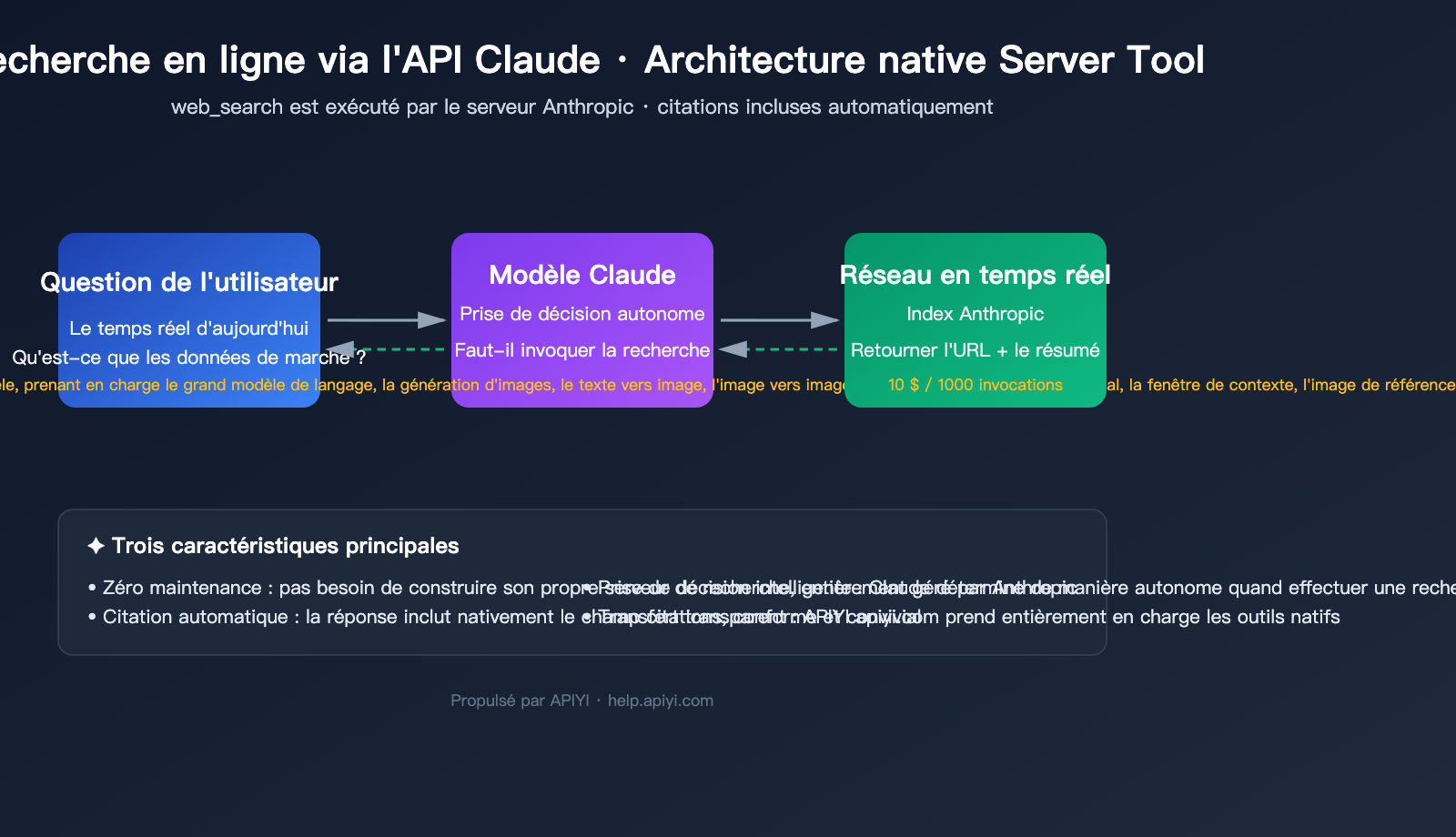
Les connaissances des modèles ont une date limite, alors que les problèmes métier réels exigent souvent des données "en temps réel". En 2025, Claude a lancé officiellement l'outil natif web_search, puis l'a mis à jour en 2026 vers la version web_search_20260209 prenant en charge le filtrage dynamique. Désormais, connecter l'API Claude à Internet ne demande plus de bricolage complexe, mais simplement une ligne de paramètres.
Cet article propose une analyse systématique des dernières solutions d'invocation du modèle Claude avec recherche en ligne en 2026. Nous détaillerons les paramètres, la facturation, les limitations et les modèles de code pour les outils officiels web_search / web_fetch, tout en comparant les approches via MCP tiers et RAG auto-hébergé. À la fin, nous fournissons un exemple d'intégration via le service proxy API APIYI (apiyi.com) : il suffit de remplacer base_url et api_key pour exécuter l'ensemble du processus depuis votre environnement local.
