當你需要在一夜之間處理數萬條商品描述、數據標註、內容審覈或向量化任務時,同步調用標準 API 既慢又貴。OpenAI 的 /v1/batches 與 Google Gemini Batch Mode 給出了相同的答案:上傳一個 JSONL 文件,24 小時內異步返回全部結果,價格直接打 5 折。
然而在實際落地中,中轉站(API 聚合平臺)由於計費模型與官方批處理接口的異步 Token 結算機制不兼容,通常不支持 /v1/batches 直連。這意味着如果你希望享受官方 50% 折扣以及億級 Token 的高併發能力,你必須使用官方賬戶 + 官方密鑰調用。對於國內開發者,最便捷的路徑是通過專業的官方 API 代充服務一鍵下單——下單地址:api-sparkle-charge.lovable.app,或訪問 AI 代充網:ai.daishengji.com 查看完整價目。
本文基於 OpenAI 與 Google AI 官方英文文檔,系統梳理兩大批處理 API 的技術規範、計費機制與接入實戰,並給出代充服務的場景化選擇指南。

批處理 API 核心價值:爲什麼值得專門開官方賬戶
批處理 API (Batch API) 是 OpenAI 與 Google 爲非實時、大吞吐場景設計的專用接口。它的核心交換邏輯是:你放棄實時響應的確定性,換取官方 50% 的價格減免和更高的速率上限。
批處理與同步 API 的本質差異
下表對比兩種調用模式的關鍵參數:
| 維度 | 同步 API | 批處理 API |
|---|---|---|
| 響應延遲 | 秒級 | 最長 24 小時 |
| 單位 Token 價格 | 標準價 | 5 折(-50%) |
| 單次請求上限 | 1 條 | OpenAI 5 萬條 / Gemini 2GB JSONL |
| 速率限制 | RPM/TPM 嚴格 | 獨立更高配額 |
| 失敗重試 | 調用方自理 | 接口層自動重試 |
| 提示詞緩存 | 5-10 分鐘窗口 | 批內共享系統提示可大幅節流 |
💡 接入建議:批處理 API 必須使用官方原生賬戶與密鑰調用,中轉聚合平臺無法透傳
/v1/batches異步任務。我們建議通過官方代充服務 api-sparkle-charge.lovable.app 直接下單官方額度,即可立刻獲得 5 折批處理優惠,配合 AI 代充網 ai.daishengji.com 的多幣種結算能力,1 分鐘完成賬戶充值。
哪些場景最適合使用批處理
根據官方文檔與頭部開發者的實踐,以下場景節省最顯著:
- 數據標註/分類:10 萬條評論情感分析,同步調用 ~$500,批處理僅 ~$250
- 商品描述生成:電商 SKU 批量擴寫,通常夜間一批次完成即可
- 文檔摘要/向量化:大規模知識庫處理
- 模型評測 (eval):跑測試集,對時效不敏感
- 內容審覈:UGC 批量過濾
- Embedding 批量生成:構建向量數據庫
OpenAI Batch API 技術規範 (/v1/batches)
OpenAI 的 /v1/batches 端點是行業標杆,2024 年發佈以來已穩定運行。它的設計哲學是完全複用同步接口的請求體,開發者從同步遷移到批處理的改造成本極低。
核心約束與配額
| 項目 | 取值 | 說明 |
|---|---|---|
| 完成窗口 | 24 小時 | 目前僅支持 24h |
| 單批次請求上限 | 50,000 條 | 超過需拆分多批次 |
| 單文件大小上限 | 200 MB | 以 UTF-8 JSONL 爲準 |
| 支持端點 | /v1/chat/completions / /v1/embeddings / /v1/completions / /v1/responses |
不含圖像/音頻 |
| 價格優惠 | -50% | 所有支持模型統一 5 折 |
| 特殊速率桶 | 獨立 | 不佔用同步 TPM |
JSONL 文件格式示例
OpenAI 要求上傳文件的每一行是一個獨立 JSON 對象,包含 custom_id、method、url、body 四個字段:
{"custom_id": "req-001", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "gpt-4o-mini", "messages": [{"role": "system", "content": "你是一個商品分類專家"}, {"role": "user", "content": "iPhone 17 Pro 256GB"}]}}
