近期 GitHub 上一個名爲 ARIS-Code 的開源項目悄然衝上 8400+ Stars、783 Forks, 它由開發者 wanshuiyin 基於 Claude Code 開源版本迭代而來, 全名 Auto-Research-In-Sleep, 直譯就是"邊睡覺邊搞科研"。這並非營銷話術——它真的可以讓 Claude Code 在你睡覺時自動跑實驗、查文獻、改論文, 第二天醒來工作進度已經向前推了一大截。
ARIS-Code 在學術圈引起的討論尤其值得關注: 項目作者公佈的三個社區論文案例顯示, 它產出的初稿在 AI 評審分數上達到了 7-8/10 的水平, 已經分別投遞到 CS 頂級會議、AAAI 2026 和 IEEE TGRS。這意味着 AI 全自動科研已經不只是 demo 級別, 而是真正具備產出投稿稿件的能力。
本文將深度拆解 ARIS-Code 的核心架構、42 個內置 Skills, 以及它在國內環境通過第三方中轉服務接入 Claude 模型的具體方式, 幫你判斷這個工具是否適合你的科研工作流。
🎯 特別提示: 由於 ARIS-Code 是基於 Claude Code 開源版迭代而來, 它的執行器只能接入 Claude 系列模型 (Sonnet/Opus/Haiku), 不支持 GPT、Gemini 系列作爲主執行器。我們建議通過 API易 apiyi.com 平臺接入 Claude 模型, 該平臺兼容 Anthropic 原生協議, 國內訪問穩定且按量計費, 不需要海外信用卡。
什麼是 ARIS-Code: Auto-Research-In-Sleep 項目
ARIS (Auto-Research-In-Sleep) 是一個面向 ML/AI 學術研究者的自主科研工作流系統, 項目地址在 GitHub: github.com/wanshuiyin/Auto-claude-code-research-in-sleep。它的設計目標非常明確: 讓研究者在最小人工干預下完成"文獻綜述 → 想法生成 → 實驗執行 → 論文撰寫 → Rebuttal 應對"的全流程, 把研究者從重複性體力勞動中解放出來。
ARIS-Code 的本質是一個 方法論庫, 整套系統由純 Markdown 文件 (SKILL.md) 組成, 沒有需要安裝的框架、沒有需要維護的數據庫、沒有需要配置的 Docker。每一個 Skill 都是一份可被任意 LLM Agent 閱讀的工作流說明, 因此你可以把執行器從 Claude Code 切換到 Codex CLI、OpenClaw、Cursor、Trae 等任意支持 Agent 模式的工具, 工作流依然有效。
這種"零依賴、零鎖定"的設計是 ARIS-Code 區別於其他科研 AI 工具的最大特色, 它本質上是把科研流程"顯式化"成可執行的提示詞工程, 而不是封裝成黑盒工具。這一點對於研究者來說意義重大, 因爲它意味着工作流是可閱讀、可修改、可遷移的, 而不是被某個商業產品綁死。
值得一提的是, ARIS-Code 倉庫已經積累了 719 commits, 項目仍在高速迭代中。最近三個月新增了 paper-talk (會議講稿生成)、resubmit-pipeline (拒稿後再投流水線)、kill-argument (對抗性反駁生成) 等多個高價值 Skill, 整個生態非常活躍。
ARIS-Code 核心架構: Executor-Reviewer 雙模型對抗式審查
ARIS-Code 最關鍵的工程價值在於它的 雙模型對抗式架構, 這是它和市面上其他科研助手最本質的差異。項目作者在 README 中提出了一個非常深刻的觀察: 單模型自審存在結構性弱點, 因爲同一個模型既執行任務又評審輸出時, 它會系統性地復現自己的盲區, 形成局部最優陷阱。

ARIS-Code 給出的解法是把審查權交給一個完全獨立的模型。具體角色劃分如下:
| 角色 | 模型選型 | 職責定位 | 推薦能力傾向 |
|---|---|---|---|
