Dunia Model Bahasa Besar untuk pemrograman di tahun 2026 terbagi menjadi dua kategori produk yang sangat berbeda: kategori pertama adalah "prioritas IDE, pelengkap frekuensi tinggi" yang diwakili oleh Mistral Codestral 2 (versi terbaru saat ini Codestral 25.08), yang berfokus pada Fill-in-the-Middle (FIM), tingkat keberhasilan pelengkap yang tinggi, dan respons instan di 80+ bahasa; kategori kedua adalah "agen jangka panjang" yang diwakili oleh Zhipu GLM-5.1, yang mengandalkan arsitektur MoE 744B dan jendela konteks 200K, dengan keunggulan utama pada kemampuan pemrograman kompleks tingkat SWE-Bench Pro untuk "tugas rekayasa mandiri selama 8 jam".
Kedua jalur ini hampir tidak memiliki irisan dalam hal target pengguna maupun strategi penagihan, namun sering kali dibandingkan dalam pertanyaan "mana yang lebih cocok untuk menulis kode". Artikel ini disusun berdasarkan dokumen resmi Mistral AI (30-07-2025 Codestral 25.08) dan dokumentasi pengembang Z.ai (GLM-5.1, dirilis 27-03-2026) serta sumber bahasa Inggris lainnya. Kami menyajikan tabel keputusan pemilihan yang dapat direplikasi dari 6 dimensi: arsitektur, tolok ukur, jendela konteks, tugas jangka panjang, penyebaran, dan harga, lengkap dengan perbandingan kode akses API untuk kedua model tersebut, guna membantu Anda mengambil keputusan dalam 10 menit.

Perbedaan Posisi Inti antara Codestral 2 dan GLM-5.1
Sebelum mendalami tolok ukur, ada satu hal yang harus dipahami: kedua model ini bukan produk dari kategori yang sama. Menempatkan keduanya dalam dimensi yang sama untuk perbandingan horizontal akan menghasilkan kesimpulan yang sangat menyesatkan.
Penjelasan Singkat
- Codestral 2 (25.08): Model kode khusus yang ditujukan untuk tugas pelengkap dan penyuntingan kode. Arsitektur padat 22B, target pelatihan FIM asli, menekankan pada "respons tingkat detik + tingkat penerimaan tinggi", menjadikannya salah satu standar de facto untuk produk jenis IDE Copilot.
- GLM-5.1: Model unggulan umum yang ditujukan untuk agen umum dan tugas pemrograman jangka panjang. MoE 744B (aktivasi per token sekitar 40B), jendela konteks 200K, mencetak skor 58,4 pada SWE-Bench Pro, melampaui GPT-5.4, Claude Opus 4.6, dan Gemini 3.1 Pro.
Tiga Pertanyaan yang Harus Dijawab Sebelum Memilih
| Pertanyaan | Condong ke Codestral 2 | Condong ke GLM-5.1 |
|---|---|---|
| Skenario utama: pelengkap di dalam IDE atau perbaikan PR mandiri? | Pelengkap IDE | Tugas mandiri multi-langkah |
| Jumlah token per permintaan: puluhan atau puluhan ribu? | Puluhan ~ ribuan | Ribuan ~ belasan ribu |
| Apakah pengguna bisa mentoleransi waktu tunggu puluhan detik? | Tidak bisa | Bisa |
🎯 Saran Pemilihan: Jika 80% pemanggilan berasal dari "pelengkap langkah berikutnya saat menulis satu baris kode", pilih Codestral 2; jika 80% pemanggilan berasal dari "bantu saya memperbaiki bug di repo ini", pilih GLM-5.1. Keduanya dapat diuji secara paralel melalui antarmuka terpadu APIYI apiyi.com, tanpa perlu mengakses Mistral dan Z.ai secara terpisah.
Perbandingan Arsitektur dan Parameter Codestral 2 dan GLM-5.1
Perbedaan arsitektur adalah akar dari semua performa yang dihasilkan nantinya.
