Memilih model AI yang cepat dan murah adalah tantangan utama bagi setiap pengembang dalam skenario pemanggilan frekuensi tinggi. Google secara resmi merilis Gemini 3.1 Flash Lite Preview pada 3 Maret 2026. Ini adalah model tercepat dan paling hemat biaya dalam seri Gemini 3, yang dirancang khusus untuk skenario dengan throughput tinggi seperti penerjemahan, ringkasan, dan klasifikasi.
Nilai Inti: Setelah membaca artikel ini, Anda akan memahami parameter teknis, keunggulan performa, dan skenario penggunaan terbaik dari Gemini 3.1 Flash Lite, serta cara cepat menggunakannya melalui kode praktis.

Ringkasan Parameter Inti Gemini 3.1 Flash Lite
Sebelum mendalami Gemini 3.1 Flash Lite, mari kita lihat spesifikasi teknis utama model ini:
| Parameter | Spesifikasi Gemini 3.1 Flash Lite | Keterangan |
|---|---|---|
| ID Model | gemini-3.1-flash-lite-preview |
Saat ini versi pratinjau |
| Jendela Konteks | 1.000.000 token | Konteks panjang level jutaan |
| Output Maksimum | 64.000 token | Mendukung pembuatan teks panjang |
| Harga Input | $0,25 / juta token | Biaya sangat rendah |
| Harga Output | $1,50 / juta token | Output hemat biaya |
| Kecepatan Output | ~382 token/detik | Respons sangat cepat |
| Modalitas Input | Teks, gambar, audio, video | Multimodal asli |
| Modalitas Output | Teks | Pembuatan teks |
| Tanggal Rilis | 3 Maret 2026 | Rilis terbaru |
🚀 Mulai Cepat: Gemini 3.1 Flash Lite Preview telah tersedia di platform APIYI (apiyi.com), mendukung pemanggilan antarmuka yang kompatibel dengan OpenAI, sehingga Anda dapat mengaksesnya dengan cepat tanpa konfigurasi tambahan.
5 Keunggulan Utama Gemini 3.1 Flash Lite
Keunggulan 1: Kecepatan Meningkat 2,5 Kali Lipat
Gemini 3.1 Flash Lite telah mencapai lompatan besar dalam hal kecepatan. Berdasarkan data benchmark dari Artificial Analysis:
- Waktu Respons Token Pertama (TTFT): 2,5 kali lebih cepat dibandingkan Gemini 2.5 Flash.
- Kecepatan Output: Mencapai 382 token/detik, meningkat 64% dibandingkan Gemini 2.5 Flash yang berada di angka 232 token/detik.
- Throughput Keseluruhan: Meningkat sekitar 45%.
Ini berarti untuk skenario yang sensitif terhadap latensi seperti penerjemahan real-time, chatbot, dan ringkasan konten, pengguna bisa mendapatkan pengalaman respons yang hampir instan.
Keunggulan 2: Efisiensi Biaya Terbaik
Strategi penetapan harga Gemini 3.1 Flash Lite sangat kompetitif:
| Perbandingan Harga | Harga Input ($/1M token) | Harga Output ($/1M token) | Biaya Keseluruhan |
|---|---|---|---|
| Gemini 3.1 Flash Lite | $0,25 | $1,50 | ⭐ Terendah |
| Gemini 3 Flash | $1,00 | $4,00 | Sedang |
| Gemini 3 Pro | $2,50 | $15,00 | Tinggi |
| Claude 4.5 Haiku | $0,80 | $4,00 | Sedang |
| GPT-5 mini | $0,60 | $2,40 | Sedang |
Dengan asumsi pemrosesan 1 juta token per hari, biaya bulanan menggunakan Gemini 3.1 Flash Lite hanya sekitar $52,50, menghemat lebih dari 80% dibandingkan Gemini 3 Pro.
Keunggulan 3: Jendela Konteks 1 Juta Token
Gemini 3.1 Flash Lite mendukung jendela konteks sebesar 1 juta token, sesuatu yang sangat jarang ditemukan pada model di kelas harga yang sama. Ini memungkinkan Anda untuk:
- Menerjemahkan atau meringkas seluruh buku dalam satu kali proses.