| Executor (執行者) | Claude Sonnet / Opus | 主力執行: 寫代碼、查文獻、跑實驗、起草論文 | 速度快、長上下文、工具調用穩定 |
| Reviewer (審查者) | GPT-5.4 (Codex MCP) / Oracle Pro | 對抗審查: 找漏洞、質疑結論、提出反例 | 推理深、批判性強、風格獨立 |
| 協調機制 | LlmReview 工具鏈 | 跨模型通信、狀態持久化 | MCP 協議透明傳遞 |
整個工作流可以概括爲一個簡單的循環: Executor 寫 → Reviewer 批 → Executor 修 → 再批再修, 直至 Reviewer 給出通過判定。這個循環之所以有效, 是因爲兩個模型來自不同廠商、訓練數據不同、推理風格不同, 它們的盲區不會重疊。
爲了防止 LLM 幻覺污染科研結論, ARIS-Code 還設計了多層證據審計鏈: experiment-audit (代碼完整性) → result-to-claim (結果到斷言) → paper-claim-audit (論文斷言審計) → citation-audit (引用覈實)。每一層都有獨立的 JSON verdict 和 SHA256 哈希用於復現驗證, 這種工程嚴謹性在科研 AI 工具中相當罕見。
🔧 配置建議: 如果你想完整復現 ARIS-Code 的雙模型架構, 在國內環境推薦通過 API易 apiyi.com 同時獲取 Claude 與 GPT 系列模型 Key, 一個平臺對應兩套接口, 不需要分別開通海外賬戶和綁定信用卡。
ARIS-Code 內置 42 個 Skills 全科研流水線
ARIS-Code 最讓人印象深刻的是它內置的 42+ 個 Skills, 這些 Skill 不是孤立的小工具, 而是一條覆蓋完整科研生命週期的流水線。我把它們按工作流階段歸類如下:
| 工作流階段 | 代表 Skills | 核心能力 |
|---|---|---|
| 選題階段 (Idea Discovery) | research-lit / novelty-check / idea-creator / idea-discovery | 多源文獻檢索、跨模型新穎性驗證、8-12 個候選想法生成 |
| 實驗階段 (Experimentation) | experiment-bridge / experiment-queue / run-experiment | 代碼評審 → GPU 部署 → 多種子編排 → OOM 自動處理 |
| 自動評審 (Auto Review) | auto-review-loop / research-review / experiment-audit | 4 輪迭代改進、結構化同行評審、代碼完整性驗證 |
| 論文寫作 (Paper Writing) | paper-writing / paper-claim-audit / proof-checker / citation-audit | 敘事 → LaTeX → PDF、斷言審計、證明校驗、引用覈實 |
| Rebuttal 應對 | rebuttal | 審稿意見解析 → 回覆起草 → 壓力測試 |
| 元能力 | research-wiki / meta-optimize / deepxiv | 持久知識庫、外環優化、替代文獻源 |
最具實戰價值的 Skill 是 experiment-bridge, 它把"代碼評審 → GPU 遠程部署 → 實驗啓動 → 結果回收"打通成一條流水線。當 Reviewer 提出"這裏需要做一個消融實驗"時, Executor 會自動寫腳本、rsync 到 GPU 節點、啓動訓練、監控日誌、收集結果, 整個過程不需要研究者手動介入。
另一個值得關注的是 citation-audit 這個 Skill, 它通過對接 DBLP 和 CrossRef 真實數據庫消除了 LLM 寫論文時最大的痛點——引用幻覺。每一條 BibTeX 都來自真實數據庫, 而不是模型自己編造。這對於學術寫作來說是底線要求, 任何一處虛構引用都可能導致投稿被直接拒稿。
