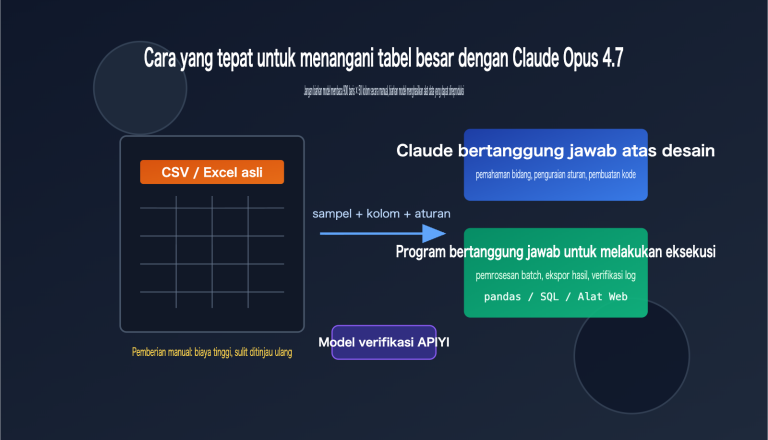
Catatan Penulis: Interpretasi mendalam benchmark Claude Opus 4.7: SWE-bench Verified 87,6%, SWE-bench Pro 64,3%, GPQA Diamond 94,2%, mengungguli GPT-5.4 dan Gemini 3.1 Pro, dilengkapi dengan praktik pemanggilan API.
Anthropic secara resmi merilis Claude Opus 4.7 pada 16 April 2026, yang berhasil memimpin di 7 dari 10 tolok ukur utama. Artikel ini akan mengulas data inti benchmark Claude Opus 4.7 dan skenario penerapannya dari sudut pandang pengujian praktis.
Ini bukan sekadar pengulangan promosi resmi, semua data berasal dari lembaga pengujian independen pihak ketiga, mencakup kelebihan serta kekurangan Opus 4.7 dalam skenario seperti pencarian web.
Nilai Inti: Melalui data benchmark nyata dan pengalaman penggunaan, kami membantu Anda memutuskan apakah Claude Opus 4.7 layak untuk digunakan, serta cara memulainya dengan biaya rendah.
💡 APIYI telah mendukung model resmi Claude Opus 4.7, isi saldo 100 USD dapat bonus mulai dari 10%, secara keseluruhan setara dengan diskon 20%, mendukung penggantian sekali klik untuk antarmuka yang kompatibel dengan OpenAI.

Poin Utama Benchmark Claude Opus 4.7
| Proyek Benchmark | Skor Opus 4.7 | vs Opus 4.6 | vs GPT-5.4 / Gemini 3.1 Pro |
|---|---|---|---|
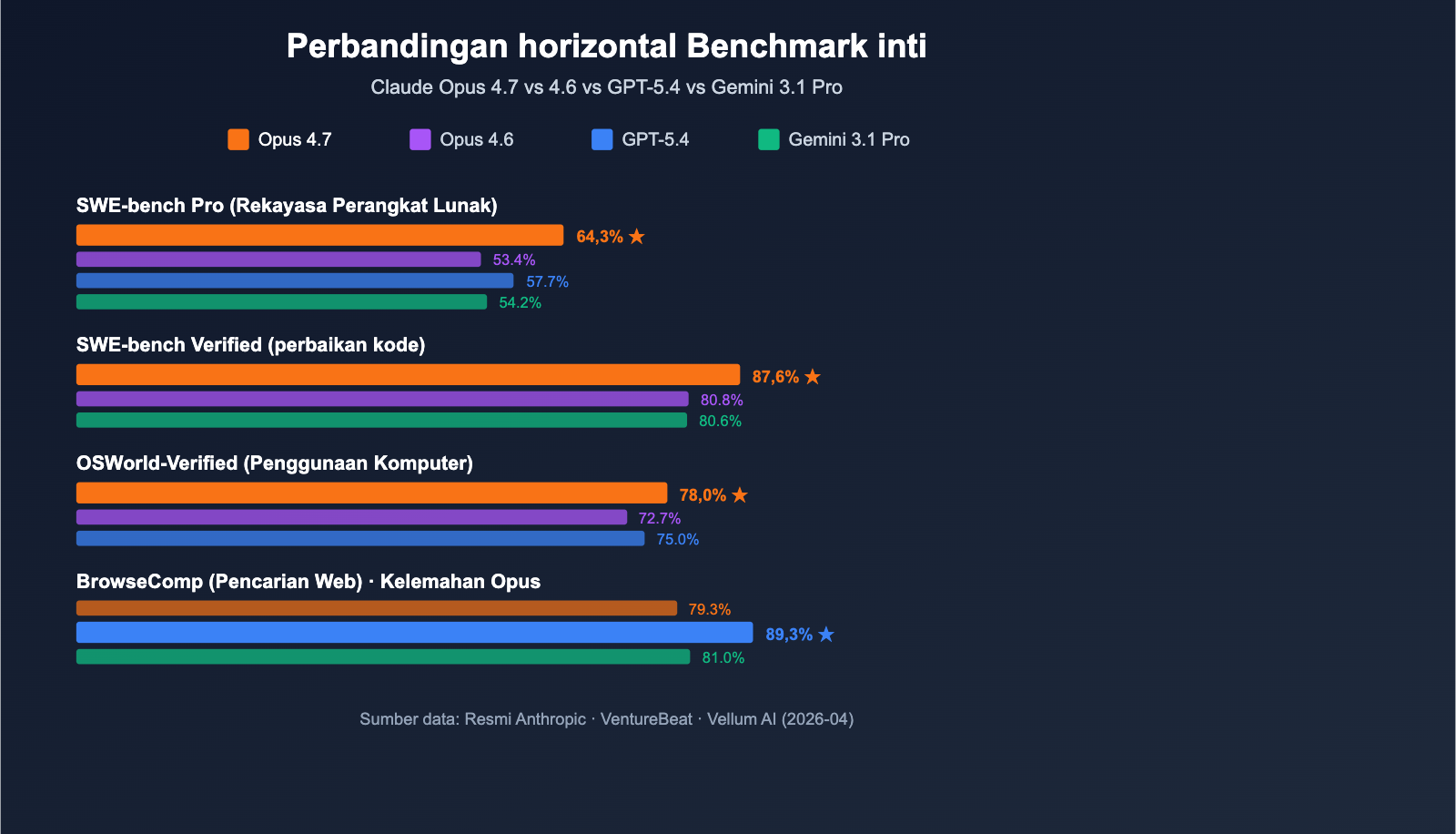
| SWE-bench Verified | 87,6% | 80,8% (+6,8) | Gemini 3.1 Pro: 80,6% ✅ Unggul |
