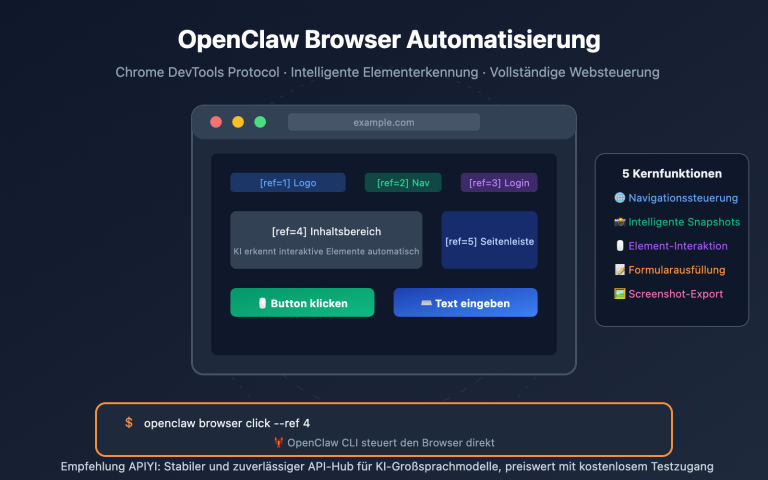
Wenn Sie über Nacht zehntausende von Produktbeschreibungen, Daten-Labelings, Inhaltsprüfungen oder Vektorisierungsaufgaben bearbeiten müssen, ist der synchrone Aufruf von Standard-APIs sowohl langsam als auch teuer. OpenAIs /v1/batches und der Google Gemini Batch-Modus bieten die gleiche Lösung: Laden Sie eine JSONL-Datei hoch und erhalten Sie alle Ergebnisse innerhalb von 24 Stunden asynchron zurück – zum halben Preis.
In der Praxis unterstützen API-Proxy-Dienste (Aggregationsplattformen) das direkte /v1/batches-Interface jedoch meist nicht, da ihre Abrechnungsmodelle nicht mit dem asynchronen Token-Abrechnungsmechanismus der offiziellen Batch-Schnittstellen kompatibel sind. Das bedeutet: Wenn Sie von den offiziellen 50 % Rabatt und der hohen Parallelverarbeitungskapazität bei Millionen von Token profitieren möchten, müssen Sie das offizielle Konto mit dem offiziellen API-Schlüssel verwenden. Für Entwickler im Inland ist der bequemste Weg die Bestellung über professionelle, offizielle API-Aufladungsdienste – bestellen Sie unter: api-sparkle-charge.lovable.app oder besuchen Sie AI-Daishengji (ai.daishengji.com), um die vollständige Preisliste einzusehen.
Dieser Artikel analysiert basierend auf den offiziellen englischsprachigen Dokumentationen von OpenAI und Google AI systematisch die technischen Spezifikationen, Abrechnungsmechanismen und die Implementierungspraxis beider Batch-APIs und bietet einen Leitfaden für die Wahl von Aufladungsdiensten in verschiedenen Szenarien.
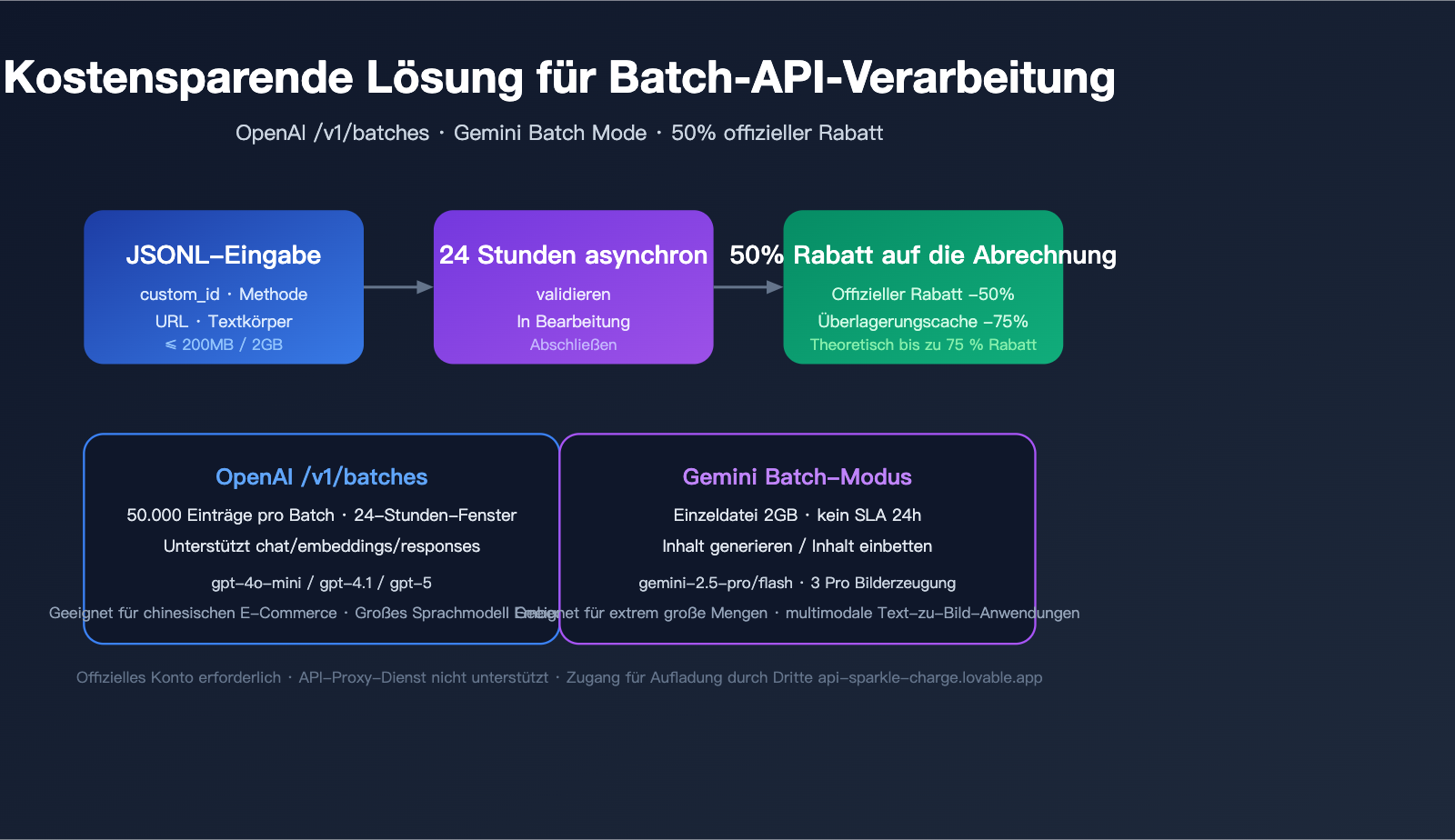
