Серия Grok 4.20 Beta от xAI официально запущена на платформе APIYI — мы добавили сразу 4 модели, которые перекрывают любые задачи: от быстрых ответов до глубоких исследований с участием нескольких агентов. Стоимость составляет $2 за миллион входных токенов и $6 за миллион выходных, что делает их одним из самых выгодных предложений среди топовых моделей на рынке.
Эти 4 модели — не просто обновление версий, а принципиально разные архитектуры: одни заточены под молниеносную реакцию, другие — под глубокие рассуждения, а одна из них задействует сразу 4 ИИ-агента для совместной работы, что снижает уровень галлюцинаций на 65%.
Главное: из этой статьи вы узнаете, для чего нужна каждая из 4 моделей Grok 4.20 Beta, как их вызывать через API и как сделать правильный выбор для ваших задач.
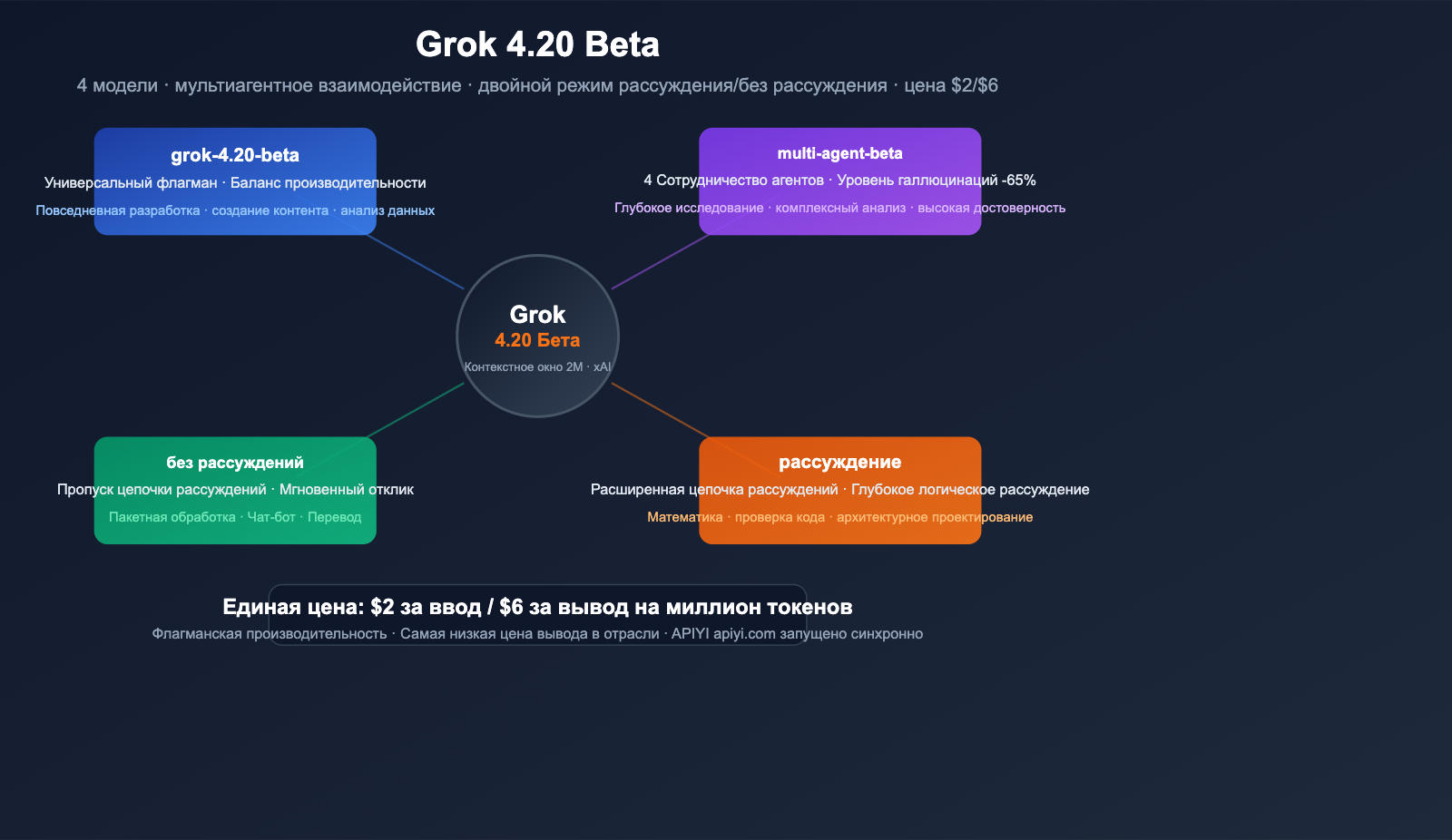
Краткий обзор 4 моделей: в чем разница
Матрица моделей
| ID модели | Позиционирование | Ключевые особенности | Лучшие сценарии |
|---|---|---|---|
grok-4.20-beta |
Универсальный флагман | Баланс производительности и скорости | Повседневная разработка, общие задачи |
grok-4.20-multi-agent-beta-0309 |
Мультиагентная работа | Параллельное взаимодействие 4 агентов | Глубокие исследования, сложный анализ |
grok-4.20-beta-0309-non-reasoning |
Быстрый отклик | Без цепочки рассуждений, низкая задержка | Пакетная обработка, простые ответы |
grok-4.20-beta-0309-reasoning |
Глубокое рассуждение | Расширенная цепочка рассуждений (CoT) | Математика, анализ кода, логические выводы |
Единая тарификация
| Параметр | Цена |
|---|---|
| Входные токены | $2.00 / млн токенов |
| Выходные токены | $6.00 / млн токенов |
