計算例
毎月1,000回 kimi-k2.5 thinkingモードを呼び出す場合(平均:入力3,000トークン + 出力5,000トークン)の例:
# 入力トークンコスト:
# 公式価格 約$0.60/1M → 1000回 × 3000トークン = 3Mトークン → $1.80
# APIYI グループ価格 0.88倍 → 約 $1.58
# 出力トークンコスト(推論を含む):
# 公式価格 約$2.50/1M → 1000回 × 5000トークン = 5Mトークン → $12.50
# APIYI グループ価格 0.88倍 → 約 $11.00
# 月間の節約額: 約 $1.72 + チャージ特典による約10%の追加コストカバー
💡 実質的な割引: APIYIの「8割以下」というメリットは、グループ価格の割引(0.88倍)と、チャージ特典($100チャージで$10付与、つまり予算が10%増える)の2つを組み合わせたものです。実質的な総合コストは公式サイトの 79〜80% 程度になります。
Kimi K2.5 Thinkingモードの最適な活用シーン
Thinkingモードの利用を推奨するシーン
1. 複雑な数学的推論
# thinkingモードに適しています
prompt = "フェルマーの最終定理について、n=3の場合を証明し、詳細な手順を提示してください"
2. コードのデバッグと最適化
# thinkingモードに適しています
prompt = """
以下のコードには隠れた並行処理のバグがあります。原因を特定し、修正してください:
[複雑なマルチスレッドコードを貼り付け]
"""
3. 多段階の論理分析
# thinkingモードに適しています
prompt = "この事業計画書の論理的な欠陥を分析し、優先順位をつけて並べてください"
4. 科学的な推論
# thinkingモードに適しています
prompt = "量子力学の基本原理から、水素原子のエネルギー準位の公式を導出してください"
Thinkingモードが不要なシーン
# 以下のシーンでは通常モード(enable_thinkingを渡さない)を使用することで、
# トークンコストを50〜70%削減できます
# 単純な質問
"今日の天気はどうですか?" # 推論不要
# テキスト翻訳
"以下の内容を日本語に翻訳してください:..." # 推論不要
# フォーマット変換
"以下のJSONデータを整形して表示して" # 推論不要
# クリエイティブなライティング
"春についての詩を書いて" # 深い推論は不要
🎯 利用アドバイス: タスクの複雑さに応じてモードを動的に切り替えることをお勧めします。APIYI (apiyi.com) を経由すれば、同じAPIキーでkimi-k2.5(thinkingモード)と他の軽量モデルを柔軟に呼び出し、必要に応じて使い分けることが可能です。
ストリーミング出力:Thinkingモードのリアルタイムレスポンス処理
Thinkingモードでストリーミング(streaming)を使用する場合、reasoning_content の増分フラグメントを特別に処理する必要があります。
from openai import OpenAI
client = OpenAI(
api_key="sk-あなたのAPI_KEY",
base_url="https://api.apiyi.com/v1"
)
# ストリーミング呼び出しの例
stream = client.chat.completions.create(
model="kimi-k2.5",
messages=[
{"role": "user", "content": "クイックソートアルゴリズムの最悪時間計算量について分析してください"}
],
extra_body={"enable_thinking": True},
temperature=1.0,
max_tokens=16000,
stream=True
)
thinking_buffer = []
answer_buffer = []
is_thinking = True
for chunk in stream:
delta = chunk.choices[0].delta
# 思考内容のストリーム処理
if hasattr(delta, 'reasoning_content') and delta.reasoning_content:
thinking_buffer.append(delta.reasoning_content)
print(delta.reasoning_content, end='', flush=True)
# 最終回答のストリーム処理
elif delta.content:
if is_thinking:
print("\n\n=== 最終回答 ===\n")
is_thinking = False
answer_buffer.append(delta.content)
print(delta.content, end='', flush=True)
print() # 改行
💡 ストリーミング処理のポイント:
reasoning_contentとcontentはストリーミングにおいて独立したフィールドです。通常はreasoning_contentが完全に出力された後にcontentが出力されます。それぞれのフィールドの増分データを個別に監視する必要があります。
よくある質問 (FAQ)
Q1:呼び出し後に reasoning_content フィールドが表示されず、思考モードが有効になりません。
A:以下の3点を確認してください:
"enable_thinking": trueパラメータが正しく渡されているかmax_tokensが 16000 以上に設定されているか- Python SDK で呼び出す際、
extra_body={"enable_thinking": True}を通じてパラメータを渡しているか
まずは curl で直接テストを行い、パラメータの形式が正しいことを確認してからコードに統合することをお勧めします。APIYI(apiyi.com)のカスタマーサポートが技術サポートを提供しています。
Q2:Thinkingモードでトークン消費量が高くなります。コストを抑えるには?
A:以下の観点から最適化が可能です:
- 単純なタスクではThinkingモードをオフにする(
enable_thinkingパラメータを渡さない) max_tokensを適切に下げる(最低8000ですが、複雑な推論が途切れる可能性があります)- タスクレベルで振り分ける:複雑な推論には
kimi-k2.5 thinkingを使い、単純なタスクにはgpt-4o-miniなどの軽量モデルを使う - APIYI(apiyi.com)のグループ価格(0.88)を利用して基礎コストを下げる
Q3:temperature は必ず 1.0 に設定する必要がありますか?
A:公式では 1.0 に設定することを強く推奨しています。これが kimi-k2.5 thinking モードにおける最適な温度パラメータです。低すぎる設定(0.7など)ではモデルの推論が保守的になり品質が低下し、高すぎる設定(1.5など)では推論の整合性が失われる可能性があります。1.0 をそのまま使用するのが最も安全な選択です。
Q4:APIYI の kimi-k2.5 は公式と完全に同じですか?
A:はい。APIYI は Alibaba Cloud の公式転送リンクを採用しており、モデルのウェイトと能力は Kimi 公式と完全に同一です。唯一の違いはパラメータの受け渡し方法で、公式はデフォルトでThinkingが有効ですが、APIYI では enable_thinking: true を手動で渡す必要があります。これはAPI中継サービスにおける標準的な仕様の違いであり、モデルの出力品質には影響しません。
まとめ:Kimi K2.5 Thinking モードの核心ポイント
| 項目 | 説明 |
|---|---|
| アクティブパラメータ | "enable_thinking": true を指定する必要があります |
| 温度設定 | temperature: 1.0 に固定してください |
| トークン予算 | max_tokens ≥ 16000 |
| レスポンスフィールド | 思考内容は reasoning_content、回答は content に格納されます |
| 接続先エンドポイント | https://api.apiyi.com/v1(OpenAI 互換) |
| 価格特典 | 公式サイトより20%以上お得、100ドルのチャージで10ドル分プレゼント |
Kimi K2.5 は、AIME 数学推論(96.1%)やコード生成(SWE-Bench 76.8%)といった主要なベンチマークで優れたパフォーマンスを発揮します。この思考モードは、多段階の推論が必要な複雑なタスクの処理に特に適しています。
🎯 今すぐ体験: APIYI 公式サイト apiyi.com にアクセスし、アカウントを登録して APIキーを取得してください。わずか5分で kimi-k2.5 thinking モードの接続が完了します。100ドルのチャージで10ドルのボーナスが付与され、グループ割引と組み合わせることで、Kimi 公式サイトの価格より20%以上安いコストで利用可能です。
本記事は APIYI 技術チームによって作成されました | データソース:Moonshot AI 公式ドキュメントおよび Artificial Analysis 評価レポート(2026年1月)
技術サポートが必要な場合は、APIYI ヘルプセンター(help.apiyi.com)までお問い合わせください。