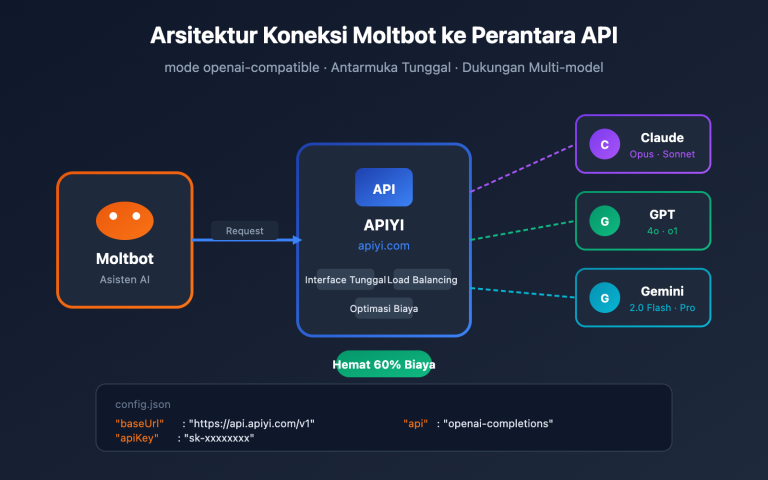
Pernahkah Anda merasa kesal karena proyek Anda menggunakan GPT dari OpenAI, Claude dari Anthropic, dan Gemini dari Google secara bersamaan, namun setiap model memiliki SDK yang berbeda, format API yang berbeda, bahkan cara penanganan error yang berbeda? Setiap kali ingin mengganti model, Anda harus mengubah banyak bagian kode?
Inilah masalah yang diselesaikan oleh LiteLLM. Singkatnya, LiteLLM adalah "penerjemah universal" untuk Model Bahasa Besar AI—Anda hanya perlu mempelajari satu cara pemanggilan (format OpenAI), dan ia akan menerjemahkannya ke format API dari lebih dari 100 penyedia model lainnya.
Nilai Inti: Setelah membaca artikel ini, Anda akan memahami apa itu LiteLLM, mengapa kerangka kerja AI Agent menggunakannya, dan cara menggunakannya dalam waktu 5 menit.
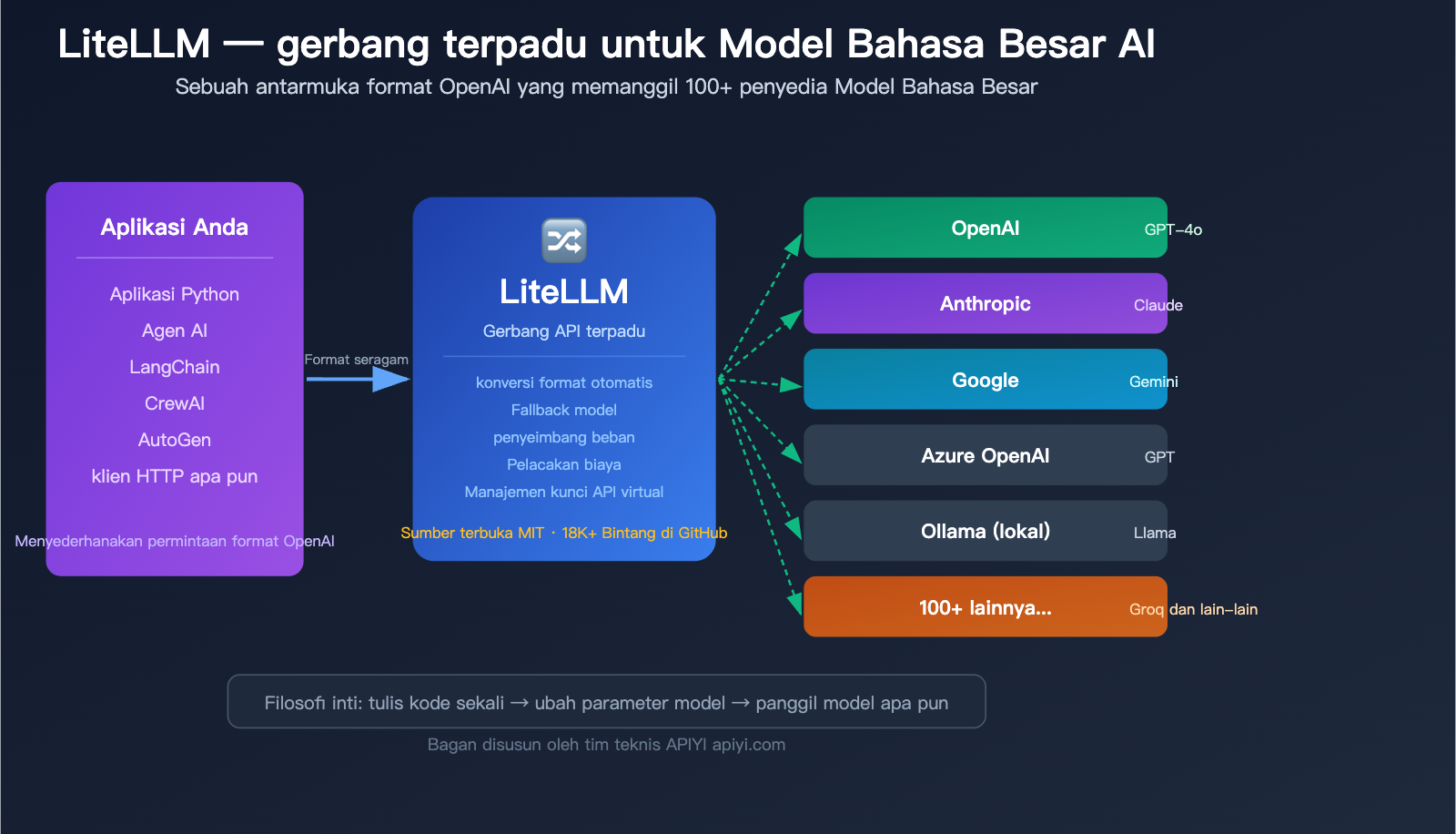
Apa itu LiteLLM: 5 Konsep Inti
Sebelum mulai menggunakannya, mari pahami 5 konsep inti LiteLLM dengan cara yang paling sederhana. Jika konsep ini sudah jelas, langkah selanjutnya akan terasa mudah.
