In 2026, the landscape for code-focused Large Language Models is being split by two distinct product archetypes. On one side, we have the "IDE-first, high-frequency completion" contenders, represented by Mistral Codestral 2 (the latest version, Codestral 25.08). These models focus on Fill-in-the-Middle (FIM) capabilities, high-accuracy completions, and near-instant responses across 80+ programming languages. On the other side are the "long-range agent" contenders, represented by Zhipu GLM-5.1, which leverage a 744B parameter MoE architecture and a 200K context window to dominate SWE-Bench Pro-level complex tasks, such as "8-hour autonomous engineering assignments."
These two paths target different user bases and billing strategies, yet they are frequently compared when developers ask, "Which one is better for coding?" This article draws from primary English sources, including the official Mistral AI announcement (2025-07-30, Codestral 25.08) and Z.ai developer documentation (GLM-5.1, released 2026-03-27). We’ll break down the differences across six dimensions—architecture, benchmarks, context, long-range tasks, deployment, and pricing—to provide a reproducible decision matrix, complete with API integration code to help you make a choice in under 10 minutes.

Core Positioning Differences: Codestral 2 vs. GLM-5.1
Before we dive into the benchmarks, we need to clarify one thing: these two models belong to entirely different product categories. Comparing them on the same scale can lead to misleading conclusions.
Positioning at a Glance
- Codestral 2 (25.08): A specialized code model designed for code completion and editing tasks. It features a 22B dense architecture and native FIM training, emphasizing "sub-second response + high acceptance rate." It is a de facto standard for IDE Copilot-style products.
- GLM-5.1: A flagship general-purpose model designed for autonomous agents and long-range programming tasks. It uses a 744B MoE architecture (activating ~40B parameters per token) and a 200K context window. It achieved a score of 58.4 on SWE-Bench Pro, outperforming GPT-5.4, Claude Opus 4.6, and Gemini 3.1 Pro.
Three Questions to Answer Before Choosing
| Question | Lean towards Codestral 2 | Lean towards GLM-5.1 |
|---|---|---|
| Is your primary use case IDE completion or autonomous PR creation? | IDE completion | Multi-step autonomous tasks |
| Is your token volume per request in the tens or tens of thousands? | Tens to thousands | Thousands to tens of thousands |
| Can you tolerate a latency of several seconds? | No | Yes |