研究者還特別欣賞 research-wiki 這個跨會話持久知識庫, 它會在多個項目之間累積研究者的論文閱讀筆記、想法草稿、失敗實驗記錄, 形成一個不斷生長的私人科研記憶體。當你三個月後回到某個擱置的方向時, 不需要重新讀一遍所有相關論文, AI 助手已經替你保留了上下文。
💡 使用提示: 調用任意一個 Skill 時, 都會消耗大量 Claude API Token, 尤其是 paper-writing 這種長文本生成任務。我們建議通過 apiyi.com 接入 Claude 模型, 該平臺支持按量計費且提供完整的 token 用量監控, 便於你預估單篇論文的成本。
ARIS-Code 接入 API易 的完整配置方案
由於 ARIS-Code 的執行器是基於 Claude Code 開源版迭代而來, 它只接受 Anthropic 原生 API 協議, 這意味着 GPT、Gemini 系列模型無法作爲 Executor 使用。這是一個硬性約束, 也是很多開發者第一次部署時的最大困惑點。
通過 API易 接入 Claude 模型的配置步驟非常簡潔, 整個過程可以歸納爲 5 步:
# 第 1 步: clone 項目倉庫
git clone https://github.com/wanshuiyin/Auto-claude-code-research-in-sleep
cd Auto-claude-code-research-in-sleep
# 第 2 步: 安裝 Skills 到本地 Claude Code 配置目錄
mkdir -p ~/.claude/skills/
cp -r skills/* ~/.claude/skills/
# 第 3 步: 配置 API易 中轉地址 (核心步驟)
export ANTHROPIC_BASE_URL="https://vip.apiyi.com"
export ANTHROPIC_AUTH_TOKEN="你的 API易 Key"
# 第 4 步: 啓動 Claude Code
claude
# 第 5 步: 在 Claude Code 中調用任意 Skill 即可
# 例如: /research-pipeline "factorized gap in discrete diffusion LMs"
這裏最關鍵的是第 3 步設置 ANTHROPIC_BASE_URL 環境變量, 它告訴 Claude Code 不要請求 Anthropic 官方端點, 而是去中轉網關。該網關的接口完全兼容 Anthropic 原生協議, ARIS-Code 內置的 Skill 不需要做任何代碼修改, 包括工具調用、流式輸出、思考鏈 (thinking) 在內的所有特性都能透明傳遞。
如果你還需要部署 Reviewer 端 (Codex MCP), 流程是:
# 安裝 Codex MCP 用於審查端
npm install -g @openai/codex
codex setup # 這裏同樣可以填中轉地址用於 GPT 模型
claude mcp add codex -s user -- codex mcp-server
對於希望完全復現 ARIS-Code 論文級別效果的研究者, 項目還提供了 Oracle MCP 接入 GPT-5.4 Pro 作爲高級 Reviewer 的方案。這個方案在嚴肅論文衝刺階段非常有用, 因爲 Pro 版本的批判深度和反例構造能力相比基礎版有明顯提升。
🚀 統一接入方案: API易 apiyi.com 平臺同時支持 Claude 系列 (Sonnet 4.5/Opus 4)、GPT 系列 (GPT-5/o4)、Gemini 系列 (Gemini 3 Pro) 等主流模型, 一個 Key 即可同時驅動 ARIS-Code 的 Executor 和 Reviewer 兩端, 這對於科研團隊的費用管理和調用記錄歸集非常友好。
ARIS-Code Effort Levels 與 GPU 配置策略
ARIS-Code 提供了 4 檔 Effort Level 用於平衡成本和質量, 這是它非常工程化的一個設計。不同的研究階段對深度的要求差異巨大, 早期探索階段沒必要燒 token, 投稿衝刺階段則需要把質量推到極致。
