Google Gemma 4가 공식 출시되었습니다. 최초로 Apache 2.0 완전 오픈소스 라이선스를 채택했으며, 라즈베리 파이부터 데이터 센터까지 모든 컴퓨팅 환경을 아우르는 4가지 모델을 선보였습니다. Gemini 3와 동일한 기술을 기반으로 하는 오픈소스 버전인 Gemma 4는 추론, 코딩, 시각, 긴 컨텍스트 윈도우 등 모든 측면에서 Gemma 3를 압도하는 성능 향상을 보여줍니다.
핵심 가치: 이 글을 통해 Gemma 4의 4가지 모델 선택 가이드, 핵심 아키텍처 혁신, 멀티모달 능력의 한계, 그리고 로컬 배포를 위한 하드웨어 요구 사항을 완벽하게 파악하실 수 있습니다.

Gemma 4 핵심 정보 요약
Gemma 4는 2026년 4월 2일 Google Cloud Next에서 발표되었습니다. Gemini 3와 동일한 연구 결과를 기반으로 구축된 Google 오픈소스 모델 제품군의 4세대 모델입니다.
| 정보 항목 | 상세 내용 |
|---|---|
| 발표일 | 2026년 4월 2일 |
| 모델 수 | 4종 (E2B / E4B / 26B-A4B / 31B) |
| 라이선스 | Apache 2.0 (최초 적용, 이전은 Google 자체 라이선스) |
| 최대 컨텍스트 | 256K 토큰 (31B 및 26B-A4B) |
| 멀티모달 | 텍스트 + 이미지 + 비디오 + 오디오 (E2B/E4B) |
| 아키텍처 특징 | 최초의 MoE 변형, PLE 기술, 하이브리드 어텐션 |
| 지원 플랫폼 | Hugging Face, Google AI Studio, Vertex AI, Ollama 등 |
Gemma 4 4가지 모델 한눈에 보기
| 모델 | 유효 파라미터 | 총 파라미터 | 아키텍처 | 컨텍스트 | 멀티모달 |
|---|---|---|---|---|---|
| Gemma 4 E2B | 2.3B | 5.1B | Dense | 128K | 텍스트+이미지+비디오+오디오 |
| Gemma 4 E4B | 4.5B | 8B | Dense | 128K | 텍스트+이미지+비디오+오디오 |
| Gemma 4 26B-A4B | 3.8B 활성 | 25.2B | MoE | 256K | 텍스트+이미지+비디오 |
| Gemma 4 31B | 30.7B | 30.7B | Dense | 256K | 텍스트+이미지+비디오 |
명명 규칙: "E" 접두사는 "Effective Parameters"(유효 파라미터)를 의미하며, PLE 기술로 인해 총 파라미터가 유효 파라미터보다 큽니다. 26B-A4B는 총 파라미터 26B, 토큰당 활성 파라미터 4B인 MoE 아키텍처를 뜻합니다.
🎯 기술 제안: Gemma 4의 4가지 모델은 엣지 디바이스부터 클라우드 추론까지 모든 시나리오를 커버합니다. 여러 오픈소스 모델 간의 성능을 비교해야 한다면, APIYI(apiyi.com) 플랫폼을 통해 통합 접속하여 모델을 빠르게 전환하고 평가해 보시길 권장합니다.
Gemma 4 vs Gemma 3 성능 비교: 역사상 가장 큰 세대 간 도약
Google은 공식적으로 Gemma 4가 "오픈 소스 모델 분야에서 가장 큰 단일 세대 성능 향상"을 이루었다고 발표했습니다. 벤치마크 데이터는 이러한 주장을 완벽하게 뒷받침합니다.