| SWE-bench Pro | 64,3% | 53,4% (+10,9) | GPT-5.4: 57,7% / Gemini: 54,2% ✅ Unggul |
| SWE-bench Multilingual | 80,5% | 77,8% (+2,7) | ✅ Unggul dalam pemrograman multibahasa |
| GPQA Diamond | 94,2% | – | ✅ Tolok ukur penalaran ilmiah |
| Terminal-Bench 2.0 | 69,4% | – | ✅ Unggul dalam operasi terminal |
| OSWorld-Verified (Computer Use) | 78,0% | 72,7% (+5,3) | GPT-5.4: 75,0% ✅ Unggul |
| MCP-Atlas (Pemanggilan Alat) | Unggul GPT-5.4 +9,2 poin | – | ✅ Terbaik untuk skenario Agen |
| Vision Multimodal | 98,5% | – | ✅ Pemahaman visual tingkat atas |
| BrowseComp (Pencarian Web) | 79,3% | – | GPT-5.4: 89,3% ❌ Tertinggal |
Sorotan Utama Benchmark Claude Opus 4.7
Anthropic merilis Claude Opus 4.7 pada 16 April 2026, yang diposisikan sebagai LLM paling kuat yang tersedia secara umum saat ini (menurut penilaian VentureBeat). Dalam 10 perbandingan langsung dengan GPT-5.4 dan Gemini 3.1 Pro, Opus 4.7 memenangkan 7 kategori, dengan keunggulan terbesar pada SWE-bench Pro.
Yang paling patut diperhatikan adalah angka SWE-bench Pro 64,3%—ini adalah skor tertinggi di industri untuk tugas rekayasa perangkat lunak nyata, 6,6 poin lebih tinggi dari GPT-5.4 (57,7%) dan melonjak 10,9 poin dari Opus 4.6 (53,4%). Pada benchmark pemanggilan alat MCP-Atlas, Opus 4.7 mengungguli GPT-5.4 sebesar 9,2 poin, yang berarti model ini lebih cocok untuk skenario AI Agen, seperti alur kerja otomatis, Agen pembuat kode, dan tugas penalaran multi-langkah.