🎯 Selection Advice: If 80% of your model invocations are for "next-line completion while typing," go with Codestral 2. If 80% of your invocations are for "help me fix this bug in the repo," go with GLM-5.1. You can test both models in parallel using the unified interface provided by APIYI (apiyi.com), so there's no need to integrate Mistral and Z.ai separately.
title: "Comparing the Architecture and Parameters of Codestral 2 and GLM-5.1"
description: "A technical breakdown comparing Codestral 2 and GLM-5.1 architectures, performance benchmarks, and deployment considerations."
tags: [AI, Codestral 2, GLM-5.1, LLM, Benchmarking]
Architectural differences are the root cause of all subsequent performance variations.
Key Specifications at a Glance
| Feature | Codestral 2 (25.08) | GLM-5.1 |
|---|---|---|
| Developer | Mistral AI | Zhipu AI (Z.ai) |
| Architecture | Dense Transformer | Mixture-of-Experts |
| Total Parameters | 22B | 744B |
| Active Parameters | 22B | ~40B (256 experts, 8 active per token) |
| Context Window | 256K | 200K |
| Max Output | Standard | 128K tokens |
| Attention Mechanism | Standard + FIM optimization | DeepSeek Sparse Attention |
| License | Mistral Commercial License / MNPL | MIT (Open Weights) |
| Release Date | 2025-07-30 (Latest iteration) | 2026-03-27 |
| Code Language Coverage | 80+ mainstream languages | General multilingual |
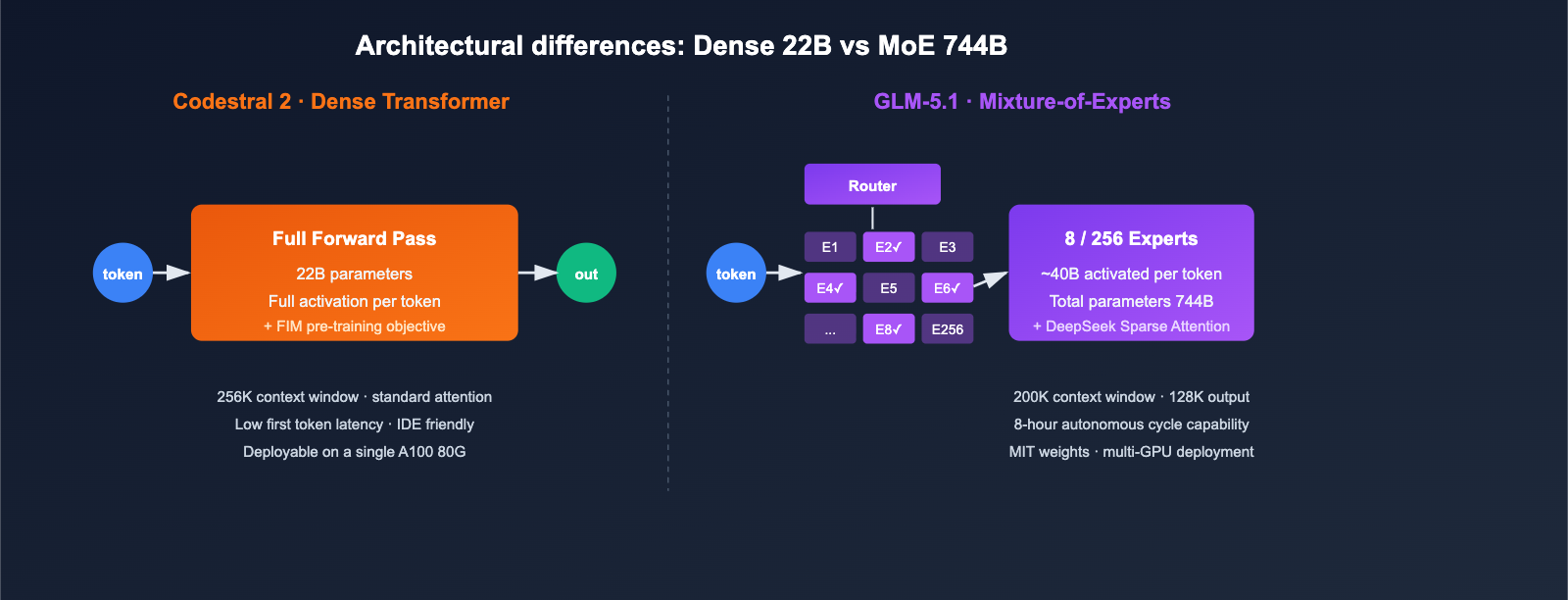
Direct Impact of Architectural Differences
- VRAM and Deployment Costs: Codestral 2 (22B) can perform inference on a single machine (A100 80G); GLM-5.1 requires multi-GPU parallelism or managed inference services.
- Per-token Latency: Codestral 2's dense architecture offers more stable latency for short inputs; GLM-5.1 is slightly slower on the first token due to router selection and sparse attention, but it holds an advantage for long sequences.
- Open Source Strategy: GLM-5.1 releases weights under the MIT license, making it more friendly for private deployment and fine-tuning; while Codestral 2 can run locally, commercial use requires a license.
🎯 Deployment Advice: Teams requiring fully private deployment should prioritize GLM-5.1's MIT-licensed weights. For teams that want quick access without managing self-hosting, you can call both model APIs directly via APIYI (apiyi.com), saving you the hassle of procurement and licensing negotiations.
Codestral 2 vs GLM-5.1 Core Code Benchmark Comparison
Both models' scores come from vendor self-testing, and the evaluation sets do not overlap entirely. Below are only the metrics with direct comparative significance.
