تم إطلاق سلسلة Grok 4.20 Beta من xAI رسمياً على منصة APIYI، حيث تمت إضافة 4 نماذج جديدة دفعة واحدة، تغطي كافة السيناريوهات بدءاً من الأسئلة والأجوبة السريعة وصولاً إلى الأبحاث العميقة متعددة الوكلاء. وبسعر 2 دولار للمدخلات و6 دولارات للمخرجات لكل مليون رمز (tokens)، تُعد هذه السلسلة واحدة من أكثر الخيارات فعالية من حيث التكلفة بين النماذج الرائدة الحالية.
هذه النماذج الأربعة ليست مجرد تحديثات رقمية، بل هي اختلافات على مستوى البنية المعمارية: فبعضها يركز على سرعة الاستجابة القصوى، وبعضها مخصص للاستنتاج العميق، كما يوجد نموذج يتيح لـ 4 وكلاء ذكاء اصطناعي العمل معاً، مما يقلل معدل الهلوسة بنسبة 65%.
القيمة الجوهرية: بعد قراءة هذا المقال، ستفهم التموضع الخاص بكل نموذج من نماذج Grok 4.20 Beta وسيناريوهات استخدامه المثلى، وستتعلم كيفية استدعاء النماذج عبر API لاتخاذ أفضل قرار بشأن اختيار النموذج المناسب.

نظرة عامة على النماذج الأربعة: فروقات جوهرية
مصفوفة النماذج
| معرف النموذج (ID) | التموضع | الخصائص الجوهرية | السيناريو الأمثل |
|---|---|---|---|
grok-4.20-beta |
رائد عام | توازن بين الأداء والسرعة | التطوير اليومي، المهام العامة |
grok-4.20-multi-agent-beta-0309 |
تعاون متعدد الوكلاء | 4 وكلاء يعملون بالتوازي | الأبحاث العميقة، التحليل المعقد |
grok-4.20-beta-0309-non-reasoning |
استجابة سريعة | تخطي سلسلة الاستنتاج، تأخير منخفض | المعالجة الدفعية، الأسئلة البسيطة |
grok-4.20-beta-0309-reasoning |
استنتاج عميق | توسيع سلسلة التفكير | الرياضيات، تحليل الكود، الحجج المنطقية |
تسعير موحد
| بند التكلفة | السعر |
|---|---|
| رموز المدخلات | $2.00 / مليون رمز |
| رموز المخرجات | $6.00 / مليون رمز |
| نافذة السياق | 2 مليون رمز (2M) |
| خصم المعالجة الدفعية | 50% |
مقارنة الأسعار مع المنافسين:
| النموذج | سعر المدخلات | سعر المخرجات | الفعالية |
|---|---|---|---|
| Grok 4.20 Beta | $2.00 | $6.00 | 🟢 الأفضل |
| Gemini 3.1 Pro | $2.00 | $12.00 | جيد |
| GPT-5.4 | $2.50 | $15.00 | متوسط |
| Claude Sonnet 4.6 | $3.00 | $15.00 | متوسط |
| Claude Opus 4.6 | $15.00 | $75.00 | مرتفع |
سعر مخرجات Grok 4.20 يمثل فقط 40% من سعر Claude Sonnet 4.6، و8% من سعر Claude Opus 4.6. بالنسبة للمهام التي تتطلب مخرجات كثيفة (توليد الكود، النصوص الطويلة)، فإن ميزة التكلفة واضحة جداً.
🎯 ملاحظة حول التسعير: تسعير سلسلة Grok 4.20 Beta على منصة APIYI apiyi.com يطابق التسعير الرسمي لموقع xAI (2 دولار للمدخلات / 6 دولارات للمخرجات)، وتنعكس الخصومات في أنشطة شحن الرصيد على المنصة. مفتاح API واحد يكفي لاستدعاء أكثر من 200 نموذج بما في ذلك Grok وClaude وGPT وغيرها.
title: "تحليل معمق لـ 4 نماذج لغة كبيرة من سلسلة Grok 4.20"
description: "دليل شامل لاستخدام نماذج Grok 4.20: من النموذج العام إلى الأنظمة متعددة الوكلاء، ونماذج الاستدلال المتخصصة، وكيفية دمجها عبر APIYI."
