La lentitud en la generación de imágenes de Nano Banana Pro es un problema reportado frecuentemente por los desarrolladores. Los clientes preguntan: "¿Por qué el tiempo de generación a veces es de 20 segundos y otras de más de 50? ¿Es aleatorio?" — La respuesta es: el tiempo de generación lo determinan tres factores principales: la resolución, el nivel de razonamiento y la transferencia de red. En este artículo compartiremos 6 trucos de optimización probados en entornos reales para ayudarte a mantener el tiempo de generación de imágenes 2K en Nano Banana Pro por debajo de los 50 segundos de forma estable.
Valor central: Al terminar de leer, dominarás la metodología completa para optimizar la velocidad de generación en Nano Banana Pro, permitiéndote ajustar parámetros con flexibilidad según tu escenario de negocio para lograr el equilibrio perfecto entre calidad y velocidad.

Factores clave que afectan la velocidad en Nano Banana Pro
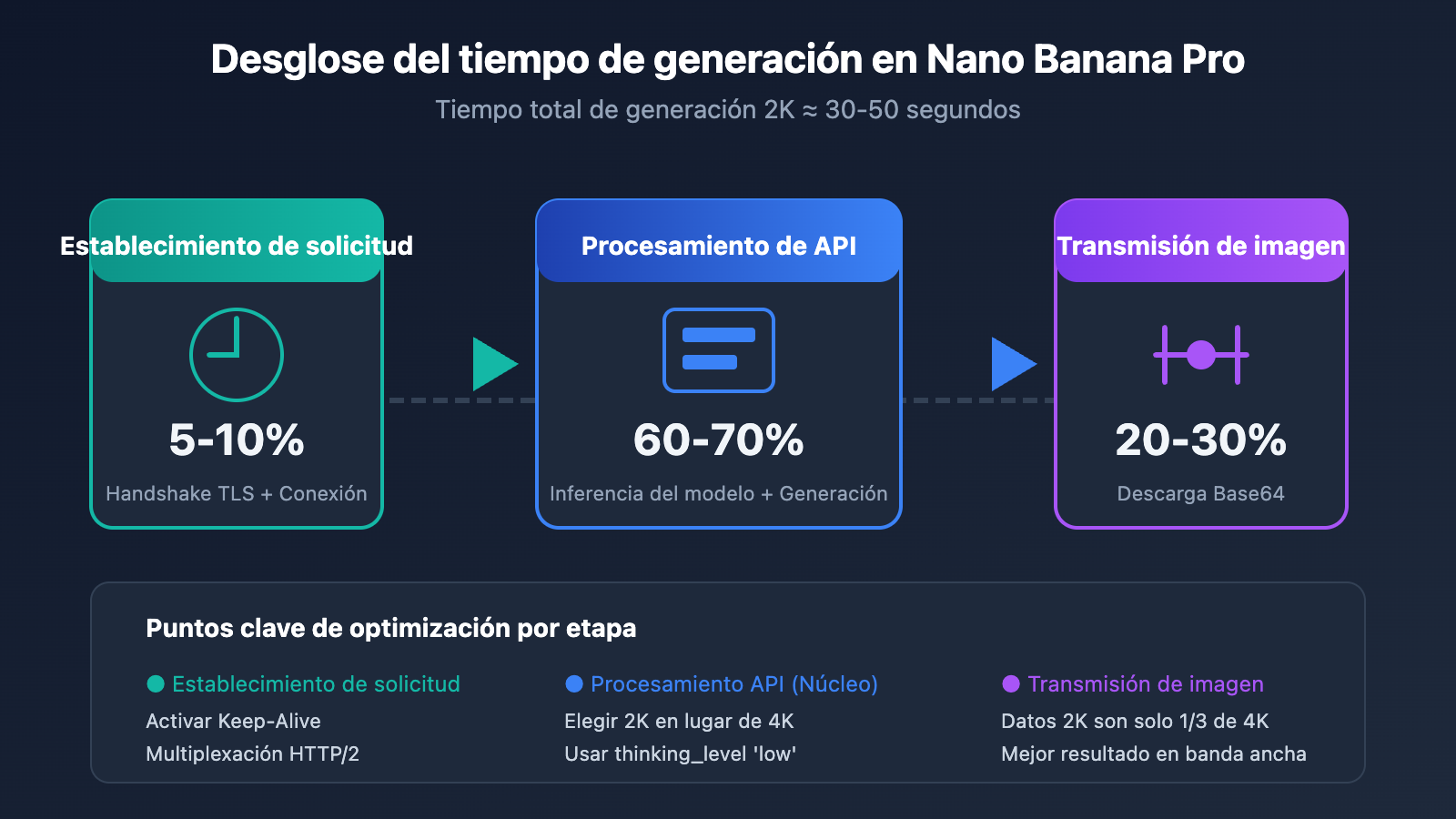
Antes de optimizar, es necesario entender los factores principales que influyen en la velocidad de generación de Nano Banana Pro. Según datos reales, el tiempo total se divide en tres etapas:
| Etapa | % del tiempo | Factores principales | Margen de optimización |
|---|---|---|---|
| Procesamiento de API | 60-70% | Resolución, nivel de razonamiento, carga del modelo | Alto |
| Transmisión y descarga | 20-30% | Ancho de banda, volumen de datos base64, ubicación | Medio |
| Establecimiento de solicitud | 5-10% | Reutilización de conexión, handshake TLS | Medio |
Datos reales de tiempo de generación en Nano Banana Pro
Basado en los datos de medición de la plataforma APIYI imagen.apiyi.com:
| Resolución | Nivel de razonamiento | Tiempo promedio | Tiempo P95 | Escenario recomendado |
|---|---|---|---|---|
| 1K | low | 15-20s | 25s | Previsualización, generación por lotes |
| 2K | low | 30-40s | 50s | Producción general, exhibición web |
| 2K | high | 45-60s | 75s | Composición compleja, texto detallado |
| 4K | low | 50-70s | 90s | Impresión, diseño de alta gama |
| 4K | high | 80-120s | 150s | Salida profesional |
