xAI 的 Grok 4.20 Beta 系列正式上線 API易平臺——一次性新增 4 款模型,覆蓋從快速問答到多智能體深度研究的全場景。定價輸入 $2 / 輸出 $6 每百萬 tokens,是當前主流旗艦模型中性價比最高的選擇之一。
這 4 款模型不是簡單的版本號遞增,而是架構層面的差異:有的追求極速響應,有的進行深度推理,還有一款讓 4 個 AI 智能體同時協作——幻覺率直降 65%。
核心價值: 讀完本文,你將理解 4 款 Grok 4.20 Beta 模型各自的定位和最佳使用場景,掌握 API 調用方法,做出最優的模型選型決策。

4 款模型一覽:核心差異速查
模型矩陣
| 模型 ID | 定位 | 核心特徵 | 最佳場景 |
|---|---|---|---|
grok-4.20-beta |
通用旗艦 | 平衡性能和速度 | 日常開發、通用任務 |
grok-4.20-multi-agent-beta-0309 |
多智能體協作 | 4 個 Agent 並行協作 | 深度研究、複雜分析 |
grok-4.20-beta-0309-non-reasoning |
快速響應 | 跳過推理鏈,低延遲 | 高吞吐批處理、簡單問答 |
grok-4.20-beta-0309-reasoning |
深度推理 | 擴展思維鏈推理 | 數學、代碼分析、邏輯論證 |
統一定價
| 計費項 | 價格 |
|---|---|
| 輸入 token | $2.00 / 百萬 tokens |
| 輸出 token | $6.00 / 百萬 tokens |
| 上下文窗口 | 200 萬 tokens (2M) |
| 批處理折扣 | 50% |
與競品價格對比:
| 模型 | 輸入價格 | 輸出價格 | 性價比 |
|---|---|---|---|
| Grok 4.20 Beta | $2.00 | $6.00 | 🟢 最優 |
| Gemini 3.1 Pro | $2.00 | $12.00 | 良好 |
| GPT-5.4 | $2.50 | $15.00 | 一般 |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 一般 |
| Claude Opus 4.6 | $15.00 | $75.00 | 較高 |
Grok 4.20 的輸出價格僅爲 Claude Sonnet 4.6 的 40%,是 Claude Opus 4.6 的 8%。對於輸出密集型任務 (代碼生成、長文本),成本優勢極其顯著。
🎯 定價說明: API易 apiyi.com 上線的 Grok 4.20 Beta 系列定價與 xAI 官網一致(輸入 $2 / 輸出 $6),折扣體現在平臺充值活動中。一個 Key 即可同時調用 Grok、Claude、GPT 等 200+ 模型。
4 款模型深度解析

模型一:grok-4.20-beta (通用旗艦)
這是 Grok 4.20 系列的默認入口,平衡了性能、速度和成本。
核心特性:
- 繼承 Grok 4 家族的全部能力
- 200 萬 token 上下文窗口——西方前沿模型中最大
- 支持圖片輸入 (JPG/PNG)
- 每週根據真實世界反饋持續改進
基準表現:
- SWE-bench: ~75% (接近 GPT-5 的 74.9%)
- GPQA (研究生級別): 88.4%
- Arena Elo: ~1,505-1,535
適用場景: 日常編程輔助、內容創作、數據分析、通用對話
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # API易統一接口
)
response = client.chat.completions.create(
model="grok-4.20-beta",
