تم إصدار Google Gemma 4 رسميًا، حيث اعتمدت لأول مرة ترخيص Apache 2.0 مفتوح المصدر بالكامل، مع إطلاق 4 نماذج تغطي سيناريوهات الحوسبة بدءًا من أجهزة Raspberry Pi وصولاً إلى مراكز البيانات. وباعتباره النسخة مفتوحة المصدر من تقنيات Gemini 3، حقق Gemma 4 قفزة نوعية شاملة مقارنة بـ Gemma 3 في مجالات الاستدلال، البرمجة، الرؤية الحاسوبية، وطول نافذة السياق.
القيمة الجوهرية: بعد قراءة هذا المقال، ستتمكن من اختيار النموذج المناسب من بين نماذج Gemma 4 الأربعة، وفهم ابتكارات البنية الأساسية، وحدود القدرات متعددة الوسائط، ومتطلبات الأجهزة للتشغيل المحلي.

نظرة سريعة على المعلومات الجوهرية لـ Gemma 4
تم إطلاق Gemma 4 في 2 أبريل 2026 خلال مؤتمر Google Cloud Next، وهي مبنية على أبحاث مشتركة مع Gemini 3، وتعد الجيل الرابع من عائلة نماذج اللغة الكبيرة مفتوحة المصدر من Google.
| عنصر المعلومات | التفاصيل |
|---|---|
| تاريخ الإصدار | 2 أبريل 2026 |
| عدد النماذج | 4 نماذج (E2B / E4B / 26B-A4B / 31B) |
| اتفاقية الترخيص | Apache 2.0 (لأول مرة، كانت سابقاً ترخيص Google الخاص) |
| أقصى نافذة سياق | 256 ألف رمز (للنموذجين 31B و 26B-A4B) |
| متعدد الوسائط | نص + صورة + فيديو + صوت (لنموذجي E2B/E4B) |
| أبرز مزايا البنية | أول متغير MoE، تقنية PLE، انتباه هجين |
| المنصات المتاحة | Hugging Face، Google AI Studio، Vertex AI، Ollama، إلخ. |
نظرة على نماذج Gemma 4 الأربعة
| النموذج | المعلمات الفعالة | إجمالي المعلمات | البنية | نافذة السياق | متعدد الوسائط |
|---|---|---|---|---|---|
| Gemma 4 E2B | 2.3 مليار | 5.1 مليار | كثيفة (Dense) | 128 ألف | نص+صورة+فيديو+صوت |
| Gemma 4 E4B | 4.5 مليار | 8 مليار | كثيفة (Dense) | 128 ألف | نص+صورة+فيديو+صوت |
| Gemma 4 26B-A4B | 3.8 مليار نشطة | 25.2 مليار | MoE | 256 ألف | نص+صورة+فيديو |
| Gemma 4 31B | 30.7 مليار | 30.7 مليار | كثيفة (Dense) | 256 ألف | نص+صورة+فيديو |
قواعد التسمية: البادئة "E" ترمز إلى "المعلمات الفعالة" (Effective Parameters)، حيث يكون إجمالي المعلمات أكبر من المعلمات الفعالة بسبب تقنية PLE. بينما يشير 26B-A4B إلى بنية MoE بإجمالي 26 مليار معلمة، مع تفعيل 4 مليارات معلمة لكل رمز (token).
🎯 نصيحة تقنية: تغطي نماذج Gemma 4 الأربعة كافة السيناريوهات بدءاً من الأجهزة الطرفية وصولاً إلى الاستدلال السحابي. إذا كنت بحاجة للمقارنة بين أداء نماذج مفتوحة المصدر متعددة، فنحن نوصي باستخدام منصة APIYI (apiyi.com) للوصول الموحد، مما يتيح لك التبديل والتقييم السريع بين النماذج المختلفة.
مقارنة الأداء بين Gemma 4 و Gemma 3: أكبر قفزة جيلية في التاريخ
تصف Google نموذج Gemma 4 بأنه "أكبر قفزة في الأداء لجيل واحد في مجال النماذج مفتوحة المصدر". وتدعم بيانات الاختبارات المعيارية هذا الادعاء تماماً.