🎯 Conclusión clave: La combinación de resolución 2K + nivel de razonamiento "low" es la más rentable; generar una imagen 2K en 50 segundos es totalmente estable. Si tu caso de uso no requiere 4K, te recomendamos encarecidamente usar 2K.
Consejo de optimización de velocidad para Nano Banana Pro #1: Elegir la resolución adecuada
La resolución es el factor más directo que influye en la velocidad de generación de Nano Banana Pro. Desde un punto de vista técnico:
- Imagen 4K (4096×4096): aprox. 16 millones de píxeles, requiere unos 2000 tokens de salida.
- Imagen 2K (2048×2048): aprox. 4 millones de píxeles, requiere unos 1120 tokens de salida.
- Imagen 1K (1024×1024): aprox. 1 millón de píxeles, requiere unos 560 tokens de salida.
Tabla comparativa de resolución y velocidad en Nano Banana Pro
| Resolución | Número de píxeles | Consumo de Tokens | Velocidad relativa | Escenario de uso |
|---|---|---|---|---|
| 1K | 1M | ~560 | Base (1x) | Vista previa, iteración rápida |
| 2K | 4M | ~1120 | aprox. 1.8x | Producción estándar |
| 4K | 16M | ~2000 | aprox. 3.5x | Calidad de nivel de impresión |
Sugerencias para elegir la resolución
# Ejemplo de selección de resolución para Nano Banana Pro
def elegir_resolucion(caso_de_uso: str) -> str:
"""Selecciona la resolución óptima según el escenario de uso"""
mapa_resoluciones = {
"preview": "1024x1024", # Vista previa rápida, la más veloz
"web_display": "2048x2048", # Visualización web, equilibrada
"social_media": "2048x2048", # Redes sociales, 2K es suficiente
"print_design": "4096x4096", # Diseño de impresión, requiere 4K
"batch_process": "1024x1024" # Procesamiento por lotes, prioridad a la velocidad
}
return mapa_resoluciones.get(caso_de_uso, "2048x2048")
💡 Sugerencia de optimización: Para la mayoría de los escenarios de aplicaciones web, una resolución 2K es más que suficiente. Solo se necesita 4K para impresiones o pantallas ultra grandes. Elegir 2K puede ahorrar un 45% del tiempo de generación, y el precio es exactamente el mismo ($0.134/imagen en el precio oficial, $0.05/imagen en la plataforma APIYI).
