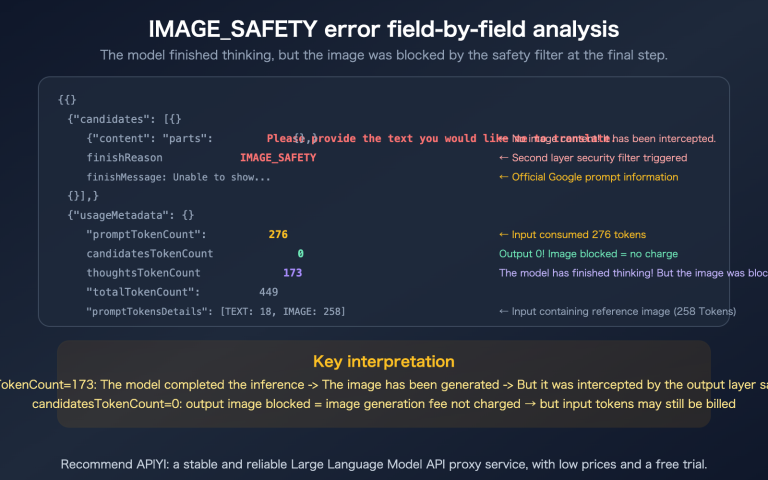
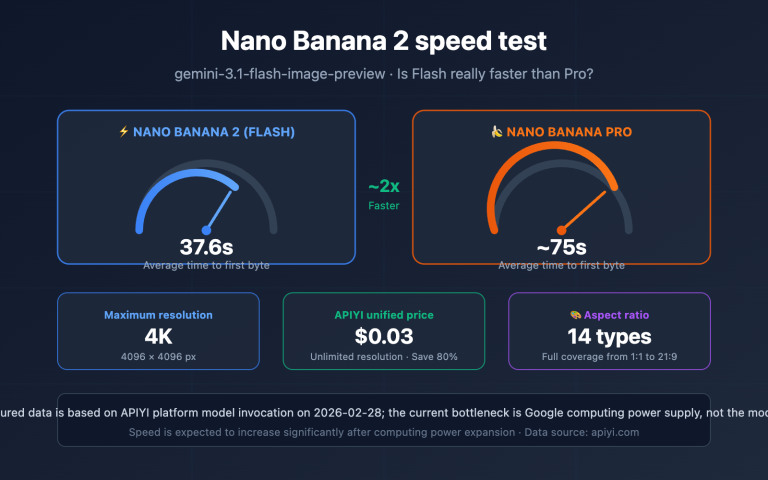
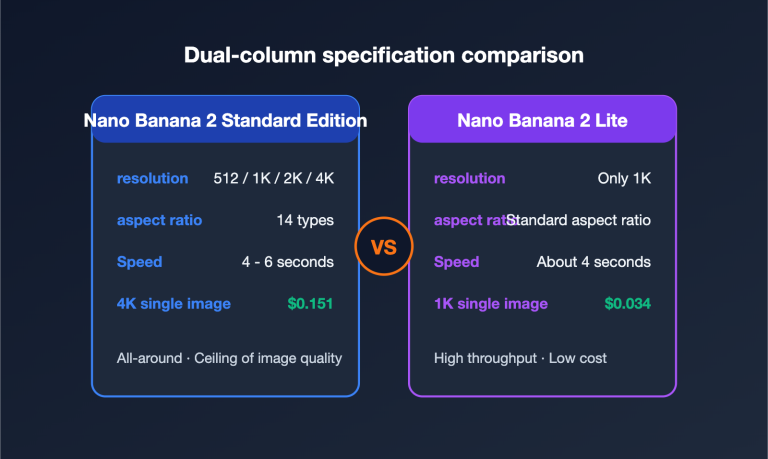
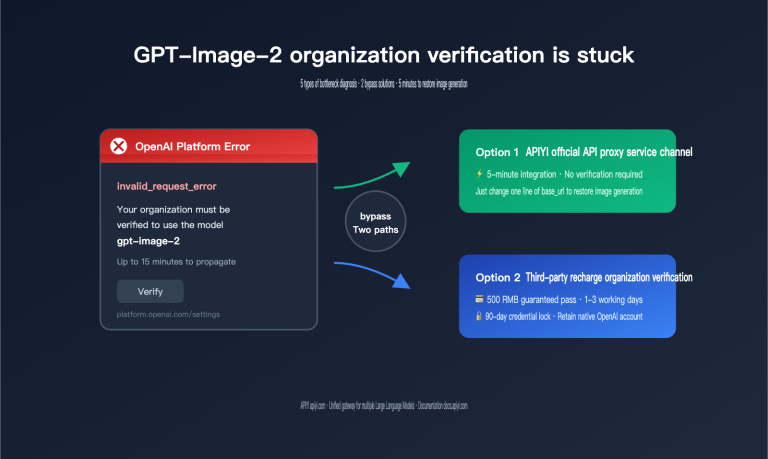
When enterprise users inquire about integration solutions for Google models like Gemini or Nano Banana Pro, "Provisioned Throughput (PT)" is a term that frequently comes up—and is just as frequently misunderstood. Common misconceptions include: "Is PT the enterprise version of AI Studio?", "Is PT just buying priority for the Gemini API?", and "Does PT lower the unit price?"
