Die Grok 4.20 Beta-Serie von xAI ist jetzt offiziell auf der APIYI-Plattform verfügbar. Wir haben 4 neue Modelle hinzugefügt, die das gesamte Spektrum von schnellen Antworten bis hin zur tiefgehenden Forschung mit mehreren Agenten abdecken. Mit einer Preisgestaltung von 2 $ pro Million Tokens für die Eingabe und 6 $ für die Ausgabe ist dies eine der kosteneffizientesten Optionen unter den führenden Modellen auf dem Markt.
Bei diesen 4 Modellen handelt es sich nicht nur um einfache Versions-Upgrades, sondern um architektonische Unterschiede: Einige sind auf extrem schnelle Reaktionszeiten ausgelegt, andere auf tiefgreifendes Schlussfolgern, und ein spezielles Modell lässt 4 KI-Agenten gleichzeitig zusammenarbeiten – wodurch die Halluzinationsrate um 65 % gesenkt wird.
Kernnutzen: Nach dem Lesen dieses Artikels verstehen Sie die Positionierung und die besten Einsatzszenarien der 4 Grok 4.20 Beta-Modelle, beherrschen den API-Aufruf und können fundierte Entscheidungen bei der Modellauswahl treffen.
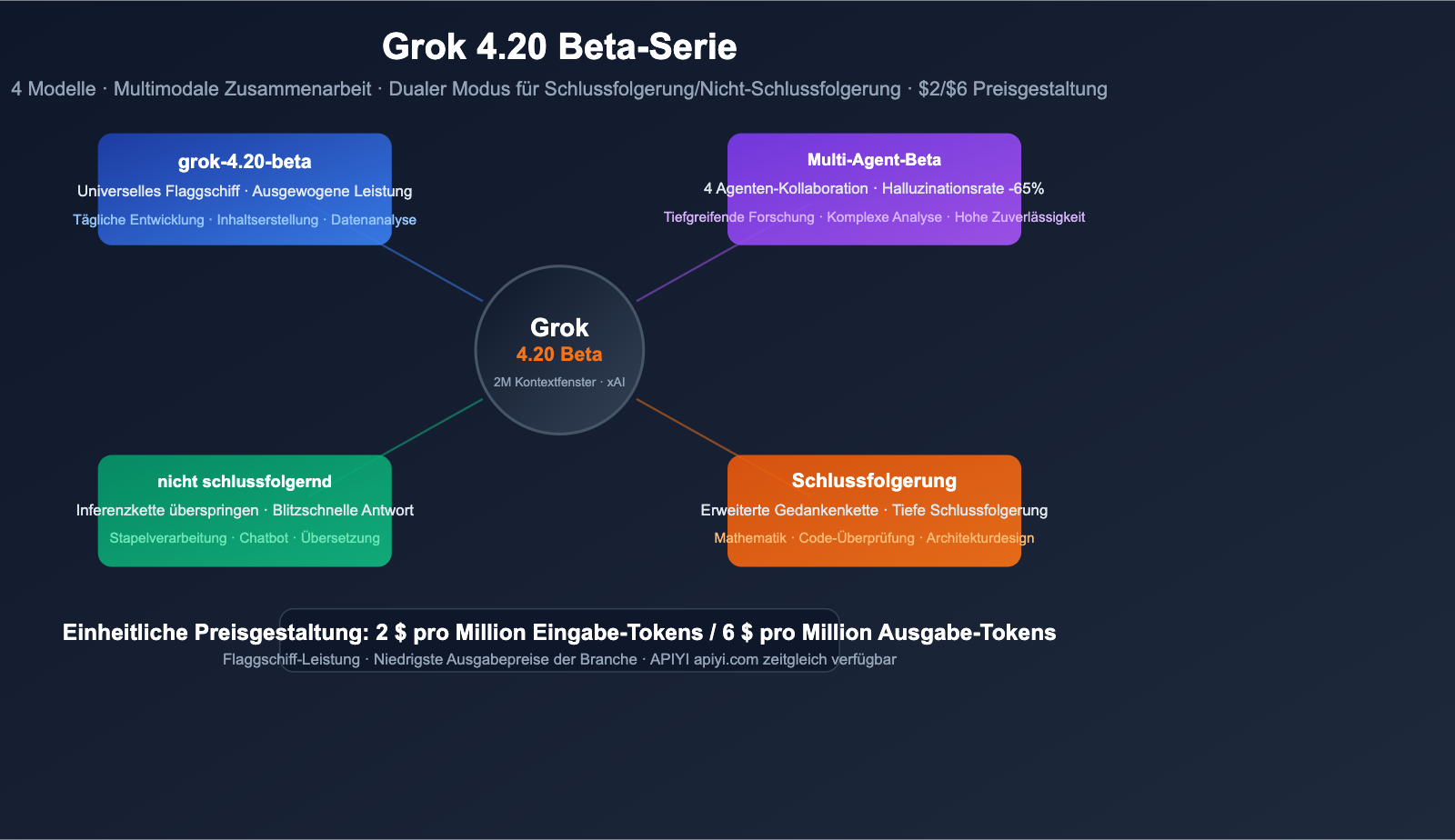
Die 4 Modelle im Überblick: Schneller Vergleich der Unterschiede
Modellmatrix
| Modell-ID | Positionierung | Kernmerkmale | Bestes Einsatzszenario |
|---|---|---|---|
grok-4.20-beta |
Universelles Flaggschiff | Ausgewogene Leistung und Geschwindigkeit | Tägliche Entwicklung, allgemeine Aufgaben |
grok-4.20-multi-agent-beta-0309 |
Multi-Agenten-Kollaboration | 4 Agenten arbeiten parallel zusammen | Tiefgehende Forschung, komplexe Analysen |