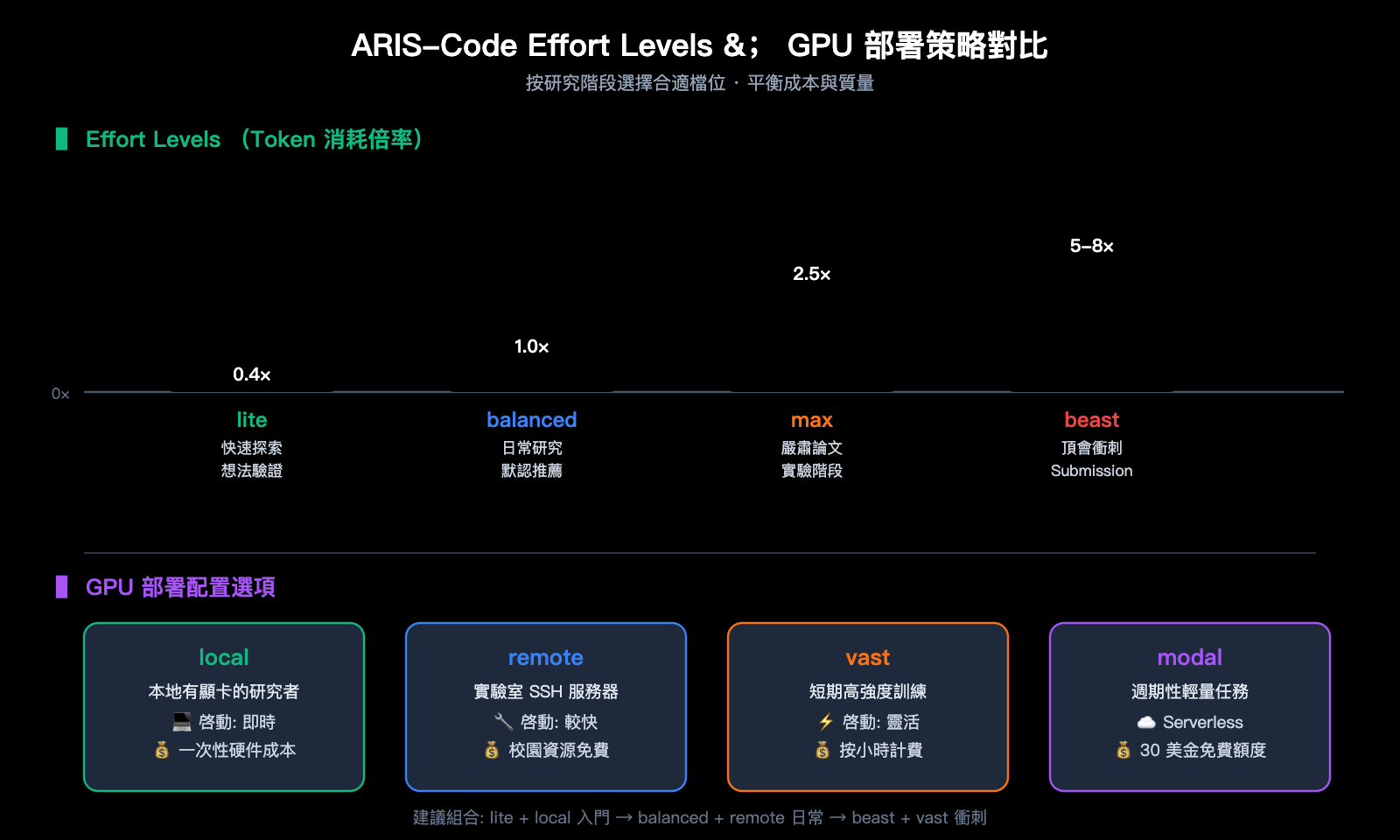
| Effort Level | Token 倍率 | 適用場景 | 單次調用預估 |
|---|---|---|---|
| lite | 0.4× | 快速探索、想法驗證 | 極低 |
| balanced | 1.0× | 默認日常研究流程 | 標準 |
| max | 2.5× | 嚴肅論文實驗階段 | 中高 |
| beast | 5-8× | 頂會衝刺、Submission Mode | 高 |
GPU 端 ARIS-Code 也給出了 4 種配置選項, 兼顧本地黨和雲上黨:
| GPU 配置 | 適用場景 | 成本特點 |
|---|---|---|
| local | 本地有顯卡的研究者 | 一次性硬件成本 |
| remote | 實驗室 SSH 服務器 | 校園資源免費 |
| vast | 短期高強度訓練 | 按小時計費, 靈活 |
| modal | 週期性輕量任務 | Serverless, 30 美金免費額度 |
💰 成本控制建議: 如果你剛開始嘗試 ARIS-Code, 建議先用 lite + local 跑通流程, 把模型調用走 apiyi.com 中轉便於覈算 token 用量。等流程穩定後再升級到 max 或 beast 模式做嚴肅研究, 這樣可以避免初期因配置失誤浪費高昂的 token 成本。
ARIS-Code 實戰工作流: 從一句話到一篇論文
ARIS-Code 最讓人驚豔的是它的端到端管線 /research-pipeline, 這個 Skill 把上面所有階段串成一條命令。你只需要給一個研究方向描述, 系統會自動在 8-24 小時內輸出一份初稿。
典型的調用方式是這樣:
# 場景 1: 全新方向, 從零開始
/research-pipeline "factorized gap in discrete diffusion LMs"
# 場景 2: 改進現有論文
/research-pipeline "improve method X" \
--ref-paper https://arxiv.org/abs/2406.04329 \
--base-repo https://github.com/org/project
# 場景 3: 僅 Rebuttal
/rebuttal "paper/ + reviews" --venue ICML --char-limit 5000
實際運行時 ARIS-Code 會按部就班地走完: 文獻綜述 → 想法生成 → 新穎性檢查 → 實驗設計 → GPU 調度 → 結果回收 → 論文撰寫 → 引用審計 → 格式打包。當遇到模糊決策點時, 它會暫停並等待人工 checkpoint, 默認配置下 --AUTO_PROCEED false 可以讓你在每一輪 Reviewer 反饋後人工介入。
ARIS-Code 還提供了一個非常實用的 style-ref 參數, 你可以指定一篇風格參考論文 (例如同一會議歷史最佳論文), 系統會模仿其結構組織和敘事節奏, 但不會複製具體段落。這對於追求"投稿命中率"的研究者來說幾乎是降維打擊, 因爲頂會評審對論文風格的隱性要求往往比內容本身更難拿捏。
另一個值得注意的工程細節是, ARIS-Code 集成了 Overleaf 雙向同步、W&B 訓練曲線監控、飛書/Lark 移動端推送等多種外部系統。當 GPU 上的實驗跑出關鍵拐點時, 你能在手機上立即收到通知, 真正實現"睡着也在跑研究"。
📊 性能數據: 項目作者公佈的 3 個社區論文案例顯示, ARIS-Code 產出的論文在 AI 評審分數上達到了 7-8/10 (CS 會議、AAAI 2026、IEEE TGRS), 但作者也明確提示人類審稿人會帶來 AI 審稿系統捕捉不到的視角, 不能完全替代人工把關。
ARIS-Code 常見問題 FAQ
Q1: ARIS-Code 爲什麼不能用 GPT-5 當 Executor?