Der Kernwert der Batch-API: Warum sich ein offizielles Konto lohnt
Die Batch-API ist eine spezialisierte Schnittstelle von OpenAI und Google für Szenarien ohne Echtzeitanforderung und mit hohem Durchsatz. Die Kernlogik des Austauschs lautet: Sie verzichten auf die Vorhersehbarkeit der Echtzeit-Antwort und erhalten im Gegenzug einen offiziellen Preisnachlass von 50 % sowie höhere Ratenobergrenzen.
Wesentliche Unterschiede zwischen Batch- und synchroner API
Die folgende Tabelle vergleicht die wichtigsten Parameter der beiden Aufrufmodi:
| Dimension | Synchrone API | Batch-API |
|---|---|---|
| Antwortverzögerung | Sekundenbereich | Bis zu 24 Stunden |
| Preis pro Token | Standardpreis | 50 % Rabatt (-50 %) |
| Limit pro Anfrage | 1 Element | OpenAI 50.000 / Gemini 2 GB JSONL |
| Ratenbegrenzung | RPM/TPM strikt | Unabhängiges, höheres Kontingent |
| Fehlerbehandlung | Durch Aufrufer | Automatische Wiederholung durch API |
| Prompt-Caching | 5-10 Minuten Fenster | System-Prompts im Batch-Kontext geteilt |
💡 Empfehlung zur Einbindung: Die Batch-API muss mit einem offiziellen nativen Konto und API-Schlüssel aufgerufen werden; API-Proxy-Plattformen können asynchrone
/v1/batches-Aufgaben nicht durchschleifen. Wir empfehlen, über den offiziellen Aufladedienst api-sparkle-charge.lovable.app direkt ein offizielles Kontingent zu bestellen, um sofort den 50%-Batch-Rabatt zu erhalten. Kombiniert mit den Multi-Währungs-Abrechnungsmöglichkeiten von AI-Daishengji (ai.daishengji.com) ist die Kontonachladung in einer Minute erledigt.
