في عام 2026، ينقسم مجال نماذج اللغة الكبيرة المخصصة للبرمجة إلى فئتين متميزتين تماماً: الفئة الأولى هي "نماذج بيئات التطوير (IDE) ذات الاستجابة السريعة"، ويمثلها Mistral Codestral 2 (الإصدار الأحدث Codestral 25.08)، والتي تركز على تقنية "التعبئة في المنتصف" (Fill-in-the-Middle – FIM)، وتحقيق معدلات إكمال عالية، والاستجابة الفورية عبر أكثر من 80 لغة برمجة. أما الفئة الثانية فهي "نماذج الوكلاء (Agents) طويلة المدى"، ويمثلها Zhipu GLM-5.1، التي تعتمد على معمارية MoE بـ 744 مليار بارامتر ونافذة سياق تصل إلى 200 ألف رمز (Token)، وتستهدف المهام البرمجية المعقدة بمستوى SWE-Bench Pro التي تتطلب "8 ساعات من العمل الهندسي المستقل".
على الرغم من أن هذين المسارين يستهدفان جماهير مختلفة واستراتيجيات تسعير متباينة، إلا أنه غالباً ما تتم مقارنتهما عند الإجابة على سؤال "أيهما أفضل لكتابة الكود؟". بناءً على الإعلانات الرسمية لشركة Mistral AI (بتاريخ 30 يوليو 2025 لنموذج Codestral 25.08) ووثائق المطورين لـ Z.ai (نموذج GLM-5.1، الصادر في 27 مارس 2026)، يقدم هذا المقال جدولاً لاتخاذ قرارات الاختيار بناءً على 6 أبعاد: المعمارية، المعايير، نافذة السياق، المهام طويلة المدى، النشر، والتكلفة، مع إرفاق كود مقارنة لاستدعاء واجهة برمجة التطبيقات (API) لكل منهما، لمساعدتك على اتخاذ قرارك في أقل من 10 دقائق.

الاختلافات الجوهرية في التموضع بين Codestral 2 و GLM-5.1
قبل الغوص في نتائج الأداء، من الضروري توضيح أمر واحد: هذان النموذجان لا ينتميان إلى نفس الفئة من المنتجات. لذا، فإن مقارنتهما على نفس المقياس ستؤدي إلى استنتاجات مضللة للغاية.
التموضع في جملة واحدة
- Codestral 2 (25.08): هو نموذج لغة كبير مخصص لمهام إكمال الكود وتحريره. يتميز بمعمارية كثيفة بـ 22 مليار بارامتر، وهدف تدريب أصلي (FIM)، ويركز على "الاستجابة في أجزاء من الثانية + معدل قبول مرتفع"، ويعد أحد المعايير الفعلية لمنتجات مثل Copilot في بيئات التطوير.
- GLM-5.1: هو نموذج لغة كبير رائد وعام موجه للوكلاء (Agents) والمهام البرمجية طويلة المدى. يعتمد على معمارية MoE بـ 744 مليار بارامتر (تنشيط حوالي 40 مليار بارامتر لكل رمز)، ونافذة سياق 200 ألف رمز، وقد حقق 58.4 نقطة في اختبار SWE-Bench Pro، متفوقاً بذلك على GPT-5.4 وClaude Opus 4.6 وGemini 3.1 Pro.
ثلاثة أسئلة يجب الإجابة عليها قبل الاختيار
| السؤال | يميل إلى Codestral 2 | يميل إلى GLM-5.1 |
|---|---|---|
| هل سيناريو الاستخدام الرئيسي هو الإكمال داخل IDE أم تعديل طلبات السحب (PR) بشكل مستقل؟ | الإكمال داخل IDE | مهام مستقلة متعددة الخطوات |
| هل حجم الرموز (Tokens) في كل طلب هو عشرات أم عشرات الآلاف؟ | عشرات إلى آلاف | آلاف إلى عشرات الآلاف |
| هل يمكن للمستخدم تحمل انتظار عشرات الثواني؟ | لا | نعم |
🎯 نصيحة للاختيار: إذا كان 80% من استدعاءاتك يأتي من "إكمال السطر التالي من الكود"، فاختر Codestral 2؛ أما إذا كان 80% من استدعاءاتك يأتي من "ساعدني في إصلاح هذا الخطأ (Bug) في المستودع (Repo)"، فاختر GLM-5.1. يمكن اختبار كلاهما بالتوازي عبر خدمة وكيل API الخاص بـ APIYI (apiyi.com)، دون الحاجة إلى دمج Mistral وZ.ai بشكل منفصل.
