Author's Note: OpenAI's latest mini series model, gpt-5.4-mini, is now available via API. It achieves 54.4% on SWE-Bench Pro, outperforming the GPT-5 mini's 45.7%. This article provides a comprehensive breakdown of its performance leap, the 90% discount on cached inputs, and how to choose between 4o-mini, 5-mini, and this new upgrade.
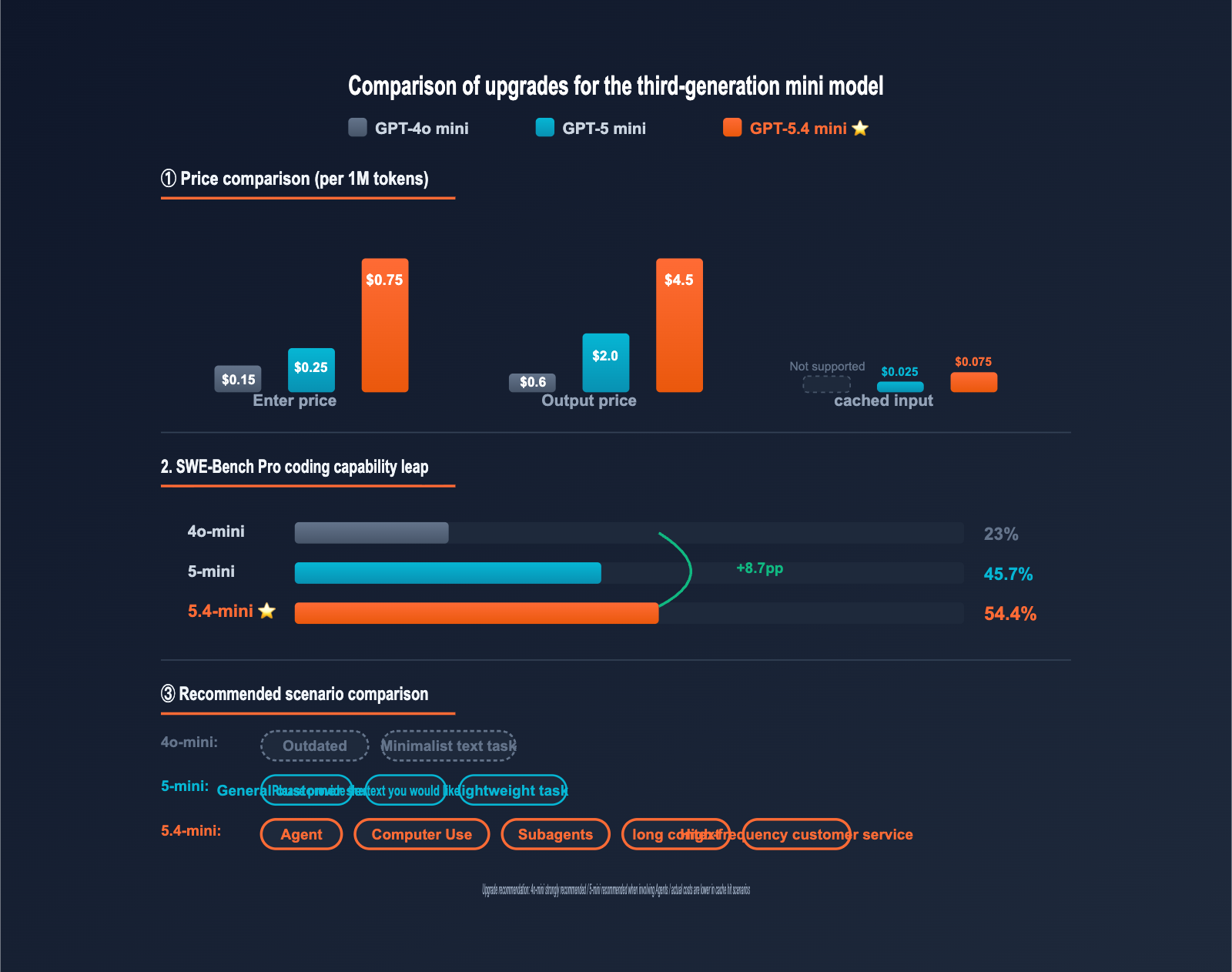
If you're still using gpt-4o-mini or gpt-5-mini, you might have noticed that on 2026-03-17, OpenAI released "our most capable mini model yet" — gpt-5.4-mini. It scored 54.4% on SWE-Bench Pro (compared to 45.7% for GPT-5 mini), 60.0% on Terminal-Bench 2.0, and 72.1% on the OSWorld-Verified benchmark for Computer Use tasks, all while being twice as fast as the previous generation.