Sekilas Spesifikasi Utama
| Item | Codestral 2 (25.08) | GLM-5.1 |
|---|---|---|
| Vendor | Mistral AI | Zhipu AI (Z.ai) |
| Arsitektur | Dense Transformer | Mixture-of-Experts |
| Total Parameter | 22B | 744B |
| Parameter Aktif | 22B | Sekitar 40B (256 pakar, 8 aktif per token) |
| Jendela Konteks | 256K | 200K |
| Output Maksimum | Standar | 128K token |
| Mekanisme Atensi | Standar + Optimasi FIM | DeepSeek Sparse Attention |
| Lisensi | Lisensi Komersial Mistral / MNPL | MIT (Bobot sumber terbuka) |
| Tanggal Rilis | 30-07-2025 (Iterasi terbaru) | 27-03-2026 |
| Cakupan Bahasa Kode | 80+ bahasa utama | Multibahasa umum |
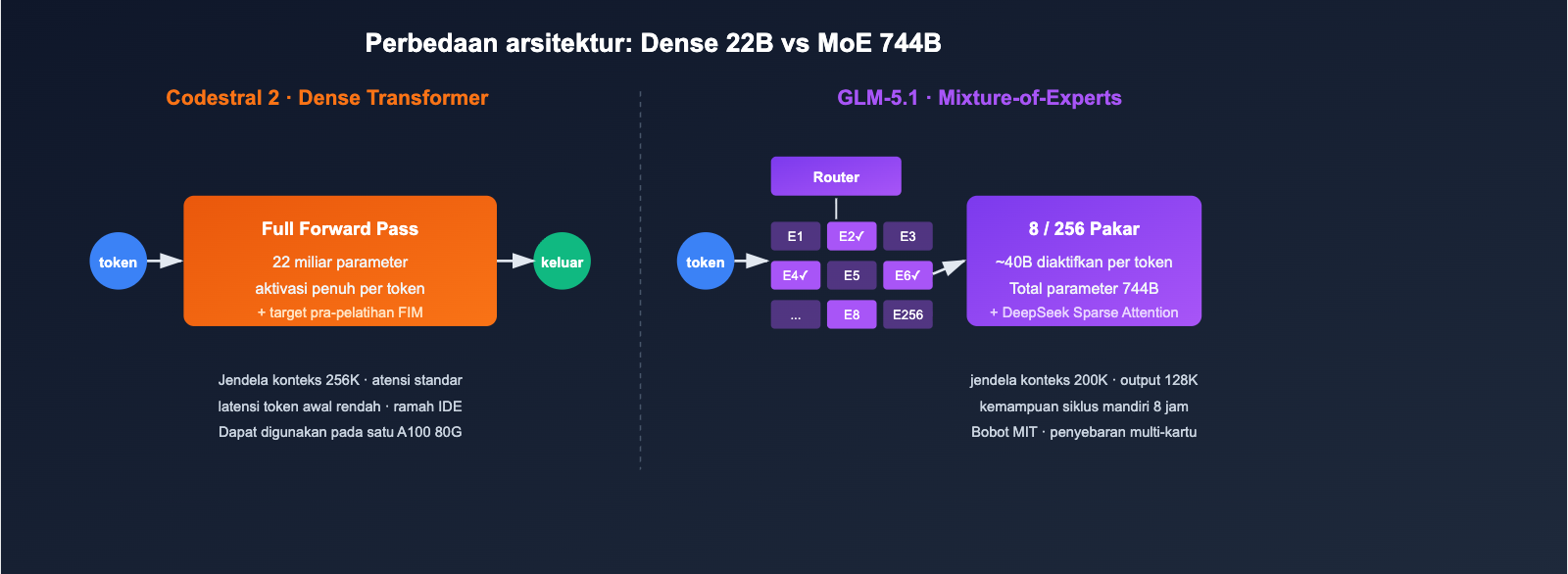
Dampak Langsung dari Perbedaan Arsitektur
- VRAM dan Biaya Deployment: Codestral 2 dengan 22B dapat diinferensi pada satu mesin (A100 80G); GLM-5.1 memerlukan paralelisme multi-GPU atau layanan inferensi terkelola.
