Когда вам нужно за одну ночь обработать десятки тысяч описаний товаров, разметить данные, провести контент-модерацию или выполнить векторизацию, синхронные вызовы стандартных API становятся слишком медленными и дорогими. OpenAI /v1/batches и Google Gemini Batch Mode предлагают одно и то же решение: загружаете JSONL-файл, получаете все результаты асинхронно в течение 24 часов, а цена при этом снижается ровно в два раза.
Однако на практике сервисы-прокси API (агрегаторы) обычно не поддерживают прямое использование /v1/batches, так как их биллинговые модели несовместимы с асинхронным механизмом списания токенов официальных пакетных интерфейсов. Это значит, что если вы хотите получить официальную скидку 50% и высокую пропускную способность для миллиардов токенов, вам необходимо использовать официальный аккаунт + официальный API-ключ. Для разработчиков из РФ и СНГ самый удобный способ — воспользоваться профессиональными услугами пополнения официальных API-аккаунтов. Оформить заказ можно здесь: api-sparkle-charge.lovable.app, а полный прайс-лист доступен на сайте AI-пополнений: ai.daishengji.com.
В этой статье мы на основе официальной англоязычной документации OpenAI и Google AI разберем технические спецификации, механизмы тарификации и практические аспекты внедрения пакетных API, а также дадим рекомендации по выбору сервисов для пополнения баланса.
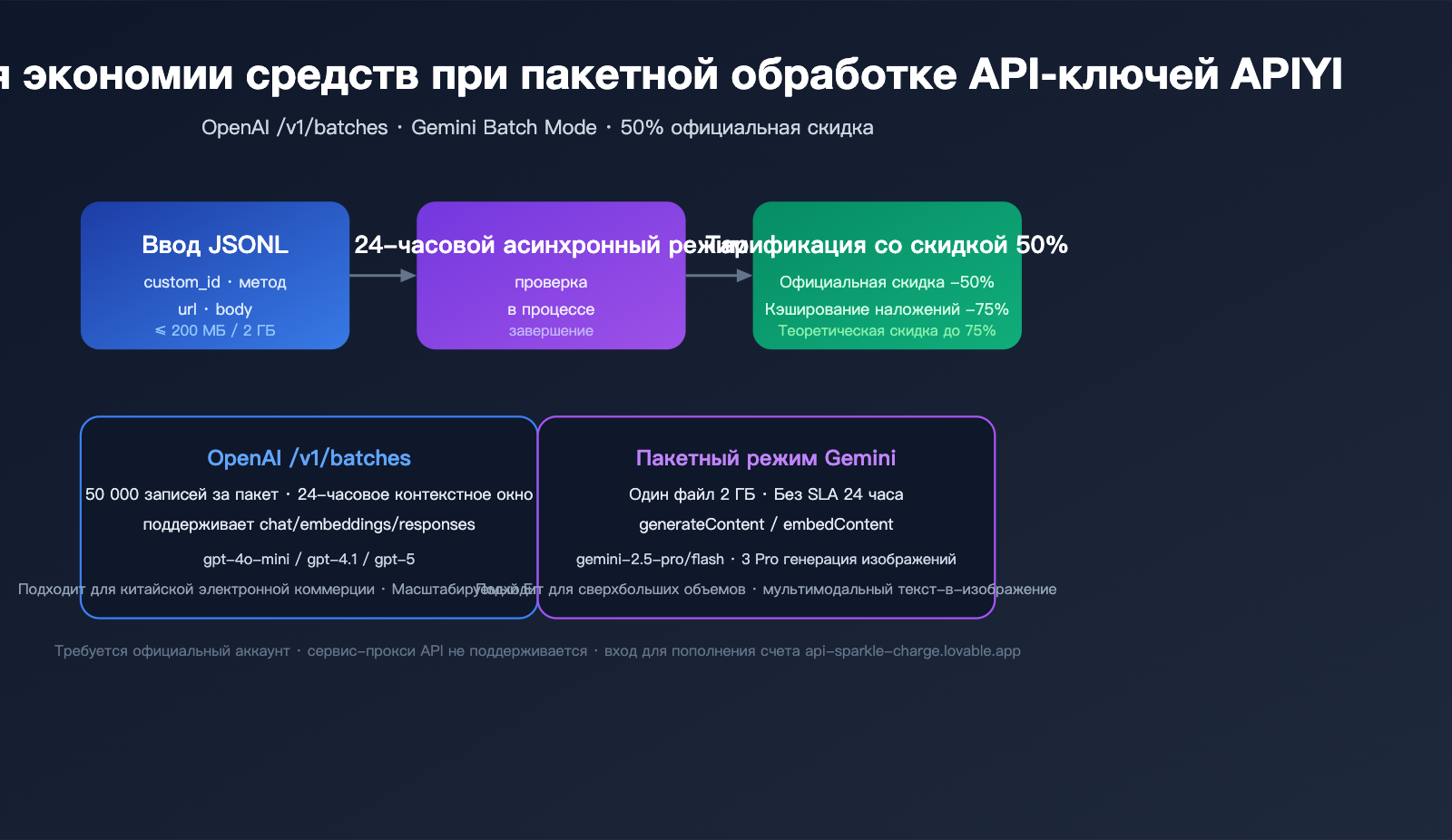
Основная ценность Batch API: почему стоит завести официальный аккаунт
Batch API — это специализированный интерфейс, разработанный OpenAI и Google для сценариев с некритичной задержкой и высокой пропускной способностью. Основная логика обмена проста: вы отказываетесь от мгновенного ответа ради экономии 50% бюджета и более высоких лимитов скорости.
Фундаментальные различия между пакетным и синхронным API
В таблице ниже приведено сравнение ключевых параметров двух режимов вызова:
| Параметр | Синхронный API | Пакетный (Batch) API |
