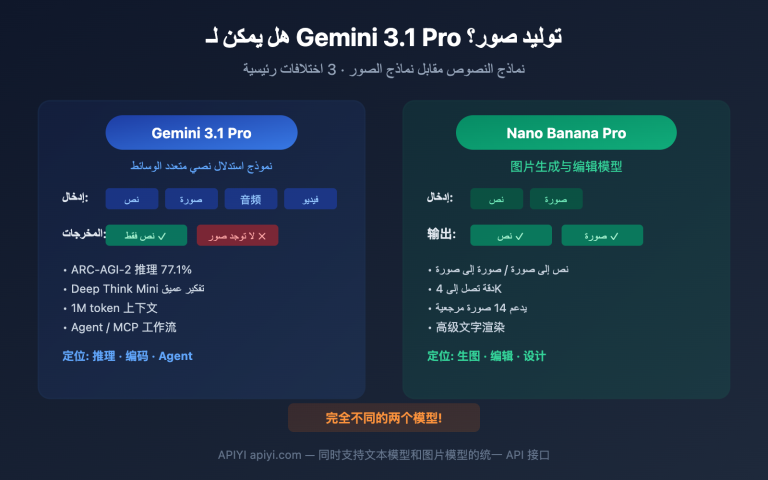
يعد اختيار نموذج ذكاء اصطناعي يتسم بالسرعة والتكلفة المنخفضة تحدياً جوهرياً يواجه كل مطور في سيناريوهات الاستدعاء عالي التردد. في 3 مارس 2026، أطلقت جوجل رسمياً نموذج Gemini 3.1 Flash Lite Preview، وهو النموذج الأسرع والأكثر كفاءة من حيث التكلفة في سلسلة Gemini 3، وقد صُمم خصيصاً لسيناريوهات الإنتاجية العالية مثل الترجمة، التلخيص، والتصنيف.
القيمة الجوهرية: بعد قراءة هذا المقال، ستكتسب فهماً شاملاً للمعايير التقنية، ومزايا الأداء، وأفضل سيناريوهات الاستخدام لنموذج Gemini 3.1 Flash Lite، وستتمكن من البدء في استخدامه بسرعة من خلال كود عملي.

نظرة سريعة على المعايير الجوهرية لنموذج Gemini 3.1 Flash Lite
قبل الغوص في تفاصيل Gemini 3.1 Flash Lite، دعنا نلقي نظرة على المواصفات التقنية الرئيسية لهذا النموذج:
| المعيار | مواصفات Gemini 3.1 Flash Lite | ملاحظات |
|---|---|---|
| معرف النموذج | gemini-3.1-flash-lite-preview |
نسخة معاينة حالياً |
| نافذة السياق | 1,000,000 رمز (tokens) | سياق طويل يصل للمليون |
| الحد الأقصى للمخرجات | 64,000 رمز | يدعم توليد نصوص طويلة |
| سعر الإدخال | 0.25 دولار / مليون رمز | تكلفة منخفضة جداً |
| سعر الإخراج | 1.50 دولار / مليون رمز | مخرجات عالية القيمة |
| سرعة الإخراج | ~382 رمز/ثانية | استجابة فائقة السرعة |
| نمط الإدخال | نص، صورة، صوت، فيديو | متعدد الوسائط أصلي |
| نمط الإخراج | نص | توليد نصوص |
| تاريخ الإصدار | 3 مارس 2026 | أحدث إصدار |
🚀 ابدأ بسرعة: أصبح Gemini 3.1 Flash Lite Preview متاحاً الآن على منصة APIYI (apiyi.com)، ويدعم واجهات برمجة التطبيقات المتوافقة مع OpenAI، مما يتيح لك الوصول إليه بسرعة دون الحاجة إلى إعدادات إضافية.
