Le 19 mai 2026, lors de la conférence Google I/O 2026, Google a officiellement lancé Gemini 3.5 Flash. Il s'agit du premier modèle public de la gamme Gemini 3.5. Son identifiant API est directement gemini-3.5-flash, sans suffixe "preview", ce qui signifie qu'il est déjà en état GA (disponibilité générale). Le jour même, la plateforme APIYI (apiyi.com) a finalisé son intégration. Les développeurs peuvent désormais invoquer Gemini 3.5 Flash via des interfaces compatibles OpenAI pour l'intégrer à leurs propres produits. Les nouveaux utilisateurs reçoivent un crédit gratuit de 0,05 $ dès leur inscription, permettant de tester l'intégration sans aucun coût.

Ce qui a le plus surpris les développeurs internationaux avec Gemini 3.5 Flash, c'est le phénomène "Flash dépasse Pro" : sur plusieurs benchmarks d'agents et de codage comme Terminal-Bench 2.1, MCP Atlas, Finance Agent v2 et GDPval-AA, il obtient des scores supérieurs au fleuron de la génération précédente, Gemini 3.1 Pro. De plus, la vitesse de sortie est annoncée par Google comme étant environ 4 fois plus rapide que les modèles de pointe de même catégorie. Pour les équipes gérant des agents de codage, des flux de travail d'invocation d'outils ou le traitement de longs documents, c'est la mise à jour de modèle la plus importante à évaluer en mai. Nous vous recommandons d'utiliser le crédit gratuit d'APIYI (apiyi.com) pour tester vos propres tâches réelles avant de décider de basculer votre production vers la version 3.5.
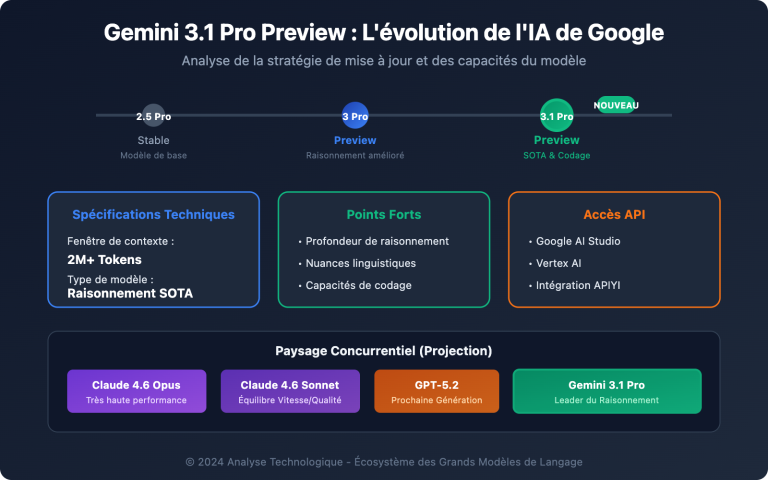
Qu'est-ce que Gemini 3.5 Flash : Le positionnement clé de la version officielle de Google
Gemini 3.5 Flash est la première version légère phare de la famille Gemini 3.5 publiée par Google DeepMind. Elle est positionnée comme un "Agentic Flash" : tout en conservant les caractéristiques de faible latence et de haut débit de la série Flash, elle intègre les capacités d'orchestration d'outils et de raisonnement en plusieurs étapes, auparavant réservées aux modèles Pro. Lors de la conférence, Google a souligné que 3.5 Flash est actuellement leur modèle d'orchestration d'agents le plus performant, déployé simultanément dans les applications Gemini, le mode IA de Google Search, Google Antigravity, Google AI Studio et le cloud d'entreprise.