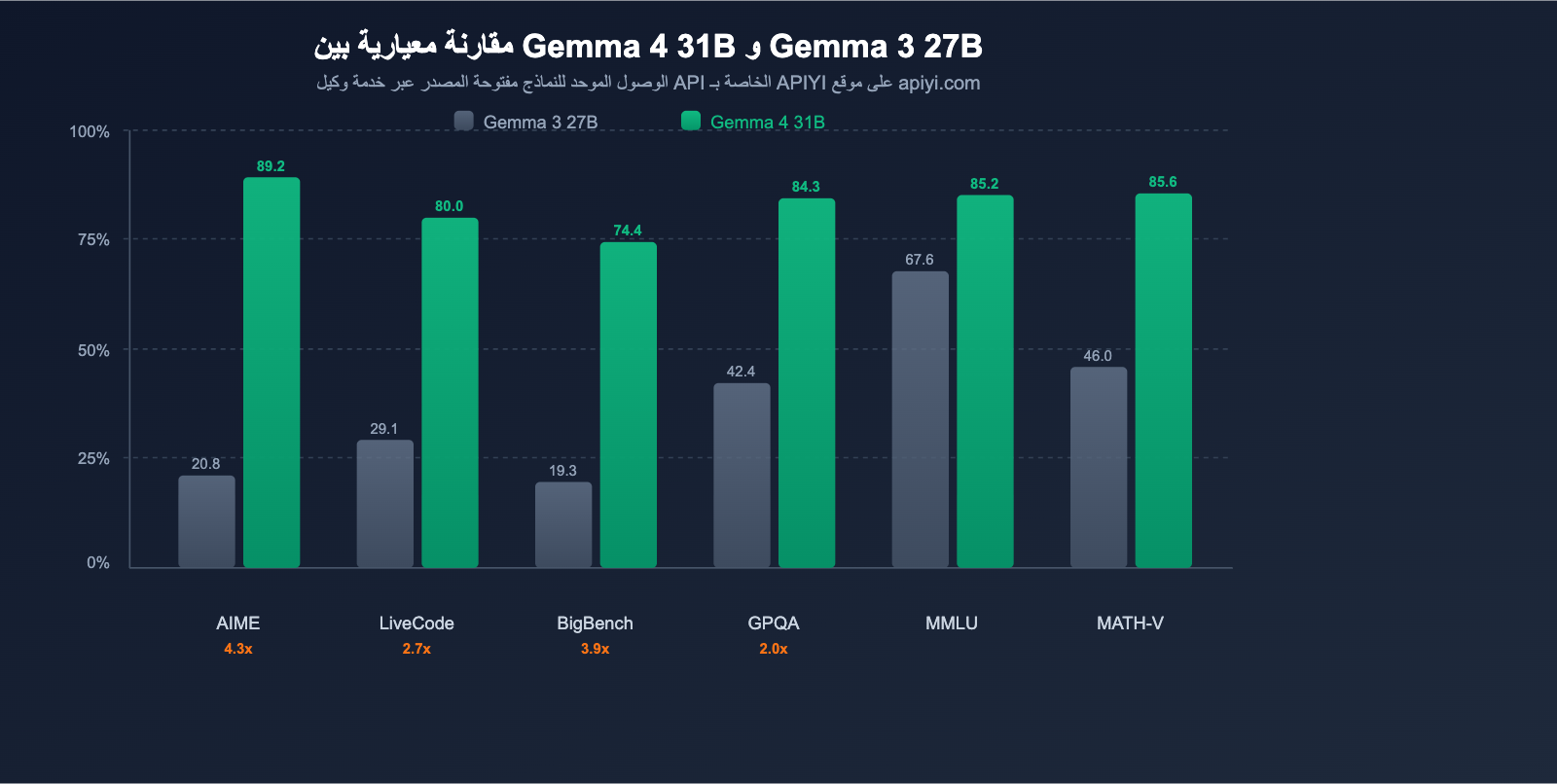
مقارنة الاختبارات المعيارية الأساسية
| الاختبار المعياري | Gemma 3 27B | Gemma 4 31B | نسبة التحسن |
|---|---|---|---|
| AIME 2026 (الاستدلال الرياضي) | 20.8% | 89.2% | +68.4 نقطة (4.3x) |
| LiveCodeBench v6 (البرمجة) | 29.1% | 80.0% | +50.9 نقطة (2.7x) |
| BigBench Extra Hard (الاستدلال) | 19.3% | 74.4% | +55.1 نقطة (3.9x) |
| GPQA Diamond (الاستدلال العلمي) | 42.4% | 84.3% | +41.9 نقطة (2.0x) |
| MMLU Pro (المعرفة) | 67.6% | 85.2% | +17.6 نقطة |
| MATH-Vision (الرياضيات البصرية) | 46.0% | 85.6% | +39.6 نقطة |
| MRCR 128K (سياق طويل) | 13.5% | 66.4% | +52.9 نقطة |
نتائج رئيسية: قفز الاستدلال الرياضي في AIME من 20.8% إلى 89.2%، بزيادة قدرها 4.3 أضعاف؛ وارتفعت قدرات البرمجة في LiveCodeBench من 29.1% إلى 80.0%، بزيادة 2.7 أضعاف. هذا ليس تحسيناً تدريجياً، بل قفزة جيلية حقيقية.
بيانات الاختبار المعياري الكاملة للنماذج الأربعة
| الاختبار المعياري | 31B | 26B-A4B | E4B | E2B |
|---|---|---|---|---|
| MMLU Pro | 85.2% | 82.6% | 69.4% | 60.0% |
| AIME 2026 | 89.2% | 88.3% | 42.5% | 37.5% |
| GPQA Diamond | 84.3% | 82.3% | 58.6% | 43.4% |
| LiveCodeBench v6 | 80.0% | 77.1% | 52.0% | 44.0% |
| MATH-Vision | 85.6% | 82.4% | 59.5% | 52.4% |
| MMMU Pro (بصري) | 76.9% | 73.8% | 52.6% | 44.2% |
| Codeforces ELO | 2150 | 1718 | 940 | 633 |