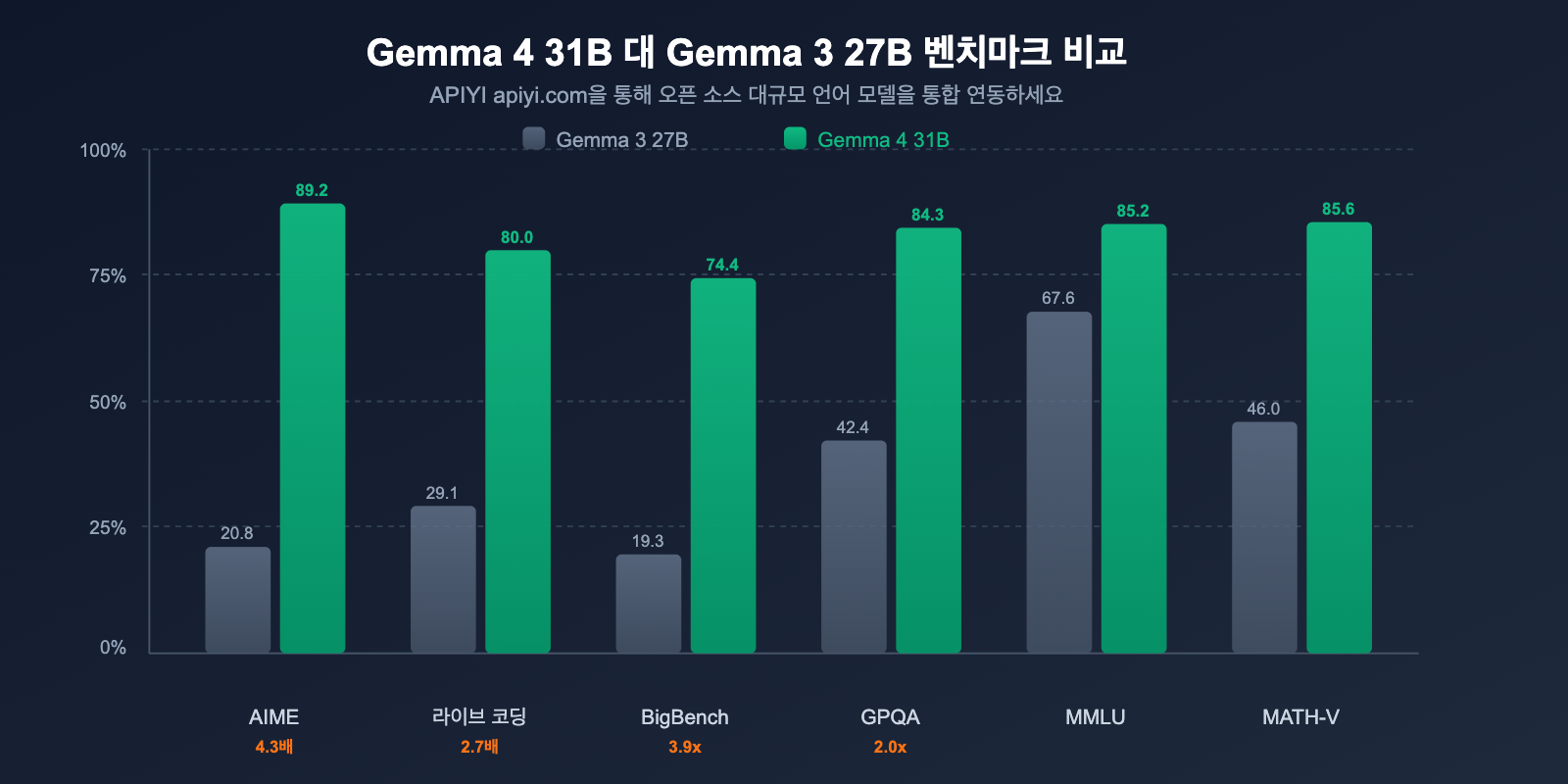
핵심 벤치마크 비교
| 벤치마크 | Gemma 3 27B | Gemma 4 31B | 향상 폭 |
|---|---|---|---|
| AIME 2026 (수학 추론) | 20.8% | 89.2% | +68.4 pts (4.3x) |
| LiveCodeBench v6 (코딩) | 29.1% | 80.0% | +50.9 pts (2.7x) |
| BigBench Extra Hard (추론) | 19.3% | 74.4% | +55.1 pts (3.9x) |
| GPQA Diamond (과학 추론) | 42.4% | 84.3% | +41.9 pts (2.0x) |
| MMLU Pro (지식) | 67.6% | 85.2% | +17.6 pts |
| MATH-Vision (시각 수학) | 46.0% | 85.6% | +39.6 pts |
| MRCR 128K (긴 컨텍스트 윈도우) | 13.5% | 66.4% | +52.9 pts |
주요 발견: AIME 수학 추론은 20.8%에서 89.2%로 4.3배 향상되었으며, LiveCodeBench 코딩은 29.1%에서 80.0%로 2.7배 향상되었습니다. 이는 점진적인 개선이 아닌 세대 간의 비약적인 도약입니다.