Cette version apporte quatre informations officielles cruciales. Premièrement, l'ID du modèle n'a pas de suffixe "preview" (version interne 3.5-flash-05-2026), ce qui signifie qu'il est disponible directement en tant que GA. Deuxièmement, le "Dynamic Thinking" (réflexion dynamique) est activé par défaut : le modèle détermine automatiquement si une question nécessite une chaîne de réflexion, sans que le développeur ait à gérer manuellement le budget de réflexion. Troisièmement, les capacités d'outils sont complètes par défaut : l'invocation de fonctions (function calling), la sortie structurée, la recherche comme outil (Search-as-a-Tool) et l'exécution de code sont toutes disponibles pour une intégration directe dans des agents complexes. Quatrièmement, la date limite des connaissances est fixée à janvier 2026, ce qui en fait l'une des bases de connaissances les plus récentes parmi les modèles fermés actuels.
Le tableau ci-dessous résume les spécifications principales de Gemini 3.5 Flash. Toutes les données proviennent de la documentation officielle de Google AI for Developers et des tests indépendants de LLM-Stats et Artificial Analysis.
| Paramètre | Valeur pour Gemini 3.5 Flash | Remarques |
|---|---|---|
| Date de sortie | 19 mai 2026 | Conférence Google I/O 2026 |
| ID du modèle | gemini-3.5-flash |
Version officielle, sans suffixe preview |
| Version interne | 3.5-flash-05-2026 |
Identique à Google AI Studio |
| Positionnement | Agentic Flash · Orchestration d'outils + Codage | Dépasse 3.1 Pro sur plusieurs tests d'agents |
| Fenêtre de contexte | 1 048 576 tokens en entrée / 65 536 en sortie | Soit 1M / 64K |
| Modalités d'entrée | Texte + Image + Audio + Vidéo | Sortie texte uniquement |
| Réflexion dynamique | Activée par défaut | Aucune configuration manuelle requise |
| Capacités d'outils | Function calling / Sortie structurée / Search-as-a-Tool / Exécution de code | Pile d'outils d'agent complète |
| Connaissances | Jusqu'en janvier 2026 | Même génération que GPT-5.5, Claude Opus 4.7 |
| Accès API | Compatible OpenAI / Interface native Gemini | APIYI (apiyi.com) prend en charge les deux |
🎯 Conseil d'intégration : Le changement majeur de Gemini 3.5 Flash est de faire de la combinaison "modèle léger + invocation d'outils" une capacité par défaut. Par conséquent, la méthode la plus rentable n'est pas un remplacement ponctuel, mais de l'utiliser comme "couche d'orchestration d'outils" dans vos flux de travail d'agents. Nous vous suggérons d'utiliser l'interface unifiée de la plateforme APIYI (apiyi.com) avec le crédit gratuit de 0,05 $ pour tester vos flux de travail existants (GPT-5.5 Instant / Claude Haiku 4.5 / Gemini 3.1 Flash) en basculant vers
gemini-3.5-flashpour une série de tests de régression avant de passer en production.
Aperçu des tarifs et de la fenêtre de contexte de Gemini 3.5 Flash
La tarification de Gemini 3.5 Flash est un autre point de controverse majeur lors de ce lancement. Google a fait passer les prix de la gamme Flash de 0,50 $ / 4 $ pour la version 3 Flash Preview à 1,50 $ / 9 $ pour la 3.5 Flash, se rapprochant ainsi du tarif de 2 $ / 12 $ du Gemini 3.1 Pro. Simon Willison, dans la communauté anglophone, suggère que Google "teste la tolérance aux prix des clients API", ce qui signifie également que l'objectif de la 3.5 Flash n'est pas d'être moins chère, mais d'offrir l'intelligence de la gamme Pro au coût d'une gamme Flash.