grok-4.20-beta-0309-non-reasoning |
Schnelle Reaktion | Überspringt die Schlussfolgerungskette, niedrige Latenz | Batch-Verarbeitung mit hohem Durchsatz, einfache Fragen |
grok-4.20-beta-0309-reasoning |
Tiefgehendes Schlussfolgern | Erweiterte Kette der Schlussfolgerung (CoT) | Mathematik, Code-Analyse, logische Argumentation |
Einheitliche Preisgestaltung
| Abrechnungsposten | Preis |
|---|---|
| Eingabe-Token | 2,00 $ / Million Tokens |
| Ausgabe-Token | 6,00 $ / Million Tokens |
| Kontextfenster | 2 Millionen Tokens (2M) |
| Batch-Rabatt | 50 % |
Preisvergleich mit Wettbewerbern:
| Modell | Eingabepreis | Ausgabepreis | Preis-Leistungs-Verhältnis |
|---|---|---|---|
| Grok 4.20 Beta | 2,00 $ | 6,00 $ | 🟢 Optimal |
| Gemini 3.1 Pro | 2,00 $ | 12,00 $ | Gut |
| GPT-5.4 | 2,50 $ | 15,00 $ | Durchschnittlich |
| Claude Sonnet 4.6 | 3,00 $ | 15,00 $ | Durchschnittlich |
| Claude Opus 4.6 | 15,00 $ | 75,00 $ | Eher hoch |
Der Ausgabepreis von Grok 4.20 beträgt nur 40 % des Preises von Claude Sonnet 4.6 und lediglich 8 % von Claude Opus 4.6. Bei ausgabeintensiven Aufgaben (Code-Generierung, lange Texte) ist der Kostenvorteil enorm.
🎯 Preishinweis: Die auf APIYI (apiyi.com) verfügbare Grok 4.20 Beta-Serie hat dieselbe Preisgestaltung wie die offizielle xAI-Website (2 $ Eingabe / 6 $ Ausgabe). Rabatte werden über Plattform-Aufladeaktionen gewährt. Mit einem einzigen API-Schlüssel können Sie über 200 Modelle wie Grok, Claude, GPT usw. aufrufen.
