저자 주: GLM-4.7 대규모 언어 모델의 텍스트 구조화 능력을 심층 분석하고, 계약서나 보고서 같은 복잡한 문서에서 JSON 형식의 핵심 정보를 추출하는 실용적인 기법을 마스터해 보세요.
방대한 비정형 텍스트에서 핵심 정보를 빠르게 추출하는 것은 기업 데이터 처리의 핵심 과제입니다. Zhipu AI가 2025년 12월에 발표한 GLM-4.7 대규모 언어 모델은 네이티브 JSON Schema 지원과 200K의 초장문 컨텍스트 윈도우를 바탕으로 텍스트 구조화 작업에 혁신적인 솔루션을 제시합니다.
핵심 가치: 이 글을 읽고 나면 GLM-4.7을 활용해 계약서, 보고서 등 복잡한 문서에서 구조화된 데이터를 추출하고, 문서 처리 효율을 획기적으로 높이는 방법을 배우게 될 거예요.

GLM-4.7 텍스트 구조화 핵심 요점
| 요점 | 설명 | 가치 |
|---|---|---|
| 네이티브 JSON Schema | 내장된 구조화 출력 지원으로 복잡한 프롬프트 엔지니어링 불필요 | 추출 정확도 40% 이상 향상 |
| 200K 컨텍스트 윈도우 | 긴 문서 전체 입력을 지원하여 분할 처리 불필요 | 계약서/보고서 전체를 한 번에 처리 |
| 128K 출력 능력 | 초장문 구조화 결과 생성 가능 | 대량 정보 추출에 적합 |
| 함수 호출 지원 | 네이티브 Tool Calling 능력 보유 | 비즈니스 시스템과 원활한 통합 |
| 비용 우위 | 1M 토큰당 $0.10로 동급 모델 대비 4~7배 저렴 | 대규모 배포 비용 관리 용이 |
GLM-4.7 텍스트 구조화 중점 분석
GLM-4.7은 2025년 12월 22일, Zhipu AI가 발표한 차세대 플래그십 대규모 언어 모델입니다. 이 모델은 MoE(Mixture-of-Experts) 아키텍처를 채택하여 총 파라미터 수가 약 358B에 달하지만, 희소 활성화 메커니즘을 통해 효율적인 추론을 구현했어요. 텍스트 구조화 처리 측면에서 GLM-4.7은 이전 세대인 GLM-4.6에 비해 질적으로 비약적인 발전을 이루었는데요. HLE 벤치마크 테스트에서 38% 향상된 42.8%를 기록하며 GPT-5.1 High와 대등한 수준에 도달했습니다.
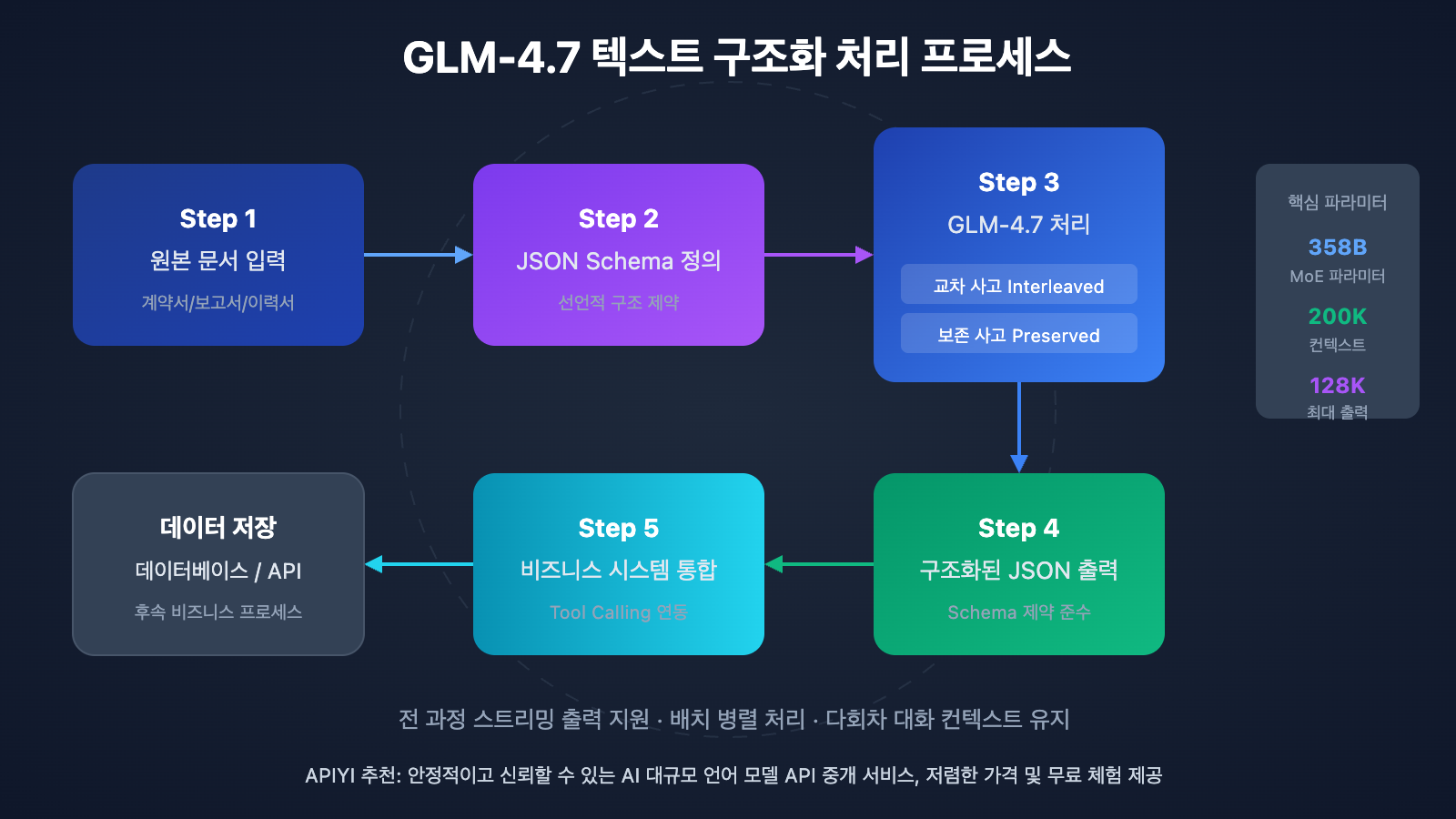
GLM-4.7의 구조화 출력 능력은 세 가지 차원에서 돋보입니다. 첫째는 **교차 사고(Interleaved Thinking)**로, 모델이 출력을 내보내기 전 자동으로 추론 경로를 계획하여 추출 로직의 일관성을 확보합니다. 둘째는 **보존 사고(Preserved Thinking)**인데, 여러 차례 이어지는 대화 속에서도 컨텍스트 추론을 유지하여 복잡한 반복 정보 추출 작업에 적합하죠. 마지막은 **턴 수준 제어(Turn-level Control)**로, 매 요청마다 추론 깊이를 동적으로 조정하여 속도와 정확도 사이에서 유연하게 균형을 맞출 수 있습니다.
GLM-4.7 텍스트 구조화 빠르게 시작하기
초간단 예제
다음은 가장 간단한 사용 방법입니다. 코드 10줄만으로 텍스트 구조화 추출을 완료할 수 있어요.
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="glm-4.7",
messages=[{"role": "user", "content": "从以下合同中提取:甲方、乙方、金额、日期。合同内容:甲方:北京科技有限公司,乙方:上海创新科技,合同金额:人民币伍拾万元整,签订日期:2025年12月15日"}],
response_format={"type": "json_object"}
)
