Saat Anda perlu memproses puluhan ribu deskripsi produk, anotasi data, moderasi konten, atau tugas vektorisasi dalam semalam, pemanggilan API sinkron biasa akan terasa lambat dan mahal. /v1/batches OpenAI dan Batch Mode Google Gemini memberikan solusi yang sama: unggah file JSONL, dapatkan hasil lengkap secara asinkron dalam 24 jam, dan harga langsung diskon 50%.
Namun, dalam praktiknya, layanan proksi API (platform agregator API) biasanya tidak mendukung koneksi langsung /v1/batches karena ketidaksesuaian antara model penagihan mereka dengan mekanisme penyelesaian token asinkron dari API batch resmi. Ini berarti jika Anda ingin menikmati diskon 50% resmi dan kapasitas konkurensi tinggi hingga ratusan juta token, Anda harus menggunakan akun resmi + kunci API resmi. Bagi pengembang di Indonesia, cara paling praktis adalah melakukan pemesanan melalui layanan pengisian saldo API resmi yang profesional—alamat pemesanan: api-sparkle-charge.lovable.app, atau kunjungi AI 代充网: ai.daishengji.com untuk melihat daftar harga lengkap.
Artikel ini disusun berdasarkan dokumentasi bahasa Inggris resmi OpenAI dan Google AI untuk merinci spesifikasi teknis, mekanisme penagihan, dan praktik implementasi API batch, serta memberikan panduan skenario untuk layanan pengisian saldo.

Nilai Inti API Batch: Mengapa Layak Menggunakan Akun Resmi
API Batch adalah antarmuka khusus yang dirancang oleh OpenAI dan Google untuk skenario tugas besar yang tidak memerlukan respons waktu nyata (non-real-time). Logika pertukarannya adalah: Anda mengorbankan kepastian respons waktu nyata demi potongan harga 50% dari pihak resmi dan batas kecepatan (rate limit) yang lebih tinggi.
Perbedaan Mendasar Antara API Sinkron dan API Batch
Tabel berikut membandingkan parameter kunci dari kedua mode pemanggilan:
| Dimensi | API Sinkron | API Batch |
|---|---|---|
| Latensi Respons | Hitungan detik | Hingga 24 jam |
| Harga per Token | Harga standar | Diskon 50% (-50%) |
| Batas per Permintaan | 1 entri | 50.000 entri OpenAI / 2GB JSONL Gemini |
| Batas Kecepatan | RPM/TPM ketat | Kuota independen yang lebih besar |
| Percobaan Ulang | Dikelola pengguna | Otomatis di tingkat API |
| Cache Petunjuk | Jendela 5-10 menit | Petunjuk sistem berbagi dalam batch menghemat biaya |
💡 Saran Implementasi: API Batch harus dipanggil menggunakan akun dan kunci resmi. Platform agregator proksi tidak dapat meneruskan tugas asinkron
/v1/batches. Kami menyarankan untuk melakukan pemesanan kuota resmi melalui layanan pengisian saldo api-sparkle-charge.lovable.app. Anda akan langsung mendapatkan diskon 50% untuk batch, dan dengan kemampuan penyelesaian multi-mata uang dari AI 代充网 ai.daishengji.com, isi ulang akun dapat selesai dalam 1 menit.
Skenario yang Paling Cocok untuk API Batch
Berdasarkan dokumentasi resmi dan praktik para pengembang, skenario berikut adalah yang paling menghemat biaya:
- Anotasi/Klasifikasi Data: 100.000 analisis sentimen ulasan; pemanggilan sinkron ~$500, Batch hanya ~$250.
- Pembuatan Deskripsi Produk: Penambahan konten SKU e-commerce secara massal, biasanya bisa diselesaikan dalam batch malam hari.
- Ringkasan Dokumen/Vektorisasi: Pemrosesan basis pengetahuan skala besar.
- Evaluasi Model (eval): Menjalankan set pengujian yang tidak sensitif terhadap waktu.
- Moderasi Konten: Pemfilteran massal UGC.
- Pembuatan Embedding Massal: Membangun basis data vektor.