Codestral 2 Strengths: Completion Quality & IDE Metrics
| Metric | Value | Description |
|---|---|---|
| Accepted Completions | +30% (vs 25.01) | IDE adoption rate in production |
| Retained Code | +10% | Proportion of suggested code not deleted upon commit |
| Runaway Generations | -50% | Reduction in useless, overly long continuations |
| IFEval v8 (Instruction Following) | +5% | Instruction accuracy |
| MultiPL-E Average Score | +5% | Multilingual coding capability |
| HumanEval (Previous 25.01 data) | 86.6% | Reference data |
| MBPP (Previous 25.01 data) | 91.2% | Reference data |
GLM-5.1 Strengths: Complex Engineering Tasks
| Metric | Value | Description |
|---|---|---|
| SWE-Bench Pro | 58.4 | Surpasses GPT-5.4 / Claude Opus 4.6 / Gemini 3.1 Pro |
| Claude Code Comparison | 45.3 (Opus 4.6 is 47.9) | Reaches 94.6% of Opus 4.6 |
| vs GLM-5 Baseline | +28% | Result of post-training optimization |
| KernelBench Level 3 | 3.6x speedup | ML kernel optimization scenarios |
| Single Task Duration | Up to 8 hours | Autonomous "experiment-analyze-optimize" loop |
Capability Overlap Assessment
| Capability | Codestral 2 | GLM-5.1 |
|---|---|---|
| Single-file completion | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| Multi-file refactoring | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| Bug location + Fix PR | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| Cross-language translation | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Agent / Tool Use | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| First-token latency | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
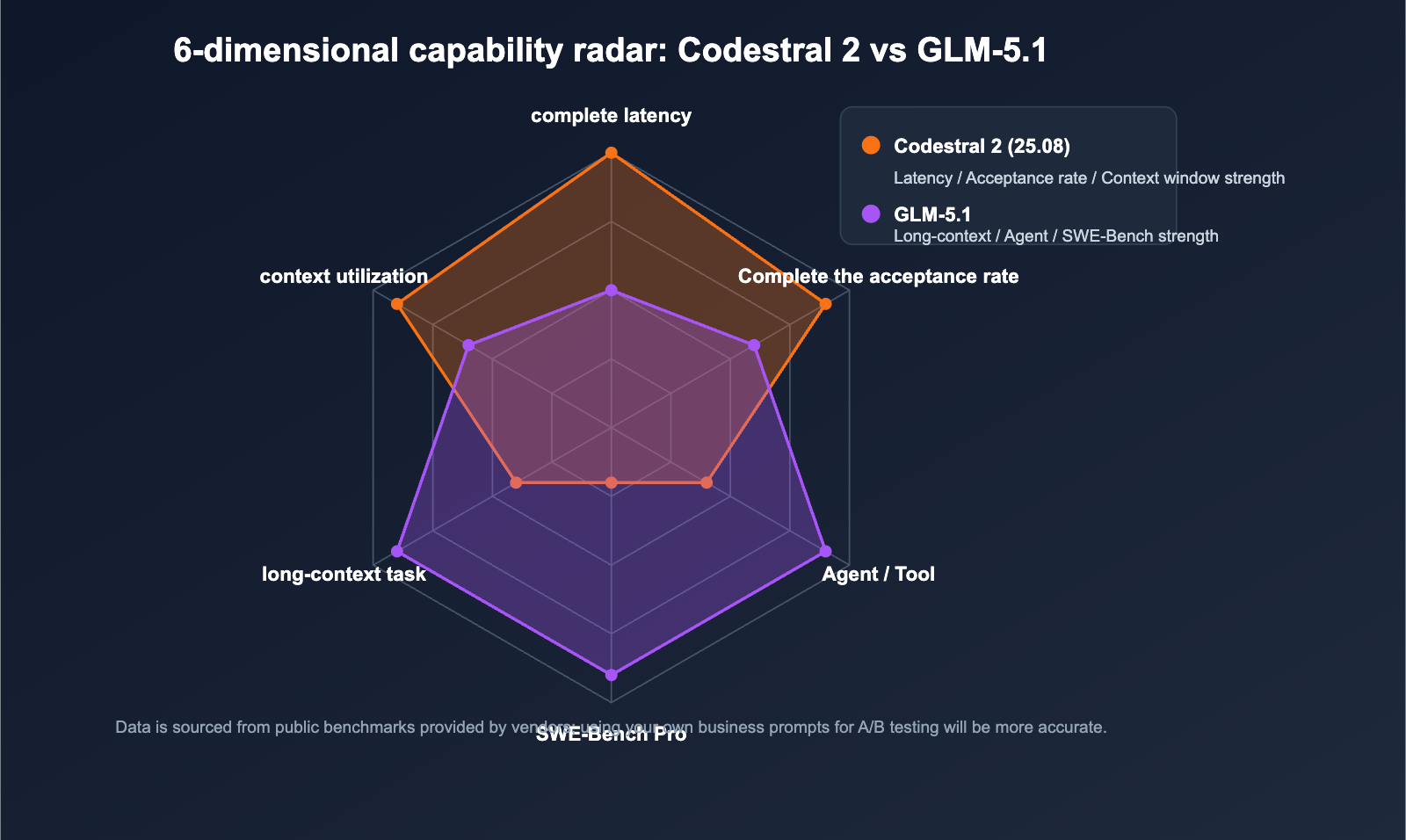
🎯 Benchmark Reading Tip: Official data usually comes from relatively optimal evaluation settings; actual business performance may fluctuate by 10%–20%. We recommend running an A/B test on your own codebase via APIYI (apiyi.com) before making a final decision.
