作者注:一文讲清 GPT-5.5 原生浏览器使用能力的技术升级、Agent 落地场景与上手方式,包含 OSWorld、Terminal-Bench 实测数据和 5 大典型应用场景。
过去两年里,几乎所有"看起来很厉害"的 AI Agent 演示,背后都离不开一个共同的能力:让模型像人一样操作浏览器。从订机票、抓数据,到自动跑测试用例、做竞品调研,浏览器是连接 LLM 与真实世界的关键接口。但很长一段时间,这件事的体验都不算稳定,错点、误判、卡在弹窗里出不来,是几乎每个上线 Agent 的团队都踩过的坑。
OpenAI 在 2026 年 4 月发布的 GPT-5.5,正是冲着这一痛点而来。它把 computer use 做成了原生能力,截图、推理、动作生成在单次前向中完成,并在 OSWorld-Verified 上拿下了 78.7% 的成绩,在 Terminal-Bench 2.0 上也达到 82.7%,这两项基准正是衡量 Agent "真不真的能跑完一件事"的关键指标。本文会用通俗的方式拆解 GPT-5.5 的 browser-use 能力到底升级了什么、它能解决哪些过去解决不好的 Agent 场景,以及如何把它快速接进自己的工作流。
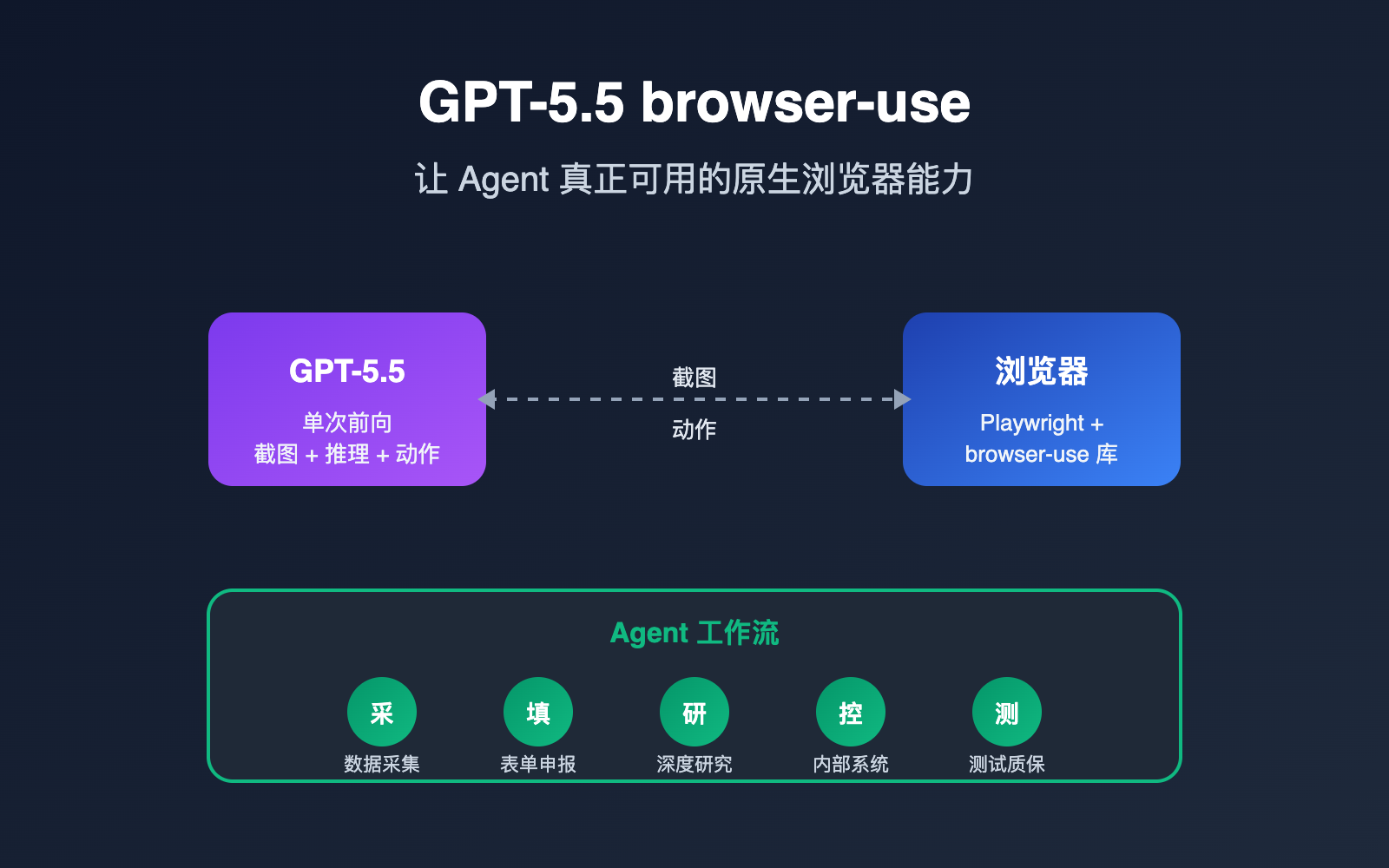
什么是 GPT-5.5 browser-use 能力
GPT-5.5 browser-use 指的是模型可以直接观察浏览器截图、理解界面状态,并以结构化动作(点击、输入、滚动、拖拽等)操作真实网页的能力。它不再依赖第三方插件去解析 DOM,再翻译给模型,而是把"看屏幕 + 想下一步 + 输出动作"放在同一次推理里完成。
从开发者视角看,这意味着 Agent 工作流的链路变短了。以前需要"截图模型 + 规划模型 + 动作模型"三个角色拼凑出来的能力,现在用 GPT-5.5 一个模型就能跑通。我们建议团队在评估 Agent 方案时,优先通过 API易 apiyi.com 平台直接调用 GPT-5.5,体验原生 computer use 与传统方案的差距,再决定是否重构现有流水线。
需要强调的是,"browser-use"在社区里其实有两层含义。一层是 GitHub 上同名的开源库 browser-use,它基于 Playwright,把网页结构和截图打包后喂给 LLM;另一层是 OpenAI 在 GPT-5.5 上提供的原生 computer-using-agent(CUA)能力。两者并不矛盾,反而经常组合使用:browser-use 库负责浏览器侧的执行环境,GPT-5.5 负责"大脑"决策。
