Google Gemma 4 has been officially released, marking its first-ever release under the fully open-source Apache 2.0 license, with four models covering the entire spectrum of computing scenarios from Raspberry Pis to data centers. As the open-source version of the technology behind Gemini 3, Gemma 4 delivers a comprehensive, crushing performance lead over Gemma 3 in reasoning, coding, vision, and long-context capabilities.
Core Value: After reading this article, you'll master the selection of the four Gemma 4 models, their core architectural innovations, the boundaries of their multimodal capabilities, and the hardware requirements for local deployment.

Gemma 4 Quick Overview
Gemma 4 was released on April 2, 2026, at Google Cloud Next. Built on the same research as Gemini 3, it represents the fourth generation of Google's open-source model family.
| Feature | Details |
|---|---|
| Release Date | April 2, 2026 |
| Model Count | 4 (E2B / E4B / 26B-A4B / 31B) |
| License | Apache 2.0 (First time; previously used Google's proprietary license) |
| Max Context | 256K tokens (31B and 26B-A4B) |
| Multimodal | Text + Image + Video + Audio (E2B/E4B) |
| Architecture Highlights | First MoE variant, PLE technology, hybrid attention |
| Available Platforms | Hugging Face, Google AI Studio, Vertex AI, Ollama, etc. |
Gemma 4 Model Lineup
| Model | Effective Params | Total Params | Architecture | Context | Multimodal |
|---|---|---|---|---|---|
| Gemma 4 E2B | 2.3B | 5.1B | Dense | 128K | Text+Image+Video+Audio |
| Gemma 4 E4B | 4.5B | 8B | Dense | 128K | Text+Image+Video+Audio |
| Gemma 4 26B-A4B | 3.8B Active | 25.2B | MoE | 256K | Text+Image+Video |
