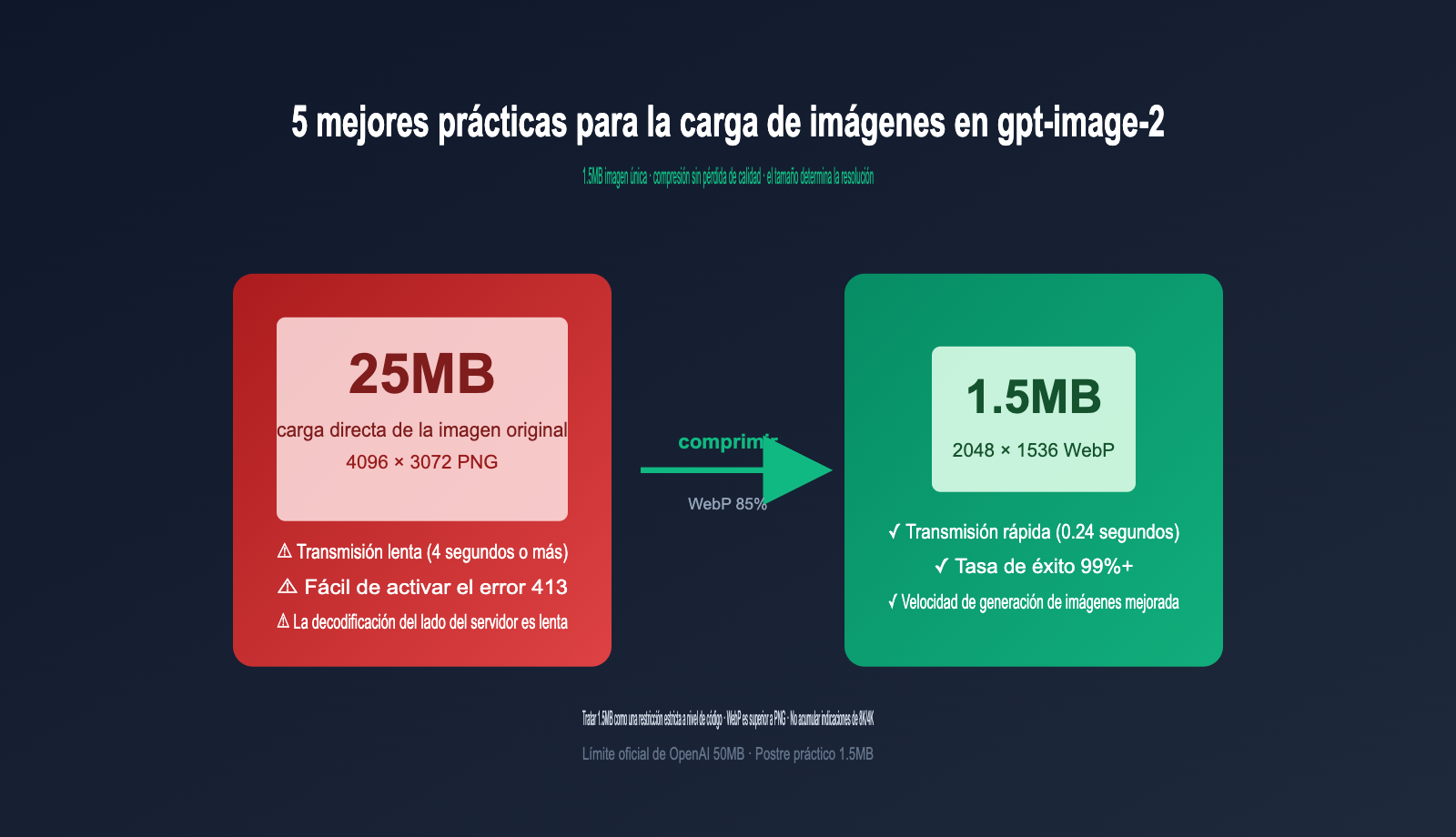
Muchos desarrolladores, al integrar por primera vez la interfaz de edición de imágenes gpt-image-2, suelen enviar la imagen original mediante POST de forma instintiva. Después de todo, la documentación oficial indica claramente un límite de 50 MB por imagen, ¿verdad? Sin embargo, tras realizar decenas de pruebas, notarás que comparar una imagen original de 20 MB con una comprimida de 1.5 MB revela que la velocidad de generación puede ser hasta 3 veces mayor, y la tasa de fallos (especialmente el error 413 Request Entity Too Large) aumenta drásticamente.
