Em 2026, o mercado de Modelos de Linguagem Grande voltados para código está sendo dividido por duas categorias de produtos completamente distintas: uma é a categoria "focada em IDE e preenchimento de alta frequência", representada pelo Mistral Codestral 2 (versão atual Codestral 25.08), que se concentra em Fill-in-the-Middle (FIM), alta taxa de aceitação de preenchimento e resposta instantânea em mais de 80 linguagens; a outra é a categoria "agente de longo curso", representada pelo Zhipu GLM-5.1, que utiliza uma arquitetura MoE de 744B de parâmetros e 200K de janela de contexto, focada em capacidades de codificação complexas de nível SWE-Bench Pro para "tarefas de engenharia autônomas de 8 horas".
Essas duas rotas possuem públicos-alvo e estratégias de cobrança que quase não se sobrepõem, mas são frequentemente comparadas na questão de "qual é melhor para escrever código". Este artigo, baseado em fontes primárias em inglês, como o anúncio oficial da Mistral AI (Codestral 25.08, 30/07/2025) e a documentação de desenvolvedor da Z.ai (GLM-5.1, lançado em 27/03/2026), apresenta uma tabela de decisão de seleção replicável abrangendo 6 dimensões: arquitetura, benchmarks, contexto, tarefas de longo curso, implantação e preço. Além disso, incluímos códigos de comparação de invocação do modelo via API para ajudar você a decidir em 10 minutos.
Diferenças de posicionamento central entre Codestral 2 e GLM-5.1
Antes de mergulhar nos benchmarks, precisamos esclarecer uma coisa: os dois modelos não pertencem à mesma categoria de produto. Colocá-los no mesmo nível de comparação levará a conclusões muito enganosas.
Posicionamento em uma frase
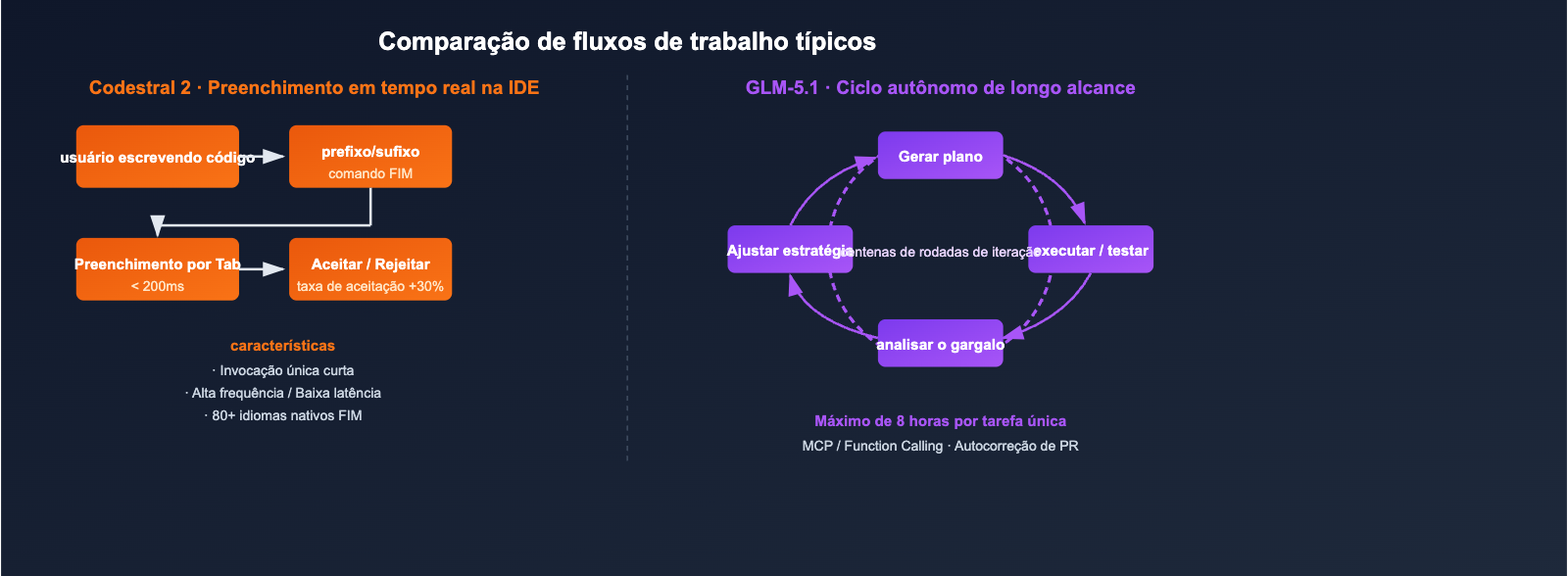
- Codestral 2 (25.08): Um Modelo de Linguagem Grande especializado em código voltado para tarefas de preenchimento e edição. Arquitetura densa de 22B, objetivo de treinamento FIM nativo, enfatiza "resposta em milissegundos + alta taxa de aceitação", sendo um dos padrões de fato para produtos do tipo IDE Copilot.
