Lo más difícil de crear contenido en Xiaohongshu no es escribir el copy, sino diseñar las imágenes. Una portada debe integrar título, subtítulo, puntos de venta, marca y elementos decorativos; su densidad de información es comparable a la de una infografía. Si sumas el tiempo en Canva, el diseño en Figma y los retoques en Photoshop, el proceso suele llevarte fácilmente 2 horas.
El lanzamiento de gpt-image-2 por parte de OpenAI en abril de 2026 cambió las reglas del juego. No solo elevó la precisión del renderizado de texto dentro de las imágenes por encima del 95%, sino que, por primera vez, incorpora capacidades de agente con "búsqueda en tiempo real + razonamiento para la generación". Si le pides: "Haz una comparativa sobre los colores del nuevo iPhone 17", el modelo buscará primero la información oficial y luego generará una infografía de alta densidad con modelos, colores y especificaciones reales.
En este artículo, explicaremos sistemáticamente la metodología completa para la creación de contenido en Xiaohongshu con gpt-image-2, desde el análisis de sus capacidades principales y un flujo de trabajo práctico de 5 pasos, hasta plantillas de indicación y preguntas frecuentes, para ayudarte a reducir el tiempo de diseño de 2 horas a solo 5 minutos.
Por qué las capacidades de creación de gpt-image-2 para Xiaohongshu son tan destacadas
Antes de gpt-image-2, los creadores de Xiaohongshu que usaban IA enfrentaban tres grandes problemas: renderizado de texto impreciso, incapacidad para manejar alta densidad de información y obsolescencia de los conocimientos. Una portada viral suele requerir entre 50 y 100 palabras, y los modelos anteriores (incluidos gpt-image-1 y Midjourney v6) generaban a menudo errores ortográficos, caracteres incompletos o deformaciones, siendo casi imposibles de usar directamente.
gpt-image-2 ha cambiado este panorama radicalmente gracias a tres avances tecnológicos. Primero, la actualización integral de su motor de renderizado de texto; según pruebas oficiales de OpenAI, la precisión de renderizado de alta fidelidad en caracteres no latinos (chino, japonés, coreano, hindi, bengalí, etc.) supera el 95%, permitiendo salidas estables incluso en tamaños de letra pequeños, superficies curvas o diseños densos.
En segundo lugar, su arquitectura de razonamiento de agente (Agentic Reasoning). gpt-image-2 es el primer modelo de imagen del sector con un ciclo cerrado de razonamiento completo: "pensar → buscar → generar → verificar", planificando la composición, consultando referencias y evaluando la calidad antes de generar.
En tercer lugar, su conocimiento integrado de navegación web. Al generar imágenes que involucran los últimos productos, logotipos de marcas, figuras públicas o eventos de actualidad, el modelo puede consultar Internet en tiempo real en lugar de depender de datos obsoletos anteriores a su fecha de corte de entrenamiento (diciembre de 2025).
💡 Recomendación de plataforma: Si quieres experimentar directamente la capacidad de generación con acceso a internet de gpt-image-2, puedes usar el modelo gpt-image-2-all disponible en la plataforma APIYI (apiyi.com). Esta es una versión conectada mediante ingeniería inversa desde la interfaz web oficial de ChatGPT, que tiene la búsqueda web activada por defecto sin necesidad de configurar parámetros adicionales, ideal para escenarios de creación de contenido en Xiaohongshu que requieren "actualidad informativa".
Análisis de las 3 dimensiones clave de las capacidades de gpt-image-2 para Xiaohongshu
Para entender por qué gpt-image-2 es especialmente adecuado para Xiaohongshu, debemos desglosar sus capacidades y ver cómo encajan con el formato de contenido de esta plataforma. La siguiente tabla compara las mejoras de gpt-image-2 frente a la generación anterior, gpt-image-1, en los escenarios clave de Xiaohongshu.