This looks like a minor version update, but its design intent goes much deeper. OpenAI has explicitly positioned gpt-5.4-mini as a model "optimized for coding, Computer Use, and Subagents" — marking the first time the mini series has brought agentic capabilities down to an entry-level price point. In this article, we'll break down exactly what GPT-5.4 mini is, how it improves upon 4o-mini and 5-mini, and what it means for your daily workflow.
Core Value: We'll decode the integration plan for GPT-5.4 mini from four angles: performance leaps, pricing structure, cache optimization, and the trade-offs with older mini models, providing you with clear criteria for when to upgrade.
{Launched on 2026-03-17}
{Official pricing (per 1M)}
{$0.75 / $4.50}
{Cache input -90%}
{GPT-5.4 mini}
{Strongest Mini for Coding · Computer Use · Subagents}
{SWE-BENCH PRO}
{54.4%}
{+8.7pp}
{vs GPT-5 mini}
{OSWORLD COMPUTER USE}
{72.1%}
{⭐ First release}
{mini series}
{SPEED vs GPT-5 MINI}
{2x}
{High speed}
{Response speed doubled}
{APIYI.COM · Default fully open · Cache discount synchronization · 10% bonus on top-ups}
GPT-5.4 mini API Core Highlights
| Feature | Description | Value |
|---|---|---|
| Performance Leap | SWE-Bench Pro 54.4% vs GPT-5 mini 45.7% | 19% improvement in coding task accuracy |
| 400K Context Window | 400,000 input tokens + 128,000 output | Process entire codebases/long docs at once |
| 90% Cache Discount | Cached input only $0.075/1M | Drastic cost reduction for high-frequency context |
| Computer Use | OSWorld-Verified 72.1% | First mini series with full desktop automation support |
| Default Access | Available directly on APIYI | Ready to use for new users, no application needed |
Core Differences: GPT-5.4 mini vs. Previous Generations
GPT-5.4 mini isn't just a "price-cut version." OpenAI has delivered substantial capability upgrades across three dimensions:
First, Subagent orchestration arrives in the mini price tier. In the past, it was nearly impossible for mini models to reliably coordinate multiple subtasks or manage complex tool-calling chains — they would typically lose context or ignore instructions after 3-4 steps. Through an enhanced Reasoning Token mechanism and instruction-following training, GPT-5.4 mini achieves about 90% of the reliability of the standard GPT-5.4 model in multi-agent collaboration scenarios, at just 1/6th the cost.
Second, full Computer Use support. GPT-5.4 mini is the first model in the OpenAI mini series to push OSWorld-Verified scores above 70%. This means you can deploy full desktop automation agents at a mini price point to handle clicks, form filling, file operations, and more.
Third, 2x faster response speeds. While boosting performance, GPT-5.4 mini is twice as fast as GPT-5 mini. For high-throughput scenarios (customer service, batch processing), this translates into direct cost savings.