تحليل معمق لـ 4 نماذج

النموذج الأول: grok-4.20-beta (النموذج العام الرائد)
هذا هو المدخل الافتراضي لسلسلة Grok 4.20، حيث يوازن بين الأداء والسرعة والتكلفة.
الخصائص الأساسية:
- يرث جميع قدرات عائلة Grok 4.
- نافذة سياق تصل إلى 2 مليون رمز (Token) – وهي الأكبر بين النماذج الغربية الرائدة.
- يدعم إدخال الصور (JPG/PNG).
- تحسين مستمر أسبوعياً بناءً على ردود الفعل الواقعية.
الأداء القياسي:
- SWE-bench: حوالي 75% (يقترب من 74.9% لنموذج GPT-5).
- GPQA (مستوى الدراسات العليا): 88.4%.
- Arena Elo: حوالي 1,505-1,535.
سيناريوهات الاستخدام: المساعدة اليومية في البرمجة، إنشاء المحتوى، تحليل البيانات، والمحادثات العامة.
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # خدمة وكيل API الموحدة من APIYI
)
response = client.chat.completions.create(
model="grok-4.20-beta",
messages=[
{"role": "user", "content": "قم بتنفيذ ذاكرة تخزين مؤقت من نوع LRU باستخدام بايثون"}
]
)
print(response.choices[0].message.content)
النموذج الثاني: grok-4.20-multi-agent-beta-0309 (متعدد الوكلاء)
هذا هو المتغير الأكثر ابتكاراً في Grok 4.20، حيث يعمل 4 وكلاء ذكاء اصطناعي معاً في وقت واحد لمعالجة طلبك.
الوكلاء الأربعة وأدوارهم:
| الوكيل | الدور | التخصص |
|---|---|---|
| Grok (القائد) | المنسق | تقسيم المهام، إدارة سير العمل، تجميع المخرجات |
| Harper | الباحث | استرجاع البيانات الفورية، التحقق من الحقائق (عبر بيانات X/Twitter) |
| Benjamin | المحلل | الاستدلال المنطقي، الحسابات الرياضية، تحليل الأكواد |
| Lucas | المتحدي | التوليف الإبداعي، موقف معارض مدمج – التشكيك في استنتاجات الوكلاء الآخرين |
سير العمل:
سؤال المستخدم
↓
Grok يقسم المهمة ← يوزعها على الوكلاء الأربعة
↓
Harper يجمع البيانات | Benjamin يحلل منطقياً | Lucas يتحدى النتائج
↓
نقاش داخلي بين الوكلاء + تحقق متقاطع
↓
Grok يجمع التوافق في الآراء ← يعيد الإجابة النهائية
أبرز ميزة – تقليل معدل الهلوسة بنسبة 65%:
| المؤشر | النموذج الفردي الأساسي | نمط متعدد الوكلاء | التحسن |
|---|---|---|---|
| معدل الهلوسة | ~12% | ~4.2% | انخفاض 65% |
| معدل "قول لا أعرف عند عدم اليقين" | — | 78% | الأعلى في الصناعة |
يعد "الموقف المعارض المدمج" لدى Lucas تصميماً جوهرياً؛ حيث تكمن وظيفته في البحث عن ثغرات في استنتاجات الوكلاء الآخرين. هذا التعاون التنافسي يجعل المخرجات النهائية أكثر موثوقية.
سيناريوهات الاستخدام: تقارير الأبحاث المتعمقة، تحليل القرارات المعقدة، المخرجات التي تتطلب مصداقية عالية.
response = client.chat.completions.create(
model="grok-4.20-multi-agent-beta-0309",
messages=[
{"role": "user", "content": "حلل المشهد التنافسي وتوقعات اتجاهات سوق أدوات البرمجة بالذكاء الاصطناعي لعام 2026"}
]
)
النموذج الثالث: grok-4.20-beta-0309-non-reasoning (غير استدلالي)
هذا المتغير مُحسّن للسرعة والإنتاجية العالية. يتجاوز سلاسل الاستدلال الداخلية (Chain-of-Thought) ويولد الإجابة مباشرة.
