Al implementar la API gpt-image-2 en entornos de producción, los desarrolladores suelen encontrarse con este desconcertante error 400:
{
"status_code": 400,
"error": {
"message": "Your request was rejected by the safety system. If you believe this is an error, contact us at Azure support ticket and include the request ID 76fd2cbc-63ee-4e30-8bea-5fc2a2e1faa3.",
"type": "shell_api_error",
"code": "moderation_blocked"
}
}
Este error moderation_blocked proviene del sistema de seguridad de contenido de OpenAI/Azure, el cual intercepta proactivamente las solicitudes que considera que infringen sus políticas, ya sea antes o después de la inferencia del modelo. A diferencia de un error 429 por limitación de tasa o un error 500 del servicio, el moderation_blocked no desaparece por sí solo: si no cambias la indicación, puedes reintentarlo diez mil veces y seguirá siendo bloqueado.
En este artículo, analizamos sistemáticamente los principios técnicos del error moderation_blocked, los 7 escenarios comunes que lo disparan, métodos de diagnóstico y reproducción, además de ofrecer 6 estrategias de reescritura de indicaciones y soluciones alternativas con otros modelos, para ayudarte a reducir la incidencia de estos errores a un nivel aceptable.

I. Principios técnicos del error 400 moderation_blocked en gpt-image-2
1.1 Desglose de la estructura del error
El cuerpo del error anterior contiene varios campos clave:
| Campo | Significado |
|---|---|
status_code: 400 |
HTTP 400 Bad Request, indica que la solicitud del cliente fue rechazada |
type: shell_api_error |
Error en la capa de la puerta de enlace de la API, no un error de inferencia del modelo |
code: moderation_blocked |
Código de error central: bloqueado por el sistema de seguridad de contenido |
message |
Explicación legible para humanos, incluye el ID de solicitud |
request id |
ID de seguimiento para reclamaciones o resolución de problemas |
Ten en cuenta que el mensaje menciona "Azure support ticket" (ticket de soporte de Azure), lo cual es una pista importante: ciertos enlaces de despliegue de gpt-image-2 son alojados finalmente por Azure OpenAI, por lo que el sistema de seguridad es el filtro de contenido de Azure. Las reglas de filtrado de Azure son más estrictas que las de la conexión directa a OpenAI, y esta es la razón fundamental por la que la tasa de activación de moderation_blocked varía significativamente entre diferentes canales.
