Récemment, un projet open source sur GitHub nommé ARIS-Code a discrètement atteint plus de 8 400 étoiles et 783 forks. Développé par wanshuiyin à partir de la version open source de Claude Code, son nom complet est "Auto-Research-In-Sleep", ce qui signifie littéralement "faire de la recherche en dormant". Ce n'est pas qu'un argument marketing : il permet réellement à Claude Code d'exécuter automatiquement des expériences, de consulter la littérature et de modifier des articles pendant que vous dormez, vous permettant de progresser considérablement dans votre travail dès le lendemain matin.
Les discussions suscitées par ARIS-Code dans le milieu universitaire sont particulièrement dignes d'intérêt : les trois cas d'articles communautaires publiés par l'auteur montrent que les premières versions produites ont atteint des scores de 7 à 8/10 lors d'évaluations par IA, et ont déjà été soumises à des conférences de premier plan en informatique, à AAAI 2026 et à IEEE TGRS. Cela signifie que la recherche scientifique entièrement automatisée par IA n'est plus au stade de simple démonstration, mais est réellement capable de produire des manuscrits prêts à être soumis.
Cet article propose une analyse approfondie de l'architecture centrale d'ARIS-Code, de ses 42 compétences (Skills) intégrées, ainsi que de la manière de le connecter aux modèles Claude via un service proxy API tiers en Chine, afin de vous aider à déterminer si cet outil est adapté à votre flux de travail de recherche.
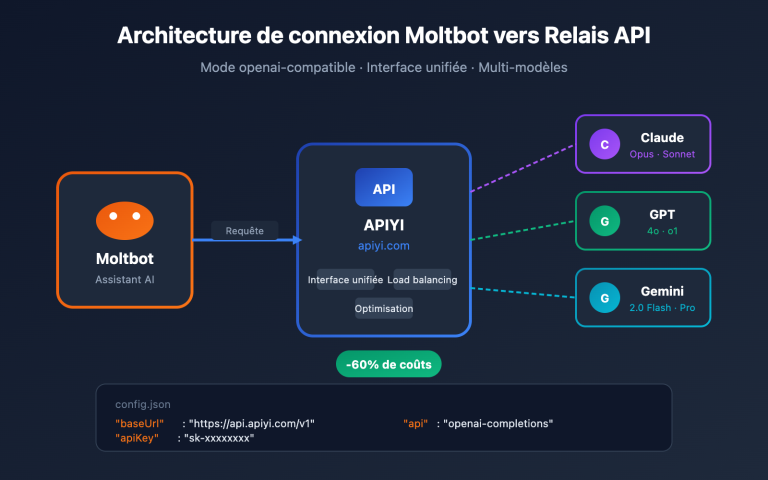
🎯 Note importante : Comme ARIS-Code est une itération basée sur la version open source de Claude Code, son exécuteur ne peut être connecté qu'aux modèles de la série Claude (Sonnet/Opus/Haiku). Il ne prend pas en charge les séries GPT ou Gemini comme exécuteur principal. Nous vous recommandons d'accéder aux modèles Claude via la plateforme APIYI (apiyi.com), qui est compatible avec le protocole natif d'Anthropic, offre un accès stable en Chine avec une facturation à l'usage, sans nécessiter de carte bancaire étrangère.
Qu'est-ce que le projet ARIS-Code : Auto-Research-In-Sleep ?