| Konsep Inti | Penjelasan Sederhana | Masalah yang Diselesaikan |
|---|---|---|
| Antarmuka Terpadu | Semua model dipanggil dengan cara yang sama | Tidak perlu mempelajari SDK untuk setiap model |
| Provider (Penyedia) | Vendor model seperti OpenAI, Anthropic, dll. | Mengelola cara koneksi ke vendor yang berbeda |
| Fallback (Failover) | Jika model A gagal, otomatis beralih ke model B | Menjamin layanan tidak terputus |
| Virtual Key (Kunci Virtual) | Memberikan "sub-akun" kepada anggota tim | Mengontrol penggunaan dan anggaran |
| Proxy (Gateway) | Server proksi API yang berjalan secara mandiri | Dapat diakses oleh bahasa pemrograman atau alat apa pun |
Masalah apa yang diselesaikan LiteLLM?
Bayangkan dunia tanpa LiteLLM:
Memanggil OpenAI:
from openai import OpenAI
client = OpenAI(api_key="sk-xxx")
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Halo"}]
)
Memanggil Anthropic:
import anthropic
client = anthropic.Anthropic(api_key="sk-ant-xxx")
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024, # Anthropic wajib menentukan ini
messages=[{"role": "user", "content": "Halo"}]
)
Memanggil Google Gemini:
import google.generativeai as genai
genai.configure(api_key="AIza-xxx")
model = genai.GenerativeModel("gemini-2.0-flash")
response = model.generate_content("Halo")
Lihat? Tiga model, tiga SDK, tiga cara penulisan. Jika proyek Anda perlu mendukung pergantian model, kode Anda akan dipenuhi dengan pernyataan kondisional seperti if provider == "openai"... elif provider == "anthropic"....
Setelah menggunakan LiteLLM:
import litellm
# Memanggil OpenAI
response = litellm.completion(model="gpt-4o", messages=[{"role": "user", "content": "Halo"}])
# Memanggil Anthropic — dengan cara yang sama
response = litellm.completion(model="anthropic/claude-sonnet-4-6", messages=[{"role": "user", "content": "Halo"}])
# Memanggil Gemini — tetap dengan cara yang sama
response = litellm.completion(model="gemini/gemini-2.0-flash", messages=[{"role": "user", "content": "Halo"}])
Cukup satu litellm.completion(), Anda hanya perlu mengganti parameter model. LiteLLM secara otomatis menangani konversi format, adaptasi parameter, dan standarisasi respons di latar belakang.
🎯 Saran Teknis: Konsep antarmuka terpadu LiteLLM mirip dengan APIYI (apiyi.com)—keduanya merupakan antarmuka untuk memanggil berbagai model. Perbedaannya adalah LiteLLM adalah solusi self-hosted (bisa di-deploy sendiri) yang bersifat open-source, sedangkan APIYI adalah layanan terkelola yang tidak perlu di-deploy. Anda bisa memilih solusi yang sesuai berdasarkan kemampuan teknis tim Anda.
Penjelasan Mendalam Dua Mode Penggunaan LiteLLM
LiteLLM menyediakan dua mode penggunaan yang disesuaikan untuk berbagai skenario. Memahami perbedaan antara kedua mode ini adalah kunci untuk memilih cara penggunaan yang tepat.
