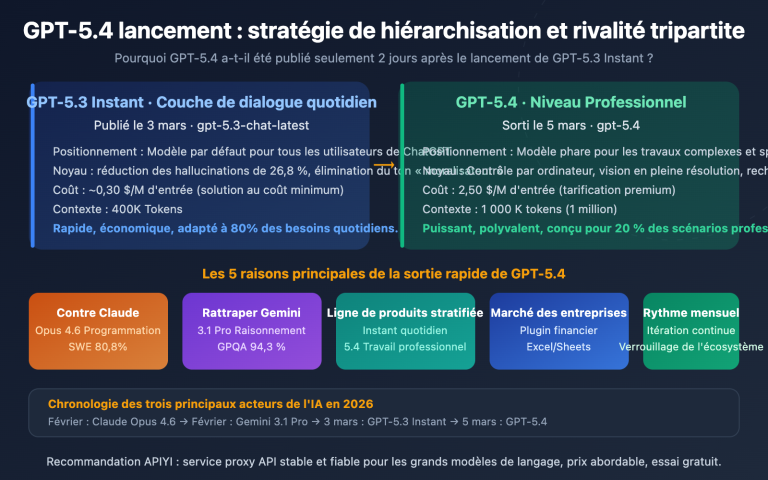
智谱AI在 2026 年 2 月 11 日正式发布了 GLM-5,这是目前参数规模最大的开源大语言模型之一。GLM-5 采用 744B MoE 混合专家架构,每次推理激活 40B 参数,在推理、编码和 Agent 任务上达到了开源模型的最佳水平。
核心价值: 读完本文,你将掌握 GLM-5 的技术架构原理、API 调用方法、Thinking 推理模式配置,以及如何在实际项目中发挥这个 744B 开源旗舰模型的最大价值。

Aperçu des paramètres clés du GLM-5
Avant de plonger dans les détails techniques, jetons un coup d'œil aux paramètres cruciaux du GLM-5 :
| Paramètre | Valeur | Description |
|---|---|---|
| Nombre total de paramètres | 744B (744 milliards) | L'un des plus grands modèles open-source actuels |
| Paramètres actifs | 40B (40 milliards) | Utilisés réellement lors de chaque inférence |
| Type d'architecture | MoE (Mélange d'experts) | 256 experts, 8 activés par token |
| Fenêtre de contexte | 200 000 tokens | Supporte le traitement de documents ultra-longs |
| Sortie maximale | 128 000 tokens | Répond aux besoins de génération de textes longs |
| Données de pré-entraînement | 28,5T tokens | Augmentation de 24 % par rapport à la génération précédente |
| Licence | Apache-2.0 | Entièrement open-source, supporte l'usage commercial |
| Matériel d'entraînement | Puces Huawei Ascend | Puissance de calcul 100 % chinoise, sans dépendance matérielle étrangère |
Une caractéristique notable du GLM-5 est qu'il a été entièrement entraîné sur des puces Huawei Ascend et le framework MindSpore, validant ainsi l'intégralité de la pile de calcul nationale chinoise. Pour les développeurs, cela représente une alternative robuste et souveraine.
Évolution des versions de la série GLM
Le GLM-5 est la cinquième génération de la série GLM de Zhipu AI, chaque version apportant des sauts de performance significatifs :
| Version | Date de sortie | Taille des paramètres | Percées majeures |
|---|---|---|---|
| GLM-4 | 01/2024 | Non communiqué | Capacités multimodales de base |
| GLM-4.5 | 03/2025 | 355B (32B actifs) | Première introduction de l'architecture MoE |
| GLM-4.5-X | 06/2025 | Idem | Raisonnement renforcé, positionnement flagship |
| GLM-4.7 | 10/2025 | Non communiqué | Mode de raisonnement "Thinking" |
| GLM-4.7-FlashX | 12/2025 | Non communiqué | Inférence rapide à ultra-bas coût |
| GLM-5 | 02/2026 | 744B (40B actifs) | Percée des capacités d'Agent, taux d'hallucination réduit de 56 % |
Du GLM-4.5 (355B) au GLM-5 (744B), le nombre total de paramètres a plus que doublé ; les paramètres actifs sont passés de 32B à 40B (+25 %) ; et les données de pré-entraînement ont grimpé de 23T à 28,5T tokens. Derrière ces chiffres se cache l'investissement massif de Zhipu AI dans la puissance de calcul, les données et les algorithmes.
🚀 Test rapide : Le GLM-5 est déjà disponible sur APIYI (apiyi.com). Les tarifs sont identiques à ceux du site officiel, et avec les promotions sur les recharges, vous pouvez bénéficier d'environ 20 % de réduction. C'est idéal pour les développeurs souhaitant tester rapidement ce modèle phare de 744B.
Analyse technique de l'architecture MoE du GLM-5
Pourquoi le GLM-5 a-t-il choisi l'architecture MoE ?
Le MoE (Mixture of Experts) est la voie technologique dominante pour l'extension des grands modèles de langage. Contrairement à l'architecture "Dense" (où tous les paramètres participent à chaque inférence), l'architecture MoE n'active qu'une petite fraction du réseau d'experts pour traiter chaque token, ce qui réduit considérablement les coûts d'inférence tout en conservant une immense capacité de connaissances.
L'architecture MoE du GLM-5 présente les caractéristiques clés suivantes :
| Caractéristique | Implémentation GLM-5 | Valeur technique |
|---|---|---|
| Nombre total d'experts | 256 | Capacité de connaissances massive |
| Activés par token | 8 experts | Haute efficacité d'inférence |
| Taux de sparsité | 5,9 % | Utilise seulement une petite fraction des paramètres |
| Mécanisme d'attention | DSA + MLA | Réduit les coûts de déploiement |
| Optimisation mémoire | MLA réduit de 33 % | Occupation de la VRAM plus faible |
En résumé, bien que le GLM-5 possède 744B de paramètres, il n'en active que 40B (environ 5,9 %) par inférence. Cela signifie que son coût d'inférence est bien inférieur à celui d'un modèle Dense de taille équivalente, tout en bénéficiant de la richesse des connaissances contenues dans ses 744B de paramètres.