4개 모델 전체 벤치마크 데이터
| 벤치마크 | 31B | 26B-A4B | E4B | E2B |
|---|---|---|---|---|
| MMLU Pro | 85.2% | 82.6% | 69.4% | 60.0% |
| AIME 2026 | 89.2% | 88.3% | 42.5% | 37.5% |
| GPQA Diamond | 84.3% | 82.3% | 58.6% | 43.4% |
| LiveCodeBench v6 | 80.0% | 77.1% | 52.0% | 44.0% |
| MATH-Vision | 85.6% | 82.4% | 59.5% | 52.4% |
| MMMU Pro (시각) | 76.9% | 73.8% | 52.6% | 44.2% |
| Codeforces ELO | 2150 | 1718 | 940 | 633 |
MoE의 효율성 이점: 26B-A4B 모델은 3.8B 활성 파라미터만으로 31B Dense 모델 성능의 약 97%를 달성하여 추론 비용을 크게 절감했습니다. LMArena에서 26B-A4B(~1441 ELO)는 OpenAI의 gpt-oss-120B를 능가하기도 했습니다.
💡 선택 가이드: 최고의 성능을 원하신다면 31B를, 가성비를 중시하신다면 26B-A4B(12%의 활성 파라미터로 97% 성능 구현)를 추천합니다. APIYI(apiyi.com) 플랫폼을 통해 두 버전의 실제 비즈니스 시나리오별 성능을 빠르게 비교해 보세요.
Gemma 4 아키텍처 혁신 6대 핵심 기술
Gemma 4는 아키텍처 차원에서 여러 혁신적인 기술을 도입했으며, 이것이 바로 성능 비약의 근본적인 이유입니다.

기술 1: Per-Layer Embeddings (PLE)
PLE는 메인 잔차 스트림(residual stream) 외에 병렬 조건부 경로를 추가하여, 각 디코더 레이어마다 전용 토큰 벡터를 생성합니다. 이 기술은 소형 모델의 표현력을 향상시켜, 2.3B 유효 파라미터를 가진 E2B 모델이 그 파라미터 규모를 훨씬 뛰어넘는 성능을 발휘하게 합니다.
기술 2: 하이브리드 어텐션 (Hybrid Attention)
로컬 슬라이딩 윈도우 어텐션과 글로벌 전체 컨텍스트 어텐션 레이어를 교차 사용합니다.
- 슬라이딩 윈도우 레이어: 로컬 컨텍스트 처리 (E2B/E4B: 512 토큰; 31B/26B: 1024 토큰)
- 글로벌 어텐션 레이어: 전체 컨텍스트 범위 처리
이러한 하이브리드 설계는 긴 컨텍스트 처리 능력을 유지하면서도 계산 비용을 크게 절감합니다.
기술 3: Dual RoPE 위치 인코딩
- 슬라이딩 윈도우 레이어는 표준 RoPE를 사용합니다.
- 글로벌 어텐션 레이어는 Proportional RoPE를 사용합니다.
이러한 이중 RoPE 설계 덕분에 품질 저하 없이 256K 컨텍스트를 구현할 수 있게 되었습니다.
기술 4: 공유 KV 캐시
마지막 N개 레이어에서 동일 유형의 마지막 비공유 레이어의 K/V 텐서를 재사용하여 계산량과 메모리 점유율을 대폭 줄였습니다. 이는 Gemma 4가 소비자용 하드웨어에서도 대규모 언어 모델을 구동할 수 있게 하는 핵심 기술 중 하나입니다.
기술 5: MoE 전문가 혼합 (26B-A4B)
Gemma 4는 처음으로 MoE 변형 모델을 도입했습니다.
- 128개의 소형 전문가(expert)
- 토큰당 8개의 전문가 + 1개의 공유 전문가 활성화
- 3.8B 활성화 파라미터로 31B Dense 모델 성능의 약 97% 달성
기술 6: 네이티브 멀티모달
시각 및 오디오 기능을 사전 학습 단계에서 직접 통합했습니다.