Basándome en una amplia experiencia práctica, presento 5 mejores prácticas para la carga de imágenes en gpt-image-2, respondiendo a las dos dudas que más dolores de cabeza causan a los desarrolladores: ¿cuál es el tamaño ideal de compresión? y ¿qué determina realmente la resolución de salida?
🎯 Conclusión clave: Se recomienda limitar la carga de imágenes para gpt-image-2 a menos de 1.5 MB. La resolución de salida viene determinada por el parámetro
size; escribir "8K" o "4K" en la indicación no sirve de nada. Todo el código de este artículo puede ejecutarse directamente mediante el servicio proxy de API de APIYI (apiyi.com), sin necesidad de una conexión a redes extranjeras.
Especificaciones de carga de imágenes en gpt-image-2: Límite oficial vs. Límite práctico
La documentación oficial de OpenAI para gpt-image-2 es bastante flexible respecto a las especificaciones de entrada, por lo que, a simple vista, parece que no hay mucho de qué preocuparse. Pero "poder usarlo" y "usarlo bien" son cosas muy distintas; en la práctica, es necesario establecer una línea roja más estricta.
La siguiente tabla compara los límites oficiales con los valores recomendados en la práctica, basados en la experiencia acumulada por desarrolladores locales:
| Dimensión | Límite oficial | Recomendación práctica | Razón de la diferencia |
|---|---|---|---|
| Tamaño por imagen | 50 MB | ≤ 1.5 MB | El tiempo total de transferencia y decodificación aumenta significativamente |
| Imágenes por solicitud | 16 imágenes | 1-4 imágenes | La superposición de imágenes reduce la tasa de éxito |
| Formatos admitidos | PNG / WEBP / JPG | WEBP / JPG (comprimido) | PNG suele ser demasiado pesado; WEBP ofrece la mejor relación calidad-precio |
| Píxeles por lado | Máx. 3840 | No más de 2048 | Internamente se realiza un submuestreo para extracción de características |
| Relación de aspecto | 1:3 ~ 3:1 | Cercana a la de salida | El desajuste de proporciones provoca rellenos o recortes innecesarios |
¿Por qué fijar el límite en 1.5 MB? Es el punto óptimo que equilibra el tiempo de transferencia, el tiempo de decodificación y la estabilidad de la red. Por debajo de 1.5 MB, la mayoría de las conexiones domésticas pueden transmitir la imagen en 1-2 segundos; por encima de 5 MB, el tiempo total de transferencia y decodificación crece de forma no lineal, y notarás claramente que la interfaz se queda "colgada".
💡 Experiencia práctica: Recomendamos establecer 1.5 MB como una restricción estricta en el código, utilizando librerías como PIL para realizar una compresión automática antes de la llamada. Al utilizar gpt-image-2 a través de APIYI (apiyi.com), la optimización de la transmisión de archivos pequeños en los nodos de centros de datos locales es notablemente efectiva.
¿Por qué se recomienda comprimir las imágenes a menos de 1.5 MB?
Muchos desarrolladores preguntan: si el límite oficial es de 50 MB, ¿por qué insistir en los 1.5 MB? En realidad, existen cuatro razones de ingeniería detrás de esto; cualquiera de ellas es suficiente para que te tomes en serio el tamaño de tus imágenes.
La primera razón es la latencia de transmisión, el factor más subestimado. Una imagen de 25 MB requiere unos 4 segundos de transmisión pura con un ancho de banda de subida de 50 Mbps, mientras que al comprimirla a 1.5 MB solo toma 0.24 segundos. Este tiempo se suma directamente al tiempo total de respuesta de la API.
La segunda razón es el riesgo de error 413. Los errores "413 Request Entity Too Large" relacionados con gpt-image-1 / gpt-image-2 son comunes en la comunidad. Incluso sin alcanzar el límite de 50 MB, la solicitud puede ser truncada en alguna capa de la red (CDN, proxy inverso, balanceador de carga). Comprimir la imagen por debajo de 1.5 MB ayuda a evitar estos errores y mejora la estabilidad de la invocación del modelo.