Codestral 2 vs. GLM-5.1: Context Windows and Long-Range Task Capabilities
While 256K and 200K context windows might look similar on paper, they are designed for fundamentally different types of tasks.
Codestral 2's 256K Context: Full-Repository Completion
Codestral 2 primarily uses its 256K context to "stuff the entire codebase into the prompt," allowing it to maintain awareness of cross-file dependencies during code completion:
- Best for: Completing large functions within a monorepo, project-wide lint fixes, and cross-module refactoring.
- Not ideal for: Agent workflows that require multi-step reasoning, tool invocation, and iterative result writing.
GLM-5.1's 200K Context + 8-Hour Autonomous Loop
The breakthrough with GLM-5.1 isn't just about "how much context it can hold," but rather "how long it can work autonomously":
- In official demos, the model can iterate through hundreds of steps within a single task: run benchmark → identify bottlenecks → adjust strategy → re-run benchmark.
- DeepSeek Sparse Attention keeps the inference costs for 200K long sequences within a practical, usable range.
- When paired with Function Calling / MCP, it can directly interface with external toolchains.
Long-Range Task Comparison
| Task | Codestral 2 | GLM-5.1 |
|---|---|---|
| Complete a 200-line function | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Generate a PR from a GitHub Issue | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| Find and fix bugs across the entire repo | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| Multi-round automated ML kernel tuning | ⭐ | ⭐⭐⭐⭐⭐ |
| Tab-completion in the IDE | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
🎯 Migration Tip: If your team has been using Codestral for full-repo completion but finds that the code "completes but fails tests," try letting GLM-5.1 take over the "generate-run-fix" loop. You can reuse your existing OpenAI-compatible code by simply switching the
base_urlvia APIYI (apiyi.com).
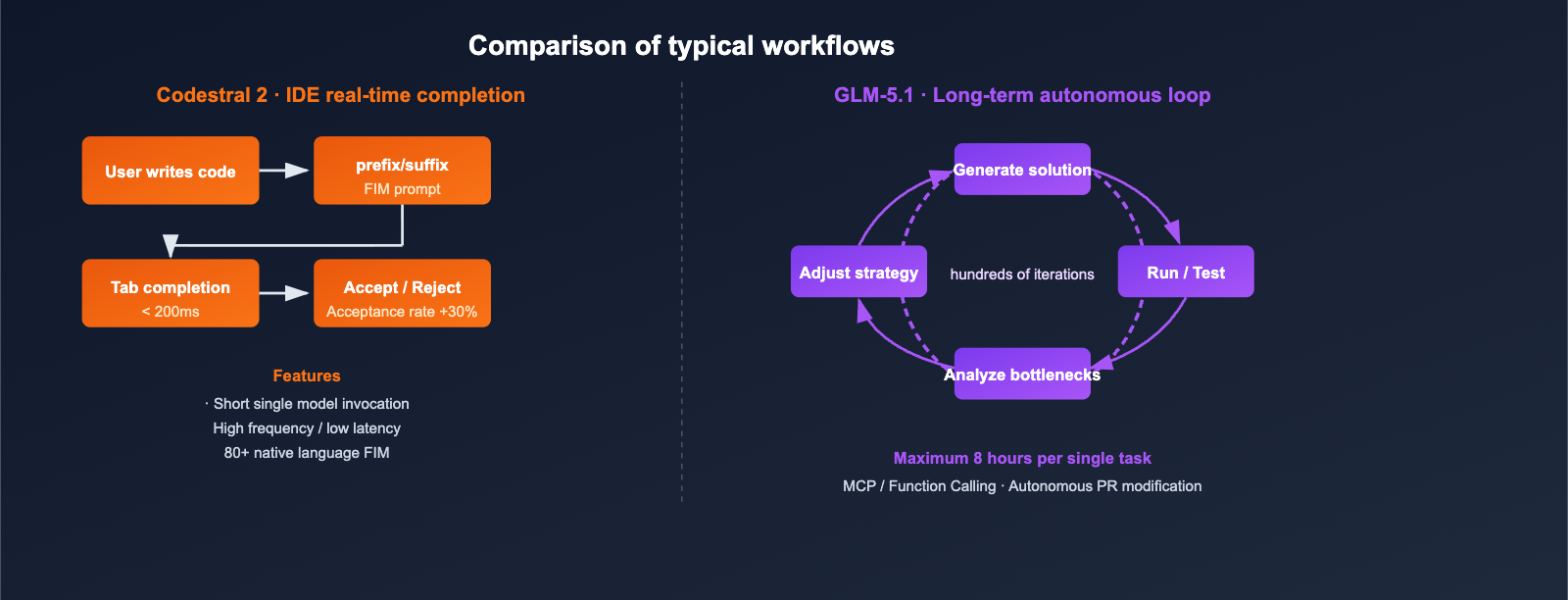
Getting Started: API Integration for Codestral 2 and GLM-5.1
Both models provide OpenAI-compatible interfaces, with the main differences being the model name and parameters. The following examples use the unified base_url from APIYI (apiyi.com) to show the minimum viable code.