Consejo de optimización de velocidad para Nano Banana Pro #2: Ajustar el parámetro del nivel de pensamiento
Nano Banana Pro incluye un mecanismo de "pensamiento" (Thinking) basado en Gemini 3 Pro. Para una indicación sencilla, este proceso de razonamiento añade una latencia innecesaria.
Detalle del parámetro thinking_level en Nano Banana Pro
| Nivel de pensamiento | Profundidad de razonamiento | Tiempo extra | Escenario de uso |
|---|---|---|---|
| low | Razonamiento básico | +0s | Indicaciones simples, instrucciones claras |
| medium | Razonamiento estándar | +5-10s | Generación creativa convencional |
| high | Razonamiento profundo | +15-25s | Composiciones complejas, renderizado de texto preciso |
Ejemplo de código: Configuración del nivel de pensamiento
import openai
client = openai.OpenAI(
api_key="TU_CLAVE_API",
base_url="https://api.apiyi.com/v1" # Usando la interfaz unificada de APIYI
)
# Escenario simple: usar nivel de pensamiento low (bajo)
response = client.images.generate(
model="nano-banana-pro",
prompt="Un gato naranja sentado en el alféizar de una ventana",
size="2048x2048",
extra_body={
"thinking_level": "low" # Indicación simple, nivel de pensamiento bajo
}
)
# Escenario complejo: usar nivel de pensamiento high (alto)
response = client.images.generate(
model="nano-banana-pro",
prompt="Una infografía de producto profesional que incluye el título 'Lanzamiento de producto 2025', tres características del producto, etiqueta de precio $99.99, con una combinación de colores azul tecnológico",
size="2048x2048",
extra_body={
"thinking_level": "high" # Renderizado de texto complejo, requiere nivel alto
}
)
🚀 Truco práctico: Para escenas simples como "un gato" o "un bosque", establecer el
thinking_levelenlowpuede ahorrar entre un 20% y un 30% del tiempo de generación. El nivelhighsolo es necesario cuando se trata de renderizado de texto preciso o relaciones espaciales complejas.
Nano Banana Pro Truco de Optimización de Velocidad 3: Optimización de la Transmisión de Red
