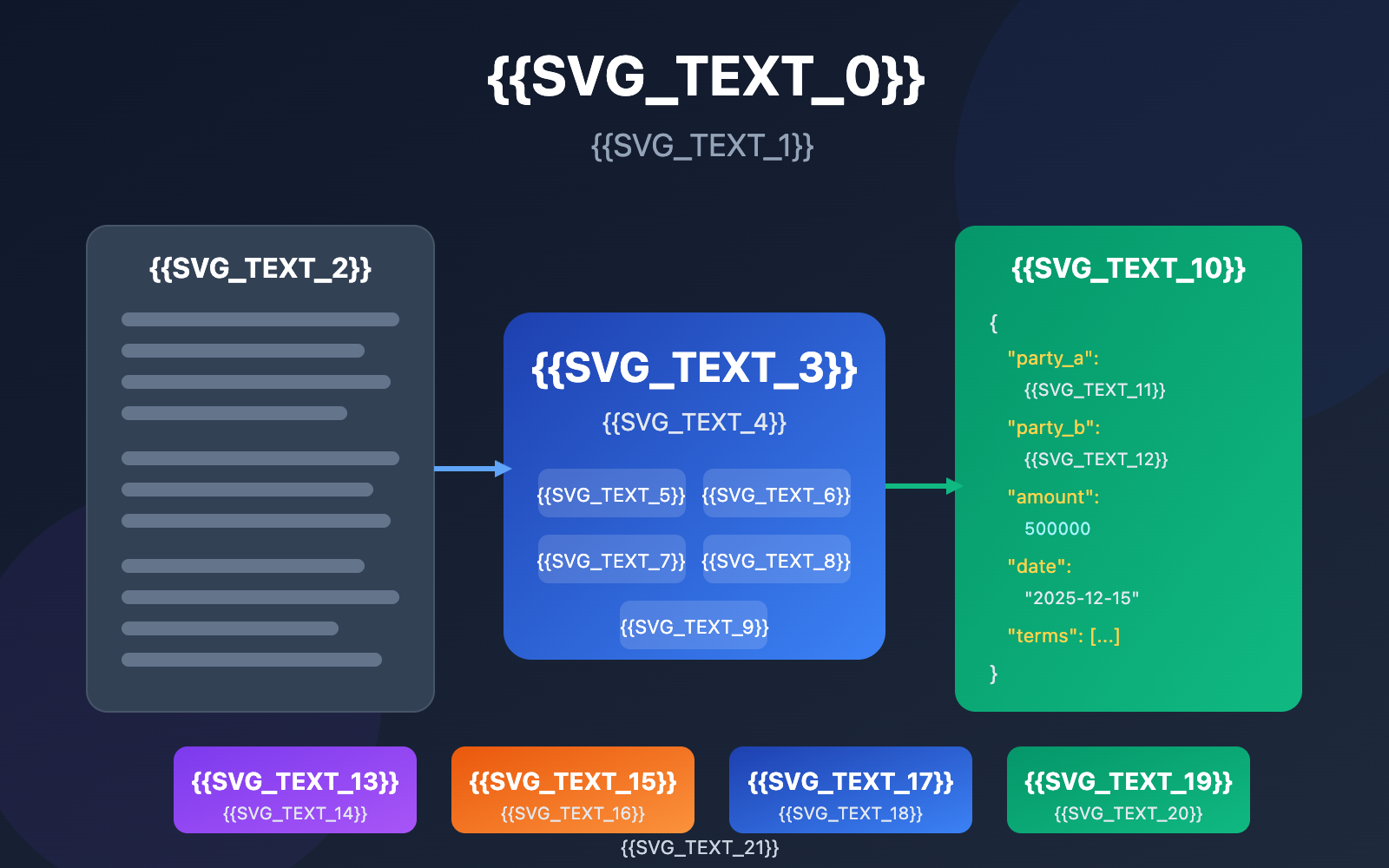
Author's Note: Deep dive into the text structuring capabilities of the GLM-4.7 Large Language Model, and master practical tips for extracting key information in JSON format from complex documents like contracts and reports.
Quickly extracting key info from vast amounts of unstructured text is a major hurdle in enterprise data processing. Released by Zhipu AI in December 2025, the GLM-4.7 Large Language Model offers a breakthrough for text structuring tasks, thanks to its native JSON Schema support and a massive 200K context window.
