¿Te has encontrado con el error thinking_budget and thinking_level are not supported together al llamar a los modelos Gemini 3.0 Pro Preview o gemini-3-flash-preview? Se trata de un problema de compatibilidad causado por la actualización de parámetros entre las distintas versiones de la API de Google Gemini. En este artículo, analizaremos desde la perspectiva de la evolución del diseño de la API la causa raíz de este error y cómo configurarlo correctamente.
Valor principal: Al terminar de leer, dominarás la configuración correcta de los parámetros del modo de pensamiento para los modelos Gemini 2.5 y 3.0, evitando errores comunes en las llamadas a la API y optimizando tanto el rendimiento de inferencia como el control de costes.
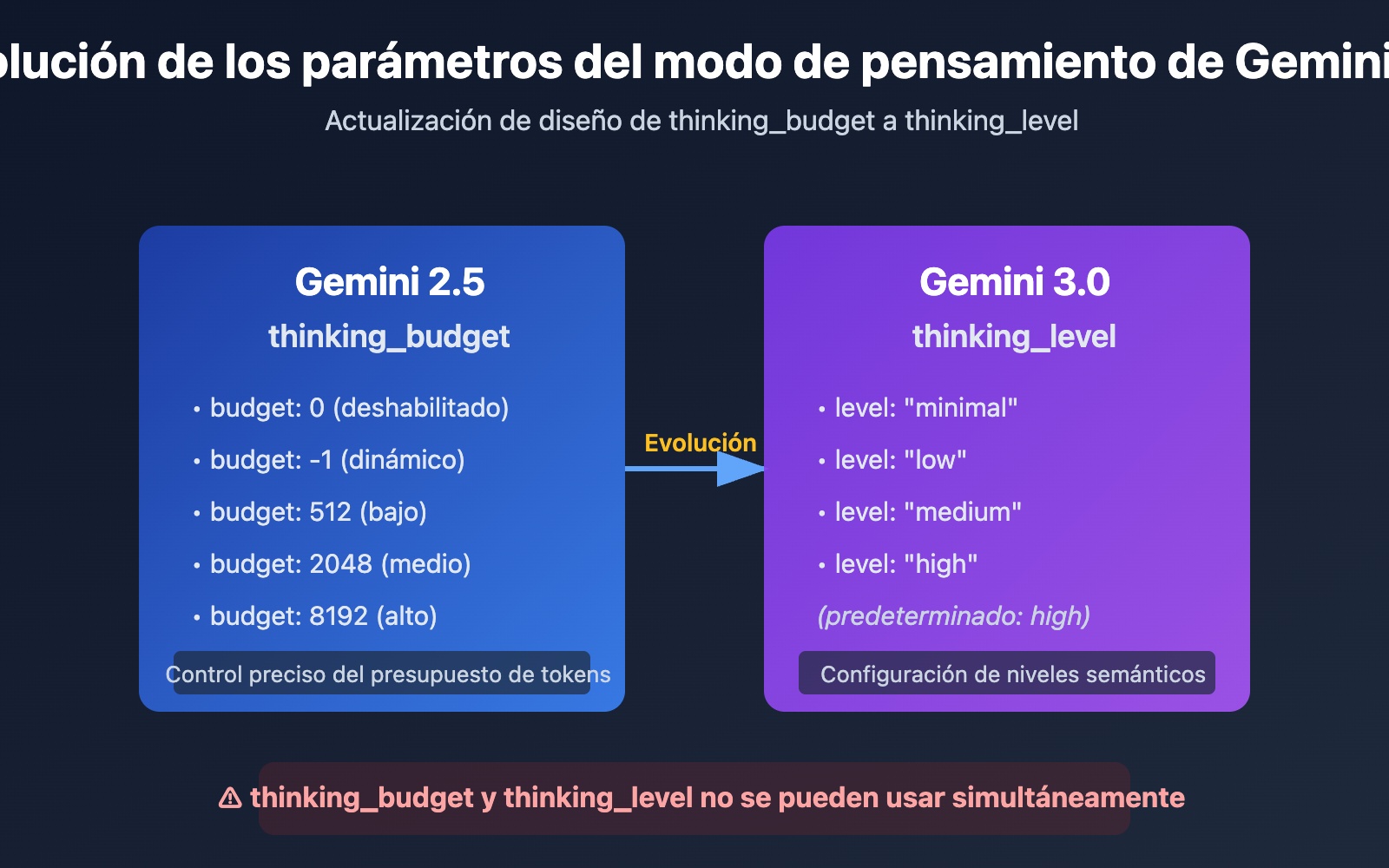
Puntos clave de la evolución de los parámetros del modo de pensamiento de Gemini API
| Versión del modelo | Parámetro recomendado | Tipo de parámetro | Ejemplo de configuración | Escenario de uso |
|---|---|---|---|---|
| Gemini 2.5 Flash/Flash-Lite | thinking_budget |
Entero o -1 | thinking_budget: 0 (deshabilitado)thinking_budget: -1 (dinámico) |
Control preciso del presupuesto de tokens de pensamiento |
| Gemini 3.0 Pro/Flash | thinking_level |
Valor enumerado | thinking_level: "minimal"/"low"/"medium"/"high" |
Configuración simplificada por niveles según escenario |
| Nota de compatibilidad | ⚠️ No se pueden usar simultáneamente | – | Enviar ambos parámetros activará un error 400 | Elegir uno según la versión del modelo |
Diferencias clave en los parámetros del modo de pensamiento de Gemini