Points clés de l'invocation du modèle Claude avec recherche en ligne
Avant de coder, clarifions les concepts. L'invocation du modèle Claude avec recherche en ligne est essentiellement un outil côté serveur (Server Tool) fourni par Anthropic. Cela signifie que la recherche est effectuée par Anthropic dans le cloud ; vous n'avez pas besoin d'intégrer l'API Google/Bing ni de déployer des robots d'indexation.
Aperçu des trois solutions principales
| Solution | Complexité d'intégration | Coût | Temps réel | Citations et conformité |
|---|---|---|---|---|
web_search natif officiel |
★☆☆ (un champ tool) | 10 $ / 1000 requêtes + jetons | Élevé (indexation en temps réel par Anthropic) | Citations automatiques |
| MCP tiers (ex: Brave/Tavily) | ★★☆ (nécessite un serveur MCP) | Facturation API de recherche tierce | Moyen à élevé | À gérer soi-même |
| Auto-hébergé (Google CSE + appel d'outil) | ★★★ (outil personnalisé + parsing) | Quota API Google | Moyen | Entièrement géré |
🎯 Conseil de sélection : Si votre objectif principal est de "permettre à Claude de répondre sur des événements récents et d'ajouter des données en temps réel", l'outil natif
web_searchest la meilleure solution actuelle : aucune maintenance, conformité des citations, et prise en charge des modèles principaux comme Sonnet 4.6 / Opus 4.7. Nous recommandons de passer par le service proxy API APIYI (apiyi.com) pour accéder à toutes les capacités de l'interface officielle d'Anthropic sans avoir besoin de VPN.
Matrice des modèles prenant en charge la recherche en ligne
Tous les modèles Claude ne prennent pas en charge web_search. La nouvelle version web_search_20260209 impose des exigences spécifiques :
| Modèle | Version de base web_search_20250305 |
Version avec filtrage dynamique web_search_20260209 |
|---|---|---|
| Claude Opus 4.7 | ✅ | ✅ |
| Claude Opus 4.6 | ✅ | ✅ |
| Claude Sonnet 4.6 | ✅ | ✅ |
| Claude Sonnet 4.5 | ✅ | ❌ |
| Claude Haiku 4.5 | ✅ | ❌ |
Le filtrage dynamique (Dynamic Filtering) est l'amélioration majeure de la version 2026 : avant d'intégrer les résultats de recherche dans la fenêtre de contexte, Claude utilise un outil d'exécution de code pour filtrer les informations, ne conservant que les segments pertinents. Pour la recherche dans de longs documents ou la synthèse de littérature technique, cela permet de réduire considérablement la consommation de jetons.
Guide détaillé des outils natifs de recherche en ligne pour l'API Claude
Anthropic propose deux outils natifs complémentaires. Comprendre leurs limites est essentiel pour tirer le meilleur parti de la recherche en ligne via l'API Claude.
Répartition des tâches entre web_search et web_fetch
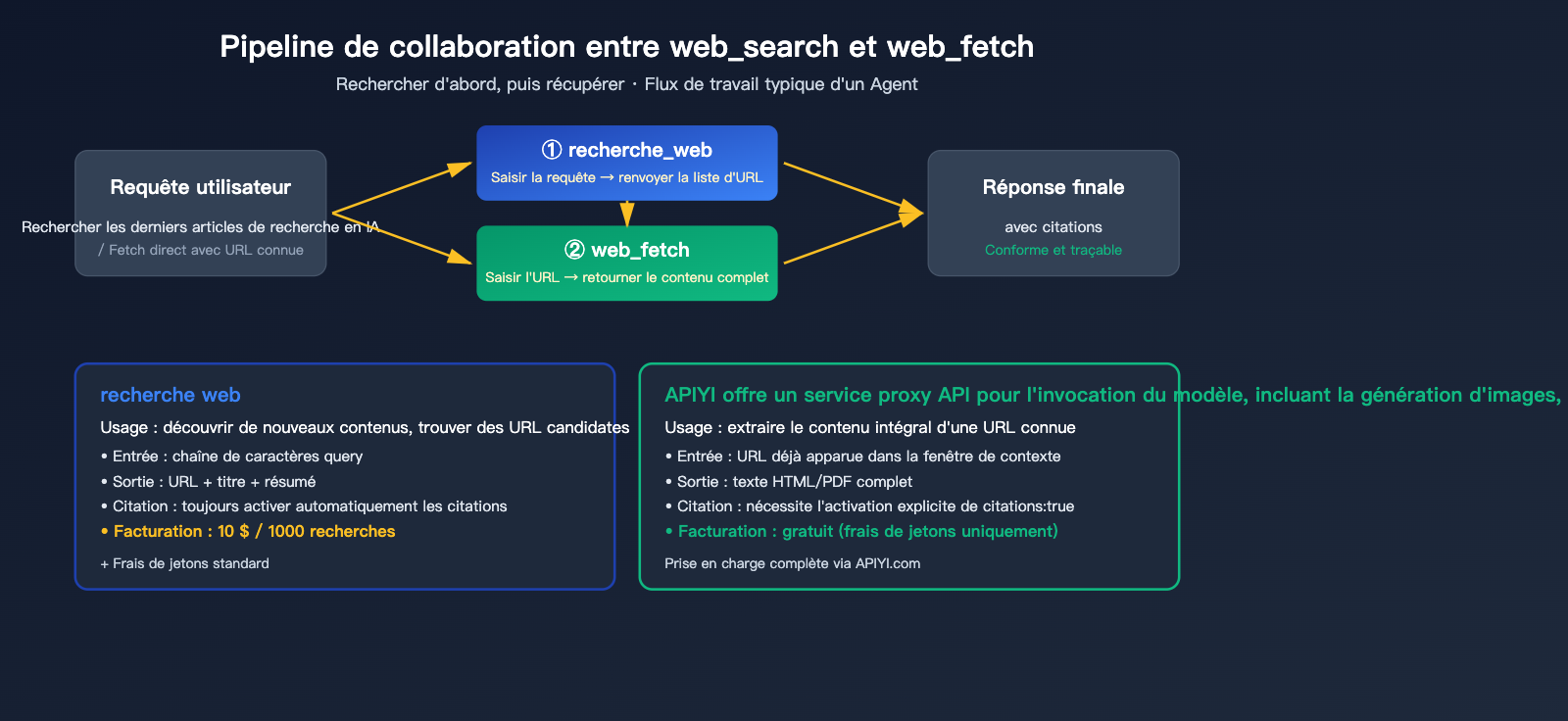