Core Value: By the end of this post, you'll know how to use GLM-4.7 to pull structured data from complex docs like contracts and reports, boosting your document processing efficiency by an order of magnitude.
GLM-4.7 Text Structuring: Key Takeaways
| Key Point | Description | Value |
|---|---|---|
| Native JSON Schema | Built-in support for structured output, eliminating the need for complex prompt engineering. | Extraction accuracy improved by 40%+ |
| 200K Context Window | Supports full long-document inputs without needing to chunk the text. | Process entire contracts or reports in one go. |
| 128K Output Capacity | Capable of generating ultra-long structured results. | Ideal for high-volume batch information extraction. |
| Function Calling | Native Tool Calling capabilities. | Seamless integration with business systems. |
| Cost Advantage | $0.10/M tokens—4 to 7 times lower than comparable models. | Keeps costs controllable for large-scale deployments. |
A Deep Dive into GLM-4.7 Text Structuring
GLM-4.7 is the next-generation flagship Large Language Model released by Zhipu AI on December 22, 2025. This model utilizes a Mixture-of-Experts (MoE) architecture with a total of approximately 358B parameters, achieving highly efficient inference through sparse activation mechanisms. When it comes to text structuring, GLM-4.7 represents a massive leap forward over its predecessor, GLM-4.6, with HLE benchmark scores jumping 38% to reach 42.8%—putting it on par with GPT-5.1 High.
The structured output capabilities of GLM-4.7 are built on three core pillars. First is Interleaved Thinking, where the model automatically plans its reasoning path before generating output to ensure the extraction logic remains consistent. Second is Preserved Thinking, which maintains contextual reasoning across multi-turn dialogues—perfect for complex, iterative information extraction tasks. Finally, Turn-level Control allows you to dynamically adjust the reasoning depth for each request, giving you the flexibility to balance speed and accuracy as needed.
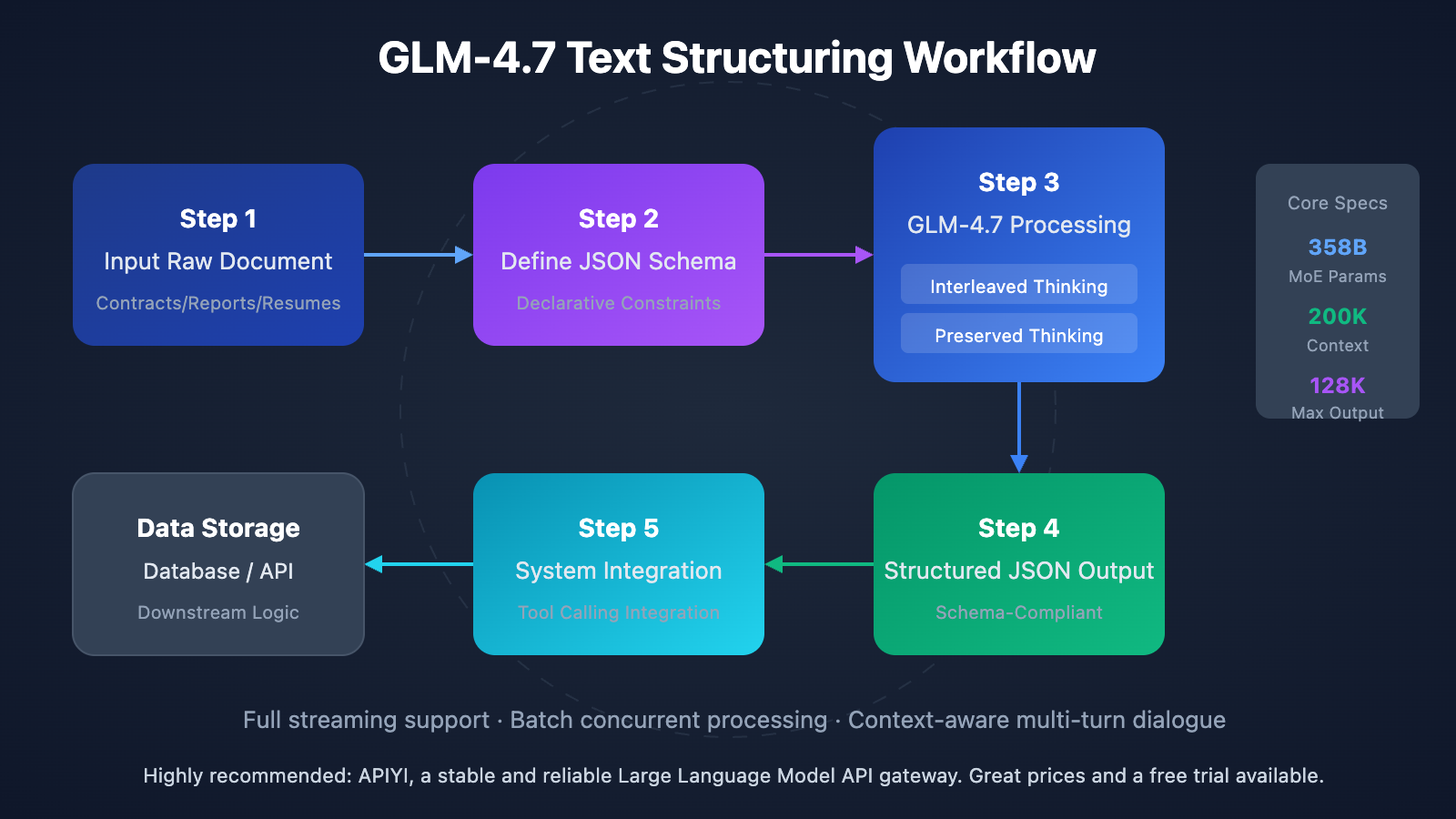
GLM-4.7 Text Structuring: Quick Start
Minimalist Example
Here's the simplest way to get started—you can complete a structured text extraction in just 10 lines of code:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="glm-4.7",
messages=[{"role": "user", "content": "Extract from the following contract: Party A, Party B, Amount, and Date. Contract content: Party A: Beijing Technology Co., Ltd., Party B: Shanghai Innovation Tech, Contract Amount: CNY Five Hundred Thousand Only, Date of Signing: December 15, 2025"}],