La tercera razón es el tiempo de decodificación en el servidor. Una vez que el servidor de OpenAI recibe la imagen, debe decodificarla, extraer características y realizar la incrustación vectorial. Estos pasos consumen tiempo proporcional al número total de píxeles. Aunque el ancho de banda no sea un cuello de botella, las imágenes grandes ralentizan la generación.
La cuarta razón es el costo de los reintentos. Si una llamada con una imagen grande falla, debes reenviar los 25 MB completos; en cambio, reintentar una imagen de 1.5 MB es casi imperceptible, lo que mejora drásticamente la fiabilidad de extremo a extremo.
Al cuantificar estas cuatro razones con datos reales, la comparación es clara: al subir la misma imagen original en tamaños de 25 MB, 5 MB, 1.5 MB y 500 KB a la interfaz de edición de gpt-image-2, y repetir el proceso 50 veces con la misma indicación y parámetros de tamaño, el tiempo total y la tasa de éxito muestran un punto de inflexión evidente. 1.5 MB es el punto óptimo de esta curva; comprimir más allá de eso ofrece rendimientos decrecientes y sacrifica calidad innecesariamente.
🔧 Consejo de optimización: Al invocar
gpt-image-2en entornos de producción, se recomienda encarecidamente que la "compresión antes de subir" sea un paso estándar en tu código, no una opción. Al utilizar los nodos de servicio proxy de API de apiyi.com para tareas por lotes, junto con una estrategia de compresión a 1.5 MB, la tasa de fallos por lote puede reducirse del 5-8% a menos del 1%; una diferencia significativa cuando manejas miles de llamadas al mes.
La compresión no equivale a pérdida de calidad: un mito muy extendido
Este es uno de los malentendidos más comunes entre los desarrolladores: "comprimir = pérdida de calidad = peor resultado en la generación de imágenes". Este juicio quizás era válido en la era JPEG de 2010, pero en la era de WebP y JPEG de alta calidad de 2026, está totalmente desactualizado.

La siguiente tabla compara los mitos comunes con los hechos para ayudarte a desarrollar una intuición correcta sobre el procesamiento de imágenes:
| Mito común | Hecho |
|---|---|
| La compresión siempre pierde calidad | WebP con calidad 85+ es visualmente indistinguible, igual que JPEG 90+ |
| Cuanto más grande la imagen, mejor la ve la IA | gpt-image-2 submuestrea imágenes grandes internamente; lo que excede la resolución de trabajo es desperdicio |
| PNG es mejor por ser sin pérdida | El tamaño de PNG suele ser 3-5 veces mayor que WebP, pero el resultado tras la decodificación es casi idéntico |
| Las herramientas de compresión alteran los colores | Las herramientas principales (Squoosh / TinyPNG / Sharp) conservan los perfiles de color ICC |
| Si la indicación es buena, no hace falta comprimir | La indicación y el tamaño de la imagen son dimensiones independientes; la compresión solo afecta la transmisión |
En cuanto a la elección de herramientas, puedes elegir una según tu escenario:
| Herramienta | Escenario de uso | Ventaja |
|---|---|---|
| PIL / Pillow | Procesamiento por lotes en backend Python | Integración sencilla, permite ajustar la calidad hasta cumplir el objetivo |
| Sharp (Node.js) | Servidor Node | Mejor rendimiento, procesa decenas de imágenes por segundo en un solo núcleo |
| Squoosh | Compresión de imagen única en frontend | WASM en navegador, comprime sin subir al servidor |
| TinyPNG | Procesamiento manual por diseñadores | Reduce la paleta de colores de forma inteligente, visualmente sin pérdida |
| Herramientas de captura | macOS / Windows | Seleccionar JPEG al 80% es suficiente |
Entender la "compresión" como un "paso de preprocesamiento necesario" en lugar de un "compromiso que daña el resultado" es la base psicológica para utilizar correctamente las API de imagen.