إليك ترجمة المحتوى التقني إلى اللغة العربية:
المزايا الخمس الرئيسية لنموذج Gemini 3.1 Flash Lite
الميزة الأولى: سرعة أكبر بـ 2.5 مرة
حقق نموذج Gemini 3.1 Flash Lite قفزة نوعية في الأداء. وفقاً لبيانات الاختبار المرجعي من Artificial Analysis:
- وقت الاستجابة للرمز الأول (TTFT): أسرع بـ 2.5 مرة مقارنة بـ Gemini 2.5 Flash.
- سرعة الإخراج: تصل إلى 382 رمزاً (tokens) في الثانية، بزيادة قدرها 64% عن سرعة Gemini 2.5 Flash البالغة 232 رمزاً في الثانية.
- الإنتاجية الإجمالية: تحسنت بنحو 45%.
وهذا يعني أن المستخدمين سيحصلون على تجربة استجابة فورية تقريباً في السيناريوهات الحساسة للتأخير مثل الترجمة الفورية، وروبوتات الدردشة، وتلخيص المحتوى.
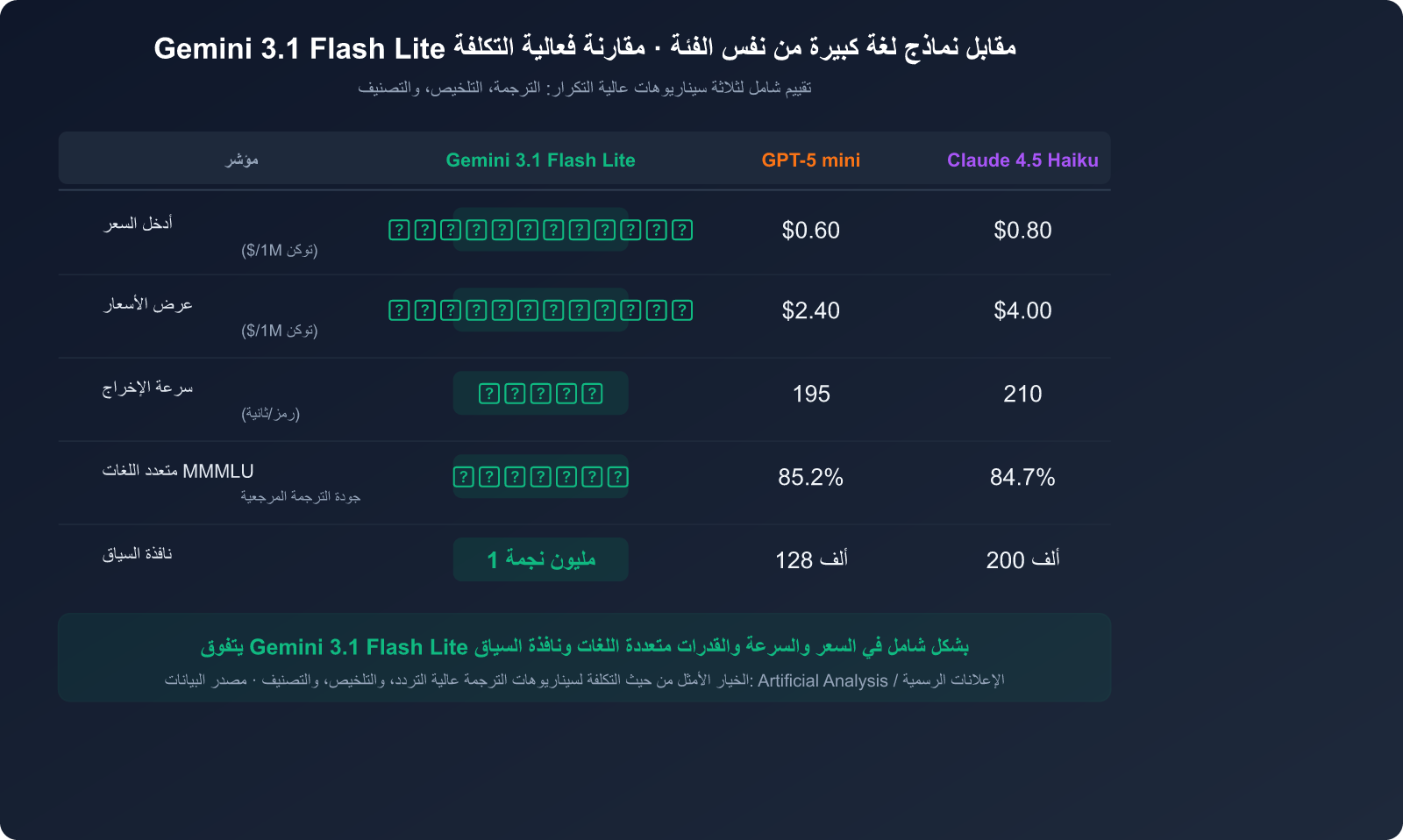
الميزة الثانية: فعالية فائقة من حيث التكلفة
تعد استراتيجية تسعير Gemini 3.1 Flash Lite تنافسية للغاية:
| مقارنة الأسعار | سعر الإدخال ($/مليون رمز) | سعر الإخراج ($/مليون رمز) | التكلفة الإجمالية |
|---|---|---|---|
| Gemini 3.1 Flash Lite | $0.25 | $1.50 | ⭐ الأقل |
| Gemini 3 Flash | $1.00 | $4.00 | متوسطة |
| Gemini 3 Pro | $2.50 | $15.00 | مرتفعة |
| Claude 4.5 Haiku | $0.80 | $4.00 | متوسطة |
| GPT-5 mini | $0.60 | $2.40 | متوسطة |
بافتراض معالجة مليون رمز يومياً، تبلغ التكلفة الشهرية لاستخدام Gemini 3.1 Flash Lite حوالي $52.50 فقط، مما يوفر أكثر من 80% مقارنة بـ Gemini 3 Pro.