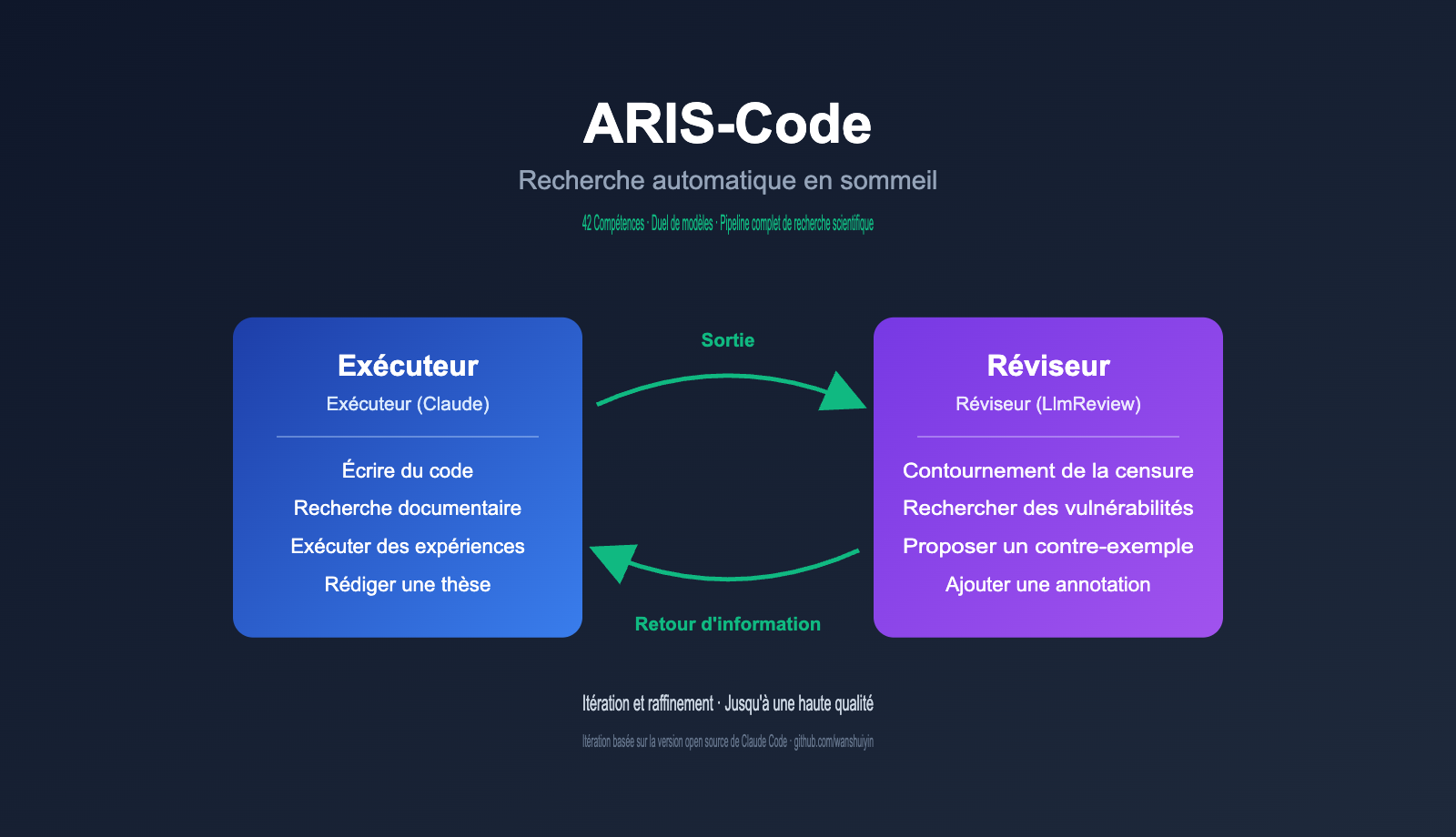
ARIS (Auto-Research-In-Sleep) est un système de flux de travail de recherche autonome destiné aux chercheurs en ML/IA. Le projet est disponible sur GitHub : github.com/wanshuiyin/Auto-claude-code-research-in-sleep. Son objectif est très clair : permettre aux chercheurs d'accomplir l'intégralité du processus — "revue de littérature → génération d'idées → exécution d'expériences → rédaction d'articles → réponse aux critiques" — avec un minimum d'intervention humaine, libérant ainsi les chercheurs des tâches répétitives.
ARIS-Code est essentiellement une bibliothèque de méthodologies. L'ensemble du système est composé de fichiers Markdown (SKILL.md) ; il n'y a aucun framework à installer, aucune base de données à maintenir, aucune configuration Docker requise. Chaque compétence (Skill) est une instruction de flux de travail lisible par n'importe quel agent LLM. Vous pouvez donc passer de l'exécuteur Claude Code à Codex CLI, OpenClaw, Cursor, Trae ou tout autre outil prenant en charge le mode Agent, et le flux de travail restera efficace.
Cette conception "zéro dépendance, zéro verrouillage" est la caractéristique principale qui distingue ARIS-Code des autres outils d'IA pour la recherche. Il s'agit fondamentalement de rendre le processus de recherche "explicite" sous forme d'ingénierie d'invite (prompt engineering) exécutable, plutôt que de l'encapsuler dans un outil boîte noire. C'est crucial pour les chercheurs, car cela signifie que le flux de travail est lisible, modifiable et transférable, sans être lié à un produit commercial spécifique.