مقارنة البنية والمعايير بين Codestral 2 و GLM-5.1
تُعد الاختلافات في البنية الهندسية هي الأساس الذي تنبني عليه كافة مستويات الأداء اللاحقة.
نظرة سريعة على المواصفات الرئيسية
| العنصر | Codestral 2 (25.08) | GLM-5.1 |
|---|---|---|
| الشركة المصنعة | Mistral AI | Zhipu AI (Z.ai) |
| البنية | Dense Transformer | Mixture-of-Experts |
| إجمالي المعايير | 22B | 744B |
| المعايير النشطة | 22B | حوالي 40B (256 خبيراً، 8 نشطين لكل token) |
| نافذة السياق | 256K | 200K |
| الحد الأقصى للمخرجات | قياسي | 128K tokens |
| آلية الانتباه | قياسي + تحسين FIM | DeepSeek Sparse Attention |
| الترخيص | ترخيص تجاري من Mistral / MNPL | MIT (أوزان مفتوحة المصدر) |
| تاريخ الإصدار | 2025-07-30 (أحدث إصدار) | 2026-03-27 |
| دعم لغات البرمجة | 80+ لغة رئيسية | متعدد اللغات عام |
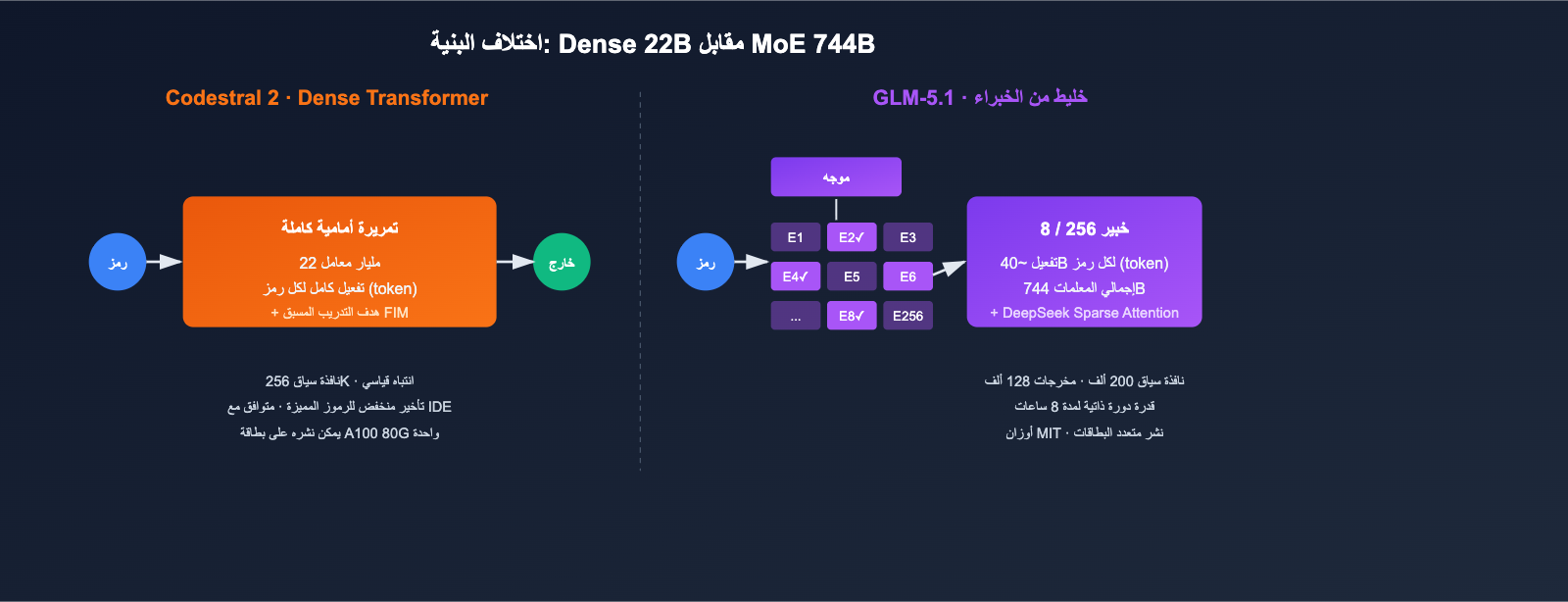
التأثيرات المباشرة للاختلافات الهيكلية
- الذاكرة الرسومية (VRAM) وتكاليف النشر: يمكن تشغيل Codestral 2 (بمعاييره الـ 22B) على جهاز واحد (A100 80G)؛ بينما يتطلب GLM-5.1 معالجة متوازية عبر عدة بطاقات أو استخدام خدمة استضافة.
