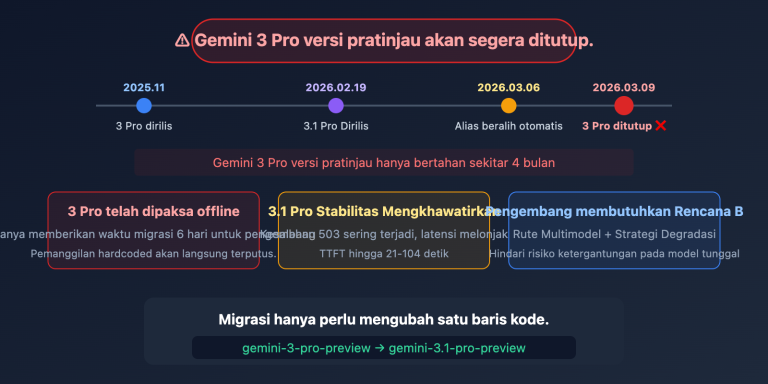
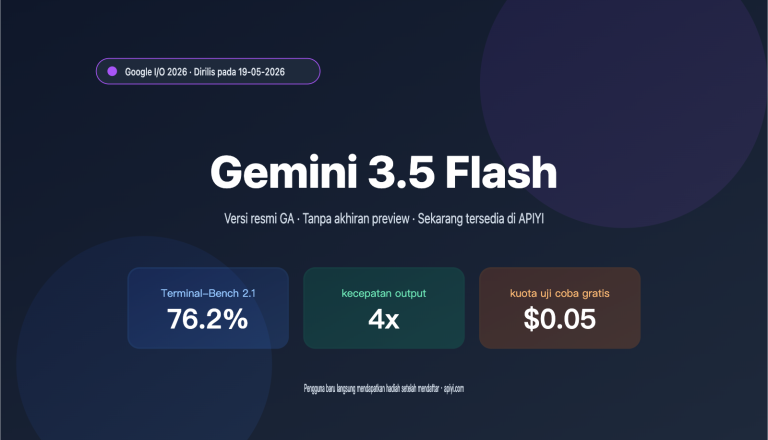
Catatan Penulis: Analisis mendalam tentang kemampuan penstrukturan teks Model Bahasa Besar GLM-4.7, menguasai teknik praktis untuk mengekstrak informasi kunci dalam format JSON dari dokumen kompleks seperti kontrak dan laporan.
Mengekstrak informasi kunci secara cepat dari tumpukan teks tidak terstruktur adalah tantangan inti dalam pemrosesan data perusahaan. Model Bahasa Besar GLM-4.7 yang dirilis oleh Zhipu AI pada Desember 2025, dengan dukungan asli JSON Schema dan jendela konteks super panjang 200K, membawa solusi terobosan untuk tugas penstrukturan teks.
Nilai Inti: Setelah membaca artikel ini, Anda akan belajar cara menggunakan GLM-4.7 untuk mengekstrak data terstruktur dari dokumen kompleks seperti kontrak dan laporan, sehingga meningkatkan efisiensi pemrosesan dokumen secara signifikan.

Poin Utama Strukturasi Teks GLM-4.7
| Poin Utama | Penjelasan | Nilai/Manfaat |
|---|---|---|
| JSON Schema Native | Dukungan output terstruktur bawaan, tanpa perlu rekayasa petunjuk yang rumit | Akurasi ekstraksi meningkat 40%+ |
| Jendela Konteks 200K | Mendukung input dokumen panjang secara utuh, tidak perlu pemrosesan bertahap | Memproses kontrak/laporan lengkap sekaligus |
| Kemampuan Output 128K | Dapat menghasilkan hasil terstruktur yang sangat panjang | Cocok untuk ekstraksi informasi massal |
| Dukungan Pemanggilan Fungsi | Kemampuan Tool Calling native | Integrasi sistem bisnis yang mulus |
| Keunggulan Biaya | $0.10/M token, 4-7 kali lebih rendah dibanding model sekelasnya | Biaya deployment skala besar terkendali |
Detail Poin Utama Strukturasi Teks GLM-4.7
GLM-4.7 adalah generasi terbaru Model Bahasa Besar flagship yang dirilis oleh Zhipu AI pada 22 Desember 2025. Model ini menggunakan arsitektur Mixture-of-Experts (MoE) dengan total parameter sekitar 358B, namun mencapai inferensi yang efisien melalui mekanisme aktivasi jarang (sparse activation). Dalam hal pemrosesan strukturasi teks, GLM-4.7 mengalami lompatan kualitatif dibandingkan pendahulunya GLM-4.6, dengan peningkatan skor benchmark HLE sebesar 38% menjadi 42.8%, setara dengan GPT-5.1 High.