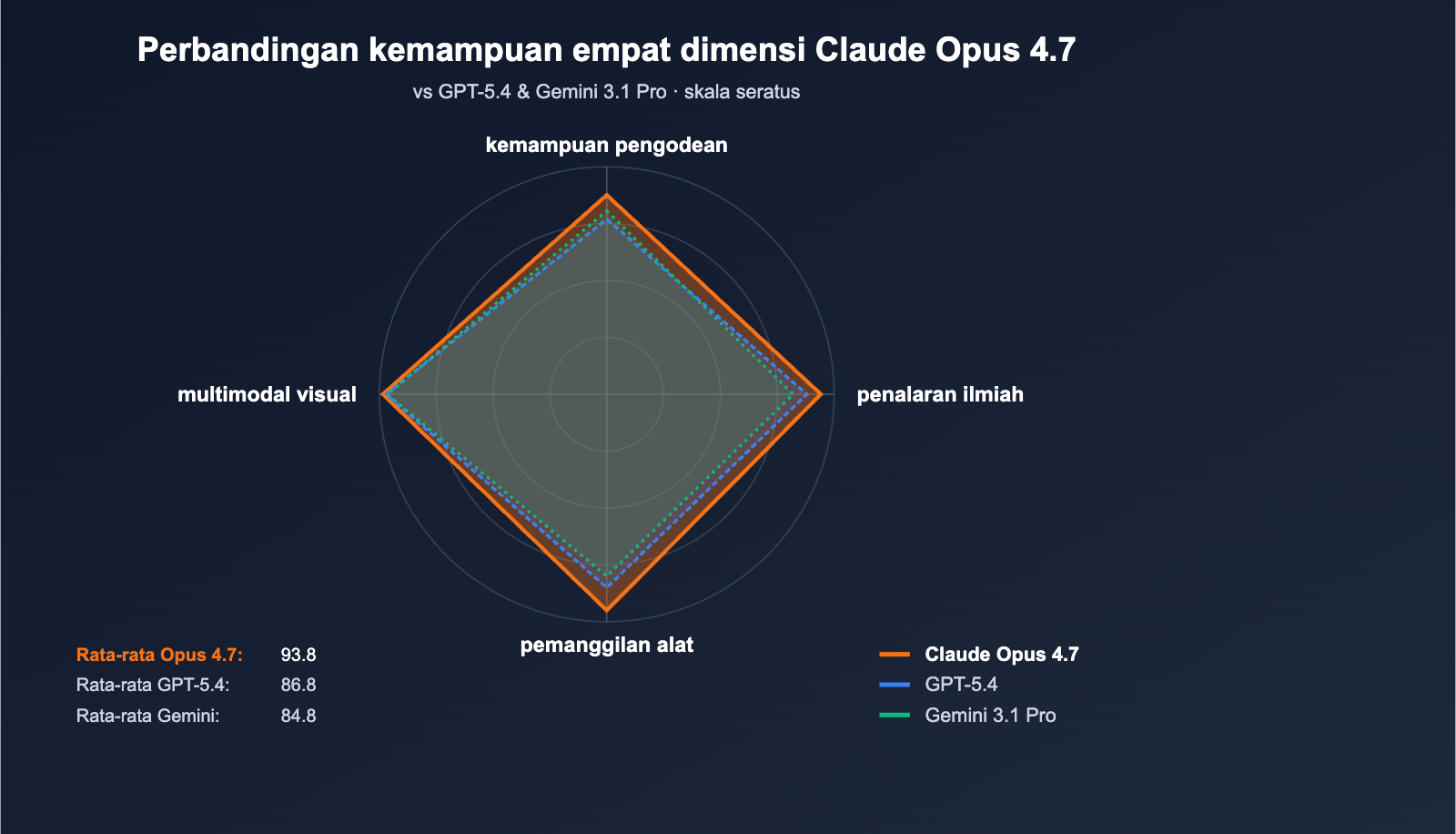
Perbandingan Claude Opus 4.7 dengan Generasi Sebelumnya dan Model Pesaing
| Dimensi | Claude Opus 4.7 | Claude Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| Tanggal Rilis | 2026-04-16 | 2026-01 | 2026-03 | 2026-02 |
| Jendela Konteks | 1M token (harga standar) | 200K | 400K | 1M |
| SWE-bench Pro | 64.3% | 53.4% | 57.7% | 54.2% |
| Agent/Pemanggilan Alat | Terkuat | Baik | Kuat | Baik |
| Pencarian Web (BrowseComp) | 79.3% | 72% | 89.3% | 81% |
| Multimodal Vision | 98.5% | 95% | 97% | 96.5% |
| Harga API Resmi | $5 / $25 (input/output, per juta token) | $5 / $25 | $4.5 / $22 | $4 / $20 |
| Diskon Komprehensif APIYI | Isi saldo $100 bonus 10% ≈ diskon 20% | Diskon serupa | Diskon serupa | Diskon serupa |
Analisis Perbandingan (Claude Opus 4.7 vs Model Lain)
Claude Opus 4.7 vs GPT-5.4: GPT-5.4 masih memimpin dalam skenario pencarian web via BrowseComp (89.3% vs 79.3%). Namun, performanya dalam SWE-bench Pro (57.7%) dan pemanggilan alat (MCP-Atlas) tertinggal jauh dari Opus 4.7. Sebaliknya, Claude Opus 4.7 lebih unggul dalam agen pemrograman, pembuatan kode, dan eksekusi tugas multi-langkah, menjadikannya pilihan tepat untuk alur kerja pengembang.
Claude Opus 4.7 vs Gemini 3.1 Pro: Gemini 3.1 Pro tetap unggul dalam pemahaman teks panjang dan skenario video multimodal. Namun, terdapat kesenjangan performa yang nyata pada SWE-bench Verified (80.6% vs 87.6%) dan SWE-bench Pro (54.2% vs 64.3%). Claude Opus 4.7 memimpin secara signifikan dalam tugas rekayasa perangkat lunak, sehingga lebih cocok untuk skenario pemrograman tingkat produksi.
Claude Opus 4.7 vs Opus 4.6: Opus 4.6 tetap menjadi pilihan stabil untuk skenario yang sensitif terhadap biaya. Namun, kemampuan pemrograman, penalaran agen, dan Computer Use pada versi 4.7 telah meningkat pesat, sementara harga API tetap sama. Bagi tim yang menangani tugas kompleks dengan rantai panjang, peningkatan ke 4.7 adalah langkah yang sangat disarankan.
