Recientemente, el Cookbook oficial de OpenAI, en colaboración con Fractional AI, publicó un caso práctico sumamente sólido: el uso de IA para la auditoría automática de recibos de gastos. A primera vista, parece una tarea común de OCR, pero al abrir el Notebook, descubres que es una verdadera "biblia" metodológica sobre cómo llevar las aplicaciones de IA de un simple demo a un entorno de producción. Además, es el ejemplo de código abierto más completo sobre el Diseño de Sistemas Impulsado por Evaluaciones (Eval-Driven System Design), un tema candente en la industria.
Lo más interesante es que esta metodología no resuelve un problema técnico, sino una duda fundamental que atormenta a todos los ingenieros de IA: ¿Cómo puedo confirmar que el cambio que hice en la indicación realmente mejoró el sistema, o si solo parece haberlo hecho? En este artículo, desglosaremos este caso de auditoría de recibos de OpenAI de la forma más sencilla posible, extrayendo 5 lecciones de ingeniería útiles para cualquier desarrollador de aplicaciones de IA.
🎯 Guía rápida: El caso proviene del directorio
eval_driven_system_designen cookbook.openai.com, creado por el equipo de Fractional AI (Hugh Wimberly, Joshua Marker y Eddie Siegel) junto con Shikhar Kwatra de OpenAI. El código completo se encuentra en el repositorio oficial del Cookbook de OpenAI. Puedes replicar todo el proceso sin cambiar ni una línea utilizando servicios proxy de API como APIYI (apiyi.com), lo cual es ideal para que los desarrolladores locales aprendan directamente.
Contexto empresarial del caso de auditoría de recibos de OpenAI: ¿Por qué es un problema real?
Antes de entrar en la parte técnica, aclaremos el trasfondo comercial. No se trata de un problema artificial creado para demostrar una API, sino de un escenario empresarial real con cifras de ROI claras.
| Dimensión de negocio | Cifra específica | Significado |
|---|---|---|
| Volumen anual | Aprox. 1 millón | Escala típica de una mediana empresa |
| Costo de procesamiento por IA | $0.20 | Costo de invocación del modelo |
| Costo de auditoría humana | $2.00 | Revisión por personal financiero |
| Multa por error de auditoría | $30 / recibo | Sanciones fiscales/cumplimiento |
| Tasa de auditoría humana actual | 5% | Solo documentos complejos |
Si multiplicas estas cifras, verás que incluso una mejora del 1% en la precisión de la auditoría, aplicada a un volumen de 1 millón de recibos, representa cientos de miles de dólares en beneficios anuales. Esto es lo que el equipo de Fractional AI enfatiza constantemente: "vincular las métricas de evaluación con el impacto en dólares". No se trata de inflar métricas, sino de asegurar que cada cambio en la indicación se refleje en el balance financiero de la empresa.
El objetivo de todo el sistema de IA es muy claro: utilizar GPT-4o para auditar automáticamente la mayoría de los recibos y enviar solo aquellos con "baja confianza" a revisión humana, reduciendo así tanto los costos de auditoría como el riesgo de errores. Suena sencillo, pero el diablo está en los detalles.
¿Qué es el Eval-Driven Design? Una metodología que solo entiendes tras haber sufrido
Si le preguntas a 100 ingenieros de IA "¿cómo verifican si un cambio en el prompt es correcto?", 99 te dirán "ejecuto un par de ejemplos y veo si la salida se siente bien". Esto es lo que el equipo de Fractional AI critica como vibe-coding (ajustar por intuición), y es precisamente la forma de desarrollo que el Eval-Driven Design (en adelante, EDD) busca reemplazar por completo.

Las diferencias entre ambos enfoques se resumen en la siguiente tabla:
| Dimensión de comparación | Vibe-Coding (por intuición) | Eval-Driven Design (basado en evaluación) |
|---|---|---|
| Método de verificación | Ejecutar 3-5 ejemplos y observar | Ejecutar 20-100+ muestras etiquetadas y calcular métricas |
| Juicio de cambios | "Parece que mejoró" | "La precisión subió del 78% al 85%" |
| Alineación de negocio | Basado en si parece importante | Convertido directamente a impacto en dólares |
| Riesgo de regresión | Cambiar A puede romper B sin saberlo | Todo el conjunto de métricas se ejecuta automáticamente |
| Escalabilidad de colaboración | Solo el autor original lo entiende | Cualquier ingeniero puede depurar |
Fractional AI tiene una frase muy citada: "La evaluación no es una herramienta, es la única forma de hacer desarrollo profesional de IA". Suena exagerado, pero en escenarios críticos como la auditoría de recibos, no tener evaluaciones es como jugar a la lotería en producción; nadie se atreve a desplegar con confianza.
