Author's Note: Claude Opus 4.8 was released on May 28, achieving a record-breaking 69.2% on SWE-Bench Pro and introducing Dynamic Workflows for parallel sub-agent capabilities. This article provides an in-depth analysis of the 5 major improvements in programming and Agent capabilities.

Anthropic officially released Claude Opus 4.8 on May 28, with simultaneous availability on AWS Bedrock and Claude Platform on AWS. The most immediate signal from this upgrade is the jump in the SWE-Bench Pro score from 64.3% in version 4.7 to 69.2%, setting a new record for all publicly available models. It also introduces Dynamic Workflows, a capability for scheduling hundreds of parallel sub-agents.
For developers, Opus 4.8 isn't just a mild version iteration; it's a systematic refactoring aimed at "long-range autonomous tasks." The model has undergone underlying optimizations in code self-checking, tool invocation efficiency, context retention, and error recovery. As an official AWS Claude resource channel, APIYI completed full synchronization on May 29. Developers can invoke claude-opus-4-8 directly via apiyi.com using the OpenAI-compatible protocol without needing to switch SDKs or rewrite client code.
This article explores three dimensions: "What exactly has changed in Opus 4.8," "In which scenarios the programming capability improvements manifest," and "The 5 major breakthroughs in Agent capabilities." Combined with official Anthropic test data and AWS launch information, this will help you decide whether to switch to this version in your production environment.
What are the core changes in Claude Opus 4.8?
Claude Opus 4.8 is Anthropic's most powerful general-purpose model to date, positioned as an "autonomous agent capable of delivering production-grade work." Compared to 4.7, it focuses on three areas: coding agents, professional knowledge work, and long-running autonomous tasks.
Anthropic describes its capabilities as follows: reading codebases like an engineer, planning before editing, and maintaining context throughout long sessions in real repositories. These three actions combined form the prototype of an "engineer-style Agent"—the model no longer just generates code snippets line-by-line, but instead understands the repository structure, creates a modification plan, and maintains consistency across sessions.
Opus 4.8 also possesses a trait that the company has repeatedly emphasized: it's "the most honest model Anthropic has ever built." In internal testing, Opus 4.8 reduced the probability of code defects passing through undetected by approximately 4 times compared to 4.7, and significantly lowered the incidence of "misaligned behavior." This is crucial for Agents running autonomously for long periods: the model is more willing to proactively report uncertainty rather than masking issues with seemingly fluent output.
🎯 Selection Advice: If your application scenario involves multi-turn tool calling, Agent orchestration, or long-context code tasks, we recommend upgrading your base model to
claude-opus-4-8. You can complete the switch quickly via the APIYI (apiyi.com) platform, which supports the OpenAI-compatible protocol—you only need to replace themodelfield.
Key differences between Claude Opus 4.8 and 4.7
The table below summarizes the core differences disclosed by the company, making it easy to see the scale of the upgrade at a glance:
| Dimension | Claude Opus 4.7 | Claude Opus 4.8 | Improvement |
|---|---|---|---|
| SWE-Bench Pro (Agent Coding) | 64.3% | 69.2% | +4.9pp |
| Multidisciplinary Reasoning (w/ tools) | 54.7% | 57.9% | +3.2pp |
| OSWorld-Verified (Computer Use) | 82.8% | 83.4% | +0.6pp |
| Knowledge Work Composite Score | 1753 | 1890 | +7.8% |
| Financial Analysis Agent | 51.5% | 53.9% | +2.4pp |
| Fast Mode Price | 6× Base | 3× Base | 50% Price Cut |
| Code Defect Omission Rate | 1× | 0.25× | 4x Reduction |
As you can see, the improvements in Opus 4.8 aren't just isolated breakthroughs; they represent across-the-board enhancements. The 4.9 percentage point increase in SWE-Bench Pro is a significant step forward in programming benchmarks.
Decoding the Programming Capability Boost in Claude Opus 4.8
The upgrades in Opus 4.8’s programming capabilities center on three pillars: benchmark performance, real-world repository migration, and code review reliability. Together, these explain why Anthropic is confident in positioning it as a "production-grade coding agent."