Spesifikasi Teknis OpenAI Batch API (/v1/batches)
Endpoint /v1/batches dari OpenAI adalah standar industri yang telah berjalan stabil sejak dirilis pada tahun 2024. Filosofi desainnya adalah menggunakan kembali body permintaan dari antarmuka sinkron secara penuh, sehingga biaya migrasi bagi pengembang dari mode sinkron ke batch sangatlah rendah.
Batasan dan Kuota Utama
| Item | Nilai | Penjelasan |
|---|---|---|
| Jendela penyelesaian | 24 jam | Saat ini hanya mendukung 24h |
| Batas permintaan per batch | 50.000 item | Jika lebih, harus dipecah menjadi beberapa batch |
| Batas ukuran file tunggal | 200 MB | Berdasarkan format UTF-8 JSONL |
| Endpoint yang didukung | /v1/chat/completions / /v1/embeddings / /v1/completions / /v1/responses |
Tidak termasuk gambar/audio |
| Diskon harga | -50% | Diskon 50% untuk semua model yang didukung |
| Bucket tarif khusus | Independen | Tidak memakan TPM sinkron |
Contoh Format File JSONL
OpenAI mewajibkan setiap baris dalam file yang diunggah berupa objek JSON independen, yang mencakup empat field: custom_id, method, url, dan body:
{"custom_id": "req-001", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "gpt-4o-mini", "messages": [{"role": "system", "content": "Anda adalah pakar klasifikasi produk"}, {"role": "user", "content": "iPhone 17 Pro 256GB"}]}}
{"custom_id": "req-002", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "gpt-4o-mini", "messages": [{"role": "system", "content": "Anda adalah pakar klasifikasi produk"}, {"role": "user", "content": "Sony WH-1000XM6"}]}}
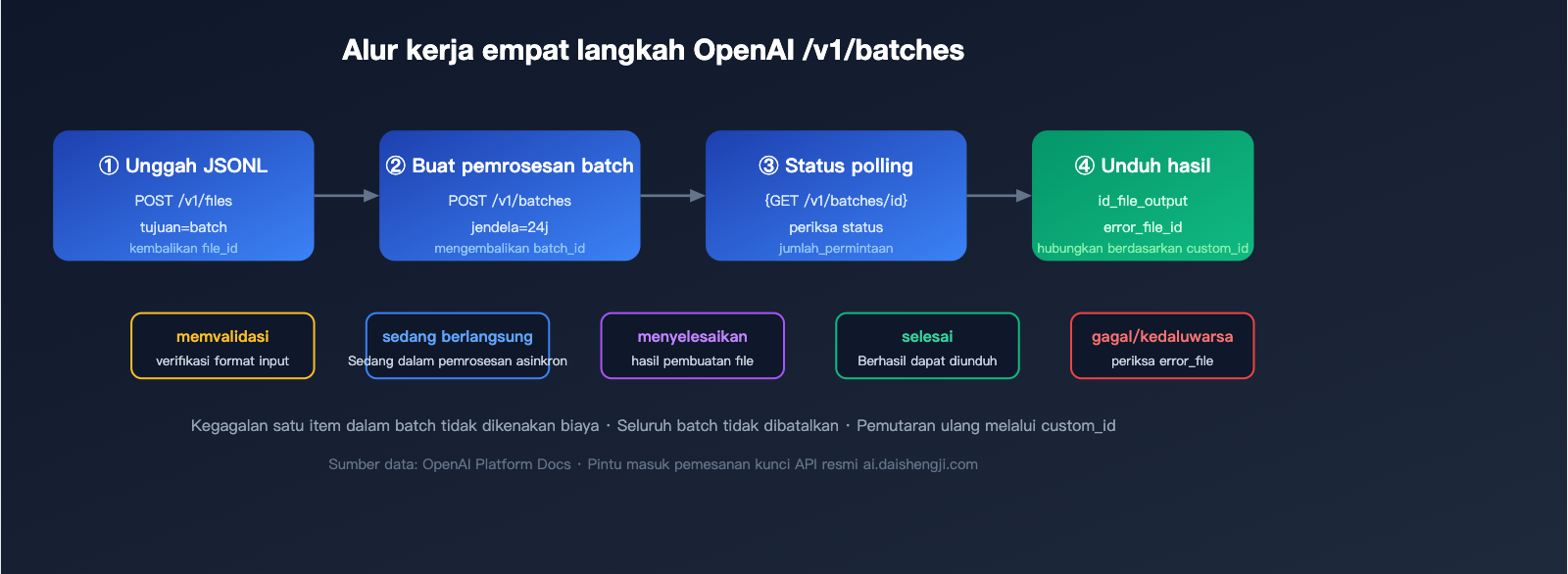
Empat Langkah Melakukan Pemanggilan Batch OpenAI
Langkah 1: Unggah file JSONL
from openai import OpenAI
client = OpenAI(api_key="sk-kunci-resmi") # Kunci resmi yang didapat dari layanan isi ulang
batch_file = client.files.create(
file=open("requests.jsonl", "rb"),
purpose="batch"
)
Langkah 2: Buat tugas batch
batch = client.batches.create(
input_file_id=batch_file.id,
endpoint="/v1/chat/completions",
completion_window="24h",
metadata={"project": "sku-classification-2026q2"}
)
print(batch.id) # batch_abc123
Langkah 3: Polling status
import time
while True:
b = client.batches.retrieve(batch.id)
print(b.status, b.request_counts)
if b.status in ("completed", "failed", "expired", "cancelled"):
break
time.sleep(60)
Langkah 4: Unduh hasil
if b.status == "completed":
result_text = client.files.content(b.output_file_id).text
with open("results.jsonl", "w") as f:
f.write(result_text)