La razón principal por la que Google introdujo el parámetro thinking_level en Gemini 3.0 es para simplificar la experiencia de configuración para los desarrolladores. Mientras que thinking_budget en Gemini 2.5 requiere que el desarrollador estime con precisión la cantidad de tokens de pensamiento, thinking_level en Gemini 3.0 abstrae esa complejidad en 4 niveles semánticos, reduciendo la barrera de entrada para la configuración.
Este cambio de diseño refleja el equilibrio que Google busca en la evolución de su API: sacrificar parte de la capacidad de control minucioso a cambio de una mejor facilidad de uso y consistencia entre modelos. Para la mayoría de los escenarios de aplicación, la abstracción de thinking_level es suficiente; solo en casos que requieran una optimización de costes extrema o un control específico del presupuesto de tokens será necesario recurrir a thinking_budget.
💡 Consejo técnico: En el desarrollo real, recomendamos realizar pruebas de llamadas a la interfaz a través de la plataforma APIYI (apiyi.com). Esta plataforma ofrece una interfaz de API unificada compatible con modelos como Gemini 2.5 Flash, Gemini 3.0 Pro y Gemini 3.0 Flash, lo que facilita la validación rápida del efecto real y las diferencias de costes de las distintas configuraciones del modo de pensamiento.
Causa raíz del error: Estrategia de compatibilidad hacia adelante en el diseño de parámetros
Análisis del mensaje de error de la API
{
"status_code": 400,
"error": {
"message": "Unable to submit request because thinking_budget and thinking_level are not supported together.",
"type": "upstream_error",
"code": 400
}
}
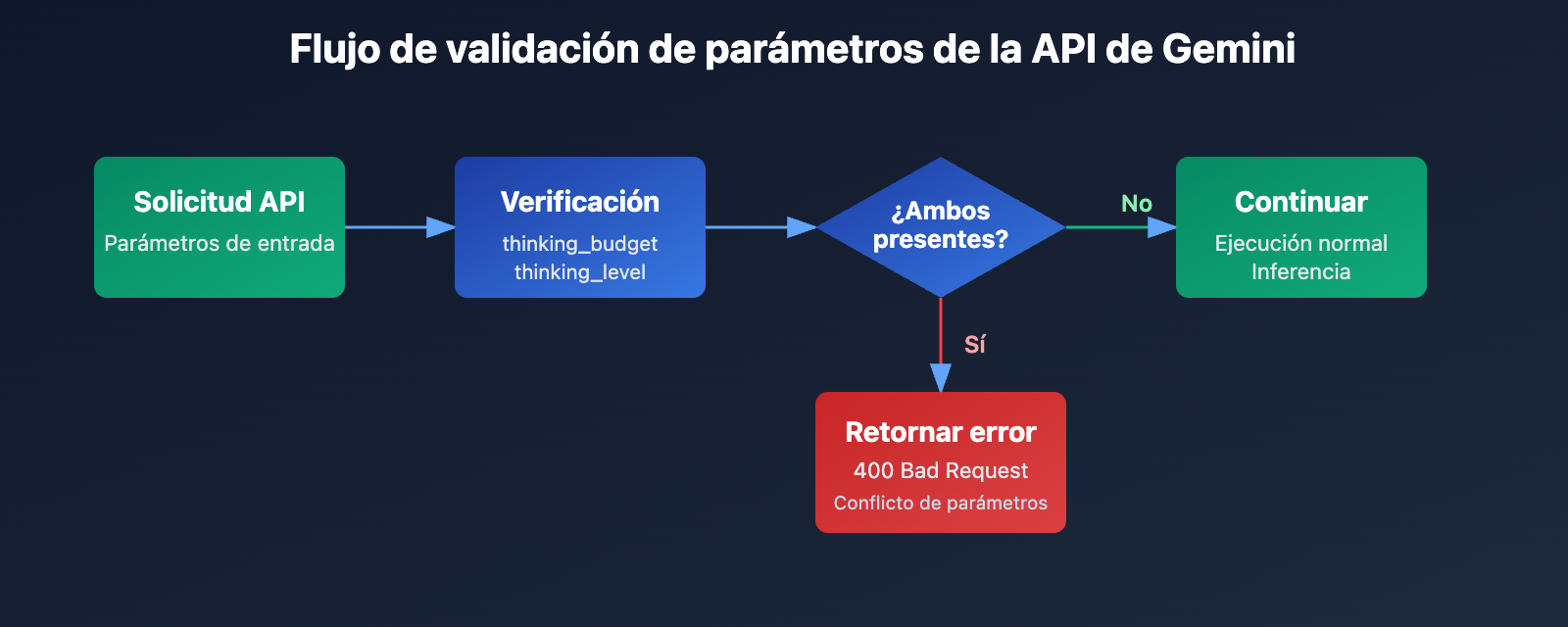
El mensaje central de este error es que thinking_budget y thinking_level no pueden coexistir. Al introducir nuevos parámetros en Gemini 3.0, Google no eliminó por completo los antiguos, sino que implementó una estrategia de exclusión mutua:
- Modelos Gemini 2.5: Solo aceptan