- زمن الاستجابة لكل token: تتميز بنية Dense في Codestral 2 باستقرار أكبر في زمن الاستجابة للمدخلات القصيرة؛ بينما يتأثر GLM-5.1 بعملية اختيار الموجه (Router) والانتباه المتناثر، مما يجعل الـ token الأول أبطأ قليلاً، لكنه يتفوق في معالجة التسلسلات الطويلة.
- استراتيجية المصدر المفتوح: يتيح GLM-5.1 أوزان النموذج بموجب ترخيص MIT، مما يجعله أكثر ملاءمة للنشر الخاص والتدريب الإضافي؛ في حين أن Codestral 2 يمكن تشغيله محلياً، إلا أن استخدامه تجارياً يتطلب ترخيصاً.
🎯 نصيحة للنشر: الفرق التي تحتاج إلى نشر خاص بالكامل يجب أن تعطي الأولوية لأوزان GLM-5.1 المتاحة بترخيص MIT؛ أما الفرق التي ترغب في الوصول السريع دون عناء الاستضافة الذاتية، فيمكنها استخدام API الخاص بالنموذجين عبر خدمة APIYI (apiyi.com)، مما يوفر الوقت والجهد في عمليات الشراء والتراخيص.
مقارنة مرجعية للكود الأساسي: Codestral 2 مقابل GLM-5.1
تأتي نتائج أداء النموذجين من اختبارات الشركات المصنعة، مع ملاحظة أن مجموعات الاختبار ليست متطابقة تماماً. فيما يلي المؤشرات التي تحمل دلالة مقارنة مباشرة فقط.
نقاط قوة Codestral 2: جودة الإكمال ومؤشرات بيئة التطوير (IDE)
| المؤشر | القيمة | الشرح |
|---|---|---|
| Accepted Completions (معدل القبول) | +30% (مقارنة بـ 25.01) | معدل اعتماد IDE في بيئة الإنتاج |
| Retained Code (معدل الاحتفاظ) | +10% | نسبة الكود المقترح الذي لم يُحذف عند الإرسال |
| Runaway Generations (التوليد غير المنضبط) | -50% | انخفاض في التوليد الطويل وغير المفيد |
| IFEval v8 (اتباع التعليمات) | +5% | دقة تنفيذ التعليمات |
| MultiPL-E (متوسط الدرجات) | +5% | قدرة الكود متعدد اللغات |