الميزة الثالثة: نافذة سياق تصل إلى مليون رمز
يدعم Gemini 3.1 Flash Lite نافذة سياق بحجم 1 مليون رمز، وهو أمر نادر جداً في النماذج التي تقع في نفس الفئة السعرية. وهذا يعني أنه يمكنك:
- معالجة ترجمة أو تلخيص كتاب كامل دفعة واحدة.
- تحليل نصوص مفرغة لاجتماعات استمرت لساعات.
- فهم قواعد بيانات برمجية ضخمة وتوليد وثائق لها.
- إجراء ترجمة متعددة اللغات لوثائق طويلة.
الميزة الرابعة: دعم أصلي متعدد الوسائط
على الرغم من تصنيفه كنموذج خفيف الوزن، إلا أن Gemini 3.1 Flash Lite يحتفظ بقدرات إدخال كاملة متعددة الوسائط:
- النص: فهم وتوليد النصوص القياسية.
- الصور: التعرف على الصور وفهمها.
- الصوت: معالجة المحتوى الصوتي.
- الفيديو: فهم محتوى الفيديو.
وهذا يجعله مناسباً ليس فقط للمهام النصية البحتة، بل أيضاً للسيناريوهات متعددة الوسائط مثل الترجمة المدمجة للصور والنصوص، وتوليد ترجمات الفيديو.
الميزة الخامسة: عمق تفكير قابل للتعديل
يدعم Gemini 3.1 Flash Lite ميزة مستويات التفكير (Thinking Levels)، حيث يمكن للمطورين تعديل عمق استنتاج النموذج بمرونة بناءً على تعقيد المهمة:
- مستوى تفكير منخفض: مناسب للمهام البسيطة مثل الترجمة والتصنيف، مع التركيز على السرعة القصوى.
- مستوى تفكير متوسط: مناسب للمهام التي تتطلب قدراً من الفهم مثل التلخيص وإعادة صياغة المحتوى.
- مستوى تفكير مرتفع: مناسب للمهام التي تتطلب تفكيراً عميقاً مثل الاستنتاج المعقد وتوليد الأكواد البرمجية.