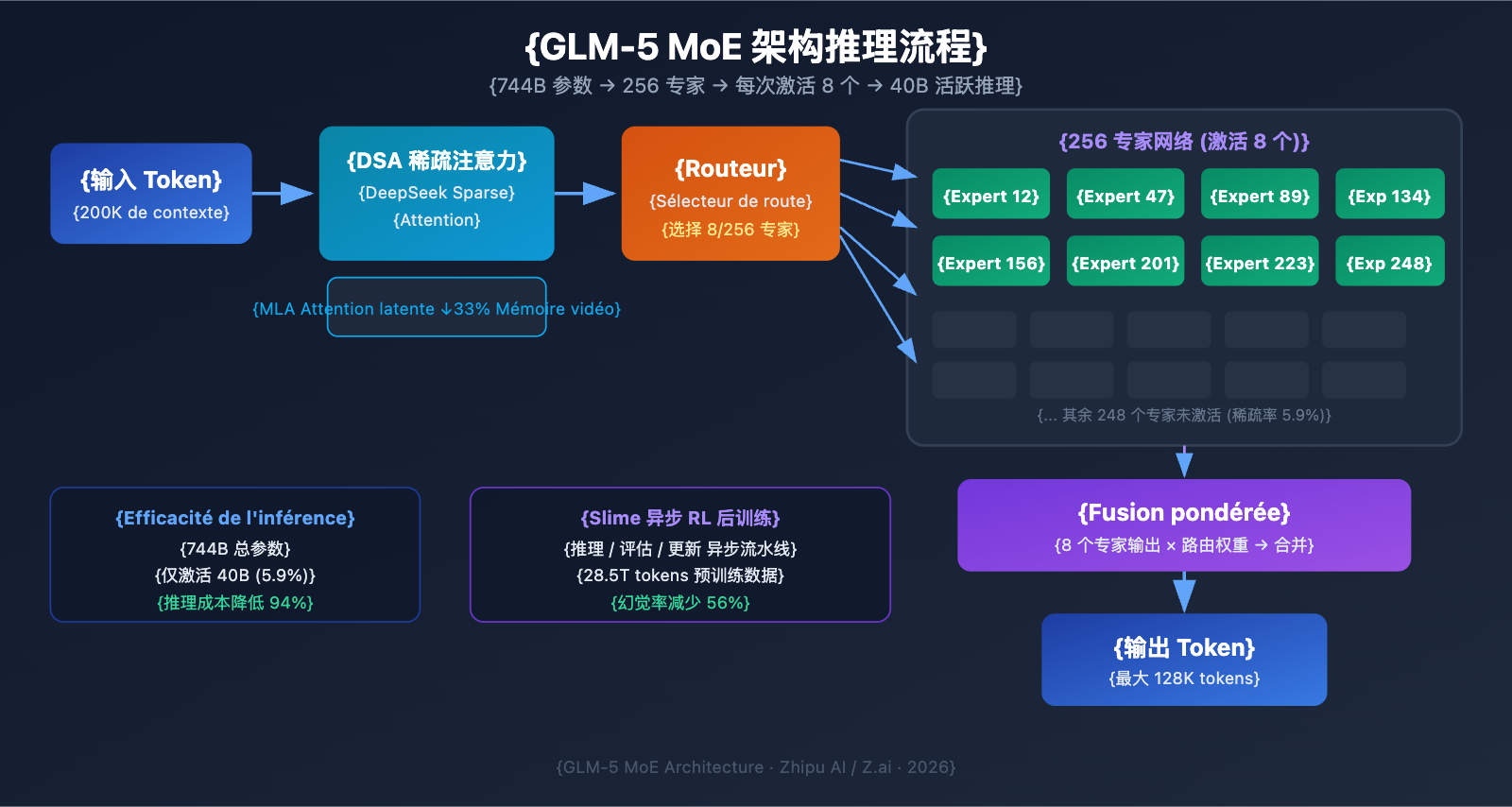
Le DeepSeek Sparse Attention (DSA) du GLM-5
Le GLM-5 intègre le mécanisme DeepSeek Sparse Attention, une technologie qui réduit considérablement les coûts de déploiement tout en maintenant des capacités de contexte long. Couplé au Multi-head Latent Attention (MLA), le GLM-5 fonctionne efficacement même avec une fenêtre de contexte ultra-longue de 200K tokens.
Plus précisément :
- DSA (DeepSeek Sparse Attention) : Réduit la complexité du calcul de l'attention via des motifs d'attention clairsemés (sparse). Alors que les mécanismes d'attention classiques deviennent extrêmement gourmands pour 200K tokens, le DSA se concentre sélectivement sur les positions clés des tokens pour réduire la charge de calcul sans perdre d'informations.
- MLA (Multi-head Latent Attention) : Compresse le cache KV (Key-Value) des têtes d'attention dans un espace latent, réduisant l'occupation de la mémoire d'environ 33 %. Dans les scénarios de contexte long, le cache KV est souvent le principal consommateur de VRAM ; le MLA lève efficacement ce goulot d'étranglement.
La combinaison de ces deux technologies signifie qu'un modèle de 744B, une fois quantifié en FP8, peut tourner sur seulement 8 GPU, abaissant ainsi drastiquement la barrière à l'entrée pour le déploiement.
Post-entraînement du GLM-5 : Le système RL asynchrone "Slime"
Le GLM-5 utilise une nouvelle infrastructure d'apprentissage par renforcement (RL) asynchrone nommée "Slime" pour son post-entraînement. L'entraînement RL traditionnel souffre de goulots d'étranglement : il y a beaucoup de temps d'attente entre les étapes de génération, d'évaluation et de mise à jour. Slime asynchronise ces étapes, permettant des itérations de post-entraînement plus fines et augmentant considérablement le débit d'entraînement.
Dans un flux RL classique, le modèle doit terminer un lot d'inférences, attendre les résultats d'évaluation, puis mettre à jour les paramètres, le tout en série. Slime découple ces trois étapes en pipelines asynchrones indépendants, permettant à l'inférence, l'évaluation et la mise à jour de se dérouler en parallèle.
Cette amélioration technique se reflète directement dans le taux d'hallucination du GLM-5, réduit de 56 % par rapport à la génération précédente. Des itérations de post-entraînement plus complètes permettent au modèle d'améliorer nettement la précision des faits.