messages=[
{"role": "user", "content": "用 Python 實現一個 LRU 緩存"}
]
)
print(response.choices[0].message.content)
模型二:grok-4.20-multi-agent-beta-0309 (多智能體)
這是 Grok 4.20 最具創新性的變體——4 個 AI 智能體同時協作處理你的請求。
4 個智能體各司其職:
| 智能體 | 角色 | 專長 |
|---|---|---|
| Grok (隊長) | 協調員 | 任務分解、流程管理、聚合輸出 |
| Harper | 研究員 | 實時數據檢索、事實覈查 (接入 X/Twitter 數據) |
| Benjamin | 分析師 | 邏輯推理、數學計算、代碼分析 |
| Lucas | 挑戰者 | 創意綜合、內建反對立場——質疑其他智能體的結論 |
工作流程:
用戶提問
↓
Grok 分解任務 → 分配給 4 個智能體
↓
Harper 蒐集數據 | Benjamin 邏輯分析 | Lucas 質疑挑戰
↓
智能體間內部辯論 + 交叉驗證
↓
Grok 聚合共識 → 返回最終答案
最大亮點——幻覺率降低 65%:
| 指標 | 單模型基線 | 多智能體模式 | 改善 |
|---|---|---|---|
| 幻覺率 | ~12% | ~4.2% | 降低 65% |
| "不確定時說不知道"比率 | — | 78% | 行業最高 |
Lucas 的"內建反對立場"是關鍵設計:它的工作就是找其他智能體結論中的漏洞。這種對抗式協作讓最終輸出更加可靠。
適用場景: 深度研究報告、複雜決策分析、需要高可信度的輸出
response = client.chat.completions.create(
model="grok-4.20-multi-agent-beta-0309",
messages=[
{"role": "user", "content": "分析 2026 年 AI 編程工具市場的競爭格局和趨勢預測"}
]
)
模型三:grok-4.20-beta-0309-non-reasoning (非推理)
這是爲速度和吞吐量優化的變體。它跳過內部推理鏈 (Chain-of-Thought),直接生成答案。
核心特性:
- 低延遲、高吞吐
- 不產生內部推理 token,節省輸出成本
- 適合簡單明確的任務
適用場景:
- 高頻 API 調用 (批量數據處理)
- 聊天機器人 / 客服系統
- 內容分類、標籤提取
- 簡單代碼補全
- 翻譯、摘要
不適合: 複雜數學推導、多步邏輯分析、需要深度思考的架構設計
response = client.chat.completions.create(
model="grok-4.20-beta-0309-non-reasoning",
messages=[
{"role": "user", "content": "將以下 JSON 轉換爲 CSV 格式: ..."}
]
)
模型四:grok-4.20-beta-0309-reasoning (推理)
這是與非推理版相對的深度推理變體。它啓用擴展思維鏈 (Extended Chain-of-Thought),在回答前進行深入的內部推理。
核心特性:
- 擴展推理 token,深度分析問題
- 數學和邏輯任務表現卓越 (AIME 2025: 100%, HMMT25: 96.7%)
- Artificial Analysis 智力指數: 48
適用場景:
- 數學證明和推導
- 代碼審查和 Bug 分析
- 架構設計權衡
- 複雜邏輯論證
- 學術論文分析
response = client.chat.completions.create(