اختبار الأداء لنموذج Gemini 3.1 Flash Lite
حقق نموذج Gemini 3.1 Flash Lite تقييم Elo بلغ 1432 نقطة على لوحة صدارة Arena.ai، مما يجعله يتفوق بوضوح ضمن فئة النماذج المماثلة له.
| اختبار الأداء | Gemini 3.1 Flash Lite | الوصف |
|---|---|---|
| GPQA Diamond | 86.9% | الاستنتاج العلمي |
| MMMU-Pro | 76.8% | الاستنتاج متعدد الوسائط |
| MMMLU | 88.9% | الأسئلة والأجوبة متعددة اللغات |
| LiveCodeBench | 72.0% | توليد الأكواد البرمجية |
| Video-MMMU | 84.8% | فهم الفيديو |
| SimpleQA | 43.3% | المعرفة البارامترية |
| MRCR v2 (128k) | 60.1% | فهم السياق الطويل |
من الجدير بالذكر أن نموذج Gemini 3.1 Flash Lite قد تفوق على GPT-5 mini و Claude 4.5 Haiku في 6 اختبارات أداء بما في ذلك GPQA Diamond و MMMLU، مما يثبت أن النماذج خفيفة الوزن يمكنها تقديم أداء ذكي بمستوى متطور.
🎯 نصيحة تقنية: تشير بيانات اختبار الأداء أعلاه إلى أن Gemini 3.1 Flash Lite يتميز بشكل خاص في معالجة اللغات المتعددة (بنسبة 88.9% في MMMLU)، مما يجعله مناسباً جداً لسيناريوهات الترجمة بين اللغات. يمكنك استدعاء هذا النموذج بسرعة لاختبار مهامك متعددة اللغات عبر خدمة APIYI (apiyi.com).
البدء السريع مع Gemini 3.1 Flash Lite
مثال برمجي بسيط
باستخدام واجهة متوافقة مع OpenAI، يمكنك استدعاء Gemini 3.1 Flash Lite ببضعة أسطر فقط من الكود:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # واجهة APIYI الموحدة
)
# مثال لسيناريو الترجمة
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=[
{"role": "system", "content": "أنت مترجم محترف، يرجى ترجمة النص الصيني الذي يدخله المستخدم إلى الإنجليزية، مع الحفاظ على المعنى الأصلي والنبرة."},
{"role": "user", "content": "人工智能正在深刻改变我们的工作方式和生活方式。"}
],
temperature=0.3
)
print(response.choices[0].message.content)
عرض الكود الكامل: سيناريو الترجمة الجماعية + التلخيص
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # واجهة APIYI الموحدة
)
MODEL = "gemini-3.1-flash-lite-preview"
def translate_text(text, target_lang="English"):
"""ترجمة النص إلى اللغة المستهدفة"""
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": f"Translate the following text to {target_lang}. Keep the original meaning and tone."},
{"role": "user", "content": text}
],
temperature=0.3
)
return response.choices[0].message.content
def summarize_text(text, max_words=100):
"""توليد ملخص للنص"""
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": f"يرجى تلخيص النقاط الأساسية للمحتوى التالي في حدود {max_words} كلمة."},
{"role": "user", "content": text}
],
temperature=0.5
)
return response.choices[0].message.content
def classify_text(text, categories):
"""تصنيف النص"""
cats = "، ".join(categories)
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": f"صنف النص التالي إلى إحدى هذه الفئات: {cats}. أرجع اسم الفئة فقط."},
{"role": "user", "content": text}
],
temperature=0.1
)
return response.choices[0].message.content
# مثال للاستخدام
texts = [
"量子计算将在未来十年彻底改变密码学领域",
"新款电动汽车续航里程突破1000公里",
"央行宣布下调基准利率25个基点"
]
categories = ["تكنولوجيا", "سيارات", "تمويل", "رياضة", "ترفيه"]
for text in texts:
# الترجمة
translated = translate_text(text)
# التصنيف
category = classify_text(text, categories)
# التلخيص
summary = summarize_text(text, max_words=30)
print(f"الأصل: {text}")
print(f"الترجمة: {translated}")
print(f"التصنيف: {category}")
print(f"الملخص: {summary}")
print("---")
💰 تحسين التكاليف: بالنسبة لسيناريوهات الاستدعاء المتكرر مثل الترجمة، التلخيص، والتصنيف، فإن التسعير المنخفض جداً لنموذج Gemini 3.1 Flash Lite (المدخلات تبدأ من 0.25 دولار لكل مليون رمز) يمكن أن يقلل من تكاليف التشغيل بشكل كبير. كما يمكنك الحصول على ميزات سعرية إضافية وأرصدة اختبار مجانية عند الاستدعاء عبر منصة APIYI apiyi.com.