🎯 Saran perolehan kunci: Pemrosesan batch OpenAI harus menggunakan kunci sk-* resmi. Kunci dari layanan proksi API seperti hub-* atau sk-proxy-* tidak dapat digunakan untuk memanggil
/v1/batches. Jika Anda memerlukan kuota resmi dengan cepat, Anda dapat memesan melalui layanan isi ulang: api-sparkle-charge.lovable.app yang mendukung isi ulang akun resmi OpenAI/Anthropic/Google dengan proses 5-30 menit, atau cek kombinasi diskon lainnya di situs isi ulang AI ai.daishengji.com.
Spesifikasi Teknis Gemini Batch Mode
Gemini Batch Mode yang diluncurkan Google pada tahun 2025 memiliki pendekatan yang mirip dengan OpenAI, namun lebih agresif dalam hal ukuran file dan adaptasi model.
Batasan dan Kuota Utama
| Item | Nilai | Penjelasan |
|---|---|---|
| Jendela penyelesaian | Maksimal 24 jam | Tidak ada SLA yang ketat |
| Batas ukuran file tunggal | 2 GB | Sekitar 10 kali lipat dari OpenAI |
| Model yang didukung | gemini-2.5-pro / flash / flash-lite | Termasuk Gemini 3 Pro Image |
| Diskon harga | -50% | Diskon 50% untuk token input + output |
| Endpoint yang berlaku | generateContent / embedContent |
Sama dengan antarmuka sinkron |
| Versi Vertex AI | Mendukung deployment regional | Untuk skenario kepatuhan perusahaan |
Contoh Format Gemini JSONL
{"key": "req-001", "request": {"contents": [{"parts": [{"text": "Tuliskan 30 kata untuk poin penjualan produk berikut: iPhone 17 Pro 256GB"}]}]}}
{"key": "req-002", "request": {"contents": [{"parts": [{"text": "Tuliskan 30 kata untuk poin penjualan produk berikut: Sony WH-1000XM6"}]}]}}
Contoh Pemanggilan Gemini Batch
from google import genai
client = genai.Client(api_key="AIza-kunci-resmi")
# Unggah file
uploaded = client.files.upload(file="requests.jsonl", config={"mime_type": "jsonl"})
# Buat tugas batch
batch_job = client.batches.create(
model="gemini-2.5-flash",
src=uploaded.name,
config={"display_name": "sku-cn-2026q2"}
)
# Dapatkan hasil
final = client.batches.get(name=batch_job.name)
if final.state.name == "JOB_STATE_SUCCEEDED":
result_file = client.files.download(file=final.dest.file_name)
📌 Tips isi ulang Gemini: Kemampuan batch Gemini hanya terbuka untuk akun berbayar resmi di Google AI Studio atau Vertex AI, dan tidak tersedia dalam kuota gratis. Jika wilayah Anda tidak mendukung kartu kredit internasional, Anda dapat menggunakan saluran isi ulang resmi Gemini di situs ai.daishengji.com untuk membuka kuota berbayar dengan cepat, atau langsung memesan melalui api-sparkle-charge.lovable.app.
