Recently, an open-source project on GitHub called ARIS-Code has quietly surged to over 8,400 stars and 780+ forks. Developed by wanshuiyin as an iteration on the open-source Claude Code, its full name is "Auto-Research-In-Sleep." This isn't just marketing hype—it genuinely allows Claude Code to automatically run experiments, search for literature, and edit papers while you sleep, meaning you wake up to significant progress on your work.
The discussion ARIS-Code has sparked in the academic community is particularly noteworthy. The author shared three community paper cases showing that the initial drafts produced by the tool achieved AI review scores of 7-8/10, with submissions already sent to top CS conferences, AAAI 2026, and IEEE TGRS. This indicates that fully automated AI research has moved beyond the "demo" stage and is now capable of producing actual submission-ready manuscripts.
In this article, we'll dive deep into the core architecture of ARIS-Code, its 42 built-in skills, and how to connect it to Claude models in China using a third-party API proxy service, helping you decide if this tool fits your research workflow.
🎯 Special Note: Since ARIS-Code is built on the open-source version of Claude Code, its executor can only connect to Claude series models (Sonnet/Opus/Haiku). It does not support GPT or Gemini series as the primary executor. We recommend using the APIYI (apiyi.com) platform to access Claude models; it is compatible with the native Anthropic protocol, offers stable access within China, and uses a pay-as-you-go model, so you don't need an overseas credit card.
What is the ARIS-Code: Auto-Research-In-Sleep Project?
ARIS (Auto-Research-In-Sleep) is an autonomous research workflow system designed for ML/AI researchers. You can find the project on GitHub: github.com/wanshuiyin/Auto-claude-code-research-in-sleep. Its design goal is clear: to allow researchers to complete the entire process—from literature review and idea generation to experiment execution, paper writing, and rebuttal handling—with minimal human intervention, freeing researchers from repetitive manual labor.