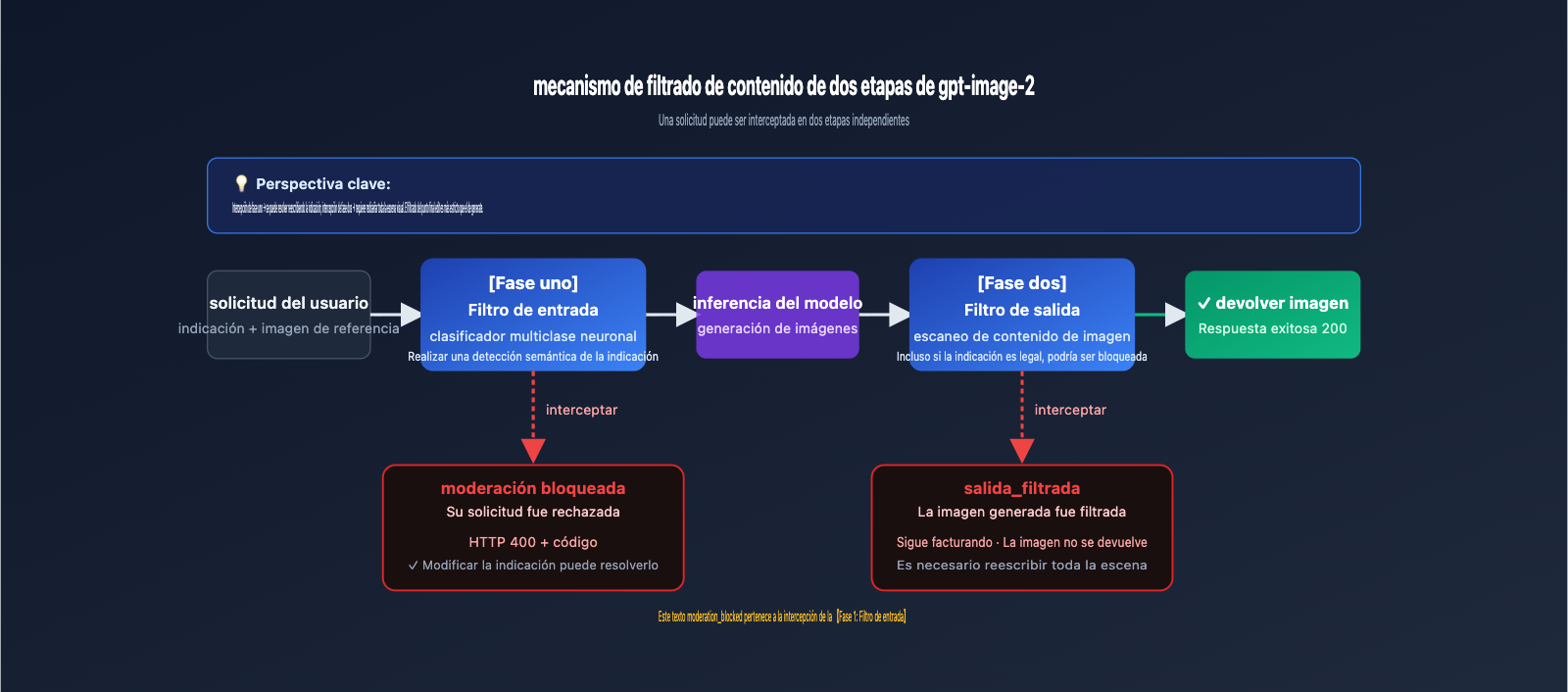
1.2 Mecanismo de filtrado de contenido de dos etapas de gpt-image-2
Según la tarjeta de sistema de ChatGPT Images 2.0 de OpenAI y la documentación de Azure OpenAI, el filtrado de contenido de gpt-image-2 emplea un filtro de dos etapas:
Solicitud del usuario
↓
【Etapa 1: Filtro de entrada】
↓ (Aprobado)
Inferencia del modelo para generar la imagen
↓
【Etapa 2: Filtro de salida】
↓ (Aprobado)
Devolver la imagen al usuario
Etapa 1 (Filtro de entrada): Antes de la inferencia del modelo, se realiza una detección de clasificación sobre el texto de la indicación + la imagen de referencia. Se utiliza un clasificador neuronal multiclase para detectar contenido que infrinja las políticas de OpenAI (odio, violencia, sexo, autolesiones, figuras públicas, derechos de autor, etc.).
Etapa 2 (Filtro de salida): Después de generar la imagen, se escanea nuevamente; incluso si la indicación es legítima, si la imagen generada "parece" infringir las normas, será bloqueada.
Diferencias clave:
- Si el error es
"Your request was rejected"→ Bloqueado en la etapa de entrada, se soluciona modificando la indicación. - Si el error es
"Generated image was filtered"→ Bloqueado en la etapa de salida, es necesario reescribir toda la escena.
El moderation_blocked que discutimos aquí pertenece al primer tipo: bloqueado en la etapa de entrada, lo que significa que la optimización a nivel de indicación sigue siendo la forma más efectiva de resolverlo.
1.3 El punto final de edición de gpt-image-2 es más estricto
Un hecho que suele pasarse por alto: la estrategia de filtrado del punto final /v1/images/edits es más estricta que la de /v1/images/generations.
Azure especifica claramente que, para la edición de imágenes, se añaden controles de seguridad adicionales sobre el filtrado de generación, lo que significa que una misma indicación + imagen puede pasar en el punto final de generación, pero ser bloqueada por moderation_blocked en el punto final de edición. Esto es un diseño intencional para evitar que los usuarios realicen modificaciones no permitidas en fotos existentes (como deepfakes, desnudos, etc.).
二、 7 escenarios principales que activan el error moderation_blocked en gpt-image-2
Los siguientes 7 escenarios están ordenados según su frecuencia de activación real y cubren más del 90% de los casos de moderation_blocked.