أفضل حالات استخدام Gemini 3.1 Flash Lite
السيناريو الأول: الترجمة الجماعية عالية التردد
يحقق نموذج Gemini 3.1 Flash Lite نتيجة عالية بلغت 88.9% في معيار الأسئلة والأجوبة متعدد اللغات MMMLU، وبالإضافة إلى تكلفة الاستدعاء المنخفضة للغاية وسرعة الاستجابة الفائقة، فإنه يعد الخيار الأمثل لمهام الترجمة الجماعية:
- ترجمة وصف منتجات التجارة الإلكترونية: ترجمة آلاف المعلومات الخاصة بالمنتجات إلى لغات متعددة يومياً.
- ترجمة تعليقات المستخدمين: ترجمة فورية لآراء المستخدمين من الخارج.
- عولمة الوثائق التقنية: إنشاء نسخ متعددة اللغات لوثائق واسعة النطاق.
- ترجمة الترجمة المصاحبة (Subtitles): تحويل سريع للترجمة المصاحبة للفيديوهات إلى لغات متعددة.
السيناريو الثاني: تلخيص المحتوى في الوقت الفعلي
تجعل سرعة الإخراج التي تصل إلى 382 رمزاً (token) في الثانية هذا النموذج مناسباً جداً لسيناريوهات التلخيص الفوري:
- إنشاء ملخصات الأخبار: استخراج تلقائي لملخصات كميات هائلة من الأخبار.
- محاضر الاجتماعات: تلخيص سريع لتسجيلات الاجتماعات الطويلة.
- مراجعة الأدبيات: إنشاء ملخصات جماعية للأوراق البحثية الأكاديمية.
- ملخصات البريد الإلكتروني: التلخيص والتصنيف التلقائي لرسائل البريد الإلكتروني للشركات.
السيناريو الثالث: مراجعة وتصنيف المحتوى على نطاق واسع
تجعله خصائص التأخير المنخفض والتكلفة الزهيدة خياراً مثالياً لخطوط أنابيب مراجعة المحتوى:
- مراجعة المحتوى الذي ينشئه المستخدم: تصفية أمن المحتوى على منصات التواصل الاجتماعي.
- التصنيف التلقائي لتذاكر الدعم: التوجيه الذكي لأنظمة خدمة العملاء.
- تحليل المشاعر: مراقبة فورية لآراء الجمهور حول العلامة التجارية.
- التوليد التلقائي للوسوم: إنشاء وسوم تلقائية لأنظمة إدارة المحتوى.
دليل اتخاذ القرار لاختيار السيناريو
| حالة الاستخدام | سبب التوصية | الميزة الرئيسية | التكلفة الشهرية التقديرية |
|---|---|---|---|
| الترجمة الجماعية | قدرة لغوية فائقة (MMMLU 88.9%) | سعر منخفض + جودة عالية | ~50 دولار (مليون رمز/يوم) |
| التلخيص الفوري | سرعة إخراج فائقة (382 رمز/ثانية) | تأخير منخفض + سرعة | ~30 دولار (500 ألف رمز/يوم) |
| مراجعة المحتوى | دقة تصنيف عالية، استجابة سريعة | تكلفة منخفضة + معالجة جماعية | ~20 دولار (300 ألف رمز/يوم) |
| بوت الدردشة | استجابة أولية (TTFT) أسرع بـ 2.5 مرة | استجابة فورية | ~80 دولار (2 مليون رمز/يوم) |
| معالجة الوثائق الطويلة | نافذة سياق تصل إلى 1 مليون رمز | معالجة كتاب كامل دفعة واحدة | محاسبة حسب الاستخدام |
💡 نصيحة للاختيار: إذا كانت طبيعة عملك تتطلب معالجة نصوص عالية التردد، جماعية، وحساسة للتكلفة، فإن Gemini 3.1 Flash Lite هو الخيار الأفضل من حيث القيمة مقابل السعر حالياً. نوصي بإجراء اختبارات عملية عبر منصة APIYI (apiyi.com)، حيث تدعم المنصة التبديل بضغطة زر واحدة إلى نماذج أخرى للمقارنة بين النتائج.