ميزة كفاءة MoE: حقق نموذج 26B-A4B حوالي 97% من أداء نموذج 31B الكثيف باستخدام 3.8 مليار معلمة نشطة فقط، مما يقلل تكاليف الاستدلال بشكل كبير. في منصة LMArena، تفوق 26B-A4B (~1441 ELO) حتى على نموذج gpt-oss-120B من OpenAI.
💡 توصية الاختيار: اختر 31B إذا كنت تسعى لأقصى أداء ممكن، واختر 26B-A4B إذا كنت تبحث عن أفضل قيمة مقابل التكلفة (97% من الأداء مقابل 12% فقط من المعلمات النشطة). يمكنك عبر منصة APIYI (apiyi.com) المقارنة السريعة بين أداء الإصدارين في سيناريوهات عملك الفعلية.
الابتكارات الستة الجوهرية في معمارية Gemma 4
قدمت Gemma 4 العديد من التقنيات المبتكرة على مستوى المعمارية، وهو ما يمثل السبب الجوهري وراء القفزة النوعية في أدائها.

التقنية 1: تضمينات لكل طبقة (Per-Layer Embeddings – PLE)
تضيف تقنية PLE مساراً شرطياً موازياً خارج تدفق البواقي (Residual Stream) الرئيسي، مما يولد متجهات "توكن" مخصصة لكل طبقة من طبقات فك التشفير (Decoder). تعمل هذه التقنية على تحسين القدرة التعبيرية للنماذج الصغيرة، مما يمنح نموذج E2B بـ 2.3 مليار بارامتر فعال أداءً يتجاوز بكثير ما توحي به أرقام البارامترات الخاصة به.
التقنية 2: الانتباه الهجين (Hybrid Attention)
تستخدم هذه التقنية تبادلاً بين طبقات الانتباه ذات النافذة المنزلقة المحلية (Local Sliding Window) وطبقات الانتباه الكامل للسياق (Global Full Context):
- طبقات النافذة المنزلقة: تعالج السياق المحلي (E2B/E4B: 512 توكن؛ 31B/26B: 1024 توكن).