Tiefenanalyse von 4 Modellen
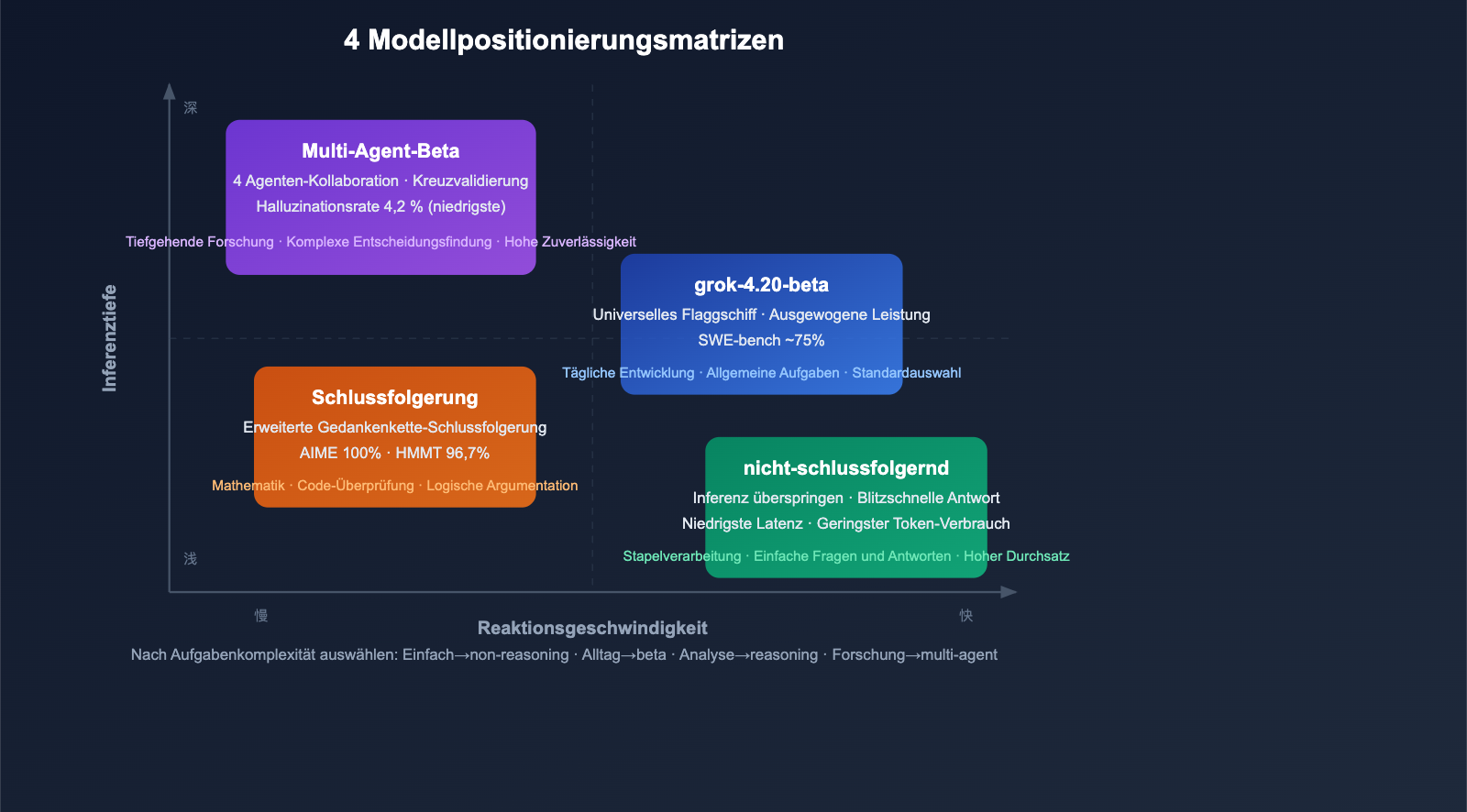
Modell 1: grok-4.20-beta (Flaggschiff für allgemeine Aufgaben)
Dies ist der Standard-Einstiegspunkt für die Grok 4.20-Serie, der Leistung, Geschwindigkeit und Kosten optimal ausbalanciert.
Hauptmerkmale:
- Erbt alle Fähigkeiten der Grok 4-Familie
- 2 Millionen Token Kontextfenster – das größte unter den westlichen Spitzenmodellen
- Unterstützt Bildeingaben (JPG/PNG)
- Kontinuierliche Verbesserung basierend auf realem Feedback
Benchmark-Leistung:
- SWE-bench: ~75 % (nahe an den 74,9 % von GPT-5)
- GPQA (Graduiertenniveau): 88,4 %
- Arena Elo: ~1.505–1.535
Anwendungsbereiche: Tägliche Programmierung, Inhaltserstellung, Datenanalyse, allgemeine Dialoge
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI einheitliche Schnittstelle
)
response = client.chat.completions.create(
model="grok-4.20-beta",
messages=[
{"role": "user", "content": "Implementiere einen LRU-Cache in Python"}
]
)
print(response.choices[0].message.content)
Modell 2: grok-4.20-multi-agent-beta-0309 (Multi-Agent)
Dies ist die innovativste Variante von Grok 4.20 – 4 KI-Agenten arbeiten gleichzeitig zusammen, um Ihre Anfrage zu bearbeiten.
