Состоялся официальный релиз Google Gemma 4. Модель впервые распространяется по полностью открытой лицензии Apache 2.0 и представлена в 4 вариантах, охватывающих любые сценарии: от Raspberry Pi до мощных дата-центров. Будучи открытой версией технологий, лежащих в основе Gemini 3, Gemma 4 демонстрирует колоссальный прирост производительности в задачах логического вывода, кодинга, работы с визуальными данными и длинным контекстом по сравнению с Gemma 3.
Ключевые моменты: после прочтения статьи вы разберетесь в выборе одной из 4 моделей Gemma 4, узнаете об инновациях в архитектуре, границах мультимодальных возможностей и системных требованиях для локального развертывания.

Краткий обзор ключевых характеристик Gemma 4
Gemma 4 была представлена 2 апреля 2026 года на конференции Google Cloud Next. Модель построена на базе исследований Gemini 3 и является четвертым поколением семейства открытых моделей Google.
| Параметр | Детали |
|---|---|
| Дата выпуска | 2 апреля 2026 г. |
| Количество моделей | 4 (E2B / E4B / 26B-A4B / 31B) |
| Лицензия | Apache 2.0 (впервые, ранее использовалась собственная лицензия Google) |
| Макс. контекст | 256K токенов (для 31B и 26B-A4B) |
| Мультимодальность | Текст + изображения + видео + аудио (E2B/E4B) |
| Особенности архитектуры | Первый вариант MoE, технология PLE, гибридное внимание |
| Платформы | Hugging Face, Google AI Studio, Vertex AI, Ollama и др. |
Обзор четырех моделей Gemma 4
| Модель | Эффективные параметры | Общие параметры | Архитектура | Контекст | Мультимодальность |
|---|---|---|---|---|---|
| Gemma 4 E2B | 2.3B | 5.1B | Dense | 128K | Текст+изобр.+видео+аудио |
| Gemma 4 E4B | 4.5B | 8B | Dense | 128K | Текст+изобр.+видео+аудио |
| Gemma 4 26B-A4B | 3.8B (актив.) | 25.2B | MoE | 256K | Текст+изобр.+видео |
| Gemma 4 31B | 30.7B | 30.7B | Dense | 256K | Текст+изобр.+видео |
Правила именования: Префикс "E" означает "Effective Parameters" (эффективные параметры). Из-за технологии PLE общее количество параметров превышает количество эффективных. 26B-A4B означает архитектуру MoE с 26 млрд общих параметров и 4 млрд активных параметров на токен.