- 시각 인코더: E2B/E4B 약 150M 파라미터; 31B/26B 약 550M 파라미터
- 오디오 인코더: USM 스타일 conformer, 약 300M 파라미터 (E2B/E4B에만 적용)
- 가변 종횡비 이미지 지원, 토큰 예산 구성 가능 (70-1120 토큰)
Gemma 4 멀티모달 및 에이전트 능력 상세 분석
Gemma 4는 단순한 대화형 모델을 넘어, 완벽한 에이전트 능력을 갖춘 멀티모달 시스템입니다.
멀티모달 입력 능력
| 모달리티 | E2B | E4B | 31B | 26B-A4B |
|---|---|---|---|---|
| 텍스트 | ✅ | ✅ | ✅ | ✅ |
| 이미지 | ✅ | ✅ | ✅ | ✅ |
| 비디오 (최대 60초, 1fps) | ✅ | ✅ | ✅ | ✅ |
| 오디오 (최대 30초) | ✅ | ✅ | ❌ | ❌ |
시각적 능력 범위:
- 객체 탐지 및 바운딩 박스 출력 (네이티브 JSON 형식)
- GUI 요소 탐지 및 포인팅
- 문서/PDF 해석, 차트 이해
- 화면/UI 인터페이스 이해
- 텍스트-이미지 교차 입력 (순서 무관 혼합 가능)
네이티브 함수 호출 및 에이전트 능력
Gemma 4는 학습 단계부터 함수 호출 능력을 내장하고 있어, 별도의 파인튜닝 없이도 강력한 성능을 발휘합니다.
- 네이티브 함수 호출: 학습 단계에서 직접 최적화되어 다중 도구 오케스트레이션을 지원합니다.
- Extended Thinking:
enable_thinking=True를 통해 다단계 추론을 활성화할 수 있습니다. - 구조화된 출력: API 통합에 최적화된 네이티브 JSON 출력을 지원합니다.
- 다중 턴 에이전트 프로세스: 계획-실행-관찰로 이어지는 자율 에이전트 루프를 지원합니다.
# Gemma 4 함수 호출 예시 (APIYI 통합 인터페이스 사용)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "지정된 도시의 날씨를 가져옵니다.",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string"}
},
"required": ["city"]
}
}
}
]
response = client.chat.completions.create(
model="gemma-4-31b-it",
messages=[{"role": "user", "content": "베이징 오늘 날씨 어때?"}],
tools=tools,
tool_choice="auto",
)
🚀 빠른 시작: Gemma 4의 네이티브 함수 호출 기능은 AI 에이전트를 구축하는 데 최적입니다. OpenAI 호환 인터페이스를 지원하며 별도의 적응 작업이 필요 없는 APIYI(apiyi.com) 플랫폼을 통해 빠르게 시작해 보세요.
Gemma 4 로컬 배포 하드웨어 가이드
Apache 2.0 라이선스를 통해 어떤 하드웨어에서든 자유롭게 Gemma 4를 배포할 수 있습니다. 각 모델별 하드웨어 요구 사항은 다음과 같습니다.
하드웨어 요구 사항 요약
| 모델 | 최소 하드웨어 | 일반적인 배포 시나리오 |
|---|---|---|
| E2B (2.3B) | 1.5GB 미만 메모리 | 라즈베리 파이 5 (133 tok/s 프리필, 7.6 tok/s 디코딩) |
| E4B (4.5B) | 모바일급 NPU/GPU | 모바일 기기, Apple Silicon (MLX) |
| 26B-A4B (MoE) | 단일 소비자용 GPU (양자화) | 개인 워크스테이션, 소형 서버 |
| 31B (Dense) | 단일 80GB H100 (FP16) | 클라우드 추론, 데이터 센터 |
지원되는 하드웨어 및 프레임워크
| 하드웨어/프레임워크 | 지원 여부 |
|---|---|
| NVIDIA (H100/B200/RTX) | ✅ 전 시리즈 지원 |
| Google TPU (Trillium/Ironwood) | ✅ 네이티브 최적화 |
| Apple Silicon (MLX) | ✅ mlx-community/gemma-4-* |
| AMD ROCm | ✅ 지원 |
| Qualcomm NPU (IQ8) | ✅ 모바일 추론 |
| GGUF (llama.cpp/Ollama) | ✅ 2-bit/4-bit 양자화 |
| ONNX (WebGPU/브라우저) | ✅ onnx-community/gemma-4-* |
| NVIDIA NIM | ✅ 컨테이너화 배포 |
E2B 모델은 라즈베리 파이 5에서 초당 7.6 토큰의 속도로 디코딩이 가능하며, 이는 엣지 AI 애플리케이션의 새로운 가능성을 열어줍니다.
