Le 24 avril 2026, DeepSeek a simultanément rendu open source les modèles V4-Pro et V4-Flash. Si le modèle Flash se positionne comme le choix idéal pour un excellent rapport qualité-prix, le V4-Pro est un produit d'une toute autre envergure :
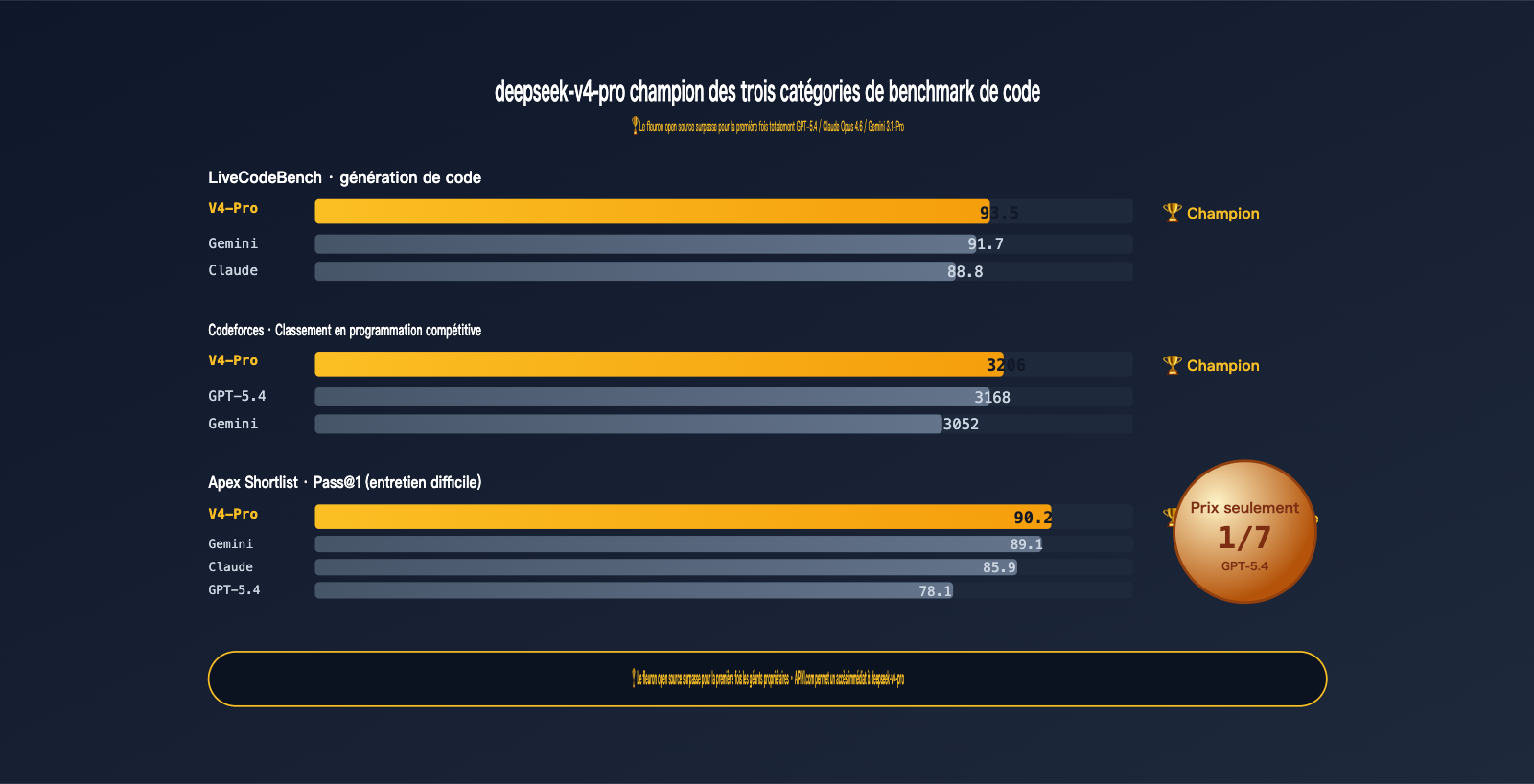
Il s'agit actuellement du modèle open source doté des capacités de codage les plus puissantes.