Comparaison : GLM-5 vs Architecture Dense
Pour mieux comprendre les avantages de l'architecture MoE, comparons le GLM-5 à un modèle Dense hypothétique de taille équivalente :
| Dimension de comparaison | GLM-5 (744B MoE) | Dense 744B (hypothétique) | Différence réelle |
|---|---|---|---|
| Paramètres par inférence | 40B (5,9 %) | 744B (100 %) | Réduction de 94 % avec MoE |
| VRAM requise pour l'inférence | 8x GPU (FP8) | Env. 96x GPU | Nettement plus bas avec MoE |
| Vitesse d'inférence | Rapide | Très lente | MoE est plus adapté au déploiement réel |
| Capacité de connaissances | 744B de connaissances totales | 744B de connaissances totales | Équivalent |
| Capacité de spécialisation | Experts dédiés par tâche | Traitement uniforme | MoE est plus précis |
| Coût d'entraînement | Élevé mais maîtrisé | Extrêmement élevé | Meilleur rapport qualité-prix pour MoE |
L'avantage central de l'architecture MoE est qu'elle offre la capacité de connaissances d'un modèle de 744B avec l'efficacité de coût d'un modèle de 40B. C'est pourquoi le GLM-5 peut offrir des performances de pointe à un prix bien inférieur à celui des modèles propriétaires de même catégorie.
Prise en main rapide de l'API GLM-5
Détails des paramètres de requête de l'API GLM-5
Avant de commencer à coder, voici la configuration des paramètres de l'API GLM-5 :
| Paramètre | Type | Requis | Valeur par défaut | Description |
|---|---|---|---|---|
model |
string | ✅ | – | Fixé à "glm-5" |
messages |
array | ✅ | – | Messages au format chat standard |
max_tokens |
int | ❌ | 4096 | Nombre maximum de tokens en sortie (limite à 128K) |
temperature |
float | ❌ | 1.0 | Température d'échantillonnage, plus elle est basse, plus le résultat est déterministe |
top_p |
float | ❌ | 1.0 | Paramètre d'échantillonnage nucléaire (nucleus sampling) |
stream |
bool | ❌ | false | Si activé, utilise la sortie en flux (streaming) |
thinking |
object | ❌ | disabled | {"type": "enabled"} pour activer le raisonnement |
tools |
array | ❌ | – | Définition des outils pour le Function Calling |
tool_choice |
string | ❌ | auto | Stratégie de choix des outils |
Exemple d'appel minimaliste pour GLM-5
GLM-5 est compatible avec le format de l'interface du SDK OpenAI. Il suffit de modifier les paramètres base_url et model pour une intégration rapide :
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI unified interface
)
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "你是一位资深的 AI 技术专家"},
{"role": "user", "content": "解释 MoE 混合专家架构的工作原理和优势"}
],
temperature=0.7,
max_tokens=4096
)
print(response.choices[0].message.content)
Ce bloc de code représente la méthode d'appel la plus basique pour GLM-5. L'ID du modèle utilisé est glm-5, et l'interface est entièrement compatible avec le format chat.completions d'OpenAI. La migration de projets existants ne nécessite que la modification de deux paramètres.
Mode de raisonnement Thinking de GLM-5
GLM-5 prend en charge le mode de raisonnement Thinking, similaire aux capacités de réflexion étendue de DeepSeek R1 et Claude. Une fois activé, le modèle effectue un raisonnement interne par chaîne de pensée avant de répondre, ce qui améliore considérablement les performances sur les problèmes mathématiques complexes, la logique et la programmation :
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI unified interface
)
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "user", "content": "证明: 对于所有正整数 n, n^3 - n 能被 6 整除"}
],
extra_body={
"thinking": {"type": "enabled"}
},
temperature=1.0 # Thinking mode recommends 1.0
)
print(response.choices[0].message.content)
Conseils d'utilisation du mode Thinking de GLM-5 :
| Scénario | Activer Thinking | Température suggérée | Description |
|---|---|---|---|
| Preuves mathématiques / Concours | ✅ Oui | 1.0 | Nécessite un raisonnement approfondi |
| Débogage de code / Architecture | ✅ Oui | 1.0 | Nécessite une analyse système |
| Raisonnement logique / Analyse | ✅ Oui | 1.0 | Nécessite une réflexion en chaîne |
| Conversation quotidienne / Rédaction | ❌ Non | 0.5-0.7 | Pas besoin de raisonnement complexe |
| Extraction d'infos / Résumé | ❌ Non | 0.3-0.5 | Recherche d'une sortie stable |
| Génération de contenu créatif | ❌ Non | 0.8-1.0 | Nécessite de la diversité |
Sortie en flux (Streaming) avec GLM-5
Pour les scénarios nécessitant une interaction en temps réel, GLM-5 prend en charge la sortie en flux, permettant aux utilisateurs de voir les résultats s'afficher progressivement au fur et à mesure de la génération :
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
stream = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "user", "content": "用 Python 实现一个带缓存的 HTTP 客户端"}
],
stream=True,
temperature=0.6
)
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
GLM-5 Function Calling et construction d'Agents
GLM-5 prend nativement en charge le Function Calling (appel de fonctions), qui est la capacité centrale pour construire des systèmes d'Agents. GLM-5 a obtenu un score de 50,4 % sur HLE w/ Tools, surpassant Claude Opus (43,4 %), ce qui démontre son excellence dans l'appel d'outils et l'orchestration de tâches :
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "search_documents",
"description": "搜索知识库中的相关文档",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "搜索关键词"},
"top_k": {"type": "integer", "description": "返回结果数量", "default": 5}
},
"required": ["query"]
}
}
},
{
"type": "function",
"function": {
"name": "execute_code",
"description": "在沙箱环境中执行 Python 代码",
"parameters": {
"type": "object",
"properties": {
"code": {"type": "string", "description": "要执行的 Python 代码"},
"timeout": {"type": "integer", "description": "超时时间(秒)", "default": 30}
},
"required": ["code"]
}
}
}
]
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "你是一个能够搜索文档和执行代码的AI助手"},
{"role": "user", "content": "帮我查一下 GLM-5 的技术参数,然后用代码画一个性能对比图"}
],
tools=tools,
tool_choice="auto"
)
# 处理工具调用
message = response.choices[0].message
if message.tool_calls:
for tool_call in message.tool_calls:
print(f"调用工具: {tool_call.function.name}")
print(f"参数: {tool_call.function.arguments}")
Voir l’exemple d’appel cURL
curl https://api.apiyi.com/v1/chat/completions \
-H "Authorization: Bearer $API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "glm-5",
"messages": [
{"role": "system", "content": "你是一位资深软件工程师"},
{"role": "user", "content": "设计一个分布式任务调度系统的架构"}
],
"max_tokens": 8192,
"temperature": 0.7,
"stream": true
}'
🎯 Conseil technique : GLM-5 est compatible avec le format du SDK OpenAI. Pour migrer vos projets existants, il suffit de modifier les paramètres
base_urletmodel. En passant par la plateforme APIYI (apiyi.com), vous bénéficiez d'une gestion d'interface unifiée et de bonus lors de vos recharges.