- Latensi per Token: Arsitektur Dense pada Codestral 2 memberikan latensi yang lebih stabil pada input pendek; GLM-5.1 dipengaruhi oleh pemilihan router dan atensi jarang, sehingga token pertama sedikit lebih lambat namun unggul pada urutan panjang.
- Strategi Open Source: GLM-5.1 merilis bobot dengan lisensi MIT, yang lebih ramah untuk deployment privat dan pelatihan ulang; Codestral 2 dapat dijalankan secara lokal namun memerlukan lisensi untuk penggunaan komersial.
🎯 Saran Deployment: Tim yang membutuhkan deployment privat sepenuhnya harus memprioritaskan bobot MIT dari GLM-5.1; tim yang hanya ingin integrasi cepat tanpa memikirkan self-hosting dapat menggunakan API APIYI (apiyi.com) untuk memanggil API kedua model tersebut, sehingga menghemat waktu pengadaan dan komunikasi lisensi.
Perbandingan Tolok Ukur Kode Inti Codestral 2 vs GLM-5.1
Skor kedua model berasal dari pengujian mandiri vendor, dan set evaluasi tidak sepenuhnya tumpang tindih. Berikut hanya dicantumkan metrik yang memiliki signifikansi perbandingan langsung.
Keunggulan Codestral 2: Kualitas Penyelesaian & Metrik IDE
| Metrik | Nilai | Penjelasan |
|---|---|---|
| Accepted Completions (Tingkat Penerimaan) | +30% (relatif terhadap 25.01) | Tingkat adopsi IDE di lingkungan produksi |
| Retained Code (Tingkat Retensi) | +10% | Proporsi kode yang disarankan tidak dihapus saat commit |
| Runaway Generations (Generasi Tak Terkendali) | -50% | Penurunan penulisan berlebih yang tidak berguna |
| IFEval v8 (Mengikuti Instruksi) | +5% | Akurasi instruksi |