Ce n'est pas une simple formule de politesse pour dire qu'il est "le meilleur parmi les modèles open source", c'est un champion dont les données brutes surpassent directement GPT-5.4, Claude Opus 4.6 et Gemini 3.1-Pro :
- LiveCodeBench 93,5 — Premier du classement, dépassant Gemini 3.1-Pro (91,7) et Claude Opus 4.6 (88,8).
- Codeforces Rating 3206 — Supérieur à GPT-5.4 (3168) et Gemini 3.1-Pro (3052).
- Apex Shortlist Pass@1 90,2 — Largement en tête devant GPT-5.4 (78,1) et Claude (85,9).
- IMOAnswerBench 89,8 — Sur les problèmes de mathématiques de compétition, il devance Claude Opus 4.6 (75,3) de 14 points.
La configuration est impressionnante : 1,6T de paramètres totaux / 49B activés / 32T tokens de pré-entraînement / 1M de fenêtre de contexte / 384K en sortie, auxquels s'ajoutent les quatre innovations architecturales conçues par DeepSeek pour la série V4 : Hybrid Attention, Manifold-Constrained Hyper-Connections (mHC), Engram Conditional Memory et Muon Optimizer.
Le modèle deepseek-v4-pro est désormais disponible sur APIYI (apiyi.com). Vous pouvez l'intégrer sans aucune modification de code via les SDK compatibles avec les protocoles OpenAI ou Anthropic, pour un tarif représentant seulement 1/7ème du coût de GPT-5.4.
Cet article ne reviendra pas sur les bases déjà abordées dans notre présentation du modèle Flash (migration ou choix de modèles économiques) — voici une analyse technique dédiée aux adeptes de la performance pure avec deepseek-v4-pro :
- 3 minutes pour comprendre pourquoi le modèle Pro mérite son titre de "flagship" (architecture + données + échelle).
- 4 tableaux de comparaison des benchmarks pour identifier les points forts et les limites du modèle Pro.
- 5 minutes pour l'intégration + 2 cas d'usage réels en code et en mathématiques.

I. Les quatre capacités phares de deepseek-v4-pro
1.1 Tableau des spécifications principales
| Dimension | deepseek-v4-pro |
|---|---|
| Date de sortie | 24-04-2026 (version préliminaire) |
| Dépôt open source | huggingface.co/deepseek-ai/DeepSeek-V4-Pro |
| Paramètres totaux | 1,6 T (Mixture of Experts) |
| Paramètres activés | 49 B |
| Données de pré-entraînement | > 32 T tokens |
| Fenêtre de contexte | 1 M tokens |
| Sortie maximale | 384 K tokens |
| Innovation architecturale | Hybrid Attention + mHC + Engram Memory + Muon |
| Mode d'inférence | Double mode Thinking / Non-Thinking |
| Function Calling | ✅ Supporté |
| Mode JSON | ✅ Supporté |
| Protocole API | Double compatibilité OpenAI + Anthropic |
| Prix d'entrée | 1,74 $ / M tokens |
| Prix de sortie | 3,48 $ / M tokens |
Retenez ces 4 chiffres clés : 1,6 T / 49 B / 32 T / 1 M — c'est la force de frappe de ce modèle phare.
1.2 1,6 T / 49 B MoE : le "plafond de verre" de l'open source
DeepSeek-V4-Pro possède 1,6 billion de paramètres totaux, utilisant une architecture Mixture of Experts, avec seulement 49 B de paramètres activés par token. Voici ce que ces chiffres signifient :
| Modèle | Paramètres totaux | Paramètres activés | Type |
|---|---|---|---|
| Llama 3 70B | 70 B | 70 B | Dense (activation totale) |
| Mistral Large 2 | 123 B | 123 B | Dense |
| DeepSeek-V3.2 | 671 B | 37 B | MoE |
| DeepSeek-V4-Pro | 1,6 T | 49 B | MoE ⭐ |
| Claude Opus 4.6 | Non divulgué | Non divulgué | Fermé |
Les 1,6 T de paramètres totaux confèrent au modèle une étendue de connaissances proche de GPT-5.4 / Claude Opus, tandis que les 49 B de paramètres activés permettent de maîtriser les coûts d'inférence par token — c'est la raison fondamentale pour laquelle l'architecture MoE permet d'atteindre des performances de pointe.