At its core, ARIS-Code is a methodology library. The entire system consists of pure Markdown files (SKILL.md). There are no frameworks to install, no databases to maintain, and no Docker configurations required. Each "Skill" is a workflow instruction that can be read by any LLM agent. This means you can switch the executor from Claude Code to Codex CLI, OpenClaw, Cursor, Trae, or any other tool that supports agent mode, and the workflow remains effective.
This "zero-dependency, zero-lock-in" design is what sets ARIS-Code apart from other research AI tools. It essentially "externalizes" the research process into executable prompt engineering rather than wrapping it in a black-box tool. This is significant for researchers because it means the workflow is readable, modifiable, and portable, rather than being tied to a specific commercial product.
It's worth mentioning that the ARIS-Code repository has already accumulated over 700 commits and is still iterating rapidly. In the last three months, it has added several high-value skills, such as paper-talk (generating conference presentation scripts), resubmit-pipeline (a workflow for resubmitting after rejection), and kill-argument (generating adversarial rebuttals), making the entire ecosystem very active.
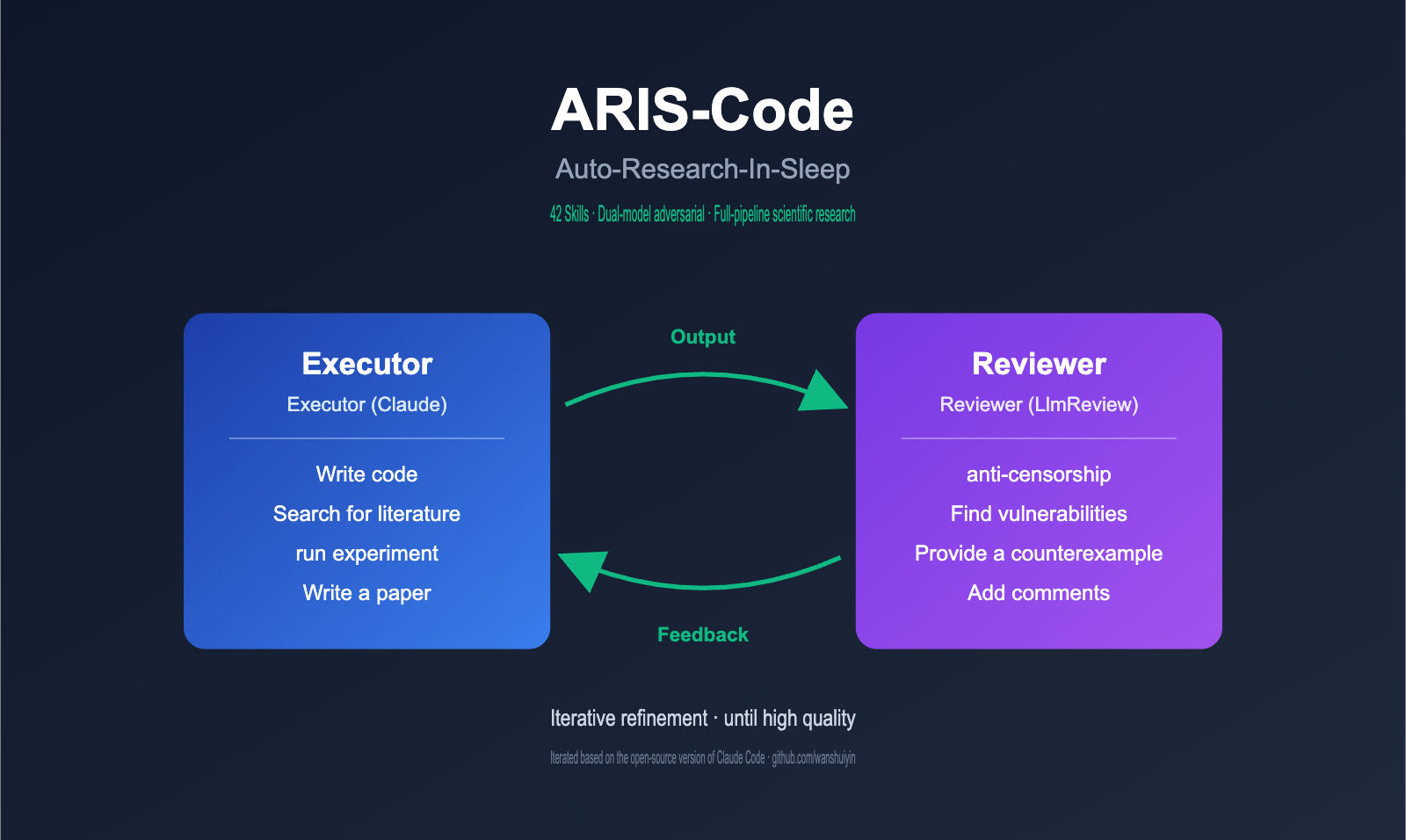
ARIS-Code Core Architecture: Executor-Reviewer Adversarial Review
The most significant engineering value of ARIS-Code lies in its dual-model adversarial architecture, which is the fundamental differentiator between it and other research assistants on the market. The project author makes a profound observation in the README: single-model self-review has structural weaknesses. When the same model both executes a task and reviews its own output, it systematically reproduces its own blind spots, falling into a local optimum trap.