| Dimensión de capacidad | gpt-image-1 | gpt-image-2 | Valor para Xiaohongshu |
|---|---|---|---|
| Renderizado de texto en chino | 60-70% de precisión, errores frecuentes | 95%+ de precisión, texto pequeño estable | Listo para portadas y texto en infografías |
| Imágenes por salida | 1 imagen | 1-10 imágenes opcionales | Genera un carrusel completo de 9 fotos |
| Resolución máxima | 1024×1024 | 2K (lado largo 3840px) | Cumple con portadas HD en 3:4 |
| Relación de aspecto | 3 tipos | 9 tipos (incluye 3:4) | Adaptación perfecta a portadas |
| Conocimiento conectado | Ninguno | Búsqueda web integrada | Referencias precisas de productos y tendencias |
| Razonamiento visual | Ninguno | Razonamiento agente | Planificación automática de infografías |
Ventaja 1 de gpt-image-2 para Xiaohongshu: Renderizado de infografías de alta densidad
Las "infografías", "tarjetas de contenido" y "gráficos educativos" de Xiaohongshu son tipos de contenido de alta interacción. Su característica típica es que cada imagen contiene entre 80 y 150 palabras, lo que requiere una jerarquía, combinación de colores e iconos claros. La mejora de gpt-image-2 en este escenario proviene de tres detalles:
Primero, gradiente de tamaño de fuente. El modelo puede entender instrucciones jerárquicas como "título principal 60pt + subtítulo 32pt + cuerpo 18pt", manteniendo proporciones estables en el resultado.
Segundo, control de espacios en blanco. El razonamiento del agente realiza una "composición virtual" antes de dibujar, evitando que el texto se amontone o se corte en los bordes.
Tercero, mezcla de iconos y texto. El modelo puede insertar iconos correspondientes (✓, ★, →, insignias numéricas, etc.) en posiciones específicas, asegurando que estén alineados con el texto.
Ventaja 2 de gpt-image-2 para Xiaohongshu: Precisión garantizada mediante conocimiento conectado
Esta es la capacidad más subestimada de gpt-image-2. El conocimiento de los modelos de IA tradicionales se limita a sus datos de entrenamiento; cuando les pides generar "comparativa de colores del nuevo iPhone 17", "ranking de marcas de café 2026" o "últimas tendencias de belleza", es muy probable que inventen información errónea.
En su fase de "pensamiento" interno, gpt-image-2 determina si la tarea requiere información externa. Si es así, activa automáticamente la búsqueda web y fusiona los datos reales encontrados (parámetros de producto, formas de logotipos, colores oficiales) en el proceso de generación. Esto significa que los creadores de Xiaohongshu pueden usarlo con confianza para comparativas de productos, recomendaciones y contenido educativo, sin miedo a las "alucinaciones" de la IA.
🎯 Sugerencia de integración API: Para utilizar la función de conexión a la red de gpt-image-2, se necesita una plataforma de servicio proxy de API que soporte capacidades completas. Recomendamos acceder al modelo
gpt-image-2-alla través de APIYI (api.apiyi.com). Este modelo proviene del canal oficial, incluye por defecto la capacidad de búsqueda web y tiene un precio más amigable que la conexión directa a la API oficial, ideal para creadores que necesitan generar imágenes en lote.
Ventaja 3 de gpt-image-2 para Xiaohongshu: Múltiples proporciones y salida de varias imágenes
La relación de aspecto estándar para la portada de Xiaohongshu es 3:4 (vertical), el formato cuadrado 1:1 es ideal para tarjetas de información y el 9:16 para portadas de videos cortos. gpt-image-2 admite nativamente estos 3 formatos (además de otros 6: 1:1, 2:3, 3:2, 4:3, 4:5, 16:9, 21:9), eliminando la necesidad de recortes posteriores.
Lo más importante es que gpt-image-2 permite generar de 1 a 10 imágenes en una sola solicitud. La longitud ideal para una nota de Xiaohongshu es de 6 a 9 imágenes (lo que recibe mayor peso del algoritmo), por lo que los creadores pueden pedir al modelo que genere un carrusel completo sobre el mismo tema de una sola vez, manteniendo un estilo visual unificado.

Matriz de adaptación de contenido para Xiaohongshu con gpt-image-2
Cada tipo de contenido en Xiaohongshu tiene requisitos de imagen específicos. La siguiente tabla te ayudará a determinar rápidamente el nivel de adecuación y los parámetros recomendados para gpt-image-2 según el formato.