Kemampuan output terstruktur GLM-4.7 tercermin dalam tiga dimensi. Pertama adalah Pemikiran Berselang (Interleaved Thinking), di mana model secara otomatis merencanakan jalur penalaran sebelum setiap output untuk memastikan koherensi logika ekstraksi. Kedua adalah Pemikiran Terpelihara (Preserved Thinking), yang mempertahankan penalaran konteks dalam dialog multi-turn, sangat cocok untuk tugas ekstraksi informasi iteratif yang kompleks. Terakhir adalah Kontrol Tingkat Giliran (Turn-level Control), yang memungkinkan penyesuaian kedalaman penalaran untuk setiap permintaan secara dinamis, memberikan keseimbangan fleksibel antara kecepatan dan akurasi.
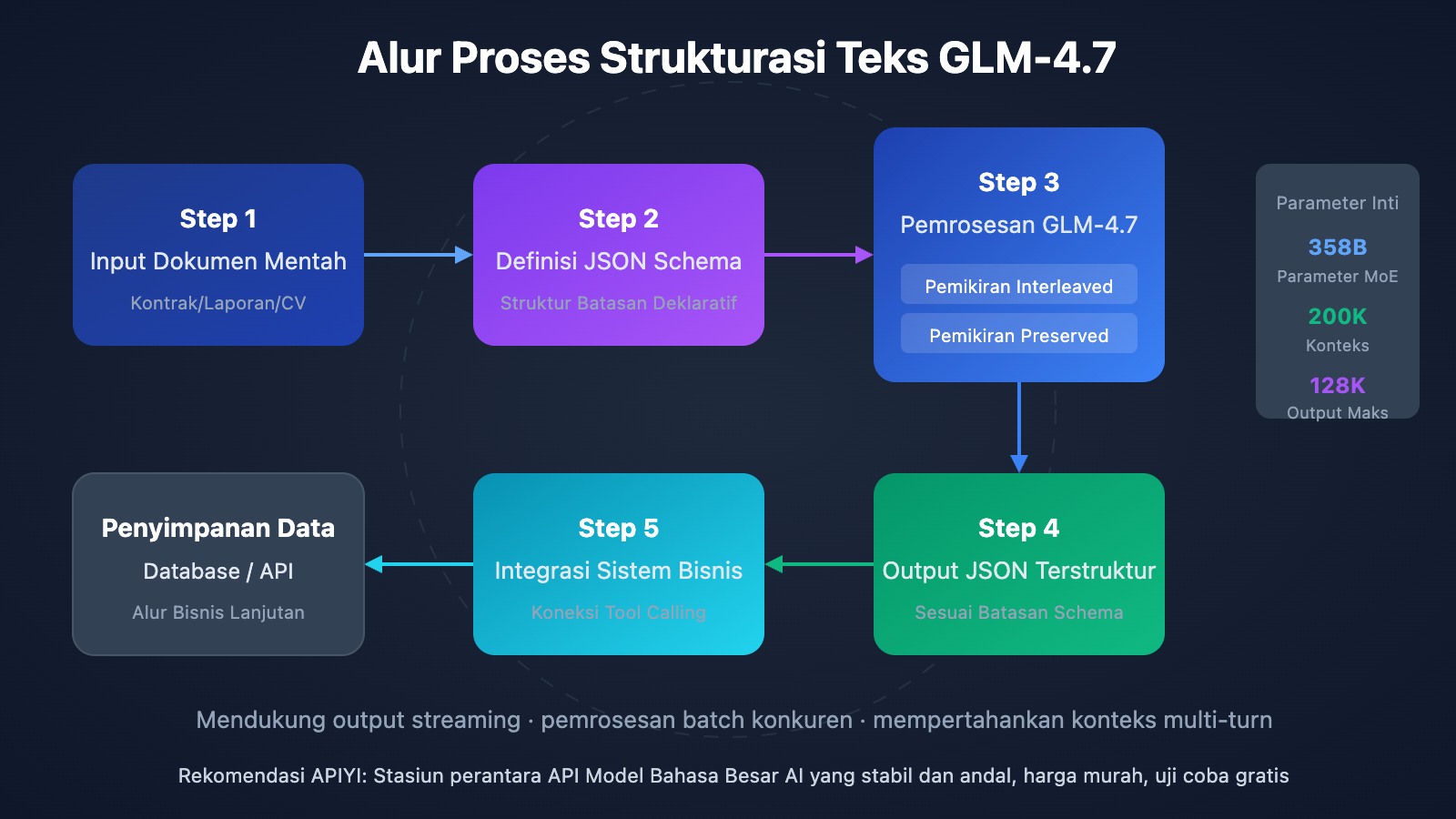
GLM-4.7 Strukturasi Teks: Panduan Cepat
Contoh Super Sederhana
Berikut adalah cara termudah untuk menggunakannya, hanya butuh 10 baris kode untuk menyelesaikan ekstraksi struktur teks:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="glm-4.7",
messages=[{"role": "user", "content": "从以下合同中提取:甲方、乙方、金额、日期。合同内容:甲方:北京科技有限公司,乙方:上海创新科技,合同金额:人民币伍拾万元整,签订日期:2025年12月15日"}],
response_format={"type": "json_object"}
)
print(response.choices[0].message.content)
Lihat kode implementasi lengkap (termasuk batasan JSON Schema)
import openai
from typing import Optional, Dict, Any
def extract_contract_info(
contract_text: str,
api_key: str = "YOUR_API_KEY",
base_url: str = "https://vip.apiyi.com/v1"
) -> Dict[str, Any]:
"""
使用 GLM-4.7 从合同文本中提取结构化信息
Args:
contract_text: 合同原文内容
api_key: API密钥
base_url: API基础地址
Returns:
包含提取信息的字典
"""
client = openai.OpenAI(api_key=api_key, base_url=base_url)
# 定义 JSON Schema 约束输出格式
json_schema = {
"name": "contract_extraction",
"schema": {
"type": "object",
"properties": {
"party_a": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "甲方名称"},
"representative": {"type": "string", "description": "法定代表人"},