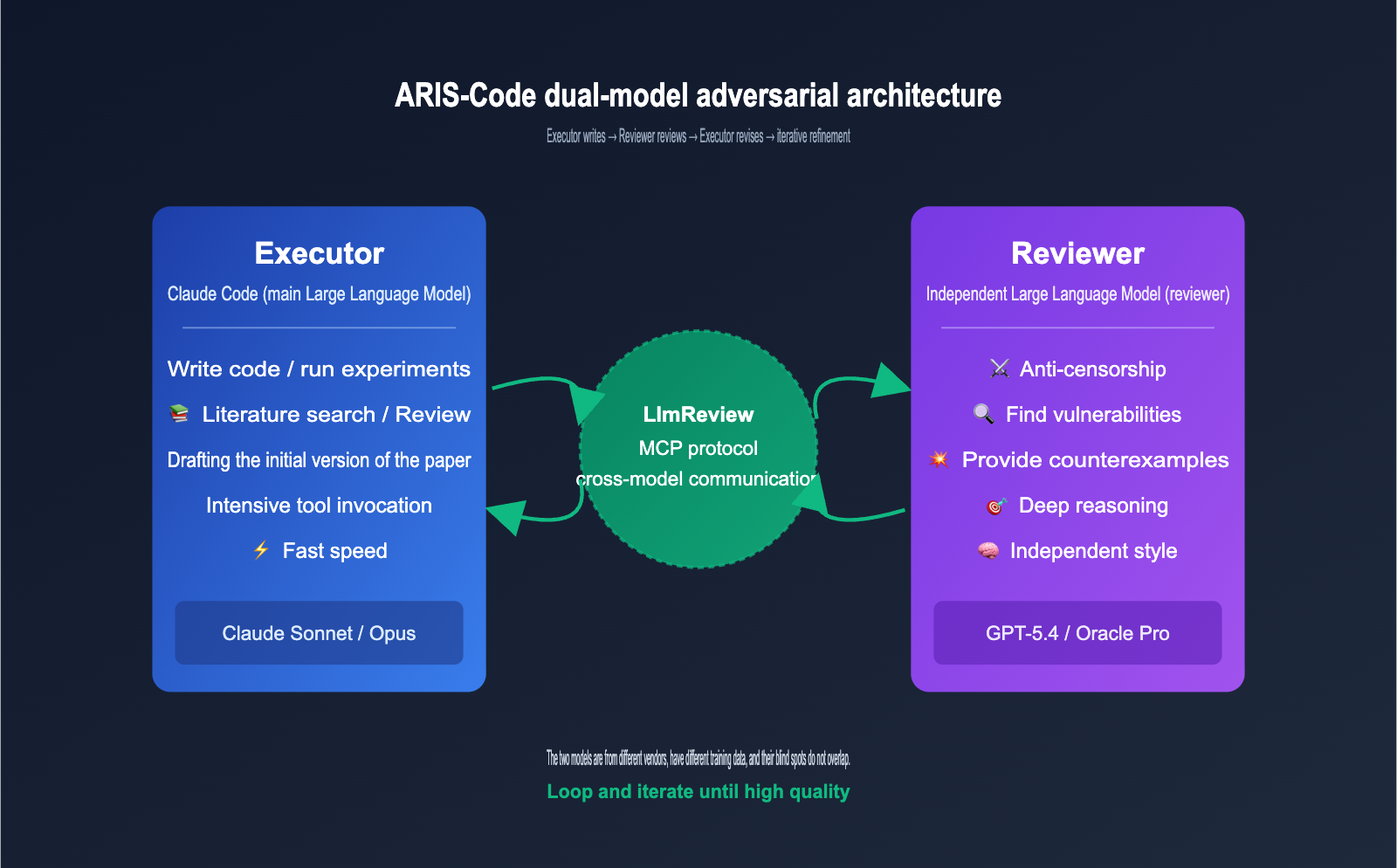
ARIS-Code's solution is to delegate the review authority to a completely independent model. The specific role division is as follows:
| Role | Model Selection | Responsibility | Recommended Capability |
|---|---|---|---|
| Executor | Claude Sonnet / Opus | Primary execution: coding, literature review, running experiments, drafting papers | Fast speed, long context window, stable tool invocation |
| Reviewer | GPT-5.4 (Codex MCP) / Oracle Pro | Adversarial review: finding bugs, questioning conclusions, proposing counter-examples | Deep reasoning, critical thinking, independent style |
| Coordination | LlmReview toolchain | Cross-model communication, state persistence | Transparent transmission via MCP protocol |
The entire workflow can be summarized as a simple loop: Executor writes → Reviewer critiques → Executor revises → repeat until the Reviewer provides a "pass" verdict. This loop is effective because the two models come from different vendors, have different training data, and possess different reasoning styles, ensuring their blind spots do not overlap.
To prevent LLM hallucinations from contaminating research findings, ARIS-Code also designs a multi-layer evidence audit chain: experiment-audit (code integrity) → result-to-claim (results to assertions) → paper-claim-audit (paper assertion audit) → citation-audit (citation verification). Each layer has an independent JSON verdict and SHA256 hash for reproducibility verification; this level of engineering rigor is quite rare in research AI tools.