Muchos desarrolladores pasan por alto un hecho: que la interfaz de la API responda rápido no significa que el tiempo total sea corto. Los datos reales muestran que la transmisión de red puede representar entre el 20% y el 30% del tiempo total.
Desglose del tiempo de red de Nano Banana Pro
Tomando como ejemplo una imagen 2K, una imagen PNG 2K codificada en base64 pesa aproximadamente entre 4 y 6 MB:
| Fase | Volumen de datos | Ancho de banda 10Mbps | Ancho de banda 100Mbps | Ancho de banda 1Gbps |
|---|---|---|---|---|
| Subida de solicitud | ~1KB | <0.1s | <0.1s | <0.1s |
| Descarga de respuesta | ~5MB | 4s | 0.4s | 0.04s |
| Handshake TLS | – | 0.1-0.3s | 0.1-0.3s | 0.1-0.3s |
Prácticas de optimización de red
import httpx
import time
# Optimización 1: Habilitar reutilización de conexiones (Keep-Alive)
# Un equipo redujo la latencia P95 de 3.5s a 0.9s habilitando Keep-Alive
client = httpx.Client(
base_url="https://api.apiyi.com/v1",
http2=True, # Habilitar HTTP/2
timeout=60.0,
limits=httpx.Limits(
max_keepalive_connections=10, # Mantener pool de conexiones
keepalive_expiry=30.0 # Tiempo de vida de la conexión
)
)
# Optimización 2: Añadir logs detallados de tiempo
def generate_with_timing(prompt: str, size: str = "2048x2048"):
"""Generación de imagen con estadísticas de tiempo"""
timings = {}
start = time.time()
# Enviar solicitud
response = client.post(
"/images/generations",
json={
"model": "nano-banana-pro",
"prompt": prompt,
"size": size,
"response_format": "b64_json"
},
headers={"Authorization": f"Bearer {api_key}"}
)
timings["api_total"] = time.time() - start
# Parsear respuesta
parse_start = time.time()
result = response.json()
timings["parse_time"] = time.time() - parse_start
print(f"API Tiempo: {timings['api_total']:.2f}s")
print(f"Tiempo de parseo: {timings['parse_time']:.2f}s")
return result
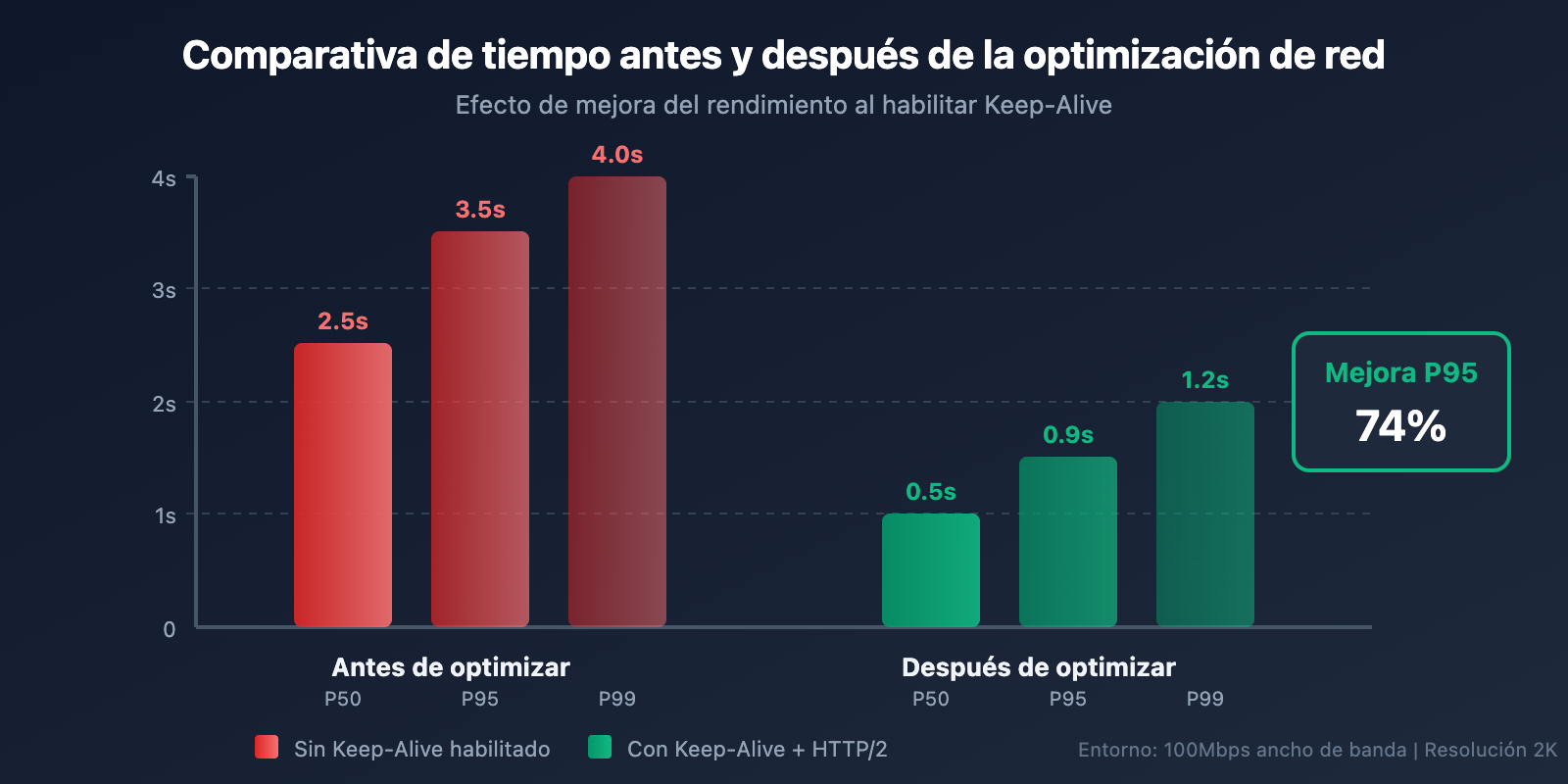
📊 Datos reales: Las pruebas de velocidad en la plataforma APIYI (imagen.apiyi.com) muestran que los usuarios que acceden a través de nodos optimizados obtienen un tiempo de respuesta de la API para imágenes 2K de unos 20-30 segundos; sumando el tiempo de descarga, el tiempo total se estabiliza por debajo de los 50 segundos.