{"custom_id": "req-002", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "gpt-4o-mini", "messages": [{"role": "system", "content": "你是一個商品分類專家"}, {"role": "user", "content": "索尼 WH-1000XM6"}]}}
四步完成一次 OpenAI 批處理調用
步驟 1:上傳 JSONL 文件
from openai import OpenAI
client = OpenAI(api_key="sk-官方密鑰") # 代充獲得的官方 key
batch_file = client.files.create(
file=open("requests.jsonl", "rb"),
purpose="batch"
)
步驟 2:創建批處理任務
batch = client.batches.create(
input_file_id=batch_file.id,
endpoint="/v1/chat/completions",
completion_window="24h",
metadata={"project": "sku-classification-2026q2"}
)
print(batch.id) # batch_abc123
步驟 3:輪詢狀態
import time
while True:
b = client.batches.retrieve(batch.id)
print(b.status, b.request_counts)
if b.status in ("completed", "failed", "expired", "cancelled"):
break
time.sleep(60)
步驟 4:下載結果
if b.status == "completed":
result_text = client.files.content(b.output_file_id).text
with open("results.jsonl", "w") as f:
f.write(result_text)

🎯 密鑰獲取建議:OpenAI 批處理必須使用官方原生 sk-* 密鑰,中轉站 hub-* 或 sk-proxy-* 密鑰均無法調用
/v1/batches。如需快速獲取官方額度,可直接通過代充服務下單:api-sparkle-charge.lovable.app 支持 OpenAI/Anthropic/Google 三大官方賬戶代充,5-30 分鐘到賬,也可以在 AI 代充網 ai.daishengji.com 查看不同面額的優惠組合。
Gemini Batch Mode 技術規範
Google 在 2025 年推出的 Gemini Batch Mode 與 OpenAI 思路相近,但在文件體積與模型適配兩方面更激進。
核心約束與配額
| 項目 | 取值 | 說明 |
|---|---|---|
| 完成窗口 | 最長 24 小時 | 無嚴格 SLA |
| 單文件大小上限 | 2 GB | 約爲 OpenAI 10 倍 |
| 支持模型 | gemini-2.5-pro / flash / flash-lite | 包含 Gemini 3 Pro Image |
| 價格優惠 | -50% | input + output token 均 5 折 |
| 適用端點 | generateContent / embedContent |
與同步接口同款 |
| Vertex AI 版本 | 支持區域化部署 | 企業合規場景 |
Gemini JSONL 格式示例
{"key": "req-001", "request": {"contents": [{"parts": [{"text": "給下面商品寫一句 30 字賣點:iPhone 17 Pro 256GB"}]}]}}
{"key": "req-002", "request": {"contents": [{"parts": [{"text": "給下面商品寫一句 30 字賣點:Sony WH-1000XM6"}]}]}}
Gemini Batch 調用示例
from google import genai
client = genai.Client(api_key="AIza-官方密鑰")
# 上傳文件
uploaded = client.files.upload(file="requests.jsonl", config={"mime_type": "jsonl"})
# 創建批處理作業
batch_job = client.batches.create(
model="gemini-2.5-flash",