الخصائص الأساسية:
- زمن استجابة منخفض، إنتاجية عالية.
- لا يولد رموز استدلال داخلية، مما يوفر تكاليف المخرجات.
- مناسب للمهام البسيطة والمباشرة.
سيناريوهات الاستخدام:
- استدعاءات API عالية التردد (معالجة البيانات الضخمة).
- روبوتات الدردشة / أنظمة خدمة العملاء.
- تصنيف المحتوى، استخراج الوسوم.
- إكمال الأكواد البسيطة.
- الترجمة والتلخيص.
غير مناسب لـ: الاستنتاجات الرياضية المعقدة، التحليل المنطقي متعدد الخطوات، وتصميم البنيات التي تتطلب تفكيراً عميقاً.
response = client.chat.completions.create(
model="grok-4.20-beta-0309-non-reasoning",
messages=[
{"role": "user", "content": "حول ملف JSON التالي إلى تنسيق CSV: ..."}
]
)
النموذج الرابع: grok-4.20-beta-0309-reasoning (استدلالي)
هذا هو المتغير المخصص للاستدلال العميق، وهو النقيض للنسخة غير الاستدلالية. يقوم بتفعيل سلسلة تفكير موسعة (Extended Chain-of-Thought) لإجراء استدلال داخلي متعمق قبل الإجابة.
الخصائص الأساسية:
- رموز استدلال موسعة لتحليل المشكلات بعمق.
- أداء متميز في المهام الرياضية والمنطقية (AIME 2025: 100%, HMMT25: 96.7%).
- مؤشر الذكاء من Artificial Analysis: 48.
سيناريوهات الاستخدام:
- البراهين والاستنتاجات الرياضية.
- مراجعة الأكواد وتحليل الأخطاء البرمجية (Bug).
- موازنة خيارات تصميم البنية البرمجية.
- الحجج المنطقية المعقدة.
- تحليل الأوراق البحثية الأكاديمية.
response = client.chat.completions.create(
model="grok-4.20-beta-0309-reasoning",
messages=[
{"role": "user", "content": "حلل احتمالية وجود ظروف السباق (Race Conditions) ومخاطر الجمود (Deadlock) في كود البرمجة المتزامنة هذا"}
]
)
💡 نصيحة اختيار النموذج: بالنسبة لمعظم المهام اليومية، يكفي استخدام
grok-4.20-beta. للمخرجات التي تتطلب موثوقية عالية استخدم نسخة "متعدد الوكلاء"، للمعالجة الجماعية استخدم النسخة "غير الاستدلالية"، وللتحليل المعقد استخدم النسخة "الاستدلالية". يمكنك استدعاء جميع النماذج الأربعة باستخدام مفتاح API واحد عبر APIYI (apiyi.com) والتبديل بينها حسب الحاجة.