🔧 Configuration Tip: If you want to fully replicate the ARIS-Code dual-model architecture, it's recommended to obtain API keys for both Claude and GPT series models via APIYI (apiyi.com). One platform provides access to both sets of interfaces, saving you the hassle of opening overseas accounts and binding credit cards separately.
ARIS-Code Built-in 42 Skills for Full Research Pipelines
What's most impressive about ARIS-Code is its 42+ built-in Skills. These aren't isolated tools but a pipeline covering the entire research lifecycle. I've categorized them by workflow stage below:
| Workflow Stage | Representative Skills | Core Capability |
|---|---|---|
| Idea Discovery | research-lit / novelty-check / idea-creator / idea-discovery | Multi-source literature retrieval, cross-model novelty verification, generation of 8-12 candidate ideas |
| Experimentation | experiment-bridge / experiment-queue / run-experiment | Code review → GPU deployment → multi-seed orchestration → automatic OOM handling |
| Auto Review | auto-review-loop / research-review / experiment-audit | 4-round iterative improvement, structured peer review, code integrity verification |
| Paper Writing | paper-writing / paper-claim-audit / proof-checker / citation-audit | Narrative → LaTeX → PDF, assertion auditing, proof checking, citation verification |
| Rebuttal | rebuttal | Reviewer comment analysis → draft response → stress testing |
| Meta-Capabilities | research-wiki / meta-optimize / deepxiv | Persistent knowledge base, outer-loop optimization, alternative literature sources |
The most practical Skill is experiment-bridge, which streamlines the "code review → remote GPU deployment → experiment launch → result retrieval" process. When the Reviewer suggests "an ablation study is needed here," the Executor automatically writes the script, rsyncs it to the GPU node, starts training, monitors logs, and collects results—all without the researcher needing to intervene manually.
Another noteworthy Skill is citation-audit, which eliminates the biggest pain point in LLM-written papers—citation hallucinations—by connecting to real DBLP and CrossRef databases. Every BibTeX entry comes from a real database, not something the model invented. This is a baseline requirement for academic writing, as any fabricated citation can lead to immediate rejection.
Researchers also particularly appreciate the research-wiki persistent cross-session knowledge base. It accumulates your paper reading notes, idea drafts, and failed experiment records across multiple projects, forming a growing personal research memory. When you return to a shelved direction three months later, you don't need to re-read all the relevant papers; the AI assistant has already preserved the context for you.
💡 Usage Tip: Calling any Skill will consume a significant amount of Claude API tokens, especially for long-text generation tasks like
paper-writing. We recommend accessing Claude models via apiyi.com, as the platform supports pay-as-you-go billing and provides complete token usage monitoring, making it easy for you to estimate the cost per paper.
Complete Configuration Guide for Connecting ARIS-Code to APIYI
Since the ARIS-Code executor is iterated from the open-source version of Claude Code, it only accepts the native Anthropic API protocol. This means GPT and Gemini series models cannot be used as an Executor. This is a hard constraint and often the biggest point of confusion for developers during their first deployment.
The configuration steps for connecting to Claude models via APIYI are very straightforward and can be summarized in 5 steps:
# Step 1: Clone the project repository
git clone https://github.com/wanshuiyin/Auto-claude-code-research-in-sleep
cd Auto-claude-code-research-in-sleep
# Step 2: Install Skills to the local Claude Code configuration directory
mkdir -p ~/.claude/skills/
cp -r skills/* ~/.claude/skills/
# Step 3: Configure the APIYI proxy URL (Core Step)
export ANTHROPIC_BASE_URL="https://vip.apiyi.com"
export ANTHROPIC_AUTH_TOKEN="Your APIYI Key"
# Step 4: Launch Claude Code
claude
# Step 5: Call any Skill within Claude Code
# For example: /research-pipeline "factorized gap in discrete diffusion LMs"
The most critical part here is setting the ANTHROPIC_BASE_URL environment variable in Step 3. It tells Claude Code not to request the official Anthropic endpoint, but to use the proxy gateway instead. This gateway is fully compatible with the native Anthropic protocol, meaning the Skills built into ARIS-Code require no code modifications. All features, including tool invocation, streaming output, and thinking chains, are passed through transparently.