Tests de performance Benchmark du GLM-5
Données clés des Benchmarks GLM-5
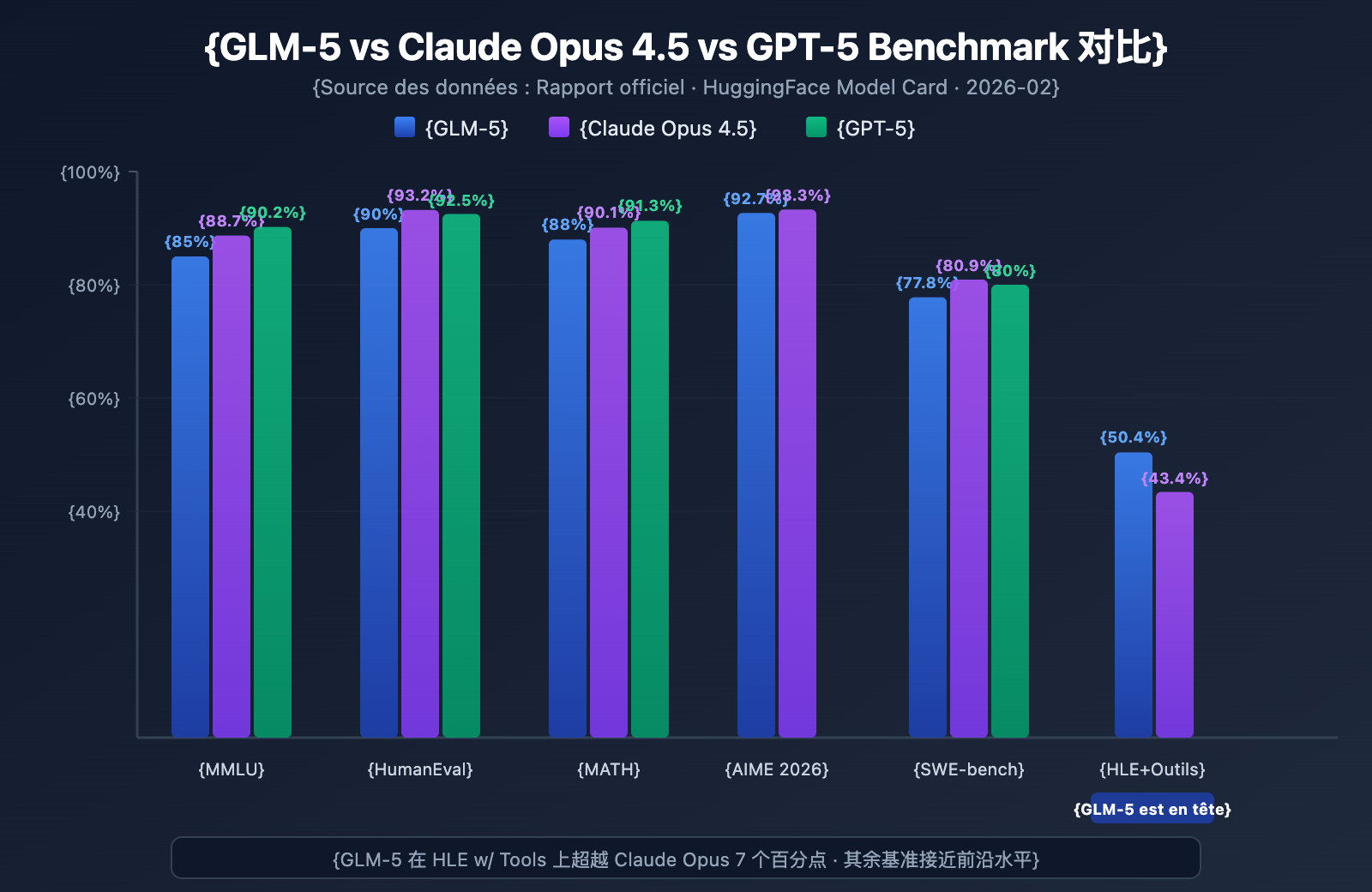
GLM-5 affiche les meilleurs niveaux parmi les modèles open-source sur plusieurs benchmarks majeurs :
| Benchmark | GLM-5 | Claude Opus 4.5 | GPT-5 | Contenu du test |
|---|---|---|---|---|
| MMLU | 85,0 % | 88,7 % | 90,2 % | Connaissances dans 57 disciplines |
| MMLU Pro | 70,4 % | – | – | Version améliorée pluridisciplinaire |
| GPQA | 68,2 % | 71,4 % | 73,1 % | Sciences de niveau universitaire |
| HumanEval | 90,0 % | 93,2 % | 92,5 % | Programmation Python |
| MATH | 88,0 % | 90,1 % | 91,3 % | Raisonnement mathématique |
| GSM8k | 97,0 % | 98,2 % | 98,5 % | Problèmes mathématiques appliqués |
| AIME 2026 I | 92,7 % | 93,3 % | – | Concours de mathématiques |
| SWE-bench | 77,8 % | 80,9 % | 80,0 % | Ingénierie logicielle réelle |
| HLE w/ Tools | 50,4 % | 43,4 % | – | Raisonnement avec outils |
| IFEval | 88,0 % | – | – | Suivi d'instructions |
| Terminal-Bench | 56,2 % | 57,9 % | – | Opérations en terminal |
Analyse des performances du GLM-5 : 4 avantages clés
Les données des benchmarks révèlent plusieurs points dignes d'intérêt :
1. Capacités d'Agent du GLM-5 : HLE w/ Tools surpasse les modèles propriétaires
Sur le Humanity's Last Exam (avec utilisation d'outils), GLM-5 a obtenu un score de 50,4 %, dépassant les 43,4 % de Claude Opus et se plaçant juste derrière les 51,8 % de Kimi K2.5. Cela démontre que GLM-5 a atteint le niveau des modèles de pointe dans les scénarios d'Agents — des tâches complexes nécessitant planification, appel d'outils et résolution itérative.