🎯 Технический совет: Четыре модели Gemma 4 охватывают все сценарии: от периферийных устройств до облачных вычислений. Если вам нужно сравнить производительность различных открытых моделей, рекомендую использовать платформу APIYI (apiyi.com) для унифицированного доступа, быстрого переключения и оценки разных моделей.
Gemma 4 против Gemma 3: самый большой скачок производительности в истории
Google официально называет Gemma 4 «самым значительным приростом производительности за одно поколение в сфере открытых моделей». Данные бенчмарков полностью подтверждают это заявление.
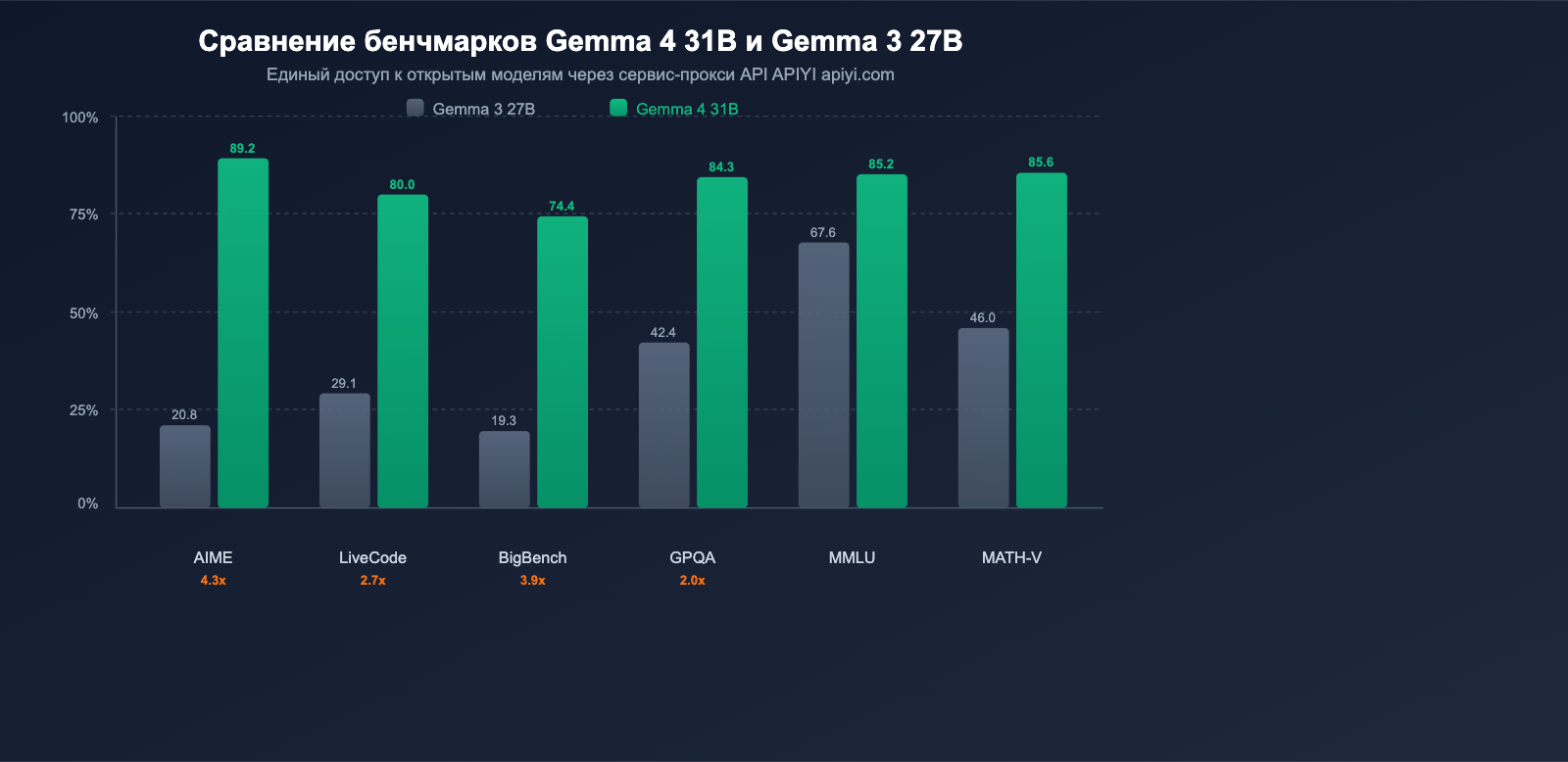
Сравнение основных бенчмарков
| Бенчмарк | Gemma 3 27B | Gemma 4 31B | Прирост |
|---|---|---|---|
| AIME 2026 (мат. рассуждения) | 20.8% | 89.2% | +68.4 п.п. (4.3x) |
| LiveCodeBench v6 (кодинг) | 29.1% | 80.0% | +50.9 п.п. (2.7x) |
| BigBench Extra Hard (рассуждения) | 19.3% | 74.4% | +55.1 п.п. (3.9x) |
| GPQA Diamond (науч. рассуждения) | 42.4% | 84.3% | +41.9 п.п. (2.0x) |
| MMLU Pro (знания) | 67.6% | 85.2% | +17.6 п.п. |
| MATH-Vision (визуальная математика) | 46.0% | 85.6% | +39.6 п.п. |
| MRCR 128K (длинный контекст) | 13.5% | 66.4% | +52.9 п.п. |
Ключевой вывод: Математические рассуждения AIME подскочили с 20.8% до 89.2% (рост в 4.3 раза), а кодинг в LiveCodeBench — с 29.1% до 80.0% (рост в 2.7 раза). Это не просто постепенное улучшение, а настоящий качественный скачок.
Полные данные бенчмарков для 4 моделей
| Бенчмарк | 31B | 26B-A4B | E4B | E2B |
|---|---|---|---|---|
| MMLU Pro | 85.2% | 82.6% | 69.4% | 60.0% |
| AIME 2026 | 89.2% | 88.3% | 42.5% | 37.5% |
| GPQA Diamond | 84.3% | 82.3% | 58.6% | 43.4% |
| LiveCodeBench v6 | 80.0% | 77.1% | 52.0% | 44.0% |
| MATH-Vision | 85.6% | 82.4% | 59.5% | 52.4% |
| MMMU Pro (визуальный) | 76.9% | 73.8% | 52.6% | 44.2% |
| Codeforces ELO | 2150 | 1718 | 940 | 633 |
Преимущество эффективности MoE: Модель 26B-A4B достигает около 97% производительности модели 31B Dense, используя всего 3.8 млрд активных параметров, что значительно снижает стоимость вывода. В рейтинге LMArena модель 26B-A4B (~1441 ELO) даже превзошла gpt-oss-120B от OpenAI.
