Nota del autor: Comparativa de Gemini 3.1 Pro y Claude Sonnet 4.6 en 5 dimensiones clave (programación, razonamiento, multimodalidad, trabajo de conocimiento y precios) para ayudarte a elegir el modelo de vanguardia con mejor relación calidad-precio.
En febrero de 2026, el panorama de los modelos de IA presenta una situación interesante: la verdadera competencia ya no es "quién es el más fuerte", sino "quién es el rey de la relación calidad-precio". El Gemini 3.1 Pro de Google (lanzado el 19 de febrero) y el Claude Sonnet 4.6 de Anthropic (lanzado el 17 de febrero) llegaron casi al mismo tiempo, con precios similares y prometiendo un rendimiento cercano al nivel insignia. La elección para los desarrolladores nunca ha sido tan difícil.
Valor principal: Tras leer este artículo, tendrás clara la diferencia real entre ambos modelos en programación, razonamiento, multimodalidad y tareas de conocimiento, y sabrás cuál elegir para tu escenario específico.
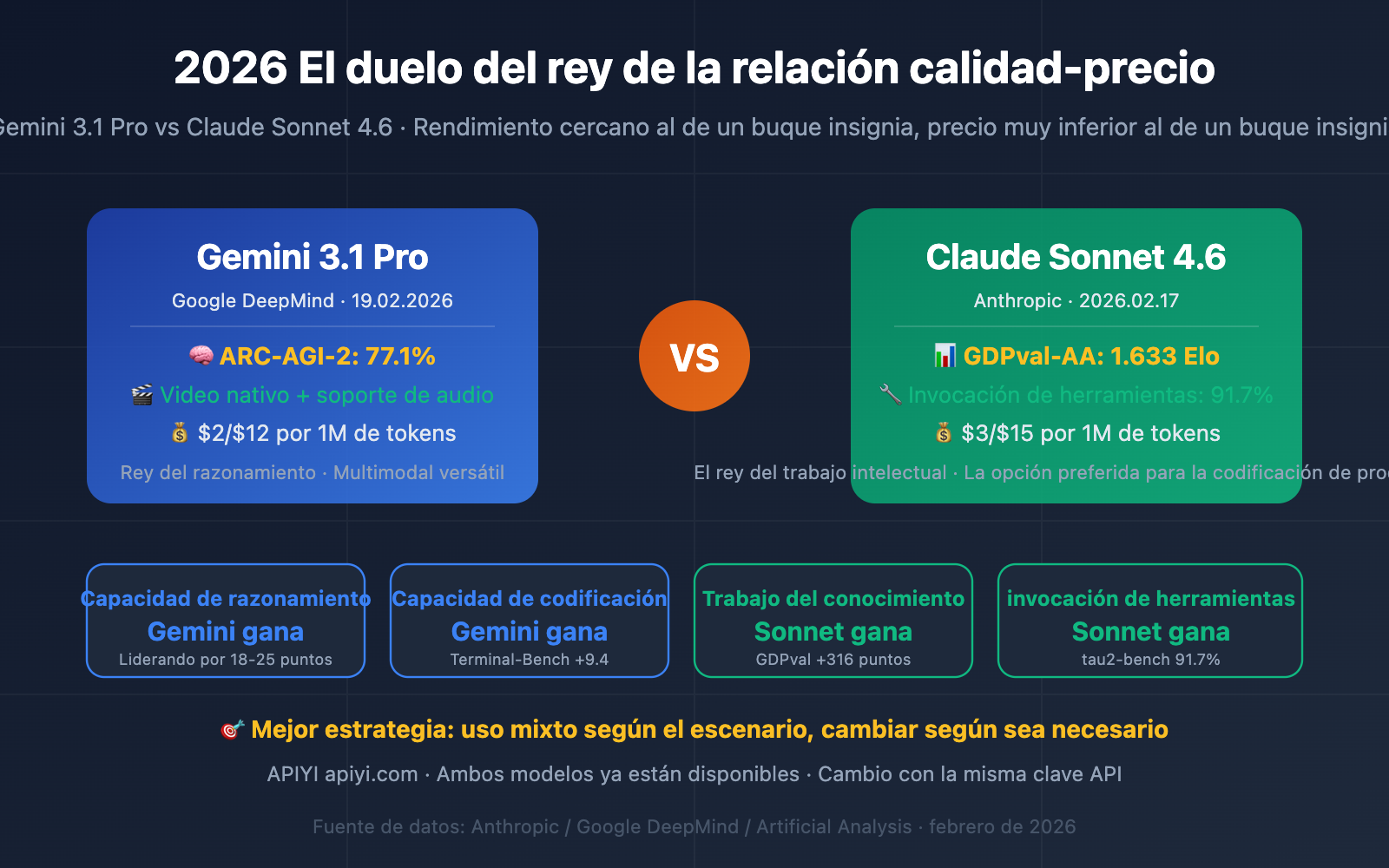
Comparativa de parámetros básicos: Gemini 3.1 Pro vs. Claude Sonnet 4.6
El posicionamiento de ambos modelos es muy similar: ambos son "pesos pesados" que ofrecen un rendimiento cercano al nivel insignia a un precio muy inferior, aunque sus rutas tecnológicas son distintas.