2.1 Escenario 1: Retratos de personas reales y nombres de celebridades
Esta es la causa más común. Cualquier indicación con las siguientes formas es muy propensa a ser bloqueada:
❌ Patrones de alto riesgo:
- Generar una foto de Musk en Marte
- Una foto grupal de Trump y Obama
- El escenario de un concierto de Taylor Swift
- Una actriz que imita a Scarlett Johansson
OpenAI protege estrictamente los retratos de celebridades que no han optado por salir (opt-out). Tras el incidente de Bryan Cranston en octubre de 2025, esta estrategia se endureció aún más. Incluso si intentas generar a alguien que "se parece a" en lugar de usar el nombre directamente, si la indicación menciona a una figura pública, será bloqueada.
2.2 Escenario 2: Artistas vivos y expresiones estilizadas
Los nombres de artistas o creadores vivos son palabras clave de bloqueo estricto:
❌ Alto riesgo:
- Ilustración al estilo de Hayao Miyazaki
- Paisaje nocturno urbano con los tonos de Makoto Shinkai
- Grafiti callejero al estilo de Banksy
✅ Escritura equivalente de bajo riesgo:
- Estilo Ghibli / Estilo de animación japonesa moderna y brillante
- Escena de animación juvenil japonesa con colores saturados
- Estilo de arte callejero urbano moderno
Regla: Convierte el "nombre del artista" en "género/estudio/nombre de estilo". Los artistas fallecidos (Van Gogh, Monet) generalmente no son bloqueados.
2.3 Escenario 3: Personajes con derechos de autor y propiedad intelectual comercial
Los personajes con nombre bajo propiedad intelectual (IP) como Disney, Marvel, Ghibli, Pixar, Nintendo, etc., son bloqueos directos:
❌ Alto riesgo:
- Spider-Man balanceándose entre edificios
- Escena de fiesta de Mickey Mouse
- Un Pikachu en el bosque
✅ Escritura equivalente de bajo riesgo:
- Un personaje vigilante original con traje de superhéroe rojo y azul, balanceándose con telarañas en una metrópolis de neón
- Una fiesta retro organizada por un ratón antropomórfico de dibujos animados
- Una criatura eléctrica amarilla de dibujos animados en el bosque
Regla: Usa "inspirado en" o "estilo similar" en lugar de nombrar directamente al personaje.
2.4 Escenario 4: Violencia, sangre y detalles de armas
❌ Alto riesgo:
- Primer plano de una herida sangrante
- Salpicaduras de sangre en el momento de una explosión
- Imagen detallada de un AK-47
✅ Escritura para evitar bloqueos:
- Imagen abstracta con salpicaduras de pintura roja intensa
- Escena de superhéroe con estallidos de luz brillante y escombros
- Concepto artístico de arma en un juego táctico (estilizado, no realista)
Regla: Sustituye descripciones "realistas, detalladas o clínicas" por descripciones "artísticas, abstractas o estilizadas".
2.5 Escenario 5: Sugestiones sexuales y vestimenta reveladora
Esta es una de las áreas más estrictas de gpt-image-2; cualquier contenido que pueda interpretarse como sexualmente sugerente será bloqueado, incluso descripciones que parecen inofensivas:
❌ Alto riesgo (parecen inofensivas pero se bloquean):
- Escena de playa con bikini
- Mujer con hombros descubiertos
- Ropa ajustada que marca el cuerpo
- Postura seductora
✅ Escritura para evitar bloqueos:
- Escena de vacaciones en la playa en verano, plano general
- Mujer con vestido de noche elegante
- Retrato de ropa deportiva estilo revista de moda
- Postura de modelo segura
Regla: Evita adjetivos como "ajustado, revelador, sexy, tentador" y cámbialos por términos neutros como "elegante, moderno, seguro".