- GLM-5.1: Um Modelo de Linguagem Grande carro-chefe de uso geral voltado para agentes e tarefas de programação de longo curso. MoE de 744B (ativação de cerca de 40B por token), 200K de janela de contexto, alcançando 58,4 pontos no SWE-Bench Pro, superando o GPT-5.4, Claude Opus 4.6 e Gemini 3.1 Pro.
Três perguntas que você deve responder antes de escolher
| Pergunta | Prefere Codestral 2 | Prefere GLM-5.1 |
|---|---|---|
| O cenário principal é preenchimento na IDE ou modificar PRs autonomamente? | Preenchimento na IDE | Tarefas autônomas de várias etapas |
| O volume de tokens por requisição é de dezenas ou dezenas de milhares? | Dezenas a milhares | Milhares a dezenas de milhares |
| O usuário pode tolerar dezenas de segundos de espera? | Não | Sim |
🎯 Sugestão de seleção: Se 80% das suas invocações do modelo vêm de "preenchimento para a próxima linha de código", escolha o Codestral 2; se 80% das invocações vêm de "ajude-me a corrigir o bug neste repositório", escolha o GLM-5.1. Ambos podem ser testados em paralelo através da interface unificada da APIYI (apiyi.com), sem a necessidade de integrar separadamente a Mistral e a Z.ai.
Comparação de Arquitetura e Parâmetros entre Codestral 2 e GLM-5.1
As diferenças de arquitetura são a raiz de todo o desempenho subsequente.
Visão Geral das Especificações Principais
| Item | Codestral 2 (25.08) | GLM-5.1 |
|---|---|---|
| Fabricante | Mistral AI | Zhipu AI (Z.ai) |
| Arquitetura | Transformer Denso | Mistura de Especialistas (MoE) |
| Parâmetros Totais | 22B | 744B |
| Parâmetros Ativos | 22B | Aprox. 40B (256 especialistas, 8 ativos por token) |
| Janela de contexto | 256K | 200K |
| Saída máxima | Padrão | 128K tokens |
| Mecanismo de atenção | Padrão + Otimização FIM | Atenção Esparsa DeepSeek |
| Licença | Licença Comercial Mistral / MNPL | MIT (pesos de código aberto) |
| Data de lançamento | 30/07/2025 (iteração mais recente) | 27/03/2026 |
| Cobertura de linguagens | 80+ linguagens principais | Multilíngue geral |

Impacto direto das diferenças de arquitetura
- Memória de vídeo e custo de implantação: O Codestral 2 de 22B pode ser inferido em uma única máquina (A100 80G); o GLM-5.1 requer paralelismo multi-GPU ou serviços de inferência gerenciados.
- Latência por token: A arquitetura densa do Codestral 2 oferece latência mais estável em entradas curtas; o GLM-5.1, devido à seleção do roteador e atenção esparsa, tem um primeiro token ligeiramente mais lento, mas ganha vantagem em sequências longas.
- Estratégia de código aberto: O GLM-5.1 libera pesos sob licença MIT, sendo mais amigável para implantações privadas e treinamento secundário; o Codestral 2 pode ser executado localmente, mas requer licença para uso comercial.
🎯 Sugestão de implantação: Equipes que precisam de implantação totalmente privada devem priorizar os pesos MIT do GLM-5.1; equipes que desejam acesso rápido sem se preocupar com auto-hospedagem podem usar o serviço proxy de API da APIYI (apiyi.com) para invocar ambos os modelos diretamente, economizando tempo com aquisições e licenciamento.
Comparação de benchmarks de código: Codestral 2 vs GLM-5.1
Os resultados de ambos os modelos vêm de testes internos dos fabricantes, e os conjuntos de avaliação não são totalmente sobrepostos. Abaixo, listamos apenas os indicadores com significado de comparação direta.
