Choosing a fast and affordable AI model is a core challenge for every developer working on high-frequency invocation scenarios. On March 3, 2026, Google officially released Gemini 3.1 Flash Lite Preview. This is the fastest and most cost-effective model in the Gemini 3 series, specifically designed for high-throughput tasks like translation, summarization, and classification.
Core Value: After reading this article, you'll have a comprehensive understanding of the technical parameters, performance advantages, and best use cases for Gemini 3.1 Flash Lite, and you'll be able to get started with your first model invocation using our code examples.

Quick Overview of Gemini 3.1 Flash Lite Parameters
Before diving deep into Gemini 3.1 Flash Lite, let's take a look at the key technical specifications of this model:
| Parameter | Gemini 3.1 Flash Lite Spec | Notes |
|---|---|---|
| Model ID | gemini-3.1-flash-lite-preview |
Currently in preview |
| Context Window | 1,000,000 tokens | Million-scale long context |
| Max Output | 64,000 tokens | Supports long-form generation |
| Input Price | $0.25 / million tokens | Extremely low cost |
| Output Price | $1.50 / million tokens | High cost-performance ratio |
| Output Speed | ~382 tokens/sec | Rapid response |
| Input Modality | Text, Image, Audio, Video | Native multimodal |
| Output Modality | Text | Text generation |
| Release Date | March 3, 2026 | Latest release |
🚀 Quick Start: Gemini 3.1 Flash Lite Preview is now live on the APIYI (apiyi.com) platform. It supports OpenAI-compatible API invocation, allowing you to integrate it quickly without any extra configuration.
5 Key Advantages of Gemini 3.1 Flash Lite
Advantage 1: 2.5x Speed Boost
Gemini 3.1 Flash Lite has achieved a massive leap in performance. According to benchmark data from Artificial Analysis:
- Time to First Token (TTFT): 2.5x faster than Gemini 2.5 Flash.
- Output Speed: Reaches 382 tokens/second, a 64% increase over the 232 tokens/second of Gemini 2.5 Flash.
- Overall Throughput: Improved by approximately 45%.
This means that in latency-sensitive scenarios like real-time translation, chatbots, and content summarization, you'll get a near-instant response experience.
Advantage 2: Unbeatable Cost-Effectiveness
The pricing strategy for Gemini 3.1 Flash Lite is incredibly competitive:
| Price Comparison | Input Price ($/1M tokens) | Output Price ($/1M tokens) | Overall Cost |
|---|---|---|---|
| Gemini 3.1 Flash Lite | $0.25 | $1.50 | ⭐ Lowest |
| Gemini 3 Flash | $1.00 | $4.00 | Moderate |
| Gemini 3 Pro | $2.50 | $15.00 | Higher |
| Claude 4.5 Haiku | $0.80 | $4.00 | Moderate |
| GPT-5 mini | $0.60 | $2.40 | Moderate |
Based on processing 1 million tokens per day, the monthly cost for using Gemini 3.1 Flash Lite is only about $52.50, saving you over 80% compared to Gemini 3 Pro.
Advantage 3: 1M Token Context Window
Gemini 3.1 Flash Lite supports a 1M token context window, which is extremely rare for a model at this price point. This means you can:
- Translate or summarize entire books in one go.
- Analyze hours of meeting transcriptions.
- Handle large-scale codebase comprehension and documentation generation.
- Perform multilingual comparative translations of long documents.
Advantage 4: Native Multimodal Support
Even though it's positioned as a lightweight model, Gemini 3.1 Flash Lite retains full multimodal input capabilities:
- Text: Standard text understanding and generation.
- Images: Image recognition and understanding.
- Audio: Processing of voice content.
- Video: Video content understanding.
This makes it suitable not just for text-only tasks, but also for multimodal scenarios like mixed text-image translation and video subtitle generation.