شجرة اتخاذ القرار لاختيار النموذج
الاختيار حسب نوع المهمة
| نوع المهمة | النموذج الموصى به | السبب |
|---|---|---|
| المساعدة البرمجية اليومية | grok-4.20-beta |
توازن مثالي بين الأداء والتكلفة |
| معالجة البيانات الضخمة | non-reasoning |
أسرع سرعة وأقل زمن استجابة |
| مراجعة الكود / تحليل الأخطاء | reasoning |
يتطلب استنتاجاً عميقاً |
| كتابة التقارير البحثية | multi-agent |
التحقق المتقاطع عبر 4 وكلاء ذكاء |
| تحليل البيانات اللحظية | multi-agent |
وصول Harper إلى بيانات X اللحظية |
| الاستنتاج الرياضي/المنطقي | reasoning |
درجة كاملة 100% في اختبار AIME |
| روبوتات الدردشة | non-reasoning |
استجابة سريعة بزمن تأخير منخفض |
| الترجمة / التلخيص | non-reasoning |
مهام بسيطة لا تحتاج لاستنتاج |
| تصميم البنية البرمجية | reasoning أو multi-agent |
يتطلب تحليلاً وموازنة |
الاختيار حسب الحساسية للتكلفة
توفير أقصى حد → non-reasoning (بدون رموز استنتاج، أقل مخرجات)
↓
توازن يومي → grok-4.20-beta (توازن عام)
↓
أولوية الجودة → reasoning (استنتاج عميق، رموز مخرجات أكثر)
↓
أعلى موثوقية → multi-agent (4 وكلاء، مخرجات الأكثر تفصيلاً)
🚀 بداية سريعة: نوصي بالبدء بتجربة
grok-4.20-beta. يمكنك الحصول على مفتاح API من خلال التسجيل في خدمة وكيل API عبر APIYI (apiyi.com)، حيث تتطابق الأسعار مع موقع xAI الرسمي (2 دولار للمدخلات / 6 دولار للمخرجات)، مع توفر خصومات إضافية ضمن عروض الشحن.
مقارنة بين Grok 4.20 والنماذج الرائدة
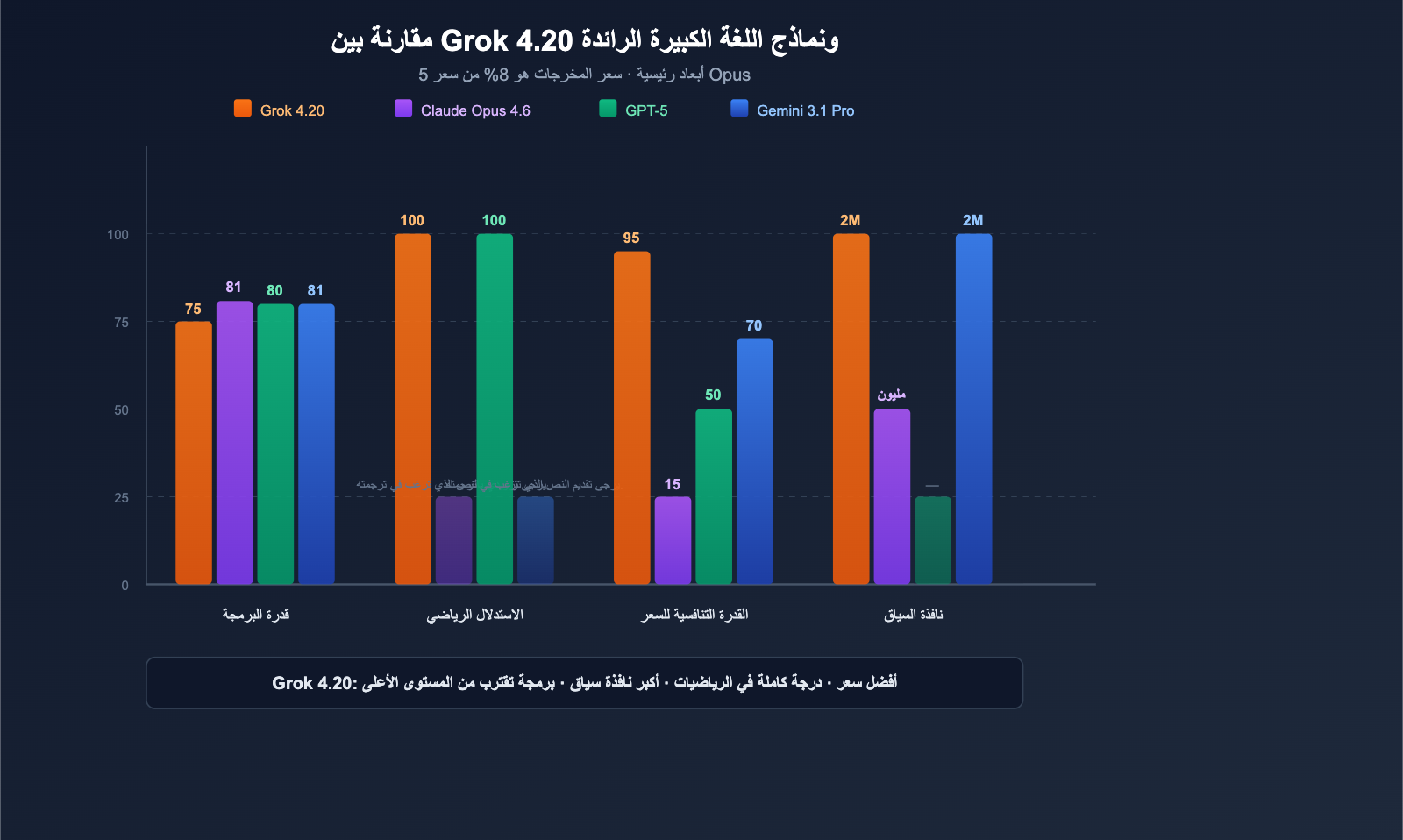