Un punto importante a aclarar: gpt-image-2 realiza un submuestreo interno de las imágenes muy grandes; su "resolución interna" de trabajo es mucho menor que el máximo que puedes subir. Esto significa que si envías una imagen original de 4000×3000 píxeles, el modelo podría estar viendo una versión submuestreada de 1024×1024. Los píxeles adicionales que envías son descartados por el modelo desde el principio, desperdiciando ancho de banda.
Al entender esto, la idea de que "la calidad antes y después de la compresión es casi idéntica" deja de ser una intuición y se convierte en una conclusión con base técnica. Comprimir la imagen al rango de 1024-2048 píxeles coincide perfectamente con la resolución de trabajo del modelo, evitando desperdicios y garantizando un rendimiento óptimo.
Resolución de salida de gpt-image-2: el parámetro size es el único interruptor
Si el "no perder calidad al comprimir" es el error más común en la carga de archivos, creer que "escribir 8K en la indicación genera una imagen 8K" es el mayor mito en la salida. En esta sección, aclararemos de una vez por todas cómo se determina realmente la resolución de salida de gpt-image-2.

El único parámetro que afecta la resolución de salida es size, nada más. Esta es una regla fundamental pero ampliamente malinterpretada. He preparado este experimento comparativo para ayudarte a entenderlo:
| Configuración de invocación API | Resolución de salida real |
|---|---|
size="1024x1024" + indicación sin "4K/8K" |
1024×1024 |
size="1024x1024" + indicación con "8K resolution" |
Sigue siendo 1024×1024 |
size="1024x1024" + indicación con "ultra HD 4K" |
Sigue siendo 1024×1024 |
size="1536x1024" + indicación con "low resolution" |
1536×1024 (size tiene prioridad) |
size="3840x2160" + cualquier indicación |
3840×2160 (experimental) |
La conclusión es clara: acumular palabras clave como "8K", "4K", "ultra HD" o "HQ" en la indicación no hará que tu imagen sea más grande o nítida; al contrario, solo desperdicias tokens de tu presupuesto de indicación.
Entonces, ¿qué valores admite el parámetro size? gpt-image-2 es mucho más flexible que la generación anterior, admitiendo tanto valores preestablecidos como personalizados:
| Método de configuración | Rango de valores | Nota |
|---|---|---|
| Estándar | 1024×1024 / 1536×1024 / 1024×1536 | Más estable, recomendado para uso diario |
| Personalizado (normal) | Múltiplos de 16 en ancho y alto | Ej: 1280×720, 1600×900 |
| Personalizado (grande) | Máximo 3840px por lado | Superior a 2560×1440 es experimental |
| Relación de aspecto | Entre 1:3 y 3:1 | No se admiten proporciones extremas |
| Límite de píxeles | 655,360 ~ 8,294,400 | Tiene límites superior e inferior |
Reserva las "descripciones de resolución" para contenido más valioso en tu indicación, como el estilo ("estilo pintura al óleo"), la composición ("toma en ángulo bajo"), la iluminación ("iluminación de hora dorada") o los materiales ("superficie de cerámica mate"). Estos son los elementos que realmente influyen en el resultado final.
Aquí hay un detalle contraintuitivo pero importante: elegir un size más grande no garantiza una imagen más detallada. Cuando seleccionas una resolución experimental alta como 3840×2160, el modelo realiza un sobremuestreo interno tras generar a baja resolución; la densidad de detalles no aumenta linealmente con los píxeles y, de hecho, la consistencia puede disminuir debido a un tiempo de generación más largo. El punto ideal para el flujo de trabajo diario es 1024×1024 o 1536×1024: son rápidos, detallados y tienen el precio de API más amigable.
📌 Consejo de limpieza de indicaciones: Antes de llamar a gpt-image-2, elimina todas las palabras clave inútiles como "8K", "4K", "ultra HD" o "high resolution" para dejar espacio a descripciones realmente útiles. Te recomendamos comparar los efectos de una misma indicación con diferentes parámetros
sizeen la plataforma apiyi.com para desarrollar tu intuición sobre la relación entre resolución y densidad de imagen.