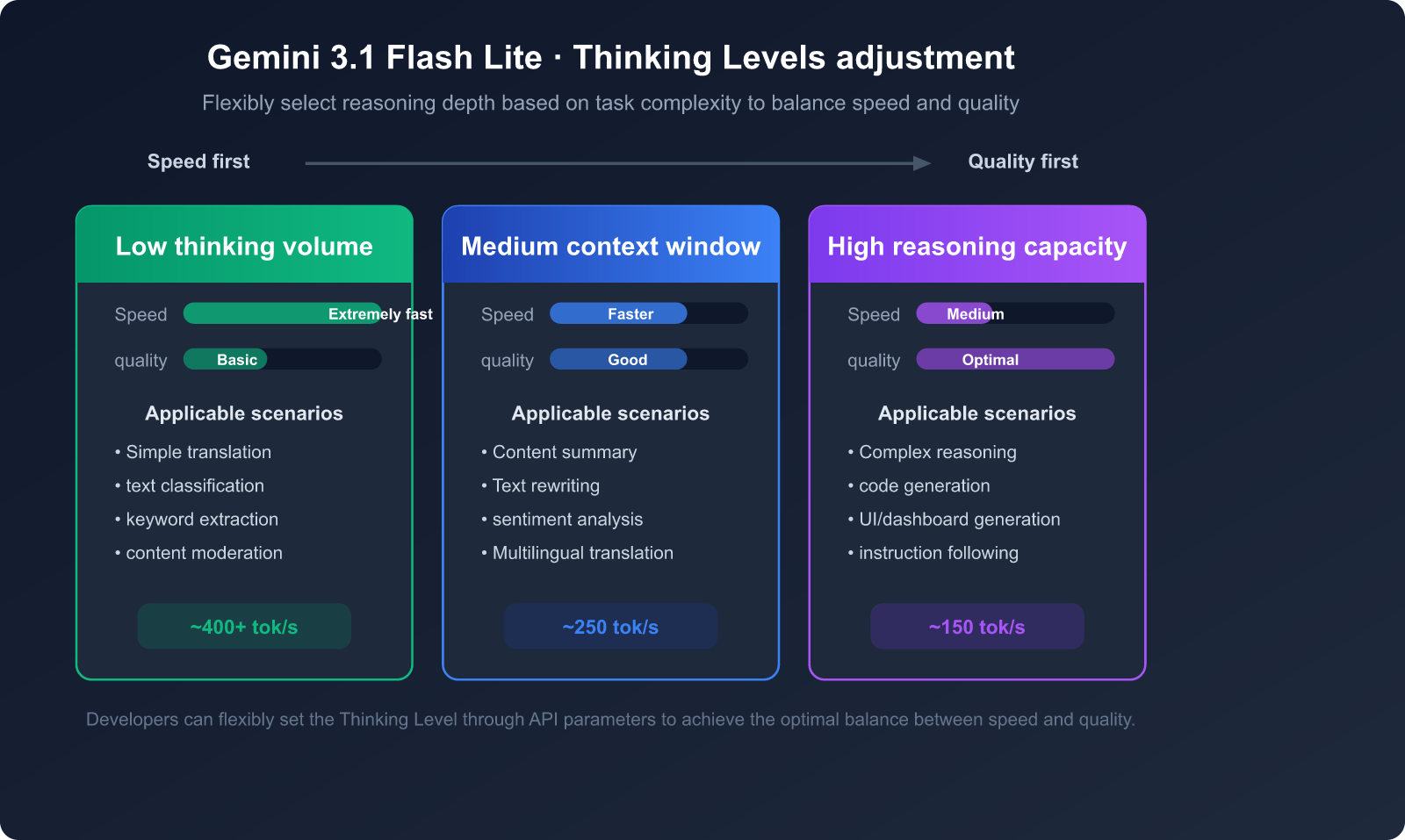
Advantage 5: Adjustable Thinking Depth
Gemini 3.1 Flash Lite supports a Thinking Levels feature, allowing developers to flexibly adjust the model's reasoning depth based on task complexity:
- Low Thinking: Ideal for simple translations, classification, and tasks where speed is the top priority.
- Medium Thinking: Suitable for summarization, content rewriting, and tasks requiring a moderate level of understanding.
- High Thinking: Best for complex reasoning, code generation, and tasks that require deep analysis.
Gemini 3.1 Flash Lite Performance Benchmarks
Gemini 3.1 Flash Lite has achieved an Elo rating of 1432 on the Arena.ai leaderboard, standing out among models in its class.
| Benchmark | Gemini 3.1 Flash Lite | Description |
|---|---|---|
| GPQA Diamond | 86.9% | Scientific reasoning |
| MMMU-Pro | 76.8% | Multimodal reasoning |
| MMMLU | 88.9% | Multilingual Q&A |
| LiveCodeBench | 72.0% | Code generation |
| Video-MMMU | 84.8% | Video understanding |
| SimpleQA | 43.3% | Parametric knowledge |
| MRCR v2 (128k) | 60.1% | Long context understanding |
It's worth noting that in 6 benchmarks, including GPQA Diamond and MMMLU, Gemini 3.1 Flash Lite outperformed GPT-5 mini and Claude 4.5 Haiku, proving that lightweight models can deliver cutting-edge intelligence.