| Dimensión / Parámetro | Gemini 3.1 Pro | Claude Sonnet 4.6 | Explicación comparativa |
|---|---|---|---|
| Fecha de lanzamiento | 19.02.2026 | 17.02.2026 | Con solo 2 días de diferencia |
| Ventana de contexto | 1 millón (estándar) | 200K estándar / 1M Beta | Gemini tiene un millón nativo |
| Salida máxima | 64K tokens | 64K tokens | Exactamente iguales |
| Precio de entrada | $2 / millón de tokens | $3 / millón de tokens | ✅ Gemini es un 33% más barato |
| Precio de salida | $12 / millón de tokens | $15 / millón de tokens | ✅ Gemini es un 20% más barato |
| Precio entrada (contexto largo) | $4 (>200K) | $3 (sin cambios) | ⚠️ Sonnet es más barato en contexto largo |
| Precio salida (contexto largo) | $18 (>200K) | $15 (sin cambios) | ⚠️ Sonnet es más barato en contexto largo |
| Modalidades de entrada | Texto, imagen, audio, video, PDF | Texto, imagen, PDF | ✅ Gemini es más completo en multimodalidad |
| Modo de razonamiento | Tres niveles (Bajo/Medio/Alto) | Razonamiento adaptativo (dinámico) | Diferentes filosofías de diseño |
| Caché de indicaciones | Soportado | Lectura de caché a solo $0.30/M (90% ahorro) | ✅ El caché de Sonnet ahorra más |