| HumanEval (بيانات الإصدار السابق 25.01) | 86.6% | بيانات مرجعية |
| MBPP (بيانات الإصدار السابق 25.01) | 91.2% | بيانات مرجعية |
نقاط قوة GLM-5.1: المهام الهندسية المعقدة
| المؤشر | القيمة | الشرح |
|---|---|---|
| SWE-Bench Pro | 58.4 | يتفوق على GPT-5.4 / Claude Opus 4.6 / Gemini 3.1 Pro |
| مقارنة Claude Code | 45.3 (Opus 4.6 حقق 47.9) | يصل إلى 94.6% من أداء Opus 4.6 |
| مقابل خط أساس GLM-5 | +28% | ناتج عن تحسينات ما بعد التدريب |
| KernelBench Level 3 | تسريع بمقدار 3.6 ضعف | سيناريوهات تحسين نواة تعلم الآلة |
| مدة المهمة الواحدة | تصل إلى 8 ساعات | حلقة "تجربة-تحليل-تحسين" ذاتية |
تقييم تداخل القدرات
| القدرة | Codestral 2 | GLM-5.1 |
|---|---|---|
| إكمال ملف واحد | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| إعادة هيكلة ملفات متعددة | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| تحديد الأخطاء + إصلاح PR | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| الترجمة عبر اللغات | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| الوكيل / استخدام الأدوات | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| تأخير الرمز الأول (Latency) | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
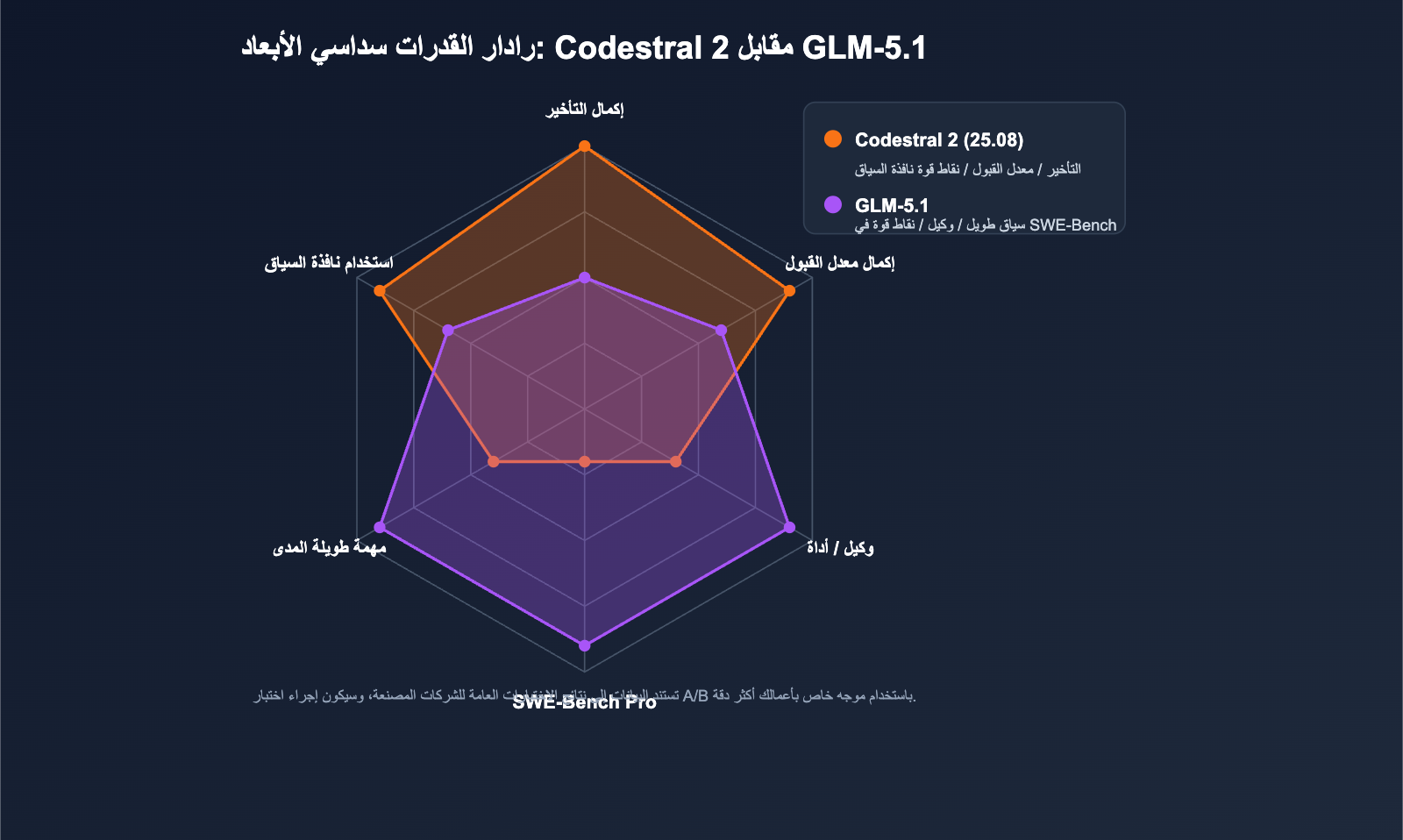
🎯 نصيحة لقراءة النتائج: عادة ما تأتي البيانات الرسمية من إعدادات تقييم مثالية، وقد يكون هناك تفاوت بنسبة 10% إلى 20% في الأداء الفعلي. نوصي بإجراء اختبار A/B باستخدام قاعدة الكود الخاصة بك على APIYI (apiyi.com) قبل اتخاذ القرار النهائي.