| Tipo de contenido | Relación de aspecto | Cantidad | Densidad de texto | Adecuación de gpt-image-2 | Calidad recomendada |
|---|---|---|---|---|---|
| Divulgación de conocimientos | 3:4 | 6-9 imágenes | Alta (80-150 palabras/imagen) | ⭐⭐⭐⭐⭐ | high |
| Tarjetas de reseñas de productos | 3:4 | 6-9 imágenes | Media (40-80 palabras/imagen) | ⭐⭐⭐⭐⭐ | high |
| Tutoriales paso a paso | 3:4 | 4-9 imágenes | Media (50-100 palabras/imagen) | ⭐⭐⭐⭐⭐ | medium-high |
| Visualización de datos | 3:4 / 1:1 | 1-3 imágenes | Alta (100+ palabras/imagen) | ⭐⭐⭐⭐⭐ | high |
| Recomendaciones de comida/moda | 3:4 | 6-9 imágenes | Baja (basado en etiquetas) | ⭐⭐⭐⭐ | medium |
| Portada de Vlog | 9:16 | 1 imagen | Media (título principal) | ⭐⭐⭐⭐ | high |
| Memes/Chistes | 1:1 | 1 imagen | Baja | ⭐⭐⭐ | low-medium |
Como se puede observar, gpt-image-2 destaca principalmente en contenido informativo con una densidad de texto de media a alta, que es precisamente el tipo de contenido con "alta tasa de guardado" que prefiere el algoritmo de Xiaohongshu. Según la ponderación del algoritmo CES oficial de Xiaohongshu, los guardados valen 1 punto (al igual que los "me gusta"), mientras que los comentarios y las veces compartidas valen 4 puntos cada uno. Las infografías, tutoriales y reseñas, gracias a su "valor práctico", tienen tasas de guardado significativamente más altas que otros tipos, lo que les permite obtener más tráfico orgánico.
Proceso práctico en 5 pasos para crear imágenes para Xiaohongshu con gpt-image-2
Entremos en la parte práctica. El flujo completo para generar imágenes de Xiaohongshu con gpt-image-2 consta de 5 pasos, cada uno con técnicas reutilizables.
Paso 1: Desglose de temas y planificación de densidad de información
Antes de abrir gpt-image-2, dedica 5 minutos a desglosar el tema. Una buena nota informativa en Xiaohongshu debe responder a tres preguntas:
- ¿Quién es el lector objetivo? (Principiante / Avanzado / Tomador de decisiones)
- ¿Cuánta información clave hay? (3 puntos / 5 puntos / 7 puntos)
- ¿Cuánta información contendrá cada imagen? (Una idea por imagen / Comparativas en una imagen)
Ejemplo: Para una nota sobre "Comparativa de herramientas de IA para dibujo 2026", puedes desglosarla en 9 imágenes: 1 portada + 1 tabla general + 5 introducciones de herramientas (una por imagen) + 1 conclusión con recomendaciones + 1 llamada a la acción. La información principal de cada imagen debe controlarse por debajo de las 80 palabras.
Paso 2: Redacción de una indicación (prompt) estructurada para gpt-image-2
La escritura de indicaciones para gpt-image-2 sigue una estructura oficial recomendada: Fondo/Escenario → Sujeto → Detalles clave → Contenido de texto → Restricciones de estilo. Para que las imágenes generadas sean estables y utilizables, hay 4 reglas de oro:
- El texto en chino debe estar envuelto en comillas dobles chinas 「」 o comillas inglesas "" para que el modelo lo renderice con precisión.
- Especifica claramente la jerarquía del tamaño de fuente en el prompt (ej. "título principal 64pt en negrita, subtítulo 28pt").
- Utiliza palabras clave como "high-fidelity", "ultra-detailed" o "crisp typography" para mejorar los detalles.
- Incluye restricciones negativas (ej. "no watermark, no extra text, no duplicate words") para evitar elementos innecesarios.
Paso 3: Invocación del modelo mediante la API de gpt-image-2
Si tienes conocimientos básicos de programación, puedes invocar gpt-image-2 directamente usando la interfaz estándar de OpenAI. Aquí tienes un código simple para generar una portada de 3:4 para Xiaohongshu:
from openai import OpenAI
client = OpenAI(
api_key="your_apiyi_key",
base_url="https://api.apiyi.com/v1"
)
response = client.images.generate(
model="gpt-image-2-all",
prompt='Portada infográfica estilo Xiaohongshu, vertical 3:4, título principal 「TOP 5 herramientas de dibujo IA 2026」 64pt blanco en negrita, subtítulo 「Imperdible, guárdalo」 28pt gris claro, muestra 5 logos de herramientas en el centro, fondo degradado de rosa a morado, high-fidelity typography, crisp text, no watermark',
size="1024x1536",
quality="high",
n=1
)
print(response.data[0].url)
📌 Nota sobre la configuración de
base_url: El código anterior utiliza el endpointapi.apiyi.com/v1de APIYI. El nombre del modelogpt-image-2-alles la versión oficial con búsqueda web habilitada por defecto. Los usuarios comunes también pueden usar el modelo estándargpt-image-2(sin búsqueda web) a un menor costo.