src=uploaded.name,
config={"display_name": "sku-cn-2026q2"}
)
# 獲取結果
final = client.batches.get(name=batch_job.name)
if final.state.name == "JOB_STATE_SUCCEEDED":
result_file = client.files.download(file=final.dest.file_name)
📌 Gemini 代充提示:Gemini 批處理能力只在 Google AI Studio 或 Vertex AI 的原生付費賬戶下開放,免費額度內不可用。如果你所在地區無法綁定國際信用卡,可通過 AI 代充網 ai.daishengji.com 的 Gemini 官方代充通道快速開通付費配額,或直接在 api-sparkle-charge.lovable.app 下單專屬代充訂單。
OpenAI 與 Gemini 批處理 API 對比決策
實際項目選型時,開發者常在兩者之間猶豫。下表給出關鍵維度對比:
| 對比項 | OpenAI Batch | Gemini Batch | 推薦場景 |
|---|---|---|---|
| 單批請求上限 | 50,000 條 | 2GB JSONL(~10 萬+) | 超大批量選 Gemini |
| 單文件體積 | 200 MB | 2 GB | 超大批量選 Gemini |
| 響應質量 (中文) | gpt-4o/4.1 系列強 | gemini-2.5-pro 綜合均衡 | 中文強推理選 GPT |
| 多模態支持 | 文本/Embeddings | 文本/圖像生成 | 圖像批量選 Gemini |
| 緩存複用 | prompt caching | implicit context caching | 相同系統詞選 OpenAI |
| 計費複雜度 | 簡單清晰 | 需區分模型檔位 | 財務審計選 OpenAI |
| 接入文檔成熟度 | 最成熟 | 持續迭代中 | 快速落地選 OpenAI |

場景化選型建議
- 中文電商 SKU 批處理:gpt-4o-mini Batch,性價比最高
- 跨模態圖文混合:Gemini 2.5 Pro Batch,統一管道
- 海量 Embedding 構建:OpenAI text-embedding-3-small Batch
- 企業合規多區域:Vertex AI Gemini Batch
系統提示詞複用與緩存深度優化
用戶常問:"批處理裏每條請求都帶相同的系統提示詞,是否可以只計費一次?" 這是一個高頻但易被誤解的問題。
OpenAI 批處理內的提示詞計費真相
OpenAI /v1/batches 本身不會自動去重相同系統提示詞。但結合Prompt Caching 機制,當批內同一 conversation 前綴連續命中時,Cached input tokens 額外享受 50% 折扣,疊加批處理的 50%,理論最低可達 2.5 折。
具體生效條件:
- 請求體前綴必須嚴格一致 (包括角色、工具定義、文本)
- 前綴長度 ≥ 1024 tokens (部分模型 512 tokens)
- 同一 24 小時窗口內觸達緩存命中閾值
Gemini 的隱式上下文緩存
Gemini Batch Mode 原生支持 Implicit Context Caching,當請求前綴重複時,系統自動創建緩存,無需手動管理 cached_content。緩存命中部分按 Gemini 緩存價格結算(約原價 25%),再疊加 Batch 的 50%,最低可至 12.5%。
批處理 + 緩存的組合成本測算
假設 10 萬條請求,每條共享 2000 tokens 系統提示 + 500 tokens 用戶輸入 + 300 tokens 輸出:
| 方案 | 單條成本 | 總成本估算 | 節省幅度 |
|---|---|---|---|
| 同步調用 (無緩存) | $0.0028 | $280 | 基準 |
| 同步 + Prompt Caching | $0.0018 | $180 | -36% |
| 批處理 (50% off) | $0.0014 | $140 | -50% |
| 批處理 + Caching | $0.0009 | $90 | -68% |
⚡ 省錢組合建議:同一系統提示詞 + 同一模型 + 夜間任務 三條件同時滿足時,務必走「批處理 + Prompt Caching」組合拳。在官方賬戶中啓用上述優化需要確認計費策略,代充服務 api-sparkle-charge.lovable.app 下單時可備註"需開啓 batch + cache 優惠",會自動爲你綁定最優價格檔位。