Il convient de noter que le dépôt ARIS-Code a déjà accumulé 719 commits et que le projet continue d'évoluer rapidement. Au cours des trois derniers mois, plusieurs compétences à haute valeur ajoutée ont été ajoutées, telles que paper-talk (génération de présentations de conférence), resubmit-pipeline (flux de travail après rejet) et kill-argument (génération d'arguments contradictoires), rendant l'écosystème très dynamique.
Architecture fondamentale d'ARIS-Code : Le système de revue contradictoire Executor-Reviewer
La valeur technique la plus importante d'ARIS-Code réside dans son architecture contradictoire à deux modèles, ce qui le distingue fondamentalement des autres assistants de recherche sur le marché. L'auteur du projet souligne dans le README une observation très pertinente : l'auto-évaluation par un modèle unique présente des faiblesses structurelles. Lorsqu'un même modèle exécute une tâche et évalue son propre résultat, il reproduit systématiquement ses propres angles morts, tombant ainsi dans le piège de l'optimum local.
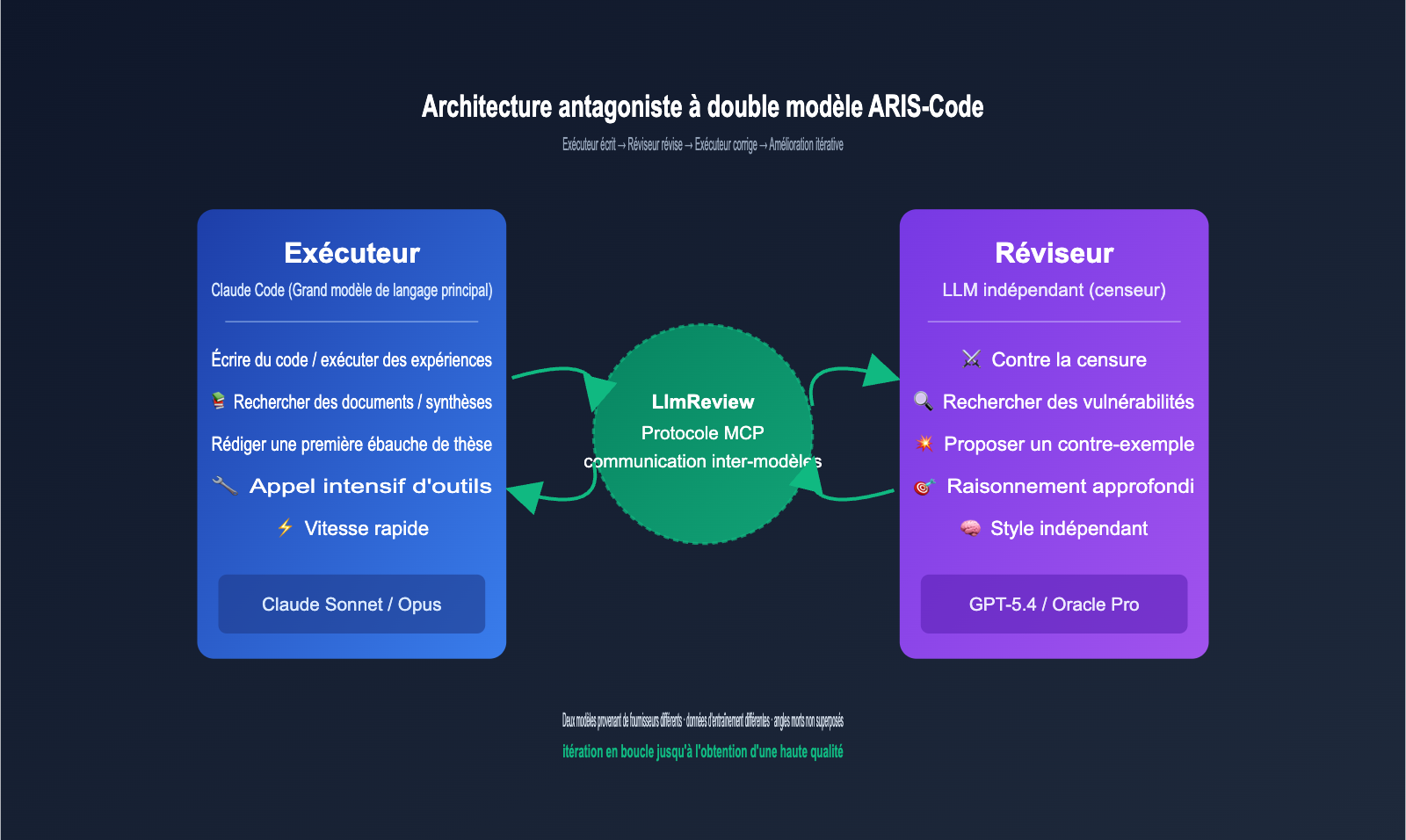
La solution proposée par ARIS-Code consiste à confier le pouvoir de revue à un modèle totalement indépendant. Voici la répartition des rôles :
| Rôle | Sélection du modèle | Responsabilité | Aptitudes recommandées |
|---|---|---|---|
| Executor (Exécuteur) | Claude Sonnet / Opus | Exécution principale : code, recherche biblio, expériences, rédaction | Vitesse, longue fenêtre de contexte, outils stables |
| Reviewer (Réviseur) | GPT-5.4 (Codex MCP) / Oracle Pro | Revue contradictoire : détection de failles, critique, contre-exemples | Raisonnement profond, esprit critique, style indépendant |
| Mécanisme de coordination | Chaîne d'outils LlmReview | Communication inter-modèles, persistance d'état | Transmission transparente via protocole MCP |
Le flux de travail se résume à une boucle simple : L'Executor écrit → Le Reviewer critique → L'Executor corrige → et ainsi de suite jusqu'à ce que le Reviewer valide. Cette boucle est efficace car les deux modèles proviennent de fournisseurs différents, possèdent des données d'entraînement distinctes et des styles de raisonnement variés, ce qui évite le chevauchement de leurs angles morts.