| Контекстное окно | 2 млн токенов (2M) |
| Скидка на пакетную обработку | 50% |
Сравнение цен с конкурентами:
| Модель | Вход (цена) | Выход (цена) | Выгода |
|---|---|---|---|
| Grok 4.20 Beta | $2.00 | $6.00 | 🟢 Лучший выбор |
| Gemini 3.1 Pro | $2.00 | $12.00 | Хорошо |
| GPT-5.4 | $2.50 | $15.00 | Средне |
| Claude Sonnet 4.6 | $3.00 | $15.00 | Средне |
| Claude Opus 4.6 | $15.00 | $75.00 | Высокая цена |
Стоимость вывода у Grok 4.20 составляет всего 40% от цены Claude Sonnet 4.6 и 8% от цены Claude Opus 4.6. Для задач с большим объемом вывода (генерация кода, длинные тексты) экономия получается колоссальной.
🎯 Примечание по ценам: Тарифы на серию Grok 4.20 Beta на платформе APIYI (apiyi.com) полностью соответствуют официальным ценам xAI ($2 вход / $6 выход), а дополнительные скидки доступны через акции по пополнению баланса. Один API-ключ позволяет вызывать более 200 моделей, включая Grok, Claude и GPT.
Глубокий разбор 4 моделей
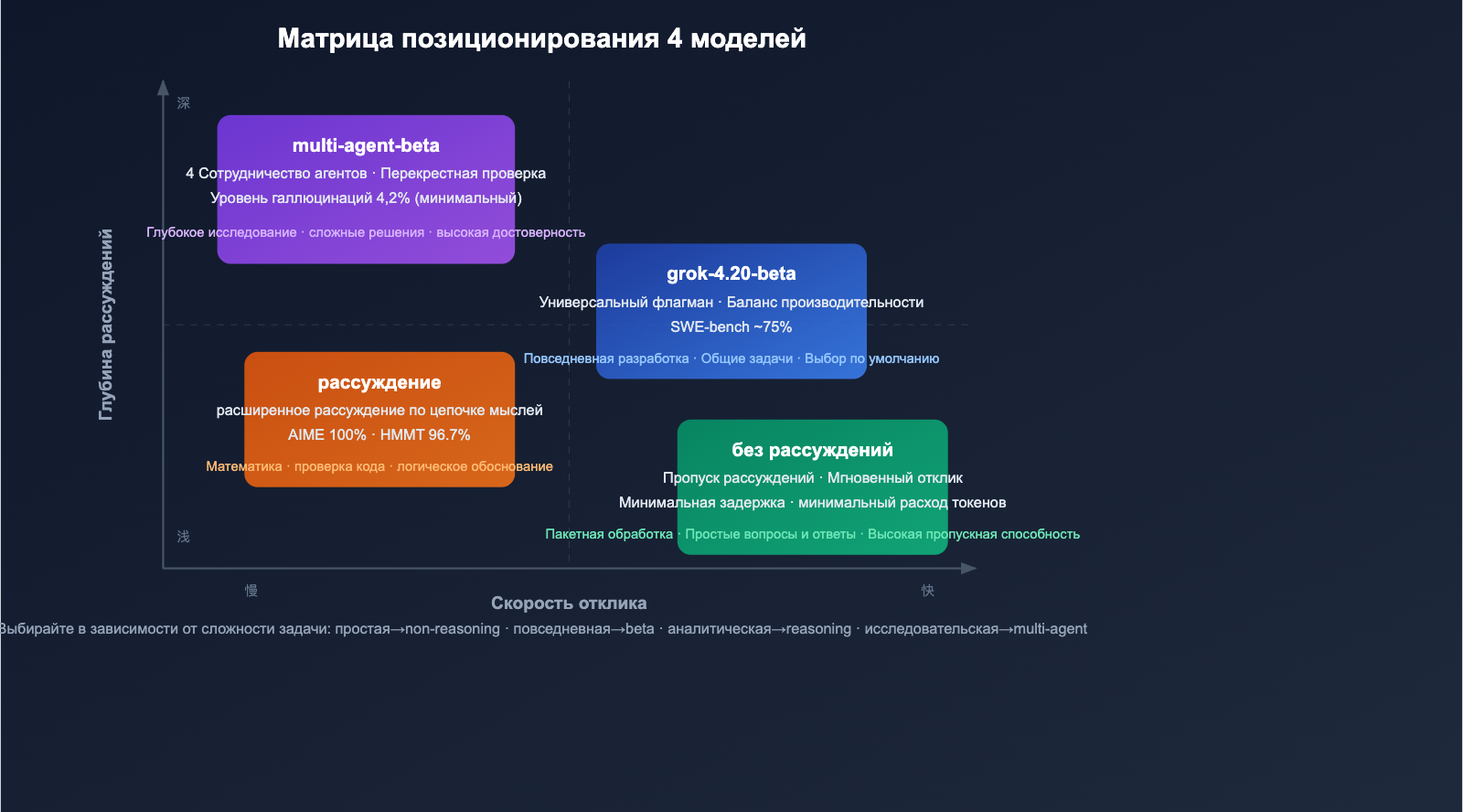
Модель 1: grok-4.20-beta (флагман общего назначения)
Это базовая точка входа в серию Grok 4.20, которая отлично балансирует между производительностью, скоростью и стоимостью.
Основные характеристики:
- Наследует все возможности семейства Grok 4
- Контекстное окно 2 млн токенов — одно из самых больших среди передовых западных моделей
- Поддержка загрузки изображений (JPG/PNG)
- Еженедельные обновления на основе реальных отзывов пользователей
Бенчмарки:
- SWE-bench: ~75% (близко к 74,9% у GPT-5)
- GPQA (уровень магистратуры): 88,4%
- Arena Elo: ~1505–1535
Применение: повседневная помощь в программировании, создание контента, анализ данных, общие диалоги.