{GPT-5.4 mini capability matrix}
{gpt-5.4-mini}
{High-Volume Reasoning}
{Core capabilities}
{Reasoning Token}
{Computer Use ⭐ NEW}
{Subagents ⭐ NEW}
{Function Calling}
{400K Long context window}
{key parameters}
{CONTEXT}
{400K}
{tokens input}
{MAX OUTPUT}
{128K}
{tokens output}
{KNOWLEDGE}
{Aug 2025}
{Benchmark leap comparison (3rd generation mini)}
{SWE-BENCH PRO}
{4o-mini}
{23%}
{5-mini}
{45.7%}
{5.4-mini ⭐}
{54.4%}
{Terminal-Bench 2.0}
{60.0%}
{OSWorld-Verified}
{72.1%}
{Data source: OpenAI official + DataCamp evaluation (2026-03)}
Quick Start with GPT-5.4 mini API
Minimal Python Example (Replacing the Older Mini Models)
If you've been using gpt-4o-mini or gpt-5-mini, you can switch to gpt-5.4-mini simply by updating the model parameter. No other code changes are required:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-5.4-mini", # Only this line changes
messages=[
{"role": "user", "content": "Implement a concurrent cache with LRU eviction in Python"}
]
)
print(response.choices[0].message.content)
Minimal cURL Example
curl https://vip.apiyi.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY" \
-d '{
"model": "gpt-5.4-mini",
"messages": [
{"role": "user", "content": "Summarize the core points of this long document"}
]
}'
Computer Use Invocation Pattern (First Time Supported in the Mini Series)
# Enable Computer Use tools
response = client.chat.completions.create(
model="gpt-5.4-mini",
messages=[{
"role": "user",
"content": "Open the browser, search for 'OpenAI API documentation', and click on the first result"
}],
tools=[{
"type": "computer_use",
"config": {
"screen_width": 1920,
"screen_height": 1080
}
}]
)
# The model returns structured action instructions (click/type/scroll, etc.)
for action in response.choices[0].message.tool_calls:
print(f"Action: {action.function.name}, Arguments: {action.function.arguments}")
View full production-ready code (includes cache hit tracking and cost statistics)
import openai
from typing import List, Dict
# GPT-5.4 mini pricing (per 1M tokens)
PRICE_INPUT = 0.75
PRICE_INPUT_CACHED = 0.075 # Cached hit price (90% discount)
PRICE_OUTPUT = 4.50
def call_gpt54_mini(
messages: List[Dict],
api_key: str,
max_tokens: int = 4096
) -> Dict:
"""
Production-grade GPT-5.4 mini call with cache hit tracking
"""
client = openai.OpenAI(
api_key=api_key,
base_url="https://vip.apiyi.com/v1"
)
try:
response = client.chat.completions.create(
model="gpt-5.4-mini",
messages=messages,
max_tokens=max_tokens
)
usage = response.usage
input_tokens = usage.prompt_tokens
output_tokens = usage.completion_tokens
# Cached tokens (depends on SDK version)
cached_tokens = getattr(usage, 'prompt_tokens_details', {}).get('cached_tokens', 0)
regular_input = input_tokens - cached_tokens
# Tiered billing
input_cost = (
regular_input / 1_000_000 * PRICE_INPUT +
cached_tokens / 1_000_000 * PRICE_INPUT_CACHED
)
output_cost = output_tokens / 1_000_000 * PRICE_OUTPUT
total_cost = input_cost + output_cost
cache_rate = cached_tokens / max(input_tokens, 1) * 100
print(f"📊 Input: {input_tokens:,} | Cache Hit: {cached_tokens:,} ({cache_rate:.1f}%)")
print(f"📊 Output: {output_tokens:,} tokens")
print(f"💰 Total Cost: ${total_cost:.4f}")
print(f"💰 Cache Savings: ${(cached_tokens / 1_000_000 * (PRICE_INPUT - PRICE_INPUT_CACHED)):.4f}")
return {
"content": response.choices[0].message.content,
"tokens": {
"input": input_tokens,
"cached": cached_tokens,
"output": output_tokens
},
"cost_usd": total_cost,
"cache_hit_rate": cache_rate
}
except openai.RateLimitError:
return {"error": "Rate limit exceeded, please try again later"}
except openai.APIError as e:
return {"error": f"API Error: {str(e)}"}
# Usage example
result = call_gpt54_mini(
messages=[
{"role": "system", "content": "You are a senior Python engineer"},
{"role": "user", "content": "Help me review this code for concurrency safety issues..."}
],
api_key="YOUR_API_KEY"
)
print(result["content"])
🎯 Quick Start Tip: GPT-5.4 mini is now fully available in the default group on APIYI. New users can call it immediately without needing an application. We recommend accessing it via the APIYI (apiyi.com) platform—get a 10% bonus on $100 deposits, which is roughly equivalent to a 15% discount off the official price. It provides direct domestic access (no VPN required) and is fully compatible with the OpenAI SDK.