Catatan Perbandingan: Data di atas bersumber dari rilis resmi Anthropic, VentureBeat, Vellum AI, Decrypt, dan lembaga evaluasi pihak ketiga lainnya. Anda dapat melakukan pengujian langsung melalui platform APIYI di apiyi.com.
Panduan Cepat Claude Opus 4.7
Contoh Minimalis
Berikut adalah cara paling sederhana untuk melakukan pemanggilan model Claude Opus 4.7 melalui APIYI, menggunakan antarmuka yang kompatibel dengan OpenAI:
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Tulis fungsi traversal in-order pohon biner menggunakan Python"}]
)
print(response.choices[0].message.content)
Lihat kode implementasi lengkap (termasuk pemanggilan mode xhigh Effort)
import openai
from typing import Optional
def call_claude_opus_47(
prompt: str,
effort_level: str = "high",
system_prompt: Optional[str] = None,
max_tokens: int = 4096
) -> str:
"""
Memanggil Claude Opus 4.7, mendukung mode xhigh effort
Args:
prompt: Input pengguna
effort_level: Tingkat upaya penalaran, pilihan "low" / "medium" / "high" / "xhigh"
system_prompt: Petunjuk sistem
max_tokens: Jumlah token output maksimum
Returns:
Konten respons model
"""
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
try:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=messages,
max_tokens=max_tokens,
extra_body={
"reasoning_effort": effort_level
}
)
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# Mode xhigh direkomendasikan untuk tugas pemrograman yang kompleks
result = call_claude_opus_47(
prompt="Rancang dan implementasikan cache LRU, dukung operasi get dan put O(1)",
effort_level="xhigh",
system_prompt="Anda adalah insinyur Python senior, tulis kode yang memiliki keterbacaan dan performa yang baik"
)
print(result)
Saran: Dapatkan kuota uji coba gratis melalui APIYI di apiyi.com untuk memverifikasi efektivitas Claude Opus 4.7 dalam skenario Anda dengan cepat. Platform ini mendukung antarmuka yang kompatibel dengan OpenAI untuk Opus 4.7, GPT-5.4, dan Gemini 3.1 Pro, sehingga memudahkan perbandingan secara horizontal. Ada promo isi ulang mulai dari $100 bonus 10%, secara keseluruhan setara dengan diskon 20% untuk penggunaan model resmi.