2.6 Escenario 6: Imágenes realistas relacionadas con niños
OpenAI tiene una política de tolerancia casi cero para la generación realista de niños. Cualquier escritura como la siguiente será bloqueada:
❌ Alto riesgo:
- Foto realista de una niña de 8 años
- Niños en traje de baño junto a la piscina
- Retrato detallado de un bebé
✅ Escritura segura:
- Ilustración de una escena de infancia estilo dibujos animados
- Plano general de una escena familiar realista, sin enfocar a ninguna persona
- Ilustración artística de una madre sosteniendo a un bebé
Regla: Para temas relacionados con niños, usa preferiblemente estilos de ilustración/dibujos animados y evita palabras como "realista, primer plano, detallado, calidad fotográfica".
2.7 Escenario 7: Odio, política extrema y símbolos sensibles
Los símbolos de odio, tótems políticos extremos y representaciones de conflictos religiosos son bloqueos directos:
❌ Alto riesgo:
- Esvástica nazi
- Escenas de confrontación política extrema
- Narrativas de conflicto de países específicos
Este tipo de contenido casi no tiene margen de reescritura, por lo que se recomienda evitar por completo esta dirección temática.
III. Proceso de diagnóstico para errores moderation_blocked en gpt-image-2
3.1 Diagrama de flujo de diagnóstico

Cuando recibas un error moderation_blocked, sigue este proceso de diagnóstico:
Paso 1. Registra el mensaje de error completo + ID de solicitud
↓
Paso 2. Determina si es "rejected" (bloqueo de entrada) o "filtered" (bloqueo de salida)
↓
Paso 3. Compara con los 7 escenarios principales para localizar la causa
↓
Paso 4. Elimina gradualmente palabras clave de la indicación usando el método de bisección para reproducir el error
↓
Paso 5. Selecciona la estrategia de reescritura correspondiente (ver capítulo 4)
↓
Paso 6. Reintenta tras la reescritura y registra el cambio en la tasa de éxito
3.2 Reproducción de palabras clave de activación mediante bisección
Cuando no estés seguro de qué palabra en la indicación activó el bloqueo, puedes usar el método de bisección:
from openai import OpenAI
client = OpenAI(
api_key="TU_CLAVE_APIYI",
base_url="https://api.apiyi.com/v1"
)
def binary_search_trigger(full_prompt: str):
"""Usa bisección para encontrar la palabra clave que activa moderation_blocked"""
words = full_prompt.split()
mid = len(words) // 2
left_half = " ".join(words[:mid])
right_half = " ".join(words[mid:])
for test_prompt in [left_half, right_half]:
try:
client.images.generate(
model="gpt-image-2",
prompt=test_prompt,
size="1024x1024",
quality="low",
n=1
)
print(f"✓ Aprobado: {test_prompt[:40]}...")
except Exception as e:
if "moderation_blocked" in str(e):
print(f"✗ Activado: {test_prompt[:40]}...")
binary_search_trigger("Contenido original de la indicación ...")
Al ejecutar este script a través de APIYI (apiyi.com), utiliza quality="low" para reducir al mínimo el costo de cada prueba ($0.006 por imagen) y localizar rápidamente la palabra que causa el bloqueo.
3.3 Pre-verificación con la API de Moderación de OpenAI
OpenAI ofrece un punto de conexión gratuito /v1/moderations que permite pre-verificar el texto de la indicación antes de realizar la invocación del modelo para ver si será bloqueada:
def pre_check_prompt(prompt: str):
result = client.moderations.create(
model="omni-moderation-latest",
input=prompt
)
categories = result.results[0].categories
scores = result.results[0].category_scores
flagged_categories = [
(cat, scores.model_dump()[cat])
for cat, flagged in categories.model_dump().items()
if flagged
]
if flagged_categories:
print(f"⚠️ Indicación marcada: {flagged_categories}")
return False
return True
Nota: La pre-verificación solo puede comprobar la dimensión del texto, no puede detectar bloqueos de tipo "juicio semántico" como derechos de autor o celebridades. Sin embargo, tiene una alta precisión para términos obviamente infractores como "violencia, sexo u odio".