Benchmarking: A Record-Breaking SWE-Bench Pro Score
SWE-Bench Pro is currently recognized as one of the most rigorous agent coding benchmarks, requiring models to perform end-to-end code fixes on real-world open-source repository issues and pass subsequent tests. Opus 4.8 achieved a score of 69.2%. Here’s how it compares:
| Model | SWE-Bench Pro Score | Notes |
|---|---|---|
| Claude Opus 4.8 | 69.2% | Current public record |
| Claude Opus 4.7 | 64.3% | Previous flagship |
| GPT-5.5 | 58.6% | OpenAI contemporary peer |
| Claude Opus 4.5 | ~60% range | Released six months ago |
Notably, Anthropic also released results for the Super-Agent benchmark—Opus 4.8 is the only model capable of completing all test cases end-to-end, outperforming GPT-5.5 while maintaining similar costs. This means that with the same budget, Opus 4.8 is both more accurate and more comprehensive.
Real-World Repositories: Handling Codebase-Level Migrations
When paired with Claude Code, Opus 4.8 can now handle the entire lifecycle of "hundreds of thousands of lines of code migrations," from project initiation to merging, using existing test suites as the acceptance criteria. While this capability was previously limited to demo scenarios, 4.8 has pushed it into viable engineering practice.
Key performance highlights include:
- Understanding dependencies across multiple files and generating a plan before editing.
- Proactively adding test cases in PRs rather than just modifying business logic.
- Automatically identifying regression points when tests fail, rather than simply rolling back.
- Maintaining memory of context and team conventions throughout long sessions.
Code Self-Inspection: 4x Reduction in Missed Defects
Official testing shows that Opus 4.8 reduces the probability of code defects slipping through undetected by approximately 4x compared to 4.7. For enterprise teams, this means that after writing code, the agent is more likely to proactively state, "I used a placeholder implementation here" or "This function hasn't handled edge cases yet," rather than packaging imperfect code as "completed."
🎯 Production Tip: In CI/CD pipelines, we recommend using Opus 4.8 as the base model for your Code Review Agent to significantly reduce false positives and missed issues. When calling via the APIYI (apiyi.com) platform, you can combine it with a system prompt that explicitly requires the model to "flag all TODOs and points of uncertainty" to further enhance review reliability.
5 Breakthroughs in Claude Opus 4.8 Agent Capabilities