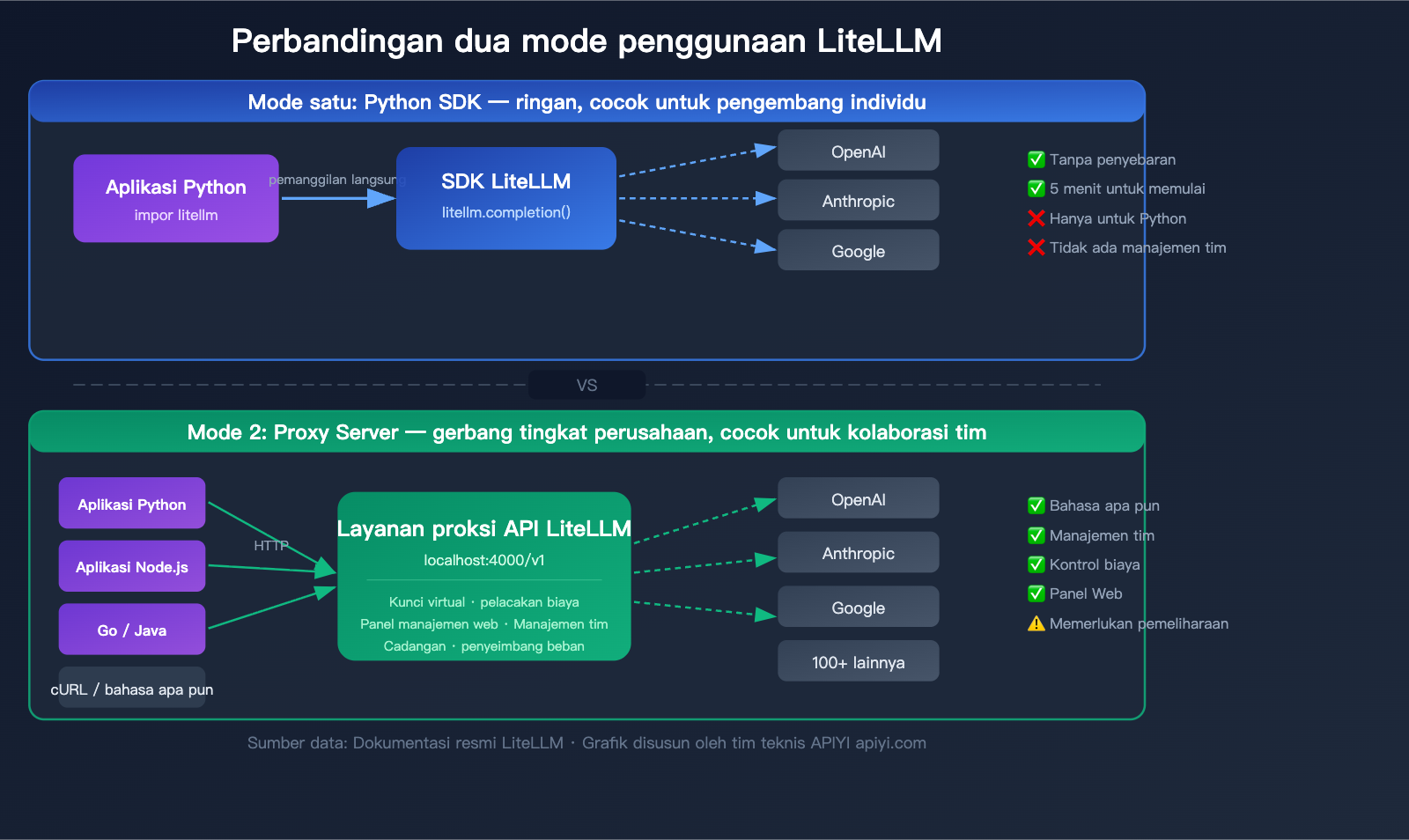
Mode 1: Python SDK (Ringan)
Impor paket litellm langsung di dalam kode Python Anda dan gunakan seperti memanggil fungsi biasa.
Skenario Penggunaan:
- Pengembang individu
- Proyek berbasis Python murni
- Validasi prototipe cepat
- Tidak memerlukan fitur manajemen tim
Instalasi:
pip install litellm
Penggunaan Dasar:
import litellm
import os
# Mengatur kunci API (melalui variabel lingkungan)
os.environ["OPENAI_API_KEY"] = "sk-kunci-anda"
os.environ["ANTHROPIC_API_KEY"] = "sk-ant-kunci-anda"
# Memanggil model apa pun
response = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "Jelaskan apa itu API gateway"}]
)
print(response.choices[0].message.content)
Mode 2: Proxy Server (Gateway Kelas Perusahaan)
Berjalan sebagai server independen yang mengekspos antarmuka HTTP yang kompatibel dengan OpenAI. Dapat digunakan oleh bahasa pemrograman atau alat apa pun yang bisa mengirim permintaan HTTP.
Skenario Penggunaan:
- Kolaborasi tim
- Proyek multi-bahasa (Java, Go, Node.js, dll.)