The answers to these questions aren't always intuitive. Based on the latest official Google Cloud Vertex AI documentation, this article will break down PT once and for all: it belongs to the Vertex AI ecosystem, not AI Studio; its unit of measurement is the GSU (Generative AI Scale Unit); it does not lower unit prices but guarantees throughput priority; and the corresponding pay-as-you-go mechanism is called DSQ (Dynamic Shared Quota).
Understanding these concepts will not only help you correctly evaluate whether your enterprise should purchase PT, but also help you rationally choose between the three paths: building your own Google integration, subscribing to PT, or using an aggregation platform like APIYI (apiyi.com).
What is Google Provisioned Throughput (PT)?
Provisioned Throughput (PT) is a fixed-cost, fixed-term throughput reservation subscription provided by the Google Cloud Vertex AI platform for generative AI models. Its core logic is: Enterprises commit to purchasing a certain amount of processing capacity in advance, and Google reserves dedicated computing power for you in exchange for certainty and priority in model invocation throughput.
Official Definition and Key Features of PT
According to official Google Cloud documentation:
Provisioned Throughput is a fixed-cost, fixed-term subscription available in several term-lengths that reserves throughput for supported generative AI models on Vertex AI.
Let's break down the three keywords in this statement:
- Fixed-cost: Independent of actual usage; paid in advance based on your commitment.
- Fixed-term: Choose from four options: 1 week, 1 month, 3 months, or 1 year.
- Reserves throughput: It doesn't reserve "computing power" in the traditional sense, but rather "tokens-per-second processing capacity."
What PT is NOT: Clearing Up Three Major Misconceptions
| Common Misconception | Fact Check |
|---|---|
| "PT = Enterprise version of AI Studio" | ❌ PT only exists in Vertex AI and has no direct connection to AI Studio. |
| "PT lowers the unit price" | ❌ PT does not lower the unit price; it only provides throughput guarantees and priority. |
| "PT can be canceled at any time" | ❌ It cannot be canceled during the term after signing; you can only add more GSUs. |
| "PT gives you exclusive GPU access" | ❌ PT reserves throughput units (GSU), not hardware exclusivity. |
| "PT applies to all Google models" | ❌ Only supported models are eligible; check the support list. |
💡 Recommendation for Common Scenarios: If your core requirement is to "lower unit costs" rather than "guarantee throughput," then PT isn't the right fit for you. In this case, accessing the Gemini series (including Nano Banana Pro) through the APIYI (apiyi.com) enterprise solution is often a more economical choice, offering up to 63% off official prices, while supporting RMB settlement and VAT invoicing.
Understanding GSU (Generative AI Scale Unit)
To understand PT (Provisioned Throughput), you first need to grasp its unit of measurement: the GSU.
Official Definition of GSU
A GSU is an abstract unit of throughput capacity. It keeps pricing and capacity consistent across all Google models that support PT, though different models have different GSU consumption efficiencies. In other words:
- The price of 1 GSU is consistent across all models.
- The capacity (tokens throughput per second) of 1 GSU is also consistent across all models.
- However, the actual model invocation volume a single GSU can support varies depending on the model.