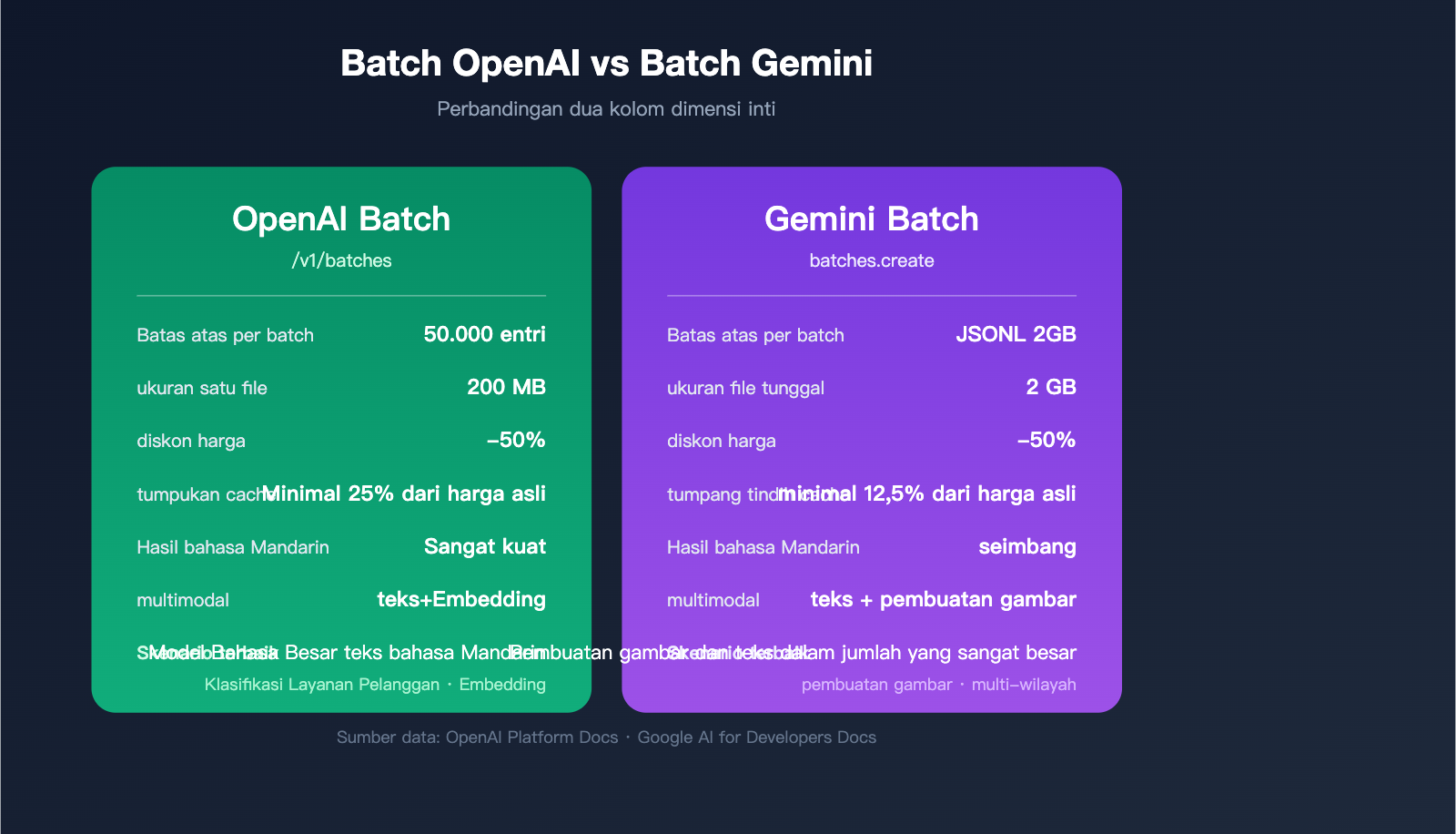
Keputusan Perbandingan API Batch OpenAI dan Gemini
Saat memilih layanan untuk proyek, pengembang sering kali bimbang antara keduanya. Tabel berikut menyajikan perbandingan dimensi utama:
| Perbandingan | OpenAI Batch | Gemini Batch | Skenario Rekomendasi |
|---|---|---|---|
| Batas Permintaan per Batch | 50.000 item | 2GB JSONL (~100rb+) | Pilih Gemini untuk batch super besar |
| Ukuran File Tunggal | 200 MB | 2 GB | Pilih Gemini untuk batch super besar |
| Kualitas Respons (Indo/Mandarin) | Seri gpt-4o/4.1 kuat | gemini-2.5-pro seimbang | Pilih GPT untuk penalaran bahasa |
| Dukungan Multimodal | Teks/Embeddings | Teks/Pembuatan gambar | Pilih Gemini untuk batch gambar |
| Penggunaan Ulang Cache | prompt caching | implicit context caching | Pilih OpenAI untuk prompt sistem sama |
| Kompleksitas Penagihan | Sederhana & jelas | Perlu bedakan tier model | Pilih OpenAI untuk audit keuangan |
| Kematangan Dokumentasi | Paling matang | Terus diperbarui | Pilih OpenAI untuk implementasi cepat |
Saran Pemilihan Berdasarkan Skenario
- Batch SKU E-commerce: gpt-4o-mini Batch, efisiensi biaya terbaik.
- Campuran Gambar & Teks Multimodal: Gemini 2.5 Pro Batch, alur kerja terpadu.
- Pembangunan Embedding Skala Besar: OpenAI text-embedding-3-small Batch.
- Kepatuhan Perusahaan Multi-wilayah: Vertex AI Gemini Batch.
Optimalisasi Mendalam untuk Penggunaan Ulang dan Cache Petunjuk Sistem
Pengguna sering bertanya: "Apakah petunjuk sistem yang sama dalam setiap permintaan batch hanya ditagih sekali?" Ini adalah pertanyaan sering muncul namun sering disalahpahami.
Fakta Penagihan Petunjuk dalam Batch OpenAI