- Memerlukan pelacakan biaya dan manajemen anggaran
- Perlu menetapkan kunci virtual untuk tim yang berbeda
- Integrasi dengan kerangka kerja AI Agent
Instalasi dan Menjalankan:
# Instalasi
pip install 'litellm[proxy]'
# Jalankan dengan file konfigurasi
litellm --config config.yaml --port 4000
# Atau menggunakan Docker
docker run -p 4000:4000 \
-e OPENAI_API_KEY=sk-xxx \
ghcr.io/berriai/litellm:main-latest
Setelah berjalan, aplikasi apa pun dapat memanggilnya seperti memanggil OpenAI:
from openai import OpenAI
# Arahkan base_url ke LiteLLM Proxy
client = OpenAI(
api_key="sk-kunci-virtual-anda",
base_url="http://localhost:4000/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Halo"}]
)
Perbandingan SDK LiteLLM vs Mode Proxy
| Dimensi Perbandingan | Python SDK | Proxy Server |
|---|---|---|
| Cara Instalasi | pip install litellm |
pip install 'litellm[proxy]' atau Docker |
| Cara Pemanggilan | Pemanggilan fungsi Python | HTTP API (bahasa apa pun) |
| Cara Konfigurasi | Diatur dalam kode | File konfigurasi config.yaml |
| Manajemen Kunci Virtual | Tidak didukung | Didukung, bisa mengatur batas anggaran |
| Panel Manajemen Web | Tidak ada | Ada, manajemen visual |
| Manajemen Tim | Tidak didukung | Mendukung pengguna/tim/anggaran |
| Pelacakan Biaya | Dasar (tingkat kode) | Lengkap (persistensi basis data) |
| Kompleksitas Deployment | Tanpa deployment | Perlu pemeliharaan server |
| Target Pengguna | Pengembang individu | Tim/Perusahaan |
💡 Saran Pemilihan: Jika Anda adalah pengembang individu yang melakukan validasi prototipe, mode SDK dapat dijalankan dalam 5 menit. Jika digunakan oleh tim atau di lingkungan produksi, mode Proxy lebih cocok. Tentu saja, jika Anda tidak ingin mengelola dan memelihara server sendiri, Anda juga bisa langsung menggunakan layanan antarmuka terpadu terkelola seperti APIYI (apiyi.com) yang siap pakai.
Panduan Cepat LiteLLM
Berikut adalah langkah-langkah lengkap untuk mulai menggunakan LiteLLM dari nol.
Memulai dengan Mode SDK LiteLLM
Langkah 1: Instalasi
pip install litellm
Langkah 2: Mengatur variabel lingkungan
# macOS / Linux
export OPENAI_API_KEY="sk-kunci-anda"
export ANTHROPIC_API_KEY="sk-ant-kunci-anda"
# Windows
set OPENAI_API_KEY=sk-kunci-anda
Langkah 3: Menulis kode
import litellm
# Pemanggilan dasar
response = litellm.completion(
model="gpt-4o",
messages=[
{"role": "system", "content": "Anda adalah asisten teknis"},
{"role": "user", "content": "Apa itu gateway LLM?"}
],
temperature=0.7
)
print(response.choices[0].message.content)
print(f"Penggunaan Token: {response.usage.total_tokens}")
print(f"Estimasi biaya: ${response._hidden_params.get('response_cost', 'N/A')}")
Lihat kode lengkap: Dengan Fallback dan output streaming
import litellm
import os
os.environ["OPENAI_API_KEY"] = "sk-kunci-anda"
os.environ["ANTHROPIC_API_KEY"] = "sk-ant-kunci-anda"
# Pemanggilan dengan Fallback: Jika GPT-4o gagal, otomatis pindah ke Claude
response = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "Jelaskan RESTful API"}],
fallbacks=["anthropic/claude-sonnet-4-6"],
num_retries=2
)
# Output streaming
stream = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "Tulis puisi tentang pemrograman"}],
stream=True
)
for chunk in stream:
content = chunk.choices[0].delta.content
if content:
print(content, end="", flush=True)
Memulai dengan Mode Proxy LiteLLM
Langkah 1: Buat file konfigurasi config.yaml
model_list:
- model_name: gpt-4o
litellm_params:
model: openai/gpt-4o
api_key: os.environ/OPENAI_API_KEY
- model_name: claude-sonnet
litellm_params:
model: anthropic/claude-sonnet-4-6
api_key: os.environ/ANTHROPIC_API_KEY
- model_name: gemini-flash
litellm_params:
model: gemini/gemini-2.0-flash
api_key: os.environ/GEMINI_API_KEY
litellm_settings:
drop_params: true
num_retries: 3
general_settings:
master_key: sk-my-master-key
Langkah 2: Jalankan Proxy
litellm --config config.yaml --port 4000
Langkah 3: Gunakan pemanggilan SDK OpenAI standar
from openai import OpenAI
client = OpenAI(
api_key="sk-my-master-key",
base_url="http://localhost:4000/v1"
)
# Memanggil GPT-4o (melalui LiteLLM Proxy)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Halo"}]
)
print(response.choices[0].message.content)
Anda juga bisa menggunakan cURL untuk pemanggilan langsung:
curl http://localhost:4000/v1/chat/completions \
-H "Authorization: Bearer sk-my-master-key" \
-H "Content-Type: application/json" \
-d '{
"model": "claude-sonnet",
"messages": [{"role": "user", "content": "Halo"}]
}'
🚀 Mulai Cepat: LiteLLM Proxy mengharuskan Anda mengelola server dan kunci API sendiri. Jika Anda ingin menggunakan antarmuka terpadu tanpa perlu deployment, cobalah APIYI (apiyi.com). APIYI mendukung format yang kompatibel dengan OpenAI untuk 100+ model tanpa perlu membangun infrastruktur apa pun.