| Outil | Usage | Entrée | Sortie | Facturation |
|---|---|---|---|---|
web_search |
Découvrir du contenu | Chaîne de requête | URL + Titre + Résumé | 10 $ / 1000 appels |
web_fetch |
Extraire le texte complet | Chaîne URL | HTML complet / Texte PDF | Gratuit (selon les tokens) |
🎯 Conseil d'architecture : Le flux de travail classique d'un agent est « d'abord search, puis fetch » :
web_searchidentifie les pages candidates, etweb_fetchrécupère le contenu complet des plus pertinentes. Si l'utilisateur a déjà fourni une URL (ex: "analyse cet article sur example.com"), utilisez directementweb_fetchpour économiser vos quotas de recherche. Sur APIYI (apiyi.com), ces deux outils sont supportés de manière transparente, sans configuration supplémentaire.
Définition complète des paramètres de web_search
Le tableau ci-dessous détaille les paramètres JSON officiels :
| Paramètre | Type | Requis | Défaut | Description |
|---|---|---|---|---|
type |
string | ✅ | – | Fixé à web_search_20250305 ou web_search_20260209 |
name |
string | ✅ | – | Fixé à web_search |
max_uses |
integer | ❌ | Illimité | Nombre max de recherches par requête |
allowed_domains |
string[] | ❌ | – | Domaines autorisés uniquement |
blocked_domains |
string[] | ❌ | – | Domaines exclus |
user_location |
object | ❌ | – | Localisation pour une recherche locale |
Structure de user_location :
{
"type": "approximate",
"city": "Paris",
"region": "Île-de-France",
"country": "FR",
"timezone": "Europe/Paris"
}
Gestion des erreurs
En cas d'échec, l'API Anthropic retourne toujours un code HTTP 200, les détails de l'erreur étant intégrés dans web_search_tool_result. Pensez à vérifier ces codes dans votre code client :
| Code erreur | Signification | Conseil |
|---|---|---|
too_many_requests |
Limite de débit atteinte | Réessayer avec backoff, réduire la concurrence |
max_uses_exceeded |
Limite max_uses dépassée |
Augmenter la limite ou diviser la requête |
query_too_long |
Requête trop longue | Tronquer ou réécrire la requête |
invalid_input |
Format invalide | Vérifier la structure JSON |
unavailable |
Erreur interne Anthropic | Réessayer après un court délai |
⚠️ Note de facturation : Les requêtes
web_searchen erreur ne sont pas facturées. Cependant, si vous avez déjà effectué une recherche réussie avant l'erreur, celle-ci sera facturée (10 $ / 1000 appels). Consultez le tableau de bord APIYI (apiyi.com) pour suivre vos consommations détaillées.
Démarrage rapide
Voici comment mettre en place le flux complet avec un minimum de code. Tous les exemples utilisent le service proxy API d'APIYI (apiyi.com) : il suffit de pointer votre base_url vers le nœud de transfert et de remplacer votre ANTHROPIC_API_KEY par votre clé APIYI.