🎯 Technical Tip: The benchmark data above shows that Gemini 3.1 Flash Lite excels in multilingual processing (MMMLU 88.9%), making it a great fit for cross-language translation tasks. You can quickly test this model for multilingual tasks via APIYI at apiyi.com.
Getting Started with Gemini 3.1 Flash Lite
Minimalist Code Example
Using the OpenAI-compatible interface, you can invoke Gemini 3.1 Flash Lite with just a few lines of code:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI unified interface
)
# Translation scenario example
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=[
{"role": "system", "content": "You are a professional translator. Please translate the user's Chinese input into English, maintaining the original meaning and tone."},
{"role": "user", "content": "Artificial intelligence is profoundly changing the way we work and live."}
],
temperature=0.3
)
print(response.choices[0].message.content)
View Full Code: Batch Translation + Summarization Scenarios
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI unified interface
)
MODEL = "gemini-3.1-flash-lite-preview"
def translate_text(text, target_lang="English"):
"""Translate text to the target language"""
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": f"Translate the following text to {target_lang}. Keep the original meaning and tone."},
{"role": "user", "content": text}
],
temperature=0.3
)
return response.choices[0].message.content
def summarize_text(text, max_words=100):
"""Generate a text summary"""
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": f"Summarize the core points of the following content in no more than {max_words} words."},
{"role": "user", "content": text}
],
temperature=0.5
)
return response.choices[0].message.content
def classify_text(text, categories):
"""Text classification"""
cats = ", ".join(categories)
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": f"Classify the following text into one of these categories: {cats}. Return only the category name."},
{"role": "user", "content": text}
],
temperature=0.1
)
return response.choices[0].message.content
# Usage example
texts = [
"Quantum computing will revolutionize the field of cryptography in the next decade",
"New electric vehicle range exceeds 1000 kilometers",
"Central bank announces 25 basis point cut to benchmark interest rate"
]
categories = ["Technology", "Automotive", "Finance", "Sports", "Entertainment"]
for text in texts:
# Translate
translated = translate_text(text)
# Classify
category = classify_text(text, categories)
# Summarize
summary = summarize_text(text, max_words=30)
print(f"Original: {text}")
print(f"Translation: {translated}")
print(f"Category: {category}")
print(f"Summary: {summary}")
print("---")
💰 Cost Optimization: For high-frequency tasks like translation, summarization, and classification, Gemini 3.1 Flash Lite’s ultra-low pricing (input at just $0.25/million tokens) can significantly reduce your operating costs. You can also get competitive pricing and free trial credits by using the APIYI platform at apiyi.com.
Best Use Cases for Gemini 3.1 Flash Lite
Scenario 1: High-Frequency Batch Translation
Gemini 3.1 Flash Lite achieves an impressive 88.9% score on the MMMLU multilingual benchmark. Combined with its extremely low cost and lightning-fast response times, it's the ideal choice for batch translation tasks:
- E-commerce Product Description Translation: Translating tens of thousands of product listings into multiple languages daily.
- User Review Translation: Real-time translation of feedback from international users.
- Internationalization of Technical Documentation: Generating multilingual versions of large-scale documentation.
- Subtitle Translation: Rapid multilingual conversion for video subtitles.
Scenario 2: Real-Time Content Summarization
With an output speed of 382 tokens/second, it's perfectly suited for real-time summarization:
- News Summary Generation: Automatically extracting summaries from massive news feeds.
- Meeting Minutes: Quickly summarizing long meeting recordings.
- Literature Reviews: Batch generation of summaries for academic papers.
- Email Summarization: Automatic summarization and categorization of corporate emails.
Scenario 3: Large-Scale Content Moderation and Classification
Its low latency and cost-effectiveness make it a perfect fit for content moderation pipelines:
- User-Generated Content Moderation: Filtering content for safety on social platforms.
- Automatic Ticket Classification: Intelligent routing for customer service systems.
- Sentiment Analysis: Real-time monitoring of brand sentiment.
- Automatic Tag Generation: Automated tagging for content management systems.
Decision Guide for Use Cases
| Use Case | Recommended Reason | Key Advantage | Estimated Monthly Cost |
|---|---|---|---|
| Batch Translation | Outstanding MMMLU 88.9% multilingual capability | Low price + High quality | ~$50 (1M tokens/day) |
| Real-Time Summary | 382 tokens/sec ultra-fast output | Low latency + Fast | ~$30 (500k tokens/day) |
| Content Moderation | High classification accuracy, fast response | Low cost + Batch processing | ~$20 (300k tokens/day) |
| Chatbot | 2.5x faster TTFT | Instant response | ~$80 (2M tokens/day) |
| Long Document Processing | 1M token context window | Process entire books at once | Pay-as-you-go |
💡 Recommendation: If your business requires high-frequency, batch, and cost-sensitive text processing, Gemini 3.1 Flash Lite is currently the best value-for-money choice. We recommend testing your specific scenarios via the APIYI (apiyi.com) platform, which allows you to switch models with one click to compare performance.
