A lentidão na geração de imagens do Nano Banana Pro é um feedback recorrente dos desenvolvedores. Muitos clientes perguntam: "Por que o tempo de geração às vezes é de 20 segundos e outras vezes passa de 50? É aleatório?" — A resposta é: o tempo de geração é determinado por três fatores principais: resolução, nível de reflexão e transmissão de rede. Neste artigo, compartilharemos 6 técnicas de otimização comprovadas na prática para ajudar você a manter o tempo de geração de imagens 2K do Nano Banana Pro estável em menos de 50 segundos.
Valor Principal: Ao terminar de ler, você terá dominado a metodologia completa de otimização de velocidade do Nano Banana Pro, sendo capaz de ajustar parâmetros de forma flexível conforme o cenário de negócio, alcançando o equilíbrio ideal entre qualidade e agilidade.

Principais Fatores que Afetam a Velocidade do Nano Banana Pro
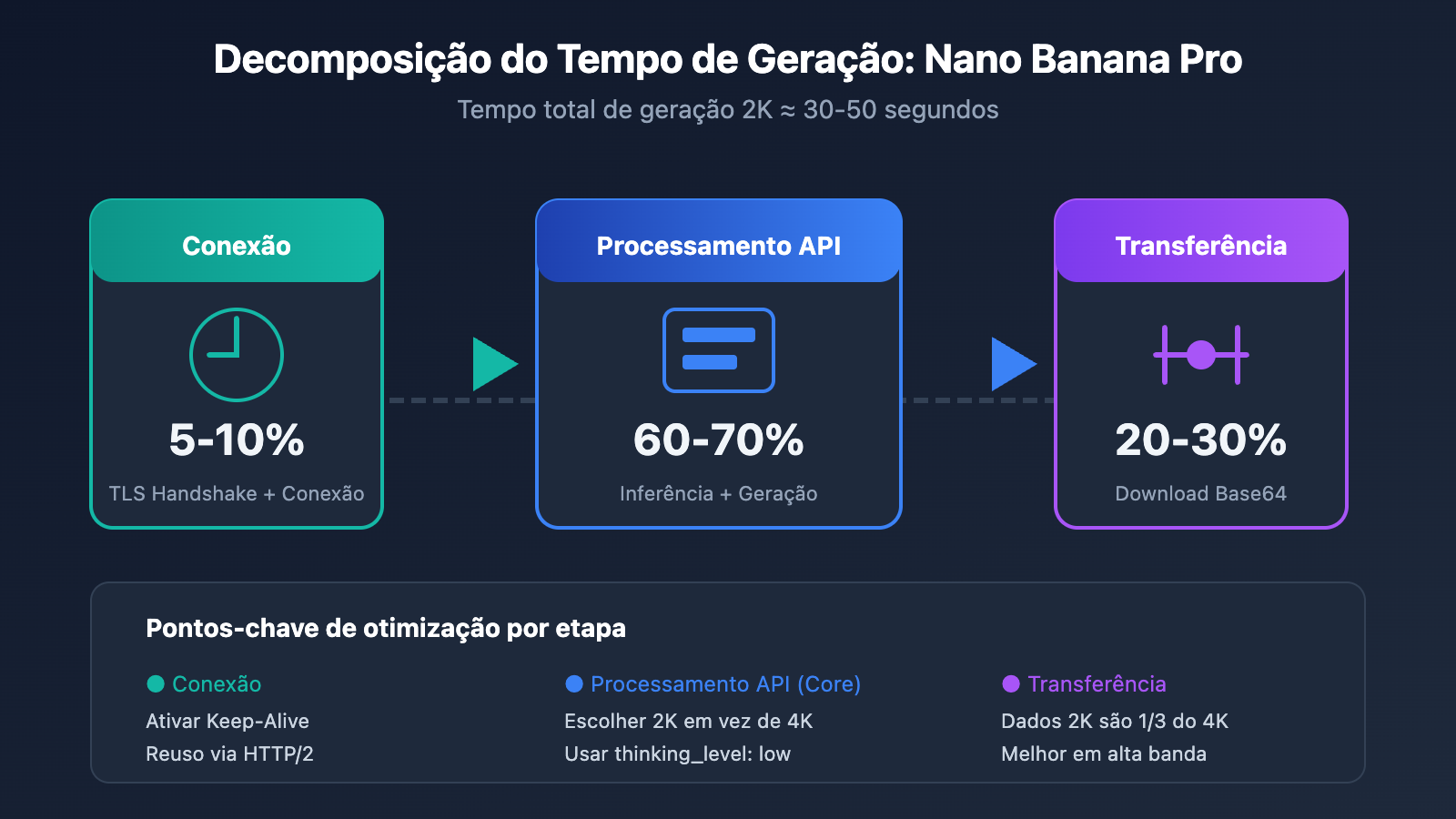
Antes de otimizar, precisamos entender os fatores centrais que influenciam a velocidade de geração do Nano Banana Pro. Com base em dados reais, o tempo total pode ser dividido em três etapas:
| Etapa | Proporção de Tempo | Principais Fatores | Espaço para Otimização |
|---|---|---|---|
| Processamento da API | 60-70% | Resolução, nível de reflexão, carga do modelo | Alto |
| Transferência da Imagem | 20-30% | Largura de banda, volume de dados base64, localização | Médio |
| Estabelecimento da Requisição | 5-10% | Reuso de conexão, TLS handshake | Médio |
Dados Reais de Tempo de Geração do Nano Banana Pro
Baseado em dados de medição da plataforma APIYI (imagen.apiyi.com):
| Resolução | Nível de Reflexão | Tempo Médio | Tempo P95 | Cenário Recomendado |
|---|---|---|---|---|
| 1K | low | 15-20s | 25s | Pré-visualização, geração em lote |
| 2K | low | 30-40s | 50s | Produção regular, exibição Web |
| 2K | high | 45-60s | 75s | Composição complexa, texto detalhado |
| 4K | low | 50-70s | 90s | Impressão, design de alto padrão |
| 4K | high | 80-120s | 150s | Saída de nível profissional |