Pour éviter que les hallucinations des modèles ne polluent les conclusions scientifiques, ARIS-Code intègre une chaîne d'audit de preuves multicouche : experiment-audit (intégrité du code) → result-to-claim (résultats vers assertions) → paper-claim-audit (audit des assertions de l'article) → citation-audit (vérification des citations). Chaque couche génère un verdict JSON indépendant et un hash SHA256 pour assurer la reproductibilité, une rigueur technique rare dans les outils d'IA pour la recherche.
🔧 Conseil de configuration : Si vous souhaitez reproduire l'architecture à deux modèles d'ARIS-Code, nous vous recommandons d'utiliser APIYI (apiyi.com) pour obtenir simultanément vos clés API Claude et GPT. Une seule plateforme pour deux interfaces, sans avoir besoin de comptes étrangers ou de cartes bancaires internationales.
ARIS-Code : 42 Skills intégrés pour un pipeline de recherche complet
Ce qui impressionne le plus avec ARIS-Code, ce sont ses 42+ Skills intégrés. Il ne s'agit pas d'outils isolés, mais d'un véritable pipeline couvrant tout le cycle de vie de la recherche. Je les ai classés par étape :
| Étape du flux de travail | Skills représentatifs | Capacité principale |
|---|---|---|
| Découverte d'idées | research-lit / novelty-check / idea-creator / idea-discovery | Recherche multi-sources, vérification de nouveauté, génération d'idées |
| Expérimentation | experiment-bridge / experiment-queue / run-experiment | Revue de code → déploiement GPU → orchestration → gestion OOM |
| Revue automatique | auto-review-loop / research-review / experiment-audit | 4 cycles d'itération, revue par les pairs structurée, audit de code |
| Rédaction d'article | paper-writing / paper-claim-audit / proof-checker / citation-audit | Narration → LaTeX → PDF, audit d'assertions, vérification, citations |
| Réponse aux critiques | rebuttal | Analyse des commentaires → rédaction de réponse → tests |
| Méta-capacités | research-wiki / meta-optimize / deepxiv | Base de connaissances, optimisation, sources alternatives |
Le Skill le plus pratique est sans doute experiment-bridge, qui automatise tout le processus : "revue de code → déploiement distant GPU → lancement d'expérience → récupération des résultats". Lorsqu'un Reviewer suggère une "expérience d'ablation", l'Executor écrit automatiquement le script, le synchronise via rsync sur le nœud GPU, lance l'entraînement, surveille les logs et collecte les résultats, sans intervention manuelle.