Nano Banana Pro – Truco de optimización de velocidad 4: Uso de generación en cuadrícula para producción por lotes
Si necesitas explorar direcciones creativas rápidamente o generar múltiples variantes, la generación en cuadrícula (grid) es un truco de aceleración a menudo subestimado.
Comparativa: Generación en cuadrícula vs. Imagen única
| Método de generación | Tiempo para 4 imágenes | Coste por imagen | Casos de uso |
|---|---|---|---|
| Imagen única ×4 | 4 × 30s = 120s | $0.05 | Cuando necesitas control individual por cada imagen |
| Cuadrícula 2×2 | aprox. 40s | ~$0.034 | Exploración rápida, iteración creativa |
Ejemplo de código para generación en cuadrícula
# Uso de generación en cuadrícula para producir múltiples variantes rápidamente
response = client.images.generate(
model="nano-banana-pro",
prompt="Diseño de sala de estar de estilo moderno y minimalista",
size="2048x2048",
extra_body={
"grid": "2x2", # Generar cuadrícula de 2x2
"thinking_level": "low" # Nivel de pensamiento bajo para la fase de exploración
}
)
# Cerca de 40 segundos para producir 4 variantes, aprox. $0.034 por imagen
🎯 Sugerencia de uso: Usa la generación en cuadrícula para iterar rápido durante la fase de exploración creativa; una vez definida la dirección, utiliza la generación de imagen única para obtener alta calidad. Al realizar llamadas a través de la plataforma APIYI (apiyi.com), la generación en cuadrícula también es compatible y ofrece métodos de facturación más flexibles.
Nano Banana Pro – Truco de optimización de velocidad 5: Configuración adecuada de tiempos de espera y reintentos
En entornos de producción, una estrategia adecuada de tiempos de espera (timeout) y reintentos puede evitar fallos en las peticiones causados por latencias ocasionales.
Configuración de timeout recomendada
| Resolución | Timeout recomendado | Número de reintentos | Intervalo de reintento |
|---|---|---|---|
| 1K | 45s | 2 | 5s |
| 2K | 90s | 2 | 10s |
| 4K | 180s | 3 | 15s |
Ejemplo de código para entornos de producción
import openai
from tenacity import retry, stop_after_attempt, wait_exponential
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1", # Interfaz unificada de APIYI
timeout=90.0 # Timeout de 90s recomendado para imágenes 2K
)
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=5, max=30)
)
def generate_image_with_retry(prompt: str, size: str = "2048x2048"):
"""Generación de imagen con reintento de retroceso exponencial"""
return client.images.generate(
model="nano-banana-pro",
prompt=prompt,
size=size,
extra_body={"thinking_level": "low"}
)
# Uso
try:
result = generate_image_with_retry("Un campo de trigo dorado al atardecer")
print("¡Generación exitosa!")
except Exception as e:
print(f"Error en la generación: {e}")
Técnica de optimización de velocidad 6 para Nano Banana Pro: Elige el proveedor de API adecuado
Las diferencias en la infraestructura de los distintos proveedores de API afectan directamente a la velocidad de respuesta.
Comparativa de proveedores de API para Nano Banana Pro
| Proveedor | Latencia de acceso local | Velocidad de generación 2K | Precio unitario | Características |
|---|---|---|---|---|
| Google Oficial | 3-8s de latencia extra | 30-50s | $0.134 | Requiere tarjeta de crédito extranjera |
| APIYI | Nodos optimizados | 30-40s | $0.05 | Soporta Alipay/WeChat |
| Otros proxies | Inestable | 40-60s | $0.08-0.15 | Calidad variable |
💰 Optimización de costos: Al realizar llamadas a Nano Banana Pro a través de APIYI (apiyi.com), el precio unitario es de solo $0.05 por imagen, lo que supone un ahorro de aproximadamente el 63% en comparación con los $0.134 oficiales. Además, la latencia de acceso local es menor, ofreciendo una mejor experiencia general. Los clientes corporativos cuentan con bonos adicionales por recarga, pudiendo alcanzar un costo mínimo de $0.04 por imagen.