Peran Utama LiteLLM dalam AI Agent
Ini adalah pertanyaan yang sering muncul bagi pemula: mengapa hampir semua kerangka kerja AI Agent populer mendukung atau bahkan merekomendasikan penggunaan LiteLLM?
Mengapa AI Agent membutuhkan LiteLLM?
AI Agent (agen cerdas) saat menjalankan tugas sering kali perlu:
- Memanggil berbagai model: Menggunakan model kecil yang murah untuk tugas sederhana, dan model besar untuk penalaran kompleks.
- Fallback otomatis: Beralih ke model cadangan saat model utama mengalami limitasi kecepatan atau down.
- Mengontrol biaya: Melacak dan membatasi penggunaan Token secara terpusat saat banyak agen berjalan secara paralel.
- Kolaborasi tim: Berbagi kumpulan sumber daya kunci API antar pengembang agen yang berbeda.
LiteLLM menyelesaikan kebutuhan ini dengan sempurna. Ia bertindak sebagai "pusat penjadwalan" antara agen dan model.
Integrasi LiteLLM dengan Kerangka Kerja AI Agent Populer
| Kerangka Kerja Agent | Cara Integrasi | Penggunaan Umum |
|---|---|---|
| LangChain / LangGraph | Dukungan bawaan SDK | ChatLiteLLM sebagai backend LLM |
| CrewAI | Koneksi Proxy | Berbagi kumpulan sumber daya model antar agen |
| AutoGen (Microsoft) | Koneksi Proxy | Akses melalui endpoint yang kompatibel dengan OpenAI |
| Dify | Provider Kustom | Dikonfigurasi sebagai endpoint yang kompatibel dengan OpenAI |
| Open WebUI | Koneksi Proxy | Endpoint API backend |
| Aider | Koneksi Proxy | Lapisan model untuk agen pembuat kode |
| Continue.dev | Koneksi Proxy | Backend asisten pengodean AI di IDE |
Arsitektur Tipikal LiteLLM dalam Sistem Multi-Agent
Dalam sistem multi-agent, LiteLLM Proxy biasanya bekerja seperti ini:
- Agen Perencana → Memanggil Claude Opus (model penalaran kuat)
- Agen Eksekutor → Memanggil GPT-4o (performa seimbang)
- Agen Validator → Memanggil GPT-4o-mini (cepat dan murah)
- Agen Ringkasan → Memanggil Gemini Flash (jendela konteks besar)
Semua agen memanggil melalui endpoint LiteLLM Proxy yang sama, dan Proxy secara otomatis merutekan ke model backend yang tepat. Administrator dapat melihat penggunaan Token dan biaya semua agen melalui Dashboard.
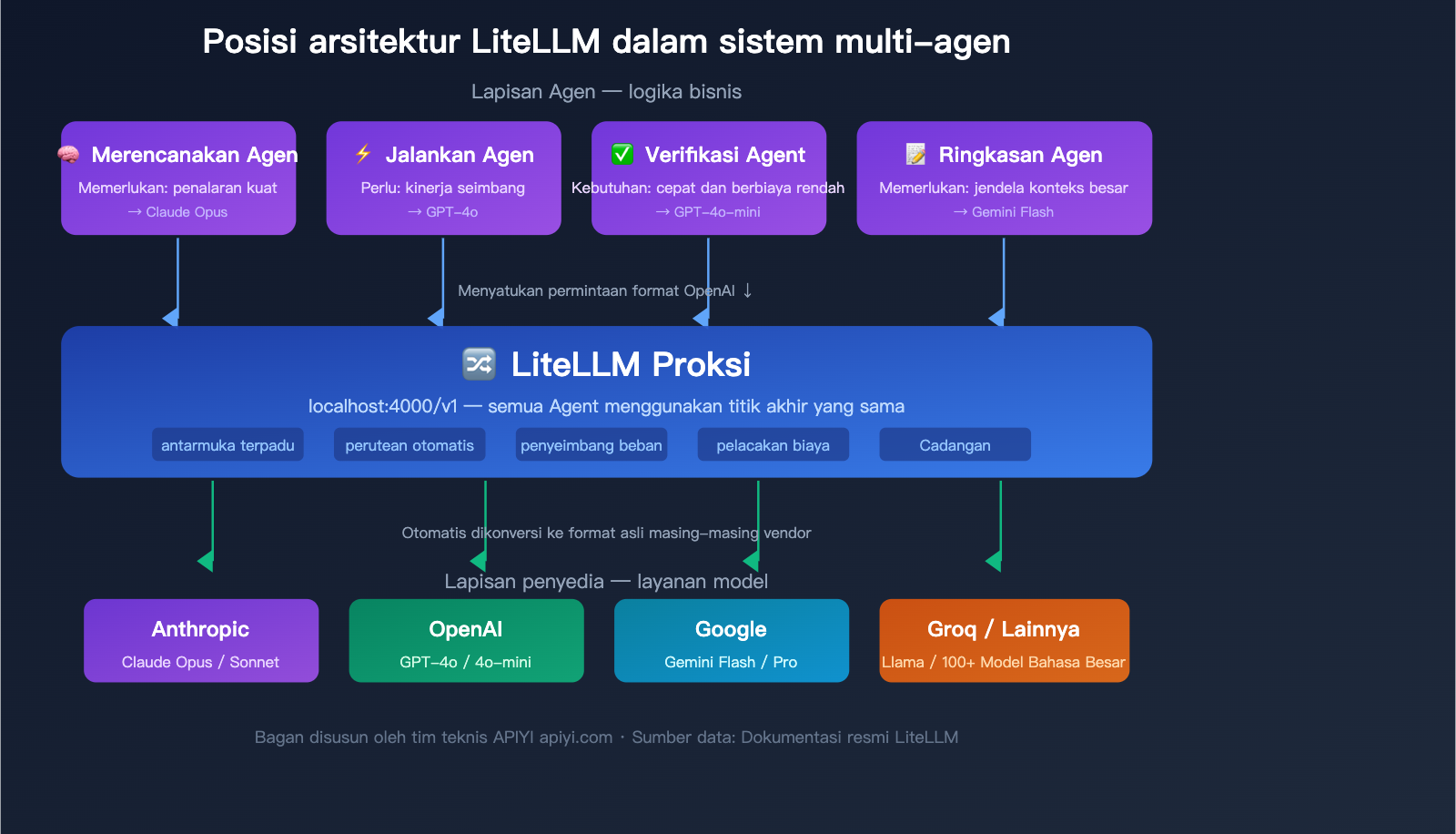