Pontos fortes do Codestral 2: Qualidade de preenchimento e métricas de IDE
| Indicador | Valor | Explicação |
|---|---|---|
| Accepted Completions (Taxa de aceitação) | +30% (relativo a 25.01) | Taxa de adoção em IDEs de produção |
| Retained Code (Taxa de retenção) | +10% | Proporção de código sugerido não deletado no commit |
| Runaway Generations (Gerações descontroladas) | -50% | Redução de continuações inúteis muito longas |
| IFEval v8 (Seguimento de instruções) | +5% | Precisão de instruções |
| Média MultiPL-E | +5% | Capacidade de código multilíngue |
| HumanEval (Dados da geração anterior 25.01) | 86.6% | Dados de referência |
| MBPP (Dados da geração anterior 25.01) | 91.2% | Dados de referência |
Pontos fortes do GLM-5.1: Tarefas de engenharia complexas
| Indicador | Valor | Explicação |
|---|---|---|
| SWE-Bench Pro | 58.4 | Supera GPT-5.4 / Claude Opus 4.6 / Gemini 3.1 Pro |
| Comparação Claude Code | 45.3 (Opus 4.6 é 47.9) | Atinge 94,6% do desempenho do Opus 4.6 |
| vs Linha de base GLM-5 | +28% | Otimizações pós-treinamento |
| KernelBench Nível 3 | Aceleração 3.6x | Cenários de otimização de kernel ML |
| Duração contínua por tarefa | Até 8 horas | Ciclo autônomo de "experimento-análise-otimização" |
Avaliação de sobreposição de capacidades
| Capacidade | Codestral 2 | GLM-5.1 |
|---|---|---|
| Preenchimento de arquivo único | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| Refatoração de múltiplos arquivos | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| Localização de bugs + PR de correção | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| Tradução entre linguagens | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Agente / Uso de ferramentas | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| Latência do primeiro token | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
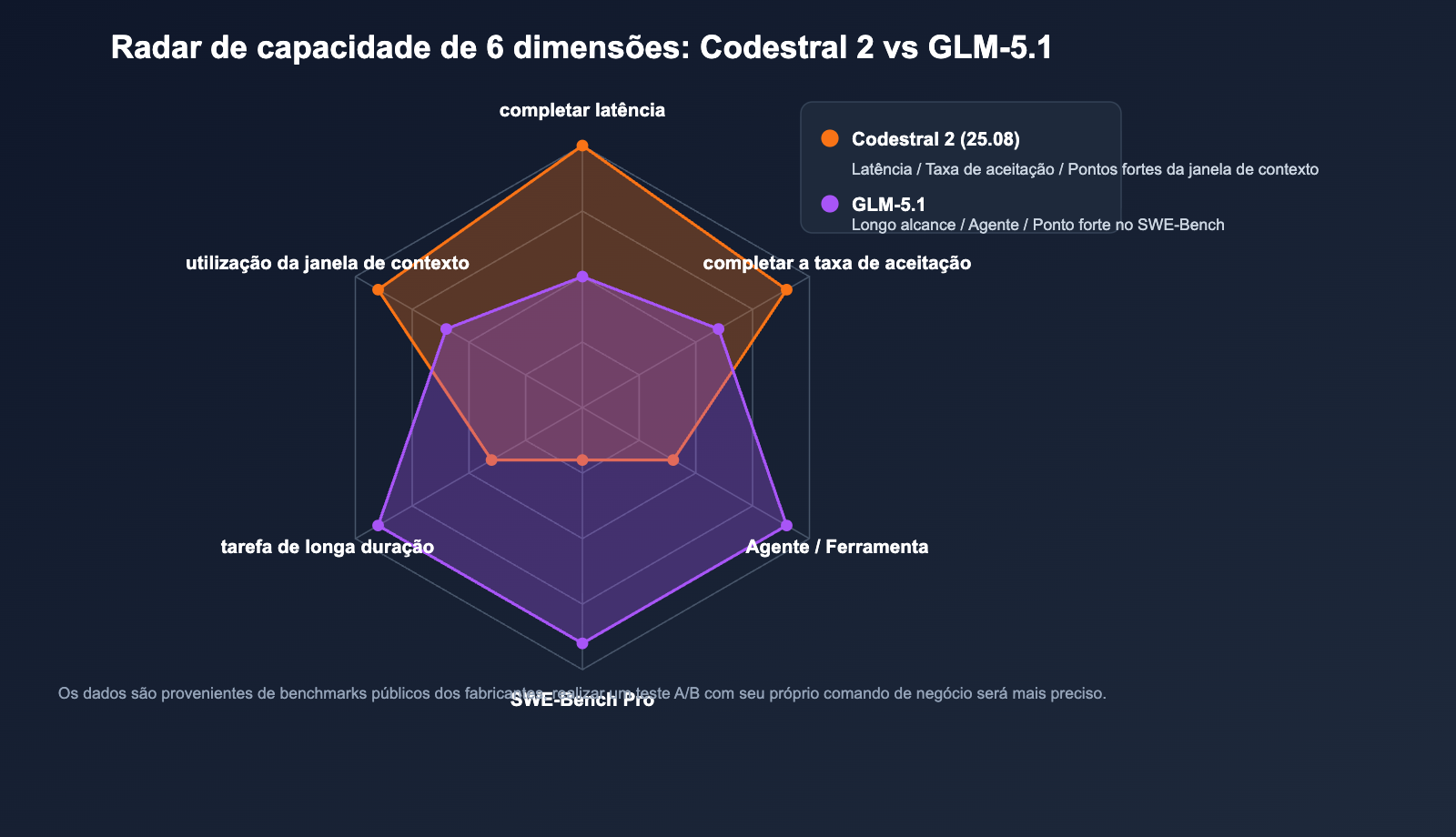
🎯 Dica de leitura de benchmarks: Os dados oficiais geralmente vêm de configurações de avaliação relativamente otimizadas, e o desempenho real nos negócios pode ter uma flutuação de 10% a 20%. Recomendamos realizar um teste A/B com sua própria base de código usando a APIYI (apiyi.com) antes de tomar uma decisão final.
Capacidades de contexto e tarefas de longo curso: Codestral 2 vs. GLM-5.1