💡 Совет по выбору: Если вам нужна максимальная производительность — выбирайте 31B. Если ищете оптимальное соотношение цены и качества — 26B-A4B (97% производительности при использовании лишь 12% активных параметров). Платформа APIYI (apiyi.com) позволит вам быстро сравнить реальную работу этих двух версий в ваших бизнес-задачах.
6 ключевых технологических инноваций в архитектуре Gemma 4
В основе впечатляющего скачка производительности Gemma 4 лежит ряд архитектурных инноваций.

Технология 1: Per-Layer Embeddings (PLE)
PLE добавляет параллельный путь условий вне основного остаточного потока, генерируя выделенные векторные представления токенов для каждого слоя декодера. Эта технология повышает выразительную способность небольших моделей, позволяя E2B с 2,3 млрд эффективных параметров достигать производительности, значительно превосходящей модели аналогичного размера.
Технология 2: Гибридное внимание (Hybrid Attention)
Чередование локального внимания со скользящим окном и глобального внимания по всему контексту:
- Слои со скользящим окном: обрабатывают локальный контекст (E2B/E4B: 512 токенов; 31B/26B: 1024 токена).
- Слои глобального внимания: обрабатывают весь объем контекста.
Такой гибридный дизайн позволяет сохранять работу с длинным контекстом при значительном снижении вычислительных затрат.
Технология 3: Позиционное кодирование Dual RoPE
- В слоях со скользящим окном используется стандартный RoPE.
- В слоях глобального внимания используется Proportional RoPE.
Такой двойной дизайн RoPE делает возможным использование контекстного окна в 256 тыс. токенов без потери качества.
Технология 4: Общий KV-кэш
Последние N слоев повторно используют K/V-тензоры последнего неразделяемого слоя того же типа, что значительно сокращает объем вычислений и потребление видеопамяти. Это одна из ключевых технологий, позволяющих Gemma 4 запускать большие модели на потребительском оборудовании.
Технология 5: Смесь экспертов MoE (26B-A4B)
Gemma 4 впервые представляет вариант MoE:
- 128 небольших экспертов.
- На каждый токен активируется 8 экспертов + 1 общий эксперт.
- Достигает около 97% производительности плотной модели 31B при 3,8 млрд активируемых параметров.
Технология 6: Нативная мультимодальность
Возможности работы с визуальными данными и аудио интегрированы непосредственно на этапе предварительного обучения:
- Визуальный энкодер: E2B/E4B ~150 млн параметров; 31B/26B ~550 млн параметров.
- Аудиоэнкодер: conformer в стиле USM, ~300 млн параметров (только для E2B/E4B).
- Поддержка изображений с переменным соотношением сторон, настраиваемый бюджет токенов (70–1120 токенов).
Подробный разбор мультимодальных возможностей и функций агента в Gemma 4
Gemma 4 — это не просто диалоговая модель, а полноценная мультимодальная система с развитыми возможностями агента.
Мультимодальные возможности ввода
| Модальность | E2B | E4B | 31B | 26B-A4B |
|---|---|---|---|---|
| Текст | ✅ | ✅ | ✅ | ✅ |
| Изображения | ✅ | ✅ | ✅ | ✅ |
| Видео (до 60 сек, 1 к/с) | ✅ | ✅ | ✅ | ✅ |
| Аудио (до 30 сек) | ✅ | ✅ | ❌ | ❌ |
Возможности визуального анализа:
- Детекция объектов и вывод ограничивающих рамок (в формате JSON)
- Детекция и наведение на элементы графического интерфейса (GUI)
- Анализ документов/PDF, понимание графиков и диаграмм
- Понимание экранных интерфейсов/UI
- Комбинированный ввод текста и изображений (в любом порядке)
Нативный вызов функций и возможности агента
В Gemma 4 функции вызова встроены на этапе обучения, а не добавлены через дообучение:
- Нативный вызов функций: оптимизирован на этапе обучения, поддерживает оркестрацию нескольких инструментов
- Extended Thinking: можно активировать многошаговые рассуждения через
enable_thinking=True - Структурированный вывод: нативный JSON-вывод, идеально подходит для интеграции через API
- Многошаговые процессы агента: поддержка автономного цикла агента «планирование-выполнение-наблюдение»
# Пример вызова функции Gemma 4 (через единый интерфейс APIYI)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Получить погоду для указанного города",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string"}
},
"required": ["city"]
}
}
}
]
response = client.chat.completions.create(
model="gemma-4-31b-it",
messages=[{"role": "user", "content": "Какая сегодня погода в Пекине?"}],
tools=tools,
tool_choice="auto",
)
🚀 Быстрый старт: Нативная поддержка вызова функций делает Gemma 4 идеальным выбором для создания AI-агентов. Рекомендуем использовать платформу APIYI (apiyi.com) для быстрого подключения — она поддерживает интерфейсы, совместимые с OpenAI, и не требует дополнительной адаптации.