model="grok-4.20-beta-0309-reasoning",
messages=[
{"role": "user", "content": "分析這段併發代碼中可能存在的競態條件和死鎖風險"}
]
)
💡 選型建議: 大多數日常任務用
grok-4.20-beta即可。需要高可信度輸出用多智能體版,批量處理用非推理版,複雜分析用推理版。通過 API易 apiyi.com 一個 Key 即可調用全部 4 款模型,按需切換。
模型選型決策樹
按任務類型選擇
| 任務類型 | 推薦模型 | 理由 |
|---|---|---|
| 日常編程輔助 | grok-4.20-beta |
平衡性能和成本 |
| 批量數據處理 | non-reasoning |
最快速度,最低延遲 |
| 代碼審查/Bug 分析 | reasoning |
需要深度推理 |
| 研究報告撰寫 | multi-agent |
4 智能體交叉驗證 |
| 實時數據分析 | multi-agent |
Harper 接入實時 X 數據 |
| 數學/邏輯推導 | reasoning |
AIME 100% 滿分 |
| 聊天機器人 | non-reasoning |
低延遲快速響應 |
| 內容翻譯/摘要 | non-reasoning |
簡單任務無需推理 |
| 架構設計方案 | reasoning 或 multi-agent |
需要權衡分析 |
按成本敏感度選擇
極致省錢 → non-reasoning (無推理 token,輸出最少)
↓
日常性價比 → grok-4.20-beta (通用平衡)
↓
質量優先 → reasoning (深度推理,輸出token更多)
↓
最高可信度 → multi-agent (4 智能體,輸出最詳盡)
🚀 快速開始: 推薦從
grok-4.20-beta入手體驗。通過 API易 apiyi.com 註冊即可獲取 API Key,定價與 xAI 官網一致(輸入 $2 / 輸出 $6),折扣體現在充值活動中。
Grok 4.20 vs 主流模型橫向對比
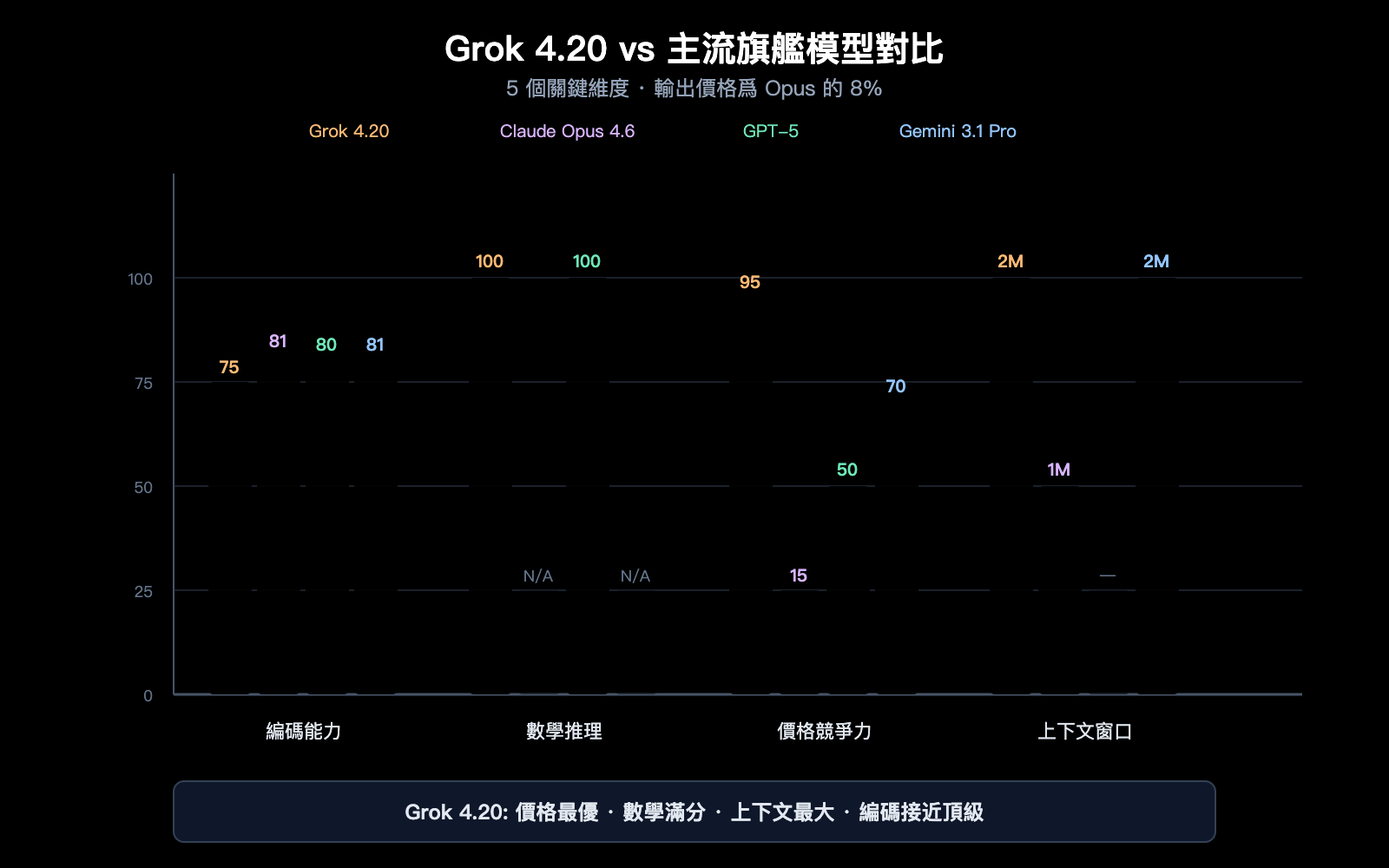
全維度對比
| 維度 | Grok 4.20 Beta | Claude Opus 4.6 | GPT-5 系列 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench | ~75% | 81.4% | ~80% | ~80.6% |
| 數學 (AIME) | 100% | — | 100% | — |
| GPQA | 88.4% | — | — | — |
| 上下文 | 200 萬 | 100 萬 | 因模型而異 | 200 萬 |
| 輸入價格 | $2 | $15 | $2.50 | $2 |
| 輸出價格 | $6 | $75 | $15 | $12 |
| 多智能體 | ✅ 4 Agent | ❌ | ❌ | ❌ |
| 實時數據 | ✅ X/Twitter | ❌ | ✅ 搜索 | ✅ 搜索 |
| 幻覺控制 | 4.2% (最低) | 較低 | 較低 | 中等 |
| 圖片輸入 | ✅ JPG/PNG | ✅ 多格式 | ✅ 多格式 | ✅ 多格式 |
各模型最佳場景
- Grok 4.20: 高性價比通用、深度研究 (多智能體)、實時數據分析
- Claude Opus 4.6: 軟件工程 (SWE-bench 最高)、超長輸出 (128K)、企業級安全
- GPT-5: 數學滿分、桌面自動化、最大用戶生態
- Gemini 3.1 Pro: Google 生態整合、200 萬上下文、成本適中