ملاحظات استخدام Gemini 3.1 Flash Lite
القيود الحالية
باعتباره نموذج لغة كبير في مرحلة المعاينة، يرجى الانتباه للنقاط التالية:
- مرحلة المعاينة: لا يزال النموذج في حالة Preview، لذا قد تطرأ تغييرات على واجهات برمجة التطبيقات (API) وسلوك النموذج.
- حدود المخرجات: الحد الأقصى للمخرجات هو 64 ألف رمز (tokens)، لذا تتطلب مهام التوليد الطويلة جداً معالجتها على أجزاء.
- أداء نافذة السياق الطويلة: الأداء في سيناريوهات السياق الطويل جداً (1 مليون رمز) متوسط (حيث سجل 12.3% فقط في اختبار MRCR v2 1M)، لذا نوصي بالبقاء ضمن نطاق 128 ألف رمز للحصول على أفضل النتائج.
- حدود الأمان: تقييمات الأمان لتحويل الصور إلى نصوص لا تزال بحاجة إلى تحسين، لذا يفضل إضافة طبقة تدقيق عند التعامل مع المحتوى الحساس.
نصائح الاستخدام
- معامل درجة الحرارة (Temperature): نوصي باستخدام
temperature=0.3لمهام الترجمة، وtemperature=0.5لمهام التلخيص. - الموجه (Prompt) النظامي: توفير تعريف واضح للدور ومتطلبات تنسيق المخرجات يمكن أن يحسن جودة النتائج بشكل ملحوظ.
- المعالجة الجماعية: استفد من أسلوب الاستدعاء غير المتزامن (Asynchronous) لزيادة الإنتاجية والاستفادة القصوى من سرعة النموذج.
- التحكم في السياق: على الرغم من دعم نافذة سياق تصل إلى 1 مليون رمز، نوصي بحصر المهام العادية في نطاق 128 ألف رمز للحصول على أفضل توازن بين التكلفة والأداء.
الأسئلة الشائعة
س1: ما الفرق بين Gemini 3.1 Flash Lite و Gemini 3 Flash؟
يعد Gemini 3.1 Flash Lite النسخة الخفيفة ضمن سلسلة Gemini 3، وهو مُحسّن خصيصاً للسيناريوهات ذات التردد العالي والتكلفة المنخفضة. مقارنة بـ Gemini 3 Flash، فإن سعر الإدخال أقل بنسبة 75% (0.25 دولار مقابل 1.00 دولار)، وسرعة المخرجات أسرع بنحو 64%، لكن قدراته في مهام الاستدلال المعقدة أقل قليلاً. ببساطة: إذا كنت تبحث عن أفضل قيمة مقابل السعر اختر Flash Lite، وإذا كنت بحاجة إلى قدرات استدلال أقوى اختر Flash. يمكنك اختبار كلا النموذجين عبر منصة APIYI (apiyi.com) للعثور بسرعة على الخيار الأنسب لسيناريوهات عملك.