Welche Szenarien eignen sich am besten für die Batch-API
Basierend auf offiziellen Dokumentationen und Erfahrungen führender Entwickler sind Einsparungen in folgenden Bereichen am signifikantesten:
- Daten-Labeling/Klassifizierung: Sentiment-Analyse von 100.000 Kommentaren (synchrone Kosten ca. 500 $, Batch-Kosten ca. 250 $)
- Erzeugung von Produktbeschreibungen: Batch-Erweiterung von E-Commerce-SKUs (meist über Nacht fertigstellbar)
- Dokumentenzusammenfassung/Vektorisierung: Verarbeitung großer Wissensdatenbanken
- Modell-Evaluierung (Eval): Test-Sets ausführen, bei denen Zeit nicht kritisch ist
- Inhaltsprüfung: Batch-Filterung von UGC-Inhalten
- Batch-Generierung von Embeddings: Aufbau von Vektordatenbanken
Technische Spezifikationen der OpenAI Batch API (/v1/batches)
Der /v1/batches-Endpunkt von OpenAI ist der Industriestandard und seit seiner Einführung im Jahr 2024 stabil im Einsatz. Die Designphilosophie basiert auf der vollständigen Wiederverwendung der Request-Bodys der synchronen Schnittstellen, wodurch der Migrationsaufwand für Entwickler minimal ist.
Kernbeschränkungen und Kontingente
| Element | Wert | Erläuterung |
|---|---|---|
| Zeitfenster | 24 Stunden | Aktuell nur 24h unterstützt |
| Limit pro Batch | 50.000 Anfragen | Bei Überschreitung in mehrere Batches aufteilen |
| Dateigrößenlimit | 200 MB | Basierend auf UTF-8 JSONL |
| Unterstützte Endpunkte | /v1/chat/completions / /v1/embeddings / /v1/completions / /v1/responses |
Ohne Bild/Audio |
| Preisvorteil | -50% | 50 % Rabatt auf alle unterstützten Modelle |
| Ratenbegrenzung | Separat | Belegt keine synchrone TPM |
Beispiel für das JSONL-Dateiformat
OpenAI erfordert, dass jede Zeile der hochgeladenen Datei ein eigenständiges JSON-Objekt ist, das die vier Felder custom_id, method, url und body enthält:
{"custom_id": "req-001", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "gpt-4o-mini", "messages": [{"role": "system", "content": "Du bist ein Experte für Produktkategorisierung"}, {"role": "user", "content": "iPhone 17 Pro 256GB"}]}}
{"custom_id": "req-002", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "gpt-4o-mini", "messages": [{"role": "system", "content": "Du bist ein Experte für Produktkategorisierung"}, {"role": "user", "content": "Sony WH-1000XM6"}]}}
Vier Schritte für einen OpenAI Batch-Aufruf
Schritt 1: JSONL-Datei hochladen
from openai import OpenAI
client = OpenAI(api_key="sk-offizieller-schlüssel") # Offizieller Key aus Aufladeservice
batch_file = client.files.create(
file=open("requests.jsonl", "rb"),
purpose="batch"
)
Schritt 2: Batch-Job erstellen
batch = client.batches.create(
input_file_id=batch_file.id,
endpoint="/v1/chat/completions",
completion_window="24h",
metadata={"project": "sku-classification-2026q2"}
)
print(batch.id) # batch_abc123
Schritt 3: Status abfragen
import time
while True:
b = client.batches.retrieve(batch.id)
print(b.status, b.request_counts)