Codestral 2 Invocation (Code Completion)
from openai import OpenAI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="YOUR_API_KEY",
)
resp = client.chat.completions.create(
model="codestral-latest", # Points to Codestral 25.08
messages=[
{"role": "system", "content": "You are a senior Python engineer."},
{"role": "user", "content": "Complete a high-performance LRU cache implementation."},
],
temperature=0.2,
max_tokens=512,
)
print(resp.choices[0].message.content)
GLM-5.1 Invocation (Long-Range Tasks)
from openai import OpenAI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="YOUR_API_KEY",
)
resp = client.chat.completions.create(
model="glm-5.1",
messages=[
{"role": "system", "content": "You are a SWE agent. Analyze repo, run tests, iterate."},
{"role": "user", "content": "Fix all failing test cases in tests/test_api.py within the repo."},
],
temperature=0.3,
max_tokens=8192,
# GLM-5.1 supports Function Calling + structured output
)
print(resp.choices[0].message.content)
📎 Expand to view FIM-specific invocation (Codestral 2 exclusive)
# Codestral native FIM uses prefix/suffix to construct the prompt
prefix = "def binary_search(arr, target):\n "
suffix = "\n return -1"
prompt = f"[PREFIX]{prefix}[SUFFIX]{suffix}[MIDDLE]"
# Send the prompt as user content to codestral-latest for high-precision completion
🎯 Integration Tip: Both models follow the OpenAI schema, so you can reuse your existing business logic by simply switching the model name. Using APIYI (apiyi.com) as your unified gateway saves you the operational overhead of managing separate accounts, balances, and rate-limiting policies for Mistral Console and Z.ai.
Pricing and Deployment Strategies for Codestral 2 and GLM-5.1
Pricing and deployment flexibility are often the final hurdles in the decision-making process.
Public Pricing Reference
| Model | Input Price | Output Price | Notes |
|---|---|---|---|
| Codestral 2 (25.08) | $0.20 / 1M | $0.60 / 1M | Follows Codestral series pricing |
| GLM-5.1 | Starts at ~$3 for Coding Plan | Subscription-based | Token-based billing also available |
Note: The prices above are based on official vendor websites and public channel information. Actual exchange rates and promotions are subject to change.
Deployment Options Comparison
| Deployment Method | Codestral 2 | GLM-5.1 |
|---|---|---|
| Official Cloud API | ✅ Mistral Console | ✅ Z.ai Platform |
| Third-party Compatible Gateway | ✅ (APIYI apiyi.com, etc.) | ✅ (APIYI apiyi.com, etc.) |
| VPC / Private Cloud | ✅ License required | ✅ MIT free deployment |
| Local Single-machine Inference | ✅ Single A100/Consumer GPU limited | ❌ Multi-card required |
| Function Calling | Supported (via chat completions) | ✅ Native support + MCP |
🎯 Cost Optimization Tip: For IDE scenarios with high completion frequency and low tokens per request, prioritize Codestral 2 with caching. For Agent scenarios with low frequency but high token volume, the GLM-5.1 subscription plan is more cost-effective. You can configure both strategies by model group on APIYI apiyi.com to prevent your total account balance from being depleted by a single model.