thinking_budgete ignoranthinking_level. - Modelos Gemini 3.0: Priorizan el uso de
thinking_level. Aunque aceptanthinking_budgetpara mantener la compatibilidad hacia atrás, no permiten que ambos se envíen al mismo tiempo. - Condición que dispara el error: La solicitud de la API incluye simultáneamente los parámetros
thinking_budgetythinking_level.
¿Por qué ocurre este error?
Los desarrolladores suelen encontrarse con este error en uno de estos tres escenarios:
| Escenario | Causa | Característica típica del código |
|---|---|---|
| Escenario 1: Autocompletado del SDK | Algunos frameworks de IA (como LiteLLM o AG2) rellenan parámetros automáticamente según el nombre del modelo, lo que provoca el envío de ambos parámetros. | Uso de SDKs empaquetados sin verificar el cuerpo real de la solicitud. |
| Escenario 2: Configuración fija (Hardcoded) | El código tiene thinking_budget grabado a fuego y no se actualizó el nombre del parámetro al cambiar a un Modelo de Lenguaje Grande como Gemini 3.0. |
Asignación simultánea de ambos parámetros en archivos de configuración o en el código. |
| Escenario 3: Error de juicio en el alias del modelo | Uso de alias como gemini-flash-preview que apuntan a Gemini 3.0, pero configurados con los parámetros de la versión 2.5. |
El nombre del modelo incluye preview o latest, pero la configuración de parámetros no se ha sincronizado. |
🎯 Recomendación: Al cambiar entre versiones de modelos Gemini, te sugerimos probar la compatibilidad de los parámetros primero a través de la plataforma APIYI (apiyi.com). Esta herramienta permite alternar rápidamente entre los modelos de las series Gemini 2.5 y 3.0, facilitando la comparación de la calidad de respuesta y la latencia según la configuración del modo de pensamiento, evitando así conflictos de parámetros en producción.