1.3 32 T tokens de pré-entraînement : un volume de données massif
Données de pré-entraînement > 32 T tokens
C'est un chiffre impressionnant :
- GPT-4 : environ 13 T tokens (estimations du secteur)
- Llama 3 : 15 T tokens
- DeepSeek-V3 : 14,8 T tokens
- DeepSeek-V4-Pro : > 32 T tokens ⭐
Les avantages directs de ce doublement de volume de données sont : une couverture plus complète des connaissances de longue traîne, des corpus de code plus récents et une base de données mathématique plus approfondie — c'est la raison pour laquelle V4-Pro domine les classements LiveCodeBench et IMOAnswerBench.
1.4 Quatre innovations architecturales : le véritable fossé concurrentiel
C'est ce qui distingue V4-Pro d'un simple "énième modèle MoE". Voici les quatre innovations majeures :
| Innovation | Nom complet | Problème résolu |
|---|---|---|
| Hybrid Attention | Attention hybride CSA + HCA | Problèmes de FLOPs et de mémoire pour le contexte long (1 M) |
| mHC | Manifold-Constrained Hyper-Connections | Stabilité des connexions résiduelles profondes, évite la disparition/explosion du gradient |
| Engram | Engram Conditional Memory | Découplage entre "faits statiques" et "capacité de raisonnement", mises à jour moins coûteuses |
| Muon | Optimiseur Muon | Vitesse de convergence et stabilité, réduction des coûts d'entraînement |
Chaque point mérite d'être détaillé :
-
Hybrid Attention (CSA + HCA) : La complexité de l'attention des Transformers traditionnels est en O(n²), ce qui fait exploser le contexte de 1 M. V4 utilise l'attention creuse compressée (CSA) pour un filtrage grossier et l'attention hautement compressée (HCA) pour une focalisation fine. Cette combinaison réduit les FLOPs à 27 % de ceux de V3.2, et le cache KV à seulement 10 %. C'est la clé qui permet à deepseek-v4-pro de "faire tourner" un contexte de 1 M.
-
mHC (Manifold-Constrained Hyper-Connections) : Lors de l'entraînement de modèles MoE profonds, les signaux des connexions résiduelles peuvent se distordre après plusieurs dizaines de couches. Le mHC ajoute des contraintes dans l'espace des variétés (manifold), rendant la propagation du signal plus stable. En pratique : le modèle peut être entraîné plus profondément et plus longtemps sans s'effondrer.
-
Engram Conditional Memory : Une innovation très pragmatique. Elle découple les "faits mémorisés" de la "capacité de raisonnement". Les faits sont stockés dans un module de mémoire dédié, tandis que la chaîne de raisonnement suit un autre chemin. Résultat : lorsqu'il faut mettre à jour les connaissances mondiales, il n'est pas nécessaire de réentraîner tout le modèle, ce qui réduira considérablement les coûts de publication des futures versions Pro.
-
Muon Optimizer : Un optimiseur développé par DeepSeek, plus rapide et plus stable que AdamW. À l'échelle d'un entraînement de mille milliards de paramètres, cela signifie un entraînement plus complet à puissance de calcul égale.
🎯 Leçon technique : deepseek-v4-pro ne se contente pas d'agrandir une ancienne architecture, il a réécrit l'infrastructure. C'est la raison fondamentale pour laquelle il atteint le niveau des géants propriétaires tout en restant open source. Si vous prévoyez une utilisation intensive, je vous conseille de tester d'abord une série d'invites métier typiques via APIYI (apiyi.com) pour ressentir la différence apportée par cette mise à niveau, surtout pour les contextes longs et les scénarios de raisonnement multi-étapes.
1.5 1 M de contexte + 384 K de sortie : un tournant pour les textes longs
Pro et Flash ont les mêmes spécifications de contexte : 1 M de tokens en entrée, 384 K en sortie. Mais l'avantage de Pro ne réside pas dans la longueur de lecture, mais dans sa capacité à "réfléchir plus profondément" sur 1 M de tokens.