Руководство по аппаратному обеспечению для локального развертывания Gemma 4
Лицензия Apache 2.0 означает, что вы можете свободно развертывать Gemma 4 на любом оборудовании. Ниже приведены требования к железу для каждой модели.
Обзор аппаратных требований
| Модель | Минимальное оборудование | Типичный сценарий развертывания |
|---|---|---|
| E2B (2.3B) | <1.5 ГБ ОЗУ | Raspberry Pi 5 (133 ток/с префилл, 7.6 ток/с декодинг) |
| E4B (4.5B) | NPU/GPU мобильного уровня | Мобильные устройства, Apple Silicon (MLX) |
| 26B-A4B (MoE) | Один потребительский GPU (квантование) | Персональные рабочие станции, небольшие серверы |
| 31B (Dense) | Один 80GB H100 (FP16) | Облачный инференс, дата-центры |
Поддерживаемое оборудование и фреймворки
| Оборудование/Фреймворк | Поддержка |
|---|---|
| NVIDIA (H100/B200/RTX) | ✅ Полная поддержка всей линейки |
| Google TPU (Trillium/Ironwood) | ✅ Нативная оптимизация |
| Apple Silicon (MLX) | ✅ mlx-community/gemma-4-* |
| AMD ROCm | ✅ Поддерживается |
| Qualcomm NPU (IQ8) | ✅ Инференс на мобильных устройствах |
| GGUF (llama.cpp/Ollama) | ✅ 2-битное/4-битное квантование |
| ONNX (WebGPU/браузер) | ✅ onnx-community/gemma-4-* |
| NVIDIA NIM | ✅ Контейнеризированное развертывание |
Модель E2B может работать на Raspberry Pi 5 со скоростью 7.6 токенов в секунду при декодировании, что открывает совершенно новые возможности для граничных (edge) AI-приложений.
Лицензия Apache 2.0: почему в этот раз всё иначе
Gemma 4 впервые выпускается под лицензией Apache 2.0, и это серьезный сдвиг. Ранее все модели Gemma использовали проприетарные лицензии Google, которые накладывали специфические ограничения на использование и давали компании право на отзыв лицензии.
Сравнение лицензий
| Параметр | Gemma 3 (лицензия Google) | Gemma 4 (Apache 2.0) |
|---|---|---|
| Коммерческое использование | С ограничениями | ✅ Полная свобода |
| Изменение и дистрибуция | Требует соблюдения доп. условий | ✅ Полная свобода |
| Производные модели | Ограничено | ✅ Полная свобода |
| Право на отзыв | Google сохраняет право отзыва | ❌ Безотзывно |
| Лицензирование патентов | Ограничено | ✅ Явно предоставлено |
Что означает Apache 2.0:
- Компании могут без опасений использовать модель в коммерческих продуктах без юридических рисков.
- Можно свободно дообучать (файн-тюнить) и распространять производные модели.
- Стратегия теперь соответствует подходам Meta Llama и DeepSeek.
- Значительно снижен порог комплаенса для корпоративного внедрения.
💰 Оптимизация затрат: Apache 2.0 + локальное развертывание = нулевые расходы на вызов модели. Для сценариев с большим объемом инференса локальный запуск Gemma 4 может оказаться выгоднее, чем использование API. Если нужно сравнить экономическую эффективность локального запуска и API, вы можете сначала протестировать качество через платформу APIYI (apiyi.com), а затем принять решение о локальном развертывании.
Получение модели Gemma 4 и быстрый старт
Где скачать модели
| Платформа | Доступные модели | Назначение |
|---|---|---|
| Hugging Face | Все 4 версии (base + IT) | Универсальное скачивание, исследования |
| Google AI Studio | 31B, 26B MoE | Бесплатный онлайн-тест |
| Vertex AI | Все 4 версии | Корпоративное развертывание |
| Ollama / llama.cpp | GGUF-квантованные версии | Быстрый локальный запуск |
| Google AI Edge Gallery | E4B, E2B | Развертывание на мобильных устройствах |
Развертывание в один клик через Ollama
# Запуск Gemma 4 31B (рекомендуется)
ollama run gemma4:31b
# Запуск MoE-версии (высокая эффективность)
ollama run gemma4:26b-a4b
# Запуск облегченной версии (для периферийных устройств)
ollama run gemma4:e4b
Поддержка дообучения (файн-тюнинга)
Gemma 4 предлагает полноценную экосистему для дообучения:
| Фреймворк | Поддерживаемые методы |
|---|---|
| TRL | SFT, DPO, обучение с подкреплением (включая мультимодальные задачи) |
| PEFT | LoRA, QLoRA (через bitsandbytes) |
| Vertex AI | Управляемое обучение |
| Unsloth Studio | Дообучение через UI |
Визуальные и аудио-энкодеры можно заморозить, дообучая только текстовую часть, что значительно снижает затраты на обучение.