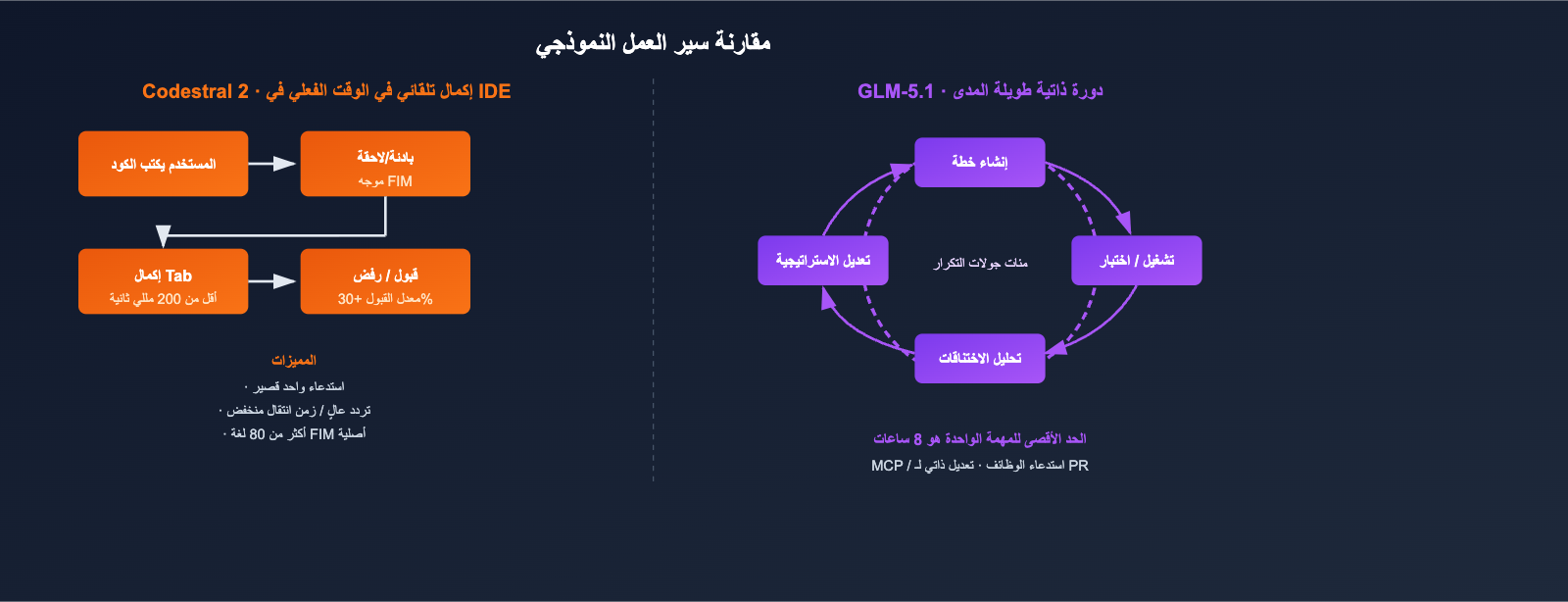
قدرات السياق والمهام طويلة المدى لـ Codestral 2 و GLM-5.1
نافذة السياق (256 ألف مقابل 200 ألف) متقاربة رقمياً، لكن أنواع المهام التي تدعمها مختلفة تماماً.
نافذة سياق Codestral 2 (256 ألف): إكمال المستودع بالكامل
يستخدم Codestral 2 نافذة السياق 256 ألف بشكل أساسي لـ "حشر كامل مستودع الكود في الموجه (Prompt)"، وذلك لتمكين النموذج من إدراك الاعتمادات بين الملفات أثناء الإكمال:
- مناسب لـ: إكمال الوظائف الكبيرة داخل مستودع واحد (monorepo)، إصلاح Lint للمشروع بالكامل، وإعادة تسمية الوحدات.
- غير مناسب لـ: عمليات الوكيل (Agent) التي تتطلب استنتاجاً متعدد الخطوات، استدعاء الأدوات، وكتابة النتائج.
نافذة سياق GLM-5.1 (200 ألف) + 8 ساعات من الحلقة الذاتية
لا تكمن قوة GLM-5.1 في "حجم السياق"، بل في "مدة العمل المستمر":
- في العروض التوضيحية الرسمية، يمكن للنموذج التكرار مئات المرات داخل مهمة واحدة: تشغيل الاختبار المرجعي (benchmark) ← تحديد الاختناقات ← تعديل الاستراتيجية ← إعادة تشغيل الاختبار.
- تتيح تقنية DeepSeek Sparse Attention الحفاظ على تكلفة الاستنتاج للسلاسل الطويلة (200 ألف) ضمن نطاق معقول.
- يمكن ربطه مباشرة بسلسلة الأدوات الخارجية عند استخدامه مع Function Calling / MCP.