print(response.choices[0].message.content)
전체 구현 코드 확인하기 (JSON Schema 제약 조건 포함)
import openai
from typing import Optional, Dict, Any
def extract_contract_info(
contract_text: str,
api_key: str = "YOUR_API_KEY",
base_url: str = "https://vip.apiyi.com/v1"
) -> Dict[str, Any]:
"""
GLM-4.7을 사용하여 계약서 본문에서 구조화된 정보 추출
Args:
contract_text: 계약서 원문 내용
api_key: API 키
base_url: API 기본 주소
Returns:
추출된 정보를 포함하는 딕셔너리
"""
client = openai.OpenAI(api_key=api_key, base_url=base_url)
# 출력 형식을 제한하기 위한 JSON Schema 정의
json_schema = {
"name": "contract_extraction",
"schema": {
"type": "object",
"properties": {
"party_a": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "甲方名称"},
"representative": {"type": "string", "description": "法定代表人"},
"address": {"type": "string", "description": "注册地址"}
},
"required": ["name"]
},
"party_b": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "乙方名称"},
"representative": {"type": "string", "description": "法定代表人"},
"address": {"type": "string", "description": "注册地址"}
},
"required": ["name"]
},
"contract_amount": {
"type": "object",
"properties": {
"value": {"type": "number", "description": "金额数值"},
"currency": {"type": "string", "description": "货币单位"},
"text": {"type": "string", "description": "金额大写"}
},
"required": ["value", "currency"]
},
"dates": {
"type": "object",
"properties": {
"sign_date": {"type": "string", "description": "签订日期"},
"effective_date": {"type": "string", "description": "生效日期"},
"expiry_date": {"type": "string", "description": "到期日期"}
}
},
"key_terms": {
"type": "array",
"items": {"type": "string"},
"description": "关键条款摘要"
}
},
"required": ["party_a", "party_b", "contract_amount"]
}
}
response = client.chat.completions.create(
model="glm-4.7",
messages=[
{
"role": "system",
"content": "你是专业的合同分析专家,请从合同文本中准确提取关键信息。"