Apache 2.0 라이선스: 이번엔 무엇이 다른가
Gemma 4가 처음으로 Apache 2.0 라이선스를 채택했습니다. 이는 매우 중요한 변화입니다. 기존의 모든 Gemma 모델은 Google 자체 라이선스 계약을 사용했기에 특정 사용 제한과 라이선스 종료 권한이 존재했습니다.
라이선스 비교
| 구분 | Gemma 3 (Google 라이선스) | Gemma 4 (Apache 2.0) |
|---|---|---|
| 상업적 이용 | 제한 조건 있음 | ✅ 완전 자유 |
| 수정 및 배포 | 추가 조항 준수 필요 | ✅ 완전 자유 |
| 파생 모델 | 제한 있음 | ✅ 완전 자유 |
| 종료 권한 | Google이 종료 권한 보유 | ❌ 취소 불가 |
| 특허 라이선스 | 제한적 | ✅ 명시적 허용 |
Apache 2.0 채택의 의미:
- 기업이 법적 리스크 없이 상업용 제품에 안심하고 도입 가능
- 파생 모델의 자유로운 미세 조정(Fine-tuning) 및 배포 가능
- Meta Llama 및 DeepSeek의 오픈소스 전략과 일치
- 기업의 도입을 위한 컴플라이언스 문턱을 대폭 낮춤
💰 비용 최적화: Apache 2.0 + 로컬 배포 = API 호출 비용 제로. 추론량이 많은 시나리오에서는 로컬에 Gemma 4를 배포하는 것이 API 호출보다 경제적일 수 있습니다. 로컬 배포와 API 호출 간의 비용 효율성을 비교해야 한다면, APIYI(apiyi.com) 플랫폼을 통해 먼저 API로 성능을 검증한 후 로컬 배포 여부를 결정해 보세요.
Gemma 4 모델 획득 및 빠른 시작
모델 다운로드 경로
| 플랫폼 | 가용 모델 | 용도 |
|---|---|---|
| Hugging Face | 4종 전체 (base + IT) | 범용 다운로드, 연구 |
| Google AI Studio | 31B, 26B MoE | 무료 온라인 체험 |
| Vertex AI | 4종 전체 | 기업용 배포 |
| Ollama / llama.cpp | GGUF 양자화 버전 | 로컬 빠른 배포 |
| Google AI Edge Gallery | E4B, E2B | 모바일 기기 배포 |
Ollama 원클릭 배포
# Gemma 4 31B 배포 (추천)
ollama run gemma4:31b
# MoE 버전 배포 (가성비 우수)
ollama run gemma4:26b-a4b
# 경량 버전 배포 (엣지 디바이스용)
ollama run gemma4:e4b
미세 조정 지원
Gemma 4는 완벽한 미세 조정 생태계를 제공합니다:
| 프레임워크 | 지원 방식 |
|---|---|
| TRL | SFT, DPO, 강화 학습 (멀티모달 포함) |
| PEFT | LoRA, QLoRA (bitsandbytes 사용) |
| Vertex AI | 관리형 학습 |
| Unsloth Studio | UI 기반 미세 조정 |
시각 및 오디오 인코더를 고정(Freeze)하고 텍스트 부분만 미세 조정하면 비용을 크게 절감할 수 있습니다.
🎯 기술 제언: 먼저 APIYI(apiyi.com) 플랫폼을 통해 API 방식으로 Gemma 4의 성능을 테스트해 보고, 요구 사항을 충족하는지 확인한 뒤 로컬 배포나 미세 조정을 진행하여 리소스 낭비를 방지하는 것을 권장합니다.