IV. 6 estrategias de reescritura de indicaciones para el error moderation_blocked en gpt-image-2
4.1 Estrategia 1: Reemplazar nombres por géneros o estudios
| Escritura original | Reescritura |
|---|---|
| Estilo Hayao Miyazaki | Ghibli / Estilo de animación japonesa moderna y brillante |
| Estilo Makoto Shinkai | Animación japonesa juvenil con colores saturados |
| Estilo Disney | Estilo de dibujos animados estadounidenses clásico |
| Anne Hathaway | Una actriz elegante de 35 años |
| Elon Musk | Un fundador de empresa tecnológica con traje |
4.2 Estrategia 2: Sustituir artistas vivos por fallecidos
Artista vivo → Artista fallecido del mismo género:
| Artista vivo (bloqueado) | Artista fallecido (permitido) |
|---|---|
| Grafiti estilo Banksy | Grafiti estilo Basquiat / Arte callejero de los 80 |
| Estilo Makoto Shinkai | (Usar directamente "estilo de animación japonesa") |
| Hayao Miyazaki | (Usar "Ghibli") |
| Takashi Murakami | Estilo arte pop / Estilo Andy Warhol |
Maestros clásicos como Van Gogh, Monet, Picasso, Rembrandt y Hokusai son referencias seguras.
4.3 Estrategia 3: Abstracción de personajes con derechos de autor
Transforma las IP con nombre en "características generales + descripción narrativa":
Escritura original: Spider-Man balanceándose sobre Nueva York
Reescritura: Un joven con un traje de superhéroe ajustado rojo y azul, con máscara, balanceándose entre los rascacielos de una metrópolis de neón usando telarañas, lleno de dinamismo y energía
Escritura original: Pikachu en el bosque
Reescritura: Una criatura de dibujos animados eléctrica, redonda y linda, con mejillas rojas y orejas puntiagudas, saltando en un bosque verde y denso
Técnica clave: conservar los rasgos visuales, eliminar el nombre.
4.4 Estrategia 4: Método de descripción en dos pasos (Two-Step Description)
Para escenas complejas que podrían rozar los límites, utiliza este método:
Paso 1: Pide a Gemini Pro o Claude 4 Sonnet que "traduzca" tu idea original a una descripción de elementos puramente visuales, eliminando proactivamente nombres de famosos, IP o términos sensibles.
Paso 2: Utiliza la salida del Paso 1 como la indicación real para gpt-image-2.
def two_step_generate(raw_idea: str):
# Usamos el LLM para limpiar la indicación
rewriter_response = client.chat.completions.create(
model="gemini-3-pro",
messages=[
{
"role": "system",
"content": (
"Eres un experto en descripción visual. Reescribe las ideas del usuario como una descripción de elementos puramente visuales:"
"Elimina todos los nombres reales, marcas, nombres de personajes con derechos de autor y términos sensibles;"
"Conserva: color, composición, iluminación, acción, atmósfera, textura, lente."
"Genera una narración coherente de 150-250 palabras, no uses listas."
)
},
{"role": "user", "content": raw_idea}
]
)
safe_prompt = rewriter_response.choices[0].message.content
return client.images.generate(
model="gpt-image-2",
prompt=safe_prompt,
size="1024x1024",
quality="medium"
)
Este método aprovecha la integración unificada de múltiples modelos de APIYI (apiyi.com), utilizando un LLM de texto como una "capa de purificación de seguridad" previa, lo que reduce drásticamente la tasa de activación de moderation_blocked en la API de imágenes.
4.5 Estrategia 5: Sustituir términos violentos o sexuales por emociones/atmósfera
| Término original | Sustituto neutral |
|---|---|
| Sangriento (bloody) | Tonos rojo oscuro / Dramático |
| Violento (violent) | Intenso / Lleno de tensión |
| Sexy (sexy) | Elegante / Seguro / Atractivo |
| Desnudo (naked/nude) | Estilo escultura clásica / Cuerpo artístico |
| Seductor (seductive) | Carácter encantador |
| Matanza (killing) | Confrontación dramática |
| Arma (weapon) | Utilería / Herramienta |
4.6 Estrategia 6: Degradación al endpoint de generación al usar el endpoint de edición
Como mencionamos, el endpoint edits tiene filtros más estrictos. Si tu tarea es "modificar una imagen existente", intenta lo siguiente:
Flujo original: /v1/images/edits (bloqueado)
Flujo alternativo:
- Usa un LLM para describir los elementos visuales de la imagen original.