|---|---|---|
| Задержка ответа | Секунды | До 24 часов |
| Цена за токен | Стандартная | Скидка 50% |
| Лимит на запрос | 1 запись | 50 тыс. (OpenAI) / 2 ГБ JSONL (Gemini) |
| Ограничения скорости | Строгие RPM/TPM | Отдельные, более высокие квоты |
| Повторные попытки | На стороне клиента | Автоматически на уровне API |
| Кэширование промптов | Окно 5-10 минут | Общий системный промпт внутри пакета |
💡 Совет по внедрению: Для работы с Batch API необходимо использовать официальные аккаунты и ключи; сервисы-прокси не могут передавать асинхронные задачи
/v1/batches. Мы рекомендуем использовать официальные сервисы пополнения, такие как api-sparkle-charge.lovable.app, для получения официальных лимитов. Это позволит сразу активировать скидку 50%, а с помощью возможностей мультивалютных расчетов на ai.daishengji.com вы сможете пополнить счет всего за минуту.
Для каких задач лучше всего подходит пакетная обработка
Согласно официальной документации и опыту ведущих разработчиков, наибольшую экономию можно получить в следующих сценариях:
- Разметка/классификация данных: анализ тональности 100 000 отзывов: синхронный вызов стоит ~$500, пакетный — ~$250.
- Генерация описаний товаров: массовое расширение описаний для SKU, которые можно подготовить за ночь.
- Саммаризация документов/векторизация: обработка масштабных баз знаний.
- Оценка моделей (eval): прогон тестовых наборов данных, где время не критично.
- Контент-модерация: массовая фильтрация пользовательского контента (UGC).
- Массовая генерация эмбеддингов: создание векторных баз данных.
Техническая спецификация OpenAI Batch API (/v1/batches)
Эндпоинт /v1/batches от OpenAI — это отраслевой стандарт, который стабильно работает с момента запуска в 2024 году. Его философия дизайна заключается в полном повторном использовании тела запроса синхронного интерфейса, поэтому затраты разработчиков на переход с синхронных вызовов на пакетную обработку минимальны.