If you also need to deploy the Reviewer side (Codex MCP), the process is:
# Install Codex MCP for the reviewer side
npm install -g @openai/codex
codex setup # You can also fill in the proxy address here for GPT models
claude mcp add codex -s user -- codex mcp-server
For researchers who want to fully replicate the paper-level effects of ARIS-Code, the project also provides an Oracle MCP solution that connects to GPT-5.4 Pro as an advanced Reviewer. This is extremely useful during the final sprint of a serious paper, as the Pro version offers significantly deeper critique and better counter-example construction compared to the base version.
🚀 Unified Access Solution: The APIYI (apiyi.com) platform supports mainstream models including the Claude series (Sonnet 4.5/Opus 4), GPT series (GPT-5/o4), and Gemini series (Gemini 3 Pro). A single key can drive both the Executor and Reviewer sides of ARIS-Code, which is very convenient for research teams managing costs and tracking model invocation logs.
ARIS-Code Effort Levels and GPU Configuration Strategy
ARIS-Code provides 4 Effort Levels to balance cost and quality, which is a highly engineered design. Different research stages have vastly different requirements for depth; there's no need to burn tokens during the early exploration phase, while you'll want to push quality to the limit during the paper submission sprint.

| Effort Level | Token Multiplier | Use Case | Estimated Per-Call Cost |
|---|---|---|---|
| lite | 0.4× | Quick exploration, idea validation | Very Low |
| balanced | 1.0× | Standard daily research workflow | Standard |
| max | 2.5× | Serious paper experimentation | Medium-High |
| beast | 5-8× | Top-tier conference sprint, Submission Mode | High |
ARIS-Code also provides 4 configuration options for the GPU side, catering to both local and cloud-based setups:
| GPU Configuration | Use Case | Cost Characteristics |
|---|---|---|
| local | Researchers with local GPUs | One-time hardware cost |
| remote | Lab SSH servers | Free campus resources |
| vast | Short-term high-intensity training | Hourly billing, flexible |
| modal | Periodic lightweight tasks | Serverless, $30 free credit |
💰 Cost Control Advice: If you are just starting with ARIS-Code, it's recommended to run the workflow using lite + local first, routing model invocations through the APIYI proxy for easier token usage tracking. Once the workflow is stable, upgrade to max or beast mode for serious research to avoid wasting high token costs due to initial configuration errors.
ARIS-Code Practical Workflow: From a Single Sentence to a Research Paper
What makes ARIS-Code truly impressive is its end-to-end /research-pipeline. This skill chains all the stages mentioned above into a single command. You only need to provide a research direction description, and the system will automatically output a first draft within 8–24 hours.
A typical call looks like this:
# Scenario 1: Brand new direction, starting from scratch
/research-pipeline "factorized gap in discrete diffusion LMs"
# Scenario 2: Improving an existing paper
/research-pipeline "improve method X" \
--ref-paper https://arxiv.org/abs/2406.04329 \
--base-repo https://github.com/org/project
# Scenario 3: Rebuttal only
/rebuttal "paper/ + reviews" --venue ICML --char-limit 5000
During actual execution, ARIS-Code follows a step-by-step process: literature review → idea generation → novelty check → experimental design → GPU scheduling → result collection → paper writing → citation audit → formatting and packaging. When it encounters ambiguous decision points, it pauses and waits for human checkpoints. With the default configuration --AUTO_PROCEED false, you can intervene manually after each round of reviewer feedback.
ARIS-Code also provides a very practical style-ref parameter. You can specify a reference paper for style (e.g., a historical best paper from the same conference), and the system will mimic its structure and narrative rhythm without copying specific paragraphs. For researchers aiming for a high acceptance rate, this is almost a "dimensional reduction attack," as the implicit requirements top-tier conference reviewers have for paper style are often harder to grasp than the content itself.
Another engineering detail worth noting is that ARIS-Code integrates with various external systems, including Overleaf bidirectional synchronization, W&B training curve monitoring, and Lark mobile push notifications. When your experiments on the GPU hit a key inflection point, you'll receive an immediate notification on your phone, truly achieving "doing research while you sleep."