🎯 Conclusão Chave: O combo Resolução 2K + Nível de reflexão
lowoferece a melhor relação custo-benefício, gerando uma imagem 2K em menos de 50 segundos de forma absolutamente estável. Se o seu cenário não exige 4K, recomendamos fortemente o uso de 2K.
Dica de Otimização de Velocidade do Nano Banana Pro 1: Escolhendo a Resolução Certa
A resolução é o fator mais direto que afeta a velocidade de geração do Nano Banana Pro. Olhando pelo lado técnico:
- Imagens 4K (4096×4096): Cerca de 16 milhões de pixels, exige cerca de 2000 tokens de saída.
- Imagens 2K (2048×2048): Cerca de 4 milhões de pixels, exige cerca de 1120 tokens de saída.
- Imagens 1K (1024×1024): Cerca de 1 milhão de pixels, exige cerca de 560 tokens de saída.
Tabela Comparativa de Resolução vs. Velocidade no Nano Banana Pro
| Resolução | Pixels | Consumo de Tokens | Velocidade Relativa | Cenários de Uso |
|---|---|---|---|---|
| 1K | 1M | ~560 | Base (1x) | Pré-visualização, iteração rápida |
| 2K | 4M | ~1120 | Cerca de 1.8x | Produção convencional |
| 4K | 16M | ~2000 | Cerca de 3.5x | Qualidade de impressão |
Sugestões para Escolha de Resolução
# Exemplo de escolha de resolução no Nano Banana Pro
def choose_resolution(use_case: str) -> str:
"""Escolhe a resolução ideal com base no cenário de uso"""
resolution_map = {
"preview": "1024x1024", # Pré-visualização rápida, a mais veloz
"web_display": "2048x2048", # Exibição Web, equilibrado
"social_media": "2048x2048", # Redes sociais, 2K é suficiente
"print_design": "4096x4096", # Design para impressão, exige 4K
"batch_process": "1024x1024" # Processamento em lote, prioridade para velocidade
}
return resolution_map.get(use_case, "2048x2048")
💡 Dica de otimização: Para a maioria dos cenários de aplicações Web, a resolução 2K já é mais do que suficiente. Apenas impressões ou exibições em telas gigantes realmente precisam de 4K. Escolher 2K pode economizar cerca de 45% do tempo de geração, e o preço é exatamente o mesmo (US$ 0,134/imagem no preço oficial, US$ 0,05/imagem na plataforma APIYI).