GSU to Model Mapping Examples
The table below is for illustrative purposes (please refer to official Google data for the most current figures):
| Model | Throughput per 1 GSU | Note |
|---|---|---|
| Gemini 2.5 Flash-Lite | Higher | Lightweight model; one GSU supports more requests |
| Gemini 2.5 Flash | Medium | Balanced; the choice for most enterprises |
| Gemini 2.5 Pro | Lower | Flagship model; consumes more GSU |
| Gemini 3 Pro | Lowest | New flagship; high GSU consumption per request |
| Gemini 3 Pro Image | Based on image size | 4K images consume significantly more than 1K |
This means that if your business uses multiple models, you need to purchase separate GSU commitments for each model rather than sharing a single GSU pool.
How to Estimate Required GSU
Google provides an official GSU calculator, but you can simplify the estimation logic like this:
Required GSU = (Peak QPS × Average tokens per request) / (Throughput capacity of 1 GSU)
Practical steps for enterprises:
- Calculate historical peak QPS (queries per second).
- Calculate average tokens consumed per request (input + output).
- Check the single GSU throughput for your target model.
- Round up and reserve a 20-30% buffer to handle traffic spikes.
Minimum Purchase Units and Tiers
A PT order typically has a minimum GSU purchase requirement (which varies by model and region). Once an enterprise signs a contract:
- ✅ Add GSUs: You can increase your commitment at any time as your business grows.
- ❌ Reduce GSUs: You cannot decrease your commitment during the current term.
- ⚠️ Renewal Adjustments: You must re-evaluate your scale before the commitment period ends.
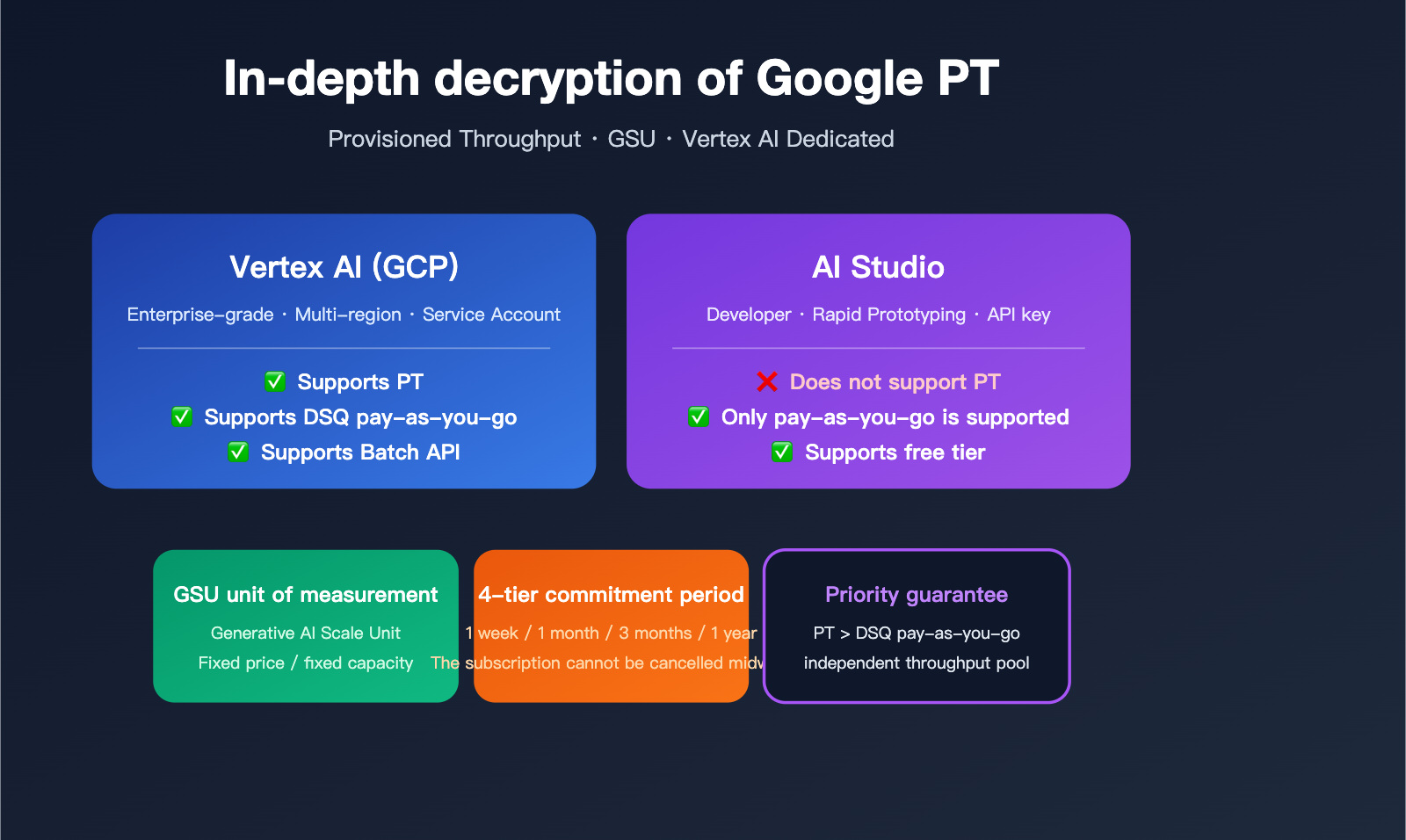
Vertex AI vs. AI Studio: Clarifying PT Ownership
This is where most customers get confused. Google operates two independent generative AI product lines:
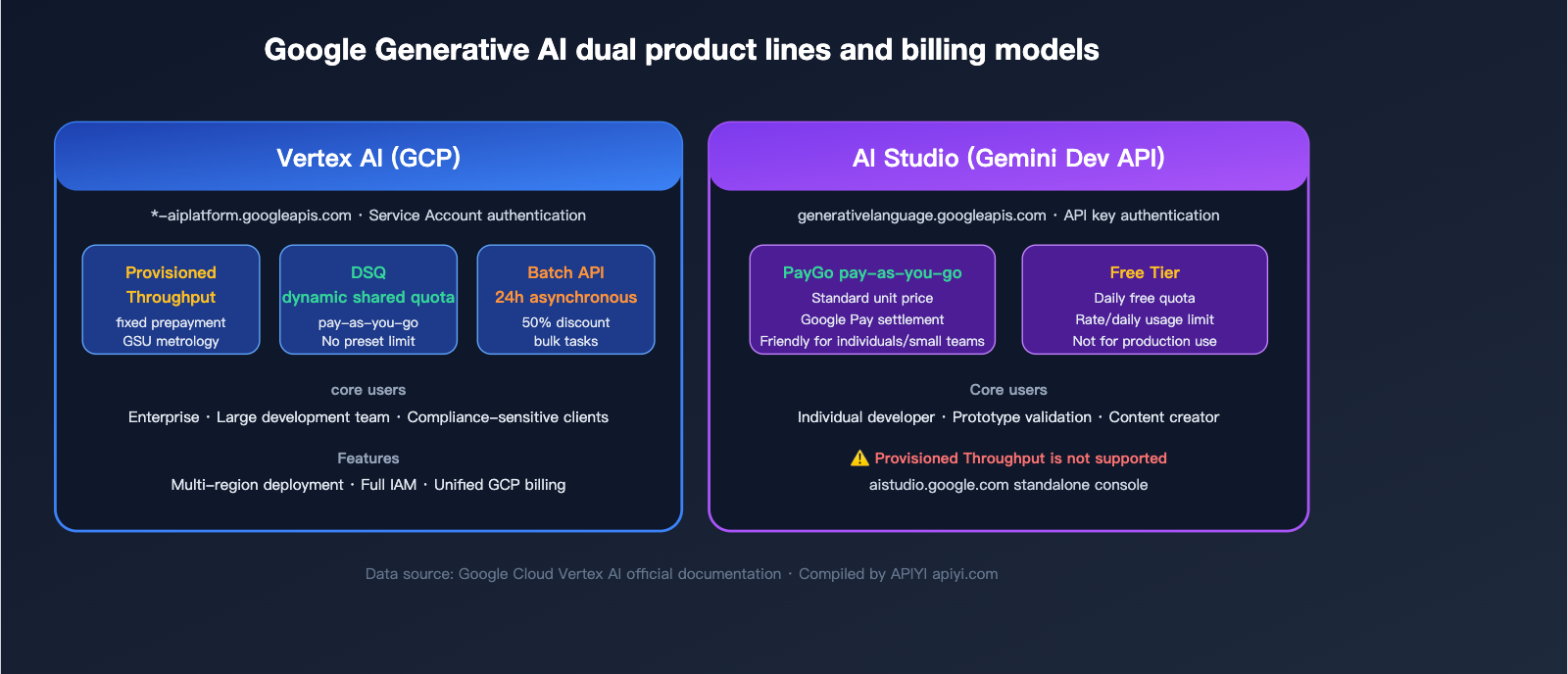
Vertex AI: Enterprise-Grade Google Cloud Platform Product
- Ownership: Google Cloud Platform (GCP)
- Target Audience: Enterprises, large development teams, compliance-sensitive customers
- Billing: Unified via GCP billing; supports Pay-as-you-go (DSQ), Provisioned Throughput (PT), and Batch