Ce résultat est cohérent avec la philosophie de conception de GLM-5 : de son architecture à son post-entraînement, il a été spécifiquement optimisé pour les flux de travail des Agents. Pour les développeurs souhaitant construire des systèmes d'Agents IA, GLM-5 offre une option open-source performante et économique.
2. Capacités de codage du GLM-5 : Dans le peloton de tête
Avec 90 % sur HumanEval et 77,8 % sur SWE-bench Verified, GLM-5 est très proche des niveaux de Claude Opus (80,9 %) et GPT-5 (80,0 %) pour la génération de code et les tâches réelles d'ingénierie logicielle. Pour un modèle open-source, atteindre 77,8 % sur SWE-bench est une avancée majeure : cela signifie que GLM-5 est capable de comprendre de réels tickets GitHub, de localiser les problèmes de code et de soumettre des correctifs valides.
3. Raisonnement mathématique du GLM-5 : Proche du plafond de verre
Sur AIME 2026 I, GLM-5 a atteint 92,7 %, n'étant devancé par Claude Opus que de 0,6 point de pourcentage. Son score de 97 % sur GSM8k prouve également que GLM-5 est extrêmement fiable sur des problèmes mathématiques de difficulté moyenne. Son résultat de 88 % sur MATH le place également dans le premier rang mondial.
4. Contrôle des hallucinations du GLM-5 : Réduction massive
Selon les données officielles, le taux d'hallucination de GLM-5 a diminué de 56 % par rapport à la génération précédente. Cela est dû aux itérations de post-entraînement plus poussées permises par le système Slime d'apprentissage par renforcement (RL) asynchrone. Dans les scénarios exigeant une grande précision, comme l'extraction d'informations, le résumé de documents et les questions-réponses sur base de connaissances, ce taux d'hallucination réduit se traduit directement par une sortie plus fiable.
Positionnement du GLM-5 face aux modèles open-source équivalents
Dans le paysage actuel de la concurrence des grands modèles de langage open-source, le positionnement de GLM-5 est clair :
| Modèle | Taille des paramètres | Architecture | Atout principal | Licence |
|---|---|---|---|---|
| GLM-5 | 744B (40B actifs) | MoE | Agent + Faibles hallucinations | Apache-2.0 |
| DeepSeek V3 | 671B (37B actifs) | MoE | Rapport qualité-prix + Raisonnement | MIT |
| Llama 4 Maverick | 400B (17B actifs) | MoE | Multimodalité + Écosystème | Llama License |
| Qwen 3 | 235B | Dense | Multilingue + Outils | Apache-2.0 |
L'avantage différenciateur de GLM-5 réside principalement dans trois domaines : l'optimisation spécifique des flux de travail d'Agents (leader sur HLE w/ Tools), un taux d'hallucination extrêmement bas (réduction de 56 %), et la sécurité de la chaîne d'approvisionnement garantie par un entraînement sur une puissance de calcul entièrement souveraine. Pour les entreprises ayant besoin de déployer des modèles open-source de pointe, GLM-5 est une option qui mérite une attention particulière.
Analyse des tarifs et des coûts de GLM-5
Tarification officielle de GLM-5
| Type de facturation | Prix officiel Z.ai | Prix OpenRouter | Description |
|---|---|---|---|
| Token d'entrée | 1,00$ / M | 0,80$ / M | Par million de tokens d'entrée |
| Token de sortie | 3,20$ / M | 2,56$ / M | Par million de tokens de sortie |
| Entrée en cache | 0,20$ / M | 0,16$ / M | Prix d'entrée lors d'un hit de cache |
| Stockage du cache | Temporairement gratuit | – | Frais de stockage des données en cache |
Comparaison des prix : GLM-5 vs Concurrents
La stratégie tarifaire de GLM-5 est très compétitive, surtout par rapport aux modèles propriétaires de pointe :
| Modèle | Entrée ($/M) | Sortie ($/M) | Coût relatif / GLM-5 | Positionnement |
|---|---|---|---|---|
| GLM-5 | 1,00$ | 3,20$ | Référence | Flagship open-source |
| Claude Opus 4.6 | 5,00$ | 25,00$ | Env. 5-8x | Flagship propriétaire |
| GPT-5 | 1,25$ | 10,00$ | Env. 1,3-3x | Flagship propriétaire |
| DeepSeek V3 | 0,27$ | 1,10$ | Env. 0,3x | Rapport Q/P open-source |
| GLM-4.7 | 0,60$ | 2,20$ | Env. 0,6-0,7x | Flagship génération précédente |
| GLM-4.7-FlashX | 0,07$ | 0,40$ | Env. 0,07-0,13x | Coût ultra-faible |
Côté prix, GLM-5 se positionne entre GPT-5 et DeepSeek V3 : bien moins cher que la plupart des modèles propriétaires de pointe, mais légèrement plus onéreux que les modèles open-source légers. Compte tenu de sa taille de 744 milliards de paramètres et de ses performances au sommet de l'open-source, ce tarif est tout à fait justifié.
Gamme complète de produits GLM et tarification
Si GLM-5 ne correspond pas exactement à votre besoin, Zhipu propose une gamme complète d'alternatives :
| Modèle | Entrée ($/M) | Sortie ($/M) | Cas d'utilisation |
|---|---|---|---|
| GLM-5 | 1,00$ | 3,20$ | Raisonnement complexe, Agents, documents longs |
| GLM-5-Code | 1,20$ | 5,00$ | Dédié au développement de code |
| GLM-4.7 | 0,60$ | 2,20$ | Tâches générales de complexité moyenne |
| GLM-4.7-FlashX | 0,07$ | 0,40$ | Appels haute fréquence à bas coût |
| GLM-4.5-Air | 0,20$ | 1,10$ | Équilibre et légèreté |
| GLM-4.7/4.5-Flash | Gratuit | Gratuit | Initiation et tâches simples |
💰 Optimisation des coûts : GLM-5 est déjà disponible sur APIYI (apiyi.com) avec des tarifs identiques à ceux de Z.ai. Grâce aux bonus de recharge de la plateforme, le coût d'utilisation réel peut être réduit d'environ 20% par rapport au prix officiel, ce qui est idéal pour les équipes et développeurs ayant des besoins récurrents.