Paso 4: Generación por lotes para carruseles de 9 imágenes
El número ideal de imágenes para una nota en Xiaohongshu es de 6 a 9. Si escribes manualmente cada indicación, la eficiencia será muy baja. El parámetro n de gpt-image-2 admite valores de 1 a 10, permitiendo generar hasta 9 imágenes de una sola vez.
Un consejo importante: No dejes que el modelo genere 9 imágenes aisladas, utiliza el prompt para guiarlo a crear una "serie". Ejemplo:
response = client.images.generate(
model="gpt-image-2-all",
prompt='''Genera un conjunto de 9 imágenes coherentes para un carrusel informativo en Xiaohongshu, vertical 3:4,
fondo morado oscuro uniforme + texto blanco, tema "5 fórmulas de Prompt esenciales para dibujo con IA",
Imagen 1: Portada, título 「Indispensable en dibujo con IA」 subtítulo 「5 fórmulas de Prompt」,
Imagen 2-6: Cada una presenta una fórmula, numeración superior 01-05, nombre de la fórmula en el centro, explicación de 30 palabras en la parte inferior,
Imagen 7: Tabla comparativa de fórmulas,
Imagen 8: Muestra de casos prácticos,
Imagen 9: Página de llamada a la acción, texto 「Guarda y dale like para no perderte nada」 ''',
size="1024x1536",
quality="high",
n=9
)
Paso 5: ¿No sabes programar? Usa la herramienta web imagen.apiyi.com
Si eres un creador de contenido puro y no tienes experiencia con Python o APIs, puedes omitir la parte de código. Recomendamos usar la herramienta web imagen.apiyi.com, que integra modelos como gpt-image-2, Nano Banana y Seedream. Ofrece una interfaz de formulario muy sencilla, permite elegir proporciones, controlar la cantidad de imágenes y realizar descargas por lotes; estarás listo en 5 minutos.
🎨 Sugerencia de herramientas: Para creadores puros, recomendamos usar directamente la herramienta web imagen.apiyi.com: sin necesidad de escribir código ni configurar APIs. Simplemente elige el modelo (se recomienda gpt-image-2 o gpt-image-2-all) y la proporción (3:4) para empezar. Para estudios que necesiten automatización por lotes, se sugiere usar la API de APIYI (apiyi.com) para conectarla a tus propias herramientas SaaS o tablas de Feishu.
Biblioteca de plantillas de indicadores para éxitos virales en Xiaohongshu con gpt-image-2
A continuación, presento 6 plantillas de indicadores (prompts) validadas y optimizadas para los tipos de contenido más frecuentes en Xiaohongshu. Todas han sido ajustadas para mejorar el renderizado de texto y puedes usarlas directamente sustituyendo el contenido entre corchetes 【】 por tu propio tema.
Plantilla 1: Tarjeta de divulgación de conocimientos (Alta densidad informativa)
Estilo Xiaohongshu para tarjeta de divulgación, formato vertical 3:4,
Barra de título superior: fondo morado oscuro, título en chino en negrita de color blanco 「【Tu título principal, menos de 15 caracteres】」 tamaño 56pt,
Subtítulo 「【Descripción de valor en una frase, menos de 20 caracteres】」 tamaño 24pt morado claro,
Zona de contenido central: 5 puntos numerados, cada punto incluye insignia numérica + título + explicación de 30 caracteres,
Parte inferior: botón CTA rosa 「Guardar para no perderlo」,
Paleta de colores: morado oscuro principal #2D1B69, rosa brillante de acento #FF6B9D,
high-fidelity Chinese typography, crisp text rendering, no watermark, no duplicate text
Plantilla 2: Tarjeta de comparación de productos
Tarjeta de comparación de productos estilo Xiaohongshu, formato vertical 3:4, fondo blanco,
Superior: fotos de dos productos a los lados + nombres 「【Producto A】」 vs 「【Producto B】」,
Central: tabla comparativa de 5 filas, cada fila incluye dimensión + puntuación A + puntuación B,
Puntuación mediante iconos de 5 estrellas (★),