💡 Analogía: El Eval-Driven Design es como un examen con respuestas correctas, donde puedes calcular cuánto mejoró tu "puntuación total" tras cada cambio. El Vibe-Coding es como responder preguntas por intuición, donde al terminar no sabes si mejoraste o empeoraste. La IA de nivel de producción debe ser lo primero.
Flujo de implementación en tres etapas del caso de auditoría de recibos de OpenAI
El OpenAI Cookbook desglosa todo el caso en tres etapas muy claras, un proceso que puede aplicarse a casi cualquier aplicación de IA de "entrada de imagen/documento + salida de decisión estructurada".
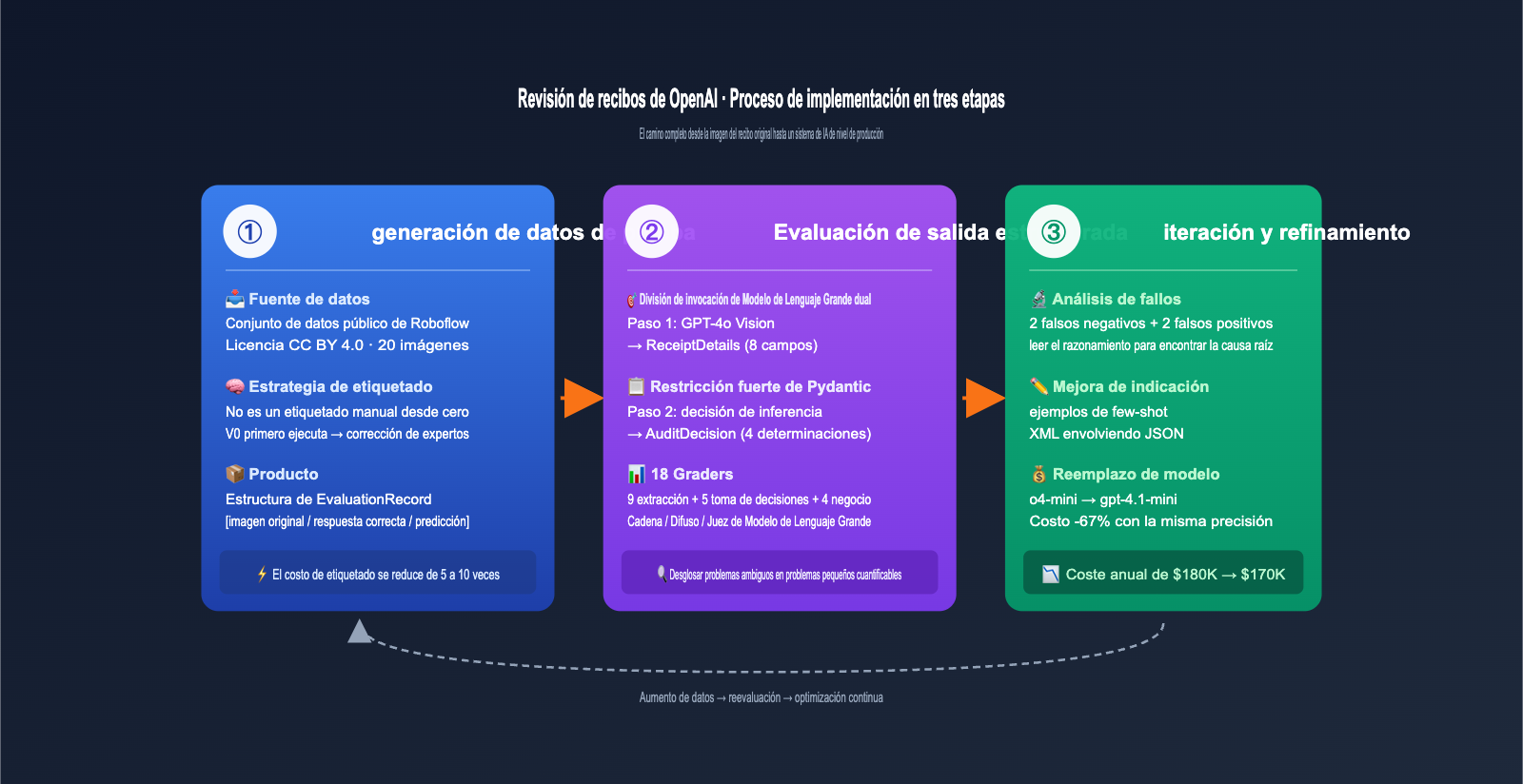
A continuación, explico cada etapa de la forma más sencilla posible.