مقارنة المهام طويلة المدى النموذجية
| المهمة | Codestral 2 | GLM-5.1 |
|---|---|---|
| إكمال وظيفة من 200 سطر | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| إنشاء PR من GitHub Issue | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| العثور على أخطاء في المستودع وإصلاحها | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| الضبط التلقائي لنواة تعلم الآلة (ML kernel) | ⭐ | ⭐⭐⭐⭐⭐ |
| الإكمال التلقائي بالضغط على Tab في IDE | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
🎯 نصيحة لنقل السيناريو: إذا كانت الفرق التي تستخدم Codestral لإكمال المستودع بالكامل تواجه سيناريوهات "تم الإكمال ولكن الاختبارات تفشل"، فيمكنها استخدام GLM-5.1 لتولي حلقة "التوليد-التشغيل-الإصلاح"، ويمكن إعادة استخدام نفس كود OpenAI المتوافق عبر تغيير
base_urlفي APIYI (apiyi.com).
دليل سريع: مقارنة الربط عبر API بين Codestral 2 و GLM-5.1
يوفر كلا النموذجين واجهات برمجة تطبيقات متوافقة مع OpenAI، وتكمن الاختلافات الفعلية بشكل أساسي في اسم النموذج والمعاملات (parameters). يوضح المثال أدناه الحد الأدنى من الكود البرمجي القابل للتشغيل باستخدام رابط القاعدة الموحد لخدمة APIYI (apiyi.com).
استدعاء Codestral 2 (إكمال الكود)
from openai import OpenAI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="YOUR_API_KEY",
)
resp = client.chat.completions.create(
model="codestral-latest", # يشير إلى Codestral 25.08
messages=[
{"role": "system", "content": "أنت مهندس بايثون خبير."},
{"role": "user", "content": "أكمل تنفيذ ذاكرة تخزين مؤقت (LRU Cache) عالية الأداء."},
],
temperature=0.2,
max_tokens=512,
)
print(resp.choices[0].message.content)
استدعاء GLM-5.1 (المهام طويلة المدى)
from openai import OpenAI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="YOUR_API_KEY",
)
resp = client.chat.completions.create(
model="glm-5.1",
messages=[
{"role": "system", "content": "أنت وكيل هندسة برمجيات (SWE agent). قم بتحليل المستودع، تشغيل الاختبارات، والتكرار."},
{"role": "user", "content": "قم بإصلاح جميع حالات الاختبار الفاشلة في tests/test_api.py داخل المستودع."},
],
temperature=0.3,
max_tokens=8192,
# يدعم GLM-5.1 استدعاء الدوال (Function Calling) + المخرجات المهيكلة
)
print(resp.choices[0].message.content)
📎 اضغط للعرض: استدعاء خاص بـ FIM (حصري لـ Codestral 2)
# يتم تجميع الموجه (prompt) الخاص بـ FIM الأصلي لـ Codestral عبر البادئة (prefix) واللاحقة (suffix)
prefix = "def binary_search(arr, target):\n "
suffix = "\n return -1"
prompt = f"[PREFIX]{prefix}[SUFFIX]{suffix}[MIDDLE]"
# أرسل الموجه كـ user content إلى codestral-latest للحصول على إكمال عالي الدقة
🎯 نصيحة للربط: يتبع كلا النموذجين مخطط (schema) OpenAI، لذا يمكنك إعادة استخدام نفس كود العمل بمجرد تبديل اسم النموذج. إن استخدام خدمة وكيل API مثل APIYI (apiyi.com) يوفر عليك تكاليف الصيانة الناتجة عن إدارة حسابات Mistral Console و Z.ai بشكل منفصل، بالإضافة إلى إدارة الأرصدة وسياسات تحديد معدل الاستخدام.
استراتيجيات التسعير والنشر لـ Codestral 2 و GLM-5.1
غالبًا ما تكون مرونة التسعير والنشر هي الخطوة الأخيرة في اتخاذ القرار.
مرجع الأسعار المعلنة
| النموذج | سعر الإدخال | سعر الإخراج | ملاحظات |
|---|---|---|---|
| Codestral 2 (25.08) | $0.20 / 1M | $0.60 / 1M | يتبع تسعير سلسلة Codestral |
| GLM-5.1 | يبدأ من $3 تقريبًا (باقات Coding Plan) | نظام باقات | يتوفر خيار الدفع حسب الـ token |
ملاحظة: الأسعار أعلاه تستند إلى المعلومات العامة من المواقع الرسمية والقنوات، وتخضع أسعار الصرف والعروض الترويجية للتغيير في يومها.