Usage Notes for Gemini 3.1 Flash Lite
Current Limitations
As a preview model, keep the following in mind:
- Preview Phase: The model is still in Preview, so API interfaces and behavior may change.
- Output Limits: The maximum output is 64K tokens; tasks requiring longer generation should be processed in segments.
- Long Context Performance: Performance is average in 1M token extreme context scenarios (only 12.3% on MRCR v2 1M tests); we recommend keeping it within 128K for best results.
- Safety Boundaries: The safety scoring for image-to-text needs improvement; add an extra moderation layer when dealing with sensitive content.
Best Practices
- Temperature Parameter: Use
temperature=0.3for translation tasks andtemperature=0.5for summarization. - System Prompt: Providing clear role definitions and output format requirements can significantly improve output quality.
- Batch Processing: Use asynchronous calls to increase throughput and fully leverage the model's speed.
- Context Control: While it supports a 1M context window, we recommend keeping standard tasks within 128K for the best price-to-performance ratio.
FAQ
Q1: What’s the difference between Gemini 3.1 Flash Lite and Gemini 3 Flash?
Gemini 3.1 Flash Lite is the lightweight version in the Gemini 3 series, specifically optimized for high-frequency, low-cost scenarios. Compared to Gemini 3 Flash, its input cost is 75% lower ($0.25 vs $1.00), and its output speed is about 64% faster, though its performance on complex reasoning tasks is slightly lower. Simply put: choose Flash Lite for extreme cost-effectiveness, or Flash if you need stronger reasoning capabilities. You can test both models via the APIYI (apiyi.com) platform to quickly find the best fit for your use case.
Q2: Is Gemini 3.1 Flash Lite suitable for translation tasks?
It's a great choice. Gemini 3.1 Flash Lite scored an impressive 88.9% on the MMMLU multilingual benchmark, ranking it among the leaders in its class. Combined with its ultra-low input price of $0.25 per million tokens and an output speed of 382 tokens/second, it's currently one of the most cost-effective models for batch translation tasks. We recommend using APIYI (apiyi.com) to get free testing credits and verify the translation quality for yourself.
Q3: How do I call Gemini 3.1 Flash Lite using an OpenAI-compatible interface?
Just set the base_url to the APIYI interface address and use gemini-3.1-flash-lite-preview for the model parameter. There's no need to change your existing OpenAI SDK code structure, making the switch seamless. See the code examples in the "Quick Start" section of this article for details.
Q4: Is the 1M context window of Gemini 3.1 Flash Lite actually useful?
It performs excellently within the 128K tokens range (MRCR v2 128K score of 60.1%), but performance drops significantly in extreme 1M tokens scenarios (MRCR v2 1M score of 12.3%). We recommend keeping your daily usage within 128K and using a chunking strategy when you need to process ultra-long documents.
Summary
With its ultra-low price of $0.25 per million input tokens, lightning-fast output of 382 tokens/second, a 1M tokens context window, and stellar performance in benchmarks like multilingual processing (MMMLU 88.9%) and scientific reasoning (GPQA Diamond 86.9%), Gemini 3.1 Flash Lite is the king of cost-effectiveness for high-frequency tasks like translation, summarization, and classification in 2026.
Whether you're handling millions of tokens in batch translations daily or building a low-latency real-time summarization service, Gemini 3.1 Flash Lite is a top-tier choice.
We recommend getting started with Gemini 3.1 Flash Lite Preview via APIYI (apiyi.com). The platform provides an OpenAI-compatible interface and supports one-click switching between various mainstream models, making it easy to verify performance and compare options.
References
-
Google DeepMind – Gemini 3.1 Flash-Lite Model Card: Official model technical specifications and benchmark data.
- Link:
deepmind.google/models/model-cards/gemini-3-1-flash-lite/
- Link:
-
Google AI for Developers – Gemini 3.1 Flash-Lite Preview: Official API documentation and developer guide.
- Link:
ai.google.dev/gemini-api/docs/models/gemini-3.1-flash-lite-preview
- Link:
-
Artificial Analysis – Performance Benchmarks: Independent third-party speed and performance benchmarks.
- Link:
artificialanalysis.ai/models/gemini-3-1-flash-lite-preview
- Link:
📝 Author: APIYI Technical Team | For more AI model usage guides and technical tutorials, please visit the APIYI Help Center at help.apiyi.com