Exemple cURL minimal
curl https://vip.apiyi.com/v1/messages \
-H "x-api-key: $APIYI_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "content-type: application/json" \
-d '{
"model": "claude-sonnet-4-6",
"max_tokens": 1024,
"messages": [
{"role": "user", "content": "Résume les derniers modèles publiés par OpenAI en avril 2026"}
],
"tools": [{
"type": "web_search_20250305",
"name": "web_search",
"max_uses": 5
}]
}'
Exemple complet avec SDK Python (incluant web_fetch)
import anthropic
client = anthropic.Anthropic(
base_url="https://vip.apiyi.com",
api_key="sk-votre-cle-apiyi",
)
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=4096,
messages=[{
"role": "user",
"content": "Trouve les articles récents sur l'évaluation des agents IA et résume le plus pertinent."
}],
tools=[
{
"type": "web_search_20260209",
"name": "web_search"
},
{
"type": "web_fetch_20260209",
"name": "web_fetch",
"max_uses": 3,
"citations": {"enabled": True}
}
]
)
for block in response.content:
if block.type == "text":
print(block.text)
elif block.type == "server_tool_use":
print(f"[Appel outil] {block.name}: {block.input}")
Exemple TypeScript / Node.js
import Anthropic from "@anthropic-ai/sdk";
const client = new Anthropic({
baseURL: "https://vip.apiyi.com",
apiKey: process.env.APIYI_API_KEY,
});
const response = await client.messages.create({
model: "claude-sonnet-4-6",
max_tokens: 2048,
messages: [
{ role: "user", content: "Quel temps fait-il à Paris aujourd'hui ?" }
],
tools: [{
type: "web_search_20250305",
name: "web_search",
max_uses: 3,
user_location: {
type: "approximate",
city: "Paris",
region: "Île-de-France",
country: "FR",
timezone: "Europe/Paris"
}
}]
});
Gestion du streaming
Avec stream: true, le processus de recherche est poussé en temps réel via SSE. Une courte "pause" peut survenir pendant que Claude attend les résultats de la recherche :
with client.messages.stream(
model="claude-sonnet-4-6",
max_tokens=2048,
messages=[{"role": "user", "content": "Prix de Claude 4.7"}],
tools=[{"type": "web_search_20250305", "name": "web_search", "max_uses": 2}]
) as stream:
for event in stream:
if event.type == "content_block_start":
block = event.content_block
if block.type == "server_tool_use":
print(f"\n[Recherche en cours]...")
elif block.type == "web_search_tool_result":
print(f"[Recherche terminée] {len(block.content)} résultats")
elif event.type == "content_block_delta":
if hasattr(event.delta, "text"):
print(event.delta.text, end="", flush=True)
Comparaison et sélection des solutions de recherche web pour l'API Claude
Maintenant que nous avons exploré les interfaces officielles, passons à la prise de décision. Il existe concrètement trois approches pour intégrer la recherche web avec l'API Claude, chacune adaptée à des cas d'usage spécifiques.

Option A : web_search natif officiel (recommandé)
Avantages :
- Zéro maintenance : pas de serveur à gérer, tout est pris en charge par Anthropic.
- Citations automatiques : chaque réponse inclut des
citations, idéal pour la conformité. - Intégration totale : Claude décide lui-même quand et quoi chercher.
- Facturation transparente : 10 $ pour 1 000 requêtes, directement sur votre facture Anthropic.
Inconvénients :
- Limité aux sources indexées par Anthropic (impossible de changer de moteur de recherche).
- Certaines versions de modèles sont limitées (Haiku/anciennes versions de Sonnet ne supportent que la version de base).
Cas d'usage : 90 % des agents conversationnels, assistants de questions-réponses et tâches de recherche.
Option B : Service MCP tiers (Brave/Tavily/Serper, etc.)
Via le Model Context Protocol, vous lancez un serveur MCP local ou distant pour injecter des capacités de recherche dans Claude :
# Exemple avec Tavily MCP, nécessite npm install -g @tavily/mcp-server
claude mcp add tavily-search npx -- @tavily/mcp-server
Avantages :
- Liberté de choisir le moteur de recherche (Brave pour la confidentialité, Tavily pour son optimisation LLM).
- Personnalisable : possibilité de nettoyer les résultats ou d'ajouter des métadonnées.
- Support natif dans les clients comme Claude Code ou Cursor.
Inconvénients :
- Nécessite de maintenir un processus serveur MCP supplémentaire.
- Les résultats ne génèrent pas automatiquement des
citationsconformes aux standards d'Anthropic. - Gestion autonome des quotas et de la facturation du fournisseur tiers.
Cas d'usage : Si vous avez déjà un compte entreprise chez Brave/Tavily ou si vous avez des besoins spécifiques en termes de moteur de recherche.