3 soluciones: Elegir el parámetro correcto según la versión del modelo
Solución 1: Configuración para modelos Gemini 2.5 (usando thinking_budget)
Modelos aplicables: gemini-2.5-flash, gemini-2.5-pro, etc.
Descripción de parámetros:
thinking_budget: 0: Desactiva por completo el modo de pensamiento, logrando la menor latencia y costo.thinking_budget: -1: Modo de pensamiento dinámico; el modelo se ajusta automáticamente según la complejidad de la solicitud.thinking_budget: <entero positivo>: Especifica con precisión el límite máximo de tokens de pensamiento.
Ejemplo minimalista
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-2.5-flash-preview-04-17",
messages=[{"role": "user", "content": "解释量子纠缠的原理"}],
extra_body={
"thinking_budget": -1 # 动态思考模式
}
)
print(response.choices[0].message.content)
Ver código completo (incluyendo extracción de contenido de pensamiento)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-2.5-flash-preview-04-17",
messages=[{"role": "user", "content": "解释量子纠缠的原理"}],
extra_body={
"thinking_budget": -1, # 动态思考模式
"include_thoughts": True # 启用思考摘要返回
}
)
# 提取思考内容 (如果启用)
for part in response.choices[0].message.content:
if hasattr(part, 'thought') and part.thought:
print(f"思考过程: {part.text}")
# 提取最终回答
final_answer = response.choices[0].message.content
print(f"最终回答: {final_answer}")
Nota: Los modelos Gemini 2.5 se retirarán el 3 de marzo de 2026. Se recomienda migrar a la serie Gemini 3.0 lo antes posible. Puedes usar la plataforma APIYI (apiyi.com) para comparar rápidamente la calidad de las respuestas antes y después de la migración.
Solución 2: Configuración para modelos Gemini 3.0 (usando thinking_level)
Modelos aplicables: gemini-3.0-flash-preview, gemini-3.0-pro-preview
Descripción de parámetros:
thinking_level: "minimal": Pensamiento mínimo, cercano a presupuesto cero. Requiere enviar firmas de pensamiento (Thought Signatures).thinking_level: "low": Pensamiento de baja intensidad, ideal para seguimiento de instrucciones simples y chats.thinking_level: "medium": Pensamiento de intensidad media, adecuado para tareas de razonamiento general (solo soportado por Gemini 3.0 Flash).thinking_level: "high": Pensamiento de alta intensidad, maximiza la profundidad del razonamiento para problemas complejos (valor predeterminado).
Ejemplo minimalista
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.0-flash-preview",
messages=[{"role": "user", "content": "分析这段代码的时间复杂度"}],
extra_body={
"thinking_level": "medium" # 中等强度思考
}
)
print(response.choices[0].message.content)
Ver código completo (incluyendo el envío de firmas de pensamiento)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# 第一轮对话
response_1 = client.chat.completions.create(
model="gemini-3.0-flash-preview",
messages=[{"role": "user", "content": "设计一个 LRU 缓存算法"}],
extra_body={
"thinking_level": "high",
"include_thoughts": True
}
)
# 提取思考签名 (Gemini 3.0 自动返回)
thought_signatures = []
for part in response_1.choices[0].message.content:
if hasattr(part, 'thought_signature'):
thought_signatures.append(part.thought_signature)
# 第二轮对话,传递思考签名以保持推理链
response_2 = client.chat.completions.create(
model="gemini-3.0-flash-preview",
messages=[
{"role": "user", "content": "设计一个 LRU 缓存算法"},
{"role": "assistant", "content": response_1.choices[0].message.content, "thought_signatures": thought_signatures},
{"role": "user", "content": "优化这个算法的空间复杂度"}
],
extra_body={
"thinking_level": "high"
}
)
print(response_2.choices[0].message.content)
💰 Optimización de costos: Para proyectos con presupuesto ajustado, considera llamar a la API de Gemini 3.0 Flash a través de APIYI (apiyi.com). Esta plataforma ofrece métodos de facturación flexibles y precios más competitivos, ideales para equipos pequeños y desarrolladores individuales. Combinarlo con
thinking_level: "low"puede reducir aún más los costos.