| Gemma 4 31B | 30.7B | 30.7B | Dense | 256K | Text+Image+Video |
Naming Convention: The "E" prefix stands for "Effective Parameters." Due to PLE technology, the total parameter count is higher than the effective parameter count. 26B-A4B indicates a total of 26B parameters with an MoE architecture that activates 4B parameters per token.
🎯 Technical Tip: The four Gemma 4 models cover everything from edge devices to cloud-based model invocation. If you need to compare performance across multiple open-source models, we recommend using the APIYI (apiyi.com) platform to integrate them uniformly, allowing you to switch and evaluate different models quickly.
Gemma 4 vs. Gemma 3 Performance Comparison: The Largest Generational Leap in History
Google officially claims that Gemma 4 represents "the largest single-generation performance leap in the open-source model landscape." The benchmark data fully supports this statement.
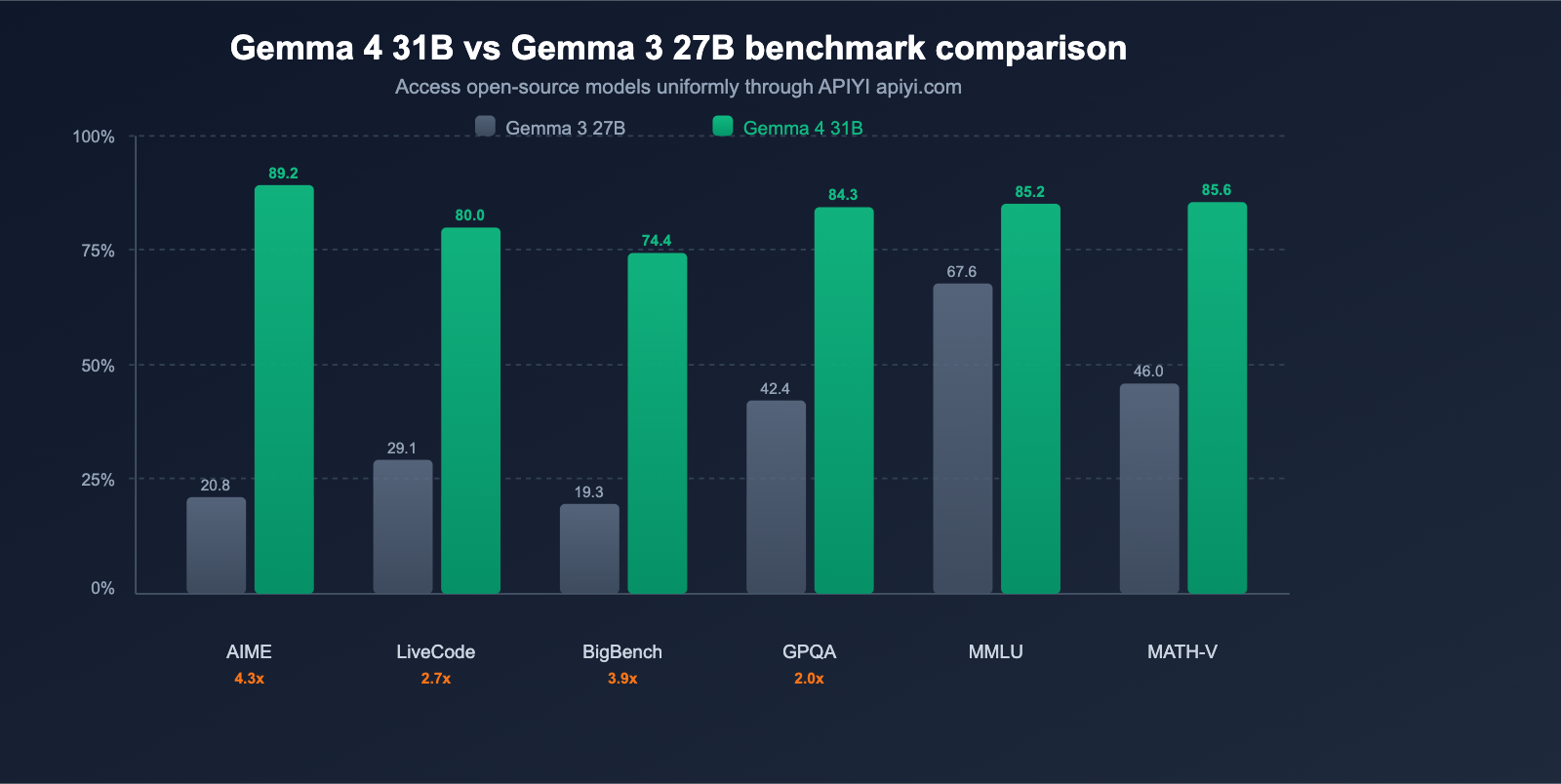
Core Benchmark Comparison
| Benchmark | Gemma 3 27B | Gemma 4 31B | Improvement |
|---|---|---|---|
| AIME 2026 (Math Reasoning) | 20.8% | 89.2% | +68.4 pts (4.3x) |
| LiveCodeBench v6 (Coding) | 29.1% | 80.0% | +50.9 pts (2.7x) |
| BigBench Extra Hard (Reasoning) | 19.3% | 74.4% | +55.1 pts (3.9x) |
| GPQA Diamond (Scientific Reasoning) | 42.4% | 84.3% | +41.9 pts (2.0x) |
| MMLU Pro (Knowledge) | 67.6% | 85.2% | +17.6 pts |
| MATH-Vision (Visual Math) | 46.0% | 85.6% | +39.6 pts |
| MRCR 128K (Long Context) | 13.5% | 66.4% | +52.9 pts |
Key Findings: AIME math reasoning jumped from 20.8% to 89.2%, a 4.3x improvement; LiveCodeBench coding went from 29.1% to 80.0%, a 2.7x improvement. This isn't just an incremental update—it's a generational leap.