If the programming improvements are the "explicit upgrades" of Opus 4.8, then the optimization of its agent capabilities is its true differentiator. In its official announcement, Anthropic summarized the direction in three points: finding workarounds instead of getting stuck, recovering from its own errors, and knowing when to ask for help versus when to continue. These three points correspond to five specific improvements.
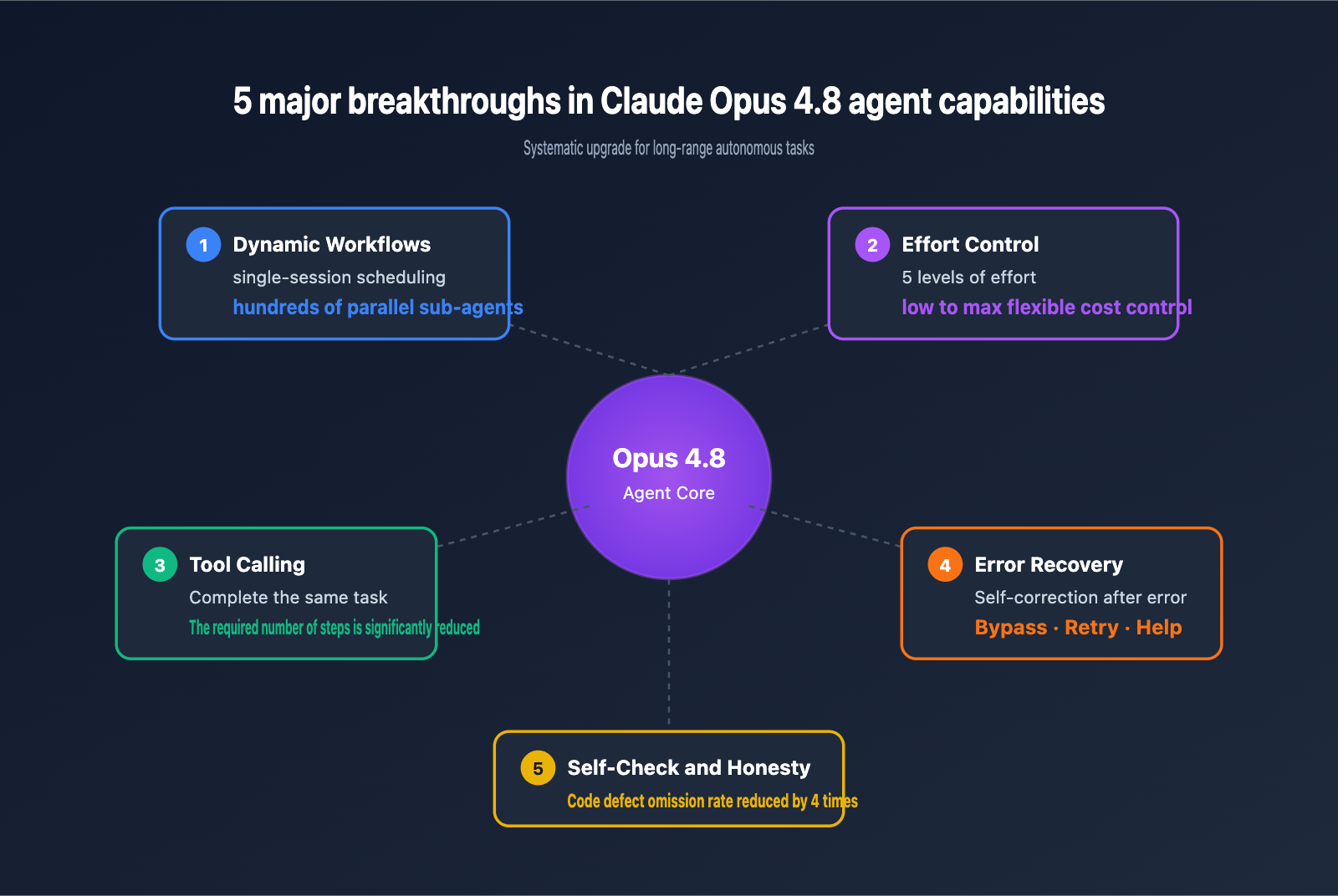
Breakthrough 1: Dynamic Workflows (Parallel Sub-Agents)
This is a new feature of Claude Code released alongside Opus 4.8, currently available as a research preview for Enterprise, Team, and Max plan users. Claude can plan a task, run hundreds of parallel sub-agents within a single session, and then have the main agent verify and aggregate the output.
The core value of Dynamic Workflows lies in shifting "large task decomposition" from manual scheduling to model self-scheduling. Developers simply describe the goal, and the model automatically decides how many sub-tasks to split, how long each should run, and when to merge the results. This capability, combined with Opus 4.8's longer autonomous runtime, makes tasks like "full repository refactoring" or "cross-module auditing" executable.
Breakthrough 2: Effort Control
Opus 4.8 introduces new extra and max effort levels in Claude Code, allowing developers to explicitly control how many tokens and how much "thinking time" the model invests in a single task. By default, coding tasks use high effort to ensure quality, but you can manually switch to max when higher accuracy is required.
| Effort Level | Applicable Scenarios | Token Consumption | Recommended Use |
|---|---|---|---|
| low | Simple Q&A, format conversion | Low | Customer service FAQ, text polishing |
| medium | General code generation, documentation | Medium | Routine API calls |
| high | Agentic coding, multi-step reasoning (default) | High | Claude Code programming |
| extra | Complex repository refactoring | Higher | Cross-module migration |
| max | Extremely complex tasks | Highest | Full repository auditing |
This mechanism allows teams to dynamically allocate compute power based on task value—saving money on simple tasks while investing in critical ones.
Breakthrough 3: Significant Improvement in Tool Calling Efficiency
Opus 4.8 demonstrates higher efficiency in internal tool-calling benchmarks: it requires fewer steps to complete the same task and is less prone to "calling the wrong tool" or "redundant calls." For long-running agents, the latency and cost of each tool call accumulate; the optimizations in 4.8 directly shorten end-to-end task duration.