Option C : Appel d'outil personnalisé (Google CSE + Custom Tool)
L'approche classique : vous définissez un tool et, dans votre code backend, vous appelez Google Custom Search ou l'API Bing pour réinjecter les résultats dans les messages :
tools = [{
"name": "google_search",
"description": "Rechercher sur Google et retourner les N meilleurs résultats",
"input_schema": {
"type": "object",
"properties": {
"query": {"type": "string"}
},
"required": ["query"]
}
}]
Avantages : Contrôle total, intégration possible avec des recherches intranet ou des bases de connaissances privées.
Inconvénients : Vous gérez tout : conception de l'invite, classement des résultats, génération des citations et gestion des erreurs. De plus, Claude ne déclenchera pas la recherche "automatiquement" — il faut le guider explicitement via le system prompt.
Cas d'usage : Scénarios d'entreprise exigeant une conformité stricte, une personnalisation poussée ou l'accès à des sources de données privées.
Arbre de décision pour les trois options
| Votre besoin | Solution recommandée |
|---|---|
| Mise en place rapide, besoins standards | Option A web_search natif |
| Besoin de changer de moteur (confidentialité/conformité) | Option B MCP tiers |
| Accès obligatoire à des données privées | Option C Outil personnalisé + RAG |
| Accès instable à Anthropic depuis la Chine | Option A + APIYI apiyi.com (proxy transparent) |
🎯 Note pour les développeurs : L'API officielle d'Anthropic peut être instable dans certaines régions et nécessite un numéro de téléphone étranger pour l'inscription. Nous recommandons d'utiliser le service proxy API d'APIYI (apiyi.com) — il transmet intégralement tous les outils serveur d'Anthropic (y compris
web_search,web_fetch,code_execution). Votre code reste inchangé, il suffit de modifierbase_urlparhttps://vip.apiyi.comet d'utiliser votre clé API APIYI.
Utilisation avancée de la recherche en ligne avec l'API Claude
Liste blanche de domaines : pour une "recherche verticale"
Vous avez besoin que Claude effectue ses recherches uniquement sur des domaines spécifiques ? Utilisez allowed_domains :
tools=[{
"type": "web_search_20250305",
"name": "web_search",
"max_uses": 5,
"allowed_domains": [
"docs.python.org",
"pypi.org",
"github.com"
]
}]
Attention à quelques limites :
allowed_domainsetblocked_domainsne peuvent pas être utilisés simultanément.- Les sous-domaines sont soumis à une correspondance exacte :
docs.example.comn'inclura pasapi.example.com. - Les restrictions de domaine au niveau de la requête doivent être compatibles avec la configuration au niveau de l'organisation ; elles ne peuvent pas élargir la portée définie par l'administrateur de l'organisation.
Activer les citations avec web_fetch
web_search active les citations par défaut, mais pour web_fetch, vous devez les activer explicitement :
{
"type": "web_fetch_20250910",
"name": "web_fetch",
"max_uses": 5,
"citations": {"enabled": True},
"max_content_tokens": 50000
}
max_content_tokens permet de tronquer les documents trop volumineux pour éviter de saturer la fenêtre de contexte lors d'un seul fetch. Voici quelques ordres de grandeur :
| Type de contenu | Taille | Approx. tokens |
|---|---|---|
| Page web standard | 10 Ko | ~2 500 |
| Page de documentation large | 100 Ko | ~25 000 |
| PDF de recherche | 500 Ko | ~125 000 |
Gestion de encrypted_content dans les conversations multi-tours
Chaque résultat renvoyé par web_search contient un champ encrypted_content. Dans une conversation multi-tours, si vous voulez que Claude continue de citer les résultats de recherche précédents, vous devez renvoyer ce champ tel quel — sinon, le contexte des citations sera perdu lors des tours suivants.
messages.append({
"role": "assistant",
"content": previous_response.content # Conserver intégralement, y compris encrypted_content
})
messages.append({
"role": "user",
"content": "Analyse en détail le 2ème article trouvé précédemment"
})
🎯 Conseil technique : Lors de l'intégration dans des frameworks d'agents (comme LangChain ou LlamaIndex), assurez-vous que le framework transmet bien tous les blocs de contenu de la réponse de Claude. Beaucoup de frameworks "nettoient" des champs comme
server_tool_use, ce qui invalide les citations. Nous recommandons de construire directement sur le SDK anthropic et d'utiliser le service proxy API APIYI (apiyi.com) pour garantir un comportement identique à l'API officielle.
Cas d'usage concrets de la recherche en ligne avec l'API Claude
Maintenant que la théorie est posée, examinons quelques combinaisons de bonnes pratiques pour l'utilisation de la recherche en ligne de Claude dans des scénarios réels.