Cas d'utilisation et conseils de sélection pour GLM-5
Dans quels cas choisir GLM-5 ?
D'après les caractéristiques techniques et les résultats aux benchmarks, voici les scénarios recommandés :
Scénarios vivement recommandés :
- Workflows d'Agents : GLM-5 est conçu pour les tâches d'Agents à cycle long. Avec un score de 50,4% sur HLE w/ Tools (dépassant Claude Opus), il est parfait pour bâtir des systèmes d'Agents capables de planification autonome et d'appels d'outils.
- Ingénierie logicielle : Avec 90% sur HumanEval et 77,8% sur SWE-bench, il excelle dans la génération de code, la correction de bugs, la revue de code et la conception d'architecture.
- Raisonnement mathématique et scientifique : Ses scores (AIME 92,7%, MATH 88%) le rendent apte aux démonstrations mathématiques, aux calculs de formules et à l'informatique scientifique.
- Analyse de documents ultra-longs : Sa fenêtre de contexte de 200K permet de traiter des bases de code entières, des documentations techniques ou des contrats juridiques complexes.
- Réponses à faible hallucination : Avec une réduction du taux d'hallucination de 56%, il est idéal pour le QA sur base de connaissances et les résumés de documents exigeant une grande précision.
Scénarios où d'autres solutions peuvent être préférables :
- Tâches multimodales : GLM-5 est purement textuel. Pour la compréhension d'images, tournez-vous vers des modèles de vision comme GLM-4.6V.
- Latence ultra-faible : Un modèle MoE de 744B n'est pas aussi rapide qu'un petit modèle. Pour de la haute fréquence à faible latence, préférez GLM-4.7-FlashX.
- Traitement par lots à très bas coût : Pour traiter d'énormes volumes de texte sans exigence de qualité extrême, DeepSeek V3 ou GLM-4.7-FlashX seront plus économiques.
Comparaison : GLM-5 vs GLM-4.7
| Dimension de comparaison | GLM-5 | GLM-4.7 | Conseil de sélection |
|---|---|---|---|
| Taille des paramètres | 744B (40B actifs) | Non publiée | GLM-5 est plus massif |
| Capacité de raisonnement | AIME 92,7% | ~85% | Raisonnement complexe : GLM-5 |
| Capacités d'Agent | HLE w/ Tools 50,4% | ~38% | Tâches d'Agent : GLM-5 |
| Capacité de codage | HumanEval 90% | ~85% | Développement : GLM-5 |
| Contrôle des hallucinations | Réduction de 56% | Référence | Haute précision : GLM-5 |
| Prix d'entrée | 1,00$ / M | 0,60$ / M | Sensible au coût : GLM-4.7 |
| Prix de sortie | 3,20$ / M | 2,20$ / M | Sensible au coût : GLM-4.7 |
| Longueur du contexte | 200K | 128K+ | Documents longs : GLM-5 |
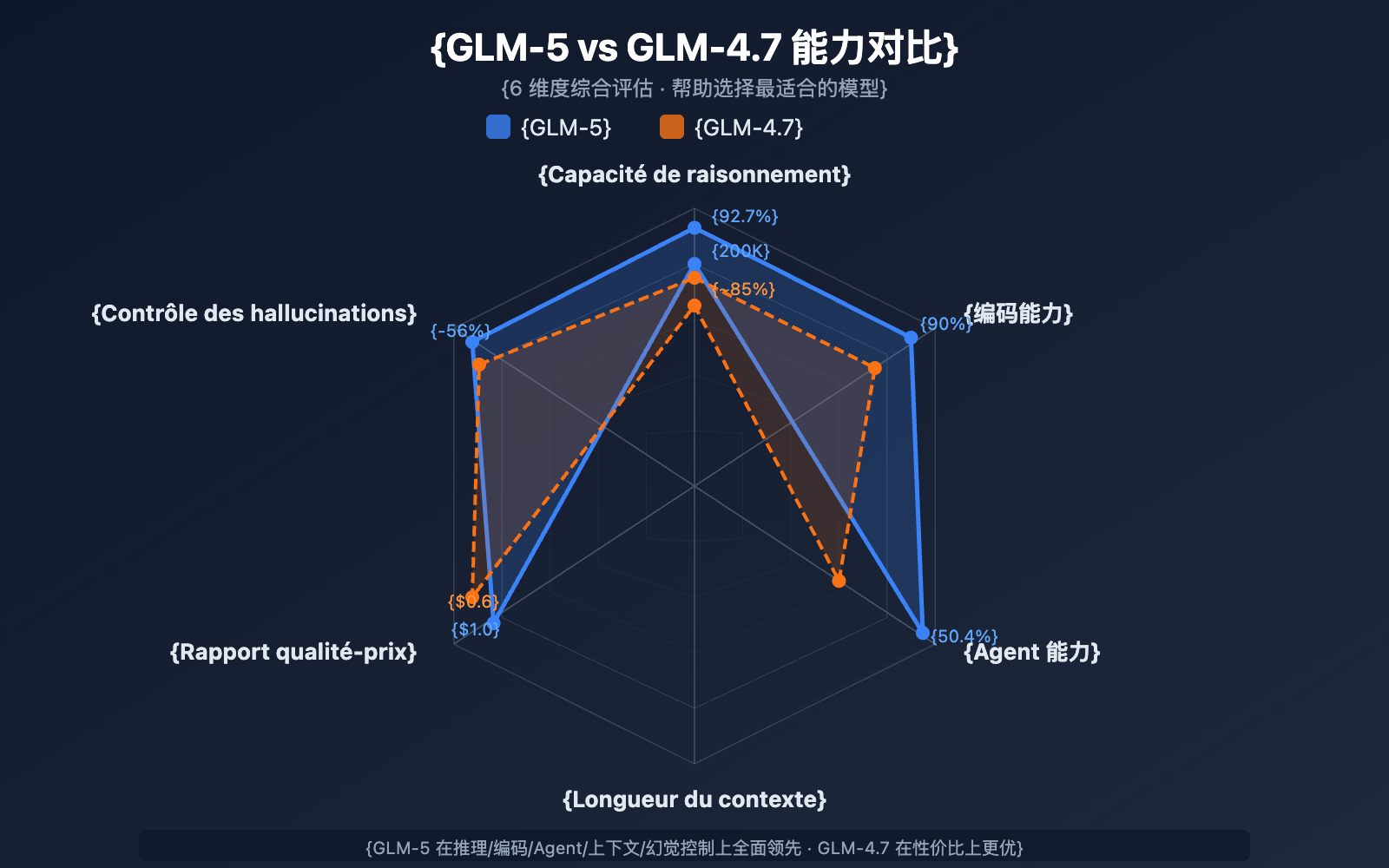
💡 Conseil de sélection : Si votre projet nécessite des capacités de raisonnement de haut niveau, des workflows d'Agents ou le traitement de contextes ultra-longs, GLM-5 est le meilleur choix. Si votre budget est limité et que la complexité des tâches est modérée, GLM-4.7 reste une excellente option en termes de rapport qualité/prix. Les deux modèles peuvent être appelés via la plateforme APIYI (apiyi.com), ce qui permet de basculer facilement de l'un à l'autre pour vos tests.