مقارنة خيارات النشر
| طريقة النشر | Codestral 2 | GLM-5.1 |
|---|---|---|
| واجهة برمجة التطبيقات السحابية الرسمية | ✅ Mistral Console | ✅ منصة Z.ai |
| بوابة طرف ثالث متوافقة | ✅ (مثل APIYI apiyi.com) | ✅ (مثل APIYI apiyi.com) |
| VPC / سحابة خاصة | ✅ يتطلب ترخيص | ✅ نشر حر MIT |
| الاستدلال المحلي (جهاز واحد) | ✅ محدود ببطاقة A100/GPU استهلاكية | ❌ يتطلب بطاقات متعددة |
| استدعاء الدوال (Function Calling) | مدعوم (عبر chat completions) | ✅ دعم أصلي + MCP |
🎯 نصيحة لتحسين التكلفة: بالنسبة لسيناريوهات بيئة التطوير المتكاملة (IDE) ذات التكرار العالي وعدد الـ tokens القليل لكل طلب، يفضل استخدام Codestral 2 مع التخزين المؤقت؛ أما بالنسبة لسيناريوهات الوكلاء (Agent) ذات التكرار المنخفض وعدد الـ tokens الكبير، فإن نظام باقات GLM-5.1 سيكون أكثر جدوى. يمكنك تكوين كلتا الاستراتيجيتين عبر مجموعات النماذج في APIYI (apiyi.com) لتجنب استنفاد رصيد الحساب الإجمالي بواسطة نموذج واحد.
دليل اختيار السيناريوهات وتجنب الأخطاء لنموذجي Codestral 2 و GLM-5.1
أربعة سيناريوهات نموذجية لاتخاذ القرار
| السيناريو | النموذج الموصى به | السبب الرئيسي |
|---|---|---|
| إضافات الإكمال التلقائي في VSCode / JetBrains | Codestral 2 | دعم أصلي لـ FIM + زمن انتقال منخفض |
| روبوتات إصلاح الأخطاء التلقائية / PR | GLM-5.1 | دورات ذاتية طويلة المدى |
| مساعد مراجعة الكود (تعليقات على ملف واحد) | Codestral 2 | استجابة سريعة وتكلفة منخفضة |
| وكيل (Agent) شامل (اختبار/نشر) | GLM-5.1 | دعم MCP + استدعاء الدوال (Function Calling) |
| توليد هيكل المشروع (Boilerplate) | كلاهما | أي من النموذجين مناسب |
| تحسين أداء نواة تعلم الآلة (ML kernel) | GLM-5.1 | تسريع KernelBench بمقدار 3.6 ضعف |
قائمة التحقق لتجنب الأخطاء الشائعة
- ❌ لا تستخدم Codestral 2 لتشغيل الوكلاء (Agents): على الرغم من انخفاض معدل التوليد غير المنضبط بنسبة 50%، إلا أنه لم يتم تحسينه لاتخاذ القرارات متعددة الخطوات.
- ❌ لا تستخدم GLM-5.1 للإكمال التلقائي بجزء من الثانية: زمن انتقال الرمز الأول (First token latency) لا يوفر تجربة جيدة عند الضغط على مفتاح Tab في بيئة التطوير.
- ❌ لا تعتمد على قائمة تصنيف واحدة: يتفوق GLM-5.1 في اختبار SWE-Bench Pro، بينما لا يتخلف Codestral عن الركب في اختبار HumanEval.
- ✅ قم بإجراء اختبار A/B صغير: استخدم 100 موجه (prompt) نموذجية من عملك، وقم بالتبديل بين معاملات النموذج عبر خدمة APIYI (apiyi.com) لإجراء مقارنة.
الأسئلة الشائعة (FAQ)
س1: لماذا تسمى الصفحة الرسمية Codestral 25.08 وليس Codestral 2؟
تتبع Mistral نمط التسمية <السلسلة>-<السنة>.<الشهر>. ينتمي Codestral 25.08 إلى الجيل الثاني من Codestral (تم إصدار الجيل الأول 24.05، وتطور الجيل الثاني من 25.01 إلى 25.08). اعتاد المجتمع والمطورون على تسمية إصدارات 25.01 وما بعدها بـ "Codestral 2". عند الاستدعاء، يكفي تحديد codestral-latest للوصول إلى أحدث إصدار من الجيل الثاني.
س2: هل سيكون استنتاج GLM-5.1 بطيئاً بسبب امتلاكه 744 مليار معامل؟
في بنية MoE، يتم تفعيل 40 مليار معامل فقط لكل رمز (token)، وبالإضافة إلى تقنية DeepSeek Sparse Attention، تقترب سرعة الاستنتاج الفعلية من نماذج الـ 40 مليار معامل الكثيفة. ومع استراتيجيات الاتصال طويل الأمد والتخزين المؤقت في APIYI (apiyi.com)، يكون زمن الانتقال في سيناريوهات السياق الطويل مقبولاً.