- طبقات الانتباه العالمي: تعالج نطاق السياق الكامل.
يقلل هذا التصميم الهجين من تكاليف الحوسبة بشكل كبير مع الحفاظ على قدرة التعامل مع سياقات طويلة.
التقنية 3: ترميز الموقع Dual RoPE
- تستخدم طبقات النافذة المنزلقة ترميز RoPE القياسي.
- تستخدم طبقات الانتباه العالمي ترميز Proportional RoPE.
هذا التصميم المزدوج لترميز الموقع يجعل من الممكن الوصول إلى نافذة سياق تصل إلى 256 ألف توكن دون المساس بجودة المخرجات.
التقنية 4: ذاكرة التخزين المؤقت المشتركة (Shared KV Cache)
تقوم الطبقات الأخيرة (N) بإعادة استخدام موترات K/V الخاصة بآخر طبقة غير مشتركة من نفس النوع، مما يقلل بشكل كبير من حجم الحوسبة واستهلاك ذاكرة الفيديو (VRAM). تُعد هذه إحدى التقنيات الرئيسية التي تمكن Gemma 4 من تشغيل نماذج لغة كبيرة على الأجهزة الاستهلاكية.
التقنية 5: خليط الخبراء MoE (إصدار 26B-A4B)
قدمت Gemma 4 لأول مرة متغيرات MoE:
- 128 خبيراً صغيراً.
- يتم تفعيل 8 خبراء + خبير مشترك واحد لكل توكن.
- يحقق أداءً يصل إلى حوالي 97% من أداء نموذج 31B الكثيف (Dense) باستخدام 3.8 مليار بارامتر مفعل فقط.
التقنية 6: تعدد الوسائط الأصلي (Native Multimodal)
تم دمج قدرات الرؤية والصوت مباشرة في مرحلة التدريب المسبق:
- مشفر الرؤية: حوالي 150 مليون بارامتر لـ E2B/E4B؛ وحوالي 550 مليون بارامتر لـ 31B/26B.
- مشفر الصوت: بنمط USM Conformer، بحوالي 300 مليون بارامتر (في E2B/E4B فقط).
- دعم الصور ذات نسب العرض إلى الارتفاع المتغيرة، مع ميزانية توكن قابلة للتهيئة (70-1120 توكن).
شرح مفصل لقدرات Gemma 4 في تعدد الوسائط والوكلاء (Agents)
لا يعد Gemma 4 مجرد نموذج محادثة فحسب، بل هو نظام متعدد الوسائط يتمتع بقدرات كاملة كوكيل ذكي (Agent).
قدرات الإدخال متعدد الوسائط
| النمط | E2B | E4B | 31B | 26B-A4B |
|---|---|---|---|---|
| النص | ✅ | ✅ | ✅ | ✅ |
| الصور | ✅ | ✅ | ✅ | ✅ |
| الفيديو (بحد أقصى 60 ثانية، 1 إطار في الثانية) | ✅ | ✅ | ✅ | ✅ |
| الصوت (بحد أقصى 30 ثانية) | ✅ | ✅ | ❌ | ❌ |
تغطي القدرات البصرية ما يلي:
- اكتشاف الكائنات وإخراج مربعات الإحاطة (بتنسيق JSON أصلي).
- اكتشاف عناصر واجهة المستخدم الرسومية (GUI) وتحديدها.
- تحليل المستندات/PDF وفهم الرسوم البيانية.
- فهم شاشات العرض وواجهات المستخدم.
- الإدخال المتقاطع بين النص والصور (بأي ترتيب مختلط).
استدعاء الوظائف الأصلي وقدرات الوكيل (Agent)
تم دمج قدرات استدعاء الوظائف في Gemma 4 منذ مرحلة التدريب، وليست إضافة لاحقة عبر الضبط الدقيق:
- استدعاء الوظائف الأصلي: تم تحسينه مباشرة في مرحلة التدريب، ويدعم تنسيق الأدوات المتعددة.