Основные ограничения и квоты
| Параметр | Значение | Примечание |
|---|---|---|
| Окно выполнения | 24 часа | В настоящее время поддерживается только 24h |
| Лимит запросов на пакет | 50 000 | Если больше — нужно разбивать на несколько пакетов |
| Макс. размер файла | 200 МБ | В формате UTF-8 JSONL |
| Поддерживаемые эндпоинты | /v1/chat/completions / /v1/embeddings / /v1/completions / /v1/responses |
Без изображений/аудио |
| Скидка | -50% | Фиксированная скидка 50% на все поддерживаемые модели |
| Отдельный лимит скорости | Да | Не расходует TPM синхронных запросов |
Пример формата файла JSONL
OpenAI требует, чтобы каждая строка загружаемого файла была отдельным JSON-объектом, содержащим четыре поля: custom_id, method, url и body:
{"custom_id": "req-001", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "gpt-4o-mini", "messages": [{"role": "system", "content": "Вы эксперт по классификации товаров"}, {"role": "user", "content": "iPhone 17 Pro 256GB"}]}}
{"custom_id": "req-002", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "gpt-4o-mini", "messages": [{"role": "system", "content": "Вы эксперт по классификации товаров"}, {"role": "user", "content": "Sony WH-1000XM6"}]}}
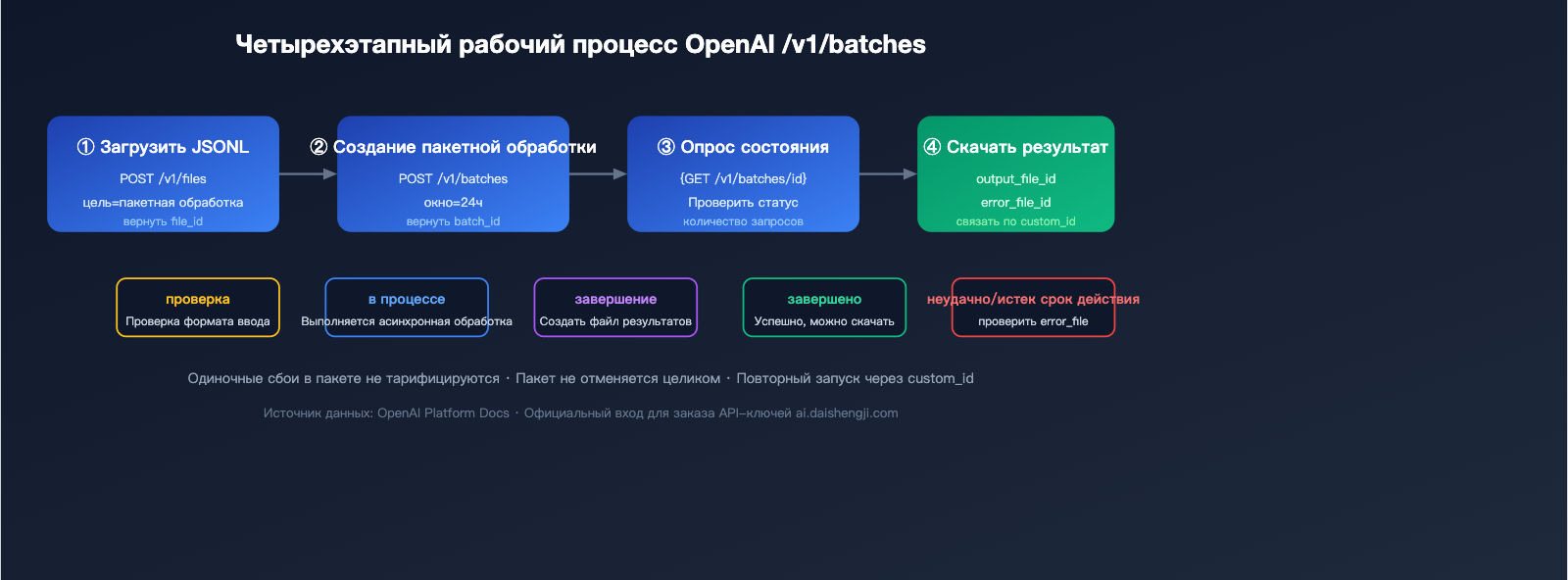
Четыре шага для выполнения пакетного вызова OpenAI
Шаг 1: Загрузка файла JSONL
from openai import OpenAI
client = OpenAI(api_key="sk-официальный_ключ") # Официальный ключ, полученный через сервис пополнения
batch_file = client.files.create(
file=open("requests.jsonl", "rb"),
purpose="batch"
)
Шаг 2: Создание задачи пакетной обработки
batch = client.batches.create(
input_file_id=batch_file.id,
endpoint="/v1/chat/completions",
completion_window="24h",
metadata={"project": "sku-classification-2026q2"}
)
print(batch.id) # batch_abc123
Шаг 3: Опрос статуса
import time
while True:
b = client.batches.retrieve(batch.id)
print(b.status, b.request_counts)
if b.status in ("completed", "failed", "expired", "cancelled"):
break
time.sleep(60)
Шаг 4: Скачивание результатов
if b.status == "completed":
result_text = client.files.content(b.output_file_id).text
with open("results.jsonl", "w") as f:
f.write(result_text)
🎯 Совет по получению ключей: Для пакетной обработки OpenAI необходимо использовать официальные нативные ключи