| Skor Rata-rata MultiPL-E | +5% | Kemampuan kode multibahasa |
| HumanEval (Data generasi sebelumnya 25.01) | 86.6% | Data referensi |
| MBPP (Data generasi sebelumnya 25.01) | 91.2% | Data referensi |
Keunggulan GLM-5.1: Tugas Rekayasa Kompleks
| Metrik | Nilai | Penjelasan |
|---|---|---|
| SWE-Bench Pro | 58.4 | Melampaui GPT-5.4 / Claude Opus 4.6 / Gemini 3.1 Pro |
| Perbandingan Claude Code | 45.3 (Opus 4.6 adalah 47.9) | Mencapai 94,6% dari Opus 4.6 |
| vs Baseline GLM-5 | +28% | Berasal dari optimasi pasca-pelatihan |
| KernelBench Level 3 | Akselerasi 3.6x | Skenario optimasi kernel ML |
| Durasi Tugas Tunggal | Maksimal 8 jam | Siklus "eksperimen-analisis-optimasi" otonom |
Evaluasi Tumpang Tindih Kemampuan
| Kemampuan | Codestral 2 | GLM-5.1 |
|---|---|---|
| Penyelesaian File Tunggal | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| Refactoring Multi-File | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| Lokalisasi Bug + Perbaikan PR | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| Terjemahan Lintas Bahasa | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Agen / Penggunaan Alat | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| Latensi Token Pertama | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
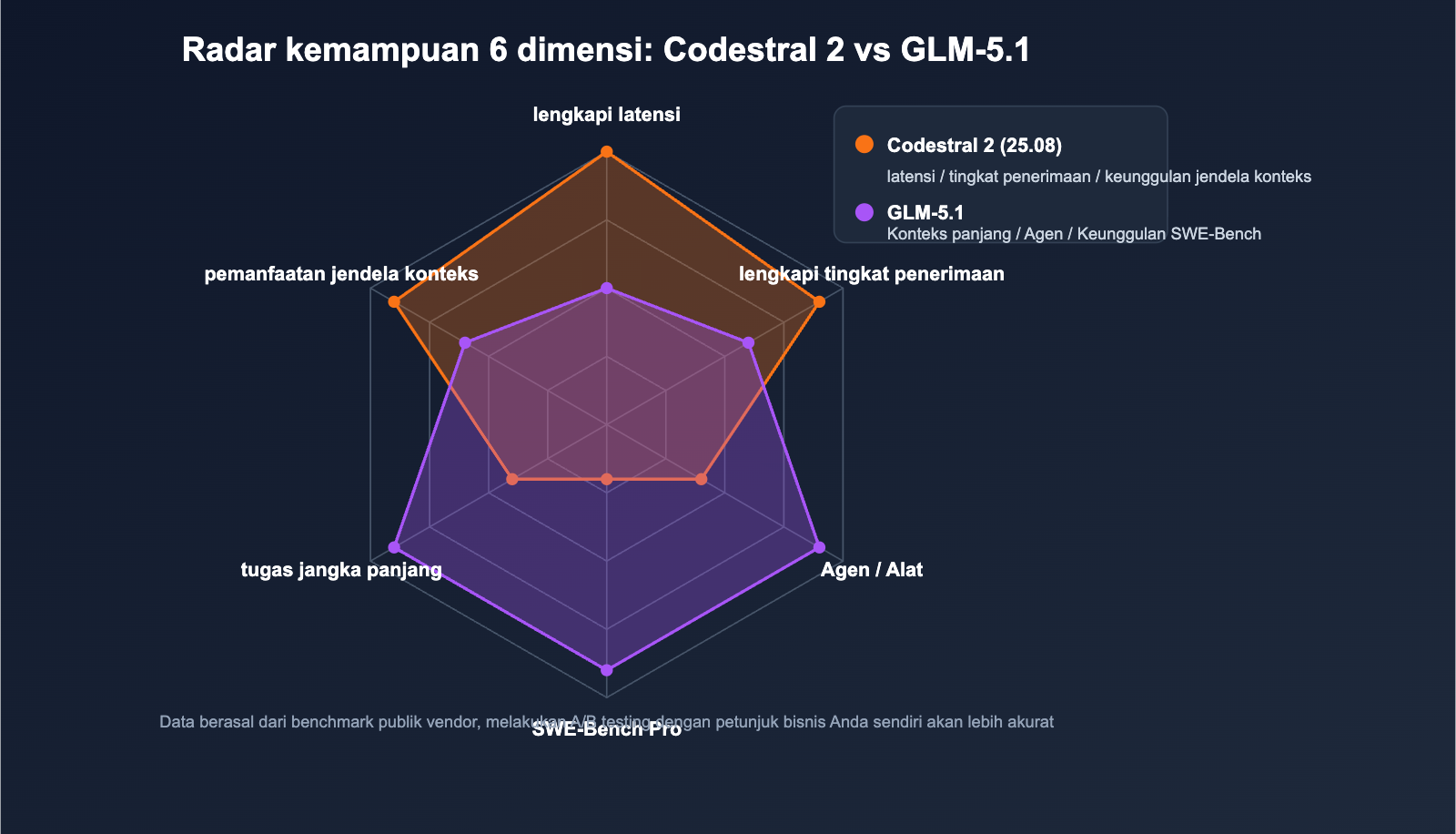
🎯 Tips Membaca Skor: Data resmi biasanya berasal dari pengaturan evaluasi yang relatif optimal, performa bisnis aktual mungkin memiliki fluktuasi 10%~20%. Disarankan untuk menjalankan pengujian A/B dengan basis kode Anda sendiri di APIYI (apiyi.com) sebelum membuat keputusan akhir.