Le tableau ci-dessous compare la tarification officielle de Gemini 3.5 Flash avec les modèles dominants de la même catégorie pour vous aider à déterminer si elle est rentable pour vos charges de travail. Tous les prix sont indiqués par million de jetons (tokens).
| Modèle | Prix entrée | Prix sortie | Entrée cache hit | Fenêtre de contexte |
|---|---|---|---|---|
| Gemini 3.5 Flash | 1,50 $ | 9,00 $ | 0,15 $ | 1M / 64K sortie |
| Gemini 3.1 Pro | 2,00 $ | 12,00 $ | 0,20 $ | 1M / 64K sortie |
| Gemini 3.1 Flash-Lite | 0,25 $ | 1,50 $ | 0,025 $ | 1M / 64K sortie |
| GPT-5.5 (modèle principal) | 5,00 $ | 30,00 $ | 0,50 $ | 400K entrée |
| Claude Opus 4.7 (1M) | 15,00 $ | 75,00 $ | 1,50 $ | 1M entrée |
Notez trois points de comparaison clés. Premièrement, par rapport au Gemini 3.1 Pro du même fabricant, Gemini 3.5 Flash est 25 % moins cher, tout en étant plus performant dans les tests de codage et d'Agent ; c'est donc une opportunité claire de "montée en gamme à prix réduit" pour les utilisateurs Pro. Deuxièmement, comparé au GPT-5.5, le prix par jeton de Gemini 3.5 Flash est inférieur à un tiers, avec un score de seulement 5 points de moins sur l'Artificial Analysis Intelligence Index, ce qui en fait un choix idéal comme modèle principal pour les conversations et les Agents sensibles aux coûts. Troisièmement, par rapport à Claude Opus 4.7, l'intelligence globale de Gemini 3.5 Flash n'est inférieure que de 2 points, mais le coût total par million de jetons est inférieur à un dixième, permettant de réaliser d'importantes économies sur les scénarios à contexte extrêmement long.
💡 Conseil d'optimisation tarifaire : Gemini 3.5 Flash propose un tarif d'entrée avec cache hit à 0,15 $ / 1M, idéal pour les longs system prompt et les scénarios RAG sur documents volumineux. Nous vous recommandons d'activer le prompt caching sur la plateforme APIYI apiyi.com pour réutiliser au maximum les instructions fixes, les extraits de bases de connaissances et l'historique des longues conversations, ce qui peut réduire le coût d'entrée de 1M de jetons au niveau du 3.1 Flash-Lite.
Benchmarks clés de Gemini 3.5 Flash : Comparaison réelle avec Gemini 3.1 Pro
L'une des données les plus contre-intuitives du lancement de Gemini 3.5 Flash est que "Flash surpasse Pro". La fiche technique officielle de Google et les tests indépendants de LLM-Stats le confirment : sur des tâches telles que les Agents, l'orchestration d'outils, le codage et l'analyse financière, les scores de la 3.5 Flash sont effectivement supérieurs à ceux du Gemini 3.1 Pro ; elle n'est légèrement inférieure au 3.1 Pro que dans le raisonnement académique pur (Humanity's Last Exam) et le raisonnement abstrait (ARC-AGI-2).
Le tableau ci-dessous résume les comparaisons de référence clés entre Gemini 3.5 Flash et Gemini 3.1 Pro, basées sur des données publiques officielles et tierces.