Dica de Otimização de Velocidade do Nano Banana Pro 2: Ajustando o Parâmetro de Nível de Pensamento
O Nano Banana Pro possui um mecanismo de "pensamento" (Thinking) integrado, baseado no Gemini 3 Pro. Para comandos simples, esse processo de raciocínio pode adicionar uma latência desnecessária.
Detalhamento do parâmetro thinking_level no Nano Banana Pro
| Nível de Pensamento | Profundidade de Raciocínio | Tempo Extra | Cenários de Uso |
|---|---|---|---|
| low | Raciocínio básico | +0s | Comandos simples, instruções diretas |
| medium | Raciocínio padrão | +5-10s | Geração criativa convencional |
| high | Raciocínio profundo | +15-25s | Composição complexa, renderização precisa de texto |
Exemplo de Código: Configurando o Nível de Pensamento
import openai
client = openai.OpenAI(
api_key="SUA_API_KEY",
base_url="https://api.apiyi.com/v1" # Usando a interface unificada da APIYI
)
# Cenário simples: Usando nível de pensamento 'low'
response = client.images.generate(
model="nano-banana-pro",
prompt="um gato laranja sentado no parapeito da janela",
size="2048x2048",
extra_body={
"thinking_level": "low" # Comando simples, baixo nível de pensamento
}
)
# Cenário complexo: Usando nível de pensamento 'high'
# "Um infográfico profissional de produto, contendo o título 'Lançamento 2025', três características do produto, etiqueta de preço $99.99, usando esquema de cores azul tecnológico"
response = client.images.generate(
model="nano-banana-pro",
prompt="一张专业的产品信息图,包含标题'2025新品发布'、三个产品特性、价格标签$99.99,采用科技蓝配色",
size="2048x2048",
extra_body={
"thinking_level": "high" # Renderização de texto complexa, exige alto nível de pensamento
}
)
🚀 Dica Prática: Para cenários simples como "um gato" ou "uma floresta", definir o
thinking_levelcomolowpode economizar de 20% a 30% do tempo de geração. O nívelhighsó é necessário quando houver renderização precisa de texto ou relações espaciais complexas.
Dica de Otimização de Velocidade 3 para o Nano Banana Pro: Otimização da Transmissão de Rede