Signification pratique pour les scénarios de textes longs :
| Tâche | Ère V3.2 | Ère V4-Pro |
|---|---|---|
| Révision complète d'un manuscrit de 500 000 mots | Découpage en 10+ morceaux | Traitement en une seule fenêtre de 1 M |
| Questions-réponses sur 200 pages de doc technique | Construction de RAG nécessaire | Injection directe |
| Audit d'un dépôt de code moyen | Analyse par résumé | Vérification de cohérence entre fichiers |
| Cohérence de l'écriture romanesque | Gestion manuelle de la mémoire | 384 K de sortie en une seule traite |
II. Le trône de deepseek-v4-pro dans les benchmarks

2.1 Capacités de code : deepseek-v4-pro domine les classements
Regardons les données les plus objectives — la programmation :
| Benchmark | V4-Pro | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1-Pro | Premier |
|---|---|---|---|---|---|
| LiveCodeBench | 93,5 | — | 88,8 | 91,7 | V4-Pro 🏆 |
| Codeforces Rating | 3206 | 3168 | — | 3052 | V4-Pro 🏆 |
| Apex Shortlist Pass@1 | 90,2 | 78,1 | 85,9 | 89,1 | V4-Pro 🏆 |
| SWE-bench Verified | 80,6–82,1 | — | 80,8 | 80,6 | Ex aequo |
| Terminal-Bench 2.0 | 67,9 | 75,1 | 65,4 | 68,5 | GPT-5.4 |
Trois victoires, deux places de "premier ex aequo ou légère défaite". C'est la première fois qu'un modèle open source surpasse globalement les modèles propriétaires sur les capacités de code — un événement marquant pour 2026.
Analyse :
- LiveCodeBench 93,5 : Mis à jour mensuellement pour éviter la contamination des données. Le score de 93,5 montre que les capacités de V4-Pro sont généralisées et ne reposent pas sur une mémorisation.
- Codeforces 3206 : Score de programmation compétitive, équivalent à un niveau IGM (International Grandmaster). C'est un avantage écrasant pour le code métier quotidien.
- Apex Shortlist Pass@1 90,2 vs GPT-5.4 78,1 : Un écart systémique. V4-Pro mène de 12 points de pourcentage sur ces tests d'entretien de haut niveau.
- Terminal-Bench 2.0 : Légèrement plus faible. GPT-5.4 garde l'avantage sur l'utilisation complexe d'outils en ligne de commande, prouvant que les "Agents complexes multi-étapes" restent une chasse gardée de GPT-5.4.
2.2 Mathématiques et raisonnement : deepseek-v4-pro au sommet
Sur les mathématiques, Pro rivalise avec les géants propriétaires :
| Benchmark | V4-Pro | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1-Pro |
|---|---|---|---|---|
| MMLU-Pro | 87,5 | 87,5 | 89,1 | 91,0 |
| IMOAnswerBench | 89,8 | 91,4 | 75,3 | 81,0 |
| HMMT 2026 | 95,2 | 97,7 | 96,2 | — |
| MATH | 92% | — | — | — |
| HumanEval | 90% | — | — | — |
| MMLU | 89% | — | — | — |
Le point fort est l'IMOAnswerBench : V4-Pro obtient 89,8 points, devançant Claude Opus 4.6 de 14,5 points et Gemini 3.1-Pro de 8,8 points. Pour le raisonnement mathématique et les preuves formelles, Pro est le plafond de verre actuel de l'open source.
Le point faible est le MMLU-Pro (connaissances générales) : Pro est à égalité avec GPT-5.4, mais à 3,5 points derrière Gemini 3.1-Pro. Gemini conserve un avantage sur les questions de culture générale.
2.3 Répartition des forces : où gagne et perd deepseek-v4-pro
| Domaine | Champion | Position de V4-Pro |
|---|---|---|
| Génération de code (LiveCodeBench) | V4-Pro 🏆 | Champion |
| Programmation compétitive (Codeforces) | V4-Pro 🏆 | Champion |
| Entretiens techniques (Apex) | V4-Pro 🏆 | Champion (large avance) |
| Ingénierie logicielle (SWE-bench) | Ex aequo | Premier ex aequo |
| Concours mathématiques (IMO) | GPT-5.4 | Deuxième (loin devant Claude/Gemini) |
| Connaissances générales (MMLU-Pro) | Gemini 3.1-Pro | Troisième |
| Chaînes d'outils multi-étapes (Terminal-Bench) | GPT-5.4 | Deuxième |
| Raisonnement cohérent (HMMT) | GPT-5.4 | Troisième |
Conclusion : Si votre charge de travail est principalement axée sur le code, deepseek-v4-pro est l'un des choix les plus puissants au monde. Si vous privilégiez les chaînes d'outils Agent multi-étapes, GPT-5.4 garde un léger avantage ; pour les connaissances générales, Gemini 3.1-Pro reste supérieur.