- التفكير الموسع (Extended Thinking): يمكن تفعيل الاستنتاج متعدد الخطوات عبر
enable_thinking=True. - المخرجات المهيكلة: إخراج JSON أصلي، مما يجعله مثالياً لتكامل API.
- سير عمل الوكيل متعدد الجولات: يدعم حلقة الوكيل المستقلة التي تعتمد على التخطيط والتنفيذ والمراقبة.
# مثال على استدعاء الوظائف في Gemma 4 (عبر واجهة APIYI الموحدة)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "الحصول على حالة الطقس لمدينة محددة",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string"}
},
"required": ["city"]
}
}
}
]
response = client.chat.completions.create(
model="gemma-4-31b-it",
messages=[{"role": "user", "content": "كيف هو الطقس في بكين اليوم؟"}],
tools=tools,
tool_choice="auto",
)
🚀 بداية سريعة: تجعل قدرات استدعاء الوظائف الأصلية في Gemma 4 منه خياراً مثالياً لبناء وكلاء الذكاء الاصطناعي. نوصي باستخدام منصة APIYI (apiyi.com) للوصول السريع، حيث تدعم واجهات متوافقة مع OpenAI دون الحاجة إلى تعديلات إضافية.
دليل الأجهزة لتشغيل Gemma 4 محلياً
يعني ترخيص Apache 2.0 أنه يمكنك تشغيل Gemma 4 بحرية على أي جهاز. فيما يلي متطلبات الأجهزة لكل نموذج.
نظرة عامة على متطلبات الأجهزة
| النموذج | الحد الأدنى للأجهزة | سيناريو النشر النموذجي |
|---|---|---|
| E2B (2.3B) | ذاكرة أقل من 1.5 جيجابايت | Raspberry Pi 5 (133 رمز/ثانية للتحضير، 7.6 رمز/ثانية للفك) |
| E4B (4.5B) | NPU/GPU للهواتف | الأجهزة المحمولة، Apple Silicon (MLX) |
| 26B-A4B (MoE) | وحدة معالجة رسومية للمستهلك (مع كمية) | محطات العمل الشخصية، خوادم صغيرة |
| 31B (Dense) | وحدة H100 واحدة بسعة 80 جيجابايت (FP16) | الاستدلال السحابي، مراكز البيانات |
الأجهزة والأطر المدعومة
| الأجهزة/الإطار | حالة الدعم |
|---|---|
| NVIDIA (H100/B200/RTX) | ✅ دعم كامل للسلسلة |
| Google TPU (Trillium/Ironwood) | ✅ تحسين أصلي |
| Apple Silicon (MLX) | ✅ mlx-community/gemma-4-* |
| AMD ROCm | ✅ مدعوم |
| Qualcomm NPU (IQ8) | ✅ استدلال على الأجهزة المحمولة |
| GGUF (llama.cpp/Ollama) | ✅ كمية 2-bit/4-bit |
| ONNX (WebGPU/المتصفح) | ✅ onnx-community/gemma-4-* |
| NVIDIA NIM | ✅ نشر عبر الحاويات |
يمكن لنموذج E2B العمل على Raspberry Pi 5 بسرعة 7.6 رمز في الثانية، مما يفتح آفاقاً جديدة لتطبيقات الذكاء الاصطناعي على الحافة.
ترخيص Apache 2.0: لماذا يختلف الأمر هذه المرة؟
يُعد اعتماد Gemma 4 لترخيص Apache 2.0 لأول مرة تغييراً جوهرياً. ففي السابق، كانت جميع نماذج Gemma تستخدم اتفاقيات ترخيص خاصة بـ Google، والتي كانت تتضمن قيوداً محددة على الاستخدام وحقوق إنهاء الخدمة.