Ejemplo completo de configuración optimizada
Haz clic para desplegar el código completo
"""
Ejemplo completo de optimización de velocidad para Nano Banana Pro
Llamadas a través de la plataforma APIYI, integrando todas las técnicas de optimización
"""
import openai
import time
import base64
from pathlib import Path
from tenacity import retry, stop_after_attempt, wait_exponential
class NanoBananaProClient:
"""Cliente optimizado para Nano Banana Pro"""
def __init__(self, api_key: str):
self.client = openai.OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1", # Interfaz unificada de APIYI
timeout=90.0,
max_retries=0 # Usamos lógica de reintento personalizada
)
def choose_params(self, use_case: str, quality: str = "balanced"):
"""Selección inteligente de parámetros según el escenario"""
configs = {
"preview": {
"size": "1024x1024",
"thinking_level": "low"
},
"production": {
"size": "2048x2048",
"thinking_level": "low" if quality == "fast" else "medium"
},
"premium": {
"size": "4096x4096",
"thinking_level": "high"
}
}
return configs.get(use_case, configs["production"])
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=5, max=30)
)
def generate(
self,
prompt: str,
use_case: str = "production",
quality: str = "balanced"
) -> dict:
"""Genera imágenes con optimización automática de parámetros"""
params = self.choose_params(use_case, quality)
start_time = time.time()
response = self.client.images.generate(
model="nano-banana-pro",
prompt=prompt,
size=params["size"],
response_format="b64_json",
extra_body={
"thinking_level": params["thinking_level"]
}
)
elapsed = time.time() - start_time
return {
"image_data": response.data[0].b64_json,
"elapsed_seconds": elapsed,
"size": params["size"],
"thinking_level": params["thinking_level"]
}
def generate_batch(
self,
prompts: list[str],
use_case: str = "preview"
) -> list[dict]:
"""Generación por lotes, usa configuración baja automáticamente para acelerar"""
results = []
for prompt in prompts:
result = self.generate(prompt, use_case=use_case, quality="fast")
results.append(result)
return results
def save_image(self, b64_data: str, output_path: str):
"""Guarda una imagen base64 en un archivo"""
image_bytes = base64.b64decode(b64_data)
Path(output_path).write_bytes(image_bytes)
# Ejemplo de uso
if __name__ == "__main__":
client = NanoBananaProClient(api_key="tu-api-key")
# Escenario 1: Vista previa rápida
preview = client.generate(
prompt="un gato naranja",
use_case="preview"
)
print(f"Tiempo de generación de vista previa: {preview['elapsed_seconds']:.2f}s")
# Escenario 2: Entorno de producción
production = client.generate(
prompt="Imagen profesional de producto para ecommerce, fondo blanco, ángulo de 45 grados",
use_case="production"
)
print(f"Tiempo de generación de producción: {production['elapsed_seconds']:.2f}s")
# Escenario 3: Diseño de alta gama
premium = client.generate(
prompt="4K Ultra HD, sala de estar moderna y minimalista, ventanales grandes, luz solar filtrada",
use_case="premium"
)
print(f"Tiempo de generación premium: {premium['elapsed_seconds']:.2f}s")
Preguntas frecuentes sobre la optimización de velocidad en Nano Banana Pro
P1: ¿Por qué el tiempo de generación varía cada vez, incluso con la misma indicación?
El tiempo de generación de Nano Banana Pro depende de varios factores:
- Fluctuaciones en la carga del modelo: Durante las horas pico (como el horario laboral en EE. UU.), la carga del servidor es mayor y el tiempo de respuesta puede aumentar entre un 10% y un 30%.
- Complejidad de la indicación: Aunque las indicaciones sean similares, la ruta de inferencia interna del modelo puede variar.
- Estado de la red: Las transmisiones transfronterizas presentan fluctuaciones naturales.