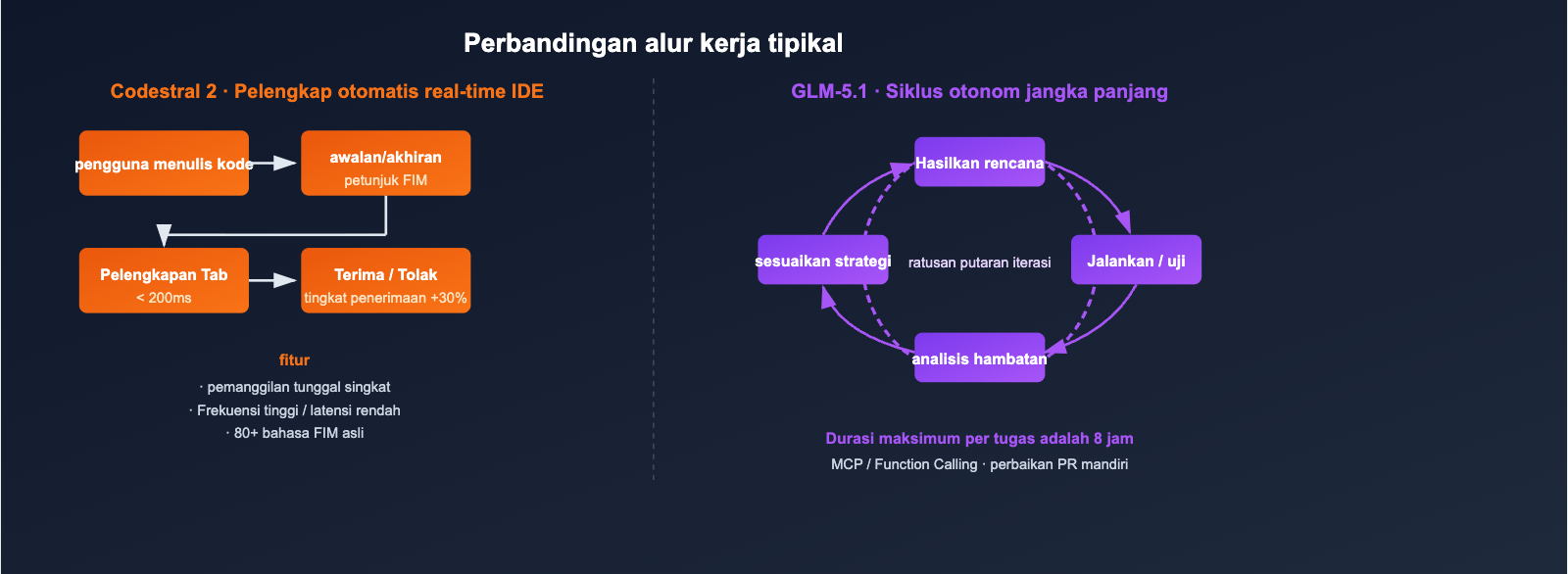
Kemampuan Konteks dan Tugas Jangka Panjang: Codestral 2 vs GLM-5.1
Jendela konteks 256K vs 200K mungkin terlihat mirip secara angka, namun jenis tugas yang dapat ditangani keduanya sangat berbeda.
Konteks 256K Codestral 2: Pelengkapan Seluruh Repositori
Codestral 2 menggunakan konteks 256K terutama untuk "memasukkan seluruh basis kode ke dalam petunjuk", agar model dapat memahami dependensi antar file saat melakukan pelengkapan:
- Cocok untuk: pelengkapan fungsi besar dalam monorepo, Lint Fix seluruh proyek, dan penggantian nama lintas modul.
- Tidak cocok untuk: alur kerja Agent yang memerlukan penalaran multi-langkah, pemanggilan alat, dan penulisan balik hasil.
Konteks 200K + Siklus Otonom 8 Jam GLM-5.1
Terobosan GLM-5.1 bukan terletak pada "seberapa besar konteks yang bisa dimuat", melainkan "berapa lama ia bisa bekerja secara terus-menerus":
- Dalam demo resmi, model dapat melakukan iterasi ratusan kali dalam satu tugas: menjalankan benchmark → mengidentifikasi hambatan → menyesuaikan strategi → menjalankan kembali benchmark.