💰 性價比分析: Grok 4.20 的輸出價格 ($6/MTok) 僅爲 Claude Opus 4.6 ($75/MTok) 的 8%。對於輸出密集型任務(長代碼生成、研究報告),使用 Grok 4.20 可以將成本降低 90% 以上。通過 API易 apiyi.com 可以同時接入 Grok、Claude、GPT 全系列模型,根據任務特點靈活切換。
API 調用實戰
基礎調用示例
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # API易統一接口
)
# 通用任務 → 基礎版
response = client.chat.completions.create(
model="grok-4.20-beta",
messages=[
{"role": "system", "content": "你是一位資深 Python 開發者。"},
{"role": "user", "content": "實現一個異步任務隊列"}
],
max_tokens=4096
)
print(response.choices[0].message.content)
根據任務自動選型
def choose_grok_model(task_type):
"""根據任務類型自動選擇最優 Grok 模型"""
model_map = {
"quick": "grok-4.20-beta-0309-non-reasoning",
"general": "grok-4.20-beta",
"analysis": "grok-4.20-beta-0309-reasoning",
"research": "grok-4.20-multi-agent-beta-0309"
}
return model_map.get(task_type, "grok-4.20-beta")
# 使用示例
model = choose_grok_model("analysis")
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "分析這段代碼的性能瓶頸..."}]
)
查看多模型對比測試代碼
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
models = [
"grok-4.20-beta",
"grok-4.20-beta-0309-non-reasoning",
"grok-4.20-beta-0309-reasoning",
"grok-4.20-multi-agent-beta-0309"
]
prompt = "用 Python 實現快速排序並分析時間複雜度"
for model in models:
try:
start = time.time()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=2048
)
elapsed = time.time() - start
tokens = response.usage.total_tokens
print(f"{model}")
print(f" 耗時: {elapsed:.1f}s | Tokens: {tokens}")
print(f" 預覽: {response.choices[0].message.content[:80]}...")
print()
except Exception as e:
print(f"{model} | 錯誤: {e}")
time.sleep(1)
🎯 實戰建議: 建議先用
grok-4.20-beta跑一遍基準測試,再和reasoning版對比複雜任務的輸出質量差異。通過 API易 apiyi.com 調用全部 4 款模型,定價與官網一致,折扣體現在充值活動中。
常見問題
Q1: 4 款模型的定價一樣嗎?