- Menganalisis transkrip rekaman rapat yang berdurasi berjam-jam.
- Memahami basis kode skala besar dan menghasilkan dokumentasi.
- Melakukan penerjemahan multibahasa untuk dokumen panjang secara berdampingan.
Keunggulan 4: Dukungan Multimodal Asli
Meskipun diposisikan sebagai model ringan, Gemini 3.1 Flash Lite tetap mempertahankan kemampuan input multimodal yang lengkap:
- Teks: Pemahaman dan pembuatan teks standar.
- Gambar: Pengenalan dan pemahaman gambar.
- Audio: Pemrosesan konten suara.
- Video: Pemahaman konten video.
Hal ini membuatnya tidak hanya cocok untuk tugas berbasis teks, tetapi juga skenario multimodal seperti penerjemahan teks-gambar campuran dan pembuatan subtitle video.
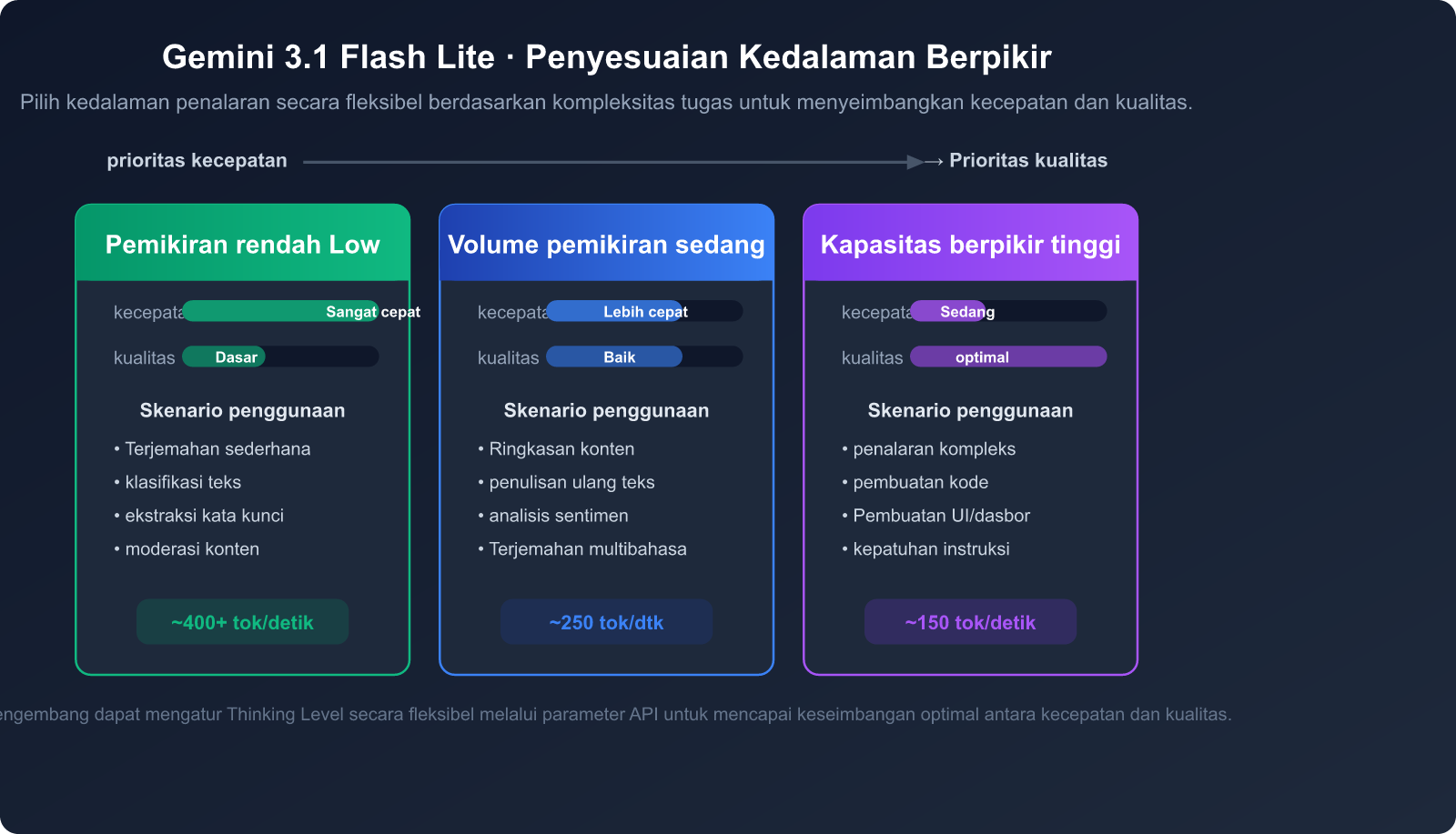
Keunggulan 5: Kedalaman Berpikir yang Dapat Diatur
Gemini 3.1 Flash Lite mendukung fitur Thinking Levels, di mana pengembang dapat menyesuaikan kedalaman penalaran model secara fleksibel sesuai dengan kompleksitas tugas:
- Tingkat Berpikir Rendah: Cocok untuk penerjemahan sederhana, klasifikasi, dll., dengan fokus pada kecepatan maksimal.
- Tingkat Berpikir Sedang: Cocok untuk ringkasan, penulisan ulang konten, dan tugas yang memerlukan pemahaman tertentu.