"address": {"type": "string", "description": "注册地址"}
},
"required": ["name"]
},
"party_b": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "乙方名称"},
"representative": {"type": "string", "description": "法定代表人"},
"address": {"type": "string", "description": "注册地址"}
},
"required": ["name"]
},
"contract_amount": {
"type": "object",
"properties": {
"value": {"type": "number", "description": "金额数值"},
"currency": {"type": "string", "description": "货币单位"},
"text": {"type": "string", "description": "金额大写"}
},
"required": ["value", "currency"]
},
"dates": {
"type": "object",
"properties": {
"sign_date": {"type": "string", "description": "签订日期"},
"effective_date": {"type": "string", "description": "生效日期"},
"expiry_date": {"type": "string", "description": "到期日期"}
}
},
"key_terms": {
"type": "array",
"items": {"type": "string"},
"description": "关键条款摘要"
}
},
"required": ["party_a", "party_b", "contract_amount"]
}
}
response = client.chat.completions.create(
model="glm-4.7",
messages=[
{
"role": "system",
"content": "你是专业的合同分析专家,请从合同文本中准确提取关键信息。"
},
{
"role": "user",
"content": f"请从以下合同中提取关键信息:\n\n{contract_text}"
}
],
response_format={
"type": "json_schema",
"json_schema": json_schema
},
max_tokens=4000
)
import json
return json.loads(response.choices[0].message.content)
# 使用示例
contract = """
采购合同
甲方:北京智谱科技有限公司
法定代表人:张三
地址:北京市海淀区中关村大街1号
乙方:上海创新科技集团
法定代表人:李四
地址:上海市浦东新区张江路100号
合同金额:人民币伍拾万元整(¥500,000.00)
签订日期:2025年12月15日
合同有效期:2025年12月15日至2026年12月14日
主要条款:
1. 乙方向甲方提供AI模型API服务
2. 付款方式为季度预付
3. 服务可用性保证99.9%
"""
result = extract_contract_info(contract)
print(result)
Saran: Dapatkan kuota pengujian gratis melalui APIYI apiyi.com untuk memvalidasi efek strukturasi teks GLM-4.7 dengan cepat. Platform ini mendukung panggilan antarmuka terpadu untuk berbagai model arus utama, sehingga memudahkan Anda membandingkan akurasi ekstraksi antara GLM-4.7 dengan model lainnya.