Inferior: conclusión recomendada 「Recomendación general: 【Nombre del producto】」,
Tipografía clara y nítida, líneas de tabla de 1px gris claro, título principal en negrita 48pt,
high-fidelity, ultra-detailed, no extra elements
Plantilla 3: Esquema de pasos para tutoriales
Diagrama de pasos de tutorial estilo Xiaohongshu, formato vertical 3:4, fondo beige cálido,
Título superior 「【Tema】listo en 3 minutos」 color negro en negrita 56pt,
Central: 3 bloques de pasos dispuestos verticalmente,
Cada bloque: número de paso grande a la izquierda (01/02/03), a la derecha título del paso + explicación de 25 caracteres,
Inferior: imagen del resultado final + texto 「¡Listo!」,
Estilo de iconos de ilustración dibujados a mano, color de acento naranja cálido,
crisp typography, clear hierarchy, no watermark
Plantilla 4: Tarjeta de visualización de datos
Tarjeta de datos estilo Xiaohongshu, formato vertical 3:4, fondo con degradado azul oscuro,
Título superior 「【Tema de datos】datos más recientes de 2026」 color blanco 52pt,
Central: 1 número grande central 「【Dato clave】」 que ocupa el 40% de la altura,
Debajo del número: nota de fuente de datos 12pt azul claro,
Parte centro-inferior: 3 filas de datos complementarios, cada una con icono + dato + descripción breve,
Inferior: CTA en color claro 「Reenviar y compartir con colegas」,
Paleta de colores: degradado de azul oscuro #0F172A a #1E40AF, texto blanco de alto contraste,
high-fidelity typography, crisp small text, no extra words
Plantilla 5: Lista de recursos imprescindibles
Portada de lista de recursos estilo Xiaohongshu, formato vertical 3:4,
Superior: barra horizontal verde fluorescente, texto negro en negrita 「【Número】 de 【Tema】」 60pt,
Subtítulo 「Colección privada del creador, mira y copia directamente」 24pt,
Central: 【Número】 puntos de lista, cada uno incluye icono ✓ + nombre del ítem,
Diseño compacto pero con espacios en blanco razonables, gradiente de tamaño de fuente claro,
Inferior: borde rosa + texto 「Mira la lista completa en la siguiente imagen」,
Estilo: minimalista y moderno, diseño tipo Notion,
high-fidelity Chinese text, crisp icons, no decorative noise
Plantilla 6: Escenario especial de generación con conexión a red (exclusivo para gpt-image-2-all)
Tarjeta de recomendación de producto nuevo estilo Xiaohongshu, formato vertical 3:4,
Tema: Introducción a 【Nombre del producto más reciente, ej. iPhone 17 Pro Max】,
Por favor, busca en línea los colores oficiales más recientes, parámetros clave y fecha de lanzamiento de este producto,
Superior: renderizado fotorrealista del producto,
Central: nombre del producto + 3 puntos de venta clave (colores/capacidad/precio),
Inferior: texto de recomendación 「¿Vale la pena comprarlo? Decide después de leer」,
Estilo: minimalista estilo Apple, fondo blanco,
high-fidelity, accurate product details from web search, no fictional specs
💡 Consejos de uso: Las plantillas anteriores han sido optimizadas para el renderizado de texto en chino. Se recomienda usar
quality="medium"en el primer intento para verificar la composición y, una vez confirmada la disposición, cambiar aquality="high"para el resultado final; esto puede ahorrar entre un 30% y un 40% de costes. Para una producción en masa, se recomienda conectar a través de APIYI (apiyi.com), cuya estabilidad y velocidad son superiores a la conexión directa.
gpt-image-2 frente a herramientas tradicionales: Comparativa de capacidades
Muchos creadores preguntan: existiendo Canva, Figma o Photoshop, ¿por qué cambiar a gpt-image-2? La siguiente tabla compara la eficiencia real de las cuatro herramientas en los escenarios operativos clave de Xiaohongshu.