Etapa 1: Generación de datos de prueba, ahorrando inteligentemente el 80% del costo de etiquetado
Si crees que el equipo comenzó desde cero etiquetando manualmente miles de imágenes de recibos, subestimas la capacidad de los ingenieros para buscar atajos. Fractional AI utilizó una estrategia muy inteligente: primero dejar que el modelo V0 lo ejecute, y luego dejar que un experto lo corrija.
El flujo es el siguiente: tomar 20 imágenes de recibos reales del conjunto de datos público de Roboflow (licencia CC BY 4.0) y enviarlas directamente a una versión simple de GPT-4o + flujo de extracción Pydantic para obtener la salida V0. Luego, pedir a un experto en finanzas que "busque y corrija errores" en esta salida, en lugar de escribir los datos desde cero.
Este método de "generar primero y corregir después" aumentó la eficiencia del tiempo del experto en el dominio entre 5 y 10 veces, ya que la mayoría de los campos ya fueron identificados correctamente por el V0, y el experto solo tuvo que corregir las partes erróneas. La estructura de datos EvaluationRecord resultante también es elegante, registrando simultáneamente "ruta de la imagen original, detalles correctos, detalles predichos por el modelo, decisión de auditoría correcta y decisión de auditoría predicha por el modelo", cubriendo todo el proceso con un solo registro.
🔧 Sugerencia de reutilización: Esta estrategia de etiquetado de "ejecutar V0 primero → corrección de expertos" puede aplicarse a casi cualquier etapa de arranque en frío de una aplicación de IA. Solo necesitas ejecutar rápidamente la salida V0 a través de una plataforma de API de OpenAI para concentrar la energía de los expertos en el juicio más valioso.
Etapa 2: Evaluación de salida estructurada, Pydantic es el verdadero héroe
Todo el sistema de IA está compuesto por dos llamadas a LLM encadenadas; este diseño de separación de responsabilidades es una de las esencias del EDD.
async def extract_receipt_details(
image_path: str, model: str = "o4-mini"
) -> ReceiptDetails:
"""Paso 1: Extraer información estructurada del recibo de la imagen"""
response = await client.responses.parse(
model=model,
input=[{"role": "user", "content": [
{"type": "input_text", "text": prompt},
{"type": "input_image", "image_url": data_url}
]}],
text_format=ReceiptDetails # Restricción fuerte del modelo Pydantic
)
return response.output_parsed
async def evaluate_receipt_for_audit(
receipt_details: ReceiptDetails, model: str = "o4-mini"
) -> AuditDecision:
"""Paso 2: Tomar decisiones de auditoría basadas en datos estructurados"""
# ... Llamar al LLM para generar el modelo Pydantic AuditDecision
¿Por qué dividirlo en dos pasos? Porque los requisitos de capacidad para estas dos tareas son completamente diferentes: el primer paso es "leer imágenes y reconocer texto" (visión + extracción de información), y el segundo paso es "juicio lógico" (razonamiento y toma de decisiones). Mezclarlos en un solo prompt no solo confunde al modelo con los límites de la tarea, sino que también dificulta la depuración cuando algo sale mal.
El diseño de los campos de los modelos Pydantic ReceiptDetails y AuditDecision es lo más valioso de este caso:
| Modelo | Campos clave | Significado de negocio |
|---|---|---|
| ReceiptDetails | merchant / location / time / items / subtotal / tax / total / handwritten_notes | Toda la información visible en el recibo |
| AuditDecision | not_travel_related / amount_over_limit / math_error / handwritten_x / reasoning / needs_audit | 4 condiciones de juicio de auditoría + proceso de razonamiento + conclusión final |
Presta especial atención al campo reasoning en AuditDecision: obliga al modelo a escribir el proceso de razonamiento antes de dar la decisión final, lo cual es clave para la evaluación de chain-of-thought. También nota que needs_audit es un OR lógico de los cuatro campos booleanos anteriores; este diseño de "puntuar primero y sintetizar la decisión después" permite que las métricas de evaluación se desglosen de forma muy detallada.