OpenAI /v1/batches sendiri tidak secara otomatis menghapus duplikasi petunjuk sistem yang sama. Namun, dengan menggabungkan mekanisme Prompt Caching, ketika awalan percakapan yang sama dalam batch terdeteksi, input tokens yang di-cache mendapatkan diskon tambahan 50%. Jika digabungkan dengan diskon 50% dari batch, secara teoritis bisa mencapai diskon hingga 75%.
Syarat agar efektif:
- Awalan isi permintaan harus benar-benar identik (termasuk peran, definisi alat, dan teks).
- Panjang awalan ≥ 1024 token (beberapa model 512 token).
- Mencapai ambang batas hit cache dalam jendela waktu 24 jam yang sama.
Cache Konteks Implisit Gemini
Gemini Batch Mode secara bawaan mendukung Implicit Context Caching. Ketika awalan permintaan berulang, sistem secara otomatis membuat cache tanpa perlu mengelola cached_content secara manual. Bagian yang terkena hit cache akan ditagih dengan harga cache Gemini (sekitar 25% dari harga asli), lalu ditambah diskon 50% dari Batch, total biaya bisa turun hingga 12,5%.
Estimasi Biaya Kombinasi Batch + Cache
Asumsikan 100.000 permintaan, masing-masing berbagi 2000 token petunjuk sistem + 500 token input pengguna + 300 token output:
| Skenario | Biaya per Item | Estimasi Total | Penghematan |
|---|---|---|---|
| Panggilan Sinkron (tanpa cache) | $0,0028 | $280 | Basis |
| Sinkron + Prompt Caching | $0,0018 | $180 | -36% |
| Batch (diskon 50%) | $0,0014 | $140 | -50% |
| Batch + Caching | $0,0009 | $90 | -68% |
⚡ Saran Kombinasi Hemat: Jika petunjuk sistem yang sama + model yang sama + tugas malam hari terpenuhi, pastikan menggunakan kombinasi "Batch + Prompt Caching". Untuk mengaktifkan optimasi ini di akun resmi, Anda perlu mengonfirmasi strategi penagihan. Saat memesan melalui layanan pengisian APIYI di api-sparkle-charge.lovable.app, Anda bisa mencantumkan catatan "perlu mengaktifkan diskon batch + cache", dan sistem akan otomatis mengikat tier harga terbaik untuk Anda.