Un autre point fort est le Skill citation-audit, qui élimine le problème majeur des hallucinations lors de la rédaction : les fausses citations. En se connectant aux bases de données DBLP et CrossRef, chaque BibTeX provient d'une source réelle. C'est une exigence académique fondamentale, car toute citation fictive peut entraîner un rejet immédiat.
Les chercheurs apprécient également research-wiki, une base de connaissances persistante qui accumule notes de lecture, brouillons d'idées et résultats d'expériences ratées entre plusieurs projets. Lorsque vous reprenez un sujet après trois mois, l'assistant a déjà conservé tout le contexte nécessaire.
💡 Conseil d'utilisation : L'appel à n'importe quel Skill consomme un grand nombre de jetons (tokens) Claude, surtout pour la rédaction d'articles. Nous vous conseillons d'utiliser APIYI (apiyi.com) pour accéder aux modèles Claude, car la plateforme permet un paiement à l'usage et offre un suivi complet de la consommation de jetons, idéal pour estimer le coût par article.
Configuration complète pour connecter ARIS-Code à APIYI
Comme l'exécuteur d'ARIS-Code est basé sur une itération de la version open source de Claude Code, il n'accepte que le protocole API natif d'Anthropic. Cela signifie que les modèles des séries GPT et Gemini ne peuvent pas être utilisés comme exécuteur. Il s'agit d'une contrainte technique stricte, et c'est souvent le point qui déroute le plus les développeurs lors de leur premier déploiement.
La configuration pour connecter les modèles Claude via APIYI est très simple et se résume en 5 étapes :
# Étape 1 : cloner le dépôt du projet
git clone https://github.com/wanshuiyin/Auto-claude-code-research-in-sleep
cd Auto-claude-code-research-in-sleep
# Étape 2 : installer les Skills dans le répertoire de configuration local de Claude Code
mkdir -p ~/.claude/skills/
cp -r skills/* ~/.claude/skills/
# Étape 3 : configurer l'adresse du service proxy APIYI (étape cruciale)
export ANTHROPIC_BASE_URL="https://vip.apiyi.com"
export ANTHROPIC_AUTH_TOKEN="Votre clé API APIYI"
# Étape 4 : lancer Claude Code
claude
# Étape 5 : invoquer n'importe quel Skill dans Claude Code
# Par exemple : /research-pipeline "factorized gap in discrete diffusion LMs"
L'étape la plus importante est la configuration de la variable d'environnement ANTHROPIC_BASE_URL à l'étape 3. Elle indique à Claude Code de ne pas interroger les points de terminaison officiels d'Anthropic, mais de passer par la passerelle de transfert. Cette passerelle est entièrement compatible avec le protocole natif d'Anthropic. Les Skills intégrés à ARIS-Code ne nécessitent aucune modification de code, et toutes les fonctionnalités, y compris l'invocation du modèle, la sortie en flux (streaming) et les chaînes de réflexion (thinking), sont transmises de manière transparente.
Si vous devez également déployer le côté Reviewer (Codex MCP), la procédure est la suivante :
# Installer Codex MCP pour le côté révision
npm install -g @openai/codex
codex setup # Vous pouvez également renseigner ici l'adresse du service proxy pour les modèles GPT
claude mcp add codex -s user -- codex mcp-server
Pour les chercheurs souhaitant reproduire fidèlement les résultats de l'article ARIS-Code, le projet propose également une solution Oracle MCP permettant de connecter GPT-5.4 Pro en tant que réviseur avancé. Cette solution est très utile lors de la phase finale de rédaction d'un article, car la profondeur critique et la capacité de construction de contre-exemples de la version Pro sont nettement supérieures à celles de la version de base.
🚀 Solution de connexion unifiée : La plateforme APIYI (apiyi.com) prend en charge simultanément les modèles des séries Claude (Sonnet 4.5/Opus 4), GPT (GPT-5/o4) et Gemini (Gemini 3 Pro). Une seule clé API suffit pour piloter à la fois l'exécuteur et le réviseur d'ARIS-Code, ce qui simplifie grandement la gestion des coûts et le suivi de l'invocation du modèle pour les équipes de recherche.
Niveaux d'effort ARIS-Code et stratégies de configuration GPU
ARIS-Code propose 4 niveaux d'effort pour équilibrer les coûts et la qualité, une conception très orientée ingénierie. Les exigences en matière de profondeur varient considérablement selon les étapes de la recherche : il n'est pas nécessaire de consommer des jetons lors de la phase d'exploration initiale, tandis que la phase de soumission d'un article exige une qualité maximale.