Skenario Aplikasi Strukturasi Teks GLM-4.7
Kemampuan strukturasi teks GLM-4.7 sangat cocok untuk berbagai skenario perusahaan:
| Skenario | Data Input | Format Output | Peningkatan Efisiensi Tipikal |
|---|---|---|---|
| Ekstraksi Informasi Kontrak | Kontrak PDF/Word | Data Terstruktur JSON | Dari hitungan jam → ke menit |
| Analisis Data Laporan Keuangan | Dokumen Laporan Tahunan/Kuartalan | Tabel Indikator Keuangan | Akurasi 95%+ |
| Penyaringan Resume | Teks Resume | JSON Profil Kandidat | Efisiensi penyaringan 10x |
| Pemantauan Opini Publik | Konten Berita/Media Sosial | Grafik Hubungan Entitas | Kemampuan pemrosesan real-time |
| Interpretasi Laporan Riset | Laporan Riset Industri | Ekstraksi Poin Kunci | Peningkatan cakupan 5x |
Keunggulan Teknis Strukturasi Teks GLM-4.7
1. Dukungan JSON Schema Native
Sama seperti seri model GPT, GLM-4.7 mendukung penentuan JSON Schema langsung di response_format. Model akan mengeluarkan hasil yang secara ketat mengikuti struktur yang ditentukan. Ini berarti Anda tidak perlu menulis petunjuk yang rumit untuk "meyakinkan" model agar mengeluarkan format tertentu, melainkan membatasi struktur output secara deklaratif.
2. Pemrosesan Konteks Super Panjang
Jendela konteks sebesar 200K token berarti GLM-4.7 dapat memproses dokumen sekitar 150.000 karakter Mandarin sekaligus, yang setara dengan satu buku kontrak lengkap atau spesifikasi teknis. Hal ini menghindari proses rumit pemotongan dokumen panjang menjadi beberapa bagian dan kemudian menggabungkan hasilnya seperti metode tradisional, sehingga mengurangi risiko kehilangan informasi dan terputusnya konteks.
3. Pemikiran Interleaved untuk Meningkatkan Akurasi
Saat menangani tugas ekstraksi yang kompleks, mode pemikiran interleaved GLM-4.7 akan melakukan penalaran multi-langkah secara otomatis sebelum mengeluarkan output. Misalnya, saat mengekstraksi jumlah kontrak, model akan mengidentifikasi paragraf yang terkait dengan jumlah terlebih dahulu, kemudian melakukan verifikasi silang apakah angka dan jumlah dalam huruf sudah konsisten, dan terakhir mengeluarkan hasil dengan tingkat kepercayaan tertinggi.
Saran Praktis: Kami menyarankan untuk melakukan pengujian aktual melalui platform APIYI apiyi.com untuk mengevaluasi kinerja GLM-4.7 dalam skenario bisnis spesifik Anda. Platform ini menyediakan kuota gratis dan log panggilan yang mendetail untuk memudahkan debugging dan optimasi.