- Añade los "puntos de modificación".
- Lanza la petición a
/v1/images/generationspara regenerar.
Aunque se sacrifica la consistencia a nivel de píxel, permite evitar el filtrado estricto de edición.
V. Soluciones de respaldo con múltiples modelos para el error moderation_blocked en gpt-image-2
Cuando un modelo único se encuentra con un bloqueo estricto, el enrutamiento entre múltiples modelos es la práctica estándar en aplicaciones empresariales.
5.1 Comparativa de severidad de filtrado en modelos de imagen
| Modelo | Severidad de filtrado | Tolerancia a famosos | Tolerancia a IP | Expresión artística |
|---|---|---|---|---|
gpt-image-2 oficial |
🔴 Estricto | Muy estricta | Estricta | Conservadora |
gpt-image-2-all |
🟡 Media | Media | Media | Flexible |
| Nano Banana Pro | 🟢 Más permisivo | Media | Media | Flexible |
| Nano Banana 2 | 🟢 Más permisivo | Media | Media | Flexible |
| Serie Imagen | 🟡 Media | Estricta | Media | Media |
Recomendación práctica: Cuando gpt-image-2 oficial sea bloqueado, intenta degradar en este orden:
gpt-image-2 (oficial) [moderation_blocked]
↓
gpt-image-2-all [posible paso]
↓
Nano Banana Pro [alta probabilidad de paso]
↓
Nano Banana 2 [más flexible, calidad ligeramente inferior]
5.2 Ejemplo de código para degradación automática
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
MODEL_FALLBACK_CHAIN = [
("gpt-image-2", "images"),
("gpt-image-2-all", "chat"),
("gemini-3-pro-image-preview", "images"),
("gemini-3.1-flash-image-preview", "images"),
]
def generate_with_fallback(prompt: str):
last_error = None
for model_id, endpoint in MODEL_FALLBACK_CHAIN:
try:
if endpoint == "images":
return client.images.generate(
model=model_id,
prompt=prompt,
size="1024x1024"
)
else:
return client.chat.completions.create(
model=model_id,
messages=[{"role": "user", "content": prompt}]
)
except Exception as e:
if "moderation_blocked" in str(e) or "content_policy" in str(e):
print(f"Modelo {model_id} bloqueado, intentando el siguiente")
last_error = e
continue
raise
raise Exception(f"Todos los modelos fueron bloqueados, último error: {last_error}")
El valor central de este patrón: bajo una misma cuenta de APIYI (apiyi.com), puedes implementar la degradación entre modelos simplemente cambiando el parámetro model, sin necesidad de registrar múltiples servicios ni gestionar múltiples credenciales.
5.3 Estrategia avanzada de enrutamiento según el tipo de contenido
Un enfoque más refinado consiste en predecir el modelo más adecuado según el tipo de contenido:
| Tipo de contenido | Modelo preferido | Motivo |
|---|---|---|
| Material de marca corporativa | gpt-image-2 oficial | Estable, cumple normativas |
| Carteles con texto en chino | gpt-image-2-all | Optimizado nativamente para chino |
| Imágenes creativas con posible IP | Nano Banana Pro | Filtrado más permisivo |
| Generación masiva y rápida | Nano Banana 2 | Rápido y bajo costo |
| Arte con estilos especiales | Nano Banana Pro | Expresión artística flexible |
VI. Proceso de apelación empresarial para moderation_blocked en gpt-image-2
Cuando tengas la certeza de que tu indicación es legítima y no debería haber sido bloqueada (un falso positivo), puedes iniciar un proceso de apelación.
6.1 Lista de verificación para la apelación
Antes de enviar tu solicitud, recopila la siguiente información:
- Respuesta de error completa (incluyendo el ID de solicitud).
- La indicación completa que activó el
moderation_blocked. - Marca de tiempo de la invocación.
- Tu ID de cuenta.
- Explicación del caso de uso (por qué necesitas esta indicación).
- Pasos para reproducir (¿es un error constante?).
6.2 Canales de apelación

L1: Nivel de autoservicio (el más rápido)
Intenta primero las 6 estrategias de reescritura del capítulo 4; más del 90% de los moderation_blocked se resuelven en este nivel sin costo alguno.