Invocación práctica de gpt-image-2: código completo en Python para compresión y carga
Teoría terminada, vamos al código. El siguiente script en Python implementa el flujo completo: "compresión automática a menos de 1.5 MB → llamada a la interfaz de edición de gpt-image-2 → guardado de la salida". Puedes copiarlo y pegarlo en tu proyecto.
import io
import base64
from PIL import Image
from openai import OpenAI
# Invocación a través del servicio proxy de API APIYI, sin necesidad de red internacional
client = OpenAI(
base_url="https://vip.apiyi.com/v1",
api_key="Tu clave API de APIYI"
)
def compress_image(input_path: str, target_kb: int = 1500) -> bytes:
"""Comprime automáticamente la imagen al tamaño en KB especificado, priorizando formato WebP"""
img = Image.open(input_path).convert("RGB")
# Limita el lado máximo a 2048, escalando proporcionalmente si es necesario
if max(img.size) > 2048:
img.thumbnail((2048, 2048), Image.LANCZOS)
# Comienza con calidad 90, reduciendo de 5 en 5 hasta cumplir el objetivo
quality = 90
while quality >= 50:
buf = io.BytesIO()
img.save(buf, format="WEBP", quality=quality)
if len(buf.getvalue()) <= target_kb * 1024:
return buf.getvalue()
quality -= 5
# Respaldo: calidad mínima
buf = io.BytesIO()
img.save(buf, format="WEBP", quality=50)
return buf.getvalue()
# Llamada a la interfaz de edición de gpt-image-2
image_bytes = compress_image("./input.png", target_kb=1500)
result = client.images.edit(
model="gpt-image-2",
image=("input.webp", image_bytes, "image/webp"),
prompt="Cambia esta foto a estilo cyberpunk, luces de neón, escena callejera en noche lluviosa",
size="1536x1024", # La resolución de salida se decide aquí
output_format="webp", # Formato de salida
output_compression=85 # Nivel de compresión de salida 0-100
)
# Guardar salida
output_b64 = result.data[0].b64_json
with open("./output.webp", "wb") as f:
f.write(base64.b64decode(output_b64))
Este código tiene varios puntos clave. Primero, la función compress_image utiliza una estrategia de "reducción de calidad en bucle", lo que permite maximizar el uso del espacio de compresión manteniendo la calidad visual.
Segundo, el parámetro output_compression=85 solo es efectivo para formatos WebP/JPEG y controla la compresión de la imagen devuelta (por defecto es 100, sin compresión). Si necesitas mostrar la imagen directamente en una web, un valor entre 80 y 90 ofrece un equilibrio excelente entre calidad y velocidad de carga.
Tercero, la línea size="1536x1024" determina realmente la resolución de salida; sin importar lo que escribas en la indicación, la imagen resultante será de 1536×1024.
🚀 Consejo de integración: gpt-image-2 es compatible con el SDK nativo de OpenAI. Solo necesitas cambiar
base_urlyapi_keypara ejecutar el código en la plataforma APIYI (apiyi.com). Esta plataforma cuenta con optimizaciones de red específicas para interfaces de imagen, reduciendo significativamente la probabilidad de tiempos de espera y errores 413.
Preguntas frecuentes sobre la carga de imágenes en gpt-image-2
P1: ¿Qué es mejor, subir archivos PNG o WebP?
WebP ocupa entre 1/3 y 1/5 del tamaño de un PNG con la misma calidad visual, y tras la decodificación interna de gpt-image-2, el resultado es prácticamente idéntico. Por lo tanto, prioriza siempre el uso de WebP. A menos que tu imagen requiera un canal alfa (transparencia) crítico, como en el recorte de logotipos, no hay razón para usar PNG.
P2: ¿Cuántas imágenes de referencia puedo subir a la vez?
El límite oficial es de 16 imágenes, pero en la práctica, si superas las 4, la tasa de éxito disminuye notablemente y la atención del modelo sobre las referencias se diluye. Recomendamos usar 1 imagen de referencia principal y 1 o 2 de estilo; añadir más solo causará que el estilo de salida sea confuso.
P3: Si escribo "8K" en mi indicación, ¿no necesito comprimir la imagen?