Die 4 Agenten und ihre Aufgaben:
| Agent | Rolle | Spezialisierung |
|---|---|---|
| Grok (Teamleiter) | Koordinator | Aufgabenzerlegung, Prozessmanagement, Zusammenführung der Ergebnisse |
| Harper | Forscher | Echtzeit-Datenabruf, Faktenprüfung (Zugriff auf X/Twitter-Daten) |
| Benjamin | Analyst | Logisches Schlussfolgern, mathematische Berechnungen, Code-Analyse |
| Lucas | Herausforderer | Kreative Synthese, eingebaute Gegenposition – hinterfragt die Schlussfolgerungen der anderen Agenten |
Arbeitsablauf:
Benutzeranfrage
↓
Grok zerlegt die Aufgabe → verteilt sie an die 4 Agenten
↓
Harper recherchiert | Benjamin analysiert | Lucas hinterfragt
↓
Interne Debatte zwischen den Agenten + Kreuzvalidierung
↓
Grok aggregiert den Konsens → liefert das Endergebnis
Highlight – 65 % geringere Halluzinationsrate:
| Metrik | Basismodell | Multi-Agent-Modus | Verbesserung |
|---|---|---|---|
| Halluzinationsrate | ~12 % | ~4,2 % | 65 % Reduktion |
| "Ich weiß es nicht"-Rate | — | 78 % | Branchenspitze |
Die "eingebaute Gegenposition" von Lucas ist ein entscheidendes Designmerkmal: Seine Aufgabe ist es, Schwachstellen in den Schlussfolgerungen der anderen Agenten zu finden. Diese adversarielle Zusammenarbeit macht das Endergebnis deutlich zuverlässiger.
Anwendungsbereiche: Detaillierte Forschungsberichte, komplexe Entscheidungsanalysen, Aufgaben, die ein hohes Maß an Vertrauenswürdigkeit erfordern
response = client.chat.completions.create(
model="grok-4.20-multi-agent-beta-0309",
messages=[
{"role": "user", "content": "Analysiere die Wettbewerbslandschaft und Zukunftstrends des Marktes für KI-Programmiertools im Jahr 2026"}
]
)
Modell 3: grok-4.20-beta-0309-non-reasoning (Nicht-schlussfolgernd)
Dies ist eine auf Geschwindigkeit und Durchsatz optimierte Variante. Sie überspringt die interne Gedankenkette (Chain-of-Thought) und generiert die Antwort direkt.
Hauptmerkmale:
- Niedrige Latenz, hoher Durchsatz
- Erzeugt keine internen Schlussfolgerungs-Token, spart Ausgabekosten
- Ideal für einfache, klare Aufgaben
Anwendungsbereiche:
- Hochfrequente API-Aufrufe (Batch-Datenverarbeitung)
- Chatbots / Kundensysteme
- Inhaltsklassifizierung, Tag-Extraktion
- Einfache Code-Vervollständigung
- Übersetzung, Zusammenfassung
Nicht geeignet für: Komplexe mathematische Herleitungen, mehrstufige logische Analysen, Architekturdesign, das tiefes Nachdenken erfordert
response = client.chat.completions.create(
model="grok-4.20-beta-0309-non-reasoning",
messages=[
{"role": "user", "content": "Konvertiere das folgende JSON in das CSV-Format: ..."}
]
)
Modell 4: grok-4.20-beta-0309-reasoning (Schlussfolgernd)
Dies ist das Gegenstück zur Nicht-Schlussfolgerungs-Variante: eine Variante für tiefgreifendes Schlussfolgern. Sie aktiviert eine erweiterte Gedankenkette (Extended Chain-of-Thought) und führt vor der Antwort eine tiefgehende interne Analyse durch.