- Console: console.cloud.google.com → Vertex AI menu
- API Path:
*-aiplatform.googleapis.com - Supports PT: ✅ Yes
- Regional Deployment: ✅ Supports global multi-region
AI Studio: Entry Point for Developers and Individuals
- Ownership: Google AI for Developers (independent of GCP)
- Target Audience: Individual developers, rapid prototyping, content creators
- Billing: Personal Google Pay account, pay-as-you-go
- Console: aistudio.google.com
- API Path:
generativelanguage.googleapis.com - Supports PT: ❌ No
- Regional Deployment: ❌ Global shared pool
API Integration Code Differences
AI Studio (Gemini Developer API):
from google import genai
client = genai.Client(api_key="AIzaSy-xxx") # AI Studio personal key
resp = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="An orange cat"
)
Vertex AI:
from google import genai
client = genai.Client(
vertexai=True,
project="your-gcp-project", # GCP project ID
location="us-central1" # Region
)
# Authentication is handled via gcloud ADC / Service Account; no API key needed
Note that the model names, authentication methods, and billing ownership differ between the two. If you start with an AI Studio API key, you cannot purchase PT; you must enable Vertex AI within a GCP project and authenticate using a Service Account.
🎯 Integration Tip: If you don't want to deal with the complexities of AI Studio vs. Vertex AI boundaries, Service Account authentication, or multi-region routing, you can use APIYI (apiyi.com) to access the entire Gemini model family. We provide a compatible OpenAI-style
base_url+api_keyand handle the underlying account architecture and routing for you.
Understanding DSQ (Dynamic Shared Quota) Pay-As-You-Go
DSQ is the default pay-as-you-go model for Vertex AI and the billing method used by the vast majority of users. Understanding DSQ is essential to grasping the true value of PT (Provisioned Throughput) priority.
Core Mechanisms of DSQ
With DSQ, there are no predefined quota limits on your usage. Instead, DSQ provides access to a large, shared pool of resources, dynamically allocated based on real-time availability of resources and real-time demand across all customers of that model.
Key takeaways:
- No Predefined Quotas: No need to submit a QIR (Quota Increase Request).
- Shared Resource Pool: All pay-as-you-go customers share the same large pool.
- Dynamic Allocation: Resources are re-partitioned based on real-time global demand.
- Throughput Fluctuations: Throughput per user may decrease during peak periods.
The Priority Relationship Between DSQ and PT
Google clearly states:
Provisioned Throughput customers are prioritized and serviced first before on-demand requests.
This is the core value of PT: your requests are processed with priority in Google's scheduling queue. Specifically:
- PT requests → Enter a dedicated high-priority queue, ensuring stable response times.
- DSQ requests → Enter a shared pool, where they may be throttled or queued during peak times.
Typical Scenarios Where DSQ Hits Limits
Enterprises without PT often face challenges in these scenarios:
- E-commerce Peak Sales (Midnight Spikes): The global shared pool becomes congested, causing P99 latency to double.
- Live Interactive Image Generation: High real-time requirements make DSQ fluctuations unacceptable.
- Cross-Border Operations: Simultaneous calls across multiple regions, where DSQ capacity varies significantly by region.
- First Week of New Model Releases: Official Google quotas may not be fully opened, leading to tight DSQ capacity.
However, it's important to note: For small and medium-sized enterprises with fewer than 50,000 monthly calls or 50,000 images per month, DSQ's stability is generally sufficient, and purchasing PT would be an over-investment.
PT Commitment Options and Purchasing Process
PT commitment periods are designed to cover everything from initial testing to long-term contracts:
Comparison of Four Commitment Periods
| Commitment | Typical Scenario | Total Cost Ratio | Flexibility |
|---|---|---|---|
| 1 Week | Short-term events/peak sales validation | Base × 1 | Highest |
| 1 Month | Stable monthly business planning | ~Base × 0.95 | Medium |
| 3 Months | Quarterly business commitment | ~Base × 0.88 | Lower |
| 1 Year | Long-term contract + budget locking | ~Base × 0.75 | Lowest |
Specific pricing can be viewed after logging into the GCP console, as prices vary by region and model.