if b.status in ("completed", "failed", "expired", "cancelled"):
break
time.sleep(60)
Schritt 4: Ergebnisse herunterladen
if b.status == "completed":
result_text = client.files.content(b.output_file_id).text
with open("results.jsonl", "w") as f:
f.write(result_text)
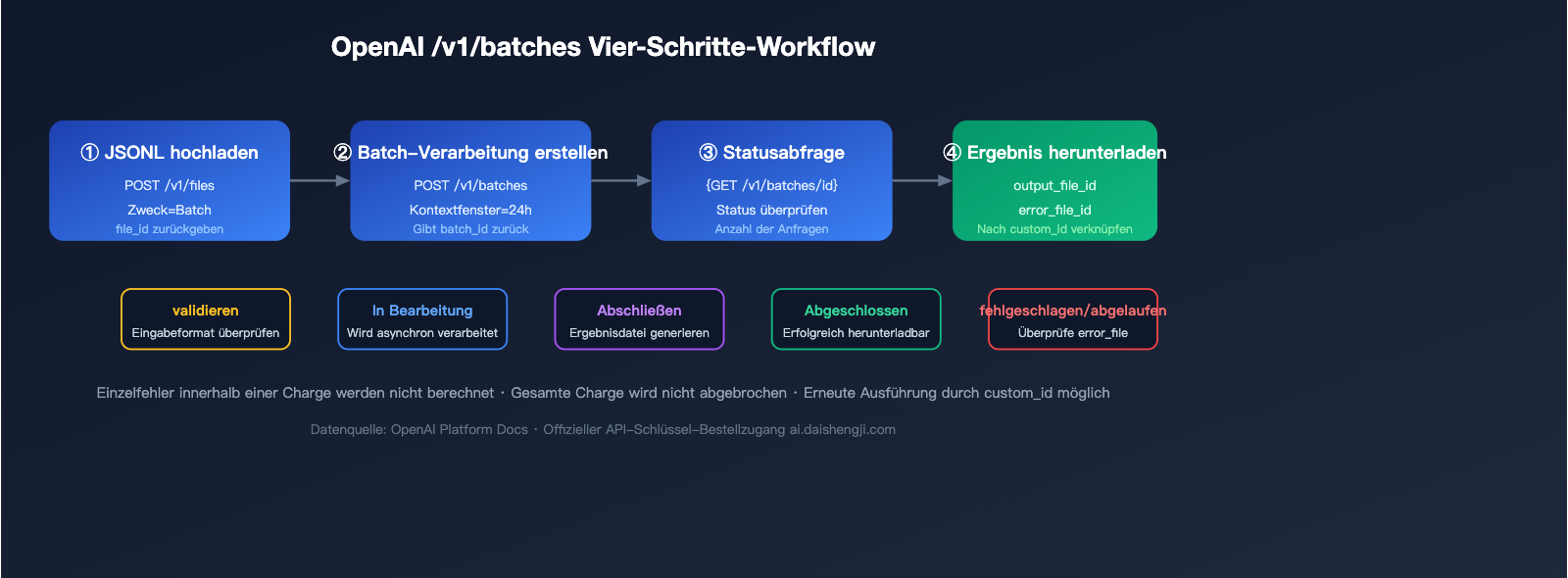
🎯 Tipp zum API-Schlüssel: Die OpenAI-Batch-Verarbeitung erfordert zwingend einen offiziellen, nativen
sk--Schlüssel. API-Proxy-Dienste (hub- oder sk-proxy-) können den/v1/batches-Endpunkt nicht aufrufen. Wenn Sie schnell offizielles Guthaben benötigen, können Sie dies über Aufladedienste wie api-sparkle-charge.lovable.app beziehen, die offizielle Konten für OpenAI/Anthropic/Google unterstützen und innerhalb von 5-30 Minuten gutschreiben. Weitere Angebote finden Sie unter ai.daishengji.com.
Technische Spezifikationen für den Gemini Batch Mode
Der 2025 von Google eingeführte Gemini Batch Mode verfolgt einen ähnlichen Ansatz wie OpenAI, ist jedoch bei der Dateigröße und der Modellanpassung deutlich aggressiver.
Kernbeschränkungen und Kontingente
| Element | Wert | Erläuterung |
|---|---|---|
| Abschlussfenster | Maximal 24 Stunden | Kein striktes SLA |
| Maximale Dateigröße | 2 GB | Etwa 10-mal so groß wie bei OpenAI |
| Unterstützte Modelle | gemini-2.5-pro / flash / flash-lite | Inklusive Gemini 3 Pro Image |
| Preisvorteil | -50% | 50 % Rabatt auf Input- und Output-Token |
| Verfügbare Endpunkte | generateContent / embedContent |
Identisch mit synchronen Schnittstellen |
| Vertex AI Version | Regionale Bereitstellung möglich | Für Compliance-Anforderungen in Unternehmen |
Beispiel für das Gemini JSONL-Format
{"key": "req-001", "request": {"contents": [{"parts": [{"text": "Schreibe ein 30-Wörter-Verkaufsargument für das folgende Produkt: iPhone 17 Pro 256GB"}]}]}}
{"key": "req-002", "request": {"contents": [{"parts": [{"text": "Schreibe ein 30-Wörter-Verkaufsargument für das folgende Produkt: Sony WH-1000XM6"}]}]}}
Beispiel für einen Gemini Batch-Aufruf
from google import genai
client = genai.Client(api_key="AIza-Offizieller-Schlüssel")
# Datei hochladen
uploaded = client.files.upload(file="requests.jsonl", config={"mime_type": "jsonl"})
# Batch-Job erstellen
batch_job = client.batches.create(
model="gemini-2.5-flash",
src=uploaded.name,
config={"display_name": "sku-cn-2026q2"}
)
# Ergebnisse abrufen
final = client.batches.get(name=batch_job.name)
if final.state.name == "JOB_STATE_SUCCEEDED":
result_file = client.files.download(file=final.dest.file_name)
📌 Hinweis zum Gemini-Guthaben: Die Batch-Verarbeitung von Gemini ist nur für kostenpflichtige Konten in Google AI Studio oder Vertex AI verfügbar und kann nicht mit dem kostenlosen Kontingent genutzt werden. Falls Sie in Ihrer Region keine internationale Kreditkarte hinterlegen können, nutzen Sie den offiziellen Aufladekanal von Gemini über ai.daishengji.com oder bestellen Sie direkt über api-sparkle-charge.lovable.app.