| Benchmark | Gemini 3.5 Flash | Gemini 3.1 Pro | Écart | Capacité évaluée |
|---|---|---|---|---|
| Terminal-Bench 2.1 | 76,2 % | 70,3 % | +5,9 | Agent de codage terminal |
| MCP Atlas | 83,6 % | 78,2 % | +5,4 | Appel d'outils MCP |
| Finance Agent v2 | 57,9 % | 43,0 % | +14,9 | Agent de documents financiers |
| GDPval-AA (Elo) | 1656 | 1314 | +342 | Agent généraliste |
| CharXiv Reasoning | 84,2 % | — | — | Raisonnement sur graphiques |
| Humanity's Last Exam | 40,2 % | 44,4 % | -4,2 | Raisonnement académique pur |
| ARC-AGI-2 | 72,1 % | 77,1 % | -5,0 | Raisonnement abstrait |
| Vitesse de sortie | ~ 284 jetons/s | Plus lent | — | Réponse en temps réel |
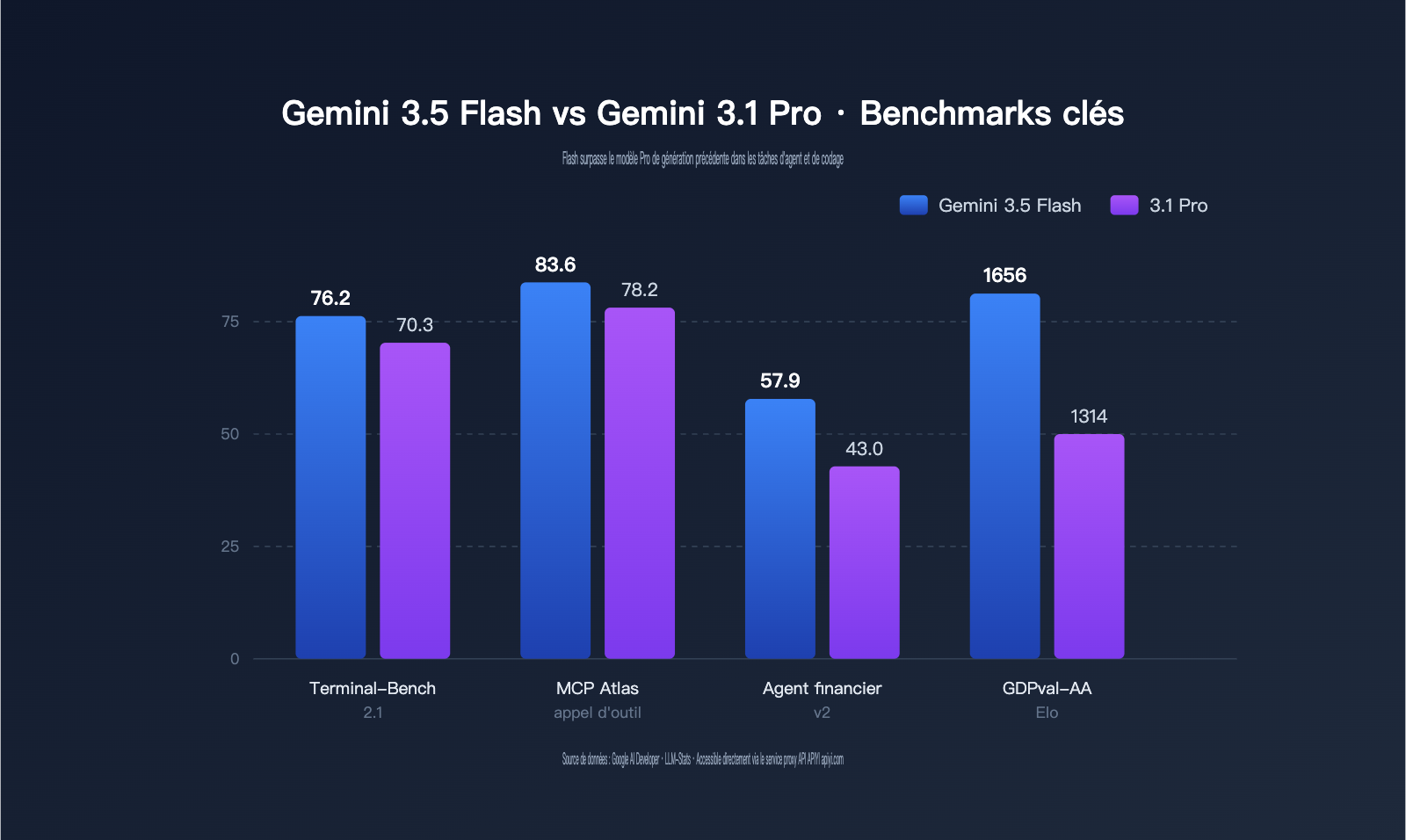
Ces données envoient trois signaux clairs. Premièrement, le "dépassement" de Gemini 3.5 Flash se concentre sur les tâches d'appel d'outils et d'Agents ; l'écart de +14,9 sur Finance Agent v2 et de +342 Elo sur GDPval-AA est considérable. Deuxièmement, les connaissances statiques pures et le raisonnement abstrait restent les points forts des modèles Pro ; si votre charge de travail est orientée vers les concours de mathématiques, le raisonnement académique ou les problèmes de logique à longue chaîne, Gemini 3.5 Flash n'est pas forcément la solution optimale. Troisièmement, Google a en fait utilisé le modèle Flash pour effectuer une "redistribution des rôles dans la généalogie des modèles". Selon des informations provenant de l'étranger, Gemini 3.5 Pro devrait être publié le mois prochain, ce qui repoussera encore plus loin le plafond de la gamme Pro.