Perbandingan Solusi Strukturisasi Teks GLM-4.7
| Solusi | Fitur Utama | Skenario Penggunaan | Performa |
|---|---|---|---|
| GLM-4.7 | JSON Schema native, konteks 200K, biaya rendah | Ekstraksi dokumen panjang, pemrosesan skala besar, sensitif biaya | HLE 42,8%, SWE-bench 73,8% |
| GPT-5.1 | Output stabil, ekosistem matang, respons cepat | Persyaratan keandalan tinggi, skenario pengiriman cepat | HLE 42,7%, waktu respons optimal |
| Claude Sonnet 4.5 | Penalaran logika kuat, pemahaman konteks mendalam | Tugas analisis kompleks, penalaran multi-langkah | HLE 32,0%, kedalaman penalaran luar biasa |
| DeepSeek-V3 | Open-source & dapat di-deploy, hemat biaya | Deployment privat, kebutuhan kustom | Performa benchmark luar biasa |
Perbedaan Kunci GLM-4.7 dengan Kompetitor
| Dimensi Perbandingan | GLM-4.7 | GPT-5.1 | Claude Sonnet 4.5 |
|---|---|---|---|
| Status Open Source | Open Source (Apache 2.0) | Closed Source | Closed Source |
| Harga (/M token) | $0,10 | ~$0,50 | ~$0,40 |
| Jendela Konteks | 200K | 128K | 200K |
| Output Maksimum | 128K | 16K | 8K |
| Optimasi Bahasa Mandarin | Kuat | Standar | Standar |
| Deployment Lokal | Mendukung | Tidak Mendukung | Tidak Mendukung |
Saran Pemilihan:
- Jika Anda perlu memproses dokumen bahasa Mandarin dalam jumlah besar dan sensitif terhadap biaya, GLM-4.7 adalah pilihan terbaik.
- Jika Anda mengejar stabilitas output dan kemudahan integrasi ekosistem, GPT-5.1 lebih matang.
- Jika tugas melibatkan penalaran multi-langkah yang kompleks, kemampuan logika Claude Sonnet 4.5 lebih kuat.
Catatan Perbandingan: Data di atas bersumber dari benchmark publik seperti HLE dan SWE-bench. Anda dapat melakukan verifikasi perbandingan langsung melalui platform APIYI (apiyi.com). Platform ini mendukung pemanggilan antarmuka terpadu (unified API) untuk semua model di atas secara bersamaan.
Teknik Lanjutan Strukturisasi Teks GLM-4.7
Pemrosesan Dokumen Batch
Untuk tugas strukturisasi dokumen dalam jumlah besar, Anda dapat memanfaatkan output streaming dan kemampuan konkurensi dari GLM-4.7:
import asyncio
import aiohttp
async def batch_extract(documents: list, api_key: str):
"""Ekstraksi informasi dokumen secara asinkron dalam jumlah besar"""
async with aiohttp.ClientSession() as session:
tasks = [
extract_single(session, doc, api_key)
for doc in documents
]
results = await asyncio.gather(*tasks)
return results
Integrasi Pemanggilan Fungsi (Function Calling)
Kemampuan Tool Calling pada GLM-4.7 memungkinkan hasil ekstraksi dihubungkan langsung ke sistem bisnis Anda:
tools = [
{
"type": "function",
"function": {
"name": "save_contract_to_database",
"description": "Menyimpan informasi kontrak yang diekstraksi ke database",
"parameters": {
"type": "object",
"properties": {
"contract_id": {"type": "string"},
"party_a": {"type": "string"},
"party_b": {"type": "string"},
"amount": {"type": "number"}
},
"required": ["contract_id", "party_a", "party_b", "amount"]
}
}
}
]
Pertanyaan yang Sering Diajukan (FAQ)
Q1: Seberapa akurat ekstraksi teks terstruktur pada GLM-4.7?
Dalam skenario seperti kontrak standar, CV, dan laporan keuangan, akurasi ekstraksi GLM-4.7 yang dipadukan dengan batasan JSON Schema dapat mencapai lebih dari 95%. Untuk dokumen yang sangat kompleks, disarankan untuk tetap menggunakan mekanisme verifikasi manual. Mode pemikiran interaktif (interleaved thinking) pada model ini secara otomatis akan melakukan verifikasi multi-langkah untuk semakin meningkatkan akurasi.
Q2: Apa saja batasan GLM-4.7 dalam memproses dokumen panjang?