🎯 Detalle clave de precios: En escenarios convencionales de menos de 200K, Gemini 3.1 Pro es más económico ($2/$12 vs $3/$15). Sin embargo, una vez que el contexto supera los 200K, el precio de Gemini sube a $4/$18, resultando más caro que los $3/$15 de Sonnet 4.6. La longitud promedio de tu contexto determinará directamente cuál es más rentable.
Gemini 3.1 Pro vs. Sonnet 4.6: Comparativa completa de Benchmarks
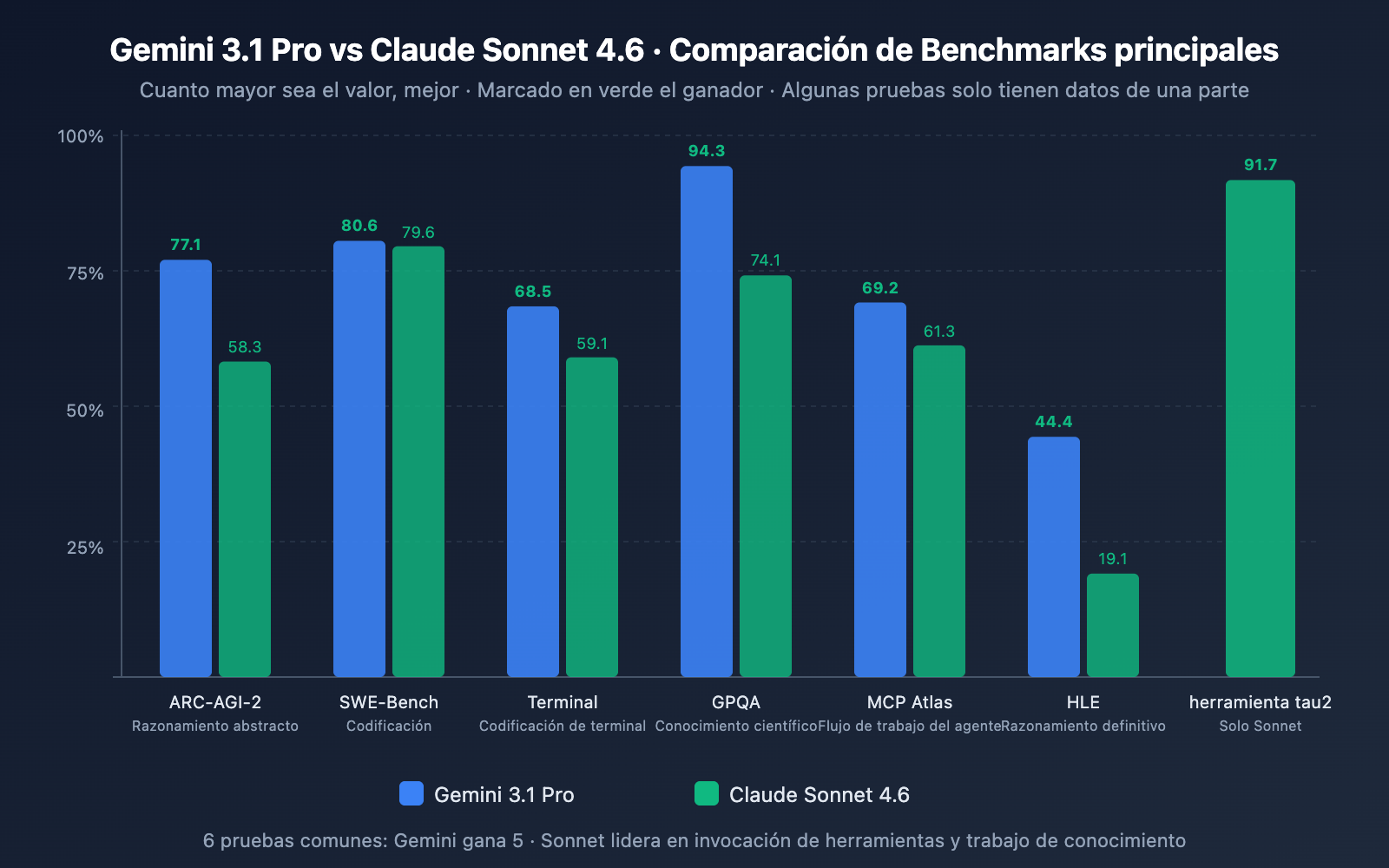
Comparativa de capacidades de programación
| Test de programación | Gemini 3.1 Pro | Claude Sonnet 4.6 | Ganador |
|---|---|---|---|
| SWE-Bench Verified | 80.6% | 79.6% | ✅ Gemini +1.0 puntos |
| SWE-Bench Pro | 54.2% | 42.7% | ✅ Gemini +11.5 puntos |
| Terminal-Bench 2.0 | 68.5% | 59.1% | ✅ Gemini +9.4 puntos |
Análisis: Gemini 3.1 Pro lidera en las tres pruebas de programación. Especialmente en SWE-Bench Pro (tareas de código real más complejas), la diferencia alcanza los 11.5 puntos, y en Terminal-Bench (programación en entorno de terminal) llega a los 9.4 puntos. No obstante, cabe destacar que Sonnet 4.6 logró una tasa de error del 0% en las pruebas internas de edición de código de producción de Replit y ha sido seleccionado como el modelo base para el agente de programación de GitHub Copilot; por lo tanto, la experiencia de programación en entornos de producción reales podría estar más reñida de lo que sugieren los benchmarks.