- Tingkat Berpikir Tinggi: Cocok untuk penalaran kompleks, pembuatan kode, dan tugas yang memerlukan pemikiran mendalam.
Tolok Ukur Performa Gemini 3.1 Flash Lite
Gemini 3.1 Flash Lite berhasil meraih skor Elo 1432 di papan peringkat Arena.ai, menjadikannya salah satu model yang paling menonjol di kelasnya.
| Tolok Ukur | Gemini 3.1 Flash Lite | Penjelasan |
|---|---|---|
| GPQA Diamond | 86.9% | Penalaran pengetahuan ilmiah |
| MMMU-Pro | 76.8% | Penalaran multimodal |
| MMMLU | 88.9% | Tanya jawab multibahasa |
| LiveCodeBench | 72.0% | Pembuatan kode |
| Video-MMMU | 84.8% | Pemahaman video |
| SimpleQA | 43.3% | Pengetahuan parametrik |
| MRCR v2 (128k) | 60.1% | Pemahaman jendela konteks panjang |
Perlu dicatat bahwa dalam 6 tolok ukur termasuk GPQA Diamond dan MMMLU, Gemini 3.1 Flash Lite melampaui GPT-5 mini dan Claude 4.5 Haiku. Ini membuktikan bahwa model ringan pun mampu memberikan performa kecerdasan tingkat lanjut.
🎯 Saran Teknis: Data tolok ukur di atas menunjukkan bahwa Gemini 3.1 Flash Lite sangat unggul dalam pemrosesan multibahasa (MMMLU 88.9%), sehingga sangat cocok untuk skenario penerjemahan lintas bahasa. Anda dapat dengan cepat menguji model ini untuk tugas multibahasa melalui APIYI di apiyi.com.