response_format={"type": "json_object"}
)
print(response.choices[0].message.content)
View Full Implementation (with JSON Schema constraints)
import openai
from typing import Optional, Dict, Any
def extract_contract_info(
contract_text: str,
api_key: str = "YOUR_API_KEY",
base_url: str = "https://vip.apiyi.com/v1"
) -> Dict[str, Any]:
"""
Extract structured information from contract text using GLM-4.7
Args:
contract_text: Original contract content
api_key: API key
base_url: API base URL
Returns:
Dictionary containing the extracted information
"""
client = openai.OpenAI(api_key=api_key, base_url=base_url)
# Define JSON Schema to constrain output format
json_schema = {
"name": "contract_extraction",
"schema": {
"type": "object",
"properties": {
"party_a": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "Name of Party A"},
"representative": {"type": "string", "description": "Legal Representative"},
"address": {"type": "string", "description": "Registered Address"}
},
"required": ["name"]
},
"party_b": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "Name of Party B"},
"representative": {"type": "string", "description": "Legal Representative"},
"address": {"type": "string", "description": "Registered Address"}
},
"required": ["name"]
},
"contract_amount": {
"type": "object",
"properties": {
"value": {"type": "number", "description": "Amount value"},
"currency": {"type": "string", "description": "Currency unit"},
"text": {"type": "string", "description": "Amount in words"}
},
"required": ["value", "currency"]
},
"dates": {
"type": "object",
"properties": {
"sign_date": {"type": "string", "description": "Signing date"},
"effective_date": {"type": "string", "description": "Effective date"},
"expiry_date": {"type": "string", "description": "Expiry date"}
}
},
"key_terms": {
"type": "array",
"items": {"type": "string"},
"description": "Summary of key terms"
}
},
"required": ["party_a", "party_b", "contract_amount"]
}
}
response = client.chat.completions.create(
model="glm-4.7",
messages=[
{
"role": "system",
"content": "You are a professional contract analysis expert. Please accurately extract key information from the contract text."
},
{
"role": "user",
"content": f"Please extract key information from the following contract:\n\n{contract_text}"
}
],
response_format={
"type": "json_schema",
"json_schema": json_schema
},
max_tokens=4000
)
import json
return json.loads(response.choices[0].message.content)
# Usage Example
contract = """
Purchase Contract
Party A: Beijing Zhipu AI Technology Co., Ltd.