GPT-5.4 mini API Pricing Breakdown
Official Pricing Structure
While the pricing for GPT-5.4 mini is higher than the older mini series, the caching mechanism can significantly reduce actual costs:
| Billing Type | Price (per 1M tokens) | Notes |
|---|---|---|
| Input | $0.75 | Standard pricing |
| Cached Input | $0.075 | 90% discount, major cost reduction |
| Output | $4.50 | Includes reasoning tokens |
| Batch API Input | $0.75 | Same as standard price |
| Regional Data Residency | +10% | For data compliance scenarios |
Three-Generation Mini Series Price Comparison
| Model | Input Price | Cached Input | Output Price | Context Window | Max Output |
|---|---|---|---|---|---|
| GPT-4o mini | $0.15 | N/A | $0.60 | 128K | 16K |
| GPT-5 mini | $0.25 | $0.025 | $2.00 | 400K | 128K |
| GPT-5.4 mini | $0.75 | $0.075 | $4.50 | 400K | 128K |
⚠️ Important Observation: The standard price for GPT-5.4 mini is 5x that of GPT-4o mini and 3x that of GPT-5 mini. However, keep two key facts in mind: 1) With caching enabled, the cost per task can drop to $0.0075/1M in high-frequency scenarios, and 2) The leap in capability often means you don't need as many rounds of debugging, reducing the total number of calls required.
Cost Estimation for Cache Hit Scenarios
The 90% cache discount for GPT-5.4 mini is the most underrated feature of this upgrade:
| Scenario | Input Tokens | Cache Hit Rate | Actual Cost per Call |
|---|---|---|---|
| High-frequency Customer Service (reusing system prompt) | 5K | 80% | $0.0046 |
| Code Assistant (reusing context) | 50K | 70% | $0.034 |
| Long Document Q&A (reusing document) | 200K | 90% | $0.030 |
| Subagent Orchestration (shared instructions) | 30K | 85% | $0.0162 |
💰 Caching Optimization Tip: The GPT-5.4 mini caching mechanism works best for scenarios involving long system prompts + repetitive context. For high-frequency use cases like customer service, coding assistants, and long document Q&A, your actual costs might end up even lower than with GPT-5 mini. You can further reduce your bill by taking advantage of the 10% bonus on deposits at APIYI (apiyi.com).
GPT-5.4 mini API Capability Leap
Benchmark Performance Comparison
| Evaluation Metric | GPT-4o mini | GPT-5 mini | GPT-5.4 mini | Improvement |
|---|---|---|---|---|
| SWE-Bench Pro (Coding) | ~23% | 45.7% | 54.4% | +8.7pp |
| Terminal-Bench 2.0 | ~30% | ~50% | 60.0% | +10pp |
| OSWorld-Verified (Computer Use) | N/A | ~58% | 72.1% | +14pp |
| Response Speed | Baseline | Baseline | 2x Faster | Doubled |
Capability Upgrade Breakdown
SWE-Bench Pro 54.4%: This is the most notable metric for the GPT-5.4 mini. Reaching 54.4% brings it very close to the 57.7% score of the standard GPT-5.4 model, yet it costs only 1/6th of the price. For tasks like resolving actual GitHub issues or refactoring codebases, the mini model is now a highly reliable choice.