🎯 Conseil de sélection : Nous recommandons de tester une série de comparaisons AB (20 à 50 exemples suffisent) entre V4-Pro et votre modèle actuel sur APIYI (apiyi.com). Ne vous fiez pas aveuglément aux benchmarks publics — votre propre distribution d'invites est le seul benchmark réel. Pour les tests AB à grande échelle, utilisez la ligne à haute concurrence
vip.apiyi.com.
III. 5 minutes pour invoquer deepseek-v4-pro sur APIYI apiyi.com
3.1 Étape 1 : Obtenir la clé et choisir la route
Prérequis : Python 3.8+ ou Node.js 18+, SDK OpenAI officiel ou SDK Anthropic au choix.
Obtenir la clé :
- Accédez à APIYI
apiyi.com, console → Clés API → Créer une nouvelle clé. - Il est conseillé de définir un quota journalier spécifique pour la clé Pro (200–500 ¥, selon l'échelle de votre activité).
- Copiez la clé commençant par
sk-.
Choisir la route (les trois routes partagent la même clé) :
| base_url | Utilisation |
|---|---|
https://api.apiyi.com/v1 |
Appels quotidiens, scénarios interactifs |
https://vip.apiyi.com/v1 |
Tâches par lots, haute concurrence |
https://b.apiyi.com/v1 |
Secours en cas d'instabilité du site principal |
3.2 Étape 2 : Appel minimal en Python (sans réflexion)
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1",
)
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "system", "content": "Vous êtes un ingénieur Python senior."},
{"role": "user", "content": "Écrivez un cache LRU prêt pour la production en 30 lignes."},
],
max_tokens=2048,
)
print(resp.choices[0].message.content)
Modifiez deux éléments : base_url et model — le reste du code du SDK OpenAI reste inchangé.
3.3 Étape 3 : Activer le mode de réflexion (le point fort de la version Pro)
La véritable valeur de deepseek-v4-pro ne se révèle pleinement qu'en mode réflexion (Thinking). Les scores de 89,8 sur IMOAnswerBench et 93,5 sur LiveCodeBench ont été obtenus dans ce mode.
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "user", "content": """
Veuillez implémenter un limiteur de débit (rate limiter) de type token bucket sécurisé pour la concurrence, avec :
1. Support du réglage dynamique du débit
2. Support de la réservation pour les pics de trafic
3. Implémentation sans verrou (CAS ou opérations atomiques)
4. Tests unitaires complets inclus
"""},
],
extra_body={
"reasoning": {"enabled": True, "effort": "high"},
},
max_tokens=16384,
)
print("--- Processus de réflexion ---")
print(resp.choices[0].message.reasoning_content)
print("\n--- Réponse finale ---")
print(resp.choices[0].message.content)
Avec effort=high, le modèle Pro effectue une planification approfondie : il analyse les besoins, conçoit l'API, discute des différentes solutions d'implémentation, et enfin fournit le code. C'est là que deepseek-v4-pro justifie son prix par rapport à la version Flash.
3.4 Étape 4 : Correction de code en conditions réelles
Scénario métier réel : demander à Pro de corriger un bug.
buggy_code = """
def find_kth_largest(nums, k):
nums.sort()
return nums[k] # BUG ici
"""
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "system", "content": "Vous êtes un relecteur de code senior. Identifiez les bugs, expliquez la cause profonde et fournissez le code corrigé."},
{"role": "user", "content": f"Relisez ce code :\n```python\n{buggy_code}\n```"},
],
extra_body={"reasoning": {"enabled": True}},
max_tokens=4096,
)
print(resp.choices[0].message.content)
Pro soulignera que l'index devrait être -k (après tri, le k-ième plus grand élément se trouve à la k-ième position en partant de la fin), et fournira la correction ainsi que la gestion des cas aux limites (k <= 0, k > len(nums)) et des cas de test.