Memulai Cepat Gemini 3.1 Flash Lite
Contoh Kode Minimalis
Dengan menggunakan antarmuka yang kompatibel dengan OpenAI, Anda hanya perlu beberapa baris kode untuk memanggil Gemini 3.1 Flash Lite:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Antarmuka terpadu APIYI
)
# Contoh skenario penerjemahan
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=[
{"role": "system", "content": "Anda adalah penerjemah profesional. Terjemahkan input bahasa Mandarin pengguna ke bahasa Inggris, pertahankan makna dan nada aslinya."},
{"role": "user", "content": "人工智能正在深刻改变我们的工作方式和生活方式。"}
],
temperature=0.3
)
print(response.choices[0].message.content)
Lihat kode lengkap: Skenario terjemahan batch + ringkasan
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Antarmuka terpadu APIYI
)
MODEL = "gemini-3.1-flash-lite-preview"
def translate_text(text, target_lang="English"):
"""Menerjemahkan teks ke bahasa target"""
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": f"Terjemahkan teks berikut ke {target_lang}. Pertahankan makna dan nada aslinya."},
{"role": "user", "content": text}
],
temperature=0.3
)
return response.choices[0].message.content
def summarize_text(text, max_words=100):
"""Menghasilkan ringkasan teks"""
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": f"Ringkas poin-poin utama dari konten berikut dalam maksimal {max_words} kata."},
{"role": "user", "content": text}
],
temperature=0.5
)
return response.choices[0].message.content
def classify_text(text, categories):
"""Klasifikasi teks"""
cats = "、".join(categories)
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": f"Klasifikasikan teks berikut ke dalam salah satu kategori ini: {cats}. Hanya kembalikan nama kategorinya."},
{"role": "user", "content": text}
],
temperature=0.1
)
return response.choices[0].message.content
# Contoh penggunaan
texts = [
"量子计算将在未来十年彻底改变密码学领域",
"新款电动汽车续航里程突破1000公里",
"央行宣布下调基准利率25个基点"
]
categories = ["Teknologi", "Otomotif", "Keuangan", "Olahraga", "Hiburan"]
for text in texts:
# Terjemahan
translated = translate_text(text)
# Klasifikasi
category = classify_text(text, categories)
# Ringkasan
summary = summarize_text(text, max_words=30)
print(f"Teks Asli: {text}")
print(f"Terjemahan: {translated}")
print(f"Kategori: {category}")
print(f"Ringkasan: {summary}")
print("---")
💰 Optimasi Biaya: Untuk skenario pemanggilan frekuensi tinggi seperti penerjemahan, ringkasan, dan klasifikasi, harga Gemini 3.1 Flash Lite yang sangat rendah (input hanya $0,25 per juta token) dapat secara signifikan mengurangi biaya operasional. Anda juga bisa mendapatkan keuntungan harga tambahan dan saldo uji coba gratis melalui platform APIYI di apiyi.com.
Skenario Penggunaan Terbaik Gemini 3.1 Flash Lite
Skenario 1: Penerjemahan Massal Frekuensi Tinggi
Gemini 3.1 Flash Lite mencapai skor tinggi 88,9% pada tolok ukur multibahasa MMMLU. Ditambah dengan biaya pemanggilan yang sangat rendah dan kecepatan respons yang sangat cepat, model ini adalah pilihan ideal untuk tugas penerjemahan massal:
- Penerjemahan deskripsi produk e-commerce: Menerjemahkan puluhan ribu informasi produk ke berbagai bahasa setiap hari
- Penerjemahan ulasan pengguna: Menerjemahkan umpan balik pengguna luar negeri secara real-time
- Internasionalisasi dokumentasi teknis: Pembuatan versi multibahasa untuk dokumen berskala besar
- Penerjemahan subtitle: Konversi multibahasa yang cepat untuk subtitle video
Skenario 2: Ringkasan Konten Real-time
Kecepatan output sebesar 382 token/detik membuatnya sangat cocok untuk skenario ringkasan real-time:
- Pembuatan ringkasan berita: Ekstraksi ringkasan otomatis untuk berita dalam jumlah besar
- Notulensi rapat: Ringkasan cepat dari rekaman rapat yang panjang