| Dimensión de comparación | gpt-image-2 | Canva | Figma | Photoshop |
|---|---|---|---|---|
| Tiempo por imagen | 30 s – 1 min | 15-30 min | 30-60 min | 1-2 horas |
| Tiempo para 9 imágenes | 5 min (n=9) | 3-4 horas | 4-6 horas | 8+ horas |
| Renderizado de texto | >95% exacto | 100% (manual) | 100% (manual) | 100% (manual) |
| Capacidad creativa | Alta (generada por IA) | Media (plantillas) | Baja (desde cero) | Baja (desde cero) |
| Conocimiento en red | ✅ Integrado | ❌ | ❌ | ❌ |
| Barrera de entrada | Baja (saber escribir) | Baja | Media | Alta |
| Coste mensual | $5-30 (según uso) | $12.99 mensual | $15 mensual | $22.99 mensual |
| Escenario ideal | Producción masiva | Uso de plantillas | Colaboración | Retoque comercial |
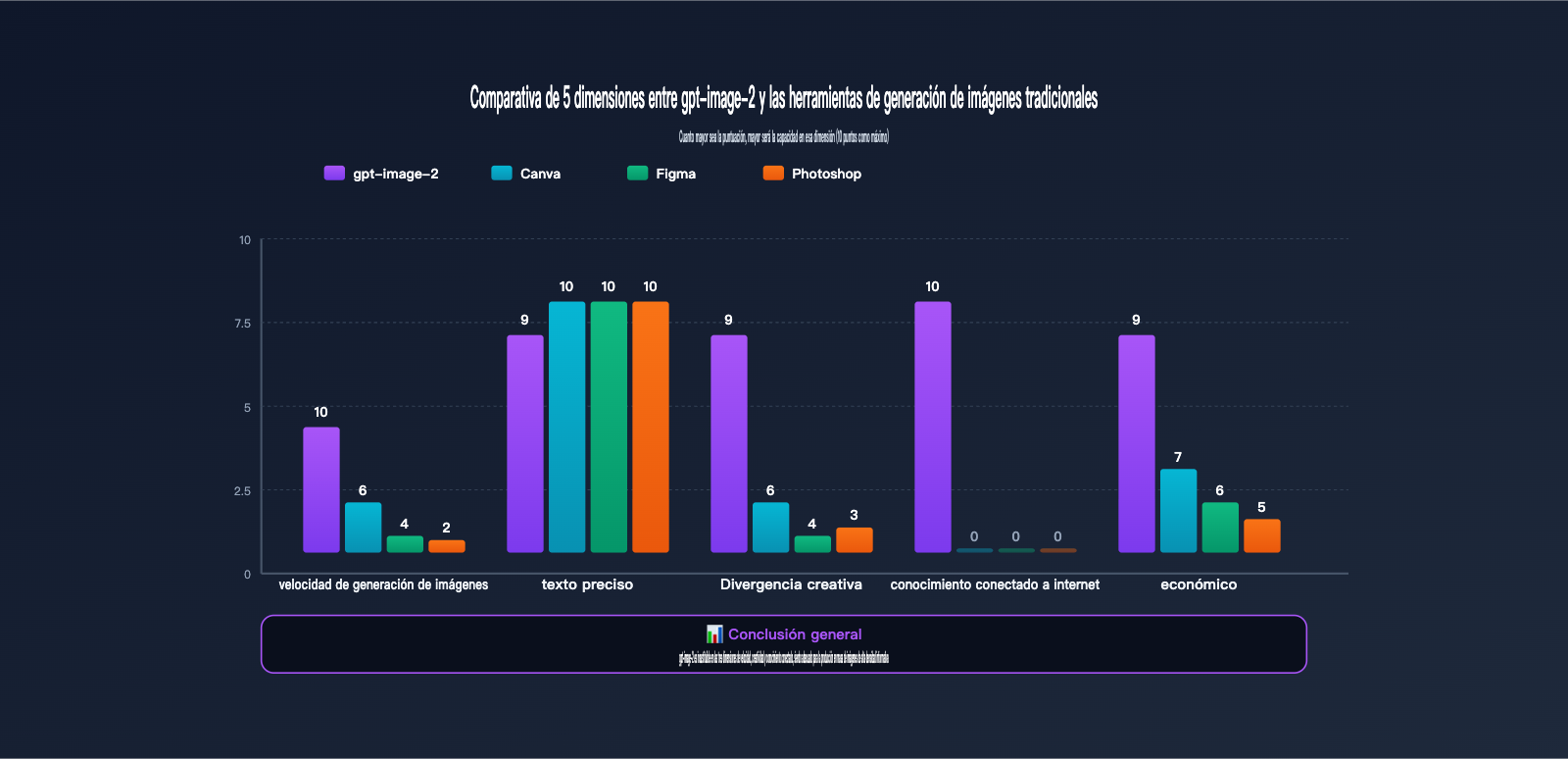
Como se puede apreciar en la tabla, gpt-image-2 no viene a reemplazar a Canva o Figma, sino a cubrir un escenario totalmente nuevo: la combinación de "creatividad, producción masiva y conocimientos conectados" en uno solo. Si tu cuenta de Xiaohongshu necesita publicar constantemente entre 3 y 5 notas gráficas por semana, gpt-image-2 puede reducir el tiempo dedicado a la creación de imágenes de 8-10 horas a menos de 1 hora.