Hauptmerkmale:
- Erweiterte Schlussfolgerungs-Token für tiefgehende Problemanalyse
- Exzellente Leistung bei mathematischen und logischen Aufgaben (AIME 2025: 100 %, HMMT25: 96,7 %)
- Artificial Analysis Intelligenz-Index: 48
Anwendungsbereiche:
- Mathematische Beweise und Herleitungen
- Code-Reviews und Bug-Analyse
- Abwägung bei Architektur-Entscheidungen
- Komplexe logische Argumentationen
- Analyse wissenschaftlicher Arbeiten
response = client.chat.completions.create(
model="grok-4.20-beta-0309-reasoning",
messages=[
{"role": "user", "content": "Analysiere die potenziellen Race Conditions und Deadlock-Risiken in diesem nebenläufigen Code"}
]
)
💡 Empfehlung zur Modellauswahl: Für die meisten täglichen Aufgaben reicht
grok-4.20-betavöllig aus. Nutzen Sie die Multi-Agent-Version für hohe Zuverlässigkeit, die Nicht-Schlussfolgerungs-Version für Batch-Verarbeitung und die Schlussfolgerungs-Version für komplexe Analysen. Über APIYI (apiyi.com) können Sie mit einem einzigen API-Schlüssel auf alle 4 Modelle zugreifen und je nach Bedarf wechseln.
Entscheidungsbaum für die Modellauswahl
Auswahl nach Aufgabentyp
| Aufgabentyp | Empfohlenes Modell | Grund |
|---|---|---|
| Tägliche Programmierhilfe | grok-4.20-beta |
Ausgewogenes Verhältnis von Leistung und Kosten |
| Stapelverarbeitung von Daten | non-reasoning |
Höchste Geschwindigkeit, geringste Latenz |
| Code-Review/Bug-Analyse | reasoning |
Erfordert tiefgreifendes Schlussfolgern |
| Erstellung von Forschungsberichten | multi-agent |
Kreuzvalidierung durch 4 Agenten |
| Echtzeit-Datenanalyse | multi-agent |
Harper greift auf Echtzeit-X-Daten zu |
| Mathematik/Logische Herleitung | reasoning |
100 % volle Punktzahl bei AIME |
| Chatbot | non-reasoning |
Schnelle Reaktion mit niedriger Latenz |
| Inhaltsübersetzung/-zusammenfassung | non-reasoning |
Einfache Aufgaben benötigen kein Schlussfolgern |
| Architektur-Design-Entwürfe | reasoning oder multi-agent |
Erfordert Abwägungsanalysen |
Auswahl nach Kostensensitivität
Maximale Ersparnis → non-reasoning (keine Reasoning-Token, minimaler Output)
↓