Embora 256K e 200K sejam números próximos em termos de janela de contexto, eles são projetados para tipos de tarefas completamente diferentes.
O contexto de 256K do Codestral 2: Completude de repositório inteiro
O Codestral 2 utiliza seus 256K de contexto principalmente para "colocar todo o repositório de código no comando", permitindo que ele perceba dependências entre arquivos durante a autocompletagem:
- Ideal para: Completude de funções grandes dentro de um monorepo, Lint Fix em todo o projeto e renomeação entre módulos.
- Não é ideal para: Fluxos de agentes que exigem raciocínio em várias etapas, chamadas de ferramentas e gravação de resultados.
O contexto de 200K + ciclo autônomo de 8 horas do GLM-5.1
O avanço do GLM-5.1 não está em "quanto contexto ele comporta", mas em "por quanto tempo ele consegue trabalhar de forma contínua":
- Na demonstração oficial, o modelo pode iterar centenas de vezes em uma única tarefa: executar benchmark → identificar gargalos → ajustar estratégia → executar benchmark novamente.
- O Sparse Attention do DeepSeek mantém o custo de inferência de sequências longas de 200K em um patamar viável.
- Com suporte a Function Calling / MCP, ele pode se conectar diretamente a cadeias de ferramentas externas.
Comparação de tarefas típicas de longo curso
| Tarefa | Codestral 2 | GLM-5.1 |
|---|---|---|
| Completar uma função de 200 linhas | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Gerar um PR a partir de um GitHub Issue | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| Encontrar e corrigir bugs em todo o repo | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| Ajuste automático de kernel de ML em várias rodadas | ⭐ | ⭐⭐⭐⭐⭐ |
| Autocompletar com Tab no IDE | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
🎯 Sugestão de migração de cenário: Equipes que usam o Codestral para completude de repositório e encontram problemas onde "o código é gerado, mas não passa nos testes", podem usar o GLM-5.1 para assumir o ciclo fechado de "gerar-executar-corrigir". Basta alterar o
base_urlvia APIYI apiyi.com para reutilizar o mesmo código compatível com OpenAI.
Início rápido: Comparação de acesso à API do Codestral 2 e GLM-5.1
Ambos os modelos oferecem interfaces compatíveis com OpenAI, com diferenças reais principalmente no nome do modelo e parâmetros. O exemplo abaixo mostra o código mínimo utilizável usando o base_url unificado da APIYI apiyi.com.