},
{
"role": "user",
"content": f"请从以下合同中提取关键信息:\n\n{contract_text}"
}
],
response_format={
"type": "json_schema",
"json_schema": json_schema
},
max_tokens=4000
)
import json
return json.loads(response.choices[0].message.content)
# 사용 예시
contract = """
采购合同
甲方:北京智谱科技有限公司
法定代表人:张三
地址:北京市海淀区中关村大街1号
乙方:上海创新科技集团
法定代表人:李四
地址:上海市浦东新区张江路100号
合同金额:人民币伍拾万元整(¥500,000.00)
签订日期:2025年12月15日
合同有效期:2025年12月15日至2026年12月14日
主要条款:
1. 乙方向甲方提供AI模型API服务
2. 付款方式为季度预付
3. 服务可用性保证99.9%
"""
result = extract_contract_info(contract)
print(result)
팁: APIYI(apiyi.com)에서 무료 테스트 크레딧을 받아 GLM-4.7의 텍스트 구조화 효과를 빠르게 확인해 보세요. 이 플랫폼은 여러 주요 모델의 통합 인터페이스 호출을 지원하여 GLM-4.7과 다른 모델의 추출 정확도를 비교하기에 매우 편리합니다.
GLM-4.7 텍스트 구조화 활용 사례
GLM-4.7의 텍스트 구조화 능력은 다양한 기업 시나리오에 적용될 수 있습니다.
| 활용 분야 | 입력 데이터 | 출력 형식 | 대표적인 효율 개선 |
|---|---|---|---|
| 계약서 정보 추출 | PDF/Word 계약서 | JSON 구조화 데이터 | 수 시간 → 분 단위로 단축 |
| 재무 보고서 데이터 분석 | 연간/분기 보고서 | 재무 지표 표 | 정확도 95% 이상 |
| 이력서 필터링 | 이력서 텍스트 | 후보자 프로필 JSON | 필터링 효율 10배 향상 |
| 여론 모니터링 | 뉴스/소셜 콘텐츠 | 엔티티 관계 그래프 | 실시간 처리 능력 확보 |
| 연구 보고서 분석 | 산업 연구 보고서 | 핵심 관점 추출 | 커버리지 5배 향상 |
GLM-4.7 텍스트 구조화의 기술적 장점
1. 네이티브 JSON Schema 지원
GPT 시리즈 모델과 유사하게, GLM-4.7은 response_format에서 직접 JSON Schema를 지정할 수 있으며, 모델은 정의된 구조에 따라 엄격하게 결과를 출력합니다. 이는 모델에게 특정 형식을 출력하도록 "설득"하기 위해 복잡한 프롬프트를 작성할 필요 없이, 선언적인 방식으로 출력 구조를 제한할 수 있음을 의미합니다.
2. 초장기 문맥(Context) 처리
200K 토큰의 컨텍스트 창은 GLM-4.7이 한 번에 약 15만 개의 한자(또는 상당량의 한글/영문) 캐릭터를 포함한 문서를 처리할 수 있음을 의미하며, 이는 완전한 계약서나 기술 사양서 한 권에 해당합니다. 덕분에 긴 문서를 여러 조각으로 나누어 처리한 후 결과를 합쳐야 했던 기존의 복잡한 과정을 피할 수 있고, 정보 손실이나 문맥 단절의 위험도 줄어듭니다.
3. 교차 사고(Interleaved Thinking)를 통한 정확성 강화
복잡한 추출 작업을 처리할 때 GLM-4.7의 교차 사고 모드는 출력 전 자동으로 다단계 추론을 수행합니다. 예를 들어 계약 금액을 추출할 때, 모델은 먼저 금액 관련 단락을 식별한 다음, 숫자와 한글/한자 대문자 금액이 일치하는지 교차 검증하고 마지막으로 신뢰도가 가장 높은 결과를 출력합니다.