爲什麼中轉站不支持批處理:技術原因剖析
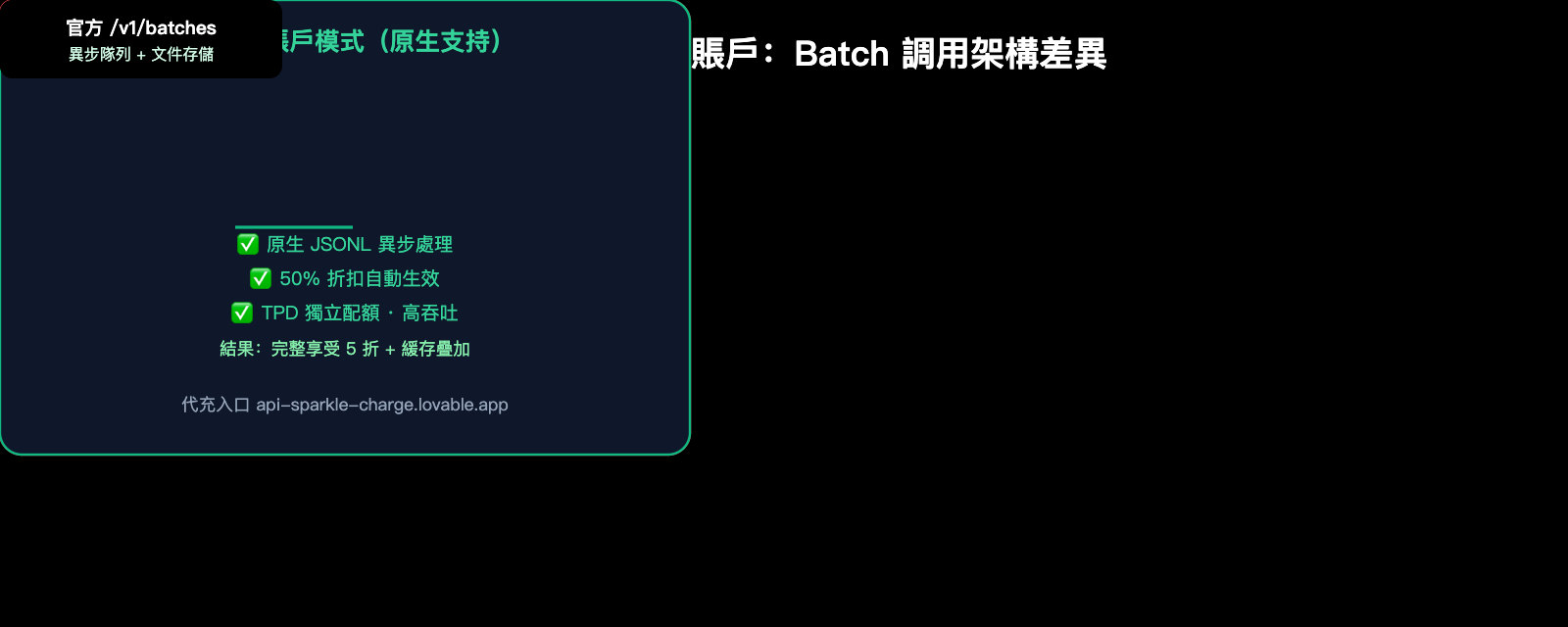
很多用戶不理解,爲什麼中轉 API 平臺普遍不支持 /v1/batches?這需要從技術架構層面說明:
根本原因一:計費模型不兼容
中轉站基於實時調用進行價差計費(官方成本 × 1.x 溢價),而批處理是24 小時後一次性結算,需要中轉站承擔先墊付、後回收的大額資金風險與匯率風險。
根本原因二:Token 回傳鏈路不透明
批處理接口返回的 output_file_id 是官方文件系統的對象,中轉站若要代理必須複製整個文件存儲、帶寬體系,且下載鏈接歸屬方難以切換。
根本原因三:速率配額獨立
批處理接口有獨立的 TPD (Tokens Per Day) 配額,與同步 TPM/RPM 完全隔離。中轉站無法預估每個終端用戶的日均額度需求,難以做合理的二次分配。
解決方案:通過代充開通官方賬戶
最乾淨的方案是讓用戶直接持有官方賬戶:
- 技術層面:繞過所有中轉限制,原生訪問
/v1/batches全部能力 - 合規層面:賬單、合規、退款走官方通道
- 效率層面:不必在批處理場景再做同步/異步分流
- 成本層面:代充服務只收取合理手續費,批處理本身的 50% 優惠完整留存
這正是 api-sparkle-charge.lovable.app 與 AI 代充網 ai.daishengji.com 的核心價值主張:幫你拿到一手官方賬戶與密鑰,讓批處理省錢紅利完整變現。
實戰:10 萬條客服問答批量分類(完整示例)
下面給出一個可直接複用的工程化示例:對 10 萬條歷史客服問答進行意圖分類。
步驟 1:構造 JSONL 輸入
import json
with open("requests.jsonl", "w") as f:
for idx, q in enumerate(questions): # questions 爲 10 萬條列表
payload = {
"custom_id": f"q-{idx:06d}",
"method": "POST",
"url": "/v1/chat/completions",
"body": {
"model": "gpt-4o-mini",
"messages": [
{"role": "system", "content": "將用戶問題分類爲: billing/tech/sales/other,只返回類別單詞"},
{"role": "user", "content": q}
],
"max_tokens": 8,
"temperature": 0
}
}
f.write(json.dumps(payload, ensure_ascii=False) + "\n")
步驟 2:拆分 200MB 閾值
# 當 10 萬條可能超過 200MB 時,按每 4 萬條拆一個文件
# 使用 Gemini 則無需拆分,直接 2GB 上限
步驟 3:提交併監控
batches = []
for path in ["part1.jsonl", "part2.jsonl", "part3.jsonl"]:
fobj = client.files.create(file=open(path, "rb"), purpose="batch")
b = client.batches.create(
input_file_id=fobj.id,
endpoint="/v1/chat/completions",
completion_window="24h"
)
batches.append(b.id)
步驟 4:結果彙總
results = {}
for bid in batches:
b = client.batches.retrieve(bid)
if b.status == "completed":
content = client.files.content(b.output_file_id).text
for line in content.splitlines():
item = json.loads(line)
results[item["custom_id"]] = item["response"]["body"]["choices"][0]["message"]["content"]
成本估算:10 萬 × ~600 tokens × gpt-4o-mini Batch 價 ≈ $6-9,同比同步調用省 $6-9。
常見問題 (FAQ)
Q1:中轉站 API 密鑰能調用 /v1/batches 嗎?