Entscheidungsmatrix: OpenAI vs. Gemini Batch API
Bei der Auswahl für reale Projekte schwanken Entwickler oft zwischen beiden Anbietern. Die folgende Tabelle bietet einen Vergleich der wichtigsten Dimensionen:
| Vergleichspunkt | OpenAI Batch | Gemini Batch | Empfehlung |
|---|---|---|---|
| Limit pro Batch | 50.000 Anfragen | 2 GB JSONL (~100.000+) | Gemini für riesige Mengen |
| Dateigröße | 200 MB | 2 GB | Gemini für riesige Mengen |
| Antwortqualität (Chinesisch) | Stärker bei gpt-4o/4.1 | Ausgewogen bei gemini-2.5-pro | GPT für komplexe Logik |
| Multimodale Unterstützung | Text/Embeddings | Text/Bilderzeugung | Gemini für Bildverarbeitung |
| Cache-Wiederverwendung | Prompt Caching | Implicit Context Caching | OpenAI für gleiche System-Prompts |
| Abrechnungskomplexität | Einfach und klar | Modellabhängige Staffelung | OpenAI für Finanz-Audits |
| Dokumentationsreife | Sehr ausgereift | Kontinuierliche Iteration | OpenAI für schnelle Umsetzung |

Empfehlungen zur Szenario-Auswahl
- Batch-Verarbeitung für chinesische E-Commerce-SKUs: gpt-4o-mini Batch, bestes Preis-Leistungs-Verhältnis
- Cross-modale Bild-Text-Mischung: Gemini 2.5 Pro Batch, einheitliche Pipeline
- Erstellung massiver Embeddings: OpenAI text-embedding-3-small Batch
- Unternehmens-Compliance und mehrere Regionen: Vertex AI Gemini Batch
Tiefenoptimierung bei Wiederverwendung und Caching von System-Eingabeaufforderungen
Benutzer fragen häufig: "Wenn jede Anfrage in einer Batch-Verarbeitung die gleiche System-Eingabeaufforderung enthält, kann mir diese dann nur einmal berechnet werden?" Dies ist eine häufig gestellte, aber oft missverstandene Frage.
Die Wahrheit über die Abrechnung von Eingabeaufforderungen in OpenAI-Batches
OpenAI /v1/batches führt selbst keine automatische Deduplizierung für identische System-Eingabeaufforderungen durch. In Kombination mit dem Prompt Caching-Mechanismus erhalten Sie jedoch, wenn die gleichen Conversation-Präfixe innerhalb eines Batches aufeinanderfolgen, einen zusätzlichen Rabatt von 50 % auf die Cached Input Tokens. Zusammen mit den 50 % Rabatt für die Batch-Verarbeitung sind theoretisch bis zu 75 % Ersparnis (25 % der Kosten) möglich.
Voraussetzungen für die Wirksamkeit:
- Das Präfix des Request-Bodys muss strikt identisch sein (einschließlich Rollen, Tool-Definitionen und Text).
- Die Präfix-Länge muss ≥ 1024 Tokens betragen (bei einigen Modellen 512 Tokens).
- Der Schwellenwert für Cache-Treffer muss innerhalb desselben 24-Stunden-Fensters erreicht werden.
Implizites Kontext-Caching bei Gemini
Der Gemini Batch Mode unterstützt nativ das Implicit Context Caching. Wenn ein Request-Präfix wiederholt wird, erstellt das System automatisch einen Cache, ohne dass cached_content manuell verwaltet werden muss. Der Bereich der Cache-Treffer wird zu den Gemini-Cache-Preisen abgerechnet (ca. 25 % des Originalpreises), worauf zusätzlich die 50 % Batch-Rabatt angewendet werden, was Gesamtkosten von bis zu 12,5 % ermöglicht.