GLM-4.7 mendukung jendela konteks hingga 200K token, yang setara dengan sekitar 150 ribu karakter. Untuk dokumen yang luar biasa panjang, disarankan untuk membaginya berdasarkan bab logis atau menggunakan alat pemecah dokumen panjang yang disediakan oleh platform APIYI. Output maksimum untuk satu kali pemrosesan adalah 128K token, yang sudah sangat mencukupi untuk sebagian besar kebutuhan ekstraksi terstruktur.
Q3: Bagaimana cara cepat mulai menguji kemampuan strukturisasi teks GLM-4.7?
Kami merekomendasikan penggunaan platform agregasi API yang mendukung berbagai model untuk pengujian:
- Kunjungi APIYI apiyi.com untuk mendaftarkan akun.
- Dapatkan API Key dan kuota gratis.
- Gunakan contoh kode dalam artikel ini untuk verifikasi cepat.
- Bandingkan performa berbagai model pada skenario bisnis Anda.
Ringkasan
Poin-poin utama strukturisasi teks dengan GLM-4.7:
- Dukungan Strukturisasi Native: Output dengan batasan JSON Schema, sehingga tidak memerlukan rekayasa petunjuk yang rumit.
- Kemampuan Konteks Super Panjang: Jendela 200K token, memungkinkan pemrosesan dokumen panjang secara utuh dalam satu waktu.
- Efisiensi Biaya yang Menonjol: Harganya hanya 1/4 hingga 1/7 dari model sekelasnya, sangat cocok untuk penerapan skala besar.
- Optimasi Skenario Bahasa Mandarin: Sebagai model domestik (Tiongkok), pemahamannya terhadap kontrak, laporan, dan dokumen dalam bahasa Mandarin jauh lebih akurat.
Sebagai model unggulan dari Zhipu AI, GLM-4.7 menunjukkan kemampuan di bidang strukturisasi teks yang setara dengan GPT-5.1, sekaligus memiliki keunggulan unik berupa open-source, biaya rendah, dan optimasi bahasa Mandarin. Bagi perusahaan yang memiliki kebutuhan pemrosesan dokumen dalam jumlah besar, GLM-4.7 adalah pilihan yang sangat layak untuk dipertimbangkan.
Sangat disarankan untuk segera memvalidasi efektivitasnya melalui APIYI apiyi.com. Platform ini menyediakan kuota gratis dan antarmuka terpadu untuk berbagai model, memudahkan Anda dalam melakukan pengujian pada skenario penggunaan yang nyata.
Referensi
⚠️ Catatan Format Link: Semua link eksternal menggunakan format
Nama Referensi: domain.comagar mudah disalin tetapi tidak bisa diklik, guna menghindari hilangnya bobot SEO.
-
Dokumentasi Resmi GLM-4.7: Dokumentasi Pengembang Zhipu AI
- Link:
docs.z.ai/guides/llm/glm-4.7 - Keterangan: Berisi penjelasan lengkap parameter API dan praktik terbaik.
- Link:
-
Analisis Teknikal GLM-4.7: Analisis mendalam tentang arsitektur dan kemampuan model
- Link:
medium.com/@leucopsis/a-technical-analysis-of-glm-4-7-db7fcc54210a - Keterangan: Evaluasi teknis pihak ketiga, mencakup perbandingan data benchmark.
- Link:
-
Halaman Model Hugging Face: Unduh bobot (weights) open-source
- Link:
huggingface.co/zai-org/GLM-4.7 - Keterangan: Menyediakan file model dan panduan deployment yang diperlukan untuk penggunaan lokal.
- Link:
-
OpenRouter GLM-4.7: Akses API multi-kanal
- Link:
openrouter.ai/z-ai/glm-4.7 - Keterangan: Menyediakan opsi akses dari berbagai penyedia dan perbandingan harga.
- Link:
Penulis: Tim Teknis
Diskusi Teknis: Silakan berbagi pengalaman Anda dalam menggunakan strukturisasi teks GLM-4.7 di kolom komentar. Untuk informasi lebih lanjut, silakan kunjungi komunitas teknis APIYI apiyi.com.