Il convient de souligner l'Artificial Analysis Intelligence Index (indice d'intelligence globale). Gemini 3.5 Flash obtient 55 points sur cet indice synthétique inter-benchmarks, à seulement 2 points de Claude Opus 4.7 et 5 points de GPT-5.5. Compte tenu du fait que le prix d'entrée de la 3.5 Flash est dix fois inférieur à celui de Claude Opus 4.7 et moins d'un tiers de celui de GPT-5.5, c'est l'un des modèles "proches du premier rang" les plus rentables actuellement. Nous vous suggérons de l'utiliser comme modèle d'Agent par défaut sur la plateforme APIYI apiyi.com, afin de réduire considérablement la charge opérationnelle liée à la répartition entre différents fournisseurs.
Analyse d'impact de Gemini 3.5 Flash : ce que cela signifie pour les développeurs
Cette sortie ne se résume pas à un simple ajout dans la liste des modèles disponibles. Google propose ici un hybride "Flash + Agent" capable de rivaliser avec les performances globales de GPT-5.5 et Claude Opus 4.7. Cela va redéfinir plusieurs flux de travail critiques pour les 1 à 2 trimestres à venir.
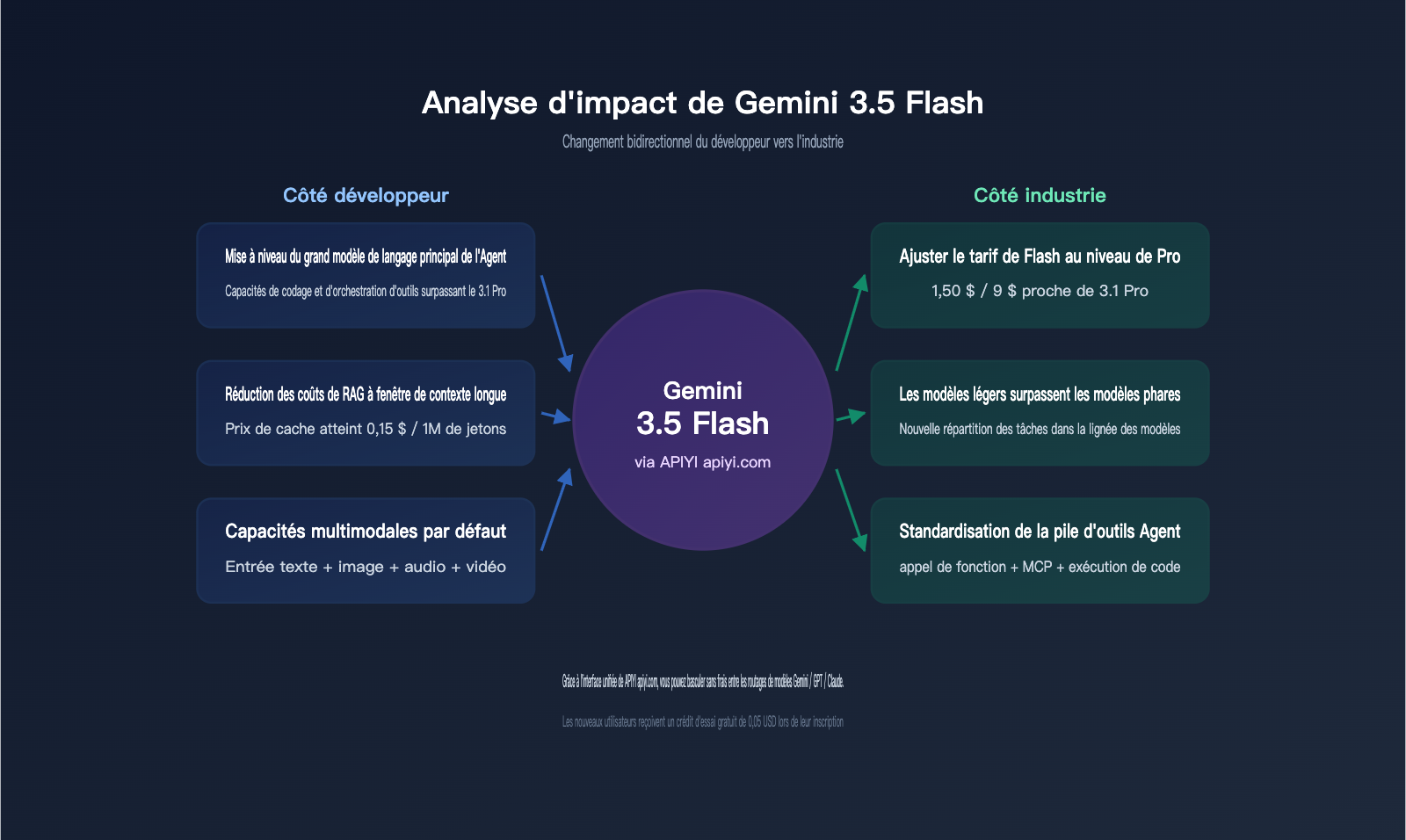
Impact direct sur les développeurs d'agents
Les équipes travaillant sur les agents sont les premiers bénéficiaires de Gemini 3.5 Flash. D'après les benchmarks, les améliorations simultanées sur Terminal-Bench 2.1 et MCP Atlas signifient que les goulots d'étranglement classiques, comme l'invocation d'outils en plusieurs étapes et la récupération après erreur, sont en nette