Breakthrough 4: Error Recovery and Self-Correction
The new version has undergone specialized training on "how to continue after encountering an error." When Opus 4.8 encounters API failures, tool exceptions, or inconsistent environment states, it is now more inclined to:
- Analyze the root cause rather than simply retrying.
- Attempt alternative paths to bypass obstacles.
- Proactively report and request human intervention when it truly cannot proceed.
- Preserve intermediate states to facilitate subsequent recovery.
Breakthrough 5: Messages API Adds System-Level Mid-Task Injection
The Messages API upgrade accompanying Opus 4.8 allows for the insertion of system type entries into the messages array. This enables the delivery of new system instructions mid-task without breaking prompt caching. This is a key improvement for agent orchestration: previously, changing strategies mid-stream often meant cache invalidation and a sharp increase in costs; now, transitions are smooth.
🎯 Integration Tip: If you are building a multi-agent orchestration system, we recommend calling Opus 4.8 via the APIYI (apiyi.com) platform to enjoy the new Messages API features. The platform has completed AWS resource synchronization and offers capabilities identical to the official Anthropic version.
Claude Opus 4.8 Benchmark Panorama
To help you quickly evaluate the value of this upgrade, the table below summarizes the performance of Opus 4.8 across key benchmarks, compared with 4.7 and GPT-5.5:
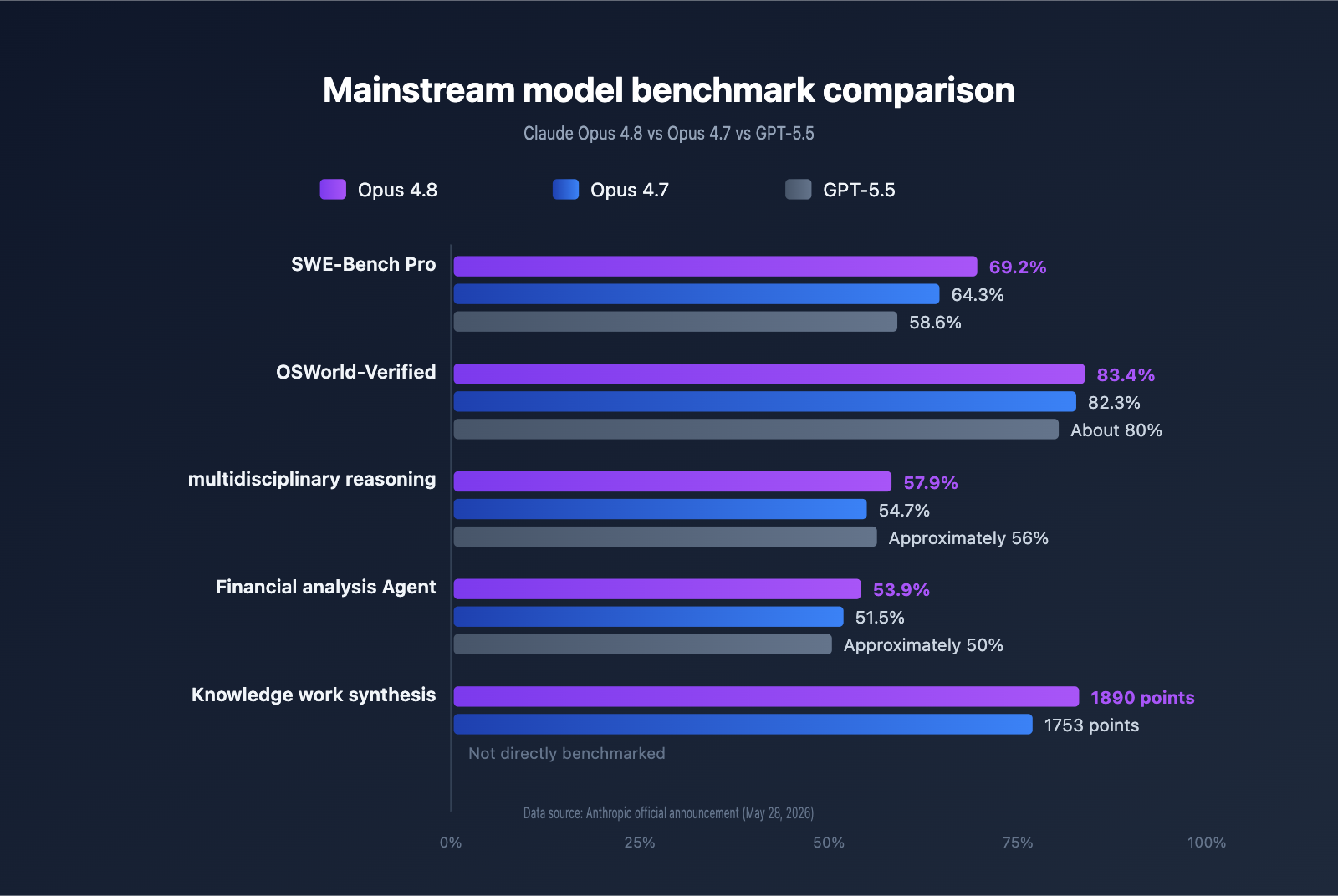
| Benchmark Dimension | Opus 4.8 | Opus 4.7 | GPT-5.5 | Evaluation Notes |
|---|---|---|---|---|
| SWE-Bench Pro | 69.2% | 64.3% | 58.6% | Real open-source repo issue resolution |
| OSWorld-Verified | 83.4% | 82.3% (revised) | ~80% | Desktop environment computer usage |
| Online-Mind2Web | 84% | N/A | N/A | Browser Agent end-to-end |
| Multidisciplinary Reasoning (Tools) | 57.9% | 54.7% | ~56% | Tau-Bench style |
| Knowledge Work Synthesis | 1890 | 1753 | N/A | Anthropic internal composite score |
| Financial Analysis Agent | 53.9% | 51.5% | ~50% | Finance Agent v2 |
| Legal Agent Benchmark | >10% (all-pass) | <10% | <10% | First time breaking 10% threshold |