Comparativa de capacidad de razonamiento
| Test de razonamiento | Gemini 3.1 Pro | Claude Sonnet 4.6 | Ganador |
|---|---|---|---|
| ARC-AGI-2 (Razonamiento abstracto) | 77.1% | 58.3% | ✅ Gemini +18.8 puntos |
| GPQA Diamond (Ciencia) | 94.3% | 74.1% | ✅ Gemini +20.2 puntos |
| HLE (Razonamiento avanzado) | 44.4% | 19.1% | ✅ Gemini +25.3 puntos |
| MATH-500 | – | 97.8% | Sonnet destaca en matemáticas |
Análisis: El razonamiento es la dimensión donde se observa la mayor brecha entre ambos. Gemini 3.1 Pro supera ampliamente a Sonnet 4.6 en las pruebas ARC-AGI-2, GPQA Diamond y HLE, con diferencias que oscilan entre los 18 y 25 puntos. Cabe aclarar que las puntuaciones de Gemini 3.1 Pro se obtuvieron bajo el modo "High" de su sistema de pensamiento de tres niveles, mientras que el pensamiento adaptativo de Sonnet 4.6 no alcanza la misma profundidad de razonamiento que Opus 4.6. Si tu necesidad principal es el razonamiento puro, Gemini 3.1 Pro tiene una ventaja evidente.
Comparativa de trabajo intelectual y capacidades de Agente
| Test | Gemini 3.1 Pro | Claude Sonnet 4.6 | Ganador |
|---|---|---|---|
| GDPval-AA Elo (Trabajo intelectual) | 1,317 | 1,633 | ✅ Sonnet +316 puntos |
| Finance Agent (Análisis financiero) | – | 63.3% | Sonnet destaca en datos |
| OSWorld (Control de SO) | – | 72.5% | Sonnet destaca en datos |
| MCP Atlas (Flujos de varios pasos) | 69.2% | 61.3% | ✅ Gemini +7.9 puntos |
| tau2-bench Retail (Uso de herramientas) | – | 91.7% | Sonnet destaca en datos |
Análisis: Aquí es donde se produce el giro más inesperado. En GDPval-AA (que simula trabajo intelectual real a nivel experto), Sonnet 4.6 no solo supera por mucho los 1,317 Elo de Gemini 3.1 Pro con sus 1,633 puntos, sino que incluso sobrepasa a Opus 4.6, el buque insignia de la propia Anthropic (1,559). Esto significa que en escenarios de trabajo intelectual de alto valor, como análisis de investigación, redacción de informes o estrategia comercial, Sonnet 4.6 es actualmente el modelo con mejor desempeño, superando incluso a Opus 4.6, que es cinco veces más costoso.
Gemini 3.1 Pro vs. Sonnet 4.6: Recomendaciones de selección por escenario
Las fortalezas y debilidades de ambos modelos son muy complementarias; elegir el escenario adecuado es más importante que decidir "cuál es mejor".

Cuándo elegir Gemini 3.1 Pro
- Algoritmos y programación competitiva: Con un Elo de 2,887 en LiveCodeBench, tiene un liderazgo aplastante en codificación algorítmica.
- Razonamiento complejo e investigación científica: Con puntuaciones de 77.1% en ARC-AGI-2 y 94.3% en GPQA Diamond, su capacidad de razonamiento puro está en otro nivel comparado con Sonnet 4.6.
- Procesamiento multimodal: Soporte nativo para vídeo (hasta 1 hora) y audio (8.4 horas), capacidades que Sonnet 4.6 no ofrece.
- Flujos de trabajo de Agentes MCP: Con un 69.2% en MCP Atlas (una ventaja de 7.9 puntos), es más fiable al construir sistemas de agentes de múltiples pasos.
- Invocaciones de alta frecuencia con contexto corto: Para contextos de menos de 200K tokens, su precio de $2/$12 es la opción más económica entre ambos.
Cuándo elegir Claude Sonnet 4.6
- Trabajo de conocimiento nivel experto: Su Elo de 1,633 en GDPval-AA es la puntuación más alta de todos los modelos actuales; ideal para informes de investigación, análisis financiero y estrategia de negocios.
- Edición de código en producción: Con una tasa de error del 0% en pruebas de entorno de producción de Replit, ha sido elegido por GitHub Copilot como base para su agente de programación.
- Invocación de herramientas y Computer Use: Con 91.7% en tau2-bench y 72.5% en OSWorld, ofrece una precisión altísima en operaciones automatizadas e invocación de funciones.
- Escenarios de contexto largo: Cuando se superan los 200K tokens de contexto, el precio de $3/$15 de Sonnet 4.6 es más barato que los $4/$18 de Gemini.