📊 Performance Data: Three community paper cases published by the project author show that papers produced by ARIS-Code achieved AI review scores of 7-8/10 (CS conferences, AAAI 2026, IEEE TGRS). However, the author explicitly warns that human reviewers bring perspectives that AI review systems cannot capture, so it cannot completely replace human oversight.
ARIS-Code FAQ
Q1: Why can't ARIS-Code use GPT-5 as an Executor?
Because ARIS-Code is a fork iterated from the open-source version of Claude Code, its executor layer is strictly locked to the native Anthropic API protocol. This includes tool calling formats, streaming output formats, and chain-of-thought formats, all of which are deeply bound to Claude models. If you want to change the executor, you would need to switch to an OpenClaw or Codex CLI distribution, but that would no longer be the original ARIS-Code. We recommend accessing Claude models directly via apiyi.com, which is the most hassle-free solution.
Q2: How many tokens does it take to run a full paper?
In "beast" mode, running a full /research-pipeline consumes about 5 million to 15 million input + output tokens, which translates to a cost ranging from tens to hundreds of RMB in Claude Sonnet pricing. "Balanced" mode can reduce this to 2–5 million tokens. The specific cost depends on the complexity of the experiments and the number of iteration rounds.
Q3: Can I use ARIS-Code without a local GPU?
Absolutely. ARIS-Code is designed with two cloud GPU modes: "vast" and "modal." Modal even offers $30 in free credits, which is more than enough to run some lightweight experiments. If you are only working on theoretical papers (/proof-writer + /formula-derivation), you don't even need a GPU at all.
Q4: Does the Reviewer in the dual-model architecture have to be GPT-5.4?
Not necessarily. The project supports replacing it with any model compatible with the OpenAI protocol, such as GLM, MiniMax, or Kimi. We recommend using an aggregation platform like apiyi.com to obtain various candidate models for the Reviewer, making it easier to perform A/B testing to find the critical LLM best suited for your field. Some researchers have reported that Gemini 3 Pro performs surprisingly well as a Reviewer for mathematical reasoning papers, while GPT-5.4 remains the top choice for engineering optimization papers.
Q5: Is ARIS-Code suitable for undergraduates or beginners?
It is better suited for graduate students or those with some research experience. The reason is that the quality of its output depends heavily on the researcher's judgment of the field. For example, when a reviewer raises a counterexample, you need to determine whether it's a critical flaw or an irrelevant side issue. Those without experience can easily be led astray by the AI.
Q6: What should I do if the network is unstable when running ARIS-Code in China?
Connecting directly to the official Anthropic API often results in connection resets or timeouts in China, which can cause long-running /research-pipeline tasks to fail midway. A mature solution is to switch the ANTHROPIC_BASE_URL to an API proxy service deployed in a domestic IDC. This ensures that ARIS-Code can run continuously for 8 hours in "sleep" mode without being interrupted by network jitter, which is especially critical for continuous experiments in "beast" mode.
Summary
The emergence of ARIS-Code confirms a significant trend: research productivity tools in the era of Large Language Models are shifting from "point-based assistance" to "full-pipeline automation." Its Executor-Reviewer dual-model architecture, 42 workflow Skills, and zero-dependency Markdown design collectively form a highly mature methodological framework.
For researchers in China, the biggest hurdle to adopting ARIS-Code isn't the technical learning curve, but the stable invocation of Claude models. We recommend using the APIYI platform to access the Claude series, while simultaneously leveraging the GPT series for the Reviewer side. This way, a single platform can cover all model requirements for the entire ARIS-Code workflow, making expense settlement and log management much more convenient. Furthermore, the stability of domestic IDC nodes ensures that your "overnight experiment" scenarios won't be interrupted by network issues.
If you're preparing for a top-tier conference submission or have a research direction you're eager to validate but lack the time to iterate on manually, ARIS-Code is worth spending a weekend to explore. If you wake up to find a solid first draft waiting for you, that time investment will have been well worth it.
📌 Author: APIYI Team — Dedicated to AI Large Language Model API services and the developer ecosystem. For more case studies on Claude/GPT/Gemini multi-model integration, please visit the documentation center at apiyi.com.