sk-*. Ключи через сервисы-прокси (hub-*илиsk-proxy-*) не поддерживают вызов/v1/batches. Если вам нужно быстро получить официальные лимиты, вы можете воспользоваться сервисами пополнения: api-sparkle-charge.lovable.app поддерживает пополнение официальных аккаунтов OpenAI/Anthropic/Google (зачисление за 5-30 минут), также можно ознакомиться с различными выгодными предложениями на сайте ai.daishengji.com.
Технические спецификации Gemini Batch Mode
Представленный Google в 2025 году Gemini Batch Mode во многом перекликается с подходом OpenAI, однако он более агрессивен в плане объема файлов и адаптации моделей.
Основные ограничения и квоты
| Параметр | Значение | Примечание |
|---|---|---|
| Окно выполнения | До 24 часов | Без строгих SLA |
| Макс. размер файла | 2 ГБ | Примерно в 10 раз больше, чем у OpenAI |
| Поддерживаемые модели | gemini-2.5-pro / flash / flash-lite | Включая Gemini 3 Pro Image |
| Скидка | -50% | 50% на input и output токены |
| Эндпоинты | generateContent / embedContent |
Те же, что и у синхронных API |
| Версия Vertex AI | Поддержка регионального развертывания | Для корпоративного комплаенса |
Пример формата Gemini JSONL
{"key": "req-001", "request": {"contents": [{"parts": [{"text": "Напиши 30-символьное описание для товара: iPhone 17 Pro 256GB"}]}]}}
{"key": "req-002", "request": {"contents": [{"parts": [{"text": "Напиши 30-символьное описание для товара: Sony WH-1000XM6"}]}]}}
Пример вызова Gemini Batch
from google import genai
client = genai.Client(api_key="AIza-ваш-API-ключ")
# Загрузка файла
uploaded = client.files.upload(file="requests.jsonl", config={"mime_type": "jsonl"})
# Создание пакетного задания
batch_job = client.batches.create(
model="gemini-2.5-flash",
src=uploaded.name,
config={"display_name": "sku-cn-2026q2"}
)
# Получение результата
final = client.batches.get(name=batch_job.name)
if final.state.name == "JOB_STATE_SUCCEEDED":
result_file = client.files.download(file=final.dest.file_name)
📌 Совет по пополнению баланса Gemini: Пакетная обработка Gemini доступна только в рамках платных аккаунтов Google AI Studio или Vertex AI; в рамках бесплатных лимитов она недоступна. Если в вашем регионе нет возможности привязать международную банковскую карту, вы можете воспользоваться официальными каналами пополнения Gemini через AI-сервисы или оформить заказ на специализированных платформах.