مقارنة التراخيص
| البعد | Gemma 3 (ترخيص Google) | Gemma 4 (Apache 2.0) |
|---|---|---|
| الاستخدام التجاري | بشروط مقيدة | ✅ حر تماماً |
| التعديل والتوزيع | يخضع لشروط إضافية | ✅ حر تماماً |
| النماذج المشتقة | مقيدة | ✅ حر تماماً |
| حق الإنهاء | تحتفظ Google بحق الإنهاء | ❌ غير قابل للإلغاء |
| ترخيص براءات الاختراع | محدود | ✅ ترخيص صريح |
يعني ترخيص Apache 2.0 ما يلي:
- يمكن للشركات استخدامه في المنتجات التجارية بثقة ودون مخاطر قانونية.
- حرية كاملة في ضبط النموذج (Fine-tuning) وتوزيع النماذج المشتقة.
- توافق مع استراتيجيات المصادر المفتوحة المتبعة من قبل Meta Llama و DeepSeek.
- خفض كبير في عوائق الامتثال لاعتماد النموذج من قبل الشركات.
💰 تحسين التكلفة: ترخيص Apache 2.0 + النشر المحلي = صفر تكاليف استدعاء النموذج عبر API. بالنسبة للسيناريوهات ذات حجم الاستدلال الكبير، قد يكون النشر المحلي لنموذج Gemma 4 أكثر اقتصادية من استدعاء API. إذا كنت بحاجة إلى مقارنة فعالية التكلفة بين النشر المحلي واستدعاء API، يمكنك استخدام منصة APIYI (apiyi.com) للتحقق من النتائج عبر API أولاً، ثم اتخاذ قرار بشأن النشر المحلي.
الحصول على نموذج Gemma 4 والبدء السريع
قنوات تحميل النموذج
| المنصة | النماذج المتاحة | الغرض |
|---|---|---|
| Hugging Face | جميع الإصدارات الأربعة (base + IT) | التحميل العام، البحث |
| Google AI Studio | 31B، 26B MoE | تجربة مجانية عبر الإنترنت |
| Vertex AI | جميع الإصدارات الأربعة | النشر على مستوى المؤسسات |
| Ollama / llama.cpp | إصدارات GGUF المكممة | النشر المحلي السريع |
| Google AI Edge Gallery | E4B، E2B | النشر على الأجهزة المحمولة |
النشر السريع عبر Ollama
# نشر نموذج Gemma 4 31B (موصى به)
ollama run gemma4:31b
# نشر إصدار MoE (فعالية عالية من حيث التكلفة)
ollama run gemma4:26b-a4b
# نشر الإصدار الخفيف (للأجهزة الطرفية)
ollama run gemma4:e4b
دعم الضبط الدقيق (Fine-tuning)
يوفر Gemma 4 منظومة متكاملة للضبط الدقيق:
| الإطار البرمجي | الطرق المدعومة |
|---|---|
| TRL | SFT، DPO، التعلم التعزيزي (بما في ذلك متعدد الوسائط) |
| PEFT | LoRA، QLoRA (عبر bitsandbytes) |
| Vertex AI | التدريب المُدار |
| Unsloth Studio | الضبط الدقيق عبر واجهة المستخدم |
يمكن تجميد مشفرات الرؤية والصوت، والاكتفاء بضبط الجزء النصي فقط، مما يقلل تكاليف الضبط الدقيق بشكل كبير.
🎯 نصيحة تقنية: يُنصح باختبار أداء Gemma 4 عبر API باستخدام منصة APIYI (apiyi.com) أولاً، والتأكد من تلبيته لمتطلباتك قبل البدء في النشر المحلي أو الضبط الدقيق، وذلك لتجنب هدر الموارد.
الأسئلة الشائعة
س1: ما هي العلاقة بين Gemma 4 و Gemini 3؟
تم بناء Gemma 4 على أساس أبحاث Gemini 3، ويمكن اعتبارها النسخة مفتوحة المصدر من تقنيات Gemini 3. حجم نموذج Gemma 4 أصغر (بحد أقصى 31 مليار معلمة مقابل مئات المليارات في Gemini)، لكنه يعتمد نفس الابتكارات المعمارية الأساسية. يمكنك استخدام منصة APIYI (apiyi.com) لاستخدام كل من Gemma 4 ونماذج سلسلة Gemini للمقارنة بينهما.