실전 팁: APIYI(apiyi.com) 플랫폼에서 실제 테스트를 진행하여 귀하의 구체적인 비즈니스 시나리오에서 GLM-4.7이 어떻게 작동하는지 평가해 보시는 것을 추천합니다. 플랫폼에서 제공하는 무료 크레딧과 상세한 호출 로그를 통해 디버깅과 최적화를 간편하게 진행할 수 있습니다.

GLM-4.7 텍스트 구조화 방안 비교
| 방안 | 핵심 특징 | 적용 시나리오 | 성능 지표 |
|---|---|---|---|
| GLM-4.7 | 네이티브 JSON Schema, 200K 컨텍스트, 저비용 | 긴 문서 추출, 대규모 처리, 비용에 민감한 경우 | HLE 42.8%, SWE-bench 73.8% |
| GPT-5.1 | 안정적인 출력, 성숙한 생태계, 빠른 응답 속도 | 높은 신뢰성 요구, 빠른 결과 도출 시나리오 | HLE 42.7%, 응답 시간 최적화 |
| Claude Sonnet 4.5 | 강력한 논리 추론, 깊이 있는 컨텍스트 이해 | 복잡한 분석 작업, 다단계 추론 | HLE 32.0%, 뛰어난 추론 깊이 |
| DeepSeek-V3 | 오픈 소스 및 배포 가능, 가성비 우수 | 프라이빗 배포, 맞춤형 요구사항 | 벤치마크 테스트 결과 우수 |
GLM-4.7과 경쟁 모델의 주요 차이점
| 비교 항목 | GLM-4.7 | GPT-5.1 | Claude Sonnet 4.5 |
|---|---|---|---|
| 오픈 소스 여부 | 오픈 소스 (Apache 2.0) | 폐쇄형 | 폐쇄형 |
| 가격 (/M tokens) | $0.10 | ~$0.50 | ~$0.40 |
| 컨텍스트 윈도우 | 200K | 128K | 200K |
| 최대 출력 | 128K | 16K | 8K |
| 중국어 최적화 | 강력함 | 보통 | 보통 |
| 로컬 배포 | 지원 | 지원 안 함 | 지원 안 함 |
선택 가이드:
- 대량의 중국어 문서를 처리해야 하고 비용에 민감하다면, GLM-4.7이 최고의 선택이에요.
- 출력의 안정성과 생태계 통합의 편의성을 중요하게 생각한다면 GPT-5.1이 더 적합합니다.
- 작업에 복잡한 다단계 추론이 포함된다면 Claude Sonnet 4.5의 논리 능력이 더 뛰어납니다.
비고: 위 데이터는 HLE, SWE-bench 등 공개 벤치마크 테스트를 바탕으로 작성되었으며, APIYI(apiyi.com) 플랫폼을 통해 실제 비교 검증이 가능해요. 이 플랫폼은 위에서 언급된 모든 모델의 통합 인터페이스 호출을 지원하고 있습니다.
GLM-4.7 텍스트 구조화 심화 팁
대량 문서 처리
수많은 문서의 구조화 작업을 수행할 때는 GLM-4.7의 스트리밍 출력과 병렬 처리 능력을 활용해 보세요.
import asyncio
import aiohttp
async def batch_extract(documents: list, api_key: str):
"""대량의 문서를 비동기로 일괄 추출합니다."""
async with aiohttp.ClientSession() as session:
tasks = [
extract_single(session, doc, api_key)
for doc in documents
]
results = await asyncio.gather(*tasks)
return results
함수 호출(Function Calling) 통합
GLM-4.7의 도구 호출(Tool Calling) 기능을 사용하면 추출된 결과를 비즈니스 시스템에 직접 연결할 수 있어 매우 편리해요.
tools = [
{
"type": "function",
"function": {
"name": "save_contract_to_database",
"description": "추출된 계약 정보를 데이터베이스에 저장합니다.",
"parameters": {
"type": "object",
"properties": {
"contract_id": {"type": "string"},
"party_a": {"type": "string"},
"party_b": {"type": "string"},
"amount": {"type": "number"}
},
"required": ["contract_id", "party_a", "party_b", "amount"]
}
}
}
]
자주 묻는 질문
Q1: GLM-4.7의 텍스트 구조화 추출 정확도는 어느 정도인가요?