- DeepSeek Sparse Attention menjaga biaya inferensi untuk urutan panjang 200K tetap dalam kisaran yang wajar.
- Dengan dukungan Function Calling / MCP, model dapat langsung terhubung ke rantai alat eksternal.
Perbandingan Tugas Jangka Panjang yang Khas
| Tugas | Codestral 2 | GLM-5.1 |
|---|---|---|
| Melengkapi fungsi 200 baris | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Membuat PR dari GitHub Issue | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| Mencari dan memperbaiki bug di seluruh repo | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| Optimasi otomatis kernel ML multi-putaran | ⭐ | ⭐⭐⭐⭐⭐ |
| Pelengkapan otomatis di IDE (Tab) | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
🎯 Saran Migrasi Skenario: Bagi tim yang sebelumnya menggunakan Codestral untuk pelengkapan seluruh repositori, jika menemui skenario "sudah lengkap tapi gagal saat dijalankan", cobalah gunakan GLM-5.1 untuk mengambil alih siklus "buat-jalankan-perbaiki". Anda cukup mengganti
base_urlmelalui APIYI apiyi.com untuk menggunakan kembali kode yang kompatibel dengan OpenAI.
Memulai Cepat: Perbandingan Akses API Codestral 2 dan GLM-5.1
Kedua model menyediakan antarmuka yang kompatibel dengan OpenAI, perbedaan utamanya terletak pada nama model dan parameter. Contoh di bawah menunjukkan kode minimal yang dapat digunakan dengan base_url terpadu dari APIYI apiyi.com.
Pemanggilan Codestral 2 (Pelengkapan Kode)
from openai import OpenAI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="YOUR_API_KEY",
)
resp = client.chat.completions.create(
model="codestral-latest", # Mengarah ke Codestral 25.08
messages=[
{"role": "system", "content": "Anda adalah insinyur Python senior."},
{"role": "user", "content": "Lengkapi implementasi cache LRU berkinerja tinggi."},
],
temperature=0.2,
max_tokens=512,
)
print(resp.choices[0].message.content)
Pemanggilan GLM-5.1 (Tugas Jangka Panjang)
from openai import OpenAI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="YOUR_API_KEY",
)
resp = client.chat.completions.create(
model="glm-5.1",
messages=[
{"role": "system", "content": "Anda adalah agen SWE. Analisis repo, jalankan tes, dan lakukan iterasi."},
{"role": "user", "content": "Perbaiki semua kasus uji yang gagal di tests/test_api.py dalam repo."},
],
temperature=0.3,
max_tokens=8192,
# GLM-5.1 mendukung Function Calling + output terstruktur
)
print(resp.choices[0].message.content)
📎 Klik untuk melihat pemanggilan khusus FIM (Eksklusif Codestral 2)
# FIM asli Codestral menggunakan penyusunan petunjuk prefix / suffix
prefix = "def binary_search(arr, target):\n "
suffix = "\n return -1"
prompt = f"[PREFIX]{prefix}[SUFFIX]{suffix}[MIDDLE]"
# Kirim prompt sebagai konten user ke codestral-latest untuk mendapatkan pelengkapan presisi tinggi
🎯 Saran Akses: Kedua model mengikuti skema OpenAI, Anda hanya perlu mengganti nama model untuk menggunakan kembali kode bisnis yang sama. Mengakses melalui APIYI apiyi.com dapat menghemat biaya operasional karena tidak perlu mengelola akun, saldo, dan strategi limitasi Mistral Console serta Z.ai secara terpisah.
Strategi Harga dan Deployment untuk Codestral 2 dan GLM-5.1
Fleksibilitas harga dan deployment sering kali menjadi penentu terakhir dalam pengambilan keputusan.