amélioration. Le score de +14.9 sur Finance Agent v2 montre également des progrès significatifs dans le traitement de documents structurés. Des entreprises internationales comme Shopify, Macquarie Bank, Salesforce, Ramp, Xero et Databricks figurent déjà parmi les premiers partenaires de Google, couvrant des domaines tels que l'analyse de données, les documents financiers, l'automatisation d'entreprise, l'OCR de factures, les flux fiscaux et la surveillance de jeux de données. Si votre produit intègre un flux de type "lecture de document → invocation d'outil → sortie structurée", Gemini 3.5 Flash est un candidat à évaluer sans attendre.
Impact sur les applications RAG à longue fenêtre de contexte
Gemini 3.5 Flash conserve sa fenêtre de 1M d'entrées et 64K de sorties. Avec un coût de mise en cache des entrées à 0,15 $ / 1M de tokens, il rend le "RAG à très longue fenêtre de contexte" économiquement viable pour les SaaS grand public. À titre de référence : un préfixe de base de connaissances fixe de 500 000 tokens + une question utilisateur de 50 000 tokens coûte moins de 0,10 $ par inférence une fois la mise en cache activée, ce qui est bien inférieur aux coûts engendrés par le découpage du même contexte pour GPT-5.5 ou Claude Opus 4.7. Nous vous recommandons d'unifier vos chaînes RAG à longue fenêtre sur gemini-3.5-flash via APIYI (apiyi.com), où les stratégies de mise en cache peuvent directement réutiliser les implémentations existantes de l'interface Gemini.