Solución 3: Estrategia de adaptación de parámetros para cambio dinámico de modelos
Escenario aplicable: Cuando el código necesita soportar simultáneamente modelos Gemini 2.5 y 3.0.
Función inteligente de adaptación de parámetros
def get_thinking_config(model_name: str, complexity: str = "medium") -> dict:
"""
Selecciona automáticamente el parámetro del modo de pensamiento según la versión del modelo.
Args:
model_name: Nombre del modelo Gemini
complexity: Complejidad del pensamiento ("minimal", "low", "medium", "high", "dynamic")
Returns:
Diccionario de parámetros para extra_body
"""
# Lista de modelos Gemini 3.0
gemini_3_models = [
"gemini-3.0-flash-preview",
"gemini-3.0-pro-preview",
"gemini-3-flash",
"gemini-3-pro"
]
# Lista de modelos Gemini 2.5
gemini_2_5_models = [
"gemini-2.5-flash-preview-04-17",
"gemini-2.5-flash-lite",
"gemini-2-flash",
"gemini-2-flash-lite"
]
# Determinar versión del modelo
if any(m in model_name for m in gemini_3_models):
# Gemini 3.0 usa thinking_level
level_map = {
"minimal": "minimal",
"low": "low",
"medium": "medium",
"high": "high",
"dynamic": "high" # Por defecto alta intensidad
}
return {"thinking_level": level_map.get(complexity, "medium")}
elif any(m in model_name for m in gemini_2_5_models):
# Gemini 2.5 usa thinking_budget
budget_map = {
"minimal": 0,
"low": 512,
"medium": 2048,
"high": 8192,
"dynamic": -1
}
return {"thinking_budget": budget_map.get(complexity, -1)}
else:
# Modelo desconocido, usar parámetros de Gemini 3.0 por defecto
return {"thinking_level": "medium"}
# Ejemplo de uso
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
model = "gemini-3.0-flash-preview" # Puede cambiarse dinámicamente
thinking_config = get_thinking_config(model, complexity="high")
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "你的问题"}],
extra_body=thinking_config
)

| Complejidad del pensamiento | Gemini 2.5 (thinking_budget) | Gemini 3.0 (thinking_level) | Escenario recomendado |
|---|---|---|---|
| Mínima | 0 |
"minimal" |
Seguimiento de instrucciones simples, alta demanda. |
| Baja | 512 |
"low" |
Chatbots, preguntas y respuestas ligeras. |
| Media | 2048 |
"medium" |
Tareas de razonamiento general, generación de código. |
| Alta | 8192 |
"high" |
Resolución de problemas complejos, análisis profundo. |
| Dinámica | -1 |
"high" (por defecto) |
Adaptación automática a la complejidad. |
🚀 Comienza rápido: Recomendamos usar la plataforma APIYI (apiyi.com) para crear prototipos rápidamente. Ofrece una interfaz lista para usar con la API de Gemini, sin configuraciones complejas; puedes integrar todo en 5 minutos y alternar parámetros de pensamiento con un clic para comparar resultados.
Detalles del mecanismo de Firmas de Pensamiento (Thought Signatures) en Gemini 3.0
¿Qué son las Firmas de Pensamiento?
Las Firmas de Pensamiento (Thought Signatures) introducidas en Gemini 3.0 son representaciones cifradas del proceso de razonamiento interno del modelo. Cuando activas include_thoughts: true, el modelo devuelve una firma cifrada del proceso de pensamiento en su respuesta. Puedes pasar estas firmas en las conversaciones subsiguientes para que el modelo mantenga la coherencia en su cadena de razonamiento.