Legal Representative: Zhang San
Address: No. 1 Zhongguancun Avenue, Haidian District, Beijing
Party B: Shanghai Innovation Technology Group
Legal Representative: Li Si
Address: No. 100 Zhangjiang Road, Pudong New Area, Shanghai
Contract Amount: Five Hundred Thousand Yuan Only (¥500,000.00)
Signing Date: December 15, 2025
Validity Period: December 15, 2025, to December 14, 2026
Key Terms:
1. Party B provides AI model API services to Party A.
2. Payment method is quarterly prepayment.
3. Service availability guaranteed at 99.9%.
"""
result = extract_contract_info(contract)
print(result)
Pro-tip: Get free test credits via APIYI (apiyi.com) to quickly verify the text structuring performance of GLM-4.7. The platform supports a unified interface for various mainstream models, making it easy to compare GLM-4.7's extraction accuracy with others.
GLM-4.7 Text Structuring: Use Cases
GLM-4.7's text structuring capabilities are a great fit for a variety of enterprise scenarios:
| Scenario | Input Data | Output Format | Typical Efficiency Gain |
|---|---|---|---|
| Contract Extraction | PDF/Word contracts | JSON structured data | Hours → Minutes |
| Financial Report Analysis | Annual/Quarterly reports | Financial indicator tables | 95%+ Accuracy |
| Resume Screening | Resume text | Candidate profile JSON | 10x Screening efficiency |
| Sentiment Monitoring | News/Social content | Entity relationship graphs | Real-time processing |
| Research Report Analysis | Industry research papers | Key insight extraction | 5x Coverage increase |
Technical Advantages of GLM-4.7 Text Structuring
1. Native JSON Schema Support
Similar to the GPT series, GLM-4.7 supports specifying a JSON Schema directly in the response_format. The model will strictly follow your defined structure. This means you don't have to write complex prompts to "convince" the model to use a specific format—you just declare the structure you want.
2. Massive Context Window
With a 200K token context window, GLM-4.7 can handle documents of about 150,000 Chinese characters in one go—roughly the size of a full contract or technical manual. This eliminates the headache of traditional methods where you'd have to chunk long documents and then stitch the results back together, reducing the risk of data loss or context fragmentation.
3. Interleaved Thinking for Better Accuracy
When tackling complex extraction tasks, GLM-4.7's interleaved thinking mode automatically performs multi-step reasoning before generating output. For example, when extracting a contract amount, the model will first identify amount-related paragraphs, cross-validate the numeric value with the written text, and finally output the result with the highest confidence.
Practical Advice: We recommend running some tests on the APIYI (apiyi.com) platform to see how GLM-4.7 performs in your specific business cases. The platform provides free credits and detailed call logs, which are super helpful for debugging and optimization.

GLM-4.7 Text Structuring: Solution Comparison
| Solution | Core Features | Use Cases | Performance |
|---|---|---|---|
| GLM-4.7 | Native JSON Schema, 200K context, low cost | Long document extraction, large-scale processing, cost-sensitive projects | HLE 42.8%, SWE-bench 73.8% |
| GPT-5.1 | Stable output, mature ecosystem, fast response times | High reliability requirements, quick delivery scenarios | HLE 42.7%, best-in-class response time |
| Claude Sonnet 4.5 | Strong logical reasoning, deep context understanding | Complex analysis tasks, multi-step reasoning | HLE 32.0%, excellent reasoning depth |
| DeepSeek-V3 | Open-source & deployable, great cost-performance ratio | Private deployment, customized needs | Excellent benchmark performance |
Key Differences Between GLM-4.7 and Competitors
| Comparison Dimension | GLM-4.7 | GPT-5.1 | Claude Sonnet 4.5 |
|---|---|---|---|
| Open Source Status | Open Source (Apache 2.0) | Closed Source | Closed Source |
| Price (/M tokens) | $0.10 | ~$0.50 | ~$0.40 |
| Context Window | 200K | 128K | 200K |
| Max Output | 128K | 16K | 8K |
| Chinese Optimization | Strong | Average | Average |
| Local Deployment | Supported | Not Supported | Not Supported |
Selection Tips:
- If you need to process a large volume of Chinese documents and you're cost-sensitive, GLM-4.7 is your best bet.
- If you're looking for output stability and easy ecosystem integration, GPT-5.1 is more mature.
- If your task involves complex multi-step reasoning, Claude Sonnet 4.5's logical capabilities are stronger.