title: "Mengapa Layanan Proksi API Tidak Mendukung Batch Processing: Analisis Teknis"
Mengapa Layanan Proksi API Tidak Mendukung Batch Processing: Analisis Teknis
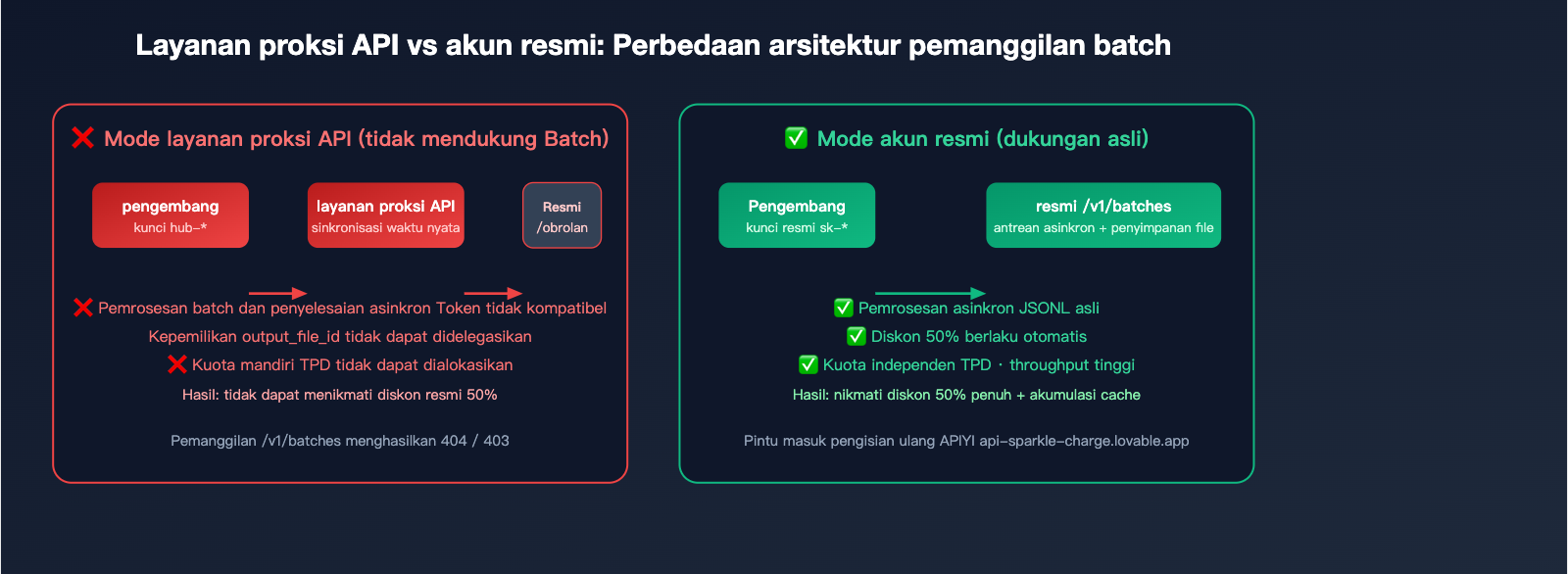
Banyak pengguna yang bertanya-tanya, mengapa platform layanan proksi API biasanya tidak mendukung /v1/batches? Hal ini perlu dijelaskan dari sisi arsitektur teknis:
Penyebab Utama 1: Model Penagihan yang Tidak Kompatibel
Layanan proksi API umumnya menagih berdasarkan pemanggilan model secara real-time (biaya resmi × markup 1.x), sedangkan pemrosesan batch dilakukan penyelesaian pembayaran sekaligus setelah 24 jam. Hal ini memaksa layanan proksi untuk menanggung risiko modal besar dan risiko fluktuasi nilai tukar jika harus menalangi pembayaran di awal.