FAQ: Preguntas frecuentes sobre la gestión de contenido en Xiaohongshu con gpt-image-2
P1: ¿Es cierto que las imágenes de Xiaohongshu generadas por gpt-image-2 no tienen errores con el chino?
Las pruebas muestran una precisión superior al 95%. OpenAI especificó en su blog oficial que gpt-image-2 es un Modelo de Lenguaje Grande "políglota", con mejoras significativas en caracteres no latinos como chino, japonés y coreano. Sin embargo, hay que tener en cuenta dos cosas: primero, el texto en chino dentro de la indicación debe ir entre comillas (por ejemplo, "texto aquí"), de lo contrario, el modelo podría tratarlo como una "interpretación" en lugar de una "copia"; segundo, los caracteres poco comunes o tradicionales aún pueden presentar errores, por lo que se recomienda revisar los textos clave antes de publicar.
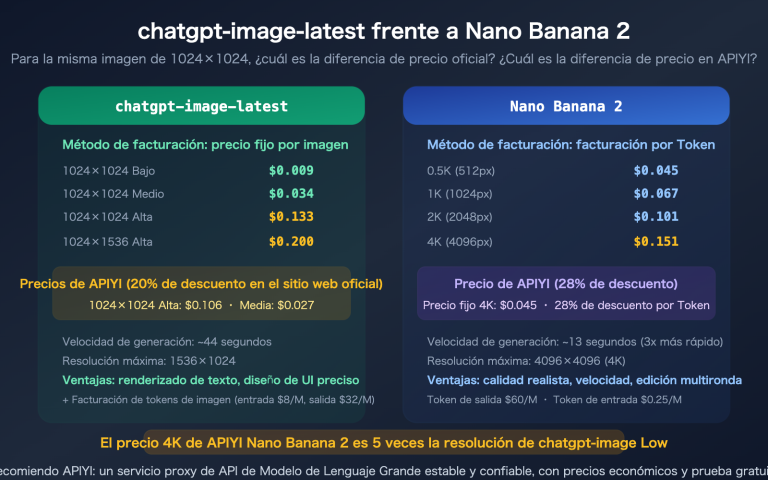
P2: ¿Cuánto cuesta aproximadamente generar una imagen de 3:4 para Xiaohongshu con gpt-image-2?
Según los precios oficiales, una imagen de alta calidad de 1024×1536 (3:4) cuesta entre $0.20 y $0.25 USD. Si haces un carrusel de 9 imágenes, costará entre $1.8 y $2.3 USD (aprox. 13-17 RMB). Al acceder a través del servicio proxy de API APIYI (apiyi.com), el precio suele ser más bajo y admite pagos en RMB y facturación, lo que lo hace ideal para creadores locales que necesitan producción masiva.
P3: ¿Cómo se usa la función de "generación de imágenes con conexión a internet" de gpt-image-2?
La función de conexión a internet está activada por defecto en la versión web de ChatGPT (modo Thinking), mientras que en la API se requiere usar una variante del modelo que soporte esta función. Al invocar el modelo gpt-image-2-all a través de APIYI (apiyi.com), la búsqueda en internet está activada por defecto: solo tienes que mencionar en tu indicación la información real que necesitas consultar (como "lanzamientos recientes", "colores oficiales" o "parámetros reales"), y el modelo activará automáticamente la búsqueda web para integrar los resultados en el proceso de generación.
P4: No sé programar, ¿puedo usar gpt-image-2 para Xiaohongshu?
Por supuesto. Recomendamos utilizar la herramienta web imagen.apiyi.com. No requiere configuración de API ni entorno de Python; simplemente selecciona el modelo en el formulario web (gpt-image-2 o gpt-image-2-all), escribe tu indicación, elige el formato (3:4) y la cantidad, y haz clic en generar. Es compatible con interfaz en chino, descarga por lotes y gestión de historial, ideal para creadores de contenido puros.
P5: ¿Las imágenes de Xiaohongshu generadas por gpt-image-2 serán limitadas por ser "generadas por IA"?
Actualmente, Xiaohongshu no tiene reglas públicas que limiten el alcance por "imágenes generadas por IA". El núcleo del algoritmo evalúa la tasa de interacción (me gusta, guardados, comentarios, compartidos, seguidores). Mientras tus imágenes tengan una alta densidad de información y aporten valor al lector, recibirás retroalimentación positiva de forma natural. Se recomienda indicar la fuente de la imagen en el texto (puedes poner "producido con asistencia de IA") para aumentar la transparencia del contenido.