س2: كيف تختار بين 26B MoE و 31B Dense؟
إذا كانت موارد أجهزتك محدودة أو كنت بحاجة إلى معدل نقل بيانات عالٍ، اختر 26B-A4B MoE، فهو يحقق حوالي 97% من أداء نموذج 31B باستخدام 3.8 مليار معلمة نشطة فقط. أما إذا كنت تسعى للحصول على أقصى أداء ولديك وحدة معالجة رسومات (GPU) بسعة 80 جيجابايت، فاختر 31B Dense. تبلغ تكلفة الاستدلال لإصدار MoE حوالي ثُمن تكلفة إصدار Dense.
س3: ما هي السيناريوهات المناسبة لـ E2B و E4B؟
نموذج E2B مناسب لسيناريوهات الحافة القصوى (مثل Raspberry Pi، أجهزة إنترنت الأشياء IoT، والهواتف)، بينما E4B مناسب للأجهزة المحمولة وأجهزة الكمبيوتر خفيفة الوزن. كلاهما يدعم الإدخال الصوتي، وهي ميزة لا تتوفر في 31B و 26B. إذا كان تطبيقك يتطلب فهم الصوت، فيجب عليك اختيار E2B أو E4B.
س4: ما تأثير ترخيص Apache 2.0 على الاستخدام التجاري؟
يُعد Apache 2.0 أحد أكثر تراخيص المصادر المفتوحة مرونة، حيث يسمح بالاستخدام التجاري والتعديل والتوزيع بحرية كاملة وغير قابلة للإلغاء. مقارنة بترخيص Google الخاص بـ Gemma 3، لا داعي للقلق بشأن مخاطر الامتثال للشركات. يمكنك اختبار النماذج أولاً عبر API على منصة APIYI (apiyi.com)، وبعد التأكد من النتائج، يمكنك نشرها محلياً في منتجاتك التجارية.
الخلاصة
تُمثل Gemma 4 ترقية كبيرة لاستراتيجية الذكاء الاصطناعي مفتوح المصدر من Google. فقد كسر ترخيص Apache 2.0 حواجز الاستخدام السابقة؛ وتغطي النماذج الأربعة جميع سيناريوهات الحوسبة من Raspberry Pi إلى H100؛ مع قفزة في الأداء عبر الأجيال بمقدار 4.3 ضعف في AIME و2.7 ضعف في LiveCodeBench؛ كما أن تعدد الوسائط الأصلي واستدعاء الدوال يجعلها النموذج الأساسي المفضل لتطوير الوكلاء (Agents) مفتوحة المصدر.
مراجعة النقاط الأساسية:
- الترخيص: لأول مرة Apache 2.0، تجاري مجاني بالكامل
- النماذج: 4 نماذج تغطي من 2B إلى 31B، بما في ذلك أول متغير MoE
- الأداء: AIME +68 نقطة (4.3 ضعف)، LiveCodeBench +51 نقطة (2.7 ضعف)
- تعدد الوسائط: نص + صورة + فيديو + صوت، مدمج أصلياً
- الوكلاء (Agents): استدعاء دوال أصلي + Extended Thinking
- النشر: تغطية كاملة من Raspberry Pi إلى H100، دعم إطارات عمل متعددة GGUF/ONNX/MLX
نوصي بالوصول السريع إلى سلسلة نماذج Gemma 4 عبر منصة APIYI (apiyi.com)، للمقارنة بين النتائج الفعلية للنماذج المختلفة تحت واجهة موحدة.
المراجع
- مدونة جوجل الرسمية – إطلاق Gemma 4:
blog.google/innovation-and-ai/technology/developers-tools/gemma-4/ - Hugging Face – نموذج Gemma 4:
huggingface.co/blog/gemma4 - Google AI – بطاقة نموذج Gemma 4:
ai.google.dev/gemma/docs/core/model_card_4
تم كتابة هذا المقال بواسطة الفريق التقني لـ APIYI، للمزيد من الدروس التعليمية حول استخدام نماذج الذكاء الاصطناعي، يرجى متابعة APIYI عبر الموقع apiyi.com