Sugerencia de optimización: Realizar las llamadas a través de la plataforma APIYI (apiyi.com), cuyos nodos optimizados pueden mitigar en parte los problemas de red. También se recomienda evitar las horas de mayor tráfico (evitando las 21:00-02:00 hora de Pekín, que coinciden con el pico en EE. UU.).
P2: Si el precio para 2K y 4K es el mismo, ¿por qué no usar 4K directamente?
Que el precio sea el mismo no significa que la eficiencia sea igual:
| Dimensión | 2K | 4K | Diferencia |
|---|---|---|---|
| Tiempo de generación | 30-40s | 50-70s | 4K es aprox. un 60% más lento |
| Transferencia de datos | ~3MB | ~10MB | Mayor volumen de datos en 4K |
| Costo de almacenamiento | Base | Aprox. 3.3x | Mayor costo de almacenamiento a largo plazo |
Conclusión: A menos que tu negocio requiera explícitamente 4K (como para impresión o pantallas gigantes), 2K es la opción más inteligente. Al realizar llamadas por lotes a través de APIYI, la ventaja de eficiencia de 2K se vuelve aún más evidente.
P3: ¿Cómo puedo saber si el cuello de botella está en la API o en mi red?
Añadir registros detallados de tiempo es clave para el diagnóstico:
import time
# Registrar momento de inicio de la solicitud
t1 = time.time()
response = client.images.generate(...)
t2 = time.time()
# Registrar momento del procesamiento de datos
data = response.data[0].b64_json
t3 = time.time()
print(f"Tiempo de respuesta de la API: {t2-t1:.2f}s")
print(f"Tiempo de procesamiento de datos: {t3-t2:.2f}s")
Si la respuesta de la API es rápida pero el tiempo total es largo, el cuello de botella está en la transmisión de red. Puedes verificar el rendimiento del lado de la API usando la herramienta de prueba de velocidad en línea imagen.apiyi.com.
P4: ¿Cómo maximizar el rendimiento al generar por lotes?
Estrategias para optimizar la generación por lotes:
- Solicitudes concurrentes: Ajusta el número de hilos según la política de límites de la API (normalmente entre 5 y 10 conexiones concurrentes).