Tägliches Preis-Leistungs-Verhältnis → grok-4.20-beta (universelles Gleichgewicht)
↓
Qualität zuerst → reasoning (tiefgreifendes Schlussfolgern, mehr Output-Token)
↓
Höchste Zuverlässigkeit → multi-agent (4 Agenten, detailliertester Output)
🚀 Schnellstart: Wir empfehlen den Einstieg mit
grok-4.20-beta. Registrieren Sie sich über APIYI (apiyi.com), um Ihren API-Schlüssel zu erhalten. Die Preisgestaltung entspricht der offiziellen xAI-Website (Input $2 / Output $6), Rabatte werden über Aufladeaktionen gewährt.
Grok 4.20 im Vergleich zu führenden Modellen
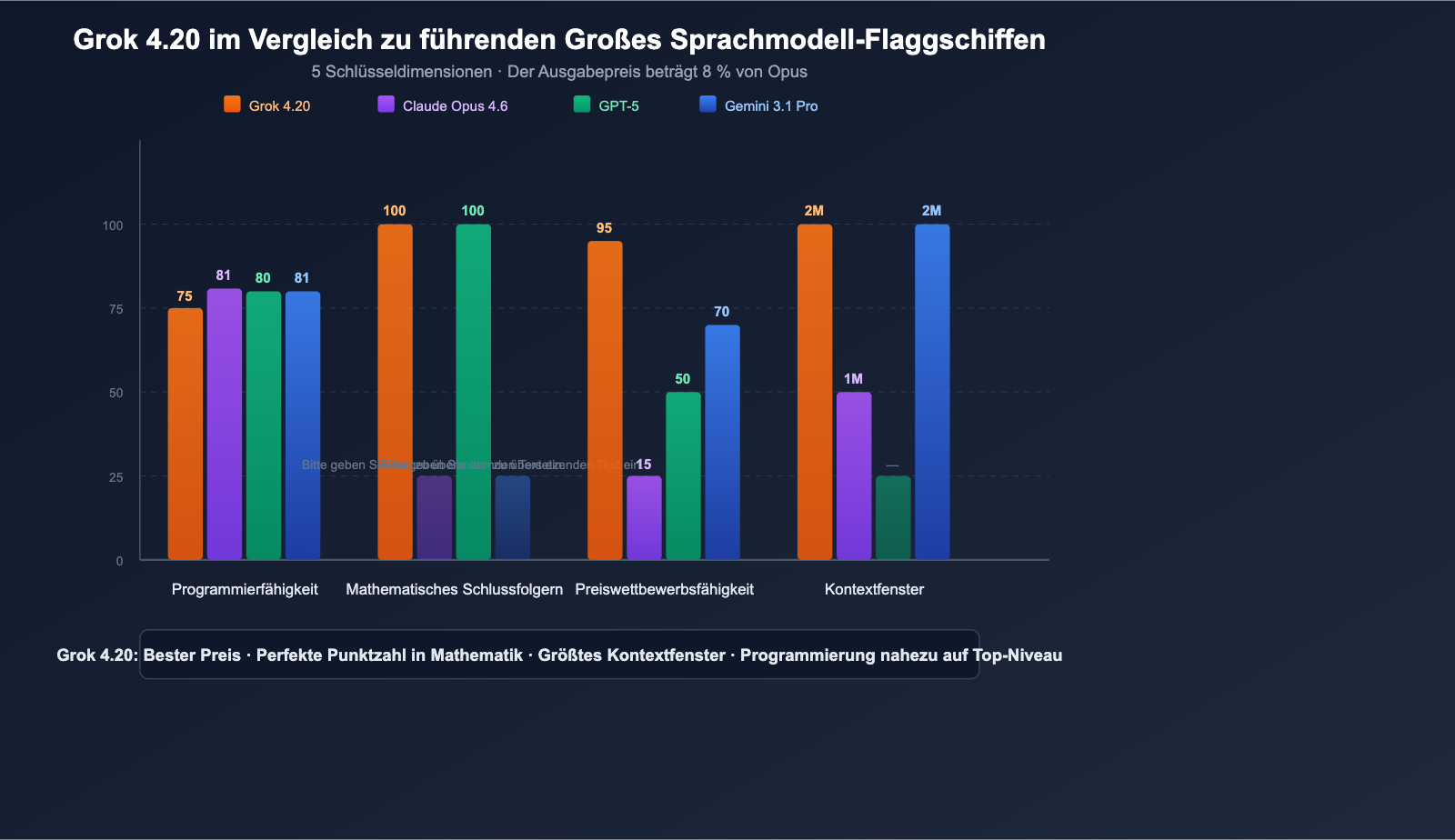
Vergleich über alle Dimensionen
| Dimension | Grok 4.20 Beta | Claude Opus 4.6 | GPT-5 Serie | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench | ~75% | 81,4% | ~80% | ~80,6% |
| Mathematik (AIME) | 100% | — | 100% | — |
| GPQA | 88,4% | — | — | — |
| Kontextfenster | 2 Mio. | 1 Mio. | modellabhängig | 2 Mio. |
| Input-Preis | $2 | $15 | $2,50 | $2 |
| Output-Preis | $6 | $75 | $15 | $12 |
| Multimodal | ✅ 4 Agenten | ❌ | ❌ | ❌ |
| Echtzeit-Daten | ✅ X/Twitter | ❌ | ✅ Suche | ✅ Suche |
| Halluzinationskontrolle | 4,2% (niedrigster) | gering | gering | mittel |
| Bildeingabe | ✅ JPG/PNG | ✅ viele Formate | ✅ viele Formate | ✅ viele Formate |
Beste Einsatzszenarien für jedes Modell
- Grok 4.20: Kosteneffiziente Allzwecklösung, tiefgreifende Forschung (Multi-Agent), Echtzeit-Datenanalyse
- Claude Opus 4.6: Software-Engineering (höchster SWE-bench), extrem lange Ausgaben (128K), Sicherheit auf Unternehmensebene
- GPT-5: Mathematische Höchstleistung, Desktop-Automatisierung, größtes Nutzer-Ökosystem
- Gemini 3.1 Pro: Integration in das Google-Ökosystem, 2 Mio. Kontextfenster, moderate Kosten
💰 Preis-Leistungs-Analyse: Der Output-Preis von Grok 4.20 ($6/MTok) beträgt nur 8 % des Preises von Claude Opus 4.6 ($75/MTok). Bei output-intensiven Aufgaben (lange Code-Generierung, Forschungsberichte) können die Kosten mit Grok 4.20 um über 90 % gesenkt werden. Über APIYI (apiyi.com) können Sie gleichzeitig auf die gesamte Modellreihe von Grok, Claude und GPT zugreifen und je nach Aufgabenanforderung flexibel wechseln.