Full Benchmark Data for 4 Models
| Benchmark | 31B | 26B-A4B | E4B | E2B |
|---|---|---|---|---|
| MMLU Pro | 85.2% | 82.6% | 69.4% | 60.0% |
| AIME 2026 | 89.2% | 88.3% | 42.5% | 37.5% |
| GPQA Diamond | 84.3% | 82.3% | 58.6% | 43.4% |
| LiveCodeBench v6 | 80.0% | 77.1% | 52.0% | 44.0% |
| MATH-Vision | 85.6% | 82.4% | 59.5% | 52.4% |
| MMMU Pro (Multimodal) | 76.9% | 73.8% | 52.6% | 44.2% |
| Codeforces ELO | 2150 | 1718 | 940 | 633 |
Efficiency Advantages of MoE: The 26B-A4B model achieves approximately 97% of the performance of the 31B Dense model using only 3.8B active parameters, significantly reducing inference costs. On LMArena, the 26B-A4B (~1441 ELO) even outperforms OpenAI's gpt-oss-120B.
💡 Recommendation: Choose the 31B model for peak performance, or the 26B-A4B for the best cost-to-performance ratio (97% of the performance with only 12% of the active parameters). You can quickly compare the actual performance of both versions in specific business scenarios via the APIYI (apiyi.com) platform.
6 Core Architectural Innovations of Gemma 4
Gemma 4 introduces several innovative architectural techniques, which are the fundamental drivers behind its massive leap in performance.
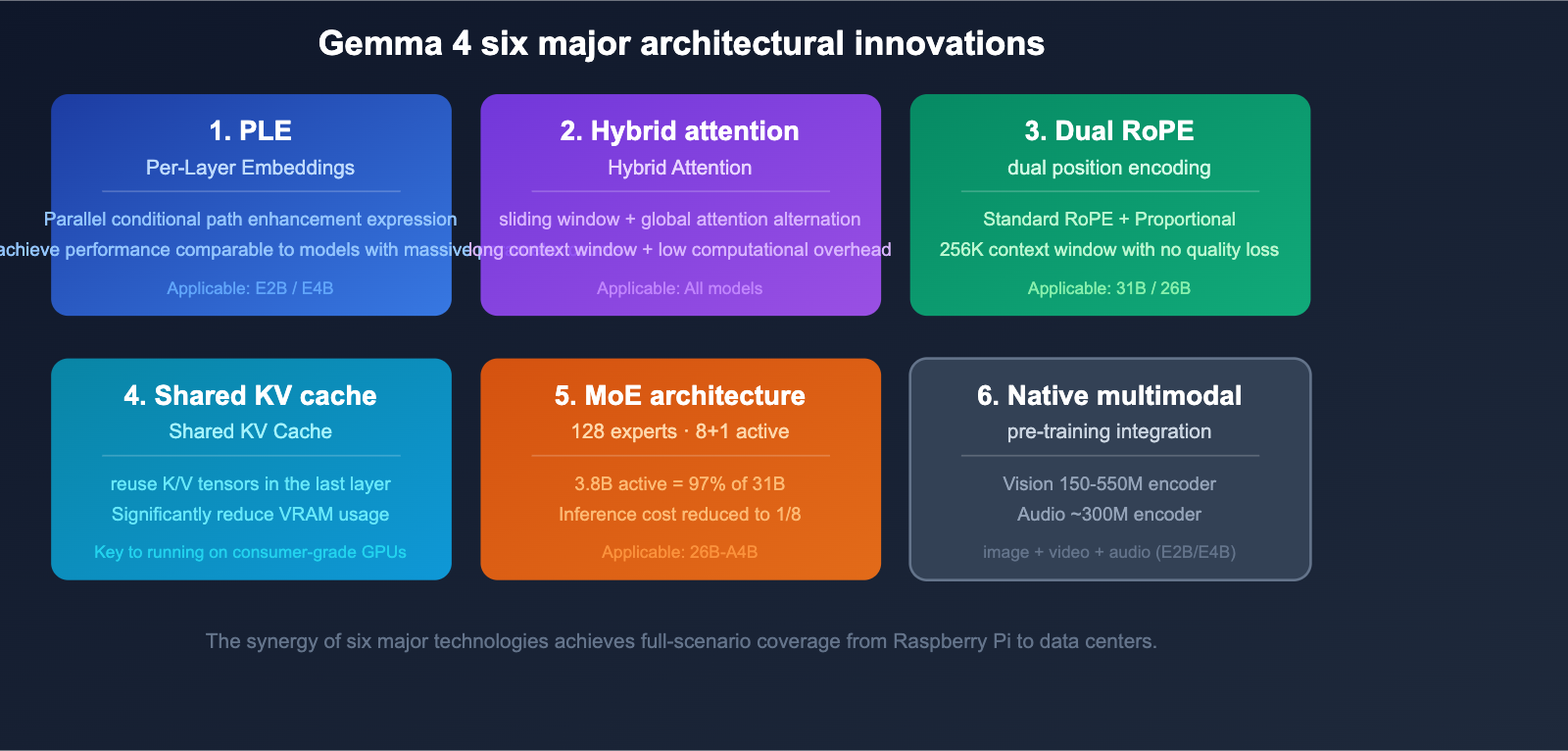
Technique 1: Per-Layer Embeddings (PLE)
PLE adds a parallel conditional path outside the main residual stream, generating dedicated token vectors for each decoder layer. This technique boosts the expressive power of smaller models, allowing the 2.3B effective parameter E2B to achieve performance far exceeding its parameter count.