Terminal-Bench 60.0%: This indicates that the mini model can reliably complete over 60% of tasks involving terminal command execution, debugging, and automated workflows. When combined with subagent orchestration, you can build robust CI/CD automation, code review bots, and other similar applications.
OSWorld 72.1%: This marks a historic breakthrough for the mini series in Computer Use tasks. You can now deploy desktop automation agents at a "mini" price point to handle form filling, clicking, and file operations.
GPT-5.4 mini vs. Peer Model Comparison
| Model | Input / Output | Context Window | Coding Ability | Computer Use | Recommended Use Case |
|---|---|---|---|---|---|
| GPT-4o mini | $0.15 / $0.60 | 128K | Weak | Not Supported | Outdated, simple tasks |
| GPT-5 mini | $0.25 / $2.00 | 400K | Moderate | Partially Supported | General customer service, lightweight tasks |
| GPT-5.4 mini | $0.75 / $4.50 | 400K | Strong | Fully Supported | Agent / Computer Use / Long context |
| GPT-5.4 Standard | $5.00 / $30.00 | 1M | Top-tier | Top-tier | Complex reasoning, critical decision-making |
| Claude Haiku 4.5 | $0.80 / $4.00 | 200K | Strong | Not Supported | Strong prose / Writing |
Upgrade Decision Guide
4o-mini → 5.4-mini Comparison: GPT-4o mini still holds a price advantage for simple text tasks. However, its capabilities have fallen significantly behind. As long as your application involves reasoning, coding, or long context, upgrading to 5.4-mini is worth it. Even at 5x the unit price, the improvement in quality and reduced need for re-runs often make it more cost-effective.
5-mini → 5.4-mini Comparison: GPT-5 mini remains competent for general customer service and translation. But if you need Computer Use, Subagent orchestration, or complex Agent workflows, 5.4-mini is the must-have choice. While the cache discount remains at 90%, the higher absolute value makes it more economical in the long run.
5.4-mini → 5.4 Standard Comparison: GPT-5.4 mini performs similarly to the standard version in 80% of routine tasks at just 1/6th the price. Only switch to the standard version when the task truly requires top-tier reasoning (e.g., mathematical proofs or complex 20-hour Agent tasks).
📊 Upgrade Path Suggestion: You can seamlessly compare the real-world performance of 4o-mini, 5-mini, 5.4-mini, and 5.4 Standard using the same API key via APIYI (apiyi.com) by simply modifying the
modelparameter. This unified access method is perfect for teams that need to perform gradual migrations or A/B testing.
GPT-5.4 mini API Use Cases
The combination of "high capability + cache optimization + Computer Use + Subagents" in GPT-5.4 mini makes it particularly suitable for the following scenarios:
- High-throughput Conversational Customer Service: High cache hit rates, fast response speeds, and sufficient reasoning depth to handle complex queries.
- Large-scale Content Generation: Batch summarization, translation, and rewriting; the 400K context window allows for processing entire documents at once.
- Subagent Collaboration: Reliable sub-task orchestration, now available for the first time at a "mini" price point.
- Desktop Automation Agents: With an OSWorld score of 72.1%, browser, form, and file operations are now fully viable.
- Lightweight Code Completion and Review: With a SWE-Bench Pro score of 54.4%, it's close to the standard version and ideal for IDE integration.
- Batch Document Processing: Combined with Batch API and caching, it offers a significant cost advantage for processing tens of thousands of documents.
- Educational Tutoring Tools: Enhanced reasoning tokens provide more reliable problem-solving and Q&A capabilities.
🎯 Scenario Decision: If your application makes > 10K calls per day, has a cache hit rate > 50%, and requires reasoning or tool-use capabilities — GPT-5.4 mini is the most worthwhile "mini" model to switch to in 2026. You can access it directly via APIYI (apiyi.com); no application is required for the Default group.