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Единый API-интерфейс APIYI
)
response = client.chat.completions.create(
model="grok-4.20-beta",
messages=[
{"role": "user", "content": "Реализуй LRU-кэш на Python"}
]
)
print(response.choices[0].message.content)
Модель 2: grok-4.20-multi-agent-beta-0309 (мультиагентная)
Это самая инновационная вариация Grok 4.20 — 4 ИИ-агента работают сообща, чтобы выполнить ваш запрос.
Роли 4 агентов:
| Агент | Роль | Специализация |
|---|---|---|
| Grok (капитан) | Координатор | Декомпозиция задач, управление процессом, агрегация ответов |
| Harper | Исследователь | Поиск данных в реальном времени, проверка фактов (через данные X/Twitter) |
| Benjamin | Аналитик | Логические рассуждения, математические вычисления, анализ кода |
| Lucas | Критик | Креативный синтез, встроенная оппозиция — ставит под сомнение выводы других агентов |
Рабочий процесс:
Запрос пользователя
↓
Grok разбивает задачу → распределяет между 4 агентами
↓
Harper ищет данные | Benjamin анализирует логику | Lucas критикует
↓
Внутренние дебаты агентов + перекрестная проверка
↓
Grok собирает консенсус → выдает финальный ответ
Главная фишка — снижение галлюцинаций на 65%:
| Показатель | Базовая модель | Мультиагентный режим | Улучшение |
|---|---|---|---|
| Уровень галлюцинаций | ~12% | ~4,2% | Снижение на 65% |
| Доля ответов "не знаю" | — | 78% | Лучший показатель в индустрии |
"Встроенная оппозиция" Лукаса — ключевая деталь дизайна: его задача искать слабые места в выводах коллег. Такое состязательное сотрудничество делает итоговый результат гораздо надежнее.