Сравнение и выбор между OpenAI и Gemini Batch API
При выборе инструмента для реальных проектов разработчики часто колеблются между этими двумя вариантами. В таблице ниже приведено сравнение по ключевым критериям:
| Критерий | OpenAI Batch | Gemini Batch | Рекомендуемый выбор |
|---|---|---|---|
| Лимит запросов в пакете | 50 000 шт. | 2 ГБ JSONL (~100 тыс.+) | Для огромных объемов — Gemini |
| Размер файла | 200 МБ | 2 ГБ | Для огромных объемов — Gemini |
| Качество ответов (RU) | Серия gpt-4o/4.1 сильнее | gemini-2.5-pro сбалансирован | Для сложного вывода — GPT |
| Мультимодальность | Текст/Embeddings | Текст/Генерация изображений | Для работы с фото — Gemini |
| Кэширование | prompt caching | implicit context caching | Для системных промптов — OpenAI |
| Сложность биллинга | Просто и понятно | Зависит от уровня модели | Для отчетности — OpenAI |
| Зрелость документации | Максимальная | В процессе развития | Для быстрого старта — OpenAI |

Рекомендации по выбору сценария
- Пакетная обработка SKU для e-commerce: gpt-4o-mini Batch — лучшее соотношение цены и качества.
- Мультимодальные задачи (текст + изображения): Gemini 2.5 Pro Batch — единый конвейер.
- Создание огромных массивов Embedding: OpenAI text-embedding-3-small Batch.
- Корпоративный комплаенс и мультирегиональность: Vertex AI Gemini Batch.
Оптимизация использования системных промптов и кэширования
Пользователи часто спрашивают: «Если в пакетной обработке (batch) каждая строка запроса содержит один и тот же системный промпт, можно ли оплатить его только один раз?» Это частый, но легко понимаемый неправильно вопрос.
Вся правда об оплате промптов в пакетной обработке OpenAI
Сам по себе /v1/batches в OpenAI не выполняет автоматическую дедупликацию одинаковых системных промптов. Однако в сочетании с механизмом Prompt Caching, когда префиксы диалогов внутри пакета идут последовательно, на Cached input tokens дополнительно предоставляется скидка 50%. В сумме со скидкой 50% на пакетную обработку, теоретически можно получить скидку до 75% (оплата 25% от базовой цены).
Условия применения:
- Префикс тела запроса должен быть строго идентичным (включая роли, определения инструментов и текст).
- Длина префикса ≥ 1024 токенов (для некоторых моделей — 512 токенов).
- Достижение порога попадания в кэш в течение одного 24-часового окна.
Неявное кэширование контекста в Gemini
Gemini Batch Mode поддерживает неявное кэширование контекста (Implicit Context Caching). Когда префиксы запросов повторяются, система автоматически создает кэш без необходимости вручную управлять cached_content. Часть, попавшая в кэш, тарифицируется по цене кэширования Gemini (около 25% от исходной цены), что в сочетании со скидкой 50% на Batch позволяет снизить стоимость до 12,5%.