- Aplicaciones empresariales: Alineación de seguridad más madura, caché de indicaciones (lectura a solo $0.30 por millón de tokens, un ahorro del 90%) y procesamiento por lotes a mitad de precio.
Acceso rápido a la API de Gemini 3.1 Pro y Claude Sonnet 4.6
Ejemplo minimalista
A través de la plataforma APIYI, ambos modelos utilizan una interfaz unificada:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Gemini 3.1 Pro - razonamiento y multimodalidad más potentes
response = client.chat.completions.create(
model="gemini-3.1-pro",
messages=[{"role": "user", "content": "Analiza la complejidad temporal de este código y optimízalo"}]
)
print(response.choices[0].message.content)
Ver ejemplo de invocación de Sonnet 4.6 y cambio automático según el escenario
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Claude Sonnet 4.6 - mejor para trabajo de conocimiento y llamadas a herramientas
response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[{"role": "user", "content": "Redacta un informe de análisis de mercado del primer trimestre, incluyendo comparativa de competidores y sugerencias de crecimiento"}]
)
print(response.choices[0].message.content)
# Enrutamiento automático por escenario
def route_model(prompt, task_type="general"):
model_map = {
"reasoning": "gemini-3.1-pro",
"multimodal": "gemini-3.1-pro",
"algorithm": "gemini-3.1-pro",
"knowledge": "claude-sonnet-4-6",
"production_code": "claude-sonnet-4-6",
"tool_call": "claude-sonnet-4-6",
"general": "gemini-3.1-pro",
}
return client.chat.completions.create(
model=model_map.get(task_type, "gemini-3.1-pro"),
messages=[{"role": "user", "content": prompt}]
)
Sugerencia: A través de la plataforma APIYI (apiyi.com) puedes acceder a ambos modelos simultáneamente, cambiando entre ellos con la misma clave API. La plataforma ofrece una cuota de prueba gratuita; te recomendamos comparar los resultados en tus escenarios reales.
Comparativa profunda de costes entre Gemini 3.1 Pro y Sonnet 4.6
Estimación de costes mensuales basada en tres escenarios de uso típicos:
| Escenario de uso | Consumo mensual de tokens | Gemini 3.1 Pro | Claude Sonnet 4.6 | Opción más económica |
|---|---|---|---|---|
| Uso ligero (5M entrada + 1M salida) | 6 millones | $22 | $30 | Gemini ahorra un 27% |
| Uso moderado (20M entrada + 5M salida) | 25 millones | $100 | $135 | Gemini ahorra un 26% |
| Uso intensivo con contexto largo (50M entrada >200K + 10M salida) | 60 millones | $380 | $300 | ⚠️ Sonnet ahorra un 21% |
🎯 Conclusión de costes: En un uso convencional, Gemini 3.1 Pro es aproximadamente un 26%-27% más barato. Sin embargo, si utilizas con frecuencia contextos largos de más de 200K (como análisis de repositorios de código completos o procesamiento de documentos extensos), Sonnet 4.6 resulta más económico. Esto se debe a que el precio del contexto largo de Gemini sube a $4/$18, mientras que Sonnet se mantiene en $3/$15. Además, con el almacenamiento en caché de indicaciones (Prompt Caching) de Sonnet (la lectura cuesta solo $0.30 por millón de tokens), el coste real podría ser entre un 30% y un 50% menor.
Acceder a través de la plataforma APIYI (apiyi.com) permite disfrutar de precios con descuentos adicionales, reduciendo aún más los costes de uso de ambos modelos.
Preguntas frecuentes
P1: El GDPval-AA de Sonnet 4.6 es superior al del propio Opus 4.6, ¿es esto normal?
Efectivamente. Sonnet 4.6 obtuvo 1,633 Elo en GDPval-AA, superando los 1,559 de Opus 4.6. Anthropic ha confirmado oficialmente estos datos. La razón probable es que Sonnet 4.6 ha sido optimizado específicamente para escenarios de trabajo de conocimiento empresarial, mientras que Opus 4.6 se centra más en el razonamiento general y el procesamiento de una ventana de contexto larga. La tasa de preferencia de los desarrolladores por Sonnet 4.6 también alcanzó el 70% (frente a Sonnet 4.5) y el 59% (frente a Opus 4.5).
P2: ¿Qué modelo es mejor para crear un AI Agent?