Применение: глубокие исследовательские отчеты, сложный анализ для принятия решений, задачи, требующие высокой достоверности.
response = client.chat.completions.create(
model="grok-4.20-multi-agent-beta-0309",
messages=[
{"role": "user", "content": "Проанализируй конкурентную среду и тренды на рынке инструментов ИИ-программирования в 2026 году"}
]
)
Модель 3: grok-4.20-beta-0309-non-reasoning (без глубокого рассуждения)
Вариант, оптимизированный для максимальной скорости и пропускной способности. Модель пропускает цепочку внутренних рассуждений (Chain-of-Thought) и сразу генерирует ответ.
Основные характеристики:
- Низкая задержка, высокая скорость
- Не тратит токены на внутренние рассуждения, экономя бюджет
- Идеальна для простых и четких задач
Применение:
- Высокочастотные вызовы API (обработка больших объемов данных)
- Чат-боты / системы поддержки клиентов
- Классификация контента, извлечение тегов
- Простое автодополнение кода
- Перевод, создание кратких выжимок (саммари)
Не подходит для: сложных математических доказательств, многошаговой логики, архитектурного проектирования.
response = client.chat.completions.create(
model="grok-4.20-beta-0309-non-reasoning",
messages=[
{"role": "user", "content": "Преобразуй следующий JSON в формат CSV: ..."}
]
)
Модель 4: grok-4.20-beta-0309-reasoning (с рассуждением)
Вариант для глубоких рассуждений. Модель активирует расширенную цепочку мыслей (Extended Chain-of-Thought) и проводит тщательный внутренний анализ перед ответом.
Основные характеристики:
- Расширенные токены рассуждений для глубокого анализа
- Превосходные результаты в математике и логике (AIME 2025: 100%, HMMT25: 96,7%)
- Индекс интеллекта Artificial Analysis: 48
Применение:
- Математические доказательства и вычисления
- Code review и анализ багов
- Оценка компромиссов при проектировании архитектуры
- Сложные логические аргументации
- Анализ научных статей
response = client.chat.completions.create(
model="grok-4.20-beta-0309-reasoning",
messages=[
{"role": "user", "content": "Проанализируй возможные состояния гонки и риски взаимных блокировок (deadlock) в этом коде"}
]
)
💡 Совет по выбору: Для большинства повседневных задач достаточно
grok-4.20-beta. Если нужна высокая достоверность — берите мультиагентную версию, для массовой обработки — версию без рассуждений, а для сложных аналитических задач — версию с рассуждением. Все 4 модели доступны через один API-ключ на APIYI apiyi.com, переключайтесь между ними по мере необходимости.
Дерево принятия решений по выбору модели
Выбор по типу задачи
| Тип задачи | Рекомендуемая модель | Обоснование |
|---|---|---|
| Повседневная помощь в программировании | grok-4.20-beta |
Баланс производительности и стоимости |
| Пакетная обработка данных | non-reasoning |
Максимальная скорость, минимальная задержка |
| Code Review / Анализ багов | reasoning |
Требуется глубокое рассуждение |
| Написание исследовательских отчетов | multi-agent |
Перекрестная проверка 4 агентами |
| Анализ данных в реальном времени | multi-agent |
Harper с доступом к данным X в реальном времени |
| Математика / логические выводы | reasoning |
100% результат на AIME |
| Чат-боты | non-reasoning |
Быстрый отклик с низкой задержкой |
| Перевод / суммаризация контента | non-reasoning |
Простые задачи, не требующие рассуждений |
| Архитектурное проектирование | reasoning или multi-agent |
Требуется взвешенный анализ |
Выбор по чувствительности к затратам
Максимальная экономия → non-reasoning (нет токенов рассуждения, минимум вывода)
↓
Оптимальный выбор → grok-4.20-beta (универсальный баланс)
↓
Приоритет качества → reasoning (глубокое рассуждение, больше выходных токенов)
↓
Максимальная достоверность → multi-agent (4 агента, максимально подробный вывод)
🚀 Быстрый старт: Рекомендуем начать с
grok-4.20-beta. Зарегистрируйтесь через сервис-прокси API APIYI (apiyi.com), чтобы получить API-ключ. Тарифы соответствуют официальному сайту xAI ($2 за ввод / $6 за вывод), а скидки предоставляются в рамках акций при пополнении баланса.