Performa Claude Opus 4.7 dan Skenario Tipikal
4 Skenario Utama yang Cocok untuk Claude Opus 4.7
- 🧑💻 Refaktorisasi Kode Skala Besar: SWE-bench Verified 87,6% membuktikan kemampuannya memahami konteks lintas file, cocok untuk penyesuaian arsitektur, peningkatan dependensi, dan refaktorisasi massal pada basis kode dengan 100.000 baris.
- 🤖 Alur Kerja Otomasi Agen: Pemanggilan alat MCP-Atlas unggul 9,2 poin dibandingkan GPT-5.4, cocok untuk membangun otomatisasi browser, RPA, dan agen penalaran multi-langkah.
- 🔬 Bantuan Penelitian dan Penalaran: GPQA Diamond 94,2% berarti kemampuan penalaran disiplin ilmu setingkat pascasarjana, cocok untuk bantuan penulisan makalah, analisis data, dan verifikasi hipotesis.
- 🖥️ Otomasi Desktop Computer Use: OSWorld-Verified 78,0% memimpin industri, cocok untuk pengujian otomatisasi dan operasi UI yang memerlukan simulasi mouse dan keyboard.
Skenario yang Tidak Cocok untuk Claude Opus 4.7
- Pencarian Web Real-time: BrowseComp 79,3%, tertinggal jauh dari GPT-5.4 dengan 89,3%. Untuk skenario ini, disarankan beralih ke GPT-5.4.
- Pemanggilan Skala Besar dengan Biaya Rendah: Harga output $25/M token. Untuk aplikasi percakapan sehari-hari, disarankan menggunakan Claude Haiku atau GPT-5.4-mini.
- Persyaratan Latensi Sangat Rendah: Latensi respons seri Opus lebih tinggi daripada Sonnet/Haiku, gunakan dengan hati-hati untuk skenario interaksi real-time.
Estimasi Harga dan Biaya Claude Opus 4.7
Harga Resmi vs Biaya Komprehensif APIYI
| Item | Harga Resmi (Anthropic) | Harga APIYI (Termasuk Bonus Isi Ulang) |
|---|---|---|
| Token input | $5 / juta token | Harga satuan sama dengan resmi |
| Token output | $25 / juta token | Harga satuan sama dengan resmi |
| Bonus isi ulang | Tidak ada | Mulai dari 10% untuk isi ulang $100 |
| Diskon setara | Tidak ada | Sekitar 20% (semakin besar isi ulang, semakin besar bonusnya) |
| Metode pembayaran | Hanya kartu kredit USD | Mendukung RMB, USD, dan berbagai metode lainnya |
| Mata uang tagihan | USD | Bisa pilih RMB / USD |
Catatan Biaya: Tokenizer baru pada Opus 4.7 akan mengonsumsi sekitar 1x-1,35x lebih banyak token dibandingkan versi 4.6 saat memproses teks (bervariasi tergantung jenis konten). Meskipun harga satuan resmi tidak naik, biaya tagihan aktual mungkin meningkat sekitar 20-30%. Dengan memanfaatkan promo bonus isi ulang dari APIYI apiyi.com, Anda dapat mengimbangi biaya tersembunyi ini, sehingga biaya penggunaan aktual tetap setara atau bahkan lebih rendah dibandingkan era 4.6.
Pertanyaan Umum (FAQ)
Q1: Apa itu Claude Opus 4.7?
Claude Opus 4.7 adalah Model Bahasa Besar unggulan yang dirilis oleh Anthropic pada 16 April 2026. Model ini memimpin di berbagai tolok ukur seperti pengodean (SWE-bench Verified 87,6%), pemanggilan alat Agen, dan penalaran ilmiah (GPQA Diamond 94,2%), melampaui GPT-5.4 dan Gemini 3.1 Pro. Dibandingkan dengan Opus 4.6, model ini menambahkan mode penalaran mendalam "xhigh effort" dengan harga resmi yang tetap.