FAQ sur l'appel de l'API GLM-5
Q1 : Quelle est la différence entre GLM-5 et GLM-5-Code ?
GLM-5 est le modèle phare polyvalent (entrée 1,00 $/M, sortie 3,20 $/M), idéal pour tous types de tâches textuelles. GLM-5-Code est une version optimisée spécifiquement pour le code (entrée 1,20 $/M, sortie 5,00 $/M), avec des performances accrues pour la génération de code, le débogage et les tâches d'ingénierie. Si votre cas d'utilisation principal est le développement logiciel, GLM-5-Code vaut le détour. Les deux modèles peuvent être appelés via une interface unifiée compatible avec OpenAI.
Q2 : Le mode Thinking de GLM-5 affecte-t-il la vitesse de sortie ?
Oui. En mode Thinking, GLM-5 génère d'abord une chaîne de raisonnement interne avant de fournir la réponse finale, ce qui augmente la latence du premier token (TTFT). Pour des questions simples, il est conseillé de désactiver le mode Thinking pour obtenir une réponse plus rapide. Pour les problèmes complexes de mathématiques, de programmation ou de logique, il est recommandé de l'activer : bien que plus lent, le taux de précision sera nettement plus élevé.
Q3 : Quelles modifications de code sont nécessaires pour passer de GPT-4 ou Claude à GLM-5 ?
La migration est très simple, il suffit de modifier deux paramètres :
- Changez l'URL de base (
base_url) pour l'adresse de l'interface APIYI :https://api.apiyi.com/v1 - Changez le paramètre
modelpour"glm-5"
GLM-5 est entièrement compatible avec le format d'interface chat.completions du SDK OpenAI, incluant les rôles system/user/assistant, le streaming, le Function Calling, etc. Passer par une plateforme intermédiaire d'API unifiée permet également de basculer entre les modèles de différents fournisseurs avec la même clé API, ce qui est très pratique pour les tests A/B.
Q4 : GLM-5 supporte-t-il l’entrée d’images ?
Non. GLM-5 est un grand modèle de langage purement textuel et ne supporte pas les entrées d'images, d'audio ou de vidéo. Si vous avez besoin de capacités de compréhension d'image, vous pouvez utiliser les variantes visuelles de Zhipu comme GLM-4.6V ou GLM-4.5V.
Q5 : Comment utiliser la fonction de mise en cache du contexte de GLM-5 ?
GLM-5 supporte la mise en cache du contexte (Context Caching). Le prix de l'entrée mise en cache n'est que de 0,20 $/M, soit 1/5 du prix d'une entrée normale. Dans les conversations longues ou les scénarios nécessitant le traitement répété du même préfixe, la mise en cache peut réduire considérablement les coûts. Le stockage du cache est actuellement gratuit. Dans les dialogues multi-tours, le système identifie et met en cache automatiquement les préfixes de contexte redondants.
Q6 : Quelle est la longueur de sortie maximale de GLM-5 ?
GLM-5 supporte une longueur de sortie allant jusqu'à 128 000 tokens. Pour la plupart des scénarios, la valeur par défaut de 4096 tokens est suffisante. Si vous devez générer des textes longs (comme une documentation technique complète ou de longs blocs de code), vous pouvez ajuster ce paramètre via max_tokens. Notez que plus la sortie est longue, plus la consommation de tokens et le temps d'attente augmenteront proportionnellement.
Meilleures pratiques pour l'appel de l'API GLM-5
Lors de l'utilisation réelle de GLM-5, ces quelques conseils pratiques peuvent vous aider à obtenir de meilleurs résultats :
Optimisation du Prompt Système (System Prompt) GLM-5
GLM-5 répond très bien aux invites système. Concevoir une invite système pertinente peut améliorer considérablement la qualité de la sortie :
# Recommandé : Définition claire du rôle + exigences de format de sortie
messages = [
{
"role": "system",
"content": """Vous êtes un architecte de systèmes distribués expérimenté.
Veuillez suivre ces règles :
1. La réponse doit être structurée, utilisez le format Markdown.
2. Proposez des solutions techniques concrètes plutôt que des généralités.
3. Si du code est impliqué, fournissez un exemple prêt à l'emploi.
4. Indiquez les risques potentiels et les points de vigilance aux endroits appropriés."""
},
{
"role": "user",
"content": "Concevoir un système de file d'attente de messages supportant des millions de connexions simultanées."
}
]
Guide de réglage de la température (temperature) pour GLM-5
La sensibilité à la température varie selon les tâches. Voici nos recommandations basées sur des tests réels :
- temperature 0.1-0.3 : Génération de code, extraction de données, conversion de format et autres tâches nécessitant une sortie précise.
- temperature 0.5-0.7 : Documentation technique, questions-réponses, résumés et tâches nécessitant de la stabilité avec une certaine flexibilité d'expression.
- temperature 0.8-1.0 : Écriture créative, brainstorming et tâches nécessitant de la diversité.