- Uso de generación en cuadrícula: Una cuadrícula de 2×2 produce 4 imágenes a la vez, aumentando la eficiencia casi 3 veces.
- Bajar la configuración: En escenarios de lotes masivos, prioriza el uso de 1K + low thinking.
- Procesamiento asíncrono: Utiliza
asyncioo un grupo de hilos (thread pool) para el procesamiento paralelo.
Al utilizar la plataforma APIYI, se admiten límites de concurrencia más altos, lo cual es ideal para necesidades de generación masiva.
Resumen de optimización de velocidad de Nano Banana Pro
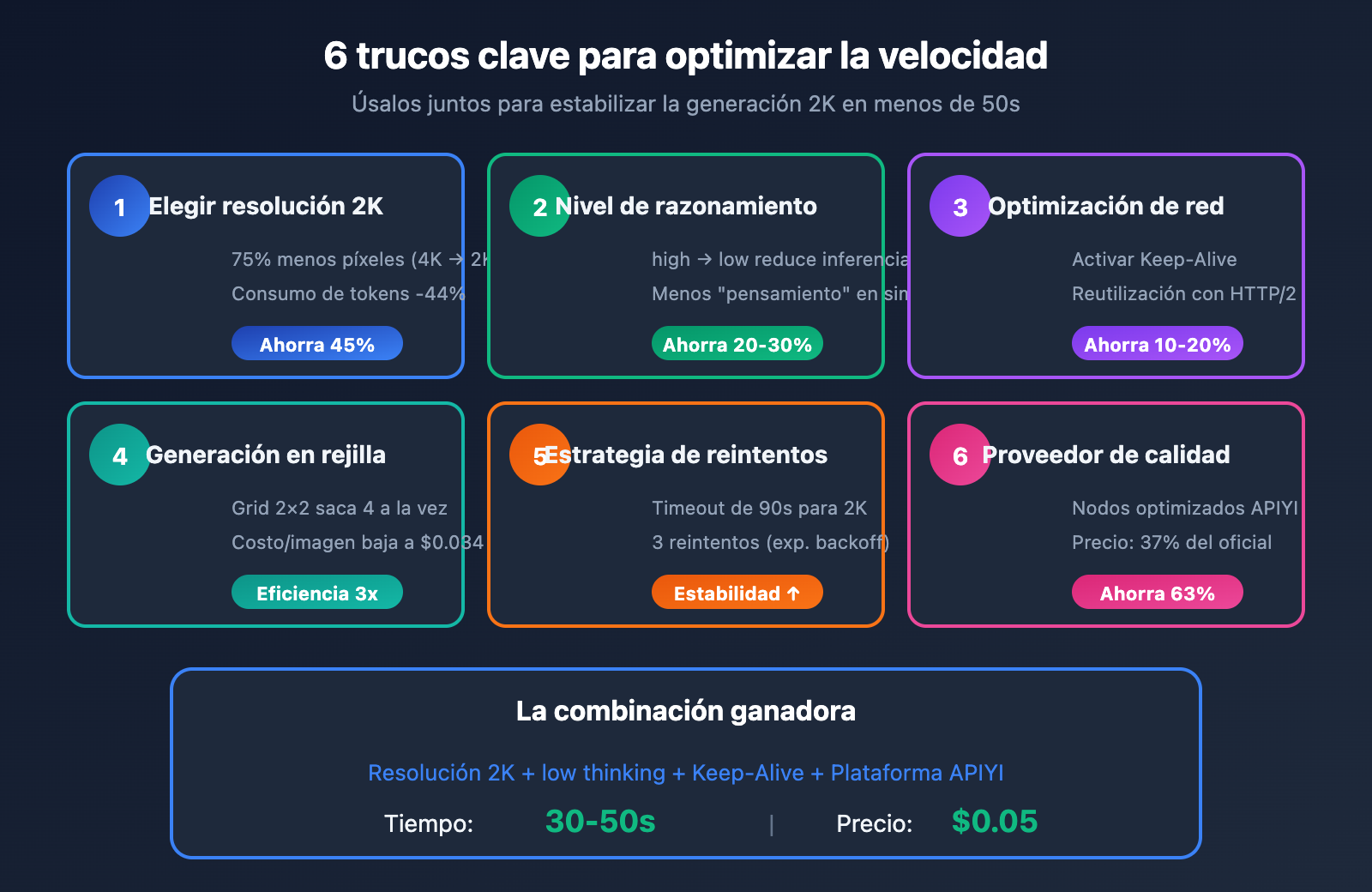
En este artículo, te presentamos 6 trucos para optimizar la velocidad de generación con Nano Banana Pro:
| Truco | Efecto de optimización | Dificultad | Prioridad |
|---|---|---|---|
| Elegir resolución 2K | Ahorra un 45% de tiempo | Baja | ⭐⭐⭐⭐⭐ |
| Ajustar nivel de razonamiento | Ahorra un 20-30% | Baja | ⭐⭐⭐⭐⭐ |
| Optimización de red | Ahorra un 10-20% | Media | ⭐⭐⭐⭐ |
| Generación por lotes (Grid) | Eficiencia 3x superior | Baja | ⭐⭐⭐⭐ |
| Estrategia de reintentos | Mejora la estabilidad | Media | ⭐⭐⭐ |
| Elegir un buen proveedor | Mejora integral | Baja | ⭐⭐⭐⭐⭐ |
Conclusión clave: Al combinar la resolución 2K, un nivel de razonamiento "low" y la reutilización de conexiones, es totalmente posible generar una imagen 2K en 50 segundos de forma estable.
🎯 Consejo final: Te recomendamos usar APIYI (apiyi.com) para verificar rápidamente estos efectos de optimización. La plataforma ofrece una herramienta de prueba de velocidad en imagen.apiyi.com, lo que facilita el monitoreo en tiempo real de cada etapa. Además, su precio de $0.05 por imagen (un 37% de los $0.134 oficiales) te permite controlar mejor los costos de experimentación.
Este artículo fue escrito por el equipo técnico de APIYI. Si quieres conocer más trucos sobre el uso de APIs para la generación de imágenes con IA, visita apiyi.com para recibir soporte técnico.