Referensi Harga Publik
| Model | Harga Input | Harga Output | Keterangan |
|---|---|---|---|
| Codestral 2 (25.08) | $0,20 / 1M | $0,60 / 1M | Mengikuti harga seri Codestral |
| GLM-5.1 | Mulai dari $3 (Paket Coding) | Berbasis paket | Tersedia opsi penagihan per token |
Catatan: Harga di atas didasarkan pada informasi publik dari situs resmi vendor dan saluran terkait. Nilai tukar dan promosi aktual mengikuti ketentuan yang berlaku pada hari tersebut.
Perbandingan Opsi Deployment
| Metode Deployment | Codestral 2 | GLM-5.1 |
|---|---|---|
| API Cloud Resmi | ✅ Mistral Console | ✅ Platform Z.ai |
| Gateway Pihak Ketiga | ✅ (APIYI apiyi.com, dll.) | ✅ (APIYI apiyi.com, dll.) |
| VPC / Cloud Pribadi | ✅ Perlu lisensi | ✅ Deployment bebas MIT |
| Inferensi Lokal (Single Machine) | ✅ Terbatas (A100 tunggal/GPU konsumen) | ❌ Perlu multi-GPU |
| Function Calling | Didukung (via chat completions) | ✅ Dukungan natif + MCP |
🎯 Saran Optimasi Biaya: Untuk skenario IDE dengan frekuensi penyelesaian tinggi namun jumlah token per permintaan sedikit, gunakan Codestral 2 + cache. Untuk skenario Agent dengan frekuensi rendah namun jumlah token besar, paket GLM-5.1 akan jauh lebih hemat. Kedua strategi ini dapat dikonfigurasi berdasarkan grup model di APIYI apiyi.com agar penggunaan akun tidak habis oleh satu model saja.
Panduan Rekomendasi Skenario dan Tips Menghindari Masalah untuk Codestral 2 dan GLM-5.1
Keputusan untuk Empat Skenario Utama
| Skenario | Model Rekomendasi | Alasan Utama |
|---|---|---|
| Plugin pelengkap VSCode / JetBrains | Codestral 2 | FIM natif + latensi rendah |
| Robot perbaikan bug / PR otomatis | GLM-5.1 | Siklus otonom jangka panjang |
| Asisten review kode (komentar per file) | Codestral 2 | Respons cepat, biaya rendah |
| Agent end-to-end (pengujian/deployment) | GLM-5.1 | MCP + Function Calling |
| Membuat kerangka proyek boilerplate | Setara | Keduanya bisa digunakan |
| Optimasi performa ML kernel | GLM-5.1 | Akselerasi KernelBench 3,6x |
Daftar Tips Menghindari Masalah
- ❌ Jangan gunakan Codestral 2 untuk menjalankan Agent: Meskipun tingkat kegagalan pembuatan berkurang 50%, model ini tidak dioptimalkan untuk pengambilan keputusan multi-langkah.
- ❌ Jangan gunakan GLM-5.1 untuk pelengkap tingkat milidetik: Latensi token pertama kurang ramah untuk pengalaman respons tombol Tab di IDE.
- ❌ Jangan hanya melihat satu papan peringkat: GLM-5.1 mungkin unggul di SWE-Bench Pro, namun seri Codestral tidak tertinggal di HumanEval.
- ✅ Lakukan A/B testing skala kecil: Gunakan 100 petunjuk paling khas dari bisnis Anda, lalu jalankan perbandingan dengan mengganti parameter model di APIYI apiyi.com.
FAQ Pertanyaan Umum
Q1: Mengapa halaman resmi menyebutnya Codestral 25.08, bukan Codestral 2?
Konvensi penamaan Mistral adalah <seri>-<tahun>.<bulan>. Codestral 25.08 termasuk dalam iterasi generasi ke-2 dari Codestral (generasi ke-1 dirilis pada 24.05, dan generasi ke-2 berkembang dari 25.01 hingga 25.08). Industri dan komunitas terbiasa menyebut 25.01+ sebagai "Codestral 2". Saat melakukan pemanggilan, cukup tentukan codestral-latest untuk mendapatkan versi terbaru dari generasi ke-2 saat ini.