Technique 2: Hybrid Attention
It alternates between local sliding window attention and global full-context attention layers:
- Sliding Window Layer: Handles local context (E2B/E4B: 512 tokens; 31B/26B: 1024 tokens)
- Global Attention Layer: Handles the full context range
This hybrid design significantly reduces computational overhead while maintaining long context capabilities.
Technique 3: Dual RoPE Positional Encoding
- Sliding window layers use standard RoPE
- Global attention layers use Proportional RoPE
This dual RoPE design makes a 256K context window possible without sacrificing quality.
Technique 4: Shared KV Cache
The last N layers reuse the K/V tensors from the last non-shared layer of the same type, drastically reducing computation and memory footprint. This is one of the key technologies that allows Gemma 4 to run large models on consumer-grade hardware.
Technique 5: MoE (Mixture of Experts) (26B-A4B)
Gemma 4 introduces an MoE variant for the first time:
- 128 small experts
- 8 experts + 1 shared expert activated per token
- Achieves approximately 97% of the performance of a 31B Dense model with only 3.8B active parameters
Technique 6: Native Multimodal
Visual and audio capabilities are integrated directly during the pre-training stage:
- Vision Encoder: E2B/E4B ~150M parameters; 31B/26B ~550M parameters
- Audio Encoder: USM-style conformer, ~300M parameters (E2B/E4B only)
- Supports variable aspect ratio images with configurable token budgets (70-1120 tokens)
title: "Gemma 4: A Deep Dive into Multimodal and Agent Capabilities"
description: "Explore the multimodal features and native agent capabilities of Gemma 4, along with hardware requirements for local deployment."
tags: [Gemma 4, AI Agent, Multimodal, LLM, APIYI]
Gemma 4: A Deep Dive into Multimodal and Agent Capabilities
Gemma 4 isn't just another conversational model; it's a full-fledged multimodal system built with native agent capabilities.
Multimodal Input Capabilities
| Modality | E2B | E4B | 31B | 26B-A4B |
|---|---|---|---|---|
| Text | ✅ | ✅ | ✅ | ✅ |
| Image | ✅ | ✅ | ✅ | ✅ |
| Video (Max 60s, 1fps) | ✅ | ✅ | ✅ | ✅ |
| Audio (Max 30s) | ✅ | ✅ | ❌ | ❌ |
Visual capabilities include:
- Object detection and bounding box output (native JSON format)
- GUI element detection and pointing
- Document/PDF parsing and chart comprehension
- Screen/UI interface understanding
- Interleaved text-and-image input (mixed in any order)
Native Function Calling and Agent Capabilities
Gemma 4 features built-in function calling from the training stage, rather than being added via post-training fine-tuning:
- Native Function Calling: Optimized during training, supporting multi-tool orchestration.