Impact sur les stratégies de routage multi-modèles
Avec l'arrivée de Gemini 3.5 Flash, les stratégies de routage multi-modèles courantes doivent être repensées. La répartition traditionnelle "GPT pour le dialogue, Claude pour le code, Gemini pour le multimodal" est devenue obsolète, car Gemini 3.5 Flash est désormais compétitif sur ces trois fronts : agents de codage, invocation d'outils et entrées multimodales. Nous suggérons d'adopter gemini-3.5-flash comme nouveau "modèle de couche d'outils universel", tout en conservant GPT-5.5 Instant, Claude Opus 4.7 et Gemini 3.1 Pro comme renforts pour des tâches spécifiques. Grâce à l'interface unifiée d'APIYI (apiyi.com), vous pouvez effectuer ces changements de routage de modèles sans aucun coût technique.
Intégration et essai gratuit de Gemini 3.5 Flash sur APIYI
L'intégration de Gemini 3.5 Flash sur la plateforme APIYI (apiyi.com) est entièrement compatible avec OpenAI, ce qui signifie que les développeurs n'ont pas besoin de reconstruire leur logique d'authentification ou de routage. Les nouveaux utilisateurs reçoivent un crédit d'essai de 0,05 $ dès leur inscription, suffisant pour exécuter les exemples officiels et effectuer un test de régression complet de votre flux de travail Agent.
Exemple d'invocation minimaliste
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
)
response = client.chat.completions.create(
model="gemini-3.5-flash",
messages=[
{"role": "system", "content": "Vous êtes un ingénieur en orchestration d'agents."},
{"role": "user", "content": "Veuillez planifier une chaîne d'outils pour extraire les tickets (issues) de GitHub et générer un rapport hebdomadaire."},
],
)
print(response.choices[0].message.content)
Voir l’invocation complète avec appel de fonction (function calling)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
)
tools = [
{
"type": "function",
"function": {
"name": "fetch_github_issues",
"description": "Extraire la liste des tickets d'un dépôt spécifié",
"parameters": {
"type": "object",
"properties": {
"repo": {"type": "string", "description": "propriétaire/dépôt"},
"state": {"type": "string", "enum": ["open", "closed", "all"]},
},
"required": ["repo"],
},
},
}
]
response = client.chat.completions.create(
model="gemini-3.5-flash",
messages=[
{"role": "user", "content": "Aide-moi à consulter les nouveaux tickets ouverts cette semaine sur le dépôt anthropics/anthropic-cookbook"},
],
tools=tools,
tool_choice="auto",
)
print(response.choices[0].message)
💡 Conseil d'essai : Avec une tarification de 1,50 $ / 9 $ pour Gemini 3.5 Flash, le crédit de 0,05 $ permet environ 30 000 à 40 000 jetons en entrée ou 5 000 jetons en sortie. C'est largement suffisant pour tester vos invites (prompts) existantes sur APIYI. Nous vous recommandons d'utiliser ce crédit gratuit pour tester des tâches réelles plutôt que de simples exemples officiels, afin de mieux évaluer si le modèle "Flash surpasse Pro" dans votre cas d'usage.
Trois étapes pour l'intégration
- Créez un compte sur APIYI (apiyi.com) et validez votre profil pour recevoir le crédit gratuit de 0,05 $.
- Générez une clé API dans le tableau de bord, modifiez le
base_urldu SDK OpenAI enhttps://api.apiyi.com/v1et définissez le champmodelsurgemini-3.5-flash. - Réutilisez directement vos invites actuelles de GPT-5.5 Instant ou Gemini 3.1 Pro Preview pour comparer la qualité des réponses, la latence et la consommation de jetons.
FAQ sur Gemini 3.5 Flash
Q1 : Qui est le plus performant entre Gemini 3.5 Flash et Gemini 3.1 Pro Preview ?