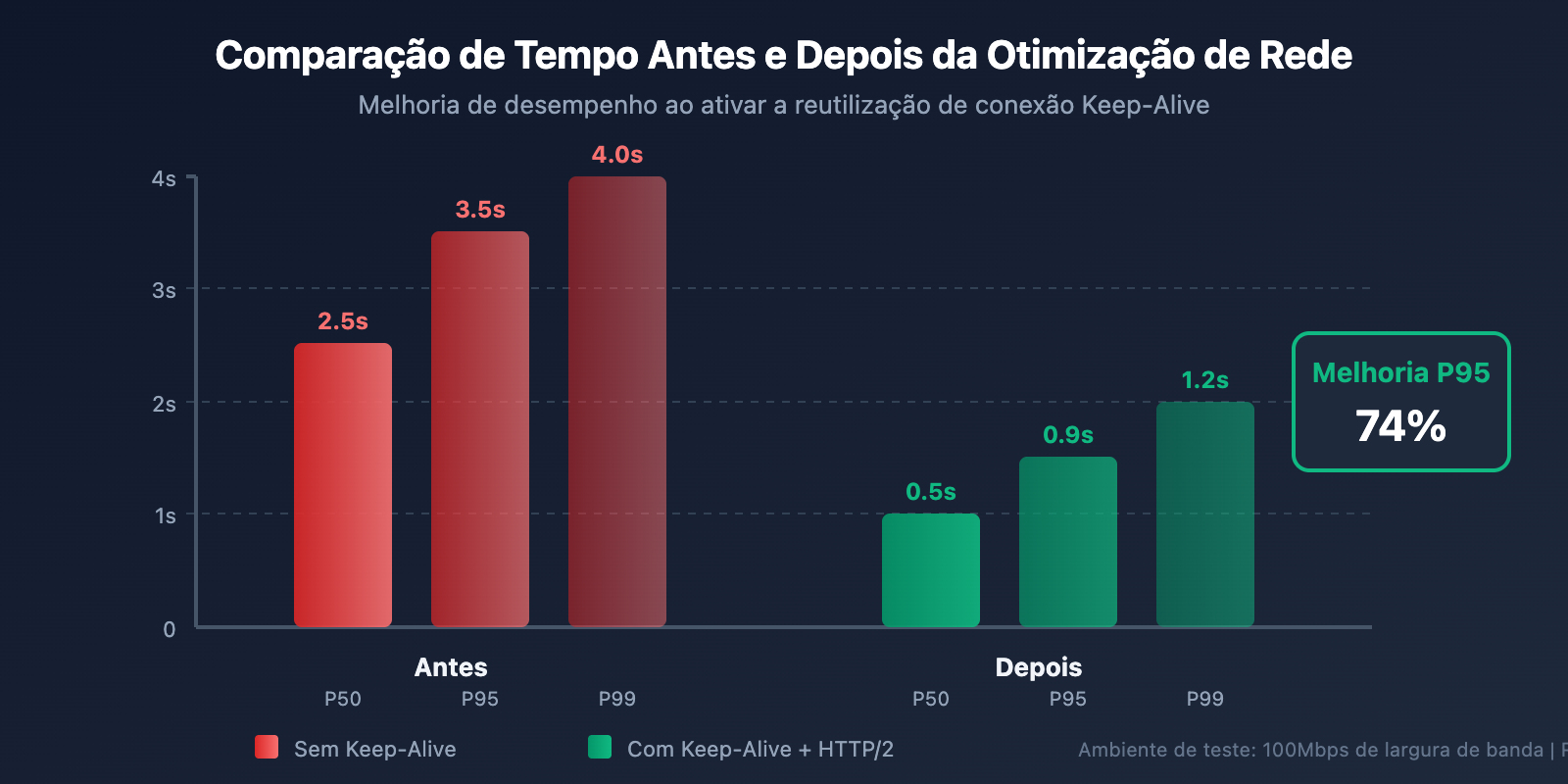
Muitos desenvolvedores ignoram o fato de que: uma resposta rápida da interface da API não significa que o tempo total seja curto. Dados de testes reais mostram que a transmissão de rede pode ocupar de 20% a 30% do tempo total.
Decomposição do Tempo de Rede do Nano Banana Pro
Tomando como exemplo uma imagem 2K, uma imagem PNG 2K codificada em base64 tem cerca de 4-6MB:
| Etapa | Volume de Dados | Largura de Banda 10Mbps | Largura de Banda 100Mbps | Largura de Banda 1Gbps |
|---|---|---|---|---|
| Upload da requisição | ~1KB | <0.1s | <0.1s | <0.1s |
| Download da resposta | ~5MB | 4s | 0.4s | 0.04s |
| Handshake TLS | – | 0.1-0.3s | 0.1-0.3s | 0.1-0.3s |
Prática de Otimização de Rede
import httpx
import time
# 优化1: 启用连接复用 (Keep-Alive)
# 某团队通过启用 Keep-Alive 将 P95 延迟从 3.5s 降到 0.9s
client = httpx.Client(
base_url="https://api.apiyi.com/v1",
http2=True, # 启用 HTTP/2
timeout=60.0,
limits=httpx.Limits(
max_keepalive_connections=10, # 保持连接池
keepalive_expiry=30.0 # 连接存活时间
)
)
# 优化2: 添加详细的耗时日志
def generate_with_timing(prompt: str, size: str = "2048x2048"):
"""带耗时统计的图像生成"""
timings = {}
start = time.time()
# 发送请求
response = client.post(
"/images/generations",
json={
"model": "nano-banana-pro",
"prompt": prompt,
"size": size,
"response_format": "b64_json"
},
headers={"Authorization": f"Bearer {api_key}"}
)
timings["api_total"] = time.time() - start
# 解析响应
parse_start = time.time()
result = response.json()
timings["parse_time"] = time.time() - parse_start
print(f"API 耗时: {timings['api_total']:.2f}s")
print(f"解析耗时: {timings['parse_time']:.2f}s")
return result
📊 Dados reais: Testes de velocidade na plataforma APIYI (imagen.apiyi.com) mostram que, para usuários que acessam através de nós otimizados, o tempo de resposta da API para imagens 2K é de cerca de 20 a 30 segundos. Somado ao tempo de download, o tempo total pode ser estabilizado em menos de 50 segundos.