- Extended Thinking: Enable multi-step reasoning by setting
enable_thinking=True. - Structured Output: Native JSON output, perfect for API integration.
- Multi-turn Agent Workflow: Supports autonomous agent loops involving planning, execution, and observation.
# Gemma 4 function calling example (via APIYI unified interface)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the weather for a specific city",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string"}
},
"required": ["city"]
}
}
}
]
response = client.chat.completions.create(
model="gemma-4-31b-it",
messages=[{"role": "user", "content": "What's the weather like in Beijing today?"}],
tools=tools,
tool_choice="auto",
)
🚀 Quick Start: Gemma 4's native function calling makes it an ideal choice for building AI Agents. We recommend using the APIYI (apiyi.com) platform for quick access; it supports OpenAI-compatible interfaces, so no extra adaptation is needed.
Gemma 4 Hardware Guide for Local Deployment
The Apache 2.0 license means you're free to deploy Gemma 4 on any hardware. Here are the requirements for each model.
Hardware Requirements Overview
| Model | Minimum Hardware | Typical Deployment Scenario |
|---|---|---|
| E2B (2.3B) | <1.5GB RAM | Raspberry Pi 5 (133 tok/s prefill, 7.6 tok/s decode) |
| E4B (4.5B) | Mobile-grade NPU/GPU | Mobile devices, Apple Silicon (MLX) |
| 26B-A4B (MoE) | Single consumer GPU (quantized) | Personal workstations, small servers |
| 31B (Dense) | Single 80GB H100 (FP16) | Cloud inference, data centers |
Supported Hardware and Frameworks
| Hardware/Framework | Support Status |
|---|---|
| NVIDIA (H100/B200/RTX) | ✅ Full support |
| Google TPU (Trillium/Ironwood) | ✅ Native optimization |
| Apple Silicon (MLX) | ✅ mlx-community/gemma-4-* |
| AMD ROCm | ✅ Supported |
| Qualcomm NPU (IQ8) | ✅ Mobile inference |
| GGUF (llama.cpp/Ollama) | ✅ 2-bit/4-bit quantization |
| ONNX (WebGPU/Browser) | ✅ onnx-community/gemma-4-* |
| NVIDIA NIM | ✅ Containerized deployment |
The E2B model can run decoding on a Raspberry Pi 5 at 7.6 tokens per second, opening up entirely new possibilities for edge AI applications.
Apache 2.0 License: Why This Time Is Different
Gemma 4 is the first to adopt the Apache 2.0 license, which is a major shift. Previously, all Gemma models were governed by Google's proprietary license, which included specific usage restrictions and termination rights.
License Comparison
| Dimension | Gemma 3 (Google License) | Gemma 4 (Apache 2.0) |
|---|---|---|
| Commercial Use | Restricted | ✅ Completely Free |
| Modification & Distribution | Subject to additional terms | ✅ Completely Free |
| Derivative Models | Restricted | ✅ Completely Free |
| Termination Rights | Google reserves termination rights | ❌ Irrevocable |
| Patent Grant | Limited | ✅ Explicitly Granted |
Apache 2.0 means:
- Businesses can use it in commercial products with peace of mind, free from legal risks.
- You're free to fine-tune and distribute derivative models.
- It aligns with the open-source strategies of Meta Llama and DeepSeek.
- It significantly lowers the compliance barrier for enterprise adoption.
💰 Cost Optimization: Apache 2.0 + local deployment = zero cost for model invocation. For high-inference scenarios, local deployment of Gemma 4 might be more cost-effective than using an API. If you need to compare the cost-benefit ratio between local deployment and API usage, you can first verify the results via the APIYI (apiyi.com) platform before deciding whether to deploy locally.