Cela dépend du scénario. Pour les tâches d'agent et de codage (Terminal-Bench 2.1, MCP Atlas, Finance Agent v2, GDPval-AA), Gemini 3.5 Flash surpasse Gemini 3.1 Pro. En revanche, pour le raisonnement académique pur (Humanity's Last Exam) et le raisonnement abstrait (ARC-AGI-2), il est légèrement en retrait. Conclusion : les équipes travaillant sur des agents, des appels d'outils, du code ou du RAG sur documents longs devraient privilégier Gemini 3.5 Flash. Celles axées sur le raisonnement statique peuvent conserver la version 3.1 Pro. Vous pouvez effectuer un test comparatif sur APIYI avec votre crédit gratuit.
Q2 : Pourquoi Gemini 3.5 Flash n’a-t-il plus le suffixe « preview » ?
C'est le résultat de la nouvelle stratégie de publication de Google pour la série 3.5. Gemini 3.5 Flash est directement disponible en version GA (General Availability) sous l'identifiant gemini-3.5-flash (version interne 3.5-flash-05-2026). Il a passé les évaluations de sécurité et offre un SLA de niveau production. Contrairement à la version 3.1 Pro Preview, vous pouvez l'intégrer en toute confiance dans votre code de production sans craindre une suppression ou un changement soudain.
Q3 : Combien de requêtes Gemini 3.5 Flash puis-je effectuer avec 0,05 $ ?
Avec une tarification de 1,50 $ / 1M de jetons en entrée et 9 $ / 1M en sortie, 0,05 $ couvrent environ 30 000 jetons d'entrée et 1 500 jetons de sortie, soit environ 30 à 50 appels de conversation de longueur moyenne. Si vous activez la mise en cache des invites (prompt caching), les parties mises en cache sont facturées à 0,15 $ / 1M, ce qui prolonge encore davantage votre crédit gratuit.
Q4 : Gemini 3.5 Flash prend-il en charge les entrées vidéo et audio ?
Oui. Les modalités d'entrée de Gemini 3.5 Flash incluent le texte, l'image, l'audio et la vidéo (la sortie est uniquement textuelle). Notez que la vidéo et l'audio sont comptabilisés en jetons selon leur mode de traitement. L'interface d'APIYI expose déjà ces paramètres multimodaux, vous permettant de réutiliser votre code d'invocation existant pour Gemini 3.x.
Résumé : Gemini 3.5 Flash est la mise à jour de modèle la plus pertinente à évaluer en mai
Revenons sur ce fait contre-intuitif : le Gemini 3.5 Flash surpasse la génération précédente, Gemini 3.1 Pro, sur les tâches d'agent et de codage, tout en coûtant 25 % de moins que la version Pro. Avec une base de connaissances mise à jour jusqu'en janvier 2026 et une vitesse de génération annoncée comme étant 4 fois supérieure à celle des modèles de pointe de sa catégorie, c'est la mise à jour de modèle Google la plus intéressante à évaluer dès maintenant pour les équipes travaillant sur des agents, l'invocation d'outils, le RAG sur documents longs ou les flux de travail automatisés en entreprise.
Gemini 3.5 Flash est désormais disponible sur la plateforme APIYI (apiyi.com). Les nouveaux utilisateurs reçoivent un crédit gratuit de 0,05 $ à l'inscription, permettant de tester l'intégration sans aucun coût. Nous recommandons de l'intégrer en priorité dans la couche de planification d'outils de vos flux de travail d'agent. Grâce à l'interface compatible OpenAI d'APIYI (apiyi.com), vous pouvez non seulement bénéficier des dernières mises à jour de Google, mais aussi router vos requêtes de manière flexible entre différents modèles comme Claude Opus 4.7, GPT-5.5 Instant ou Gemini 3.1 Pro.
Auteur : Équipe technique APIYI · apiyi.com
Date de publication : 20 mai 2026
Références : Google AI for Developers, LLM-Stats, Artificial Analysis, Simon Willison Blog, Interesting Engineering, 9to5Google