Chamada do Codestral 2 (autocompletagem de código)
from openai import OpenAI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="SUA_CHAVE_API",
)
resp = client.chat.completions.create(
model="codestral-latest", # Aponta para Codestral 25.08
messages=[
{"role": "system", "content": "Você é um engenheiro Python sênior."},
{"role": "user", "content": "Complete uma implementação de cache LRU de alto desempenho."},
],
temperature=0.2,
max_tokens=512,
)
print(resp.choices[0].message.content)
Chamada do GLM-5.1 (tarefas de longo curso)
from openai import OpenAI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="SUA_CHAVE_API",
)
resp = client.chat.completions.create(
model="glm-5.1",
messages=[
{"role": "system", "content": "Você é um agente de engenharia de software. Analise o repositório, execute testes e itere."},
{"role": "user", "content": "Corrija todos os casos de teste com falha em tests/test_api.py no repositório."},
],
temperature=0.3,
max_tokens=8192,
# GLM-5.1 suporta Function Calling + saída estruturada
)
print(resp.choices[0].message.content)
📎 Expandir para ver a chamada dedicada FIM (exclusiva do Codestral 2)
# O FIM nativo do Codestral é montado via prefix / suffix no prompt
prefix = "def binary_search(arr, target):\n "
suffix = "\n return -1"
prompt = f"[PREFIX]{prefix}[SUFFIX]{suffix}[MIDDLE]"
# Envie o prompt como conteúdo de usuário para codestral-latest para obter alta precisão
🎯 Sugestão de integração: Ambos os modelos seguem o esquema da OpenAI, bastando alterar o nome do modelo para reutilizar o mesmo código de negócio. O uso unificado via APIYI apiyi.com elimina os custos operacionais de manter contas, saldos e estratégias de limite de taxa separadas no Mistral Console e Z.ai.
Estratégias de Preço e Implantação para Codestral 2 e GLM-5.1
O preço e a flexibilidade de implantação costumam ser a "última milha" na tomada de decisão.
Referência de Preços Públicos
| Modelo | Preço de Entrada | Preço de Saída | Observação |
|---|---|---|---|
| Codestral 2 (25.08) | $0.20 / 1M | $0.60 / 1M | Mantém a precificação da série Codestral |
| GLM-5.1 | A partir de ~$3 (Plano de Codificação) | Baseado em pacote | Opção de cobrança por token também disponível |
Nota: Os preços acima baseiam-se em informações públicas dos sites oficiais e canais dos fabricantes; a taxa de câmbio real e promoções estão sujeitas ao dia da consulta.
Comparação de Opções de Implantação
| Método de Implantação | Codestral 2 | GLM-5.1 |
|---|---|---|
| API de Nuvem Oficial | ✅ Mistral Console | ✅ Plataforma Z.ai |
| Gateway Compatível de Terceiros | ✅ (APIYI apiyi.com, etc.) | ✅ (APIYI apiyi.com, etc.) |
| VPC / Nuvem Privada | ✅ Requer licença | ✅ Implantação livre MIT |
| Inferência Local (Single-node) | ✅ Limitado a uma A100/GPU de consumo | ❌ Requer múltiplas placas |
| Function Calling | Suportado (via chat completions) | ✅ Suporte nativo + MCP |
🎯 Dica de otimização de custos: Para cenários de IDE com alta frequência de preenchimento e poucos tokens por vez, priorize o Codestral 2 com cache; para cenários de Agent com baixa frequência, mas alto volume de tokens por chamada, o modelo de pacotes do GLM-5.1 será mais econômico. Ambas as estratégias podem ser configuradas por grupo de modelos no APIYI apiyi.com, evitando que o saldo total da conta seja consumido por um único modelo.
Recomendações de Cenários e Guia de Evitação de Erros para Codestral 2 e GLM-5.1
Decisões para Quatro Cenários Típicos
| Cenário | Modelo Recomendado | Motivo Principal |
|---|---|---|
| Plugin de preenchimento VSCode / JetBrains | Codestral 2 | FIM nativo + baixa latência |
| Correção automática de bugs / Robô de PR | GLM-5.1 | Ciclo autônomo de longo curso |
| Assistente de revisão de código (comentários em arquivo único) | Codestral 2 | Resposta rápida, baixo custo |
| Agent ponta a ponta (integração de testes/implantação) | GLM-5.1 | MCP + Function Calling |
| Geração de estrutura de projeto (boilerplate) | Empate | Qualquer um dos modelos |
| Ajuste de desempenho de kernel ML | GLM-5.1 | Aceleração de 3.6x no KernelBench |
Lista de Erros Comuns a Evitar
- ❌ Não use o Codestral 2 para rodar Agents: Embora a taxa de geração fora de controle tenha caído 50%, ele não foi otimizado para tomadas de decisão em múltiplas etapas.