El término "8K" en la indicación es una palabra clave ineficaz. No hará que la salida sea 8K (eso lo determina el parámetro size), ni permitirá que gpt-image-2 omita el procesamiento de compresión. Te sugerimos comparar los resultados antes y después de la compresión desde el panel de control de apiyi.com; verás que visualmente es casi imposible notar la diferencia.
P4: ¿Cuál es la resolución de salida máxima que admite el modelo?
El parámetro size admite hasta 3840×2160, pero todo lo que supere los 2560×1440 está etiquetado oficialmente como "experimental", por lo que la estabilidad y la consistencia pueden verse afectadas. Para entornos de producción, recomendamos limitarse a 1536×1024; es el punto óptimo entre velocidad y estabilidad.
P5: ¿Puedo ajustar áreas específicas de la imagen después de subirla?
Sí, a través del parámetro mask puedes especificar una máscara del mismo tamaño. El modelo solo generará contenido nuevo en las áreas transparentes de la máscara, manteniendo el resto intacto. Esta es una capacidad muy potente de la interfaz de edición de gpt-image-2, ideal para retoques locales o cambios de vestuario.
P6: ¿Qué hago si la tasa de fallos al invocar gpt-image-2 desde mi país es alta?
La conexión directa a OpenAI suele sufrir tiempos de espera o fallos en el handshake SSL, especialmente en interfaces de imagen, ya que el payload es mayor y más propenso a interrupciones que las de texto. Al cambiar la base_url a un servicio proxy de API como apiyi.com, desplegado en infraestructura local, y combinarlo con una estrategia de compresión de 1.5 MB, la tasa de éxito general puede estabilizarse por encima del 99%.
P7: ¿Realmente no se nota la diferencia de calidad tras la compresión? ¿Existe riesgo de comprimir demasiado?
Con una calidad WebP superior a 85 o JPEG superior a 90, no hay diferencia visual en imágenes naturales (personas, paisajes, productos). Sin embargo, en escenarios con texto denso (carteles, capturas de pantalla de presentaciones) o líneas nítidas (diagramas técnicos, pixel art), recomendamos subir la calidad a 92-95 o mantener el formato PNG para evitar artefactos de ruido en los bordes del texto. La función de compresión en Python que proporcionamos en el artículo ya establece un punto de partida de 90, lo cual es suficiente para la mayoría de los casos.
P8: ¿Qué diferencia hay en la estrategia de carga entre gpt-image-2 y gpt-image-1.5?
La estrategia general es la misma: 1.5 MB por imagen, prioridad a WebP y el tamaño determinado por size. La diferencia principal es que gpt-image-2 admite resoluciones personalizadas (múltiplos de 16) y resoluciones altas experimentales, mientras que gpt-image-1.5 solo admite preajustes fijos. Si estás migrando, puedes reutilizar tu código de compresión con total confianza.
Resumen
Volviendo a las dos preguntas clave del inicio, las respuestas ahora deberían ser muy claras.
Primera pregunta: ¿Qué tamaño es adecuado para subir imágenes a gpt-image-2? Aunque el límite oficial es de 50 MB, en la práctica, mantén el límite estricto por debajo de 1.5 MB. Es el punto ideal tras equilibrar la latencia de transmisión, el riesgo de error 413, el tiempo de decodificación y el costo de reintentos. La compresión moderna apenas pierde calidad, así que no hay necesidad de insistir en subir la imagen original.
Segunda pregunta: ¿Qué determina la resolución de salida? La única respuesta es el parámetro size, no la indicación. Elimina por completo términos como "8K", "4K" o "ultra HD" de tus plantillas de indicación y reserva tu valioso presupuesto de tokens para descripciones útiles sobre estilo, composición e iluminación.
Si integras estas dos reglas en tu flujo de trabajo, la velocidad y la tasa de éxito de tus invocaciones a gpt-image-2 mejorarán notablemente. Te recomendamos empezar con el código de compresión en Python que incluimos aquí, conectarte a través de apiyi.com para validar rápidamente y dedicar un par de días a encontrar tu combinación de parámetros ideal.
📌 Autor: Equipo de APIYI — Especialistas en la práctica de ingeniería con APIs multimodales de OpenAI, Anthropic y Google. Para más usos avanzados de gpt-image-2 y plantillas de indicación, visita el centro de documentación en apiyi.com.