Penyebab Utama 2: Jalur Pengembalian Token yang Tidak Transparan
output_file_id yang dikembalikan oleh antarmuka batch adalah objek dalam sistem file resmi. Jika layanan proksi ingin menjadi perantara, mereka harus mereplikasi seluruh penyimpanan file dan infrastruktur bandwidth, dan tautan unduhan sangat sulit untuk dialihkan ke pihak ketiga.
Penyebab Utama 3: Kuota Kecepatan (Rate Limit) yang Terpisah
Antarmuka batch memiliki kuota TPD (Tokens Per Day) tersendiri yang terisolasi dari TPM/RPM sinkron. Layanan proksi sulit memprediksi kebutuhan kuota harian setiap pengguna akhir, sehingga sulit untuk melakukan alokasi sekunder yang wajar.
Solusi: Membuka Akun Resmi melalui Layanan Pengisian Saldo
Solusi paling bersih adalah membiarkan pengguna memiliki akun resmi secara langsung:
- Sisi Teknis: Melewati semua batasan layanan proksi, mengakses kemampuan penuh
/v1/batchessecara native. - Sisi Kepatuhan: Tagihan, kepatuhan, dan pengembalian dana diproses melalui saluran resmi.
- Sisi Efisiensi: Tidak perlu melakukan pemisahan sinkron/asinkron lagi dalam skenario batch.
- Sisi Biaya: Layanan pengisian saldo hanya membebankan biaya admin yang wajar, sehingga diskon 50% dari pemrosesan batch tetap dinikmati pengguna sepenuhnya.
Inilah nilai utama dari api-sparkle-charge.lovable.app dan situs pengisian saldo AI ai.daishengji.com: membantu Anda mendapatkan akun dan kunci API resmi secara langsung, sehingga keuntungan penghematan dari pemrosesan batch dapat Anda nikmati seutuhnya.
Praktik: Klasifikasi Batch untuk 100.000 Tanya Jawab Layanan Pelanggan (Contoh Lengkap)
Berikut adalah contoh teknis yang bisa langsung Anda gunakan untuk mengklasifikasikan 100.000 data tanya jawab pelanggan historis berdasarkan niatnya.
Langkah 1: Konstruksi Input JSONL
import json
with open("requests.jsonl", "w") as f:
for idx, q in enumerate(questions): # questions adalah daftar 100.000 pertanyaan
payload = {
"custom_id": f"q-{idx:06d}",
"method": "POST",
"url": "/v1/chat/completions",
"body": {
"model": "gpt-4o-mini",
"messages": [
{"role": "system", "content": "Klasifikasikan pertanyaan pengguna menjadi: billing/tech/sales/other, kembalikan hanya nama kategorinya saja"},
{"role": "user", "content": q}
],
"max_tokens": 8,
"temperature": 0
}
}
f.write(json.dumps(payload, ensure_ascii=False) + "\n")
Langkah 2: Membagi Batas 200MB
# Jika 100.000 baris melebihi 200MB, pecah menjadi beberapa file (misal per 40.000 baris)
# Jika menggunakan Gemini, tidak perlu dipecah karena batasnya hingga 2GB
Langkah 3: Pengiriman dan Pemantauan
batches = []
for path in ["part1.jsonl", "part2.jsonl", "part3.jsonl"]:
fobj = client.files.create(file=open(path, "rb"), purpose="batch")
b = client.batches.create(
input_file_id=fobj.id,
endpoint="/v1/chat/completions",
completion_window="24h"
)
batches.append(b.id)
Langkah 4: Rekapitulasi Hasil
results = {}
for bid in batches:
b = client.batches.retrieve(bid)
if b.status == "completed":
content = client.files.content(b.output_file_id).text
for line in content.splitlines():
item = json.loads(line)
results[item["custom_id"]] = item["response"]["body"]["choices"][0]["message"]["content"]
Estimasi Biaya: 100.000 × ~600 tokens × harga Batch gpt-4o-mini ≈ $6-9, menghemat $6-9 dibandingkan dengan pemanggilan sinkron.
Pertanyaan Umum (FAQ)
Q1: Apakah kunci API layanan proksi API bisa digunakan untuk memanggil /v1/batches?