🚀 Consejo de integración: El método
client.responses.parse()mencionado arriba es la interfaz de salida estructurada más reciente de OpenAI, que permite restringir directamente el modelo Pydantic como formato de salida, eliminando casi por completo el riesgo de fallos en el análisis JSON. Recomendamos realizar llamadas a través de plataformas de proxy de API de OpenAI como apiyi.com, ya que esta interfaz requiere versiones específicas del SDK y la puerta de enlace garantiza que el protocolo esté siempre actualizado.
Etapa 3: Iteración y mejora, 18 evaluadores (graders) para cuantificar cada cambio
Esta etapa es donde el EDD realmente brilla. El equipo de Fractional AI configuró 18 métricas de evaluación independientes (graders) para este sistema de auditoría de recibos, descomponiendo la pregunta vaga de "¿es bueno el sistema?" en 18 preguntas pequeñas y cuantificables.
Estos 18 graders se dividen aproximadamente en tres categorías:
| Tipo de Grader | Métricas representativas | Método de evaluación |
|---|---|---|
| Precisión de extracción (9) | Coincidencia de nombre de comerciante / dirección / monto total | Coincidencia exacta de cadenas / coincidencia difusa |
| Precisión de decisión de auditoría (5) | Determinación de viaje / límite excedido / detección de error matemático / reconocimiento de X manuscrita / decisión final | Precisión de clasificación binaria |
| Métricas de alineación de negocio (4) | Productos faltantes / productos adicionales / precisión de productos / calidad de razonamiento | LLM-as-Judge (0-10 puntos) |
La evaluación inicial encontró 2 falsos negativos + 2 falsos positivos en 20 muestras. Este número no parece grande, pero a una escala de 1 millón de pedidos al año, representa miles de auditorías omitidas. El enfoque del equipo de Fractional fue muy ingenioso:
- Análisis de causa raíz: Revisar el campo
reasoningde cada caso erróneo para identificar dónde se bloquea el modelo. - Modificación específica del prompt: Agregar ejemplos few-shot, definir claramente "relacionado con viajes" y envolver ejemplos JSON en XML.
- Reejecución del conjunto de evaluación: Verificar que el cambio realmente corrigió el error y no introdujo uno nuevo.
- Experimentos de reemplazo de modelos: Ejecutar el mismo prompt en o4-mini y gpt-4.1-mini para elegir el que tenga un mejor ROI.
El resultado final fue impresionante: al cambiar de o4-mini a gpt-4.1-mini, el costo se redujo en un 67%, bajando el costo anual de aproximadamente $180K a $170K, sin que la precisión disminuyera prácticamente nada. Sin un conjunto de evaluación completo, ¿quién se atrevería a tomar esta decisión de reducción de costos?
📊 Perspectiva clave: Los 18 graders no están ahí para rellenar, sino para descomponer un problema aparentemente incalculable ("¿es precisa la IA?") en 18 problemas pequeños que pueden repararse y medirse de forma independiente. También puedes crear un sistema de graders similar llamando a la API de OpenAI Evals a través de apiyi.com, cuya interfaz es totalmente compatible con la oficial.
5 lecciones de ingeniería del caso de auditoría de recibos de OpenAI
Tras leer el caso completo, he extraído 5 lecciones aplicables a cualquier aplicación de IA; son experiencias aprendidas a base de invertir dinero real.
Lección 1: Vincula la evaluación al dólar, no busques que todos los indicadores lleguen al 100%
En el caso hay un hallazgo muy contraintuitivo: mejorar la precisión en el reconocimiento del nombre del comercio apenas influye en la decisión final de auditoría, ya que las reglas de auditoría no dependen del nombre del establecimiento. Si el equipo se obsesiona con subir la precisión del reconocimiento del nombre del 92% al 98%, está desperdiciando recursos de ingeniería.
Por el contrario, los errores en el reconocimiento de la "X" escrita a mano provocan pérdidas de unos 75.000 dólares anuales por auditorías fallidas, y ese es el indicador con mayor prioridad. Por lo tanto, la elección de los indicadores siempre debe responder a una pregunta: "¿Cuánto dinero ahorro al corregir este error?"