Scénario 1 : Assistant de questions-réponses sur l'actualité en temps réel
Si un utilisateur demande "Comment se porte le marché boursier aujourd'hui ?", des données en temps réel sont nécessaires. Stratégie de configuration :
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system="Tu es un assistant financier. Pour toute question sur les cours en temps réel ou l'actualité, utilise impérativement web_search. Les réponses doivent être sourcées.",
messages=[{"role": "user", "content": "Quel est le cours de clôture de l'indice SSE aujourd'hui ? Quelle est la tendance ?"}],
tools=[{
"type": "web_search_20250305",
"name": "web_search",
"max_uses": 3,
"allowed_domains": ["sina.com.cn", "eastmoney.com", "163.com"],
"user_location": {
"type": "approximate",
"country": "CN",
"timezone": "Asia/Shanghai"
}
}]
)
Points clés : Utilisez allowed_domains pour cibler des sites financiers faisant autorité, et user_location pour que Claude privilégie les résultats en chinois.
Scénario 2 : RAG amélioré pour la documentation technique
Permettre à Claude de privilégier la documentation officielle lors de réponses à des questions techniques :
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=4096,
messages=[{
"role": "user",
"content": "Comment implémenter un heartbeat WebSocket dans FastAPI ? Donne-moi un exemple complet."
}],
tools=[
{
"type": "web_search_20260209",
"name": "web_search",
"max_uses": 5,
"allowed_domains": [
"fastapi.tiangolo.com",
"docs.python.org",
"github.com",
"stackoverflow.com"
]
},
{
"type": "web_fetch_20260209",
"name": "web_fetch",
"max_uses": 3,
"citations": {"enabled": True}
}
]
)
Points clés : Utilisez le filtrage dynamique de web_search_20260209 pour éliminer le HTML non pertinent, puis web_fetch pour récupérer le texte intégral de la documentation officielle.
Scénario 3 : Assistant de recherche académique
Pour les scénarios nécessitant des citations rigoureuses et une analyse sur une longue fenêtre de contexte, nous recommandons Opus 4.7 avec une combinaison de deux outils :
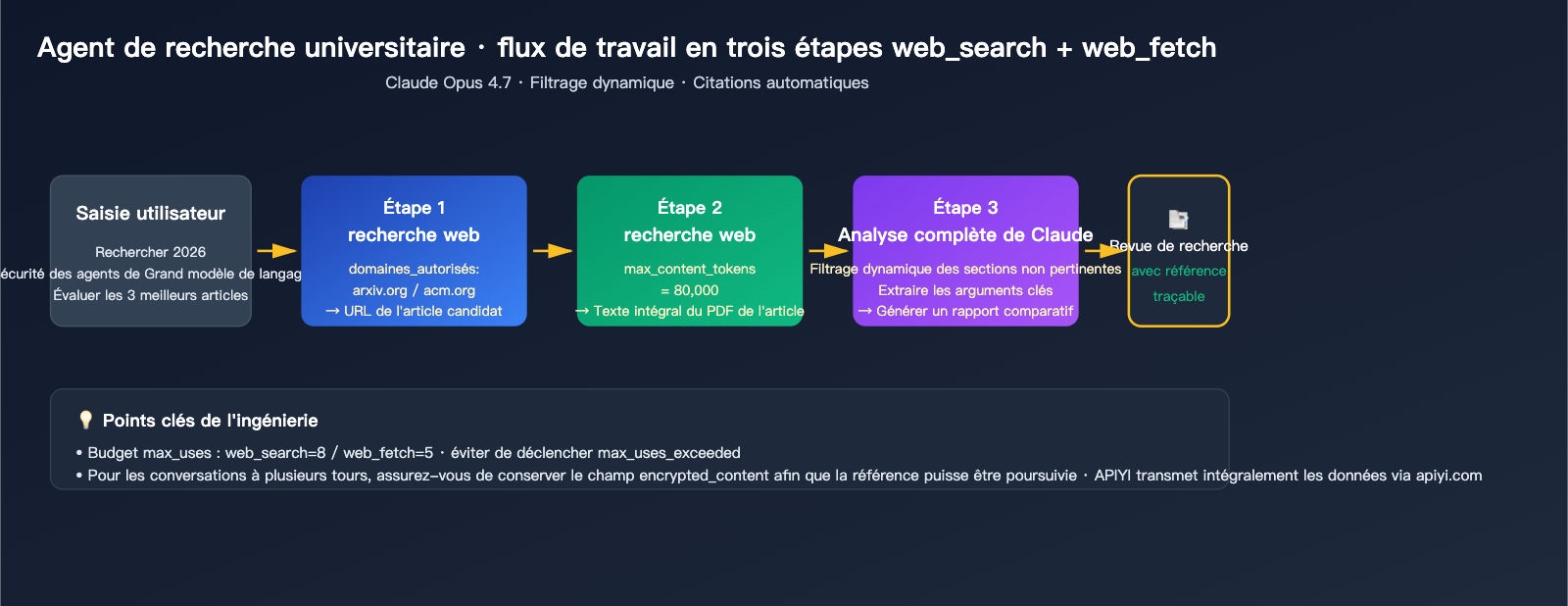
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=8192,
messages=[{
"role": "user",
"content": "Recherche les articles de 2026 sur l'évaluation de la sécurité des agents LLM, sélectionne les 3 meilleurs pour une analyse comparative."