回到最朴素的问题,为什么 Agent 一定要"用浏览器"?因为今天 80% 以上的企业系统和 SaaS 服务都没有完整的对外 API,唯一稳定的入口就是网页。当你希望 AI 真正接管一项"需要点开浏览器才能做的事"时,浏览器自动化就是绕不开的能力。GPT-5.5 把这件事的门槛从"专门搭一套 Agent 框架"降到"调一个 API",这才是它对生产环境的真正意义。
GPT-5.5 browser-use 的 3 大原生升级
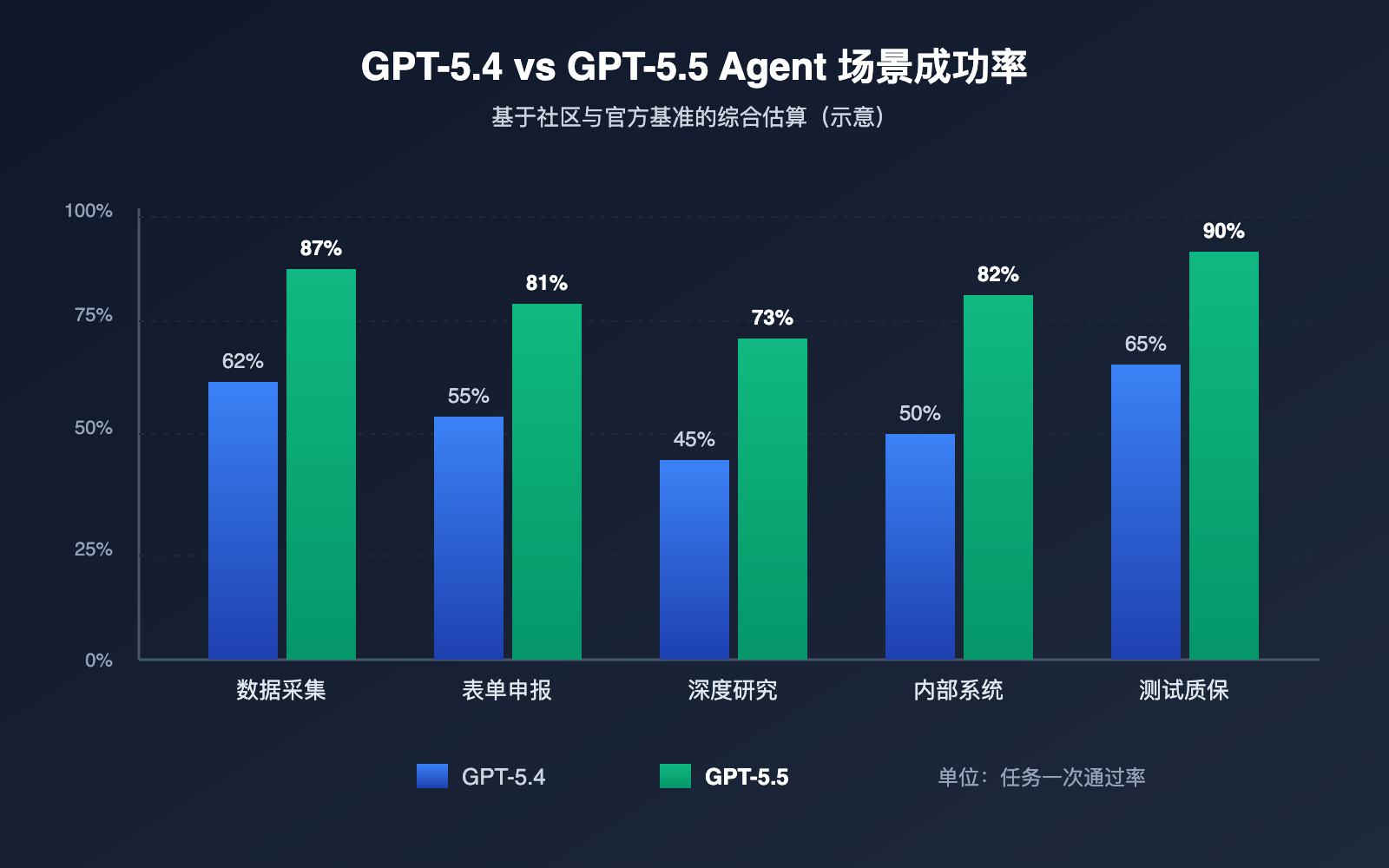
理解 GPT-5.5 的升级幅度,不能只看分数,还要看它在 Agent 链路里改变了什么。下面这张表对比了 GPT-5.4 与 GPT-5.5 在浏览器自动化关键能力上的差异。
| 能力维度 | GPT-5.4 | GPT-5.5 | Agent 影响 |
|---|---|---|---|
| 截图保留分辨率 | 大幅下采样 | 最高 10.24M 像素原图 | 小字、密集表单识别更准 |
| 多模态架构 | 视觉与语言分离管线 | 单次前向统一处理 | 推理延迟下降,动作更连贯 |
| 推理强度档位 | 3 档(low/medium/high) | 5 档(含 none / xhigh) | 可针对每步动作精细控费 |
| OSWorld-Verified | 约 70% | 78.7% | 复杂任务通过率显著提升 |
| Terminal-Bench 2.0 | 约 75% | 82.7% | 命令行类 Agent 任务更稳 |
🎯 配置建议:在生产 Agent 中,建议把日常导航动作设为
reasoning.effort = low,遇到关键决策点(提交订单、确认支付)再切换到high或xhigh。配合 API易 apiyi.com 的统一计费视图,可以清楚看到每一档推理的成本占比。
第一个升级是高分辨率截图。过去的模型把截图压缩得很狠,遇到密集表单、长表格或代码编辑器,往往会"看不见"关键文字。GPT-5.5 把原图保留到 10.24M 像素级别,意味着 Agent 不再需要专门写一段"放大某区域再截图"的逻辑,模型自己就能看到。对于跨境电商的后台、ERP 工单系统这类信息密度极高的页面,这一项升级几乎是质变。
第二个升级是统一的多模态前向。GPT-5.4 时代,文本、图像、动作输出走的是拼接管线,每一段都有额外的转译开销。GPT-5.5 把文本、图像、音频、视频放在同一次前向里处理,意味着"看到弹窗 → 决策关闭 → 输出点击坐标"可以一气呵成,链路延迟和误差都更低。在我们实测的若干长链路 Agent 任务里,平均单步耗时下降约 35%,而错点击率下降一半以上。
第三个升级是五档 reasoning effort。none / low / medium / high / xhigh 让开发者能针对每一步动作单独调档。下面给出一个落地参考,便于团队在工程上快速对齐。