L2: Canal de servicio empresarial de APIYI (recomendado)
Para clientes corporativos, APIYI (apiyi.com) ofrece soporte técnico exclusivo, proporcionando para casos específicos de moderation_blocked:
- Sugerencias de reescritura de la indicación.
- Diseño de planes de degradación a otros modelos.
- Gestión del proceso de apelación ante OpenAI/Azure.
Este nivel ofrece una respuesta rápida y, además, el equipo de APIYI cuenta con una amplia experiencia en la apelación de falsos positivos en modelos de imagen, lo que resulta mucho más eficiente que gestionar los tickets oficiales por cuenta propia.
L3: Apelación oficial (la más lenta, pero definitiva)
Envía una apelación a través del ticket de soporte de Azure o el Centro de Ayuda oficial de OpenAI mencionado en el mensaje de error, adjuntando el ID de solicitud completo. El tiempo de respuesta suele ser de 3 a 10 días hábiles.
6.3 Prácticas de ingeniería para reducir sistemáticamente la tasa de activación
Para sistemas de producción con alta frecuencia de llamadas, recomendamos construir una puerta de enlace de seguridad para indicaciones:
Solicitud original del usuario
↓
[1] Pre-filtrado de lista negra de palabras clave (nivel de segundos)
↓
[2] Pre-verificación con la API de moderación de OpenAI (gratuito, 300ms)
↓
[3] Reescritura de la indicación mediante un LLM de texto para mayor seguridad (opcional, 1-2 segundos)
↓
[4] Invocación de gpt-image-2
↓
[5] Degradación automática a un modelo de respaldo al recibir moderation_blocked
↓
Devolver resultado
Mediante estas 5 capas de protección, puedes reducir la tasa de visibilidad para el usuario final de moderation_blocked a menos del 1%.
🎯 Consejo de implementación: Todas las llamadas externas de esta puerta de enlace de seguridad (API de moderación, LLM de texto, múltiples modelos de imagen) pueden realizarse a través del punto de acceso único de APIYI (apiyi.com), lo que permite una facturación unificada y registros centralizados, reduciendo drásticamente la complejidad de la ingeniería.
VII. Preguntas frecuentes (FAQ) sobre moderation_blocked en gpt-image-2
P1: ¿Por qué la misma indicación funciona hoy, pero mañana recibe un error moderation_blocked?
Los clasificadores de seguridad de OpenAI y Azure se actualizan continuamente, especialmente después de eventos políticos importantes (como la exclusión voluntaria de celebridades), lo que provoca endurecimientos masivos. Te recomendamos registrar una instantánea de la indicación que genera el error moderation_blocked en tu sistema de producción para analizarla más adelante.
P2: ¿Puedo usar gpt-image-2-all (versión inversa oficial) para evitar el moderation_blocked?
En algunos casos sí, pero no es una solución mágica. El enlace de la versión inversa también tiene sus propios controles de seguridad, solo que los umbrales y reglas de activación son ligeramente diferentes. Para ciertos tipos de bloqueos (como nombres de celebridades), ambos modelos bloquearán la solicitud. Te recomendamos realizar pruebas A/B entre ambos modelos a través de APIYI apiyi.com para encontrar el camino con mayor tolerancia para tu caso de uso.
P3: ¿El error moderation_blocked genera cargos?
No. El error 400 es un error del cliente; ni OpenAI ni APIYI cobran por las solicitudes bloqueadas. Puedes realizar pruebas de indicación con total tranquilidad.
P4: ¿Por qué la probabilidad de activar moderation_blocked es mayor con indicaciones en chino que en inglés?
No es un problema del idioma chino en sí, sino que las indicaciones en chino pueden introducir palabras de activación en inglés inesperadas al traducirse a la representación interna del modelo. Recomendaciones: (1) Evita nombrar directamente a celebridades o propiedad intelectual (IP) en tus indicaciones en chino. (2) Prueba gpt-image-2-all, ya que tiene una optimización nativa para indicaciones en chino.
P5: ¿Se bloqueará si quiero generar fotos de mis propios empleados para uso interno?