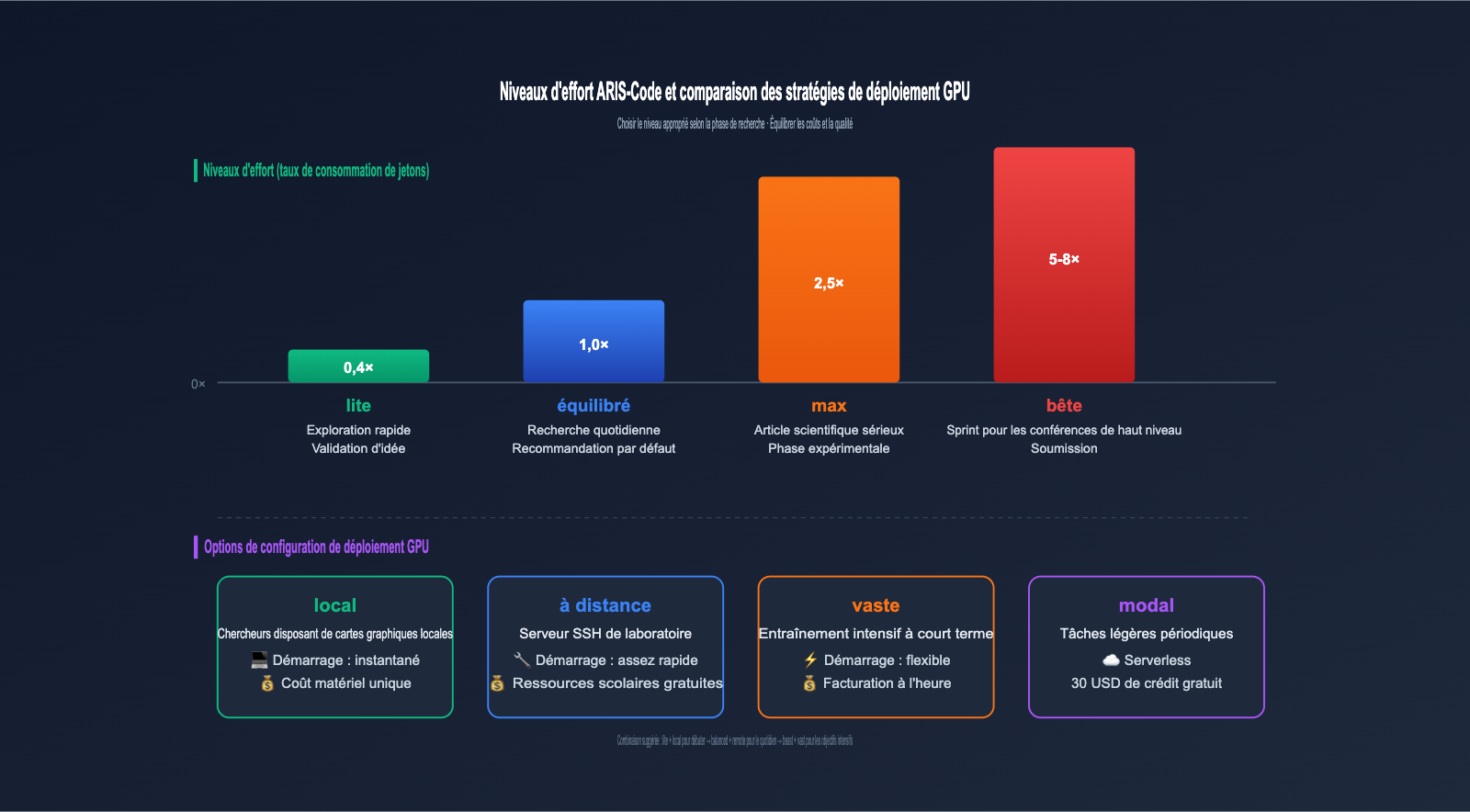
| Niveau d'effort | Multiplicateur de jetons | Scénarios d'application | Estimation par appel |
|---|---|---|---|
| lite | 0.4× | Exploration rapide, validation d'idées | Très faible |
| balanced | 1.0× | Flux de recherche quotidien par défaut | Standard |
| max | 2.5× | Phase d'expérimentation d'article sérieux | Moyen-élevé |
| beast | 5-8× | Sprint pour conférence, mode soumission | Élevé |
Pour le GPU, ARIS-Code propose également 4 options de configuration, adaptées aussi bien aux utilisateurs locaux qu'à ceux utilisant le cloud :
| Configuration GPU | Scénarios d'application | Caractéristiques de coût |
|---|---|---|
| local | Chercheurs disposant d'une carte graphique locale | Coût matériel unique |
| remote | Serveur SSH de laboratoire | Ressources universitaires gratuites |
| vast | Entraînement haute intensité à court terme | Facturation horaire, flexible |
| modal | Tâches légères périodiques | Serverless, 30 $ de crédit gratuit |
💰 Conseils de contrôle des coûts : Si vous commencez tout juste à utiliser ARIS-Code, il est recommandé de tester le flux avec lite + local, en passant par le service proxy apiyi.com pour faciliter le suivi de la consommation de jetons. Une fois le processus stabilisé, vous pourrez passer aux modes max ou beast pour vos recherches sérieuses, évitant ainsi de gaspiller des coûts de jetons élevés en raison d'erreurs de configuration initiales.