Depende del tipo de Agent. Si se trata de un Agent de flujo de trabajo de múltiples pasos basado en MCP, Gemini 3.1 Pro lidera con un 69.2% en MCP Atlas (7.9 puntos por encima). Si es un Agent intensivo en invocación de herramientas (como OpenClaw), el 91.7% de Sonnet 4.6 en tau2-bench es más fiable. Si es un Agent de tipo "Computer Use" (que controla el navegador y el escritorio), el 72.5% de Sonnet 4.6 en OSWorld es uno de los mejores resultados actuales. Ambos modelos se pueden probar directamente a través de la plataforma APIYI (apiyi.com).
P3: Actualmente uso Sonnet 4.5, ¿debería actualizar a Sonnet 4.6 o cambiar a Gemini 3.1 Pro?
Si estás satisfecho con la experiencia de trabajo de conocimiento y programación de Sonnet 4.5, actualizar directamente a Sonnet 4.6 es la opción más segura: compatibilidad de API, mismo precio y una mejora de rendimiento integral (SWE-Bench sube del 77.2% al 79.6%, y ARC-AGI-2 del 13.6% al 58.3%, una mejora de 4.3 veces). Si tus necesidades principales se inclinan hacia el razonamiento, la multimodalidad o la programación de algoritmos, Gemini 3.1 Pro tiene ventajas significativas en esas áreas. Te recomendamos probar ambos modelos a través de la plataforma APIYI (apiyi.com).
Resumen
Conclusiones clave de la comparativa entre Gemini 3.1 Pro y Claude Sonnet 4.6:
- Elige Gemini 3.1 Pro para razonamiento y multimodalidad: Lidera por 18.8 puntos en ARC-AGI-2 y 20.2 puntos en GPQA Diamond; cuenta con soporte nativo para vídeo/audio y es más económico en contextos cortos.
- Elige Claude Sonnet 4.6 para trabajo de conocimiento y programación de producción: Su puntuación de 1,633 Elo en GDPval-AA es la más alta de todos los modelos (incluido Opus 4.6), tiene una tasa de error del 0% en Replit y es la opción preferida para GitHub Copilot.
- Sonnet es más rentable en escenarios de ventana de contexto larga: Superando los 200K de contexto, Sonnet cuesta $3/$15 frente a los $4/$18 de Gemini; además, con el almacenamiento en caché de indicaciones se puede ahorrar un 30%-50% adicional.
Estos dos modelos son los de vanguardia con mejor relación calidad-precio en febrero de 2026. La mejor estrategia es utilizarlos de forma híbrida según el escenario. Recomendamos acceder a ambos simultáneamente a través de APIYI (apiyi.com), alternando según sea necesario con la misma clave API.
📚 Referencias
-
Anuncio de lanzamiento de Claude Sonnet 4.6: Blog oficial de Anthropic
- Enlace:
anthropic.com/news/claude-sonnet-4-6 - Descripción: Introducción completa a las funciones de Sonnet 4.6, datos de Benchmark y la función de pensamiento adaptativo.
- Enlace:
-
Blog oficial de Gemini 3.1 Pro: Anuncio de lanzamiento de Google DeepMind
- Enlace:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - Descripción: El sistema de pensamiento de tres niveles de Gemini 3.1 Pro y datos de rendimiento completos.
- Enlace:
-
Comparativa de pruebas reales de Tom's Guide: 7 desafíos de prueba real entre Gemini 3.1 Pro y Sonnet 4.6
- Enlace:
tomsguide.com/ai/i-tested-gemini-3-1-pro-vs-claude-sonnet-4-6-in-7-tough-challenges-and-there-was-one-clear-winner - Descripción: Comparación del rendimiento real en escenarios de tareas cotidianas.
- Enlace:
-
Clasificación de Artificial Analysis: Plataforma independiente de evaluación de modelos de terceros
- Enlace:
artificialanalysis.ai/leaderboards/models - Descripción: Datos objetivos de comparación horizontal de rendimiento, velocidad y precio.
- Enlace:
Autor: Equipo técnico
Intercambio técnico: Te invitamos a compartir tu experiencia en la sección de comentarios. Para más noticias sobre modelos de IA, visita APIYI apiyi.com