🎯 Saran Teknis: Dalam sistem multi-agent di lingkungan produksi, LiteLLM Proxy perlu dipasangkan dengan PostgreSQL dan Redis agar fitur pelacakan biaya dan caching dapat berfungsi penuh. Jika tim Anda berskala kecil atau tidak ingin mengelola infrastruktur tambahan, APIYI (apiyi.com) menyediakan kemampuan antarmuka terpadu serupa, serta dilengkapi dengan pelacakan biaya dan statistik penggunaan bawaan, tanpa perlu men-deploy database tambahan.
Penjelasan Mendalam Fitur Lanjutan LiteLLM
Setelah memahami penggunaan dasarnya, berikut adalah 3 fitur lanjutan yang paling sering digunakan dalam lingkungan produksi.
Fitur Lanjutan 1: Model Fallback (Failover)
Saat model utama mengalami limitasi kecepatan (rate limit), timeout, atau error, LiteLLM akan secara otomatis beralih ke model cadangan untuk memastikan layanan tetap berjalan tanpa gangguan.
Konfigurasi Fallback di SDK:
response = litellm.completion(
model="gpt-4o",
messages=messages,
fallbacks=["anthropic/claude-sonnet-4-6", "gemini/gemini-2.0-flash"],
num_retries=2
)
Logika eksekusi: Coba GPT-4o terlebih dahulu → Jika gagal, coba Claude Sonnet → Jika gagal lagi, coba Gemini Flash.
Konfigurasi Fallback di Proxy (config.yaml):
litellm_settings:
fallbacks:
- gpt-4o: [claude-sonnet, gemini-flash]
- claude-sonnet: [gpt-4o, gemini-flash]
Fitur Lanjutan 2: Penyeimbang Beban (Load Balancing)
Anda dapat mengonfigurasi beberapa deployment backend untuk satu nama model, dan LiteLLM akan mendistribusikan permintaan secara otomatis.
model_list:
# Satu nama model, dua backend berbeda
- model_name: gpt-4o
litellm_params:
model: openai/gpt-4o
api_key: os.environ/OPENAI_KEY_1
- model_name: gpt-4o
litellm_params:
model: azure/gpt-4o-deployment
api_key: os.environ/AZURE_KEY_1
api_base: https://my-azure.openai.azure.com
router_settings:
routing_strategy: least-busy # Prioritaskan yang paling tidak sibuk
# Strategi lain: simple-shuffle, latency-based
Saat melakukan pemanggilan, Anda cukup menentukan model="gpt-4o", dan LiteLLM akan membagi lalu lintas antara koneksi langsung OpenAI dan deployment Azure secara otomatis.
Fitur Lanjutan 3: Pelacakan Biaya dan Kunci Virtual
Membuat Kunci Virtual (Mode Proxy):
curl http://localhost:4000/key/generate \
-H "Authorization: Bearer sk-master-key" \
-H "Content-Type: application/json" \
-d '{
"max_budget": 50.0,
"budget_duration": "monthly",
"models": ["gpt-4o", "claude-sonnet"],
"metadata": {"user": "developer-01"}
}'
Perintah ini akan membuat kunci virtual dengan anggaran bulanan maksimal $50, yang hanya dapat digunakan untuk memanggil GPT-4o dan Claude Sonnet.