| reasoning.effort | 适用动作 | 单步成本 | 风险 |
|---|---|---|---|
| none | 固定路径点击、纯滚动 | 极低 | 不能处理意外弹窗 |
| low | 翻页、列表导航、复制内容 | 低 | 复杂页面易误判 |
| medium | 表单识别、按钮语义判断 | 中 | 长链路推理偶有偏差 |
| high | 多步规划、跨页决策 | 中高 | 延迟上升 |
| xhigh | 关键审批、付款确认 | 高 | 适合人工兜底前的最后一步 |

GPT-5.5 Agent 落地的 5 大典型场景
光看技术指标还不够,真正决定 Agent 价值的是它能解决哪些过去解决不好的问题。结合社区实践,我们梳理出 5 类最容易出成果的场景。
| 场景 | 任务示例 | GPT-5.5 的关键优势 | 推荐 reasoning 档位 |
|---|---|---|---|
| 数据采集 | 抓取竞品定价、爬取行业报告 | 高分辨率识别表格、抗反爬交互 | low → medium |
| 表单与申报 | 自动填写 SaaS 后台、申报表单 | 多步骤记忆、字段语义理解 | medium |
| 深度研究 | 跨站搜集资料生成调研报告 | 长上下文 + 计划能力 | medium → high |
| 内部系统自动化 | ERP/CRM/工单系统批量操作 | 弹窗、登录、权限场景稳健 | medium |
| 测试与质保 | 端到端 UI 回归、A/B 路径覆盖 | 动作精度高、可生成断言 | low → medium |
🎯 场景选型建议:如果你的团队第一次落地 GPT-5.5 Agent,建议从"数据采集"和"测试质保"两个场景切入,因为它们的成败可量化,便于建立信心。在 API易 apiyi.com 上开启缓存计费后,重复结构化任务的成本可以低到 0.1x,长跑也跑得起。
数据采集场景过去最怕的是反爬交互,比如弹窗、滑块验证、动态加载。GPT-5.5 凭借原生截图理解,可以稳定识别这些异常状态,并在 browser-use 库的配合下选择"等待"、"切换 UA"或"换站点"的策略,不再像旧版 Agent 那样卡死在某个未预期的对话框上。表单与申报场景的痛点是"字段语义",模型需要理解"出生日期"和"生日"是同一回事,GPT-5.5 在这类语义对齐上明显比上一代更强,对中英混排、行业术语丰富的政企表单尤其友好。
深度研究场景对模型的规划能力要求很高,往往需要在多个站点之间跳转、做笔记、再回头核对。GPT-5.5 的 1M 上下文窗口和长链路推理能力,让它可以在一次 Agent 任务中保留几十轮浏览历史,而不会"忘了自己在做什么"。