API-Aufruf in der Praxis
Beispiel für einen Basis-Aufruf
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI einheitliche Schnittstelle
)
# Allgemeine Aufgabe → Basisversion
response = client.chat.completions.create(
model="grok-4.20-beta",
messages=[
{"role": "system", "content": "Du bist ein erfahrener Python-Entwickler."},
{"role": "user", "content": "Implementiere eine asynchrone Aufgabenwarteschlange"}
],
max_tokens=4096
)
print(response.choices[0].message.content)
Automatische Modellauswahl basierend auf der Aufgabe
def choose_grok_model(task_type):
"""Wählt automatisch das optimale Grok-Modell basierend auf dem Aufgabentyp"""
model_map = {
"quick": "grok-4.20-beta-0309-non-reasoning",
"general": "grok-4.20-beta",
"analysis": "grok-4.20-beta-0309-reasoning",
"research": "grok-4.20-multi-agent-beta-0309"
}
return model_map.get(task_type, "grok-4.20-beta")
# Anwendungsbeispiel
model = choose_grok_model("analysis")
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "Analysiere die Performance-Engpässe dieses Codes..."}]
)
Testcode für den Vergleich mehrerer Modelle anzeigen
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
models = [
"grok-4.20-beta",
"grok-4.20-beta-0309-non-reasoning",
"grok-4.20-beta-0309-reasoning",
"grok-4.20-multi-agent-beta-0309"
]
prompt = "Implementiere Quicksort in Python und analysiere die Zeitkomplexität"
for model in models:
try:
start = time.time()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=2048
)
elapsed = time.time() - start
tokens = response.usage.total_tokens
print(f"{model}")
print(f" Dauer: {elapsed:.1f}s | Tokens: {tokens}")
print(f" Vorschau: {response.choices[0].message.content[:80]}...")
print()
except Exception as e:
print(f"{model} | Fehler: {e}")
time.sleep(1)
🎯 Praxistipp: Wir empfehlen, zunächst einen Benchmark-Test mit
grok-4.20-betadurchzuführen und diesen dann mit derreasoning-Version hinsichtlich der Ausgabequalität bei komplexen Aufgaben zu vergleichen. Über APIYI (apiyi.com) können alle 4 Modelle aufgerufen werden; die Preisgestaltung entspricht der offiziellen Website, Rabatte werden über Auflade-Aktionen gewährt.
Häufig gestellte Fragen (FAQ)
Q1: Haben alle 4 Modelle die gleiche Preisgestaltung?
Ja, für alle 4 Modelle gilt ein einheitlicher Preis: $2 für Input / $6 für Output pro Million Tokens. Die tatsächlichen Kosten variieren jedoch je nach Modell – Reasoning-Modelle erzeugen mehr Reasoning-Tokens (die als Output gezählt werden), und die Multi-Agenten-Version verbraucht aufgrund der Zusammenarbeit von 4 Agenten möglicherweise mehr Tokens. Die Nicht-Reasoning-Version ist am kostengünstigsten, da sie die Reasoning-Kette überspringt und die wenigsten Output-Tokens generiert. Der Aufruf über APIYI (apiyi.com) erfolgt zu den offiziellen xAI-Preisen; Rabatte werden über Plattform-Aktionen gewährt.
Q2: Was ist der Unterschied zwischen der Multi-Agenten- und der Reasoning-Version?
Die Reasoning-Version ist ein einzelner Agent, der tiefgreifend nachdenkt – ideal für Analyseaufgaben mit eindeutigen Antworten (Mathematik, Code-Review). Die Multi-Agenten-Version besteht aus 4 Agenten, die zusammenarbeiten – ideal für offene Fragen, die eine Analyse aus verschiedenen Blickwinkeln erfordern (Marktforschung, Entscheidungsanalyse). Der Hauptvorteil der Multi-Agenten-Version ist die Kreuzvalidierung, die die Halluzinationsrate senkt (von 12 % auf 4,2 %).