Características principales:
- Representación cifrada: El contenido de la firma no es legible, solo el modelo puede interpretarlo.
- Mantenimiento de la cadena de razonamiento: Al pasar la firma en diálogos de varias rondas, el modelo puede continuar razonando basándose en sus pensamientos previos.
- Retorno forzado: Gemini 3.0 devuelve las firmas de pensamiento por defecto, incluso si no se solicitan.
Escenarios de aplicación real de las Firmas de Pensamiento
| Escenario | ¿Es necesario pasar la firma? | Descripción |
|---|---|---|
| Consulta de una sola ronda | ❌ No es necesario | Pregunta independiente, no requiere mantener una cadena de razonamiento. |
| Diálogo multirronda (Simple) | ❌ No es necesario | El contexto es suficiente, no hay dependencias de razonamiento complejo. |
| Diálogo multirronda (Razonamiento complejo) | ✅ Necesario | Por ejemplo: refactorización de código, demostraciones matemáticas, análisis de múltiples pasos. |
| Modo de pensamiento mínimo (minimal) | ✅ Obligatorio | El nivel thinking_level: "minimal" requiere pasar la firma; de lo contrario, devuelve un error 400. |
Código de ejemplo para pasar Firmas de Pensamiento
import openai
client = openai.OpenAI(
api_key="TU_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Primera ronda: pedir al modelo que diseñe un algoritmo
response_1 = client.chat.completions.create(
model="gemini-3.0-pro-preview",
messages=[{"role": "user", "content": "Diseña un algoritmo de limitación de tasa distribuido"}],
extra_body={
"thinking_level": "high",
"include_thoughts": True
}
)
# Extraer las firmas de pensamiento
signatures = []
for part in response_1.choices[0].message.content:
if hasattr(part, 'thought_signature'):
signatures.append(part.thought_signature)
# Segunda ronda: optimizar basándose en el razonamiento previo
response_2 = client.chat.completions.create(
model="gemini-3.0-pro-preview",
messages=[
{"role": "user", "content": "Diseña un algoritmo de limitación de tasa distribuido"},
{
"role": "assistant",
"content": response_1.choices[0].message.content,
"thought_signatures": signatures # Pasar las firmas de pensamiento
},
{"role": "user", "content": "¿Cómo manejarías el problema de la inconsistencia del reloj distribuido?"}
],
extra_body={"thinking_level": "high"}
)
💡 Mejor práctica: En escenarios que requieren razonamiento complejo de varias rondas (como diseño de sistemas, optimización de algoritmos o revisión de código), te sugiero probar la diferencia de rendimiento al pasar las firmas a través de la plataforma APIYI (apiyi.com). Esta plataforma soporta el mecanismo completo de firmas de pensamiento de Gemini 3.0, lo que facilita validar la calidad del razonamiento bajo diferentes configuraciones.
Preguntas frecuentes (FAQ)
Q1: ¿Por qué Gemini 2.5 Flash sigue devolviendo contenido de pensamiento tras configurar thinking_budget=0?
Este es un error (bug) conocido en la versión Gemini 2.5 Flash Preview 04-17, donde thinking_budget=0 no se ejecuta correctamente. Los foros oficiales de Google ya han confirmado este problema.
Soluciones temporales:
- Usa
thinking_budget=1(un valor mínimo) en lugar de 0. - Actualiza a Gemini 3.0 Flash y usa
thinking_level="minimal". - Filtra el contenido del pensamiento en el post-procesamiento (si la API devuelve el campo
thought).
Te recomendamos cambiar rápidamente al modelo Gemini 3.0 Flash a través de APIYI (apiyi.com), ya que la plataforma soporta las versiones más recientes y permite evitar este tipo de errores.
Q2: ¿Cómo puedo saber si estoy usando el modelo Gemini 2.5 o el 3.0?
Método 1: Revisar el nombre del modelo
- Gemini 2.x: El nombre incluye
2.5-flash,2-flash-lite. - Gemini 3.x: El nombre incluye
3.0-flash,3-pro,gemini-3-flash.