- Tinjauan pustaka: Pembuatan ringkasan massal untuk makalah akademik
- Ringkasan email: Klasifikasi dan ringkasan otomatis untuk email perusahaan
Skenario 3: Moderasi dan Klasifikasi Konten Skala Besar
Karakteristik latensi rendah dan biaya murah menjadikannya pilihan ideal untuk alur kerja moderasi konten:
- Moderasi konten buatan pengguna: Penyaringan keamanan konten di platform media sosial
- Klasifikasi tiket otomatis: Perutean cerdas untuk sistem layanan pelanggan
- Analisis sentimen: Pemantauan real-time untuk opini publik terhadap merek
- Pembuatan tag otomatis: Pelabelan otomatis untuk sistem manajemen konten
Panduan Keputusan Pemilihan Skenario
| Skenario Penggunaan | Alasan Rekomendasi | Keunggulan Utama | Estimasi Biaya Bulanan |
|---|---|---|---|
| Penerjemahan Massal | Kemampuan multibahasa MMMLU 88,9% yang menonjol | Harga murah + kualitas tinggi | ~$50 (1 juta token/hari) |
| Ringkasan Real-time | Output super cepat 382 token/detik | Latensi rendah + cepat | ~$30 (500 ribu token/hari) |
| Moderasi Konten | Akurasi klasifikasi tinggi, respons cepat | Biaya rendah + pemrosesan massal | ~$20 (300 ribu token/hari) |
| Chatbot | TTFT 2,5 kali lebih cepat | Respons instan | ~$80 (2 juta token/hari) |
| Pemrosesan Dokumen Panjang | Jendela konteks 1M token | Memproses seluruh buku sekaligus | Penagihan sesuai pemakaian |
💡 Saran Pemilihan: Jika skenario bisnis Anda adalah tugas pemrosesan teks yang bersifat frekuensi tinggi, massal, dan sensitif terhadap biaya, Gemini 3.1 Flash Lite adalah pilihan dengan rasio harga-performa terbaik saat ini. Kami menyarankan untuk melakukan pengujian skenario nyata melalui platform APIYI apiyi.com, yang mendukung peralihan satu klik ke model lain untuk perbandingan hasil.
Catatan Penggunaan Gemini 3.1 Flash Lite
Batasan Saat Ini
Sebagai model versi pratinjau, perhatikan beberapa hal berikut:
- Tahap Pratinjau: Model masih dalam status Pratinjau, antarmuka API dan perilakunya mungkin akan mengalami penyesuaian
- Batasan Output: Output maksimum adalah 64K token, tugas pembuatan yang sangat panjang perlu diproses secara bertahap
- Performa Konteks Sangat Panjang: Performa dalam skenario konteks sangat panjang 1M token (uji MRCR v2 1M hanya 12,3%) tergolong biasa saja, disarankan untuk mengontrolnya dalam 128K agar mendapatkan hasil terbaik
- Batas Keamanan: Skor keamanan dari gambar ke teks masih perlu ditingkatkan, tambahkan lapisan moderasi jika melibatkan konten sensitif
Saran Penggunaan
- Parameter suhu: Untuk tugas penerjemahan disarankan menggunakan
temperature=0.3, untuk tugas ringkasan disarankantemperature=0.5 - Petunjuk sistem: Berikan definisi peran dan persyaratan format output yang jelas untuk meningkatkan kualitas output secara signifikan
- Pemrosesan massal: Manfaatkan metode pemanggilan asinkron untuk meningkatkan throughput dan memaksimalkan keunggulan kecepatan model
- Kontrol konteks: Meskipun mendukung konteks 1M, disarankan untuk mengontrol tugas rutin dalam 128K agar mendapatkan rasio harga-performa terbaik
Pertanyaan Umum (FAQ)
Q1: Apa perbedaan antara Gemini 3.1 Flash Lite dan Gemini 3 Flash?
Gemini 3.1 Flash Lite adalah versi ringan dalam seri Gemini 3 yang dioptimalkan untuk skenario frekuensi tinggi dengan biaya rendah. Dibandingkan dengan Gemini 3 Flash, harga inputnya 75% lebih murah ($0,25 vs $1,00) dan kecepatan outputnya sekitar 64% lebih cepat, namun kemampuannya dalam tugas penalaran kompleks sedikit lebih rendah. Singkatnya: pilih Flash Lite jika Anda mengutamakan efisiensi biaya, dan pilih Flash jika Anda membutuhkan kemampuan penalaran yang lebih kuat. Anda dapat menguji kedua model tersebut melalui platform APIYI apiyi.com untuk menemukan pilihan yang paling sesuai dengan kebutuhan Anda.