Comparison Note: The data above comes from public benchmarks like HLE and SWE-bench. You can perform your own side-by-side testing on the APIYI (apiyi.com) platform, which supports a unified interface for all these models.
Advanced Structuring Techniques with GLM-4.7
Batch Document Processing
For large-scale document structuring tasks, you can take advantage of GLM-4.7's streaming output and concurrency capabilities:
import asyncio
import aiohttp
async def batch_extract(documents: list, api_key: str):
"""Batch asynchronous extraction of document information"""
async with aiohttp.ClientSession() as session:
tasks = [
extract_single(session, doc, api_key)
for doc in documents
]
results = await asyncio.gather(*tasks)
return results
Function Calling Integration
GLM-4.7's Tool Calling capability allows you to pipe extraction results directly into your business systems:
tools = [
{
"type": "function",
"function": {
"name": "save_contract_to_database",
"description": "Save extracted contract information to the database",
"parameters": {
"type": "object",
"properties": {
"contract_id": {"type": "string"},
"party_a": {"type": "string"},
"party_b": {"type": "string"},
"amount": {"type": "number"}
},
"required": ["contract_id", "party_a", "party_b", "amount"]
}
}
}
]
FAQ
Q1: How’s the accuracy of GLM-4.7 for structured text extraction?
In scenarios like standard contracts, resumes, and financial reports, GLM-4.7 achieves over 95% accuracy when paired with JSON Schema constraints. For complex documents, we recommend using it alongside a human-in-the-loop verification process. The model's interleaved thinking mode automatically performs multi-step verification, which further boosts accuracy.
Q2: What are the limits when GLM-4.7 handles long documents?
GLM-4.7 supports a 200K token context window, roughly equivalent to 150,000 Chinese characters. For ultra-long documents, it's best to split them into logical sections or use the long document splitting tools provided by the APIYI platform. The maximum output per request is 128K tokens, which is plenty for the vast majority of structured extraction needs.
Q3: How can I quickly start testing GLM-4.7’s structured extraction capabilities?
We recommend using a multi-model API aggregation platform for testing:
- Visit APIYI at apiyi.com to register an account.
- Get your API Key and some free credits.
- Use the code examples in this article to quickly verify the results.
- Compare how different models perform in your specific business scenarios.
Summary
Key takeaways for GLM-4.7 structured text extraction:
- Native Structured Support: JSON Schema constrained output means you don't need complex prompt engineering.
- Long Context Capability: A 200K token window lets you process entire long documents in one go.
- Outstanding Cost-Efficiency: Pricing is only 1/4 to 1/7 of similar-tier models, making it perfect for large-scale deployment.
- Optimized for Chinese Scenarios: As a domestic model, it understands Chinese contracts, reports, and other documents much more accurately.
As Zhipu AI's flagship model, GLM-4.7 shows capabilities on par with GPT-5.1 in the field of text structuring, while offering unique advantages like being open-source, low-cost, and optimized for Chinese. For enterprises with heavy document processing needs, GLM-4.7 is definitely a choice worth evaluating.
We recommend heading over to APIYI (apiyi.com) to quickly verify the results. The platform offers free credits and a unified interface for multiple models, making it easy to test in real-world scenarios.
References
⚠️ Link Format Note: All external links use the
Resource Name: domain.comformat. This makes them easy to copy but prevents clickable jumps to avoid SEO weight loss.
-
GLM-4.7 Official Documentation: Zhipu AI Developer Docs
- Link:
docs.z.ai/guides/llm/glm-4.7 - Description: Includes full API parameter descriptions and best practices.
- Link:
-
GLM-4.7 Technical Analysis: Deep dive into model architecture and capabilities
- Link:
medium.com/@leucopsis/a-technical-analysis-of-glm-4-7-db7fcc54210a - Description: Third-party technical evaluation, including benchmark data comparisons.
- Link:
-
Hugging Face Model Page: Open-source weight downloads
- Link:
huggingface.co/zai-org/GLM-4.7 - Description: Provides model files and deployment guides needed for local hosting.
- Link:
-
OpenRouter GLM-4.7: Multi-channel API access
- Link:
openrouter.ai/z-ai/glm-4.7 - Description: Offers access options from multiple providers and price comparisons.
- Link:
Author: Technical Team
Technical Exchange: Feel free to discuss your experiences with GLM-4.7 text structuring in the comments. For more resources, visit the APIYI apiyi.com technical community.