Accessing GPT-5.4 mini via APIYI
Default Group Access Policy
APIYI applies the same access policy to GPT-5.4 mini as it does to Grok 4.3, which differs from the policy for GPT-5.5 Pro:
- ✅ Default Group: Fully open; available to new users immediately upon registration.
- ✅ SVIP Group: Fully open; no restrictions.
- ✅ Cache Discount: $0.075/1M cache pricing is fully supported.
Why is GPT-5.4 mini open to all groups while GPT-5.5 Pro is restricted to SVIP? It primarily comes down to risk assessment per model invocation:
- GPT-5.4 mini: Each call typically costs only a few cents, making it safe for all groups.
- GPT-5.5 Pro: A single call can cost several dollars, requiring SVIP group protection to prevent accidental misuse by new users.
This risk-based management design keeps the mini series accessible to all developers while providing necessary safeguards for high-value models.
APIYI vs. Official Pricing Comparison
| Item | OpenAI Official | APIYI (apiyi.com) |
|---|---|---|
| Base Price | $0.75 / $4.50 per 1M | $0.75 / $4.50 per 1M (Same) |
| Cache Discount | $0.075 / 1M (90%) | $0.075 / 1M (Fully synced) |
| Top-up Bonus | None | Deposit $100, get $10 (10%) |
| Actual Cost | 100% Standard | |
| Domestic Access | VPN required | Direct access, no VPN needed |
| Payment Methods | International Credit Card | Alipay, WeChat Pay, RMB supported |
| SDK Compatibility | OpenAI Native | Fully compatible with OpenAI SDK |
| Group Limits | None | Default + SVIP fully open |
💰 Cost Optimization: By accessing GPT-5.4 mini through APIYI (apiyi.com), you get a 10% bonus on $100 deposits, effectively providing a 15% discount compared to official pricing, with cache discounts fully synced. For applications with high monthly volume and high cache hit rates, the total cost can be over 20% lower than the OpenAI official site.
FAQ
Q1: What is GPT-5.4 mini? How does it differ from GPT-5 mini and GPT-4o mini?
GPT-5.4 mini is the next-generation mini model launched by OpenAI on 2026-03-17, positioned as "our strongest mini model to date." Key differences: 1) SWE-Bench Pro score of 54.4%, significantly leading over GPT-5 mini (45.7%) and 4o-mini (23%); 2) First-time full support for Computer Use (OSWorld 72.1%); 3) Subagent orchestration capabilities at a mini price point; 4) 2x faster response speed than 5 mini. While the price has increased to $0.75/$4.50, caching can offset some of these costs.
Q2: I’m currently using gpt-4o-mini / gpt-5-mini. Is it worth upgrading to 5.4-mini?
4o-mini users are strongly encouraged to upgrade: The performance gap is significant. Even at 5x the unit price, the overall quality and reduced need for multi-round debugging usually make it more cost-effective.
5-mini users should decide based on the scenario:
- ✅ Upgrade recommended: For applications involving Computer Use, Subagents, complex tool chains, or long context (>200K).
- ⏸️ Continue using: For simple FAQ bots, lightweight translation, or pure text generation where 5-mini is already sufficient.
Best practice: Run an A/B test using the same API key on APIYI (apiyi.com) to see which is more cost-effective for your specific use case.
Q3: How do I enable the $0.075/1M cache discount for GPT-5.4 mini?
OpenAI's caching mechanism is triggered automatically without extra parameters. When your prompt prefix (typically the system prompt + shared context) matches a request from the last 5-10 minutes, it will automatically hit the cache and receive the 90% discount ($0.075/1M).
Optimization Tips:
- Place the system prompt at the very beginning of the messages array.
- Put shared context (e.g., knowledge base, document summaries) after the system prompt.
- Place the user's actual query at the end.
- Maintain high-frequency calls (caching expires after >5 minutes).
When calling via APIYI (apiyi.com), cache discounts are fully synced with the official site, requiring no extra configuration.