是的,4 款模型統一定價:輸入 $2 / 輸出 $6 每百萬 tokens。但實際成本因模型而異——推理模型會產生更多推理 token (計爲輸出),多智能體版因 4 個 Agent 協作可能消耗更多 token。非推理版最省錢,因爲它跳過推理鏈,輸出 token 最少。通過 API易 apiyi.com 調用定價與 xAI 官網一致,折扣體現在平臺充值活動中。
Q2: 多智能體版和推理版有什麼區別?
推理版是單個 Agent 進行深度思考——適合有明確答案的分析任務 (數學、代碼審查)。多智能體版是4 個 Agent 協作討論——適合需要多角度分析的開放性問題 (市場研究、決策分析)。多智能體版的核心優勢是交叉驗證降低幻覺率 (從 12% 降到 4.2%)。
Q3: Grok 4.20 能替代 Claude 做代碼審查嗎?
部分場景可以。Grok 4.20 推理版在 SWE-bench 上達到 ~75%,低於 Claude Opus 4.6 的 81.4%,但價格僅爲其 8%。對於非安全關鍵的日常代碼審查,Grok 4.20 推理版是高性價比選擇。對於安全審計和大型架構審查,Claude Opus 4.6 仍然更可靠。通過 API易 apiyi.com 可以同時接入兩家模型,按任務靈活切換。
Q4: 200 萬 token 上下文有什麼實際用處?
200 萬 token 約等於一本 1500 頁的技術書籍。實際應用:(1) 一次性加載整個中大型代碼庫進行分析;(2) 處理超長文檔 (法律合同、學術論文集);(3) 保持超長對話記憶。這是目前西方前沿模型中最大的上下文窗口。
Q5: 如何在 API易平臺調用這些模型?
註冊 API易 apiyi.com 獲取 Key 後,使用 OpenAI 兼容格式調用即可。只需將 base_url 設爲 https://api.apiyi.com/v1,model 設爲對應的模型 ID (如 grok-4.20-beta)。代碼示例見上文。4 款模型定價與官網一致,折扣通過充值活動發放。
總結:4 款模型的最優使用策略
Grok 4.20 Beta 系列爲不同場景提供了精準的模型選擇。核心策略是按任務複雜度匹配模型:
| 複雜度 | 推薦模型 | 成本 |
|---|---|---|
| 🟢 簡單/高頻 | non-reasoning |
最低 |
| 🟡 日常通用 | grok-4.20-beta |
適中 |
| 🟠 深度分析 | reasoning |
較高 |
| 🔴 最高可信度 | multi-agent |
最高 |
$2/$6 的定價讓 Grok 4.20 成爲當前市場上輸出成本最低的旗艦模型。配合 200 萬 token 上下文和多智能體系統,它在研究、分析和高吞吐場景下極具競爭力。
推薦通過 API易 apiyi.com 一站式接入 Grok 4.20 Beta 全系列模型,定價與官網一致,折扣體現在充值活動中。一個 Key 同時調用 Grok、Claude、GPT 等 200+ 模型。
參考資料
-
xAI 官方文檔: Grok 模型和定價說明
- 鏈接:
docs.x.ai/developers/models
- 鏈接:
-
Artificial Analysis: Grok 4.20 Beta 基準評測
- 鏈接:
artificialanalysis.ai/models/grok-4-20
- 鏈接:
-
xAI 多智能體文檔: Multi-Agent 能力詳解
- 鏈接:
docs.x.ai/developers/model-capabilities/text/multi-agent
- 鏈接:
-
OpenRouter: Grok 4.20 Beta 模型頁面
- 鏈接:
openrouter.ai
- 鏈接:
作者: APIYI Team | 第一時間上線最新 AI 模型,歡迎訪問 API易 apiyi.com 體驗 Grok 4.20 Beta 全系列模型。