- temperature 1.0 (Mode Thinking) : Raisonnement mathématique, programmation complexe et autres tâches de raisonnement approfondi.
Astuces pour gérer les contextes longs avec GLM-5
GLM-5 supporte une fenêtre de contexte de 200K tokens, mais il faut faire attention aux points suivants lors de l'utilisation :
- Priorité aux informations importantes : Placez les éléments de contexte les plus critiques au début de l'invite, et non à la fin.
- Traitement par segments : Pour les documents dépassant 100K tokens, il est conseillé de les traiter par segments puis de fusionner les résultats pour obtenir une sortie plus stable.
- Exploiter le cache : Dans les dialogues multi-tours, le contenu identique du préfixe est automatiquement mis en cache, avec un prix d'entrée de seulement 0,20 $/M.
- Contrôler la longueur de sortie : Lors d'entrées avec un long contexte, réglez
max_tokensde manière appropriée pour éviter des sorties trop longues qui augmenteraient inutilement les coûts.
Référence pour le déploiement local de GLM-5
Si vous avez besoin de déployer GLM-5 sur votre propre infrastructure, voici les principales méthodes de déploiement :
| Méthode de déploiement | Matériel recommandé | Précision | Caractéristiques |
|---|---|---|---|
| vLLM | 8x A100/H100 | FP8 | Framework d'inférence grand public, supporte le décodage spéculatif |
| SGLang | 8x H100/B200 | FP8 | Inférence haute performance, optimisé pour les GPU Blackwell |
| xLLM | Huawei Ascend NPU | BF16/FP8 | Adaptation pour la puissance de calcul domestique (Chine) |
| KTransformers | GPU grand public | Quantification | Inférence accélérée par GPU |
| Ollama | Matériel grand public | Quantification | L'expérience locale la plus simple |
GLM-5 propose deux formats de poids : BF16 (pleine précision) et FP8 (quantifié). Ils peuvent être téléchargés depuis HuggingFace (huggingface.co/zai-org/GLM-5) ou ModelScope. La version quantifiée en FP8 réduit considérablement les besoins en mémoire vidéo (VRAM) tout en conservant la majeure partie des performances.
Configurations clés pour le déploiement de GLM-5 :
- Parallélisme de tenseurs (Tensor Parallel) : 8 voies (tensor-parallel-size 8)
- Utilisation de la VRAM : conseillé à 0.85
- Analyseur d'appels d'outils (Tool call parser) : glm47
- Analyseur d'inférence : glm45
- Décodage spéculatif : supporte les méthodes MTP et EAGLE
Pour la plupart des développeurs, l'appel via API est la méthode la plus efficace. Elle évite les coûts de déploiement et de maintenance, vous permettant de vous concentrer uniquement sur le développement de l'application. Pour les scénarios nécessitant un déploiement privé, vous pouvez consulter la documentation officielle :
github.com/zai-org/GLM-5
Résumé des appels API GLM-5
Aperçu des capacités clés de GLM-5
| Dimension de capacité | Performance GLM-5 | Scénarios d'application |
|---|---|---|
| Raisonnement | AIME 92.7%, MATH 88% | Preuves mathématiques, raisonnement scientifique, analyse logique |
| Codage | HumanEval 90%, SWE-bench 77.8% | Génération de code, correction de bugs, conception d'architecture |
| Agent | HLE w/ Tools 50.4% | Appels d'outils, planification de tâches, exécution autonome |
| Connaissances | MMLU 85%, GPQA 68.2% | Questions-réponses académiques, conseil technique, extraction de connaissances |
| Instructions | IFEval 88% | Sortie formatée, génération structurée, respect des règles |
| Précision | Hallucinations réduites de 56% | Résumé de documents, vérification des faits, extraction d'informations |
Valeur de l'écosystème open source de GLM-5
GLM-5 est publié sous licence Apache-2.0, ce qui signifie :
- Liberté commerciale : Les entreprises peuvent l'utiliser, le modifier et le distribuer gratuitement sans frais de licence.
- Personnalisation par fine-tuning : Il est possible d'effectuer un réglage fin (fine-tuning) spécifique à un domaine pour construire des modèles métiers dédiés.
- Déploiement privé : Les données sensibles ne quittent pas le réseau interne, répondant aux exigences de conformité des secteurs de la finance, de la santé ou du gouvernement.
- Écosystème communautaire : Plus de 11 variantes quantifiées et 7 versions fine-tunées sont déjà disponibles sur HuggingFace, et l'écosystème continue de s'étendre.
En tant que dernier modèle phare de Zhipu AI, GLM-5 pose de nouveaux jalons dans le domaine des grands modèles de langage open source :
- Architecture MoE de 744B : Système à 256 experts, activant 40B de paramètres par inférence, offrant un excellent équilibre entre capacité du modèle et efficacité d'inférence.
- L'Agent open source le plus puissant : Avec 50.4% sur HLE w/ Tools, il dépasse Claude Opus, conçu spécifiquement pour les workflows d'agents à cycle long.
- Entraînement sur puissance de calcul 100% chinoise : Entraîné sur 100 000 puces Huawei Ascend, prouvant la capacité des infrastructures de calcul domestiques pour l'entraînement de modèles de pointe.
- Excellent rapport qualité-prix : 1 $/M en entrée, 3,2 $/M en sortie, des tarifs bien inférieurs aux modèles propriétaires de même niveau. La communauté peut le déployer et le fine-tuner librement.
- Contexte ultra-long de 200K : Supporte le traitement en une seule fois de bases de code complètes et de documents techniques volumineux, avec une sortie maximale de 128K tokens.
- Faible taux d'hallucination (-56%) : Le post-entraînement par RL asynchrone (Slime) a considérablement amélioré l'exactitude des faits.
Nous vous recommandons d'utiliser APIYI (apiyi.com) pour tester rapidement les différentes capacités de GLM-5. Les tarifs de la plateforme sont identiques aux tarifs officiels, et les promotions sur les recharges permettent de bénéficier d'une réduction d'environ 20 %.
Cet article a été rédigé par l'équipe technique d'APIYI. Pour plus de tutoriels sur l'utilisation des modèles d'IA, n'hésitez pas à consulter le centre d'aide d'APIYI (apiyi.com).