Kostenkalkulation für die Kombination aus Batch-Verarbeitung + Caching
Angenommen, es werden 100.000 Anfragen verarbeitet, wobei sich jede eine System-Eingabeaufforderung von 2.000 Tokens, eine Benutzereingabe von 500 Tokens und eine Ausgabe von 300 Tokens teilt:
| Szenario | Kosten pro Einheit | Gesamtkostenschätzung | Ersparnis |
|---|---|---|---|
| Synchrone Aufrufe (ohne Cache) | $0,0028 | $280 | Basis |
| Synchron + Prompt Caching | $0,0018 | $180 | -36 % |
| Batch-Verarbeitung (50 % Rabatt) | $0,0014 | $140 | -50 % |
| Batch + Caching | $0,0009 | $90 | -68 % |
⚡ Spar-Empfehlung: Wenn eine identische System-Eingabeaufforderung, dasselbe Modell und eine Ausführung in der Nacht zusammenkommen, sollten Sie unbedingt auf die Kombination aus "Batch-Verarbeitung + Prompt Caching" setzen. Um diese Optimierungen in offiziellen Konten zu aktivieren, prüfen Sie die Abrechnungsstrategien. Bei Bestellungen über den Aufladeservice api-sparkle-charge.lovable.app können Sie den Hinweis "Batch + Cache Rabatt erforderlich" hinterlassen, wodurch Sie automatisch in die günstigste Preisklasse eingestuft werden.
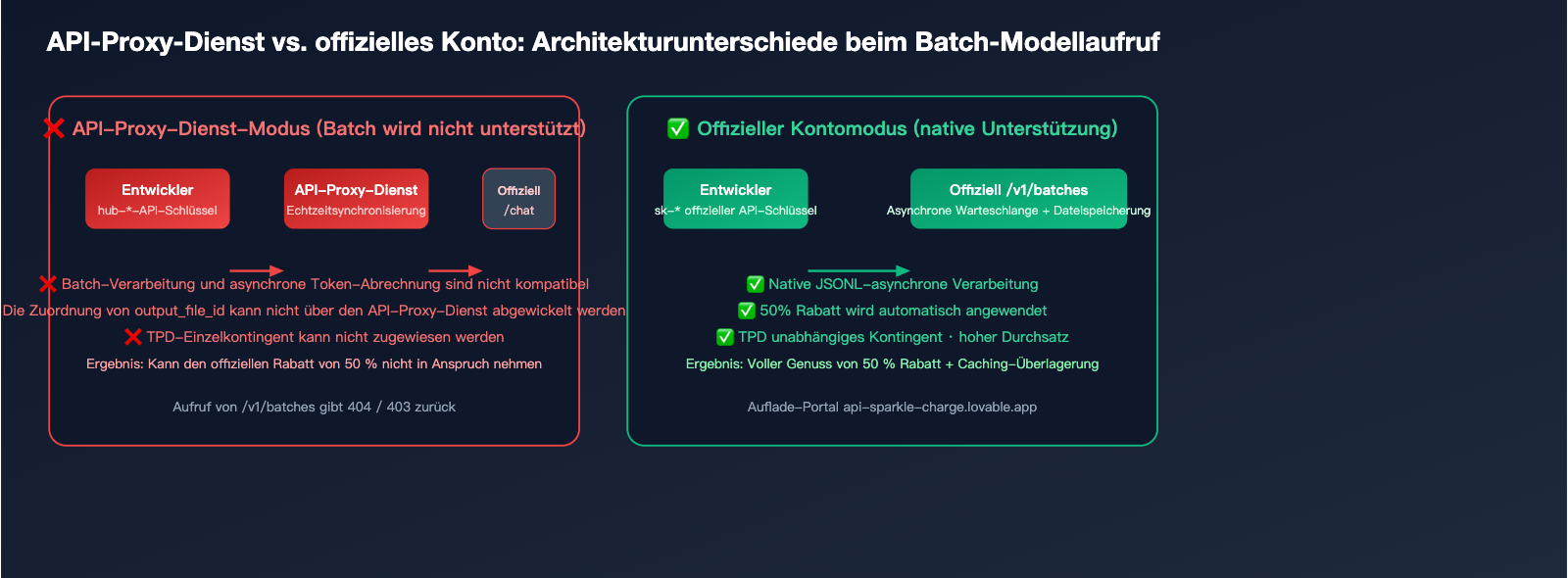
Warum API-Proxy-Dienste keine Batch-Verarbeitung unterstützen: Technische Analyse
Viele Benutzer verstehen nicht, warum API-Proxy-Plattformen im Allgemeinen /v1/batches nicht unterstützen. Dies muss auf technischer Architekturebene erläutert werden:
Grund 1: Inkompatibles Abrechnungsmodell
API-Proxy-Dienste basieren auf einer Echtzeit-Abrechnung (offizielle Kosten × Aufschlag), während Batches nach 24 Stunden gesammelt abgerechnet werden. Dies erfordert, dass der Proxy-Dienst finanzielle Vorleistungen erbringt und hohe Währungs- sowie Ausfallrisiken trägt.