Lección 2: Primero haz que funcione con el modelo más potente, luego piensa en ahorrar
En la fase V0 del caso, se eligió directamente un modelo como o4-mini, el más potente en ese momento. No es porque al equipo no le importaran los costes, sino porque sabían que hacer que un modelo con capacidades insuficientes trabaje a duras penas es mucho más difícil que hacer que un modelo con capacidades sobradas trabaje de forma económica. Primero hay que validar la lógica de negocio y establecer un sistema de evaluación completo, y luego realizar experimentos de sustitución de modelos; este orden no se puede invertir.
Lección 3: La extracción y la toma de decisiones deben estar separadas, no intentes escribir una indicación universal
Muchos principiantes piensan: "¡Qué ahorro, obtener la conclusión de 'si requiere auditoría' directamente de la imagen en una sola llamada!". Pero este diseño tiene dos defectos fatales: no se puede depurar (si falla, no sabes si fue por leer mal la imagen o por una lógica de juicio errónea) y no se puede reutilizar (el resultado de la extracción solo sirve para esta decisión). Dividirlo en dos pasos parece implicar una llamada extra a la API, pero en realidad aumenta la mantenibilidad de todo el sistema en un orden de magnitud.
Lección 4: La evaluación mediante cadena de pensamiento (Chain-of-Thought) puede detectar riesgos de "respuesta correcta por motivos equivocados"
El campo reasoning en AuditDecision, que parece redundante, se utilizó durante la evaluación para identificar una situación peligrosa: el modelo dio la respuesta final correcta, pero el proceso de razonamiento fue erróneo. Este tipo de "acierto por suerte" no se nota en muestras pequeñas, pero en cuanto la distribución de los datos cambia ligeramente, el sistema falla estrepitosamente. Forzar la salida del razonamiento y utilizar LLM-as-Judge para evaluar la calidad del mismo es un seguro indispensable para aplicaciones de IA en producción.
Lección 5: El coste del etiquetado puede reducirse mediante ingeniería
No te dejes intimidar por el estereotipo de que "los proyectos de IA necesitan cantidades masivas de datos etiquetados". La estrategia de usar 20 muestras + correcciones de expertos sobre la salida de la V0 ya puede sustentar un conjunto de evaluación útil. La clave es que el conjunto de evaluación sea consistente con la distribución real de los datos de negocio, en lugar de perseguir la cantidad de muestras. La experiencia de Fractional fue utilizar la salida inicial de la V0 como "etiquetado semilla", lo que aumentó la eficiencia entre 5 y 10 veces en comparación con el etiquetado manual desde cero.
Consideraciones para replicar el caso de auditoría de recibos de OpenAI en China
Los desarrolladores en China que deseen replicar este libro de recetas (cookbook) deben resolver tres problemas: si pueden invocar los nuevos modelos como o4-mini / gpt-4.1-mini, si pueden usar la interfaz más reciente responses.parse y si pueden conectar con el punto final de la API de Evals.
La conexión directa con OpenAI desde China es muy inestable, especialmente con las interfaces de imagen, ya que al tener una carga útil (payload) mayor, la tasa de fallos es más alta que en las interfaces de texto. Usar una puerta de enlace (gateway) de API oficial de APIYI puede resolver estos tres problemas casi al instante; el código clave solo requiere cambiar una línea en base_url:
from openai import AsyncOpenAI
client = AsyncOpenAI(
base_url="https://vip.apiyi.com/v1", # La única línea que hay que cambiar
api_key="Tu clave API de APIYI"
)
# Todo el código posterior es idéntico al del cookbook
response = await client.responses.parse(
model="gpt-4.1-mini",
input=[...],
text_format=ReceiptDetails
)
Esta es la diferencia clave entre una "API de transferencia oficial de OpenAI" y una "API compatible con OpenAI": la primera garantiza que la interfaz esté sincronizada con la oficial de OpenAI, mientras que la segunda solo es compatible con las interfaces básicas y puede no admitir capacidades avanzadas como responses.parse o la API de Evals. Al replicar casos oficiales como los de este cookbook, elegir una puerta de enlace oficial te ahorrará un montón de problemas de compatibilidad.
Preguntas frecuentes sobre el caso de auditoría de recibos con OpenAI
P1: ¿Este método solo sirve para recibos?