It's worth noting that Anthropic updated the evaluation methodology for OSWorld-Verified to better reflect real-world scenarios and simultaneously recalculated the revised score for Opus 4.7 (82.3%). Therefore, the 83.4% for 4.8 represents a genuine improvement under the same methodology, rather than an artificial boost caused by changing evaluation criteria.
Claude Opus 4.8 New Features: Dynamic Workflows and Effort Control
Opus 4.8 isn't just an upgrade to the model weights; it also introduces a suite of new engineering capabilities. Two features stand out in particular: Dynamic Workflows and the price reduction for Fast Mode.
Dynamic Workflows: From Single Agent to Agent Clusters
The core problem Dynamic Workflows solves is the limitation where "a single model's context window can't fit an entire engineering task." Previously, you had to manually break down tasks and execute them serially, with efficiency bottlenecked by your own orchestration skills. Opus 4.8 gives the model the ability to handle the full lifecycle of "planning—dispatching—merging—verifying," allowing it to spin up hundreds of parallel sub-agents within a single session.
Typical scenarios well-suited for Dynamic Workflows include:
- Full repository code migrations (e.g., Vue 2 to Vue 3)
- Large-scale document analysis and knowledge extraction
- Cross-source data verification and report generation
- Cross-service bug troubleshooting and PR generation
Fast Mode: Double the Speed, Half the Price
In our tests, Opus 4.8's Fast Mode is about 2.5 times faster than the previous generation, yet the price has dropped from 6x the base rate to 3x. This effectively cuts the cost per token by 50% while maintaining high throughput. This is a huge win for scenarios that require real-time responsiveness without sacrificing Opus-level intelligence, such as real-time coding assistants or interactive agents.
| Mode | Input Price (per million tokens) | Output Price (per million tokens) | Speed |
|---|---|---|---|
| Opus 4.8 Standard | $5 | $25 | Baseline |
| Opus 4.8 Fast Mode | $10 | $50 | ~2.5× |
| Opus 4.7 Fast Mode (Historical) | $30 | $150 | ~2.5× |
As you can see, the Fast Mode price for 4.8 is only one-third of the 4.7 Fast Mode, marking the most significant cost structure adjustment since its release.