P6: ¿Cuántas imágenes puede generar gpt-image-2 a la vez?
En la API, la solicitud única permite hasta 10 imágenes (n=10), mientras que en la versión web de ChatGPT el límite es de 8. Para el formato de carrusel de 9 imágenes de Xiaohongshu, la API puede completarlo de una sola vez, lo que es significativamente más eficiente que otros modelos. Ten en cuenta que a mayor valor de "n", mayor será el tiempo de espera y procesamiento; se recomienda configurar tareas asíncronas para la producción masiva.
P7: ¿Qué modelo es mejor para Xiaohongshu: gpt-image-2, Nano Banana Pro o Seedream?
En resumen: gpt-image-2 es ideal para contenido con "alta densidad de información y mucho texto" (infografías, tarjetas de reseñas, gráficos de datos); Nano Banana Pro es mejor para "escenarios creativos y consistencia facial" (historias en serie, narrativas con múltiples imágenes); y Seedream es perfecto para "estética oriental y renderizado en chino" (Hanfu, estilo nacional, tinta china). Puedes probar los tres modelos en imagen.apiyi.com; te sugerimos hacer pruebas A/B antes de elegir tu modelo principal.
P8: ¿Cómo lograr que varias imágenes generadas por gpt-image-2 tengan un estilo uniforme?
Tres técnicas clave: primero, genera las 9 imágenes de una sola vez con n=9, el modelo mantendrá automáticamente la consistencia del estilo; segundo, bloquea la paleta de colores en la indicación (por ejemplo, "usar uniformemente violeta #2D1B69 + rosa #FF6B9D"); tercero, bloquea la estructura de diseño (por ejemplo, "todas las imágenes deben tener título arriba, contenido en el centro y llamada a la acción abajo"). Si necesitas una mayor consistencia de personajes o escenas, considera usar la función de edición de múltiples imágenes de gpt-image-2, generando a partir de una imagen de referencia.
Resumen: Las 3 lógicas fundamentales para usar gpt-image-2 en Xiaohongshu
Al llegar a este punto, podemos destilar 3 lógicas fundamentales para la creación de contenido en Xiaohongshu con gpt-image-2:
Primera: trata la generación de imágenes como un "diseño de producto" y no como "dibujar". El razonamiento agente de gpt-image-2 lo hace parecer más un "diseñador que piensa". Cuanto más se parezca tu indicación a un documento de requisitos de diseño (objetivos claros, jerarquía de información, restricciones visuales), más preciso será el resultado.
Segunda: utiliza la "densidad de información" como arma de diferenciación. El algoritmo de Xiaohongshu premia el contenido con alta tasa de guardados, y la esencia de esto es el "valor práctico". El avance de gpt-image-2 en el renderizado de texto y la maquetación te permite crear "infografías de alta densidad" que las plantillas de Canva no pueden igualar; este es el mejor camino para que las cuentas nuevas superen a la competencia.
Tercera: aprovecha el "conocimiento conectado a internet" para la actualidad del contenido. Para contenido que involucre productos nuevos, eventos de actualidad o datos oficiales, asegúrate de usar modelos como gpt-image-2-all que admitan conexión a internet, evitando así errores por información inventada por la IA.
🚀 Recomendación de acción: Si planeas integrar gpt-image-2 en tu flujo de trabajo de Xiaohongshu, sugerimos empezar por dos vías: los creadores puros pueden comenzar con la herramienta web imagen.apiyi.com, con la que obtendrás tu primera imagen en 3 minutos; los estudios con capacidad técnica pueden conectarse a través de la API de APIYI (api.apiyi.com) al modelo gpt-image-2-all para construir una línea de producción masiva. Ambos accesos admiten generación con conexión a internet, tienen precios amigables y son ideales para el uso a escala de equipos creativos locales.
Dominar gpt-image-2 no hará que tu cuenta de Xiaohongshu se vuelva viral de la noche a la mañana, pero puede reducir el costo de tiempo en la fase de creación de imágenes en un 90%, permitiéndote dedicar más energía a la planificación de temas, el pulido de textos y la gestión de la interacción, que son los factores que realmente impactan en los datos. Ese es el mayor valor de las herramientas de IA para los creadores de contenido.
Autor de este artículo: Equipo técnico de APIYI — Especialistas en la integración de API de modelos de lenguaje grandes y desarrollo de herramientas de creación de contenido. Visita apiyi.com para obtener más evaluaciones de modelos, plantillas de indicaciones y guías de desarrollo.