Método 2: Enviar una solicitud de prueba
# Pasa solo thinking_level y observa la respuesta
response = client.chat.completions.create(
model="nombre-de-tu-modelo",
messages=[{"role": "user", "content": "test"}],
extra_body={"thinking_level": "low"}
)
# Si devuelve un error 400 indicando que no soporta thinking_level, es Gemini 2.5
Método 3: Ver los encabezados (headers) de la respuesta de la API
Algunas implementaciones de API devuelven el campo X-Model-Version en los encabezados, lo que permite identificar directamente la versión del modelo.
Q3: ¿Cuántos tokens consume exactamente cada nivel de thinking_level en Gemini 3.0?
Google no ha hecho público el presupuesto exacto de tokens para cada thinking_level, solo ha proporcionado la siguiente guía orientativa:
| thinking_level | Costo relativo | Latencia relativa | Profundidad de razonamiento |
|---|---|---|---|
| minimal | El más bajo | La más baja | Casi sin pensamiento |
| low | Bajo | Baja | Razonamiento superficial |
| medium | Medio | Media | Razonamiento intermedio |
| high | Alto | Alta | Razonamiento profundo |
Sugerencias basadas en pruebas:
- Compara el consumo real de tokens de los diferentes niveles en la plataforma APIYI (apiyi.com).
- Usa la misma indicación y llama a low/medium/high por separado para observar la diferencia en la facturación.
- Elige el nivel adecuado según tu escenario de negocio (Calidad de respuesta vs. Costo).
Q4: ¿Se puede forzar el uso de thinking_budget en Gemini 3.0?
Sí, se puede, pero no es recomendable.
Para mantener la compatibilidad hacia atrás, Gemini 3.0 sigue aceptando el parámetro thinking_budget, pero la documentación oficial indica claramente:
"Aunque se acepta
thinking_budgetpor compatibilidad, usarlo con Gemini 3 Pro puede resultar en un rendimiento subóptimo."
Razones:
- El mecanismo de razonamiento interno de Gemini 3.0 ya ha sido optimizado para
thinking_level. - Forzar
thinking_budgetpodría omitir las estrategias de razonamiento de la nueva versión. - Podría causar una disminución en la calidad de la respuesta o un aumento en la latencia.
Lo correcto es:
- Migrar al parámetro
thinking_level. - Consultar la función de adaptación de parámetros mencionada anteriormente para seleccionar dinámicamente el parámetro correcto.
Resumen
Puntos clave sobre los errores de thinking_budget y thinking_level en la API de Gemini:
- Parámetros mutuamente excluyentes: Gemini 2.5 utiliza
thinking_budget, mientras que Gemini 3.0 utilizathinking_level. No se pueden enviar ambos de forma simultánea. - Identificación del modelo: Determina la versión a través del nombre del modelo; la serie 2.5 usa
thinking_budgety la serie 3.0 usathinking_level. - Adaptación dinámica: Emplea una función de adaptación de parámetros que seleccione automáticamente el parámetro correcto según el nombre del modelo, evitando así el código estático o "hard-coded".
- Firma de pensamiento: Gemini 3.0 introduce un mecanismo de firma de pensamiento. En escenarios de razonamiento complejo con múltiples turnos, es necesario pasar la firma para mantener la cadena de razonamiento.
- Sugerencia de migración: Gemini 2.5 se retirará el 3 de marzo de 2026. Se recomienda migrar a la serie 3.0 lo antes posible.
Te recomendamos usar APIYI (apiyi.com) para validar rápidamente el efecto real de las diferentes configuraciones del modo de pensamiento. Esta plataforma es compatible con toda la serie de modelos Gemini, ofrece una interfaz unificada y métodos de facturación flexibles, lo que la hace ideal para pruebas comparativas rápidas y despliegues en entornos de producción.
Autor: Equipo técnico de APIYI | Si tienes dudas técnicas, te invitamos a visitar APIYI (apiyi.com) para obtener más soluciones de integración de modelos de IA.