Les 80%+ de réussite sur SWE-bench se ressentent concrètement dans ce type de scénario.
3.5 Étape 5 : Appel de fonction / Utilisation d'outils
Pro est très stable pour les appels d'outils simples. Bien que les chaînes d'outils multi-étapes soient légèrement inférieures à GPT-5.4, elles surpassent Claude :
tools = [
{
"type": "function",
"function": {
"name": "run_sql",
"description": "Exécute une requête SQL en lecture seule sur la base de données analytique.",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "SQL de type SELECT uniquement"},
},
"required": ["query"],
},
},
},
]
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "user", "content": "Quelles sont les 5 villes avec le plus haut DAU des 30 derniers jours ?"},
],
tools=tools,
tool_choice="auto",
)
print(resp.choices[0].message.tool_calls)
3.6 Étape 6 : Protocole Anthropic (Intégration de Claude Code avec Pro)
C'est la valeur la plus sous-estimée de deepseek-v4-pro : tous vos projets existants utilisant le SDK Claude ou Claude Code peuvent basculer sur le modèle V4-Pro sans modifier une seule ligne de code métier.
from anthropic import Anthropic
client = Anthropic(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com", # Notez l'absence de /v1
)
resp = client.messages.create(
model="deepseek-v4-pro",
max_tokens=4096,
messages=[
{"role": "user", "content": "Refactorez ce code Python en style async/await..."},
],
)
print(resp.content[0].text)
Terminal Claude Code : dans la configuration, réglez ANTHROPIC_BASE_URL=https://api.apiyi.com, ANTHROPIC_API_KEY=sk-... et changez le modèle pour deepseek-v4-pro. Vous obtenez immédiatement un Agent de terminal aux capacités de codage supérieures.
3.7 Étape 7 : Intégration de deepseek-v4-pro dans Cursor
Dans Cursor, allez dans Settings → Models → Custom OpenAI-Compatible :
- Base URL :
https://api.apiyi.com/v1 - API Key :
sk-... - Model Name :
deepseek-v4-pro
Une fois configuré, les entrées Chat / Cmd+K / Composer de Cursor utiliseront V4-Pro, améliorant nettement la qualité de la complétion et du refactoring de code.
🎯 Conseil d'intégration IDE : Les outils de programmation IA populaires comme Cursor, Windsurf, Cline et Continue sont compatibles avec le protocole OpenAI. Il suffit de pointer
base_urlversapi.apiyi.com/v1sur APIYI et de changer le modèle pourdeepseek-v4-propour une migration transparente. Des exemples de configuration détaillés sont disponibles dans la rubrique DeepSeek V4 de la documentation officielledocs.apiyi.com.
IV. Quand choisir (ou non) deepseek-v4-pro
4.1 Conditions de décision pour choisir Pro
✅ Choisissez directement deepseek-v4-pro dans les cas suivants :
| Scénario | Pourquoi |
|---|---|
| Génération, refactoring et revue de code | Champion toutes catégories avec 93,5 sur LiveCodeBench |
| Programmation compétitive, entraînement aux algorithmes | Niveau IGM équivalent avec 3206 sur Codeforces |
| Réponses par lots aux questions d'entretien | Large avance avec 90,2 sur Apex Shortlist |
| Raisonnement mathématique, preuves formelles | 89,8 sur IMOAnswerBench, devançant Claude de 14 points |
| Compréhension de grands dépôts de code | 1M de fenêtre de contexte + 49B de paramètres activés |
| Rédaction et édition de longs textes | 384K en sortie en une seule fois |
| Déploiement local / réentraînement | Poids open-source + module Engram facilitant le fine-tuning |
| Remplacement du modèle sous-jacent de Cursor / Claude Code | Intégration sans modification via le protocole Anthropic |
4.2 Quand ne pas choisir Pro
❌ Ne gaspillez pas la puissance de calcul de Pro dans ces cas :
| Scénario | Suggestion |
|---|---|
| Conversations quotidiennes, FAQ | Utilisez Flash (12 fois moins cher) |