Q2: Mana yang lebih baik, Claude Opus 4.7 atau GPT-5.4?
Tergantung pada skenario penggunaan. Dalam hal pemrograman (SWE-bench Pro 64,3% vs 57,7%), pemanggilan alat (MCP-Atlas +9,2 poin), dan Computer Use (78,0% vs 75,0%), Opus 4.7 jelas lebih unggul. Namun, untuk pencarian web (BrowseComp 79,3% vs 89,3%), GPT-5.4 tetap memegang keunggulan. Untuk alur kerja pengembangan, pilih Opus 4.7, sedangkan untuk pencarian daring, pilih GPT-5.4.
Q3: Kapan Claude Opus 4.7 dirilis? Kapan bisa digunakan di dalam negeri?
Tanggal rilis resmi adalah 16 April 2026, dan sudah tersedia di Claude API, Amazon Bedrock, Google Cloud Vertex AI, serta Microsoft Foundry. Pengembang di dalam negeri dapat menggunakan model resmi ini secara sinkron melalui platform agregasi seperti APIYI apiyi.com tanpa perlu mengajukan akun luar negeri.
Q4: Proyek apa yang paling cocok untuk Claude Opus 4.7?
Sangat cocok untuk skenario berikut:
- Refaktorisasi kode skala besar: Pemahaman konteks lintas file, migrasi dependensi, dan penyesuaian arsitektur
- Otomatisasi Agen: Rantai alat MCP, otomatisasi browser, dan alur kerja RPA
- Penelitian dan analisis data: Penalaran tingkat pascasarjana, verifikasi hipotesis, dan bantuan penulisan makalah
- Otomatisasi desktop Computer Use: Pengujian otomatisasi UI dan skrip operasi GUI
Q5: Bagaimana cara memanggil Claude Opus 4.7 melalui API dengan cepat?
Disarankan untuk menggunakan platform agregasi yang mendukung protokol yang kompatibel dengan OpenAI. Anda bisa mulai dalam 3 langkah:
- Kunjungi APIYI apiyi.com untuk mendaftar akun dan mendapatkan kunci API
- Lakukan isi ulang $100 untuk mendapatkan bonus mulai dari 10% (diskon sekitar 20%), atau gunakan kuota gratis untuk pengujian terlebih dahulu
- Ubah
base_urlpada SDK OpenAI menjadihttps://vip.apiyi.com/v1, dan isi model denganclaude-opus-4-7
APIYI mendukung akses terpadu ke model utama seperti Claude Opus 4.7, GPT-5.4, dan Gemini 3.1 Pro, sehingga memudahkan perbandingan dan peralihan model.
Q6: Apa saja batasan yang diketahui dari Claude Opus 4.7?
Batasan utama meliputi:
- Peningkatan konsumsi token: Tokenizer baru menggunakan 1x-1,35x lebih banyak token dibanding 4.6, tagihan aktual bisa naik 20-30%
- Kelemahan pencarian web: Skor BrowseComp 79,3%, tertinggal dari GPT-5.4, harap berhati-hati untuk skenario daring waktu nyata
- Latensi respons: Seri Opus memiliki latensi lebih tinggi daripada Sonnet/Haiku, untuk aplikasi percakapan waktu nyata disarankan menggunakan model yang lebih ringan
- Harga satuan resmi yang tinggi: $5/$25 per juta token, untuk pemanggilan skala besar disarankan menggunakan promo isi ulang APIYI untuk mengimbangi biaya
Q7: Berapa jendela konteks Claude Opus 4.7?
Claude Opus 4.7 mendukung jendela konteks 1 juta (1M) token dengan harga standar tanpa biaya tambahan untuk konteks panjang. Ini berarti Anda dapat memproses seluruh repositori kode berukuran sedang, dokumen teknis panjang, atau catatan rapat lengkap dalam satu permintaan, setara dengan sekitar 750.000 karakter Mandarin atau 200 halaman PDF.