Сравнительный анализ Grok 4.20 и популярных моделей
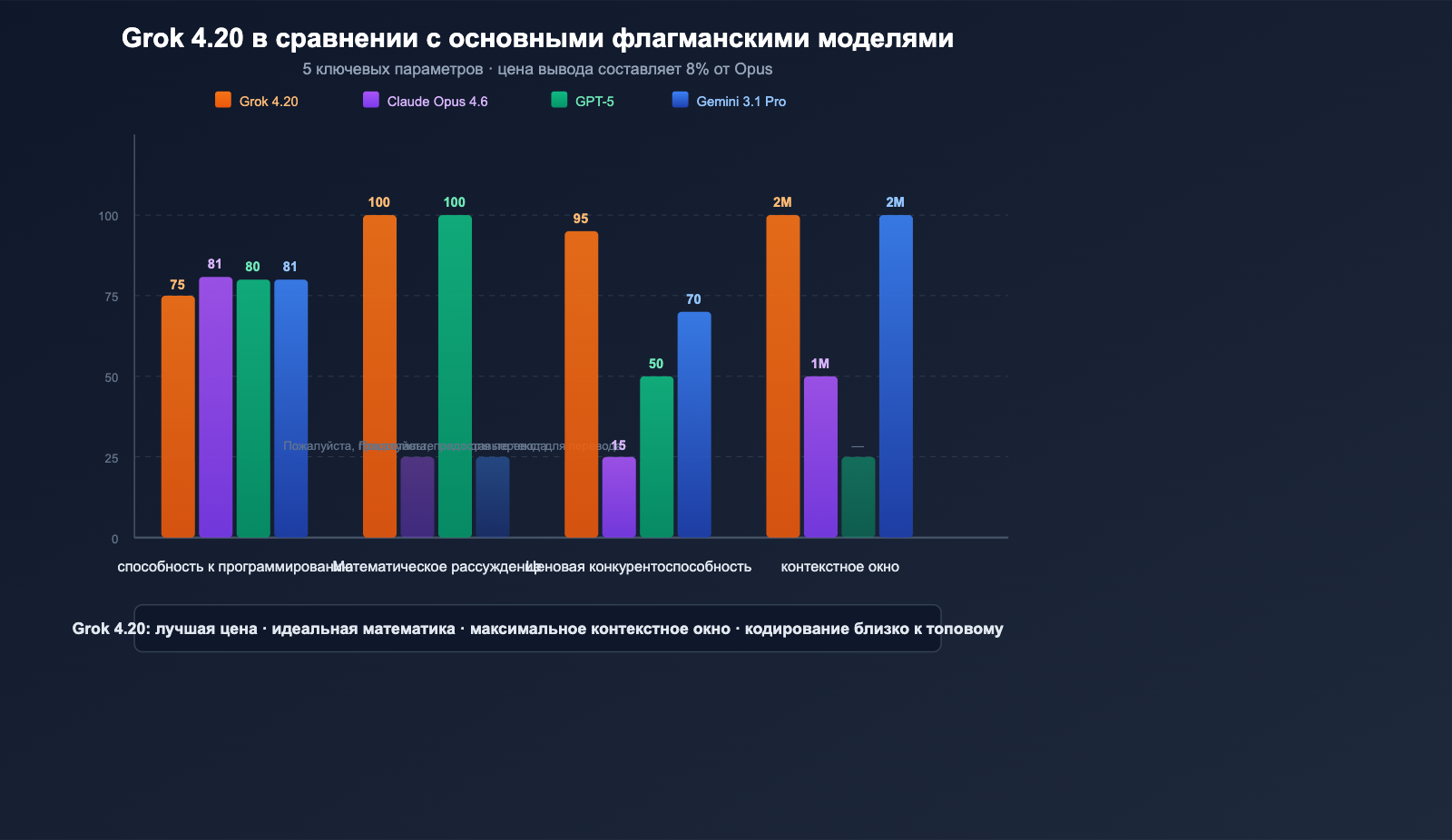
Сравнение по всем параметрам
| Параметр | Grok 4.20 Beta | Claude Opus 4.6 | GPT-5 Series | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench | ~75% | 81.4% | ~80% | ~80.6% |
| Математика (AIME) | 100% | — | 100% | — |
| GPQA | 88.4% | — | — | — |
| Контекст | 2 млн | 1 млн | Зависит от модели | 2 млн |
| Цена ввода | $2 | $15 | $2.50 | $2 |
| Цена вывода | $6 | $75 | $15 | $12 |
| Мультиагентность | ✅ 4 агента | ❌ | ❌ | ❌ |
| Данные в реальном времени | ✅ X/Twitter | ❌ | ✅ Поиск | ✅ Поиск |
| Контроль галлюцинаций | 4.2% (минимум) | Низкий | Низкий | Средний |
| Ввод изображений | ✅ JPG/PNG | ✅ Разные форматы | ✅ Разные форматы | ✅ Разные форматы |
Лучшие сценарии использования моделей
- Grok 4.20: Универсальное решение с высокой эффективностью, глубокие исследования (мультиагенты), анализ данных в реальном времени.