س2: هل Gemini 3.1 Flash Lite مناسب لأعمال الترجمة؟
مناسب جداً. فقد حقق Gemini 3.1 Flash Lite درجة عالية بلغت 88.9% في اختبار المعايير متعدد اللغات MMMLU، مما يجعله في صدارة النماذج من فئته. وبالإضافة إلى سعر الإدخال المنخفض جداً (0.25 دولار لكل مليون رمز) وسرعة مخرجات تصل إلى 382 رمزاً/ثانية، فهو أحد أكثر النماذج كفاءة من حيث التكلفة لمهام الترجمة الجماعية. نوصي بالحصول على رصيد اختبار مجاني عبر APIYI (apiyi.com) للتحقق من جودة الترجمة الفعلية.
س3: كيف يمكن استدعاء Gemini 3.1 Flash Lite عبر واجهة متوافقة مع OpenAI؟
ما عليك سوى ضبط base_url على عنوان واجهة APIYI، واستخدام gemini-3.1-flash-lite-preview كمعامل للنموذج (model). لا حاجة لتعديل هيكل كود OpenAI SDK الحالي، مما يتيح لك الانتقال بسلاسة. راجع أمثلة الكود في قسم "البدء السريع" في هذا المقال لمزيد من التفاصيل.
س4: هل نافذة السياق بسعة 1 مليون رمز في Gemini 3.1 Flash Lite عملية حقاً؟
الأداء ممتاز ضمن نطاق 128 ألف رمز (حقق 60.1% في اختبار MRCR v2 128K)، ولكن الأداء ينخفض بشكل ملحوظ في سيناريوهات 1 مليون رمز القصوى (حقق 12.3% في اختبار MRCR v2 1M). نوصي بالتحكم في الاستخدام اليومي ضمن نطاق 128 ألف رمز، واعتماد استراتيجية التجزئة عند التعامل مع المستندات الطويلة جداً.
ملخص
يبرز نموذج Gemini 3.1 Flash Lite Preview كخيار مثالي من حيث التكلفة والأداء لعام 2026 في سيناريوهات الاستخدام المكثف مثل الترجمة، التلخيص، والتصنيف. وذلك بفضل سعره التنافسي البالغ 0.25 دولار لكل مليون رمز (tokens) مدخل، وسرعة استجابة فائقة تصل إلى 382 رمزاً في الثانية، ونافذة سياق ضخمة تصل إلى مليون رمز، بالإضافة إلى أدائه المتميز في اختبارات القياس مثل معالجة اللغات المتعددة (MMMLU بنسبة 88.9%) والاستدلال العلمي (GPQA Diamond بنسبة 86.9%).
سواء كنت بحاجة إلى معالجة ملايين الرموز يومياً في عمليات الترجمة الجماعية، أو بناء خدمة تلخيص فورية ذات زمن استجابة منخفض، فإن Gemini 3.1 Flash Lite هو خيارك الأول.
نوصي بالوصول السريع إلى Gemini 3.1 Flash Lite Preview عبر منصة APIYI (apiyi.com)، حيث توفر المنصة واجهة متوافقة مع OpenAI، وتدعم التبديل بضغطة زر بين العديد من النماذج الرائدة، مما يسهل عليك التحقق من النتائج ومقارنة النماذج بسرعة.
المراجع
-
Google DeepMind – بطاقة نموذج Gemini 3.1 Flash-Lite: المواصفات التقنية الرسمية للنموذج وبيانات اختبارات القياس
- الرابط:
deepmind.google/models/model-cards/gemini-3-1-flash-lite/
- الرابط:
-
Google AI for Developers – معاينة Gemini 3.1 Flash-Lite: وثائق API الرسمية ودليل المطورين
- الرابط:
ai.google.dev/gemini-api/docs/models/gemini-3.1-flash-lite-preview
- الرابط:
-
Artificial Analysis – تقييم الأداء: اختبارات قياس مستقلة للسرعة والأداء
- الرابط:
artificialanalysis.ai/models/gemini-3-1-flash-lite-preview
- الرابط:
📝 الكاتب: الفريق التقني لـ APIYI | للمزيد من أدلة استخدام نماذج الذكاء الاصطناعي والدروس التقنية، يرجى زيارة مركز مساعدة APIYI على help.apiyi.com