Расчет стоимости комбинации «Пакетная обработка + Кэширование»
Предположим, у нас 100 000 запросов, каждый из которых содержит 2000 токенов системного промпта, 500 токенов ввода пользователя и 300 токенов вывода:
| Сценарий | Стоимость одного запроса | Общая стоимость | Экономия |
|---|---|---|---|
| Синхронный вызов (без кэша) | $0.0028 | $280 | База |
| Синхронный + Prompt Caching | $0.0018 | $180 | -36% |
| Пакетная обработка (скидка 50%) | $0.0014 | $140 | -50% |
| Пакетная обработка + Caching | $0.0009 | $90 | -68% |
⚡ Совет по экономии: Если одновременно выполняются три условия: один и тот же системный промпт, одна и та же модель и запуск задачи в ночное время — обязательно используйте связку «Пакетная обработка + Prompt Caching». Для активации этих оптимизаций в официальном аккаунте необходимо уточнить стратегию биллинга. При заказе через сервис пополнения api-sparkle-charge.lovable.app можно оставить комментарий «нужно включить скидку batch + cache», и вам автоматически привяжут оптимальный тарифный план.
Почему сервисы-прокси API не поддерживают пакетную обработку: технический разбор
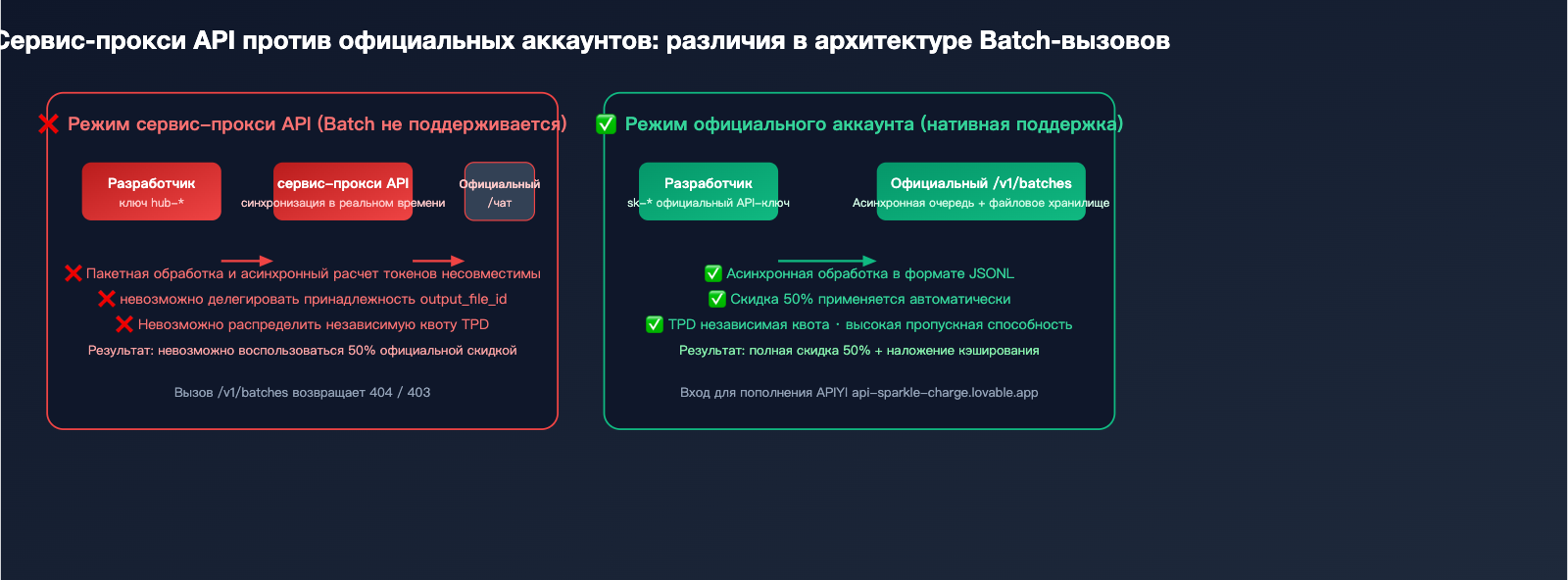
Многие пользователи не понимают, почему платформы-прокси API повсеместно не поддерживают /v1/batches? Это нужно объяснить с точки зрения технической архитектуры:
Причина №1: Несовместимость моделей биллинга
Сервисы-прокси работают на основе вызовов в реальном времени (официальная стоимость × наценка), в то время как пакетная обработка предполагает оплату по факту через 24 часа. Это вынуждает сервис-прокси брать на себя огромные финансовые риски и риски колебания валютных курсов из-за необходимости предварительной оплаты.