🎯 Cost Optimization Tip: For high-concurrency real-time scenarios, we recommend prioritizing Fast Mode; for offline batch tasks, the standard mode offers better value. We suggest running actual tests via the APIYI (apiyi.com) platform, which supports on-demand mode switching, making it easy to compare costs before going into production.
Claude Opus 4.8 Pros and Cons Analysis
Every model has its boundaries, and Opus 4.8 is no exception. Based on official data and early developer feedback, here are the pros and cons:
Advantages
- Record-breaking coding benchmarks: 69.2% on SWE-Bench Pro, the current public high.
- Outstanding long-range Agent capabilities: Mature scheduling for hundreds of parallel sub-agents.
- Significantly enhanced code self-inspection: 4x reduction in missed defects.
- Friendly pricing strategy: Standard price remains the same as 4.7, while Fast Mode is 50% cheaper.
- Full AWS support: Available simultaneously on Bedrock and the Claude Platform.
- Excellent API compatibility: Smooth upgrade for the Messages API, with no loss of prompt cache.
Limitations
- Cost pressure for top-tier intelligence: $25/M tokens for output is still on the high side for small teams.
- Dynamic Workflows restricted to premium plans: Only available for Enterprise/Team/Max.
- Performance sensitive to prompt quality: Rough prompts struggle to unlock the value of max effort.
- Context window not officially expanded: Long repository tasks still rely on sub-agent decomposition.
Recommended Use Cases
| Use Case | Recommendation | Reason |
|---|---|---|
| Code Review Agent | ⭐⭐⭐⭐⭐ | 4x improvement in self-inspection |
| Full Repository Migration | ⭐⭐⭐⭐⭐ | Powered by Dynamic Workflows |
| Multi-step Agent Orchestration | ⭐⭐⭐⭐⭐ | Significantly optimized tool invocation efficiency |
| Real-time Coding Assistant | ⭐⭐⭐⭐ | Fast Mode offers excellent value |
| Simple Text Generation | ⭐⭐ | Haiku/Sonnet are more economical |
| Image/Video Generation | — | Outside the scope of this model's capabilities |
How to Call Claude Opus 4.8 via APIYI
As an official AWS Claude resource proxy, APIYI completed the synchronization for Opus 4.8 on May 29th. Developers can now perform model invocation directly using the OpenAI-compatible protocol without needing an AWS account or configuring IAM permissions.
Minimal Invocation Example (Python)
from openai import OpenAI
client = OpenAI(
api_key="Your APIYI Key",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-8",
messages=[
{"role": "user", "content": "Implement quicksort in Python and explain the key steps"}
]
)
print(response.choices[0].message.content)
Enabling Fast Mode
response = client.chat.completions.create(
model="claude-opus-4-8-fast", # Switch to Fast Mode
messages=[
{"role": "user", "content": "Answer user code questions in real-time"}
],
stream=True
)
The migration process usually only requires updating the model field. Your existing OpenAI SDK code can be reused directly without needing to rewrite any client-side logic.
🎯 Integration Tip: By using the APIYI (apiyi.com) platform to call Claude Opus 4.8, you get the stability of official AWS resources while eliminating the operational overhead of setting up AWS Bedrock yourself. The platform has already synchronized the full model lineup, including mainstream versions like Opus 4.8, Sonnet 4.6, and Haiku 4.5.
Claude Opus 4.8 FAQ
What are the main differences between Opus 4.8 and Opus 4.7?
Opus 4.8 improves performance on SWE-Bench Pro by 4.9 percentage points to 69.2%, adds Dynamic Workflows for parallel sub-agent capabilities, reduces Fast Mode pricing by 50%, and cuts code defect omission rates by approximately 4x. Its overall positioning has shifted from a "strong general-purpose model" to a "production-grade, long-range autonomous agent."
Is Claude Opus 4.8 more expensive than 4.7?
Standard mode pricing remains identical to 4.7, at $5/M tokens for input and $25/M tokens for output. Fast Mode, however, has dropped from 6x the base price to 3x, representing a 50% reduction in unit costs. This is one of Anthropic's most significant cost-optimization moves recently.