Steps to Purchase PT

Standard process for enterprises to purchase PT:
- Estimate Requirements: Use the official Google GSU calculator to estimate required capacity.
- Create GCP Project: Enable Vertex AI API and configure a Service Account.
- Initiate Purchase: Place an order via GCP Console → Vertex AI → Provisioned Throughput.
- Select Parameters: Choose model, region, GSU quantity, and commitment period.
- Financial Approval: Pay via USD credit card or corporate ACH.
- Activation: Typically takes 1-5 business days to become active.
- API Configuration: Add the
provisioned_throughput_idparameter in your code to switch to the PT channel.
PT API Usage Example
After enabling PT, you must explicitly specify it in your code:
from google import genai
from google.genai import types
client = genai.Client(
vertexai=True,
project="your-gcp-project",
location="us-central1"
)
resp = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="An orange cat",
config=types.GenerateContentConfig(
# Specify the PT subscription ID to route requests through the priority channel
labels={"dedicated-capacity": "your-pt-subscription-id"}
)
)
If you don't specify this parameter, your requests will continue to use the DSQ channel, even if you have an active PT subscription.
Comparing Vertex AI Billing: PT vs. DSQ vs. Batch
Vertex AI offers three distinct billing models. Understanding the boundaries between them is crucial for corporate decision-making:
| Dimension | Provisioned Throughput | Dynamic Shared Quota | Batch API |
|---|---|---|---|
| Billing Model | Fixed Prepaid | Pay-as-you-go | Pay-as-you-go |
| Unit Price | Same as pay-as-you-go | Official list price | 50% discount |
| Priority | Highest (Dedicated) | Shared pool | Lowest (24h window) |
| Commitment | Week/Month/Quarter/Year | None | None |
| Latency | Stable (Low) | Variable | 24h asynchronous |
| Use Case | High-concurrency real-time | General daily use | Large-scale offline |
| Entry Barrier | Thousands of dollars | Free start | Free start |
The Winning Strategy: PT + DSQ + Batch
Mature enterprises typically adopt a hybrid billing architecture:
- PT for core real-time services: Think live-stream image generation or interactive user experiences.
- DSQ for daily baseline traffic: Most non-critical requests run on pay-as-you-go.
- Batch for large-scale nightly tasks: Such as report generation or data labeling.