Причина №2: Непрозрачность цепочки передачи токенов
output_file_id, возвращаемый интерфейсом пакетной обработки, является объектом официальной файловой системы. Если сервис-прокси захочет выступать посредником, ему придется копировать всю систему хранения файлов и пропускную способность, при этом переключение владельца ссылки на скачивание крайне затруднительно.
Причина №3: Независимые квоты скорости
Интерфейс пакетной обработки имеет независимую квоту TPD (Tokens Per Day), которая полностью изолирована от синхронных TPM/RPM. Сервис-прокси не может заранее оценить среднюю дневную потребность каждого конечного пользователя, что делает невозможным разумное перераспределение квот.
Решение: Открытие официального аккаунта через сервис пополнения
Самый чистый вариант — дать пользователю возможность напрямую владеть официальным аккаунтом:
- Технический аспект: обход всех ограничений прокси, нативный доступ ко всем возможностям
/v1/batches. - Комплаенс: счета, соответствие требованиям и возвраты проходят через официальные каналы.
- Эффективность: нет необходимости разделять потоки на синхронные и асинхронные в сценариях пакетной обработки.
- Стоимость: сервис пополнения берет лишь разумную комиссию, а 50% скидка на пакетную обработку сохраняется в полном объеме.
В этом и заключается основная ценность api-sparkle-charge.lovable.app и ai.daishengji.com: помочь вам получить официальный аккаунт и API-ключ, чтобы вы могли в полной мере воспользоваться выгодой от пакетной обработки.
Практика: пакетная классификация 100 000 обращений в службу поддержки (полный пример)
Ниже приведен готовый к использованию инженерный пример: классификация намерений для 100 000 исторических записей диалогов службы поддержки.
Шаг 1: Формирование входного файла JSONL
import json
with open("requests.jsonl", "w") as f:
for idx, q in enumerate(questions): # questions — это список из 100 000 вопросов
payload = {
"custom_id": f"q-{idx:06d}",
"method": "POST",
"url": "/v1/chat/completions",
"body": {
"model": "gpt-4o-mini",
"messages": [
{"role": "system", "content": "Классифицируй вопрос пользователя как: billing/tech/sales/other, верни только одно слово категории"},
{"role": "user", "content": q}
],
"max_tokens": 8,
"temperature": 0
}
}
f.write(json.dumps(payload, ensure_ascii=False) + "\n")
Шаг 2: Разделение при превышении лимита в 200 МБ
# Если 100 000 записей превышают 200 МБ, разбиваем файл по 40 000 записей
# При использовании Gemini разбивка не требуется, так как лимит составляет 2 ГБ
Шаг 3: Отправка и мониторинг
batches = []
for path in ["part1.jsonl", "part2.jsonl", "part3.jsonl"]:
fobj = client.files.create(file=open(path, "rb"), purpose="batch")
b = client.batches.create(
input_file_id=fobj.id,
endpoint="/v1/chat/completions",
completion_window="24h"
)
batches.append(b.id)
Шаг 4: Сбор результатов
results = {}
for bid in batches:
b = client.batches.retrieve(bid)
if b.status == "completed":
content = client.files.content(b.output_file_id).text
for line in content.splitlines():
item = json.loads(line)
results[item["custom_id"]] = item["response"]["body"]["choices"][0]["message"]["content"]
Оценка стоимости: 100 000 × ~600 токенов × цена Batch для gpt-4o-mini ≈ $6-9, что на $6-9 дешевле, чем при обычном синхронном вызове.
Часто задаваемые вопросы (FAQ)
Q1: Можно ли использовать API-ключ сервиса-прокси для вызова /v1/batches?