Grund 2: Intransparente Token-Rückkanäle
Die über die Batch-Schnittstelle zurückgegebene output_file_id ist ein Objekt des offiziellen Dateisystems. Wenn ein API-Proxy dies vermitteln wollte, müsste er das gesamte Dateispeicher- und Bandbreitensystem replizieren, zudem sind die Download-Links schwer an Dritte zu übertragen.
Grund 3: Unabhängige Ratenbegrenzungen
Die Batch-Schnittstelle verfügt über ein separates TPD-Kontingent (Tokens Per Day), das von der synchronen TPM/RPM-Rate isoliert ist. Proxy-Dienste können den täglichen Bedarf der Endbenutzer nicht präzise abschätzen, was eine faire Zuweisung erschwert.
Lösung: Eröffnung eines offiziellen Kontos über einen Aufladedienst
Der sauberste Ansatz besteht darin, dass Benutzer direkt ein offizielles Konto besitzen:
- Technisch: Alle Proxy-Beschränkungen entfallen, Sie erhalten nativen Zugriff auf alle Funktionen von
/v1/batches. - Compliance: Abrechnungen, Konformität und Rückerstattungen erfolgen über offizielle Kanäle.
- Effizienz: Es ist keine Unterteilung zwischen synchronen und asynchronen Abläufen bei Batch-Szenarien erforderlich.
- Kosten: Der Aufladeservice erhebt nur eine angemessene Gebühr, und der 50 %-Vorteil der Batch-Verarbeitung bleibt vollständig erhalten.
Dies ist der Kernwert von api-sparkle-charge.lovable.app und ai.daishengji.com: Wir helfen Ihnen, offizielle Konten und Schlüssel direkt zu erhalten, damit Sie die Sparvorteile der Batch-Verarbeitung voll ausschöpfen können.
Praxis: Batch-Klassifizierung von 100.000 Kundenservice-Anfragen (Komplettbeispiel)
Hier ist ein direkt einsatzbereites technisches Beispiel für die Klassifizierung von 100.000 historischen Kundenservice-Anfragen nach ihrem Zweck.
Schritt 1: JSONL-Eingabe erstellen
import json
with open("requests.jsonl", "w") as f:
for idx, q in enumerate(questions): # questions ist eine Liste mit 100.000 Einträgen
payload = {
"custom_id": f"q-{idx:06d}",
"method": "POST",
"url": "/v1/chat/completions",
"body": {
"model": "gpt-4o-mini",
"messages": [
{"role": "system", "content": "Klassifiziere die Nutzeranfrage als: billing/tech/sales/other, gib nur das Wort der Kategorie zurück"},
{"role": "user", "content": q}
],
"max_tokens": 8,
"temperature": 0
}
}
f.write(json.dumps(payload, ensure_ascii=False) + "\n")
Schritt 2: Aufteilung bei der 200-MB-Grenze
# Wenn 100.000 Einträge die 200 MB überschreiten, teilen Sie die Datei in Blöcke von jeweils 40.000 Einträgen auf.
# Bei Gemini ist keine Aufteilung erforderlich, da das Limit bei 2 GB liegt.
Schritt 3: Übermittlung und Überwachung
batches = []
for path in ["part1.jsonl", "part2.jsonl", "part3.jsonl"]:
fobj = client.files.create(file=open(path, "rb"), purpose="batch")
b = client.batches.create(
input_file_id=fobj.id,
endpoint="/v1/chat/completions",
completion_window="24h"
)
batches.append(b.id)
Schritt 4: Zusammenfassung der Ergebnisse
results = {}
for bid in batches:
b = client.batches.retrieve(bid)
if b.status == "completed":
content = client.files.content(b.output_file_id).text
for line in content.splitlines():
item = json.loads(line)
results[item["custom_id"]] = item["response"]["body"]["choices"][0]["message"]["content"]
Kostenschätzung: 100.000 × ~600 Tokens × Batch-Preis für gpt-4o-mini ≈ 6-9 $, was eine Einsparung von 6-9 $ gegenüber synchronen Aufrufen bedeutet.
Häufig gestellte Fragen (FAQ)
Q1: Können API-Schlüssel von einem API-Proxy-Dienst für /v1/batches verwendet werden?