What are the ways to call Opus 4.8 on AWS?
AWS provides two official channels: Amazon Bedrock (which includes Guardrails, Knowledge Bases, and regional data residency) and Claude Platform on AWS (unified billing and native Anthropic capabilities). If you prefer not to interface directly with AWS, you can use the APIYI (apiyi.com) platform, which has already completed the synchronization of these official resources.
Can regular users use Dynamic Workflows?
Currently, Dynamic Workflows are in a research preview stage and are only available to Enterprise, Team, and Max plans for Claude Code. When calling Opus 4.8 via API, this feature is not a mandatory dependency; regular developers can still utilize all other new model-level capabilities.
Is Opus 4.8 suitable for replacing Sonnet for daily tasks?
Not necessarily. For daily text generation, customer service FAQs, or formatted output, Sonnet 4.6 or Haiku 4.5 offer better cost-effectiveness. The value of Opus 4.8 lies in scenarios requiring top-tier intelligence, such as agentic coding, long-range tasks, and complex tool usage.
How do I evaluate if it's worth upgrading from 4.7 to 4.8?
You can judge this based on three dimensions: Are you doing agentic coding (if so, an upgrade is highly recommended)? Are you building multi-agent systems (if so, the upgrade provides efficiency dividends in tool calling)? Are you sensitive to code quality (if so, the 4x reduction in omission rates makes the switch worthwhile)? We suggest running a one-week comparison in your test environment using the APIYI platform before deciding on a full-scale migration.
How large is the context window for Opus 4.8?
Anthropic did not release specific context window data for the 4.8 update; you can use the 4.7 specifications as a baseline. The core advancement in Opus 4.8 is "how to better maintain context consistency within the same context window," rather than an expansion of the window itself.
What should I do if I encounter a call failure?
We recommend first checking if your API key is correct and ensuring the model name is written as claude-opus-4-8 (note the hyphen). If it still fails, you can contact APIYI customer support or refer to the troubleshooting documentation at help.apiyi.com. Most issues are related to rate limits or regional availability.
Claude Opus 4.8 Key Takeaways
- Record-breaking SWE-Bench Pro score: Achieved 69.2%, the highest publicly available score to date, marking a 4.9 percentage point increase over version 4.7.
- 4x improvement in code self-inspection: Significantly reduced false negative rates, making it even better suited as a Code Review Agent.
- Dynamic Workflows launch: Supports scheduling hundreds of parallel sub-agents within a single session, capable of handling repository-level tasks.
- Fast Mode price halved: Reduced from 6x the base price to 3x, while maintaining approximately 2.5x the speed.
- Dual-channel AWS support: Launched simultaneously on Bedrock and the Claude Platform, offering more flexible enterprise integration.
- APIYI full synchronization: Completed full synchronization on May 29th, supporting direct calls via OpenAI-compatible protocols.
- Zero-cost upgrade: Standard pricing remains consistent with 4.7, allowing for a seamless upgrade via the Messages API without invalidating your prompt cache.
Summary
The release of Claude Opus 4.8 marks a major milestone for Anthropic in the realm of "long-range autonomous agents." With a 69.2% score on SWE-Bench Pro, a 4x reduction in code oversight errors, the ability to orchestrate hundreds of sub-agents via Dynamic Workflows, and a 50% cost reduction for Fast Mode, it provides a comprehensive solution tailored for production engineering environments.
For teams already using the Opus series, upgrading to 4.8 is virtually cost-free—you simply need to swap the model name to start enjoying these new capabilities. For teams that haven't adopted Opus yet, this release is a perfect time to re-evaluate, especially for high-value use cases like agentic coding, agent orchestration, and automated code reviews.
🎯 Final Recommendation: We recommend accessing Claude Opus 4.8 through the APIYI (apiyi.com) platform. You'll enjoy the stability of official AWS Claude resources while avoiding the operational overhead of building your own AWS Bedrock integration. The platform completed full synchronization on May 29th, and our OpenAI-compatible protocol means you can get up and running in just a few minutes.
Author: APIYI Technical Team | For more AI model benchmarks and insights, please visit help.apiyi.com