Q4: When should I use GPT-5.4 mini versus the GPT-5.4 standard version?
Choose mini for:
- High throughput (>10K requests/day)
- Cache hit rates > 50%
- SWE-Bench / Terminal-Bench tasks
- Computer Use automation
- Cost-sensitive production environments
Choose standard version for:
- FrontierMath-level mathematical proofs
- Complex 20-hour-long agent tasks
- High-risk tasks like legal contract review or medical diagnosis
- Critical decisions where a single call is worth > $0.10
Simple rule: 80% of tasks are handled well by mini; only upgrade to the standard version for extremely complex reasoning.
Q5: How do I call GPT-5.4 mini via APIYI? What code needs to change?
APIYI is fully compatible with the OpenAI SDK. Just follow these three steps:
- Visit APIYI (apiyi.com) to register (no application needed, Default group is available immediately).
- Get your API key.
- Update the
base_urlin your code tohttps://vip.apiyi.com/v1and set themodeltogpt-5.4-mini.
client = openai.OpenAI(
api_key="YOUR_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-5.4-mini",
messages=[...]
)
Top up $100 and get a 10% bonus, effectively giving you a 15% discount compared to official pricing, with cache discounts fully synced.
Q6: Does GPT-5.4 mini support fine-tuning?
No. This is one of the current limitations of GPT-5.4 mini. If your application requires fine-tuning, you should choose:
- GPT-5 mini (supports fine-tuning, slightly lower capability)
- GPT-4o mini (supports fine-tuning, lower capability)
- GPT-5.4 standard (supports fine-tuning, 6x the price)
Alternative: GPT-5.4 mini's Reasoning Tokens + Function Calling + caching mechanism often achieve excellent results without the need for fine-tuning.
Q7: How do I call Computer Use for GPT-5.4 mini?
Enable it via the tools parameter:
response = client.chat.completions.create(
model="gpt-5.4-mini",
messages=[{"role": "user", "content": "Help me open the browser and search for..."}],
tools=[{
"type": "computer_use",
"config": {"screen_width": 1920, "screen_height": 1080}
}]
)
The model will return structured operation instructions (click/type/scroll/screenshot). You need to implement these actions on the client side and feed the results back to the model to continue reasoning. An OSWorld-Verified score of 72.1% means it can handle most desktop tasks.
Q8: What are the known limitations of GPT-5.4 mini?
Key limitations include:
- No Fine-tuning support: Cannot be fine-tuned with custom datasets.
- No image output: Text-only output; cannot generate images.
- Higher price than older minis: Standard price is 5x that of 4o-mini; requires cache optimization.
- Reasoning Tokens count toward output billing: Costs for complex tasks may exceed expectations.
- Regional data residency +10%: Additional fees apply for compliance-sensitive scenarios.
For scenarios extremely sensitive to latency (<1 second response), we recommend testing before deciding whether to switch.
GPT-5.4 mini API Key Takeaways
- Capability Leap: Achieved 54.4% on SWE-Bench Pro, outperforming GPT-5 mini's 45.7% by a solid 8.7 percentage points.
- Cache Discount: 90% discount on input cache at $0.075/1M, significantly slashing costs for high-frequency scenarios.
- Computer Use: Reached 72.1% on OSWorld, marking the first time the mini series fully supports desktop automation.
- Subagent Friendly: Brings multi-agent collaboration to the mini price tier for the first time.
- 400K Context Window: Process entire technical books or complete codebases in a single pass.
- 2x Faster Response: Doubled the speed while simultaneously boosting capabilities.
- Default Access: Available immediately in the APIYI default group—no application required.
Summary
Here are the core takeaways for the GPT-5.4 mini API:
- Upgrade Motivation: Comprehensive improvements across three major benchmarks—SWE-Bench Pro, Terminal-Bench, and OSWorld. It’s the first time Computer Use and Subagents have been introduced at the mini price point.
- Pricing: $0.75 / $4.50 per 1M tokens, with a 90% discount on input cache ($0.075). For high-frequency use cases, the actual cost may even be lower than the previous mini model.