Nein. Die Schlüssel, die von einem API-Proxy-Dienst zurückgegeben werden (normalerweise mit hub-, sk-proxy- oder benutzerdefinierten Präfixen), unterstützen nur synchrone Endpunkte wie /v1/chat/completions. Die Batch-Schnittstelle ist an das Dateisystem und die asynchronen Aufgabenwarteschlangen des offiziellen Kontos gebunden; hierfür müssen native sk-*-Schlüssel verwendet werden. Wenn Sie offizielle Schlüssel benötigen, können Sie diese über api-sparkle-charge.lovable.app bestellen oder unter ai.daishengji.com verschiedene offizielle Kontopakete einsehen.
Q2: Gilt der 50%-Rabatt für Gemini Batch für alle Modelle?
Derzeit profitieren Gemini 2.5 Pro, 2.5 Flash, 2.5 Flash-Lite und Gemini 3 Pro Image von einem Batch-Rabatt von 50 %, wobei sowohl Eingabe- als auch Ausgabetokens halbiert werden. Kostenlose Konten (Free Tier) können keine Batch-Verarbeitung nutzen; ein kostenpflichtiges Konto ist erforderlich. Offizielle kostenpflichtige Konten, die über Vermittlungsdienste aktiviert wurden, sind sofort einsatzbereit.
Q3: Was passiert bei einem Batch-Fehler? Werden die Kosten erstattet?
Die Strategie beider Anbieter ist identisch: Fehlerhafte Einzelanfragen werden nicht berechnet, die gesamte Charge wird nicht storniert. Die von OpenAI zurückgegebene output_file enthält fehlerhafte Einträge mit einem error-Feld, und error_file_id aggregiert alle Fehler. Bei Gemini erhalten Sie bei state=JOB_STATE_FAILED Details zum Fehler. Sie können fehlgeschlagene Einträge direkt über die custom_id erneut senden.
Q4: Wird das Prompt Caching bei der Batch-Verarbeitung ausgelöst?
Ja. Die Dokumentation von OpenAI besagt ausdrücklich, dass Batch-Anfragen, die zwischengespeicherte Eingabetokens (Cached Input Tokens) treffen, nach Anwendung des 50%-Batch-Rabatts zusätzlich einen weiteren Rabatt von 50 % auf die zwischengespeicherten Tokens erhalten (insgesamt 25 % des ursprünglichen Preises). Für die Praxis muss sichergestellt werden, dass die Präfixe der Anfragen innerhalb der Batch identisch sind und die Mindestlänge für das Caching erreichen.
Q5: Sind offizielle Konten von Vermittlungsdiensten sicher? Kann ich sie später selbst aufladen?
Seriöse Vermittlungsdienste (wie api-sparkle-charge.lovable.app) liefern offizielle Konten mit vollständigen Eigentumsrechten. Anmeldedaten und Zahlungsmethoden können von Ihnen selbst geändert werden, und Sie können das Konto später mit einer internationalen Kreditkarte oder Apple Pay aufladen. AI 代充网 (ai.daishengji.com) bietet verschiedene Pakete an, unterstützt Rechnungsstellung und hilft bei der Einhaltung von Compliance-Anforderungen für Unternehmen.
Zusammenfassung
Die Batch-API ist der am meisten unterschätzte Hebel zur Kosteneinsparung bei der KI-Implementierung im Jahr 2026: Eine einzige Zeile completion_window="24h" halbiert die gesamte Kostenstruktur. Dies stellt jedoch eine harte Anforderung an den Aufrufer: Es muss ein offizielles, natives Konto mit entsprechendem API-Schlüssel verwendet werden. API-Proxy-Dienste können dies aufgrund ihrer Abrechnungsarchitektur nicht unterstützen.
Für Teams mit umfangreichen Offline-Aufgaben ist der wirtschaftlichste Weg die direkte Eröffnung eines offiziellen Kontos in Kombination mit einer tiefgreifenden Optimierung durch Prompt Caching. Der offizielle API-Aufladeservice von APIYI ist für Entwickler hierzulande der bequemste Zugang, um von diesem Vorteil zu profitieren: Bestellen Sie unter api-sparkle-charge.lovable.app, die vollständige Preisliste finden Sie unter ai.daishengji.com. Nach nur 5 Minuten Bestellung und 30 Minuten Gutschrift können Sie den 50%igen Batch-Rabatt sofort nutzen.
📌 Autorenhinweis: Dieser Artikel wurde vom technischen Team von APIYI (apiyi.com) zusammengestellt. Der Inhalt basiert auf den offiziellen englischsprachigen Dokumentationen von OpenAI Platform und Google AI for Developers. Preise und Kontingente basieren auf den offiziellen Richtlinien vom 14.04.2026. Link zur Aufladung: api-sparkle-charge.lovable.app / ai.daishengji.com