مقارنة شاملة
| البعد | Grok 4.20 Beta | Claude Opus 4.6 | سلسلة GPT-5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench | ~75% | 81.4% | ~80% | ~80.6% |
| الرياضيات (AIME) | 100% | — | 100% | — |
| GPQA | 88.4% | — | — | — |
| نافذة السياق | 2 مليون | 1 مليون | يختلف حسب النموذج | 2 مليون |
| سعر المدخلات | $2 | $15 | $2.50 | $2 |
| سعر المخرجات | $6 | $75 | $15 | $12 |
| متعدد الوكلاء | ✅ 4 وكلاء | ❌ | ❌ | ❌ |
| بيانات لحظية | ✅ X/Twitter | ❌ | ✅ بحث | ✅ بحث |
| التحكم في الهلوسة | 4.2% (الأدنى) | منخفض | منخفض | متوسط |
| مدخلات الصور | ✅ JPG/PNG | ✅ صيغ متعددة | ✅ صيغ متعددة | ✅ صيغ متعددة |
أفضل سيناريوهات الاستخدام لكل نموذج
- Grok 4.20: استخدام عام عالي القيمة، أبحاث عميقة (متعدد الوكلاء)، تحليل بيانات لحظية.
- Claude Opus 4.6: هندسة البرمجيات (الأعلى في SWE-bench)، مخرجات طويلة جداً (128K)، أمان على مستوى المؤسسات.
- GPT-5: كامل الدرجة في الرياضيات، أتمتة سطح المكتب، أكبر نظام بيئي للمستخدمين.
- Gemini 3.1 Pro: تكامل مع نظام Google، نافذة سياق 2 مليون، تكلفة معتدلة.
💰 تحليل التكلفة: سعر مخرجات Grok 4.20 (6 دولار لكل مليون رمز) يمثل 8% فقط من سعر Claude Opus 4.6 (75 دولار لكل مليون رمز). بالنسبة للمهام كثيفة المخرجات (توليد كود طويل، تقارير بحثية)، يمكن لـ Grok 4.20 خفض التكاليف بأكثر من 90%. من خلال APIYI (apiyi.com)، يمكنك الوصول إلى جميع نماذج Grok وClaude وGPT والتبديل بينها بمرونة حسب متطلبات المهمة.