Dica de Otimização de Velocidade 4 para o Nano Banana Pro: Usando geração em grade para produção em lote
Se você precisa explorar direções criativas rapidamente ou gerar múltiplas variantes, a geração em grade é um truque de aceleração subestimado.
Comparativo: Geração em grade vs. Geração de imagem única
| Método de geração | Tempo para 4 imagens | Custo por imagem | Cenário ideal |
|---|---|---|---|
| Imagem única ×4 | 4 × 30s = 120s | $0.05 | Quando precisa de controle individual |
| Grade 2×2 | Cerca de 40s | ~$0.034 | Exploração rápida, iteração criativa |
Exemplo de código para geração em grade
# Use a geração em grade para produzir rapidamente múltiplas variantes
response = client.images.generate(
model="nano-banana-pro",
prompt="Design de sala de estar em estilo moderno e minimalista",
size="2048x2048",
extra_body={
"grid": "2x2", # Gera uma grade 2x2
"thinking_level": "low" # Use nível de pensamento baixo na fase de exploração
}
)
# Aproximadamente 40 segundos para 4 variantes, cerca de $0,034 por imagem
🎯 Sugestão de uso: Use a geração em grade para iterar rapidamente durante a fase de exploração criativa. Depois de definir a direção, use a geração de imagem única para alta qualidade. Ao fazer chamadas pela plataforma APIYI (apiyi.com), a geração em grade também é suportada e possui métodos de tarifação mais flexíveis.
Dica de Otimização de Velocidade 5 para o Nano Banana Pro: Configurando timeout e tentativas de forma inteligente
Em ambientes de produção, estratégias adequadas de timeout (tempo esgotado) e retentativas (retry) evitam que requisições falhem por causa de latências ocasionais.
Configurações de timeout recomendadas
| Resolução | Timeout recomendado | Tentativas (Retries) | Intervalo |
|---|---|---|---|
| 1K | 45s | 2 | 5s |
| 2K | 90s | 2 | 10s |
| 4K | 180s | 3 | 15s |
Exemplo de código para ambiente de produção
import openai
from tenacity import retry, stop_after_attempt, wait_exponential
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1", # Interface unificada da APIYI
timeout=90.0 # Timeout recomendado de 90s para imagens 2K
)
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=5, max=30)
)
def generate_image_with_retry(prompt: str, size: str = "2048x2048"):
"""Geração de imagem com retry e exponential backoff"""
return client.images.generate(
model="nano-banana-pro",
prompt=prompt,
size=size,
extra_body={"thinking_level": "low"}
)
# Uso
try:
result = generate_image_with_retry("Um campo de trigo dourado ao pôr do sol")
print("Gerado com sucesso!")
except Exception as e:
print(f"Falha na geração: {e}")
Dica de Otimização de Velocidade do Nano Banana Pro 6: Escolhendo o Provedor de API Adequado
As diferenças na infraestrutura de diferentes provedores de API afetam diretamente a velocidade de resposta.