Workflow pratique ARIS-Code : d'une simple idée à un article scientifique
Ce qui rend ARIS-Code vraiment impressionnant, c'est son pipeline de bout en bout /research-pipeline. Ce Skill regroupe toutes les étapes précédentes en une seule commande. Il vous suffit de fournir une description de votre axe de recherche, et le système génère automatiquement une première ébauche en 8 à 24 heures.
Voici comment l'utiliser dans des scénarios classiques :
# Scénario 1 : Nouveau sujet, en partant de zéro
/research-pipeline "factorized gap in discrete diffusion LMs"
# Scénario 2 : Améliorer un article existant
/research-pipeline "improve method X" \
--ref-paper https://arxiv.org/abs/2406.04329 \
--base-repo https://github.com/org/project
# Scénario 3 : Uniquement pour le Rebuttal
/rebuttal "paper/ + reviews" --venue ICML --char-limit 5000
Lors de son exécution, ARIS-Code suit une procédure rigoureuse : revue de littérature → génération d'idées → vérification de la nouveauté → conception expérimentale → planification GPU → collecte des résultats → rédaction de l'article → audit des citations → mise en forme. En cas de décision ambiguë, le système se met en pause pour attendre une validation humaine. Par défaut, l'option --AUTO_PROCEED false vous permet d'intervenir manuellement après chaque retour des relecteurs.
ARIS-Code propose également un paramètre style-ref très pratique. Vous pouvez spécifier un article de référence pour le style (par exemple, le meilleur article historique d'une conférence donnée) : le système imitera sa structure et son rythme narratif, sans pour autant copier des passages spécifiques. Pour les chercheurs visant un taux d'acceptation élevé, c'est un avantage décisif, car les exigences implicites des relecteurs sur le style sont souvent plus difficiles à cerner que le contenu lui-même.
Un autre détail technique notable est l'intégration par ARIS-Code de la synchronisation bidirectionnelle avec Overleaf, du suivi des courbes d'entraînement avec W&B, et des notifications mobiles via Lark/Feishu. Lorsqu'une expérience sur GPU atteint un point critique, vous recevez une notification immédiate sur votre téléphone, permettant de "faire avancer la recherche même en dormant".
📊 Données de performance : Les 3 cas d'études communautaires publiés par l'auteur montrent que les articles générés par ARIS-Code ont obtenu des scores de 7-8/10 lors d'évaluations par IA (conférences CS, AAAI 2026, IEEE TGRS). Toutefois, l'auteur précise bien que les relecteurs humains apportent des perspectives que les systèmes d'évaluation par IA ne peuvent pas capturer, et qu'ils ne peuvent donc pas être totalement remplacés.
FAQ sur ARIS-Code
Q1 : Pourquoi ARIS-Code ne peut-il pas utiliser GPT-5 comme exécuteur ?
Parce qu'ARIS-Code est une évolution issue de la version open source de Claude Code. Sa couche d'exécution est entièrement verrouillée sur le protocole API natif d'Anthropic, incluant le format d'appel d'outils, le streaming et la chaîne de pensée, qui sont profondément liés aux modèles Claude. Pour changer d'exécuteur, il faudrait utiliser une distribution comme OpenClaw ou Codex CLI, mais il ne s'agirait plus de l'ARIS-Code original. Nous recommandons d'accéder aux modèles Claude via APIYI.com, c'est la solution la plus simple.