不能。中轉站返回的密鑰 (通常以 hub-、sk-proxy- 或自定義前綴開頭) 僅支持 /v1/chat/completions 等同步端點。批處理接口依賴官方賬戶體系的文件系統與異步任務隊列,必須使用官方原生 sk-* 密鑰。如果你需要官方密鑰,可通過 api-sparkle-charge.lovable.app 代充下單獲取,或訪問 AI 代充網 ai.daishengji.com 查看不同規格的官方賬戶方案。
Q2:Gemini Batch 的 50% 折扣是否適用於所有模型?
目前 Gemini 2.5 Pro、2.5 Flash、2.5 Flash-Lite、Gemini 3 Pro Image 均享受批處理 50% 折扣,input 與 output token 同比減半。免費層級(Free Tier)賬戶無法使用批處理,必須是付費賬戶。通過代充開通的官方付費賬戶開箱即用。
Q3:批處理任務失敗了怎麼辦?費用會退還嗎?
兩家策略相同:失敗的單條請求不計費,整批次不取消。OpenAI 返回的 output_file 裏會包含 error 字段的失敗條目,error_file_id 聚合所有錯誤;Gemini 在 state=JOB_STATE_FAILED 時提供 error 詳情。你可以基於 custom_id 直接重放失敗條目。
Q4:提示詞 Prompt Caching 在批處理裏會觸發嗎?
會。OpenAI 文檔明確指出 Batch 請求命中 Cached Input Tokens 時,疊加 Batch 50% 折扣後的 cached input tokens 再享受 50% (即 25% 原價)。實際落地需保證批內請求前綴嚴格一致且達到最低緩存長度。
Q5:代充服務的官方賬戶是否安全?後續能否自己充值?
正規代充服務(如 api-sparkle-charge.lovable.app)交付的是完整權屬的官方賬戶,登錄信息、支付綁定均可由你自主修改,後續可自行使用國際信用卡或 Apple Pay 續費。AI 代充網 ai.daishengji.com 提供多檔套餐,支持賬單發票與企業報賬,滿足合規需求。
總結
批處理 API 是 2026 年 AI 工程化落地最被低估的省錢槓桿:一行 completion_window="24h",整條成本鏈腰斬。但它對調用方有一條硬性要求——必須使用官方原生賬戶與密鑰,中轉聚合平臺受計費架構限制無法代理。
對於有大規模離線任務的團隊,最經濟的路徑是直接開通官方賬戶、疊加 Prompt Caching 深度優化。官方 API 代充服務是國內開發者接入這一紅利的最便捷入口:下單地址 api-sparkle-charge.lovable.app,完整價目請訪問 AI 代充網 ai.daishengji.com。5 分鐘下單、30 分鐘到賬,讓 50% 批處理折扣立刻變現。
📌 作者署名:本文由 API易 apiyi.com 技術團隊整理,內容基於 OpenAI Platform Docs 與 Google AI for Developers 官方英文文檔,價格與配額以 2026-04-14 官方政策爲準。代充下單入口:api-sparkle-charge.lovable.app / ai.daishengji.com