Scenario Recommendations and Pitfalls for Codestral 2 and GLM-5.1
Four Typical Scenario Decisions
| Scenario | Recommended Model | Key Reason |
|---|---|---|
| VSCode / JetBrains Completion Plugin | Codestral 2 | FIM native + low latency |
| Auto Bug Fix / PR Bot | GLM-5.1 | Long-range autonomous loops |
| Code Review Assistant (Single-file comments) | Codestral 2 | Fast response, low cost |
| End-to-end Agent (Testing/Deployment) | GLM-5.1 | MCP + Function Calling |
| Generating Boilerplate Project Skeletons | Either | Both models perform well |
| ML Kernel Performance Tuning | GLM-5.1 | KernelBench 3.6x acceleration |
Common Pitfalls
- ❌ Don't use Codestral 2 for Agents: While its runaway generation rate has dropped by 50%, it isn't optimized for multi-step decision-making.
- ❌ Don't use GLM-5.1 for millisecond-level completions: The time-to-first-token latency isn't ideal for IDE Tab-key response experiences.
- ❌ Don't rely on a single benchmark: GLM-5.1 wins on SWE-Bench Pro, but the Codestral series doesn't lag behind on HumanEval.
- ✅ Run a small-sample A/B test: Take the 100 most typical prompts from your business and run a comparison by switching model parameters on APIYI apiyi.com.
FAQ
Q1: Why is the official page calling it Codestral 25.08 instead of Codestral 2?
Mistral follows a naming convention of <series>-<year>.<month>. Codestral 25.08 is the second generation of the Codestral series (the first generation, 24.05, was released earlier, and the second generation has evolved from 25.01 to 25.08). Industry insiders and the community generally refer to the 25.01+ versions as "Codestral 2." When making a model invocation, simply specify codestral-latest to hit the latest version of the second generation.
Q2: Won't the 744B parameters of GLM-5.1 make inference very slow?
Under the MoE architecture, only 40B parameters are activated per token. Combined with DeepSeek Sparse Attention, the actual inference speed is close to that of a 40B-level dense model. When paired with the persistent connections and caching strategies provided by APIYI (apiyi.com), the perceived latency in long context scenarios is well within an acceptable range.
Q3: Which model handles the context window better?
Codestral 2's 256K is more about "capacity," while GLM-5.1's 200K, combined with sparse attention, is more friendly toward "actual utilization." Before performing full-repository tasks, it's recommended to use tiktoken or the official tokenizer to estimate the actual token count to avoid unnecessary truncation.
Q4: What is the practical significance of open-source weights for enterprises?
GLM-5.1 releases its weights under the MIT license, allowing for internal deployment and fine-tuning, whereas Codestral 2 requires a commercial license agreement. For financial, government, and enterprise clients with strict compliance requirements, this makes a huge difference. If you simply want to bypass regional access restrictions, APIYI (apiyi.com) also provides stable, domestically accessible entry points.
Q5: Can I use both models together?
Yes, and it's highly recommended. A typical approach is to use Codestral 2 for IDE autocompletion and GLM-5.1 for backend Agents. You can use different model keys for each and consolidate billing through APIYI (apiyi.com).
Q6: The benchmarks are self-reported by the vendors; how credible are they?
The benchmarks for both Codestral and GLM are self-reported, and the 58.4 score on Z.ai's SWE-Bench Pro has yet to be independently reproduced. It's best to treat public benchmarks as a "reference for capability ceilings" and always perform regression testing on your specific business scenarios before deployment.
Summary: Final Selection Advice for Codestral 2 vs. GLM-5.1
Returning to the three questions at the beginning:
- If your product focuses on Copilot, tab completion, or code snippet generation, choose Codestral 2. Its FIM (Fill-In-the-Middle) capabilities, latency, pricing, and coverage of 80+ languages make it the best balance for these types of scenarios.
- If your product focuses on PR bots, bug-fixing agents, or backend agents running 8-hour tasks, choose GLM-5.1. Its 744B MoE architecture, 58.4 score on SWE-Bench Pro, and long-range autonomous loops make it the closest option in the open-source camp to Claude Opus 4.6.
- If your product includes both scenarios, using both models together is the most economical strategy for 2026.
🎯 Implementation Advice: Upgrade your selection strategy from "either-or" to "dual-model orchestration." By using the OpenAI-compatible interface from APIYI (apiyi.com), you only need to use a single field in your business code to distinguish between "short completion" and "long tasks." This allows you to automatically route requests between Codestral 2 and GLM-5.1, ensuring every request is handled by the most suitable model.
— APIYI Team (APIYI apiyi.com Technical Team)