- ❌ Não use o GLM-5.1 para preenchimento em milissegundos: A latência do primeiro token não é amigável para a experiência de resposta da tecla Tab na IDE.
- ❌ Não olhe apenas para um ranking: O GLM-5.1 vence no SWE-Bench Pro, mas a série Codestral não fica atrás no HumanEval.
- ✅ Faça um pequeno teste A/B: Use os 100 comandos (prompts) mais típicos do seu negócio e execute uma comparação alternando os parâmetros do modelo no APIYI apiyi.com.
Perguntas Frequentes (FAQ)
Q1: Por que a página oficial chama de Codestral 25.08 e não Codestral 2?
A convenção de nomenclatura da Mistral é <série>-<ano>.<mês>. O Codestral 25.08 pertence à 2ª geração de iteração do Codestral (a 1ª geração, 24.05, foi lançada anteriormente; a 2ª geração evoluiu de 25.01 para 25.08). A indústria e a comunidade costumam chamar o 25.01+ de "Codestral 2". Ao realizar a invocação do modelo, basta especificar codestral-latest para acessar a versão mais recente da 2ª geração.
Q2: Os 744B de parâmetros do GLM-5.1 não tornam a inferência muito lenta?
Na arquitetura MoE, apenas 40B de parâmetros são ativados por token. Somado ao DeepSeek Sparse Attention, a velocidade real de inferência aproxima-se da de um modelo denso de 40B. Com as estratégias de conexão persistente e cache da APIYI (apiyi.com), a latência percebida em cenários de contexto longo permanece em um nível aceitável.
Q3: Qual dos dois modelos aproveita melhor o contexto?
Os 256K do Codestral 2 referem-se mais à "capacidade", enquanto os 200K do GLM-5.1, combinados com a atenção esparsa, são mais amigáveis em termos de "taxa de utilização real". Antes de realizar tarefas em bibliotecas completas, recomenda-se usar o tiktoken ou o tokenizador oficial para estimar o número real de tokens e evitar truncamentos desnecessários.
Q4: Qual o significado prático dos pesos de código aberto para as empresas?
O GLM-5.1 libera seus pesos sob a licença MIT, permitindo a implantação em redes internas e treinamento adicional; o Codestral 2 requer um acordo de licenciamento para uso comercial. Para clientes dos setores financeiro e governamental com requisitos rigorosos de conformidade, a diferença é enorme. Se o objetivo for apenas contornar restrições de acesso regional, a APIYI (apiyi.com) também oferece um gateway estável e acessível localmente.
Q5: É possível usar os dois modelos simultaneamente?
Sim, e é recomendado. A prática comum é usar o Codestral 2 para preenchimento em IDE e o GLM-5.1 para agentes de backend. Ambos utilizam chaves de modelo diferentes, com faturamento unificado através da APIYI (apiyi.com).
Q6: Os benchmarks são testes internos dos fabricantes, qual a credibilidade?
Os benchmarks do Codestral e do GLM são auto-relatados. O resultado de 58.4 no SWE-Bench Pro da Z.ai ainda não possui replicação independente. Sugerimos tratar os benchmarks públicos como uma "referência de limite de capacidade" e realizar testes de regressão em seus cenários de negócio antes da implementação.
Conclusão: Sugestão final de seleção entre Codestral 2 e GLM-5.1
Voltando às três perguntas iniciais:
- Se o seu produto é um Copilot, preenchimento de abas ou geração de trechos de código, escolha o Codestral 2. Seu FIM (Fill-In-the-Middle), latência, preço e cobertura de mais de 80 linguagens são o melhor equilíbrio para esse tipo de cenário.
- Se o seu produto é um robô de PR, agente de correção de bugs ou um agente de backend que executa tarefas por 8 horas, escolha o GLM-5.1. Com 744B MoE + 58.4 no SWE-Bench Pro + ciclo autônomo de longa duração, é a opção no campo de código aberto mais próxima do Claude Opus 4.6 atualmente.
- Se o seu produto contém ambos os cenários, usar os dois em conjunto é a solução mais econômica para 2026.
🎯 Sugestão de implementação: Evolua sua seleção de "escolher um entre dois" para "orquestração de modelos duplos". Através da interface compatível com OpenAI da APIYI (apiyi.com), basta usar um campo no seu código de negócio para distinguir entre "preenchimento curto / tarefa longa". Assim, você pode rotear automaticamente entre o Codestral 2 e o GLM-5.1, enviando cada solicitação para o modelo mais adequado.
— Equipe APIYI (Equipe técnica da APIYI apiyi.com)