}],
tools=[
{
"type": "web_search_20260209",
"name": "web_search",
"max_uses": 8,
"allowed_domains": ["arxiv.org", "openreview.net", "acm.org"]
},
{
"type": "web_fetch_20260209",
"name": "web_fetch",
"max_uses": 5,
"citations": {"enabled": True},
"max_content_tokens": 80000
}
]
)
🎯 Conseil par scénario : Chaque activité a des exigences différentes en termes de qualité de recherche, de conformité des citations et de coûts. Nous vous recommandons de créer une clé API dédiée pour chaque cas d'usage sur APIYI (apiyi.com). Cela facilite le suivi de la facturation par projet et la surveillance du nombre réel de recherches et de la consommation de tokens, plutôt que de tout mélanger.
Meilleures pratiques d'ingénierie pour la recherche en ligne avec l'API Claude
Faire fonctionner une démo est une chose, mais intégrer réellement la recherche en ligne de l'API Claude en production demande de franchir quelques étapes supplémentaires.
Pratique 1 : Réduction des coûts et optimisation avec le prompt caching
Bien que la définition du Server Tool soit concise, elle représente un coût fixe non négligeable lorsqu'elle est combinée à un system prompt. Activez le prompt caching :
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
system=[{
"type": "text",
"text": "Tu es un assistant de recherche professionnel...(500 mots de system prompt omis ici)",
"cache_control": {"type": "ephemeral"}
}],
messages=[...],
tools=[
{
"type": "web_search_20250305",
"name": "web_search",
"max_uses": 5,
"cache_control": {"type": "ephemeral"}
}
]
)
Résultat : pour les requêtes répétées dans un intervalle de 5 minutes, le coût en tokens de la partie system + tools peut être réduit de 90 %.
Pratique 2 : Utiliser les réponses en flux (streaming) pour éviter les timeouts
Une exécution unique de web_search peut prendre entre 5 et 15 secondes. Si votre infrastructure en aval (passerelle, client) impose une limite de timeout de 30 secondes, assurez-vous d'activer stream=True pour maintenir la connexion active via un heartbeat en flux.
Pratique 3 : Cohérence multi-tours pour encrypted_content
Dans les conversations multi-tours, Claude peut citer les résultats de recherches effectuées lors des tours précédents. Vous devez conserver l'intégralité du tableau content de tous les messages assistant précédents dans chaque requête, ne gardez pas uniquement la partie text :
# ❌ Mauvaise pratique
messages.append({"role": "assistant", "content": response.content[-1].text})
# ✅ Bonne pratique
messages.append({"role": "assistant", "content": response.content})
Pratique 4 : Stratégies de limitation de débit et de nouvelle tentative
La limite de débit de web_search est indépendante de celle de l'interface de messagerie classique. Nous recommandons d'encapsuler une logique de nouvelle tentative avec backoff exponentiel au niveau du SDK :
| Code d'erreur | Stratégie de nouvelle tentative | Nombre max. de tentatives |
|---|---|---|
too_many_requests |
Backoff exponentiel (2s/4s/8s) | 3 |
unavailable |
Délai fixe (5s) | 2 |
max_uses_exceeded |
Aucune, augmenter max_uses | – |
query_too_long |
Aucune, tronquer la requête | – |
🎯 Conseil pour la production : Enregistrez toutes les erreurs de
web_searchdans votre système de monitoring et analysez régulièrement la part destoo_many_requests— c'est l'indicateur clé pour évaluer si vous devez augmenter votre capacité. Lors d'une invocation du modèle via la plateforme APIYI (apiyi.com), vous pouvez consulter directement le taux de réussite et le temps de réponse moyen dans la console pour faciliter la maintenance.
FAQ sur la recherche en ligne de l'API Claude
Q1 : Le service proxy API d'APIYI prend-il en charge le web_search natif ? Faut-il modifier le code ?
Oui, et aucune modification de code n'est nécessaire. APIYI (apiyi.com) utilise une architecture de transfert transparent, transmettant intégralement tous les Server Tools officiels d'Anthropic. Il vous suffit de changer l'URL de base (base_url) par https://vip.apiyi.com et de remplacer votre clé API par celle d'APIYI. Votre code original fonctionnera sans modification, incluant tous les outils natifs comme web_search, web_fetch ou code_execution.
Q2 : Comment est facturé web_search ? Est-ce cher à 10 $ pour 1000 recherches ?
Une recherche = 0,01 $, quel que soit le nombre de résultats retournés. Les recherches infructueuses ne sont pas facturées. Comparaison : Tavily 0,005 $/recherche, Brave 0,006 $/recherche, Google CSE 0,005 $/requête (au-delà du quota gratuit). Le web_search natif est légèrement plus cher, mais il élimine les coûts d'ingénierie liés à la maintenance d'un serveur MCP et à la conformité des citations, ce qui le rend souvent plus rentable pour les petites et moyennes équipes.