Q2: Apakah Gemini 3.1 Flash Lite cocok digunakan untuk penerjemahan?
Sangat cocok. Gemini 3.1 Flash Lite memperoleh skor tinggi 88,9% pada tolok ukur multibahasa MMMLU, menempatkannya di posisi terdepan di antara model sekelasnya. Ditambah dengan harga input yang sangat murah yaitu $0,25 per juta token dan kecepatan output 382 token/detik, ini adalah salah satu model paling hemat biaya untuk tugas penerjemahan massal saat ini. Kami sarankan untuk mendapatkan kuota uji coba gratis melalui APIYI apiyi.com guna memverifikasi kualitas terjemahan secara langsung.
Q3: Bagaimana cara memanggil Gemini 3.1 Flash Lite melalui antarmuka yang kompatibel dengan OpenAI?
Cukup atur base_url ke alamat antarmuka APIYI dan gunakan gemini-3.1-flash-lite-preview untuk parameter model. Anda tidak perlu mengubah struktur kode SDK OpenAI yang sudah ada, sehingga peralihan dapat dilakukan dengan mulus. Lihat contoh kode di bagian "Memulai dengan Cepat" dalam artikel ini untuk detail lebih lanjut.
Q4: Apakah jendela konteks 1M pada Gemini 3.1 Flash Lite benar-benar berfungsi dengan baik?
Performa model ini sangat baik dalam rentang 128K token (skor MRCR v2 128K mencapai 60,1%), namun kinerjanya menurun secara signifikan dalam skenario ekstrem 1M token (skor MRCR v2 1M mencapai 12,3%). Kami menyarankan untuk menjaga penggunaan dalam batas 128K untuk aktivitas sehari-hari, dan gunakan strategi segmentasi jika Anda perlu memproses dokumen yang sangat panjang.
Kesimpulan
Gemini 3.1 Flash Lite Preview hadir dengan harga input yang sangat terjangkau yaitu $0,25 per juta token, kecepatan output kilat 382 token/detik, jendela konteks 1M token, serta performa luar biasa dalam tolok ukur pemrosesan multibahasa (MMMLU 88,9%) dan penalaran ilmiah (GPQA Diamond 86,9%). Hal ini menjadikannya pilihan paling efisien untuk skenario frekuensi tinggi seperti penerjemahan, peringkasan, dan klasifikasi di tahun 2026.
Baik Anda perlu menangani penerjemahan massal jutaan token setiap hari atau membangun layanan peringkasan waktu nyata dengan latensi rendah, Gemini 3.1 Flash Lite adalah pilihan yang patut diprioritaskan.
Kami merekomendasikan akses cepat ke Gemini 3.1 Flash Lite Preview melalui APIYI apiyi.com. Platform ini menyediakan antarmuka yang kompatibel dengan OpenAI dan mendukung peralihan satu klik ke berbagai model utama, sehingga memudahkan Anda dalam memvalidasi hasil dan membandingkan pilihan model.
Referensi
-
Google DeepMind – Kartu Model Gemini 3.1 Flash-Lite: Spesifikasi teknis model resmi dan data pengujian tolok ukur
- Tautan:
deepmind.google/models/model-cards/gemini-3-1-flash-lite/
- Tautan:
-
Google AI for Developers – Pratinjau Gemini 3.1 Flash-Lite: Dokumentasi API resmi dan panduan pengembang
- Tautan:
ai.google.dev/gemini-api/docs/models/gemini-3.1-flash-lite-preview
- Tautan:
-
Artificial Analysis – Evaluasi Performa: Tolok ukur kecepatan dan performa dari pihak ketiga yang independen
- Tautan:
artificialanalysis.ai/models/gemini-3-1-flash-lite-preview
- Tautan:
📝 Penulis: Tim Teknis APIYI | Untuk panduan penggunaan Model Bahasa Besar dan tutorial teknis AI lainnya, silakan kunjungi pusat bantuan APIYI di help.apiyi.com