Getting Started with Gemma 4
Where to Get the Models
| Platform | Available Models | Use Case |
|---|---|---|
| Hugging Face | All 4 versions (base + IT) | General download, research |
| Google AI Studio | 31B, 26B MoE | Free online experience |
| Vertex AI | All 4 versions | Enterprise deployment |
| Ollama / llama.cpp | GGUF quantized versions | Quick local deployment |
| Google AI Edge Gallery | E4B, E2B | Mobile deployment |
One-Click Deployment with Ollama
# Deploy Gemma 4 31B (Recommended)
ollama run gemma4:31b
# Deploy MoE version (High cost-performance)
ollama run gemma4:26b-a4b
# Deploy lightweight version (Edge devices)
ollama run gemma4:e4b
Fine-Tuning Support
Gemma 4 offers a comprehensive fine-tuning ecosystem:
| Framework | Supported Methods |
|---|---|
| TRL | SFT, DPO, Reinforcement Learning (including multimodal) |
| PEFT | LoRA, QLoRA (via bitsandbytes) |
| Vertex AI | Managed training |
| Unsloth Studio | UI-based fine-tuning |
You can freeze the vision and audio encoders and only fine-tune the text component, which significantly reduces fine-tuning costs.
🎯 Technical Advice: We recommend testing the performance of Gemma 4 via the APIYI (apiyi.com) platform first. Once you've confirmed it meets your requirements, you can proceed with local deployment or fine-tuning to avoid wasting resources.
FAQ
Q1: What is the relationship between Gemma 4 and Gemini 3?
Gemma 4 is built upon the same research as Gemini 3; you can think of it as the open-source version of Gemini 3 technology. While Gemma 4 has a smaller model size (max 31B compared to Gemini's hundreds of billions), it utilizes the same core architectural innovations. You can use the APIYI (apiyi.com) platform to access and compare both Gemma 4 and the Gemini series models side-by-side.
Q2: How do I choose between 26B MoE and 31B Dense?
If you have limited hardware or need high throughput, go with the 26B-A4B MoE—it achieves about 97% of the performance of the 31B model while using only 3.8B active parameters. If you're chasing peak performance and have an 80GB GPU, choose the 31B Dense. The inference cost for the MoE version is roughly 1/8th that of the Dense version.
Q3: What scenarios are E2B and E4B best suited for?
E2B is perfect for extreme edge scenarios (Raspberry Pi, IoT devices, mobile), while E4B is great for mobile and lightweight PC deployments. Both support audio input, a feature not available in the 31B and 26B models. If your application requires voice understanding, you must choose E2B or E4B.
Q4: How does the Apache 2.0 license affect commercial use?
Apache 2.0 is one of the most permissive open-source licenses available. It allows for completely free commercial use, modification, and distribution, and it's irrevocable. Unlike the proprietary Google license used for Gemma 3, businesses don't need to worry about compliance risks. You can test the models via the APIYI (apiyi.com) platform first, and once you've confirmed the results, deploy them locally for your commercial products.
Summary
Gemma 4 represents a major upgrade in Google's open-source AI strategy. The Apache 2.0 license removes previous barriers to entry; the four models cover the entire compute spectrum from Raspberry Pi to H100; and with a 4.3x leap in AIME performance and 2.7x in LiveCodeBench, it's a generational jump. Its native multimodal capabilities and function calling make it the top choice for open-source Agent development.
Key Takeaways:
- License: First-time Apache 2.0, fully free for commercial use
- Models: 4 variants covering 2B-31B, including the first MoE variant
- Performance: AIME +68pts (4.3x), LiveCodeBench +51pts (2.7x)
- Multimodal: Native integration of text, image, video, and audio
- Agent: Native function calling + Extended Thinking
- Deployment: Full coverage from Raspberry Pi to H100, supports GGUF/ONNX/MLX frameworks
We recommend using the APIYI (apiyi.com) platform to quickly integrate the Gemma 4 series and compare the real-world performance of different models under a unified interface.
References
- Google Official Blog – Gemma 4 Release:
blog.google/innovation-and-ai/technology/developers-tools/gemma-4/ - Hugging Face – Gemma 4 Model:
huggingface.co/blog/gemma4 - Google AI – Gemma 4 Model Card:
ai.google.dev/gemma/docs/core/model_card_4
This article was written by the APIYI technical team. For more tutorials on using Large Language Models, please visit APIYI at apiyi.com.