- Claude Opus 4.6: Разработка ПО (лидер в SWE-bench), сверхдлинный вывод (128K), корпоративная безопасность.
- GPT-5: Математические задачи, автоматизация рабочих процессов, крупнейшая пользовательская экосистема.
- Gemini 3.1 Pro: Интеграция с экосистемой Google, контекстное окно 2 млн токенов, умеренная стоимость.
💰 Анализ стоимости: Стоимость вывода Grok 4.20 ($6/млн токенов) составляет всего 8% от стоимости Claude Opus 4.6 ($75/млн токенов). Для задач с интенсивным выводом (генерация длинного кода, исследовательские отчеты) использование Grok 4.20 позволяет сократить расходы более чем на 90%. Через APIYI (apiyi.com) вы можете получить доступ ко всей линейке моделей Grok, Claude и GPT, гибко переключаясь между ними в зависимости от задач.
Практика вызова API
Пример базового вызова
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Единый интерфейс APIYI
)
# Универсальная задача → базовая версия
response = client.chat.completions.create(
model="grok-4.20-beta",
messages=[
{"role": "system", "content": "Вы — опытный Python-разработчик."},
{"role": "user", "content": "Реализуй очередь асинхронных задач"}
],
max_tokens=4096
)
print(response.choices[0].message.content)
Автоматический выбор модели в зависимости от задачи
def choose_grok_model(task_type):
"""Автоматический выбор оптимальной модели Grok по типу задачи"""
model_map = {
"quick": "grok-4.20-beta-0309-non-reasoning",
"general": "grok-4.20-beta",
"analysis": "grok-4.20-beta-0309-reasoning",
"research": "grok-4.20-multi-agent-beta-0309"
}
return model_map.get(task_type, "grok-4.20-beta")
# Пример использования
model = choose_grok_model("analysis")
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "Проанализируй узкие места производительности в этом коде..."}]
)
Посмотреть код для сравнительного тестирования моделей
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
models = [
"grok-4.20-beta",
"grok-4.20-beta-0309-non-reasoning",
"grok-4.20-beta-0309-reasoning",
"grok-4.20-multi-agent-beta-0309"
]
prompt = "Реализуй быструю сортировку на Python и проанализируй временную сложность"
for model in models:
try:
start = time.time()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=2048
)
elapsed = time.time() - start
tokens = response.usage.total_tokens
print(f"{model}")
print(f" Время: {elapsed:.1f}с | Токены: {tokens}")
print(f" Превью: {response.choices[0].message.content[:80]}...")
print()
except Exception as e:
print(f"{model} | Ошибка: {e}")
time.sleep(1)
🎯 Совет: Рекомендую сначала прогнать базовый тест на
grok-4.20-beta, а затем сравнить качество ответов на сложных задачах с версиейreasoning. Вызов всех 4 моделей через APIYI (apiyi.com) доступен по официальным ценам, а скидки предоставляются в рамках акций при пополнении баланса.
Часто задаваемые вопросы
Q1: Одинакова ли цена у всех 4 моделей?