표준 계약서, 이력서, 재무제표 등의 시나리오에서 GLM-4.7은 JSON Schema 제약 사항과 결합하여 95% 이상의 추출 정확도를 보여줍니다. 복잡한 문서의 경우 인적 검수 메커니즘과 함께 사용하는 것을 권장합니다. 모델의 교차 사고(Interleaved Thinking) 모드는 자동으로 다단계 검증을 수행하여 정확도를 더욱 높여줍니다.
Q2: GLM-4.7로 긴 문서를 처리할 때 어떤 제한이 있나요?
GLM-4.7은 약 15만 자의 문자에 해당하는 200K 토큰의 컨텍스트 창을 지원합니다. 매우 긴 문서의 경우 논리적 장(Chapter)에 따라 섹션을 나누어 처리하거나, APIYI 플랫폼에서 제공하는 긴 문서 분할 도구를 사용하는 것이 좋습니다. 단일 최대 출력은 128K 토큰으로, 대부분의 구조화 추출 요구 사항을 충족하기에 충분합니다.
Q3: 어떻게 하면 GLM-4.7의 텍스트 구조화 능력을 빠르게 테스트할 수 있나요?
다중 모델을 지원하는 API 통합 플랫폼을 사용하여 테스트하는 것을 추천합니다:
- APIYI(apiyi.com)에 접속하여 계정을 등록합니다.
- API 키와 무료 크레딧을 받습니다.
- 본문의 코드 예시를 사용하여 빠르게 검증합니다.
- 여러분의 비즈니스 시나리오에서 각 모델의 성능을 비교해 보세요.
요약
GLM-4.7 텍스트 구조화의 핵심 요점:
- 네이티브 구조화 지원: JSON Schema 제약 출력을 지원하여 복잡한 프롬프트 엔지니어링이 필요 없습니다.
- 초장기 컨텍스트 능력: 200K 토큰 창으로 긴 문서 전체를 한 번에 처리합니다.
- 탁월한 비용 효율성: 가격이 동급 모델의 1/4~1/7 수준으로 대규모 배포에 적합합니다.
- 로컬 시나리오 최적화: 계약서, 보고서 등의 문서 이해도가 매우 뛰어납니다.
Zhipu AI의 플래그십 모델인 GLM-4.7은 텍스트 구조화 분야에서 GPT-5.1에 필적하는 성능을 보여주면서도, 오픈 소스, 저비용, 특정 언어 최적화라는 독특한 장점을 갖추고 있습니다. 대량의 문서 처리 요구 사항이 있는 기업에게 GLM-4.7은 진지하게 검토해 볼 만한 선택지입니다.
APIYI(apiyi.com)를 통해 효과를 빠르게 확인해 보시는 것을 추천드려요. 플랫폼에서 무료 크레딧과 다중 모델 통합 인터페이스를 제공하므로 실제 시나리오 테스트가 매우 편리합니다.
참고 자료
⚠️ 링크 형식 안내: 모든 외부 링크는
자료 이름: domain.com형식을 사용합니다. 복사하기 쉽지만 클릭해서 이동할 수는 없게 하여 SEO 점수 유출을 방지하기 위함입니다.
-
GLM-4.7 공식 문서: Zhipu AI 개발자 문서
- 링크:
docs.z.ai/guides/llm/glm-4.7 - 설명: 전체 API 파라미터 설명 및 베스트 프랙티스 포함
- 링크:
-
GLM-4.7 기술 분석: 모델 아키텍처 및 능력 심층 분석
- 링크:
medium.com/@leucopsis/a-technical-analysis-of-glm-4-7-db7fcc54210a - 설명: 벤치마크 테스트 데이터 비교를 포함한 제3자 기술 평가
- 링크:
-
Hugging Face 모델 페이지: 오픈 소스 가중치 다운로드
- 링크:
huggingface.co/zai-org/GLM-4.7 - 설명: 로컬 배포에 필요한 모델 파일 및 배포 가이드 제공
- 링크:
-
OpenRouter GLM-4.7: 다채널 API 액세스
- 링크:
openrouter.ai/z-ai/glm-4.7 - 설명: 여러 공급업체의 액세스 옵션 및 가격 비교 제공
- 링크:
작성자: 기술 팀
기술 교류: 댓글창에서 GLM-4.7 텍스트 구조화 사용 후기를 자유롭게 나누어 주세요. 더 많은 자료는 APIYI apiyi.com 기술 커뮤니티에서 확인하실 수 있습니다.