Pelacakan Biaya:
LiteLLM memiliki tabel harga bawaan untuk setiap model, sehingga biaya dihitung secara otomatis setiap kali ada pemanggilan API. Anda dapat melihatnya di panel manajemen Proxy:
- Total biaya berdasarkan model
- Rincian biaya per pengguna/tim
- Tren biaya berdasarkan periode waktu
- Statistik penggunaan token
💰 Optimasi Biaya: Fitur pelacakan biaya LiteLLM membantu Anda mengidentifikasi model mana yang paling memakan biaya. Dengan memanfaatkan keunggulan harga dari APIYI apiyi.com, pemanggilan model yang sama bisa mendapatkan harga yang lebih kompetitif, sehingga menurunkan biaya operasional aplikasi AI Anda lebih jauh.
Sekilas 100+ Provider Model yang Didukung LiteLLM
Jumlah provider yang didukung LiteLLM sangat banyak. Berikut adalah beberapa kategori yang paling umum digunakan:
| Kategori | Provider | Awalan Model | Contoh Model |
|---|---|---|---|
| Model Bahasa Besar Komersial | OpenAI | openai/ |
GPT-4o, GPT-4o-mini, o3 |
| Anthropic | anthropic/ |
Claude Opus 4, Sonnet 4, Haiku | |
gemini/ |
Gemini 2.0 Flash, Gemini 2.5 Pro | ||
| Platform Cloud | Azure OpenAI | azure/ |
Seri GPT di deployment Azure |
| AWS Bedrock | bedrock/ |
Claude/Llama di Bedrock | |
| Google Vertex AI | vertex_ai/ |
Gemini di Vertex | |
| Akselerasi Inferensi | Groq | groq/ |
Llama 3.1 70B (inferensi super cepat) |
| Together AI | together_ai/ |
Berbagai model open source | |
| Fireworks AI | fireworks_ai/ |
Inferensi performa tinggi | |
| Deployment Lokal | Ollama | ollama/ |
Llama/Mistral yang berjalan lokal |
| vLLM | openai/ (base kustom) |
Mesin inferensi mandiri | |
| Model Domestik | Deepseek | deepseek/ |
Deepseek Chat/Coder |
| Pencarian Teraugmentasi | Perplexity | perplexity/ |
Sonar Pro |
| Platform Agregator | OpenRouter | openrouter/ |
Berbagai model |
🎯 Saran Pemilihan: Pemilihan model bergantung pada skenario spesifik Anda. Jika Anda ragu model mana yang harus digunakan, Anda bisa menguji performa berbagai model dengan cepat melalui platform APIYI apiyi.com, yang juga mendukung pemanggilan antarmuka yang kompatibel dengan OpenAI untuk sebagian besar model di atas.

FAQ LiteLLM
Q1: Apa perbedaan antara LiteLLM dan menggunakan SDK OpenAI secara langsung?
SDK OpenAI hanya bisa memanggil model OpenAI. LiteLLM memperluas kemampuan SDK OpenAI, memungkinkan Anda memanggil 100+ penyedia model seperti Anthropic, Google, Azure, dan lainnya dengan format kode yang sama. Jika proyek Anda hanya menggunakan model OpenAI, SDK OpenAI sudah cukup. Namun, jika Anda membutuhkan dukungan multi-model, failover, atau kontrol biaya, LiteLLM adalah pilihan yang lebih baik.
Q2: Apakah LiteLLM gratis?
Fitur inti LiteLLM sepenuhnya sumber terbuka dan gratis (lisensi MIT). Namun, perlu diingat: LiteLLM sendiri gratis, tetapi API model yang dipanggil tetap berbayar. Anda perlu mendapatkan kunci API dari OpenAI, Anthropic, dan penyedia lainnya secara mandiri dan membayar biaya pemanggilan model. Jika Anda tidak ingin mengelola banyak kunci API secara terpisah, Anda bisa menggunakan platform antarmuka terpadu seperti APIYI (apiyi.com) untuk menyederhanakan manajemen kunci.
Q3: Konfigurasi server apa yang dibutuhkan untuk LiteLLM Proxy?
LiteLLM Proxy sangat ringan, server dengan 1 core dan RAM 1GB sudah cukup untuk menjalankannya. Namun, jika Anda membutuhkan fitur lengkap (pelacakan biaya, manajemen kunci virtual), Anda juga memerlukan basis data PostgreSQL dan Redis. Untuk lingkungan produksi, disarankan minimal menggunakan 2 core, RAM 4GB, ditambah PostgreSQL dan Redis.
Q4: Apa perbedaan antara LiteLLM dan OpenRouter?
Perbedaan utamanya: LiteLLM adalah solusi self-hosted (mandiri) yang bersifat sumber terbuka, sedangkan OpenRouter adalah layanan terkelola (managed service).