Comparação de Provedores de API para Nano Banana Pro
| Provedor | Latência de Acesso | Velocidade de Geração 2K | Preço Unitário | Características |
|---|---|---|---|---|
| Google Oficial | 3-8s de latência extra | 30-50s | $0.134 | Requer cartão internacional |
| APIYI | Nós otimizados | 30-40s | $0.05 | Suporta Alipay/WeChat |
| Outros intermediários | Instável | 40-60s | $0.08-0.15 | Qualidade variável |
💰 Otimização de custos: Ao utilizar o Nano Banana Pro através da APIYI (apiyi.com), o preço unitário é de apenas $0,05 por imagem, o que representa uma economia de cerca de 63% em comparação aos $0,134 do site oficial. Além disso, a latência de acesso local é menor, resultando em uma melhor experiência geral. Clientes de grande volume ainda contam com bônus extras, podendo chegar ao custo mínimo de $0,04 por imagem.
Exemplo Completo de Configuração Otimizada
Clique para expandir o código completo
"""
Nano Banana Pro 速度优化完整示例
通过 APIYI平台调用,集成所有优化技巧
"""
import openai
import time
import base64
from pathlib import Path
from tenacity import retry, stop_after_attempt, wait_exponential
class NanoBananaProClient:
"""优化后的 Nano Banana Pro 客户端"""
def __init__(self, api_key: str):
self.client = openai.OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1", # APIYI 统一接口
timeout=90.0,
max_retries=0 # 使用自定义重试逻辑
)
def choose_params(self, use_case: str, quality: str = "balanced"):
"""根据场景智能选择参数"""
configs = {
"preview": {
"size": "1024x1024",
"thinking_level": "low"
},
"production": {
"size": "2048x2048",
"thinking_level": "low" if quality == "fast" else "medium"
},
"premium": {
"size": "4096x4096",
"thinking_level": "high"
}
}
return configs.get(use_case, configs["production"])
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=5, max=30)
)
def generate(
self,
prompt: str,
use_case: str = "production",
quality: str = "balanced"
) -> dict:
"""生成图像,带自动参数优化"""
params = self.choose_params(use_case, quality)
start_time = time.time()
response = self.client.images.generate(
model="nano-banana-pro",
prompt=prompt,
size=params["size"],
response_format="b64_json",
extra_body={
"thinking_level": params["thinking_level"]
}
)
elapsed = time.time() - start_time
return {
"image_data": response.data[0].b64_json,
"elapsed_seconds": elapsed,
"size": params["size"],
"thinking_level": params["thinking_level"]
}
def generate_batch(
self,
prompts: list[str],
use_case: str = "preview"
) -> list[dict]:
"""批量生成,自动使用低配置加速"""
results = []
for prompt in prompts:
result = self.generate(prompt, use_case=use_case, quality="fast")
results.append(result)
return results
def save_image(self, b64_data: str, output_path: str):
"""保存 base64 图像到文件"""
image_bytes = base64.b64decode(b64_data)
Path(output_path).write_bytes(image_bytes)
# 使用示例
if __name__ == "__main__":
client = NanoBananaProClient(api_key="your-api-key")
# 场景1: 快速预览
preview = client.generate(
prompt="一只橙色的猫",
use_case="preview"
)
print(f"预览生成耗时: {preview['elapsed_seconds']:.2f}s")
# 场景2: 生产环境
production = client.generate(
prompt="专业的电商产品展示图,白色背景,侧面 45 度角",
use_case="production"
)
print(f"生产生成耗时: {production['elapsed_seconds']:.2f}s")
# 场景3: 高端设计
premium = client.generate(
prompt="4K 超高清,现代简约客厅,大落地窗,阳光洒落",
use_case="premium"
)
print(f"高端生成耗时: {premium['elapsed_seconds']:.2f}s")
Perguntas Frequentes sobre Otimização de Velocidade do Nano Banana Pro
P1: Por que o tempo de geração varia para o mesmo comando em cada tentativa?
O tempo de geração do Nano Banana Pro é influenciado por vários fatores:
- Flutuação da carga do modelo: Durante horários de pico (como o horário comercial nos EUA), a carga do servidor é maior, e o tempo de resposta pode aumentar em 10-30%.
- Complexidade do comando: Mesmo para comandos semelhantes, o caminho de inferência interna do modelo pode variar.
- Condições da rede: Existem flutuações naturais na transmissão internacional de dados.