Q2 : Combien de jetons (tokens) faut-il pour un article complet ?
En mode "beast", un /research-pipeline complet consomme environ 5 à 15 millions de jetons (entrée + sortie), ce qui représente un coût en Claude Sonnet allant de quelques dizaines à quelques centaines d'euros. Le mode "balanced" permet de réduire cette consommation à 2-5 millions de jetons. Le coût réel dépend de la complexité des expériences et du nombre d'itérations.
Q3 : Peut-on utiliser ARIS-Code sans GPU local ?
Absolument. ARIS-Code a été conçu pour supporter les modes GPU cloud "vast" et "modal". Modal offre même 30 dollars de crédit gratuit, ce qui est largement suffisant pour des expériences légères. Si vous ne faites que des articles théoriques (/proof-writer + /formula-derivation), vous n'avez même pas besoin de GPU.
Q4 : Le relecteur (Reviewer) doit-il obligatoirement être GPT-5.4 dans l'architecture à double modèle ?
Ce n'est pas obligatoire. Le projet permet de remplacer ce modèle par n'importe quel modèle compatible avec le protocole OpenAI (GLM, MiniMax, Kimi, etc.). Nous suggérons d'utiliser une plateforme d'agrégation comme APIYI.com pour accéder à divers modèles de relecteurs, facilitant ainsi les tests A/B pour trouver l'IA critique la plus adaptée à votre domaine. Certains chercheurs rapportent que Gemini 3 Pro est étonnamment efficace comme relecteur pour les articles de raisonnement mathématique, tandis que GPT-5.4 reste le choix privilégié pour les articles d'optimisation technique.
Q5 : ARIS-Code est-il adapté aux étudiants de premier cycle ou aux débutants ?
Il est plutôt destiné aux étudiants diplômés ou aux chercheurs ayant une certaine expérience. La qualité de la sortie dépend fortement du jugement du chercheur sur son domaine. Par exemple, si un relecteur soulève un contre-exemple, vous devez être capable de juger s'il s'agit d'une faille critique ou d'un détail sans importance. Un utilisateur sans expérience risque d'être facilement induit en erreur par l'IA.
Q6 : Que faire si la connexion est instable lors de l'exécution d'ARIS-Code en Chine ?
Une connexion directe aux interfaces officielles d'Anthropic subit souvent des réinitialisations ou des délais d'attente, ce qui peut faire échouer les tâches longues de research-pipeline. Une solution éprouvée consiste à basculer ANTHROPIC_BASE_URL vers une passerelle proxy API déployée localement. Ainsi, ARIS-Code peut fonctionner en continu pendant 8 heures sans interruption due aux instabilités réseau, ce qui est crucial pour les expériences prolongées en mode "beast".
Résumé
L'émergence d'ARIS-Code confirme une tendance majeure : les outils de productivité scientifique à l'ère des grands modèles de langage passent de l'« assistance ponctuelle » à l'« automatisation complète des pipelines ». Son architecture à double modèle Executor-Reviewer, ses 42 compétences de flux de travail et sa conception Markdown sans dépendances forment un cadre méthodologique particulièrement abouti.
Pour les chercheurs, le principal obstacle à l'adoption d'ARIS-Code n'est pas la courbe d'apprentissage technique, mais la stabilité de l'invocation du modèle Claude. Nous recommandons de passer par la plateforme apiyi.com pour accéder à la gamme de modèles Claude, tout en utilisant les modèles GPT pour la partie Reviewer. Une seule plateforme permet ainsi de couvrir l'ensemble des besoins en modèles du flux de travail ARIS-Code, simplifiant grandement la gestion des coûts et la centralisation des journaux d'invocation. De plus, la stabilité des nœuds IDC locaux garantit que le scénario clé de « lancer des expériences pendant son sommeil » ne sera pas interrompu par des problèmes de réseau.
Si vous préparez une soumission pour une conférence de haut niveau, ou si vous avez une piste de recherche que vous souhaitez valider sans avoir le temps de l'itérer manuellement, ARIS-Code mérite que vous y consacriez un week-end. Si vous vous réveillez avec une première ébauche prête, cet investissement en temps sera largement rentabilisé.
📌 Auteur : APIYI Team — Spécialisé dans les services d'API pour grands modèles de langage et l'écosystème des développeurs. Pour plus d'exemples d'intégration de modèles Claude/GPT/Gemini, consultez le centre de documentation sur apiyi.com.