🎯 Технический совет: Рекомендуем сначала протестировать возможности Gemma 4 через API на платформе APIYI (apiyi.com). Убедитесь, что модель соответствует вашим задачам, прежде чем приступать к локальному развертыванию или дообучению, чтобы избежать напрасной траты ресурсов.
Часто задаваемые вопросы
Q1: Какова связь между Gemma 4 и Gemini 3?
Gemma 4 построена на тех же исследованиях, что и Gemini 3, и её можно считать версией технологий Gemini 3 с открытым исходным кодом. Модели Gemma 4 имеют меньший масштаб (максимум 31B против сотен миллиардов у Gemini), но используют те же инновации в архитектуре ядра. Через платформу APIYI apiyi.com вы можете одновременно использовать Gemma 4 и модели серии Gemini для сравнительного анализа.
Q2: Что выбрать: 26B MoE или 31B Dense?
Если у вас ограниченное аппаратное обеспечение или требуется высокая пропускная способность, выбирайте 26B-A4B MoE — она достигает около 97% производительности 31B, используя при этом всего 3,8B активных параметров. Если же вы стремитесь к максимальной производительности и у вас есть GPU на 80 ГБ, выбирайте 31B Dense. Стоимость инференса версии MoE составляет примерно 1/8 от стоимости версии Dense.
Q3: Для каких сценариев подходят E2B и E4B?
E2B подходит для экстремальных граничных сценариев (Raspberry Pi, IoT-устройства, мобильные телефоны), а E4B — для мобильных устройств и легких ПК. Обе модели поддерживают ввод аудио, чего нет у 31B и 26B. Если вашему приложению требуется понимание речи, обязательно выбирайте E2B или E4B.
Q4: Как лицензия Apache 2.0 влияет на коммерческое использование?
Apache 2.0 — одна из самых либеральных лицензий с открытым кодом, которая разрешает полностью свободное коммерческое использование, модификацию и распространение, причем без возможности отзыва. В отличие от собственной лицензии Google для Gemma 3, предприятиям не нужно беспокоиться о комплаенс-рисках. Вы можете сначала протестировать API на платформе APIYI apiyi.com, а после подтверждения эффективности развернуть модель локально для коммерческого продукта.
Итоги
Gemma 4 — это значительный шаг вперед в стратегии Google по развитию ИИ с открытым исходным кодом. Лицензия Apache 2.0 устраняет прежние барьеры использования; четыре модели охватывают все сценарии вычислений — от Raspberry Pi до H100; скачок производительности в 4,3 раза в AIME и в 2,7 раза в LiveCodeBench; нативная мультимодальность и вызов функций делают её предпочтительной базовой моделью для разработки агентов с открытым кодом.
Краткий обзор ключевых моментов:
- Лицензия: Впервые Apache 2.0, полная свобода для коммерции
- Модели: 4 версии от 2B до 31B, включая первый вариант MoE
- Производительность: AIME +68 баллов (4,3x), LiveCodeBench +51 балл (2,7x)
- Мультимодальность: текст + изображения + видео + аудио, нативная интеграция
- Агенты: нативный вызов функций + Extended Thinking
- Развертывание: от Raspberry Pi до H100, поддержка фреймворков GGUF/ONNX/MLX
Рекомендуем быстро подключиться к серии моделей Gemma 4 через APIYI apiyi.com, чтобы сравнить фактическую эффективность различных моделей в рамках единого интерфейса.
Справочные материалы
- Официальный блог Google — Релиз Gemma 4:
blog.google/innovation-and-ai/technology/developers-tools/gemma-4/ - Hugging Face — Модель Gemma 4:
huggingface.co/blog/gemma4 - Google AI — Карточка модели Gemma 4:
ai.google.dev/gemma/docs/core/model_card_4
Эта статья подготовлена технической командой APIYI Team. Больше руководств по использованию AI-моделей вы найдете на сайте APIYI — apiyi.com