⚡ Hybrid Architecture Tip: If your team is lean and you don't want to deal with complex multi-channel routing, we recommend using APIYI (apiyi.com) as your unified interface. We've implemented intelligent routing on the backend: urgent requests hit the VIP channel, batch tasks move to the Batch channel, and daily calls use the standard channel. It’s transparent to your application—a single API key gives you all the benefits of a hybrid strategy.
Detailed PT Applicability Assessment
Four Types of Businesses That Really Need PT
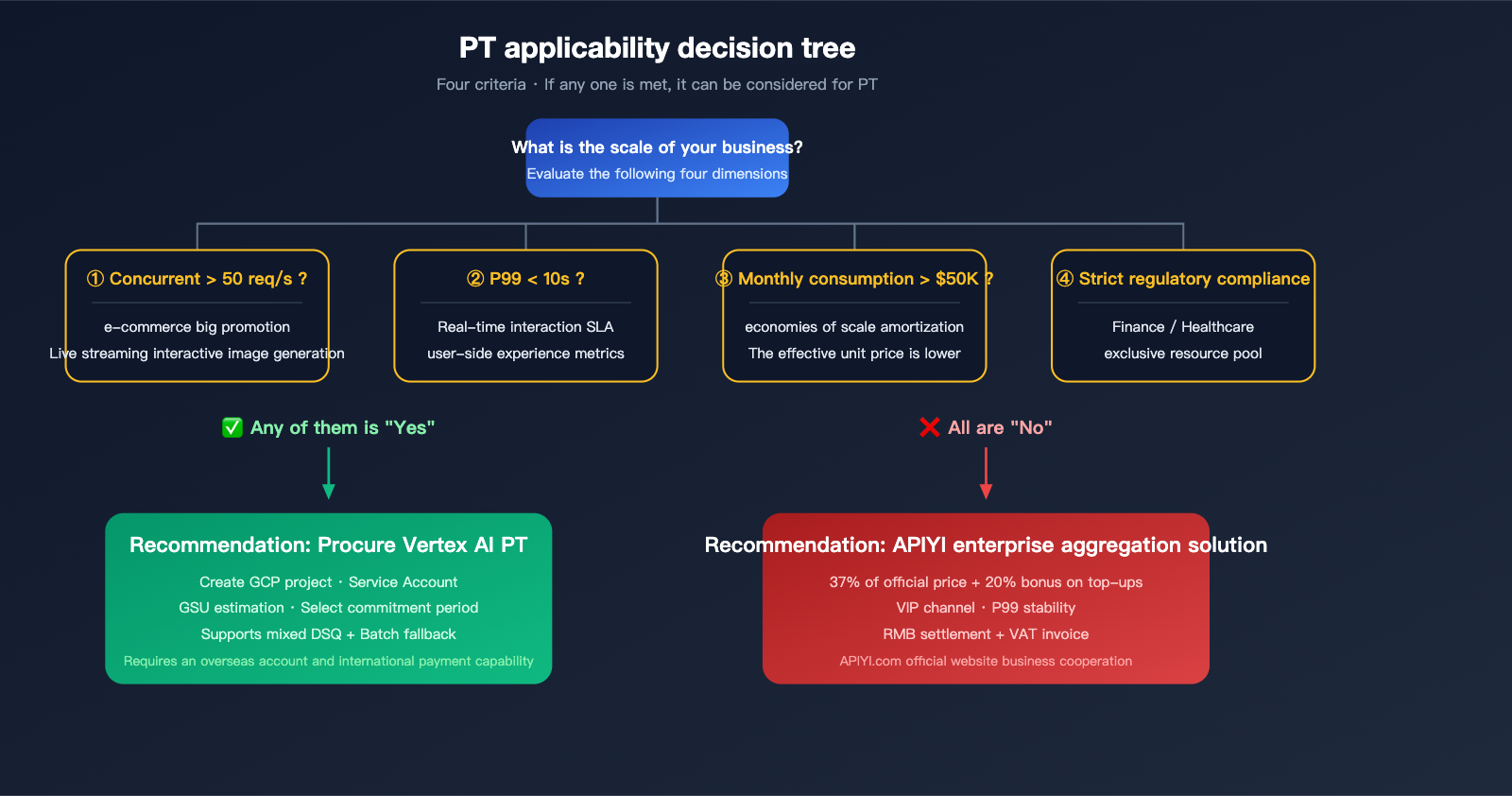
Scenario 1: High-concurrency real-time business
E-commerce spikes, short-video platforms, and live-stream interactive scenarios often require peak concurrency > 50 requests/second. DSQ might trigger rate limiting here, making PT essential for guaranteed capacity.
Scenario 2: Strict P99 latency requirements
If your SLA mandates a P99 time-to-first-token of < 10 seconds (e.g., real-time AI art tools), DSQ, which typically fluctuates between 15-30 seconds, simply won't cut it.
Scenario 3: Exceeding monthly spend thresholds
When monthly spend exceeds $50,000, the fixed commitment cost of PT is diluted by economies of scale. At this level, unit costs can be lower than DSQ, making PT both more economical and more stable.
Scenario 4: Stringent regulatory compliance
Industries like finance and healthcare often require dedicated resource pools and specific compliance declarations. PT provides the explicit isolation guarantees necessary for these use cases.
Five Scenarios Where PT Doesn't Make Sense
- Monthly usage < 50,000 requests: The fixed cost of PT isn't well-utilized; pay-as-you-go is much more cost-effective.
- Highly volatile traffic: Prepaid commitments often lead to significant waste during idle periods.
- Just looking for lower unit prices: PT doesn't reduce the base unit price; look for volume-based aggregator channels instead.
- Mixing multiple models: Managing individual GSU commitments for every model creates unnecessary operational overhead.
- Small to mid-sized teams: Often lack the finance and operations bandwidth to manage long-term enterprise commitments.
If you don't fit the PT profile, you can access the full Gemini model family via APIYI (apiyi.com) at an enterprise discount of 37% off. Combine that with our top-up bonuses of up to 20%, and your effective unit cost can drop to around 32% of Google’s official price—giving you better stability at a much lower price point.