- How to Access: Call it directly via the APIYI (apiyi.com) default group. Plus, get a 10% bonus on top-ups of 100, with direct domestic connectivity—no VPN required.
GPT-5.4 mini isn't just a "price-hiked version of GPT-5 mini"; it's a pivotal move by OpenAI to bring agentic capabilities to the entry-level price tier. If your application makes over 10K calls per day, has a cache hit rate above 50%, or requires Agent or Computer Use capabilities, this upgrade is essentially a must-have. For simple, text-only tasks, GPT-4o mini or GPT-5 mini remain perfectly viable options.
We recommend getting started with GPT-5.4 mini via the APIYI (apiyi.com) platform. You get immediate access via the default group, full synchronization with cache discounts, a 10% top-up bonus, and stable, direct domestic access.
Related Articles
If you're interested in the GPT-5.4 mini API, we recommend checking out these articles:
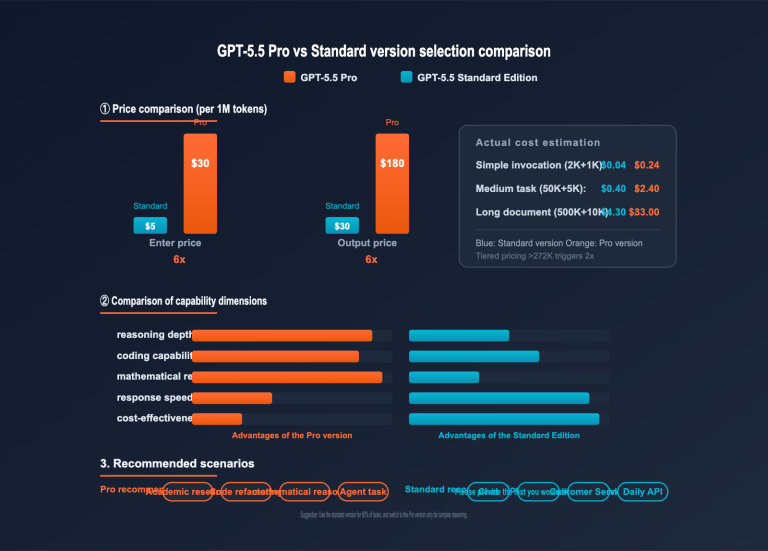
- 📘 GPT-5.5 Pro API Integration Guide – Learn about OpenAI's top-tier reasoning flagship and how it complements the mini model for various use cases.
- 📊 Deep Dive into OpenAI Caching: Best Practices for 90% Discounts – Master the engineering techniques for cache optimization.
- 🚀 Building a Computer Use Automation Agent with GPT-5.4 mini – Explore production-grade applications for desktop automation.
📚 References
-
Official OpenAI GPT-5.4 mini Model Documentation: Model specifications, pricing, and invocation examples.
- Link:
developers.openai.com/api/docs/models/gpt-5.4-mini - Note: Get the latest and most authoritative official technical parameters.
- Link:
-
DataCamp GPT-5.4 mini Review: Detailed benchmark breakdown and cross-generational comparison.
- Link:
datacamp.com/blog/gpt-5-4-mini-nano - Note: Independent third-party review, perfect for horizontal comparisons with similar models.
- Link:
-
APIYI GPT-5.4 mini Integration Documentation: Domestic access solutions, grouping instructions, and recharge discounts.
- Link:
docs.apiyi.com - Note: A practical integration guide tailored for developers in China.
- Link:
-
OpenAI Pricing Page: Complete price list and details on the caching mechanism.
- Link:
developers.openai.com/api/docs/pricing - Note: The latest billing standards for all models.
- Link:
Author: APIYI Technical Team
Technical Discussion: Feel free to share your experience with the GPT-5.4 mini upgrade in the comments. For more model integration resources, visit the APIYI documentation center at docs.apiyi.com.