Q3: Kann Grok 4.20 Claude bei Code-Reviews ersetzen?
In einigen Szenarien ja. Grok 4.20 Reasoning erreicht im SWE-bench ca. 75 %, was unter den 81,4 % von Claude Opus 4.6 liegt, aber nur 8 % des Preises kostet. Für alltägliche Code-Reviews, bei denen es nicht um sicherheitskritische Aspekte geht, ist Grok 4.20 Reasoning eine kosteneffiziente Wahl. Für Sicherheitsaudits und umfassende Architekturprüfungen bleibt Claude Opus 4.6 zuverlässiger. Über APIYI (apiyi.com) können Sie beide Modelle einbinden und je nach Aufgabe flexibel wechseln.
Q4: Welchen praktischen Nutzen hat ein Kontextfenster von 2 Millionen Tokens?
2 Millionen Tokens entsprechen etwa einem technischen Fachbuch mit 1500 Seiten. Praktische Anwendungen: (1) Einmaliges Laden ganzer mittelgroßer bis großer Codebasen zur Analyse; (2) Verarbeitung extrem langer Dokumente (Rechtsverträge, wissenschaftliche Papers); (3) Beibehaltung eines extrem langen Konversationsgedächtnisses. Dies ist derzeit eines der größten Kontextfenster unter den führenden westlichen Modellen.
Q5: Wie rufe ich diese Modelle auf der APIYI-Plattform auf?
Registrieren Sie sich bei APIYI (apiyi.com), erhalten Sie Ihren Schlüssel und nutzen Sie das OpenAI-kompatible Format für den Aufruf. Setzen Sie einfach die base_url auf https://api.apiyi.com/v1 und model auf die entsprechende Modell-ID (z. B. grok-4.20-beta). Codebeispiele finden Sie oben. Die Preisgestaltung für alle 4 Modelle entspricht der offiziellen Website; Rabatte werden über Auflade-Aktionen gewährt.
Zusammenfassung: Die optimale Strategie für die 4 Modelle
Die Grok 4.20 Beta-Serie bietet präzise Modellauswahlen für verschiedene Szenarien. Die Kernstrategie besteht darin, das Modell an die Komplexität der Aufgabe anzupassen:
| Komplexität | Empfohlenes Modell | Kosten |
|---|---|---|
| 🟢 Einfach/Häufig | non-reasoning |
Niedrigste |
| 🟡 Täglicher Gebrauch | grok-4.20-beta |
Moderat |
| 🟠 Tiefenanalyse | reasoning |
Höher |
| 🔴 Höchste Zuverlässigkeit | multi-agent |
Höchste |
Dank der Preisgestaltung von $2/$6 ist Grok 4.20 derzeit das Flaggschiff-Modell mit den niedrigsten Ausgabekosten auf dem Markt. In Kombination mit einem Kontextfenster von 2 Millionen Token und einem Multi-Agenten-System ist es äußerst wettbewerbsfähig bei Forschungsaufgaben, Analysen und Szenarien mit hohem Durchsatz.
Wir empfehlen den Zugriff auf die gesamte Grok 4.20 Beta-Modellreihe über APIYI (apiyi.com). Die Preisgestaltung entspricht der offiziellen Website, wobei Rabatte durch Aufladeaktionen gewährt werden. Mit einem einzigen API-Schlüssel können Sie über 200 Modelle wie Grok, Claude und GPT abrufen.
Referenzen
-
xAI Offizielle Dokumentation: Grok-Modelle und Preisübersicht
- Link:
docs.x.ai/developers/models
- Link:
-
Artificial Analysis: Grok 4.20 Beta Benchmark-Bewertung
- Link:
artificialanalysis.ai/models/grok-4-20
- Link:
-
xAI Multi-Agent Dokumentation: Detaillierte Erläuterung der Multi-Agent-Fähigkeiten
- Link:
docs.x.ai/developers/model-capabilities/text/multi-agent
- Link:
-
OpenRouter: Grok 4.20 Beta Modellseite
- Link:
openrouter.ai
- Link:
Autor: APIYI Team | Wir stellen die neuesten KI-Modelle zeitnah bereit. Besuchen Sie APIYI unter apiyi.com, um die gesamte Grok 4.20 Beta-Serie zu testen.