Q2: Apakah 744B parameter pada GLM-5.1 akan membuat inferensi menjadi lambat?
Dalam arsitektur MoE, hanya 40B parameter yang diaktifkan per token. Ditambah dengan DeepSeek Sparse Attention, kecepatan inferensi aktualnya mendekati model padat (dense) kelas 40B. Dengan dukungan koneksi panjang dan strategi cache dari APIYI apiyi.com, latensi yang dirasakan dalam skenario konteks panjang masih dalam batas yang dapat diterima.
Q3: Model mana yang lebih optimal dalam penggunaan jendela konteks?
Kapasitas 256K pada Codestral 2 lebih ke arah "volume", sedangkan 200K pada GLM-5.1 ditambah dengan sparse attention lebih ramah terhadap "tingkat pemanfaatan nyata". Sebelum melakukan tugas pada seluruh basis kode, disarankan untuk memperkirakan jumlah token aktual menggunakan tiktoken atau tokenizer resmi guna menghindari pemotongan yang tidak perlu.
Q4: Apa arti praktis dari bobot sumber terbuka (open-source weights) bagi perusahaan?
GLM-5.1 merilis bobot di bawah lisensi MIT, sehingga dapat dideploy di jaringan internal dan dilatih ulang; sementara Codestral 2 memerlukan perjanjian lisensi untuk penggunaan komersial. Bagi klien di sektor keuangan atau pemerintah dengan persyaratan kepatuhan yang ketat, perbedaannya sangat signifikan. Jika Anda hanya ingin melewati batasan akses regional, APIYI apiyi.com juga menyediakan pintu masuk yang stabil dan dapat diakses dari dalam negeri.
Q5: Bisakah kedua model digunakan secara bersamaan?
Bisa, dan sangat disarankan. Praktik yang umum adalah menggunakan Codestral 2 untuk pelengkapan kode di IDE, dan GLM-5.1 untuk Agent di latar belakang. Keduanya menggunakan model key yang berbeda, namun penagihannya disatukan melalui APIYI apiyi.com.
Q6: Skor benchmark adalah hasil tes mandiri vendor, seberapa kredibel?
Skor benchmark Codestral dan GLM adalah laporan mandiri, dan skor 58.4 pada SWE-Bench Pro dari Z.ai belum memiliki replikasi independen. Disarankan untuk menjadikan skor publik sebagai "referensi batas kemampuan" dan pastikan untuk melakukan pengujian regresi pada skenario bisnis Anda sebelum implementasi.
Kesimpulan: Saran Pemilihan Akhir Codestral 2 vs GLM-5.1
Kembali ke tiga pertanyaan di awal:
- Jika produk Anda adalah Copilot, pelengkapan tab, atau pembuatan cuplikan kode, pilih Codestral 2. FIM, latensi, harga, dan cakupan 80+ bahasanya adalah keseimbangan terbaik untuk kategori skenario ini.
- Jika produk Anda adalah bot PR, agen perbaikan bug, atau Agent latar belakang yang menjalankan tugas selama 8 jam, pilih GLM-5.1. 744B MoE + SWE-Bench Pro 58.4 + siklus otonom jangka panjang menjadikannya opsi yang paling mendekati Claude Opus 4.6 di kubu sumber terbuka saat ini.
- Jika produk Anda mencakup kedua skenario di atas, menggunakan keduanya secara bersamaan adalah solusi paling ekonomis di tahun 2026.
🎯 Saran Implementasi: Tingkatkan pemilihan model dari "pilih salah satu" menjadi "orkestrasi model ganda". Melalui antarmuka yang kompatibel dengan OpenAI dari APIYI apiyi.com, Anda hanya perlu membedakan "pelengkapan singkat / tugas panjang" dalam kode bisnis Anda. Dengan begitu, sistem akan secara otomatis melakukan perutean antara Codestral 2 dan GLM-5.1, mengirimkan setiap permintaan ke model yang paling sesuai.
— Tim APIYI (Tim Teknis APIYI apiyi.com)