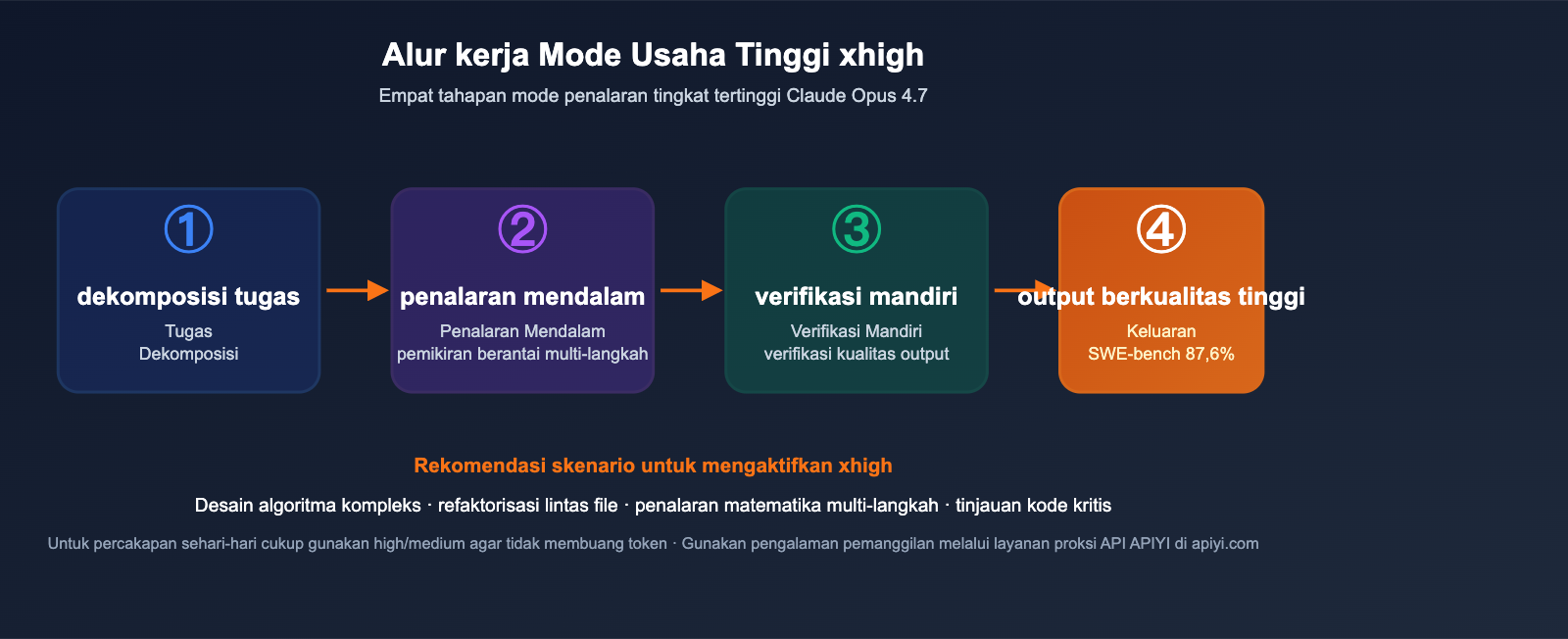
Q8: Apa itu Mode xhigh Effort? Kapan harus digunakan?
"xhigh effort" adalah mode penalaran tingkat tertinggi yang baru ditambahkan pada Opus 4.7. Model akan menghabiskan lebih banyak token dan waktu untuk berpikir langkah demi langkah serta melakukan verifikasi mandiri. Disarankan untuk mengaktifkannya dalam skenario berikut:
- Desain algoritma kompleks (seperti cache LRU, konsistensi terdistribusi)
- Tugas refaktorisasi lintas file
- Penalaran matematika yang memerlukan rantai logika multi-langkah
- Peninjauan kode kritis dan pemeriksaan kerentanan
Untuk percakapan sehari-hari atau penulisan CRUD sederhana, gunakan mode high atau medium saja untuk menghindari penggunaan token yang tidak perlu.
Poin-Poin Utama Claude Opus 4.7
- 🏆 Unggul di 7 Peringkat Utama: SWE-bench Pro 64,3%, Verified 87,6%, GPQA 94,2%, serta MCP-Atlas yang unggul 9,2 poin di atas GPT-5.4.
- 💡 Mode Usaha Ekstra (xhigh Effort): Menambahkan mode penalaran tingkat tertinggi, cocok untuk algoritma kompleks dan pemfaktoran ulang lintas file.
- 🚀 Ideal untuk Skenario Agen: Pemanggilan alat dan Computer Use yang sepenuhnya unggul, menjadikannya model pilihan utama untuk AI Agen.