Sugestão de otimização: Ao utilizar a plataforma APIYI (apiyi.com), seus nós otimizados podem mitigar parcialmente os problemas de flutuação de rede. Também recomendamos evitar horários de pico internacionais.
P2: Se o preço de 2K e 4K é o mesmo, por que não usar 4K diretamente?
Preço igual não significa eficiência igual:
| Dimensão | 2K | 4K | Diferença |
|---|---|---|---|
| Tempo de Geração | 30-40s | 50-70s | 4K é cerca de 60% mais lento |
| Transmissão de Dados | ~3MB | ~10MB | Volume de dados muito maior no 4K |
| Custo de Armazenamento | Referência | Aprox. 3.3x | Custo de armazenamento a longo prazo é alto |
Conclusão: A menos que seu projeto exija explicitamente 4K (como materiais impressos ou telas gigantes), o 2K é a escolha mais inteligente. Ao realizar chamadas em lote pela plataforma APIYI, a vantagem de eficiência do 2K torna-se ainda mais evidente.
P3: Como identificar se o gargalo está na API ou na rede?
Adicionar logs detalhados de tempo é a chave para o diagnóstico:
import time
# Registra o momento do envio da requisição
t1 = time.time()
response = client.images.generate(...)
t2 = time.time()
# Registra o tempo de processamento dos dados
data = response.data[0].b64_json
t3 = time.time()
print(f"Tempo de resposta da API: {t2-t1:.2f}s")
print(f"Tempo de processamento de dados: {t3-t2:.2f}s")
Se a resposta da API for rápida, mas o tempo total for longo, o gargalo está na transmissão de rede. Você pode validar o desempenho do lado da API usando ferramentas de teste de velocidade online como imagen.apiyi.com.
P4: Como maximizar o rendimento na geração em lote?
Estratégias de otimização para geração em lote:
- Requisições simultâneas: Configure o número de conexões paralelas de acordo com a política de limite de taxa da API (geralmente entre 5 e 10).
- Geração em grade (Grid): Uma grade de 2×2 produz 4 imagens de uma vez, aumentando a eficiência em cerca de 3 vezes.
- Reduzir configurações: Para cenários em lote, priorize o uso de 1K + low thinking.
- Processamento assíncrono: Utilize
asyncioou pools de threads para processamento paralelo.
Ao utilizar a APIYI, você tem acesso a limites de simultaneidade mais altos, ideal para demandas de geração em grande escala.
Resumo de Otimização de Velocidade do Nano Banana Pro

Este artigo apresenta 6 dicas de otimização de velocidade para o Nano Banana Pro:
| Dica | Efeito de Otimização | Dificuldade | Prioridade |
|---|---|---|---|
| Escolher Resolução 2K | Economia de 45% de tempo | Baixa | ⭐⭐⭐⭐⭐ |
| Ajustar Nível de Reflexão | Economia de 20-30% | Baixa | ⭐⭐⭐⭐⭐ |
| Otimizar Transmissão de Rede | Economia de 10-20% | Média | ⭐⭐⭐⭐ |
| Geração em Lote de Grade | Aumento de 3x na eficiência | Baixa | ⭐⭐⭐⭐ |
| Estratégia de Timeout/Retry | Melhora a estabilidade | Média | ⭐⭐⭐ |
| Escolher Provedor de Qualidade | Melhoria geral | Baixa | ⭐⭐⭐⭐⭐ |
Conclusão Principal: Combinando resolução 2K, nível de reflexão "low" e reuso de conexão, é perfeitamente possível estabilizar a geração de uma imagem 2K em 50 segundos.
🎯 Sugestão Final: Recomendamos usar a APIYI (apiyi.com) para validar rapidamente os efeitos da otimização. A plataforma oferece a ferramenta de teste online
imagen.apiyi.com, facilitando o monitoramento em tempo real do tempo gasto em cada etapa. Além disso, o preço de $0,05 por imagem (37% dos $0,134 oficiais) ajuda a reduzir drasticamente os custos de teste.
Este artigo foi escrito pela equipe técnica da APIYI. Para saber mais dicas sobre o uso de APIs de geração de imagens por IA, visite apiyi.com para obter suporte técnico.