자주 묻는 질문 (FAQ)
Q1: Gemma 4와 Gemini 3은 어떤 관계인가요?
Gemma 4는 Gemini 3의 연구 결과를 기반으로 구축되었으며, Gemini 3 기술의 오픈 소스 버전이라고 이해하시면 됩니다. Gemma 4는 모델 규모가 더 작지만(최대 31B vs Gemini 수천억 파라미터), 동일한 핵심 아키텍처 혁신을 채택했습니다. APIYI(apiyi.com) 플랫폼을 통해 Gemma 4와 Gemini 시리즈 모델을 동시에 사용하여 성능을 비교해 볼 수 있습니다.
Q2: 26B MoE와 31B Dense 중 무엇을 선택해야 할까요?
하드웨어 자원이 제한적이거나 높은 처리량이 필요하다면 26B-A4B MoE를 선택하세요. 단 3.8B의 활성화 파라미터만으로도 31B 모델 성능의 약 97%를 구현합니다. 반면, 최고의 성능을 추구하고 80GB GPU를 보유하고 있다면 31B Dense 모델이 적합합니다. MoE 버전의 추론 비용은 Dense 버전의 약 1/8 수준입니다.
Q3: E2B와 E4B는 어떤 상황에 적합한가요?
E2B는 라즈베리 파이, IoT 기기, 모바일과 같은 초경량 엣지 환경에 적합하며, E4B는 모바일 및 경량 PC 배포에 최적화되어 있습니다. 두 모델 모두 31B나 26B 모델에서는 지원하지 않는 오디오 입력을 지원합니다. 음성 이해가 필요한 애플리케이션을 개발 중이라면 반드시 E2B 또는 E4B를 선택해야 합니다.
Q4: Apache 2.0 라이선스가 상업적 사용에 어떤 영향을 미치나요?
Apache 2.0은 가장 자유로운 오픈 소스 라이선스 중 하나로, 상업적 사용, 수정 및 배포를 완전히 허용하며 철회할 수 없습니다. 기존 Gemma 3의 Google 자체 라이선스와 달리 기업에서 규정 준수 위험을 걱정할 필요가 없습니다. APIYI(apiyi.com) 플랫폼에서 먼저 API로 테스트하여 성능을 확인한 후, 상업용 제품에 로컬 배포하는 방식을 추천합니다.
요약
Gemma 4는 Google 오픈 소스 AI 전략의 중대한 업그레이드입니다. Apache 2.0 라이선스로 사용 장벽을 허물었으며, 라즈베리 파이부터 H100까지 모든 컴퓨팅 환경을 아우르는 4가지 모델을 제공합니다. AIME 4.3배, LiveCodeBench 2.7배의 비약적인 성능 향상을 이뤄냈으며, 네이티브 멀티모달 및 함수 호출 기능 덕분에 오픈 소스 에이전트 개발을 위한 최고의 기반 모델로 자리매김했습니다.
핵심 요약:
- 라이선스: 최초의 Apache 2.0 적용, 완전한 상업적 자유
- 모델: 2B~31B까지 4종 구성, 최초의 MoE 변형 포함
- 성능: AIME +68pts (4.3배), LiveCodeBench +51pts (2.7배)
- 멀티모달: 텍스트, 이미지, 비디오, 오디오 네이티브 통합
- 에이전트: 네이티브 함수 호출 + Extended Thinking 지원
- 배포: 라즈베리 파이부터 H100까지 지원, GGUF/ONNX/MLX 등 다양한 프레임워크 호환
APIYI(apiyi.com)를 통해 Gemma 4 시리즈 모델을 빠르게 연동하고, 통합 인터페이스에서 모델별 실제 성능을 직접 비교해 보세요.
참고 자료
- Google 공식 블로그 – Gemma 4 출시:
blog.google/innovation-and-ai/technology/developers-tools/gemma-4/ - Hugging Face – Gemma 4 모델:
huggingface.co/blog/gemma4 - Google AI – Gemma 4 모델 카드:
ai.google.dev/gemma/docs/core/model_card_4
본 글은 APIYI 팀 기술진이 작성했습니다. 더 많은 AI 모델 활용 튜토리얼은 APIYI(apiyi.com)에서 확인해 주세요.