- ⚠️ Kekurangan dalam Penelusuran Web: BrowseComp tertinggal 10 poin di belakang GPT-5.4, disarankan untuk melakukan perbandingan jika skenarionya melibatkan pencarian daring.
- 💰 Mulai dengan Diskon 20% melalui APIYI: Harga resmi tidak naik, namun dengan isi saldo 100 USD melalui apiyi.com, Anda mendapatkan bonus mulai dari 10%, yang berarti setara dengan diskon sekitar 20%.
Ringkasan
Data benchmark Claude Opus 4.7 dengan jelas menunjukkan satu kesimpulan—ini adalah model umum terkuat untuk skenario pemrograman dan Agen saat ini. Poin-poin kuncinya:
- Keunggulan Mutlak dalam Pemrograman: SWE-bench Pro 64,3% jauh melampaui GPT-5.4 dan Gemini 3.1 Pro, menjadikannya pilihan utama untuk tugas kode tingkat produksi.
- Raja Pemanggilan Alat Agen: Unggul 9,2 poin di MCP-Atlas dan 3 poin di Computer Use, menjadikannya opsi terbaik untuk skenario otomatisasi.
- Perlu Memperhatikan Biaya Aktual: Tokenizer baru membawa kenaikan biaya implisit sebesar 20-30%, sehingga perlu diseimbangkan dengan promosi isi saldo dari platform agregator.
Jika fokus pekerjaan Anda adalah pemrograman AI, pengembangan Agen, atau tugas penalaran kompleks, Claude Opus 4.7 layak untuk segera digunakan. Kami merekomendasikan untuk mencobanya dengan cepat melalui APIYI di apiyi.com—model resmi langsung tersedia, antarmuka kompatibel dengan OpenAI dapat diganti dengan sekali klik, dan isi saldo 100 USD mendapatkan bonus mulai dari 10% yang setara dengan diskon 20%, sehingga Anda terbebas dari kerumitan akun luar negeri dan pembayaran dalam USD.
Bacaan Lanjutan
Jika Anda tertarik dengan tolok ukur Claude Opus 4.7, kami merekomendasikan bacaan berikut:
- 📘 Panduan Lengkap Pemanggilan API Claude Opus 4.7 – Pelajari penggunaan lengkap xhigh Effort Mode, Prompt Caching, dan pemanggilan alat.
- 📊 Perbandingan Mendalam: GPT-5.4 vs Claude Opus 4.7 vs Gemini 3.1 Pro – Pahami keputusan pemilihan tiga model unggulan untuk berbagai skenario spesifik.
- 🚀 Protokol MCP dan Praktik Agen Claude Opus 4.7 – Jelajahi cara membangun alur kerja Agen tingkat produksi menggunakan Opus 4.7.
📚 Referensi
-
Pengumuman Resmi Anthropic: Pengenalan produk dan data tolok ukur Claude Opus 4.7
- Tautan:
anthropic.com/news/claude-opus-4-7 - Keterangan: Sumber data langsung, mencakup seluruh hasil uji tolok ukur resmi.
- Tautan:
-
Ulasan Independen VentureBeat: Analisis Opus 4.7 yang kembali menempati peringkat pertama di antara LLM umum
- Tautan:
venturebeat.com/technology/anthropic-releases-claude-opus-4-7-narrowly-retaking-lead-for-most-powerful-generally-available-llm - Keterangan: Perspektif pihak ketiga yang independen mengenai perbandingan komprehensif Opus 4.7 vs kompetitor.
- Tautan:
-
Interpretasi Tolok Ukur Vellum AI: Membedah metodologi dan kredibilitas tolok ukur poin demi poin
- Tautan:
vellum.ai/blog/claude-opus-4-7-benchmarks-explained - Keterangan: Cocok bagi pembaca teknis yang ingin memahami metode pengujian secara mendalam.
- Tautan:
-
Dokumentasi API Resmi Claude: Penjelasan jendela konteks, harga, dan tokenizer
- Tautan:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - Keterangan: Referensi otoritatif untuk integrasi dan pemanggilan, termasuk panduan migrasi.
- Tautan:
Penulis: Tim Teknis APIYI
Diskusi Teknis: Silakan berdiskusi di kolom komentar mengenai pengalaman penggunaan Claude Opus 4.7. Untuk materi pemanggilan API lainnya, kunjungi pusat dokumentasi APIYI di docs.apiyi.com.