| Classification ou extraction de textes courts | Utilisez Flash ou un modèle plus petit |
| Chaînes d'outils complexes multi-étapes | Privilégiez GPT-5.4 (en avance sur Terminal-Bench) |
| Questions-réponses basées sur des connaissances générales | Gemini 3.1-Pro est plus performant |
| Interactions en ligne sensibles à la latence | Utilisez Flash (mode sans réflexion) ou ajoutez un cache |
4.3 Conseils de routage hybride
La solution optimale en environnement de production est généralement le routage par couches :
def pick_model(request_type: str, complexity: str) -> str:
# Travaux lourds de code → Pro
if request_type in ("code_gen", "code_review", "refactor") and complexity == "hard":
return "deepseek-v4-pro"
# Raisonnement mathématique → Pro
if request_type in ("math_proof", "competitive_programming"):
return "deepseek-v4-pro"
# Compréhension approfondie de longs documents → Pro
if request_type == "long_doc_analysis":
return "deepseek-v4-pro"
# Autres usages quotidiens → Flash
return "deepseek-v4-flash"
Sur APIYI apiyi.com, ces deux modèles partagent la même clé. Le basculement ne nécessite que la modification du champ model, sans changer aucune autre configuration.
V. FAQ sur deepseek-v4-pro
Q1 : Pourquoi les capacités de codage du modèle Pro sont-elles si performantes ?
C'est la combinaison de trois facteurs :
- Pré-entraînement sur 32T tokens : incluant une vaste quantité de corpus de code de haute qualité.
- 1,6T MoE / 49B activés : permet de stocker et d'accéder efficacement aux connaissances en programmation.
- Mode Thinking + Engram Memory : dissocie la "mémorisation des paradigmes de code" du "raisonnement pour générer du nouveau code".
Aucun de ces éléments seul ne permettrait d'atteindre ce score ; c'est leur synergie qui permet d'obtenir 93,5 sur LiveCodeBench.
Q2 : Les 1,6T de paramètres ne rendent-ils pas la réponse lente ?
La vitesse de réponse dépend des paramètres activés, pas du total. Le modèle Pro n'active que 49B par token. Avec l'optimisation des FLOPs via Hybrid Attention, la latence du premier token est proche de celle de Flash. Le mode Thinking est un peu plus lent (car il doit générer le processus de raisonnement), mais c'est un choix de conception : vous payez en temps pour la qualité du raisonnement.
Q3 : Le mode Thinking est-il obligatoire ?
Non. Pour les conversations simples, le code basique ou les questions quotidiennes, vous pouvez le désactiver. Cependant, la majeure partie de la valeur de votre abonnement Pro réside dans le mode Thinking. Pour du code complexe, des problèmes mathématiques ou une logique multi-étapes, activez impérativement reasoning.enabled=true + effort=high.
Q4 : Comment l'utiliser dans Cursor / Claude Code ?
- Cursor : Paramètres → Modèles → Custom OpenAI-Compatible, Base URL :
https://api.apiyi.com/v1, Modèle :deepseek-v4-pro. - Claude Code : Variables d'environnement
ANTHROPIC_BASE_URL=https://api.apiyi.com+ANTHROPIC_API_KEY=sk-..., spécifiezdeepseek-v4-proau lancement.
Vous trouverez des captures d'écran détaillées dans la section intégration IDE sur docs.apiyi.com.
Q5 : Lequel est le plus rentable par rapport à GPT-5.4 ?
Si vous devez choisir :
- Code quotidien / Compétitions / Maths / Sensibilité aux coûts → deepseek-v4-pro (champion du code, prix divisé par 7).
- Agents multi-outils / Connaissances générales → GPT-5.4.
- L'usage mixte est la solution optimale (utilisez la même clé API via APIYI apiyi.com pour basculer entre les deux modèles).
Q6 : Peut-on le déployer localement ?
Oui, les poids complets de V4-Pro sont en open source sur Hugging Face (deepseek-ai/DeepSeek-V4-Pro). Mais le déploiement autonome exige :
- Une configuration ≥ 8×H200 ou GPU équivalent par machine.