Para nada. El diseño basado en evaluación (Eval-Driven Design) es aplicable a cualquier escenario donde la "entrada sea relativamente abierta y la salida requiera una decisión estructurada": revisión de contratos, triaje de imágenes médicas, control de calidad en atención al cliente, filtrado de currículums o detección de fraudes. Lo que no cambia es el diseño del esquema Pydantic y del evaluador (grader).
P2: ¿18 evaluadores no son demasiados para un equipo pequeño?
Puedes empezar con 5 o 6 evaluadores clave, como la precisión en la decisión final y la precisión en la extracción de campos críticos. Lo importante no es la cantidad, sino que cada evaluador corresponda a un patrón de fallo específico. Recomendamos ejecutar una pequeña muestra con GPT-4o en la consola de apiyi.com y, una vez que el flujo de negocio esté validado, ampliar las dimensiones de evaluación.
P3: ¿No resulta muy caro usar o4-mini directamente en la V0?
En la fase V0, el volumen de llamadas suele ser de unas pocas decenas a cientos, con un coste total de unos pocos dólares a unas decenas de dólares, lo cual es totalmente asumible. Donde realmente se ahorra es en el entorno de producción con millones de llamadas; para entonces, ya tendrás un conjunto de evaluación completo para realizar experimentos de sustitución de modelos, tal como se muestra en el caso donde el cambio de o4-mini a gpt-4.1-mini redujo los costes en un 67%.
P4: ¿Qué tal funciona GPT-4o Vision con recibos escritos a mano en chino?
La precisión en recibos impresos en inglés es muy alta (más del 95%) y en chino impreso también es buena (más del 90%), pero en chino manuscrito depende de la claridad de la letra. Sugerimos crear un conjunto de evaluación con 100 muestras reales en lugar de confiar solo en los vídeos de demostración. El coste de invocar GPT-4o Vision a través de una API oficial es el mismo que el oficial, lo que lo hace ideal para experimentos de evaluación a gran escala.
P5: Si no tengo permisos para la API de Evals, ¿puedo ejecutar este cookbook?
Sí. La API de Evals se encarga principalmente de gestionar la configuración y ejecución de los evaluadores en OpenAI, pero la lógica de evaluación real es equivalente si la ejecutas tú mismo con Python. Las funciones de evaluación del cookbook son de código abierto; puedes copiarlas y usarlas localmente. Si el volumen de negocio aumenta, puedes considerar migrar a la API de Evals gestionada.
P6: ¿Qué diferencia hay entre usar este caso con APIYI y la versión oficial?
El protocolo de interfaz, las versiones de los modelos y los parámetros son totalmente sincronizados con OpenAI, lo cual es el compromiso central de nuestro "servicio proxy de API". La diferencia radica principalmente en la red: las conexiones directas a OpenAI desde China suelen sufrir fallos en el handshake SSL o tiempos de espera, mientras que nuestra pasarela está desplegada en centros de datos locales, lo que mejora notablemente la estabilidad de las interfaces de imagen. Esto es crucial para ejecutar tareas de evaluación prolongadas.
Conclusión
El caso de auditoría de recibos con OpenAI merece ser estudiado a fondo porque desglosa el problema abstracto de "cómo usar IA para resolver un problema de negocio real" en tres etapas, 18 indicadores de evaluación y una práctica de ingeniería cuantificable en dólares. Es el ejemplo de ingeniería de IA que más falta hace actualmente en la comunidad hispanohablante.
Si estás desarrollando cualquier aplicación de IA que implique "introducir documentos/imágenes y obtener decisiones estructuradas", te recomendamos encarecidamente que ejecutes este cookbook completo. No te limites a leer, hazlo tú mismo; el verdadero valor del diseño basado en evaluación se siente en el momento en que ves los cambios en los indicadores. Sugerimos replicar esto a través de plataformas de API proxy como apiyi.com, lo que te ahorrará todos los problemas de configuración del entorno y te permitirá centrarte en la metodología.
Graba las palabras "evaluación dirigida" en tu proceso de desarrollo y tu sistema de IA dejará de ser un juguete que "parece funcionar" para convertirse en un producto de ingeniería listo para producción y con un ROI claro. Esa diferencia podría ser de 75.000 dólares.
📌 Autor: Equipo de APIYI — Seguimiento a largo plazo de casos prácticos de ingeniería con APIs multimodales de OpenAI / Anthropic / Google. Para más guías prácticas de cookbook y acceso a nuestra API, visita el centro de documentación en apiyi.com.