Нет. Ключи, выдаваемые сервисами-прокси (обычно начинающиеся с hub-, sk-proxy- или имеющие префикс), поддерживают только синхронные эндпоинты, такие как /v1/chat/completions. Интерфейс пакетной обработки (Batch) опирается на файловую систему и очередь асинхронных задач официальной учетной записи, поэтому требуются оригинальные ключи sk-*. Если вам нужен официальный ключ, вы можете оформить заказ через APIYI (api-sparkle-charge.lovable.app) или ознакомиться с вариантами официальных аккаунтов на AI 代充网 (ai.daishengji.com).
Q2: Распространяется ли 50% скидка Gemini Batch на все модели?
В настоящее время Gemini 2.5 Pro, 2.5 Flash, 2.5 Flash-Lite и Gemini 3 Pro Image поддерживают 50% скидку на пакетную обработку, при этом стоимость входных и выходных токенов сокращается вдвое. Учетные записи уровня Free Tier не могут использовать пакетную обработку, необходим платный аккаунт. Официальные платные аккаунты, открытые через сервис пополнения, готовы к работе сразу.
Q3: Что делать, если пакетная задача завершилась ошибкой? Вернут ли деньги?
Стратегия у обоих провайдеров одинаковая: неудачные запросы не тарифицируются, весь пакет не отменяется. OpenAI возвращает output_file, где в поле error указаны неудачные записи, а error_file_id агрегирует все ошибки; Gemini предоставляет детали ошибки при state=JOB_STATE_FAILED. Вы можете повторно отправить только те запросы, которые завершились ошибкой, используя custom_id.
Q4: Работает ли кэширование промптов (Prompt Caching) в пакетной обработке?
Да. Документация OpenAI подтверждает, что если пакетный запрос попадает в кэшированные входные токены (Cached Input Tokens), к ним применяется 50% скидка Batch, а затем еще 50% (итого 25% от базовой цены). Для корректной работы необходимо обеспечить строгое совпадение префикса запроса внутри пакета и достижение минимальной длины кэширования.
Q5: Безопасны ли официальные аккаунты от сервисов пополнения? Можно ли потом пополнять их самостоятельно?
Надежные сервисы пополнения (например, api-sparkle-charge.lovable.app) передают вам полноценный официальный аккаунт, где вы можете самостоятельно менять данные для входа и привязанные способы оплаты. В дальнейшем вы сможете продлевать их с помощью международных банковских карт или Apple Pay. AI 代充网 (ai.daishengji.com) предлагает различные пакеты, поддерживает выставление счетов и отчетность для компаний, что удобно для корпоративных нужд.
Резюме
Batch API — это самый недооцененный способ сэкономить бюджет в AI-инжиниринге в 2026 году: одна строка completion_window="24h", и расходы сокращаются вдвое. Однако есть жесткое требование к вызывающей стороне: необходимо использовать официальные аккаунты и ключи. Сервисы-прокси API из-за особенностей своей архитектуры биллинга не могут выступать посредниками в этом процессе.
Для команд, работающих с масштабными офлайн-задачами, самый экономичный путь — это использование официальных аккаунтов в сочетании с глубокой оптимизацией через Prompt Caching. Официальные услуги по пополнению API — самый удобный способ для разработчиков из РФ воспользоваться этими преимуществами: оформить заказ можно на api-sparkle-charge.lovable.app, а актуальный прайс-лист доступен на ai.daishengji.com. Заказ оформляется за 5 минут, средства поступают в течение 30 минут — начните экономить 50% на пакетной обработке прямо сейчас.
📌 Авторство: Статья подготовлена технической командой APIYI (apiyi.com) на основе официальной документации OpenAI Platform и Google AI for Developers. Цены и квоты актуальны на 14.04.2026. Ссылки для пополнения: api-sparkle-charge.lovable.app / ai.daishengji.com