因爲 ARIS-Code 是從 Claude Code 開源版本 fork 迭代而來, 它的執行器層完全鎖定在 Anthropic 原生 API 協議上, 包括工具調用格式、流式輸出格式、思考鏈格式都和 Claude 模型深度綁定。如果想換執行器, 需要改用 OpenClaw 或者 Codex CLI 的發行版, 但那已經不是原版 ARIS-Code 了。我們建議通過 apiyi.com 直接接入 Claude 模型, 是最省事的方案。
Q2: 跑一篇完整論文大概需要多少 Token?
beast 模式下完整跑一遍 /research-pipeline 大約消耗 500 萬到 1500 萬 input + output token, 折算 Claude Sonnet 價格在幾十到幾百元區間。balanced 模式可以降低到 200-500 萬 token。具體費用取決於實驗複雜度和迭代輪次。
Q3: 沒有本地 GPU 也能用 ARIS-Code 嗎?
完全可以。ARIS-Code 設計了 vast 和 modal 兩種雲 GPU 模式, modal 還有 30 美金免費額度, 跑一些輕量級實驗綽綽有餘。如果只做理論論文 (/proof-writer + /formula-derivation), 甚至完全不需要 GPU。
Q4: 雙模型架構裏 Reviewer 一定要用 GPT-5.4 嗎?
不強制。項目支持替換爲 GLM、MiniMax、Kimi 等任何兼容 OpenAI 協議的模型。我們建議通過 apiyi.com 這類聚合平臺獲取多種 Reviewer 候選模型, 便於做 A/B 測試找到最適合你領域的批判性 LLM。一些研究者反饋, 在數學推理類論文上 Gemini 3 Pro 作爲 Reviewer 效果意外地好, 在工程優化類論文上 GPT-5.4 仍是首選。
Q5: ARIS-Code 適合本科生或者初學者嗎?
更適合有一定科研經驗的研究生及以上羣體。原因是它的輸出質量很大程度依賴於研究者對領域的判斷力, 比如 Reviewer 提出某個反例時, 你需要判斷這是不是真的關鍵漏洞還是無關的枝節問題。完全無經驗者容易被 AI 帶偏方向。
Q6: 在國內運行 ARIS-Code 網絡不穩定怎麼辦?
直連 Anthropic 官方接口在國內確實經常出現連接重置或超時, 這會讓長時間的 research-pipeline 任務在中途失敗。一種成熟的解決方案是把 ANTHROPIC_BASE_URL 切換到國內 IDC 部署的中轉網關, 這樣 ARIS-Code 在睡覺模式下連續運行 8 小時也不會因爲網絡抖動而中斷, 這對於 beast 模式的連續實驗尤其關鍵。
總結
ARIS-Code 的出現驗證了一個重要趨勢: 大模型時代的科研生產力工具正在從"單點輔助"走向"全流水線自動化"。它的 Executor-Reviewer 雙模型架構、42 個工作流 Skills、零依賴的 Markdown 設計, 共同構成了一個非常成熟的方法論框架。
對於國內研究者來說, 接入 ARIS-Code 最大的門檻不是技術學習曲線, 而是 Claude 模型的穩定調用。我們建議通過 apiyi.com 平臺接入 Claude 系列模型, 同時獲取配套的 GPT 系列模型用於 Reviewer 端, 這樣一個平臺就能覆蓋整個 ARIS-Code 工作流的模型需求, 在費用結算和調用日誌歸集上都更省心。同時國內 IDC 節點的穩定性也保證了"睡覺跑實驗"這個核心場景不會因爲網絡問題中斷。
如果你正在準備頂會投稿, 或者有一個想驗證但又沒時間手動迭代的研究方向, ARIS-Code 值得花一個週末認真試一試——醒來時如果真的能看到一份初稿, 這個時間投資就太划算了。
📌 作者: APIYI Team — 長期關注 AI 大模型 API 服務與開發者生態, 更多 Claude/GPT/Gemini 多模型接入案例參見 apiyi.com 文檔中心。