Да, для всех 4 моделей установлена единая цена: $2 за входные и $6 за выходные токены на миллион. Однако фактические затраты различаются: модели с рассуждением (reasoning) генерируют больше токенов рассуждения (которые считаются как выходные), а мультиагентная версия может потреблять больше токенов из-за взаимодействия 4 агентов. Не-рассуждающая версия — самая экономная, так как пропускает цепочку рассуждений и выдает минимум токенов. При использовании APIYI apiyi.com цены соответствуют официальным ценам xAI, а скидки действуют через акции платформы.
Q2: В чем разница между мультиагентной и рассуждающей версиями?
Версия с рассуждением — это один агент, выполняющий глубокий анализ, что подходит для задач с четким ответом (математика, проверка кода). Мультиагентная версия — это коллаборация 4 агентов, что идеально для открытых вопросов, требующих анализа с разных сторон (исследование рынка, принятие решений). Главное преимущество мультиагентной версии — перекрестная проверка, снижающая вероятность галлюцинаций (с 12% до 4.2%).
Q3: Может ли Grok 4.20 заменить Claude при проверке кода?
В некоторых сценариях — да. Grok 4.20 с рассуждением достигает ~75% в бенчмарке SWE-bench, что чуть ниже 81.4% у Claude Opus 4.6, но цена при этом составляет лишь 8% от стоимости Claude. Для повседневной проверки кода, не требующей критической безопасности, Grok 4.20 — отличный выбор по соотношению цена-качество. Для аудита безопасности и анализа крупной архитектуры Claude Opus 4.6 остается более надежным. Через APIYI apiyi.com можно подключить обе модели и гибко переключаться между ними в зависимости от задачи.
Q4: В чем практическая польза контекстного окна в 2 млн токенов?
2 миллиона токенов — это примерно 1500 страниц технической литературы. Практическое применение: (1) загрузка целой кодовой базы среднего или крупного проекта для анализа за один раз; (2) обработка сверхдлинных документов (юридические контракты, сборники научных статей); (3) удержание контекста очень длинных диалогов. На текущий момент это одно из самых больших контекстных окон среди передовых западных моделей.
Q5: Как вызывать эти модели на платформе APIYI?
После регистрации на apiyi.com и получения ключа используйте стандартный формат OpenAI. Просто установите base_url на https://api.apiyi.com/v1, а model — на ID нужной модели (например, grok-4.20-beta). Примеры кода приведены выше. Цены на все 4 модели соответствуют официальным, а скидки предоставляются при пополнении баланса.
Итоги: оптимальные стратегии использования 4 моделей
Серия Grok 4.20 Beta предлагает точный выбор моделей для различных сценариев. Ключевая стратегия заключается в соответствии модели сложности задачи:
| Сложность | Рекомендуемая модель | Стоимость |
|---|---|---|
| 🟢 Простая/Частая | non-reasoning |
Минимальная |
| 🟡 Повседневная | grok-4.20-beta |
Средняя |
| 🟠 Глубокий анализ | reasoning |
Высокая |
| 🔴 Максимальная точность | multi-agent |
Максимальная |
Благодаря ценообразованию $2/$6, Grok 4.20 становится флагманской моделью с самой низкой стоимостью вывода на текущем рынке. В сочетании с контекстным окном в 2 миллиона токенов и мультиагентной системой, она крайне конкурентоспособна в задачах исследования, анализа и сценариях с высокой пропускной способностью.
Рекомендуем подключаться ко всей серии моделей Grok 4.20 Beta через сервис-прокси API APIYI (apiyi.com). Цены соответствуют официальным, а скидки доступны в рамках акций при пополнении баланса. Один API-ключ позволяет вызывать более 200 моделей, включая Grok, Claude, GPT и другие.
Справочные материалы
-
Официальная документация xAI: Описание моделей Grok и ценообразование
- Ссылка:
docs.x.ai/developers/models
- Ссылка:
-
Artificial Analysis: Бенчмарк-тестирование Grok 4.20 Beta
- Ссылка:
artificialanalysis.ai/models/grok-4-20
- Ссылка:
-
Документация xAI по мультиагентным системам: Подробный разбор возможностей Multi-Agent
- Ссылка:
docs.x.ai/developers/model-capabilities/text/multi-agent
- Ссылка:
-
OpenRouter: Страница модели Grok 4.20 Beta
- Ссылка:
openrouter.ai
- Ссылка:
Автор: Команда APIYI | Мы первыми добавляем новейшие ИИ-модели. Приглашаем вас посетить APIYI (apiyi.com), чтобы протестировать всю серию моделей Grok 4.20 Beta.