FAQ
Q1: I've already been developing with a Gemini API key in AI Studio. Can I purchase PT?
No. AI Studio (Gemini Developer API) and Vertex AI are two separate systems; PT is exclusive to Vertex AI. To use PT, you must: ① Create a GCP project and enable Vertex AI; ② Migrate to the Vertex AI Service Account authentication method; and ③ Rewrite parts of your model invocation code. If you'd rather skip this migration, you can use APIYI (apiyi.com) to call Gemini via an OpenAI-compatible base_url without worrying about the underlying account architecture.
Q2: Is the unit price cheaper with PT compared to pay-as-you-go?
The unit price remains the same, but when spread across total costs per million tokens, the overall cost can be lower for large-scale usage. The mechanism works like this: PT is billed as a fixed monthly commitment. If you fully utilize your GSU capacity, your effective unit price is roughly 80-95% of DSQ. If you don't fully utilize it, it actually becomes more expensive. The real value of PT isn't just saving money—it's about guaranteed throughput, stable latency, and higher priority.
Q3: Can I cancel or reduce the number of GSUs mid-term?
No. Once you sign the contract, you cannot cancel or reduce your GSU count during the commitment period. You can only choose whether to renew before the cycle ends. The only allowed change is adding more GSUs (if your business expands). This is the biggest risk with PT—your prepaid commitment must be based on conservative usage estimates.
Q4: Does Gemini 3 Pro Image (Nano Banana Pro) support PT?
As of April 2026, according to Google's official support list, the Gemini 3 Pro series models (including gemini-3-pro-image-preview) support Provisioned Throughput. However, keep in mind that GSU consumption for image models is calculated based on image dimensions and tokens; a 4K image consumes significantly more GSU per request than a 1K image. Specific consumption coefficients are subject to Google's official data. For a quick cost comparison, you can contact the APIYI (apiyi.com) sales team to get an enterprise pricing comparison table.
Q5: I don't have a GCP account or an international credit card. Can I still get a priority channel similar to PT?
Yes. APIYI (apiyi.com) enterprise solutions achieve a similar priority channel effect through multi-account aggregation + VIP exclusive queues. You only need a domestic business entity and RMB corporate payment to get started. The enterprise channel's P99 latency is comparable to Google's native pay-as-you-go channel. For customers with a monthly volume of less than 50,000 images, this is more than sufficient, and the cost is only 32-37% of the official pay-as-you-go price.
Q6: Can PT and Google Batch API be used together?
Yes. The Batch API uses an independent asynchronous channel, which doesn't conflict with PT/DSQ. A mature architecture combines all three: real-time critical requests go through PT, daily requests go through DSQ, and large-scale nighttime tasks go through Batch (enjoying a 50% discount). This "three-channel hybrid" approach maximizes overall cost efficiency.
Summary
Back to the core question of this article—What is Google Provisioned Throughput (PT), and which system does it belong to?
The short answer is: PT is an enterprise-grade throughput reservation subscription under Google Cloud Vertex AI (GCP). It uses GSU (Generative AI Scale Unit) as the unit of measurement and offers commitment periods of 1 week, 1 month, 3 months, or 1 year. During the commitment period, it does not lower the unit price but provides scheduling priority and stable throughput. It is unrelated to AI Studio (generativelanguage.googleapis.com) and forms a "priority vs. shared" binary structure with the pay-as-you-go DSQ (Dynamic Shared Quota) mechanism.
For the vast majority of small and medium-sized enterprises, individual developers, and content creators, the barrier to entry and the commitment period constraints of PT are too high. A more practical path is to access the full range of Gemini models through an aggregation platform like APIYI (apiyi.com), enjoying enterprise-grade stable channels at a lower price (37% of the official rate) while avoiding the complexities of cross-border accounts, international payments, and English-language compliance.
Only when your business scale truly hits one of the four PT thresholds (high concurrency, low P99, monthly spend >$50K, or strict regulation) is it a rational choice to invest the time to research and purchase PT.
📌 Author's Note: This article was compiled by the APIYI (apiyi.com) enterprise solutions team. The content is based on official Google Cloud Vertex AI documentation and the latest enterprise policies as of April 2026. If you need a quick assessment of whether your business is better suited for PT or aggregated access, feel free to contact us via the business portal on our official website for a 1-on-1 analysis.