- Un cache KV supplémentaire pour 1M de fenêtre de contexte (bien que Pro ait réduit le cache à 10 % de celui de V3.2).
- Des coûts d'ingénierie pour maintenir le service d'inférence.
Calcul de coût : à moins que votre volume mensuel ne dépasse 50 milliards de tokens, l'utilisation du service hébergé via APIYI apiyi.com est plus économique que l'auto-hébergement.
Q7 : Quelle est la limite de concurrence ?
Recommandations pour l'environnement de production :
- Site principal
api.apiyi.com: 50 requêtes simultanées sécurisées. - Ligne haute concurrence
vip.apiyi.com: 200+ requêtes simultanées. - Secours
b.apiyi.com: basculement automatique en cas d'instabilité de la ligne principale.
La latence étant plus élevée pour les tâches complexes en mode Thinking, le nombre de requêtes simultanées ne doit pas être maximisé aveuglément : estimez votre fenêtre de concurrence en fonction du QPS × temps de réponse moyen.
Q8 : Une version officielle sortira-t-elle bientôt ?
La version publiée le 24/04/2026 est une version Preview. Selon le rythme habituel de DeepSeek, la version officielle sort généralement 1 à 2 mois après, avec potentiellement de légères améliorations des benchmarks. Utiliser la version Preview sur APIYI apiyi.com ne pose aucun problème : l'identifiant du modèle restera très probablement deepseek-v4-pro pour assurer la rétrocompatibilité.
VI. Résumé du lancement de deepseek-v4-pro
Si vous n'avez retenu que l'essentiel :
- ✅ deepseek-v4-pro est actuellement le modèle open source le plus performant pour le code : il surpasse GPT-5.4, Claude Opus 4.6 et Gemini 3.1-Pro sur les trois benchmarks de référence (LiveCodeBench / Codeforces / Apex).
- ✅ Quatre innovations architecturales (Hybrid Attention / mHC / Engram Memory / Muon) en font une nouvelle espèce technologique, bien plus qu'un simple "grand modèle de langage".
- ✅ 1,6T / 49B MoE + 32T tokens de pré-entraînement + 1M de fenêtre de contexte : il atteint le plafond de ce qui est possible en open source.
- ✅ Disponible sur APIYI apiyi.com, compatible avec les protocoles OpenAI et Anthropic, intégration sans modification dans Cursor, Claude Code, Cline, etc.
- ✅ Prix représentant 1/7ème de celui de GPT-5.4, avec un mode Thinking qui révèle son véritable potentiel.
Pour les équipes de développement axées sur le code, deepseek-v4-pro mérite d'être testé immédiatement. Ce n'est pas juste une alternative moins chère, c'est un modèle phare qui pourrait bien devenir la nouvelle référence.
🎯 Conseil d'action : demandez dès aujourd'hui une clé sur APIYI
apiyi.com(dédiée au modèle Pro, avec un plafond journalier de 200–500 ¥). Testez-le sur 20 invites (prompts) représentatives de votre activité (code, maths, textes longs) et comparez les résultats avec votre modèle habituel. Si la qualité du code s'améliore nettement, basculez votre modèle par défaut dans Cursor / Claude Code. Si vous avez besoin de décharger les tâches simples, ajoutez V4-Flash (voir le guide de migration précédent). Pour les tests en masse, utilisezvip.apiyi.comet laissezb.apiyi.comgérer le basculement automatique. Exemples d'intégration, configuration IDE et scripts de reproduction de benchmarks sont disponibles surdocs.apiyi.com.
La portée de deepseek-v4-pro dépasse celle d'un simple modèle SOTA bon marché. Il marque la première fois qu'un modèle open source surpasse totalement les modèles propriétaires phares sur les capacités de codage fondamentales. C'est une étape que toute équipe sérieuse en ingénierie IA se doit d'évaluer.
Auteur : Équipe technique APIYI
Ressources associées :
- Annonce officielle DeepSeek : api-docs.deepseek.com/news/news260424
- Dépôt open source Hugging Face : huggingface.co/deepseek-ai/DeepSeek-V4-Pro
- Site officiel APIYI : apiyi.com
- Documentation APIYI : docs.apiyi.com
- Site principal APIYI : api.apiyi.com (secours vip.apiyi.com / b.apiyi.com)