تطبيق عملي لاستدعاء واجهة برمجة التطبيقات (API)
مثال على الاستدعاء الأساسي
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # واجهة برمجة التطبيقات الموحدة من APIYI
)
# المهام العامة → الإصدار الأساسي
response = client.chat.completions.create(
model="grok-4.20-beta",
messages=[
{"role": "system", "content": "أنت مطور Python خبير."},
{"role": "user", "content": "قم بتنفيذ طابور مهام غير متزامن"}
],
max_tokens=4096
)
print(response.choices[0].message.content)
الاختيار التلقائي للنموذج بناءً على المهمة
def choose_grok_model(task_type):
"""اختيار نموذج Grok الأمثل تلقائيًا بناءً على نوع المهمة"""
model_map = {
"quick": "grok-4.20-beta-0309-non-reasoning",
"general": "grok-4.20-beta",
"analysis": "grok-4.20-beta-0309-reasoning",
"research": "grok-4.20-multi-agent-beta-0309"
}
return model_map.get(task_type, "grok-4.20-beta")
# مثال على الاستخدام
model = choose_grok_model("analysis")
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "حلل اختناقات الأداء في هذا الكود..."}]
)
عرض كود اختبار المقارنة بين النماذج المتعددة
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
models = [
"grok-4.20-beta",
"grok-4.20-beta-0309-non-reasoning",
"grok-4.20-beta-0309-reasoning",
"grok-4.20-multi-agent-beta-0309"
]
prompt = "استخدم Python لتنفيذ خوارزمية الترتيب السريع (Quick Sort) وتحليل التعقيد الزمني"
for model in models:
try:
start = time.time()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=2048
)
elapsed = time.time() - start
tokens = response.usage.total_tokens
print(f"{model}")
print(f" الوقت المستغرق: {elapsed:.1f} ثانية | الرموز (Tokens): {tokens}")
print(f" معاينة: {response.choices[0].message.content[:80]}...")
print()
except Exception as e:
print(f"{model} | خطأ: {e}")
time.sleep(1)
🎯 نصيحة عملية: يُنصح بتشغيل اختبار قياسي باستخدام
grok-4.20-betaأولاً، ثم مقارنة جودة المخرجات في المهام المعقدة مع إصدارreasoning. يمكنك استدعاء جميع النماذج الأربعة عبر APIYI (apiyi.com)، حيث تتطابق الأسعار مع الموقع الرسمي، وتتوفر الخصومات ضمن عروض شحن الرصيد.
الأسئلة الشائعة
س1: هل تسعير النماذج الأربعة متطابق؟
نعم، النماذج الأربعة لها تسعير موحد: 2 دولار للمدخلات / 6 دولارات للمخرجات لكل مليون رمز (token). لكن التكلفة الفعلية تختلف حسب النموذج؛ حيث تولد نماذج الاستنتاج (reasoning) رموز استنتاج إضافية (تُحسب كمخرجات)، وقد يستهلك إصدار "متعدد الوكلاء" (multi-agent) المزيد من الرموز بسبب تعاون 4 وكلاء. الإصدار غير الاستنتاجي هو الأكثر توفيراً لأنه يتخطى سلسلة الاستنتاج ويقلل من رموز المخرجات. الاستدعاء عبر APIYI (apiyi.com) يضمن أسعاراً مطابقة للموقع الرسمي لـ xAI، مع خصومات إضافية عبر عروض المنصة.
س2: ما الفرق بين إصدار “متعدد الوكلاء” وإصدار “الاستنتاج”؟
إصدار الاستنتاج يعتمد على وكيل واحد يقوم بتفكير عميق، وهو مناسب لمهام التحليل التي تتطلب إجابات محددة (مثل الرياضيات ومراجعة الكود). أما إصدار متعدد الوكلاء فيعتمد على تعاون 4 وكلاء في نقاش جماعي، وهو مثالي للمسائل المفتوحة التي تتطلب تحليلاً من زوايا متعددة (مثل أبحاث السوق وتحليل القرارات). الميزة الأساسية لهذا الإصدار هي التحقق المتبادل لتقليل معدل الهلوسة (من 12% إلى 4.2%).
س3: هل يمكن لـ Grok 4.20 استبدال Claude في مراجعة الكود؟
في بعض الحالات نعم. حقق Grok 4.20 (إصدار الاستنتاج) حوالي 75% في اختبار SWE-bench، وهو أقل من Claude Opus 4.6 الذي حقق 81.4%، لكن تكلفته تعادل 8% فقط من سعره. بالنسبة لمراجعة الكود اليومية غير الحساسة أمنياً، يعتبر Grok 4.20 خياراً عالي القيمة. أما بالنسبة للتدقيق الأمني ومراجعة البنى التحتية الضخمة، يظل Claude Opus 4.6 أكثر موثوقية. يمكنك الوصول للنموذجين عبر APIYI (apiyi.com) والتبديل بينهما بمرونة حسب المهمة.