Tidak bisa. Kunci yang diberikan oleh layanan proksi API (biasanya diawali dengan hub-, sk-proxy-, atau prefiks kustom) hanya mendukung titik akhir sinkron seperti /v1/chat/completions. Antarmuka pemrosesan batch (batch processing) bergantung pada sistem file dan antrean tugas asinkron dari akun resmi, sehingga wajib menggunakan kunci sk-* asli dari penyedia resmi. Jika Anda membutuhkan kunci resmi, Anda bisa memesannya melalui api-sparkle-charge.lovable.app, atau kunjungi AI 代充网 ai.daishengji.com untuk melihat berbagai pilihan paket akun resmi.
Q2: Apakah diskon 50% untuk Gemini Batch berlaku untuk semua model?
Saat ini, Gemini 2.5 Pro, 2.5 Flash, 2.5 Flash-Lite, dan Gemini 3 Pro Image semuanya menikmati diskon 50% untuk pemrosesan batch, di mana token input dan output dipotong setengahnya. Akun tingkat gratis (Free Tier) tidak dapat menggunakan pemrosesan batch; Anda harus menggunakan akun berbayar. Akun berbayar resmi yang diaktifkan melalui layanan pengisian saldo dapat langsung digunakan.
Q3: Apa yang harus dilakukan jika tugas batch gagal? Apakah biayanya akan dikembalikan?
Strategi kedua penyedia sama: Permintaan individu yang gagal tidak akan dikenakan biaya, dan seluruh batch tidak akan dibatalkan. Dalam output_file yang dikembalikan oleh OpenAI, akan terdapat entri kegagalan dengan kolom error, dan error_file_id akan mengumpulkan semua kesalahan; sementara Gemini memberikan detail error saat state=JOB_STATE_FAILED. Anda dapat memproses ulang entri yang gagal secara langsung berdasarkan custom_id.
Q4: Apakah Prompt Caching akan terpicu dalam pemrosesan batch?
Ya. Dokumentasi OpenAI secara eksplisit menyatakan bahwa ketika permintaan batch mengenai Cached Input Tokens, token input yang di-cache tersebut akan mendapatkan diskon 50% tambahan setelah diskon batch 50% (yaitu menjadi 25% dari harga asli). Untuk implementasi praktis, pastikan prefiks permintaan dalam batch konsisten dan memenuhi panjang minimum cache.
Q5: Apakah akun resmi dari layanan pengisian saldo aman? Bisakah saya mengisi ulang saldo sendiri nantinya?
Layanan pengisian saldo resmi (seperti api-sparkle-charge.lovable.app) memberikan akun resmi dengan kepemilikan penuh. Informasi login dan metode pembayaran dapat Anda ubah sendiri, dan Anda dapat melakukan pengisian ulang di kemudian hari menggunakan kartu kredit internasional atau Apple Pay. AI 代充网 ai.daishengji.com menyediakan berbagai paket, mendukung faktur tagihan untuk kebutuhan pelaporan perusahaan dan kepatuhan.
Kesimpulan
API pemrosesan batch adalah pengungkit penghematan biaya yang paling diremehkan dalam implementasi teknik AI tahun 2026: cukup tambahkan satu baris completion_window="24h", dan seluruh biaya operasional akan terpotong setengahnya. Namun, ada syarat mutlak bagi pemanggil—Anda harus menggunakan akun dan kunci resmi, karena platform agregator layanan proksi API tidak dapat memprosesnya karena keterbatasan arsitektur penagihan.
Bagi tim yang memiliki tugas offline berskala besar, jalur paling ekonomis adalah langsung membuka akun resmi dan melakukan optimasi mendalam dengan Prompt Caching. Layanan pengisian saldo API resmi adalah pintu masuk paling praktis bagi pengembang di Indonesia untuk menikmati keuntungan ini: alamat pemesanan api-sparkle-charge.lovable.app, untuk daftar harga lengkap silakan kunjungi AI 代充网 ai.daishengji.com. Pesan dalam 5 menit, saldo masuk dalam 30 menit, dan nikmati diskon batch 50% sekarang juga.
📌 Atribusi Penulis: Artikel ini disusun oleh tim teknis APIYI apiyi.com, konten didasarkan pada dokumentasi resmi OpenAI Platform Docs dan Google AI for Developers, harga dan kuota berlaku sesuai kebijakan resmi per 14-04-2026. Akses pemesanan: api-sparkle-charge.lovable.app / ai.daishengji.com