Q3 : Pourquoi mon code renvoie-t-il l'erreur max_uses_exceeded ?
Claude peut appeler web_search plusieurs fois au cours d'une même conversation (il décide lui-même du nombre de recherches nécessaires). Si vous avez défini "max_uses": 1 mais que la question nécessite 3 recherches pour obtenir une réponse, cette erreur sera déclenchée. Nous recommandons d'allouer un budget de 5 à 10 recherches pour les questions complexes, et 1 à 2 pour les échanges simples.
Q4 : web_search peut-il effectuer des recherches sur des sites web en français ?
Oui. web_search s'appuie sur l'index en temps réel d'Anthropic, qui couvre très bien le contenu francophone (y compris les articles de blogs, forums, etc.). Si vous souhaitez restreindre la recherche aux sites francophones, vous pouvez utiliser la liste blanche allowed_domains.
Q5 : La consommation de tokens est élevée pour les recherches sur de longs documents, comment optimiser ?
Trois pistes d'optimisation :
- Utilisez la version
web_search_20260209avec filtrage dynamique (nécessite Claude Opus/Sonnet 4.6+), qui élimine automatiquement les segments non pertinents. - Utilisez le paramètre
max_content_tokensdeweb_fetchpour limiter la quantité de texte récupérée par page. - Activez le prompt caching pour mettre en cache la définition des outils et le system prompt, réduisant ainsi les coûts des requêtes répétées.
Q6 : Peut-on mélanger les solutions de recherche MCP tierces et le web_search natif ?
Oui. Claude permet de définir plusieurs outils simultanément, mais veillez à ce que les descriptions des outils soient claires — par exemple, décrivez le tavily_search du MCP comme "recherche d'articles académiques" et le web_search natif comme "recherche web généraliste". Claude choisira l'outil en fonction de la description. Cependant, pour éviter toute ambiguïté, nous recommandons d'utiliser un seul outil de recherche par scénario.
Q7 : Que faire si l'invocation du modèle avec recherche en ligne échoue depuis la Chine ?
Il y a deux raisons principales : l'instabilité de la connexion directe à l'API Anthropic et le fait que le backend d'Anthropic peut bloquer les adresses IP de Chine continentale lors de l'exécution de web_search. La solution la plus directe est de passer par le service proxy API d'APIYI (apiyi.com) : toutes les requêtes web_search sont transmises via les nœuds étrangers d'APIYI vers Anthropic, puis la réponse est renvoyée, garantissant une stabilité identique à une connexion directe depuis l'étranger.
Résumé et conseils de sélection pour la recherche en ligne via l'API Claude
En résumé, la recherche en ligne via l'API Claude est devenue en 2026 une solution "prête à l'emploi". Voici notre recommandation en une phrase :
✅ Pour 80 % des projets, la fonction native
web_searchofficielle suffit : configuration simple, citations conformes et maintenance assurée par Anthropic. Pour les 20 % restants nécessitant une personnalisation poussée, envisagez alors des MCP tiers ou des outils développés en interne.
Liste d'actions pour la mise en œuvre
Si vous prévoyez d'intégrer la recherche en ligne via l'API Claude dans votre projet dès aujourd'hui :
- Choix du modèle : Utilisez
claude-sonnet-4-6pour les scénarios courants (meilleur rapport performance/prix) etclaude-opus-4-7pour les recherches complexes. - Choix de la version de l'outil : Privilégiez
web_search_20260209(filtrage dynamique) et revenez àweb_search_20250305pour les anciens modèles. - Configuration de
max_uses: 1 à 3 utilisations pour les questions-réponses simples, 5 à 10 pour les recherches approfondies. - Utilisation avec
web_fetch: Pour les analyses de texte intégral, combinez-le avecweb_fetchafin d'extraire les pages pertinentes. - Configuration de l'accès : Depuis la Chine, utilisez le service proxy API APIYI (apiyi.com) pour un transfert transparent, sans VPN et sans modification de code.
🎯 Dernier conseil : L'enjeu de la recherche en ligne avec l'API Claude n'est pas de savoir si elle fonctionne, mais de trouver le juste équilibre entre la qualité des résultats de recherche, le coût en jetons et la latence de réponse. Nous vous suggérons de tester d'abord quelques cas d'usage réels sur la plateforme APIYI (apiyi.com), de mesurer le nombre de recherches et la consommation de jetons par conversation, avant de décider d'implémenter des optimisations avancées comme le prompt caching ou le filtrage dynamique. La plateforme prend en charge toute la gamme des modèles Claude ainsi que les outils serveur natifs, facilitant ainsi une itération rapide.
Auteur : Équipe technique APIYI | Pour plus de tutoriels pratiques sur l'API Claude, visitez help.apiyi.com