س4: ما هي الفائدة العملية لنافذة سياق بحجم 2 مليون رمز؟
حجم 2 مليون رمز يعادل تقريباً كتاباً تقنياً من 1500 صفحة. التطبيقات العملية تشمل: (1) تحميل مكتبة برمجية كاملة متوسطة أو كبيرة الحجم لتحليلها دفعة واحدة؛ (2) معالجة مستندات طويلة جداً (عقود قانونية، مجموعات أوراق بحثية)؛ (3) الحفاظ على ذاكرة محادثة طويلة جداً. تُعد هذه حالياً أكبر نافذة سياق بين النماذج الرائدة عالمياً.
س5: كيف يمكنني استدعاء هذه النماذج عبر منصة APIYI؟
بعد التسجيل في APIYI (apiyi.com) والحصول على مفتاح API، يمكنك الاستدعاء باستخدام تنسيق OpenAI المتوافق. ما عليك سوى ضبط base_url على https://api.apiyi.com/v1 وتعيين model على معرف النموذج المناسب (مثل grok-4.20-beta). راجع أمثلة الكود أعلاه. جميع النماذج الأربعة مطابقة في السعر للموقع الرسمي، وتُقدم الخصومات عبر عروض شحن الرصيد.
ملخص: استراتيجيات الاستخدام الأمثل لنماذج Grok الأربعة
توفر سلسلة Grok 4.20 Beta خيارات دقيقة للنماذج تناسب مختلف السيناريوهات. وتتمثل الاستراتيجية الأساسية في مطابقة النموذج مع تعقيد المهمة:
| التعقيد | النموذج الموصى به | التكلفة |
|---|---|---|
| 🟢 بسيط/عالي التكرار | non-reasoning |
الأقل |
| 🟡 عام/يومي | grok-4.20-beta |
متوسطة |
| 🟠 تحليل عميق | reasoning |
مرتفعة |
| 🔴 أعلى موثوقية | multi-agent |
الأعلى |
بفضل تسعيرها البالغ $2/$6، أصبحت Grok 4.20 النموذج الرائد صاحب أقل تكلفة مخرجات في السوق حالياً. ومع دعم نافذة سياق تصل إلى 2 مليون رمز (token) ونظام متعدد الوكلاء (Multi-Agent)، فإنها تتمتع بقدرة تنافسية عالية في سيناريوهات البحث، والتحليل، وعمليات المعالجة ذات الإنتاجية العالية.
نوصي بالوصول إلى سلسلة نماذج Grok 4.20 Beta بالكامل عبر خدمة وكيل API من APIYI (apiyi.com)، حيث يتطابق التسعير مع الموقع الرسمي، وتتوفر خصومات إضافية من خلال عروض الشحن. يمكنك باستخدام مفتاح API واحد استدعاء أكثر من 200 نموذج، بما في ذلك Grok وClaude وGPT وغيرها.
المراجع
-
وثائق xAI الرسمية: نماذج Grok وتوضيح التسعير
- الرابط:
docs.x.ai/developers/models
- الرابط:
-
Artificial Analysis: تقييم الأداء المرجعي لنموذج Grok 4.20 Beta
- الرابط:
artificialanalysis.ai/models/grok-4-20
- الرابط:
-
وثائق xAI للوكلاء المتعددين: شرح مفصل لقدرات Multi-Agent
- الرابط:
docs.x.ai/developers/model-capabilities/text/multi-agent
- الرابط:
-
OpenRouter: صفحة نموذج Grok 4.20 Beta
- الرابط:
openrouter.ai
- الرابط:
الكاتب: فريق APIYI | نوفر أحدث نماذج الذكاء الاصطناعي فور صدورها، ندعوكم لزيارة APIYI عبر apiyi.com لتجربة سلسلة نماذج Grok 4.20 Beta بالكامل.