Es muy probable. El sistema de seguridad de OpenAI no puede determinar si "eres realmente ese empleado"; si el sistema identifica un retrato de una persona real, lo bloqueará. Te sugerimos utilizar el endpoint de edición (subir la imagen original + máscara para modificar) o usar "procesamiento artístico estilizado" en lugar de fotos realistas.
P6: ¿Pueden los clientes corporativos solicitar una reducción en el umbral de filtrado?
Con la conexión directa a OpenAI es casi imposible. En el caso de Azure OpenAI, algunos contratos corporativos pueden solicitar ajustes en el nivel de filtro de contenido (sujeto a aprobación). A través del canal de servicios corporativos de APIYI apiyi.com, podemos ayudarte a gestionar el proceso de aprobación de Azure o proporcionarte soluciones multimodelo personalizadas para evitar limitaciones de un solo punto.
P7: ¿Es el filtrado de Nano Banana Pro realmente más permisivo que el de gpt-image-2?
En numerosas pruebas, Nano Banana Pro es efectivamente más tolerante con la expresión artística y las referencias a propiedad intelectual (IP) laxas. Sin embargo, en áreas críticas como contenido relacionado con menores, contenido sexual o violencia extrema, es casi idéntico a OpenAI; ningún modelo convencional puede eludir estas líneas rojas.
P8: ¿Qué significa el ticket de soporte de Azure en el mensaje de error?
Indica que el enlace subyacente pasa por Azure OpenAI. Los diferentes servicios proxy de API se conectan a diferentes backends; algunos se conectan directamente a OpenAI y otros a Azure. La rigurosidad del filtrado varía ligeramente según el backend, lo cual explica por qué la misma indicación tiene un comportamiento distinto según el proveedor.
VIII. Resumen: Estrategias para manejar el error moderation_blocked en gpt-image-2
Volviendo al mensaje de error inicial, ahora tenemos claro que:
- Naturaleza del error:
moderation_blockedno es un problema de capacidad del modelo, sino un bloqueo proactivo del clasificador de seguridad antes de la inferencia del modelo. - El error no es reintentable: Sin cambiar la indicación, el resultado será el mismo tras diez mil intentos.
- 7 escenarios de activación: Celebridades / Artistas vivos / Propiedad intelectual (IP) con derechos de autor / Violencia / Sugerencias sexuales / Realismo infantil / Símbolos de odio.
- 6 estrategias de reescritura: Reemplazo de nombres / Sustituir vivos por fallecidos / Abstracción de personajes / Descripción en dos pasos / Sustituir violencia por emociones / Degradación al endpoint de edición.
- Respaldo multimodelo: Cadena de degradación de gpt-image-2 → gpt-image-2-all → Nano Banana Pro → Nano Banana 2.
- Protección de ingeniería: Puerta de enlace de cuatro capas (pre-verificación + reescritura + degradación + apelación) para reducir la tasa de falsos positivos a < 1%.
Para los equipos que utilizan gpt-image-2 en producción, el principio fundamental es: no luches contra el sistema de seguridad, convierte la ingeniería de indicaciones y el enrutamiento multimodelo en una capacidad sistémica. Un error moderation_blocked suele significar que hay otros 10 errores similares esperando en tu capa de indicación o arquitectura.
Recomendamos utilizar la entrada unificada de APIYI apiyi.com para acceder simultáneamente a múltiples modelos como gpt-image-2, gpt-image-2-all y Nano Banana Pro/2, logrando un enrutamiento de degradación rápido bajo la misma cuenta y base de código. Este es el camino más rápido para transformar un "fallo de interrupción de negocio" por moderation_blocked en una "optimización de experiencia imperceptible".
Sobre el autor: El equipo técnico de APIYI, con amplia experiencia en la implementación empresarial de modelos de generación de imágenes, apelaciones de seguridad de contenido y arquitectura de enrutamiento multimodelo. Visita el sitio web oficial de APIYI apiyi.com para obtener soluciones de acceso a modelos convencionales como gpt-image-2, gpt-image-2-all y Nano Banana Pro, así como soporte técnico empresarial para problemas comunes como moderation_blocked.