س3: أي النموذجين يمكنه الاستفادة بشكل أفضل من نافذة السياق؟
سعة 256 ألف رمز في Codestral 2 هي "سعة" اسمية، بينما سعة 200 ألف رمز في GLM-5.1 مع تقنية الانتباه المتناثر (Sparse Attention) أكثر ملاءمة لـ "معدل الاستخدام الفعلي". قبل تنفيذ مهام على مستوى المستودع بالكامل، يُنصح بتقدير عدد الرموز الفعلي باستخدام tiktoken أو المرمز (tokenizer) الرسمي لتجنب الاقتطاع غير الضروري.
س4: ما هي الأهمية العملية للأوزان مفتوحة المصدر للشركات؟
يتم إصدار أوزان GLM-5.1 بموجب ترخيص MIT، مما يسمح بنشرها على الشبكات الداخلية وإعادة تدريبها؛ بينما يتطلب الاستخدام التجاري لـ Codestral 2 اتفاقية ترخيص. وهذا يشكل فرقاً كبيراً للشركات المالية والحكومية ذات المتطلبات الصارمة للامتثال. إذا كنت ترغب فقط في تجاوز قيود الوصول الإقليمية، توفر APIYI (apiyi.com) أيضاً بوابة وصول مستقرة ومتاحة محلياً.
س5: هل يمكن استخدام النموذجين معاً؟
نعم، وهذا موصى به. النهج النموذجي هو استخدام Codestral 2 لإكمال الكود في بيئة التطوير، واستخدام GLM-5.1 للوكيل (Agent) في الخلفية، مع استخدام مفاتيح نماذج مختلفة لكل منهما، وإدارة الفوترة مركزياً عبر APIYI (apiyi.com).
س6: نتائج الاختبارات من الشركات المصنعة، ما مدى موثوقيتها؟
نتائج اختبارات Codestral و GLM هي تقارير ذاتية، ولم يتم التحقق بشكل مستقل من نتيجة 58.4 في اختبار SWE-Bench Pro من Z.ai. يُنصح باعتبار نتائج الاختبارات العامة "كحد أقصى للقدرات"، ويجب إجراء اختبارات الرجوع (regression testing) على سيناريوهات عملك الخاصة قبل الاعتماد الفعلي.
ملخص: توصية الاختيار النهائي بين Codestral 2 و GLM-5.1
بالعودة إلى الأسئلة الثلاثة التي طرحناها في البداية:
- إذا كان منتجك يركز على مساعد البرمجة (Copilot)، الإكمال التلقائي (Tab completion)، أو توليد مقتطفات الكود، فاختر Codestral 2. فهو يمثل التوازن الأمثل لهذه السيناريوهات بفضل قدرات FIM، وزمن الاستجابة المنخفض، والسعر التنافسي، ودعم أكثر من 80 لغة برمجة.
- إذا كان منتجك عبارة عن روبوت لمراجعة طلبات السحب (PR Robot)، أو وكيل لإصلاح الأخطاء (Bug fixing agent)، أو وكيل خلفي (Background Agent) يعمل على مهام طويلة، فاختر GLM-5.1. فبفضل بنيته (744B MoE) وتحقيقه لنتيجة 58.4 في اختبار SWE-Bench Pro، بالإضافة إلى قدرته على العمل في حلقات ذاتية طويلة المدى، يعد حالياً الخيار الأقرب إلى Claude Opus 4.6 في عالم المصادر المفتوحة.
- إذا كان منتجك يجمع بين السيناريوهين أعلاه، فإن استخدام كليهما معاً هو الحل الأكثر اقتصادية لعام 2026.
🎯 نصيحة للتنفيذ: ارتقِ باستراتيجية الاختيار من "المفاضلة بين نموذجين" إلى "التنسيق بين نموذجين". من خلال واجهات APIYI (apiyi.com) المتوافقة مع OpenAI، يمكنك ببساطة استخدام حقل واحد في كود العمليات لتمييز "الإكمال السريع / المهام الطويلة"، مما يسمح بالتوجيه التلقائي بين Codestral 2 و GLM-5.1، وتوجيه كل طلب إلى النموذج الأنسب له.
— فريق APIYI (الفريق التقني لـ APIYI apiyi.com)