- LiteLLM: Gratis, Anda kelola sendiri, Anda kelola kunci API sendiri, kendali penuh atas alur data.
- OpenRouter: Siap pakai, namun ada biaya tambahan pada harga pemanggilan API, dan data melewati pihak ketiga.
Jika Anda mengutamakan privasi data atau memiliki kunci API sendiri, pilihlah LiteLLM. Jika ingin penggunaan cepat tanpa perlu melakukan deployment, pertimbangkan solusi terkelola seperti APIYI (apiyi.com).
Q5: Apakah LiteLLM mendukung output streaming?
Ya, mendukung. Baik dalam mode SDK maupun Proxy, LiteLLM mendukung penuh output streaming SSE. Respons streaming dari semua penyedia akan dikonversi secara seragam menjadi chunk dengan format OpenAI, memastikan pengalaman streaming yang konsisten.
# Contoh streaming dengan LiteLLM
stream = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "Tulis sebuah cerita"}],
stream=True
)
for chunk in stream:
print(chunk.choices[0].delta.content or "", end="")
Q6: Sebagai pemula, sebaiknya pilih mode SDK atau mode Proxy?
Jika Anda seorang pengembang Python yang baru memulai, mode SDK adalah yang paling sederhana—cukup pip install litellm dan tulis beberapa baris kode untuk menjalankannya. Setelah Anda membutuhkan kolaborasi tim, integrasi multi-bahasa, atau deployment produksi, barulah bermigrasi ke mode Proxy. Cara pemanggilan inti untuk kedua mode ini sama, sehingga biaya migrasinya sangat rendah.
Q7: Di mana file konfigurasi config.yaml LiteLLM diletakkan?
Tidak ada lokasi tetap. Saat menjalankan Proxy, cukup tentukan jalurnya melalui parameter --config:
litellm --config /path/to/your/config.yaml
Biasanya disarankan untuk meletakkannya di direktori utama proyek atau direktori konfigurasi khusus. Jika menggunakan Docker, pasang (mount) file tersebut ke dalam kontainer melalui volume.
Panduan Keputusan Cepat LiteLLM
Pilih solusi yang paling sesuai berdasarkan situasi Anda:
| Situasi Anda | Solusi yang Direkomendasikan | Alasan |
|---|---|---|
| Pengembang individu, proyek Python | LiteLLM SDK | Tanpa deployment, siap pakai dalam 5 menit |
| Pengembangan tim, butuh kontrol anggaran | LiteLLM Proxy | Kunci virtual + pelacakan biaya |
| Tidak ingin membangun infrastruktur sendiri | APIYI (apiyi.com) | Layanan terkelola, siap pakai |
| Sistem multi-agen | LiteLLM Proxy | Perutean terpadu + penyeimbang beban (load balancing) |
| Hanya menggunakan model OpenAI | Gunakan SDK OpenAI langsung | Tidak butuh lapisan tambahan |
| Mengutamakan privasi data | LiteLLM self-hosted | Data tidak melewati pihak ketiga |
Ringkasan
LiteLLM adalah alat infrastruktur yang sangat praktis dalam pengembangan aplikasi AI. Nilai intinya dapat dirangkum dalam satu kalimat: Gunakan satu format kode OpenAI untuk memanggil API dari 100+ penyedia model.
Bagi pemula, ingatlah poin-poin berikut:
- LiteLLM adalah "penerjemah": Membantu Anda menerjemahkan permintaan dengan format seragam ke dalam format API masing-masing model.
- Dua mode: SDK (paket Python ringan) dan Proxy (server gateway mandiri).
- Nilai inti: Antarmuka terpadu + Fallback + penyeimbang beban (load balancing) + pelacakan biaya.
- Standar kerangka kerja Agen: LangChain, CrewAI, AutoGen, dan lainnya hampir semuanya mendukung LiteLLM.
- Sepenuhnya sumber terbuka dan gratis: Lisensi MIT, tanpa biaya untuk penerapan mandiri.
Jika Anda merasa biaya operasional untuk penerapan mandiri LiteLLM Proxy terlalu tinggi, Anda juga bisa langsung menggunakan layanan antarmuka terpadu terkelola seperti APIYI (apiyi.com). Anda bisa mendapatkan hasil yang sama, yaitu satu kunci API untuk memanggil semua model utama, tanpa beban penerapan dan pemeliharaan.
Penulis Artikel: Tim Teknis APIYI
Diskusi Teknis: Kunjungi APIYI di apiyi.com untuk mendapatkan tutorial pemanggilan model AI dan dukungan teknis lainnya.
Tanggal Pembaruan: April 2026
Versi yang Berlaku: LiteLLM v1.x+
Referensi:
- Dokumentasi Resmi LiteLLM: docs.litellm.ai
- Repositori GitHub LiteLLM: github.com/BerriAI/litellm
- Situs Web Resmi LiteLLM: litellm.ai
- Situs Web Resmi BerriAI: berri.ai