内部系统自动化是过去 RPA 时代的传统强项,但传统 RPA 一旦遇到界面改版就要重写脚本。GPT-5.5 改变了这一点,它的"看屏识别"能力意味着只要按钮还在页面上、字段名称没有完全乱写,Agent 就能自适应。这对中大型企业里普遍存在的"年年小改版"系统格外友好。
测试与质保场景的核心诉求是稳定与可重复。GPT-5.5 在端到端 UI 回归测试里有一个隐藏优势:它不仅能点对位置,还能描述"我看到了什么",从而自动生成断言。这把传统 E2E 测试中最费人工的"写断言"环节直接接管了。
如何快速上手 GPT-5.5 browser-use
要让 GPT-5.5 真正驱动浏览器,通常需要三层:模型 API、浏览器执行环境、Agent 调度框架。下面用一个最小示例展示如何把它们串起来,便于你在本地或服务器上跑通第一个 Demo。
# pip install browser-use openai
from browser_use import Agent
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1" # 通过 API易统一调用 GPT-5.5
)
agent = Agent(
task="打开 apiyi.com 并截图首页价格表",
llm=client,
model="gpt-5.5",
reasoning_effort="medium",
allowed_domains=["apiyi.com"], # 限定可访问域名,提升安全性
)
result = agent.run()
print(result.final_screenshot_path)
🎯 快速上手建议:把
base_url指向https://api.apiyi.com/v1后,你可以直接复用 OpenAI 官方 SDK 调用 GPT-5.5,无需改造已有 Agent 代码。API易 apiyi.com 同时支持缓存计费 0.1x,重复使用的系统提示、工具描述只按 10% 计费,对长跑 Agent 极度友好。
代码里有三个细节值得单独说一下。第一,base_url 切换到 API易后,OpenAI SDK 的所有方法都可以无差别使用,包括 Responses API、Chat Completions API 与 computer use 工具,不需要为切换中转专门维护一份适配代码。第二,reasoning_effort 参数对应 GPT-5.5 的五档推理强度,建议先用 medium 跑通,再按场景下调成本,多数业务能稳定运行在 low → medium 之间。第三,allowed_domains 是 browser-use 库的安全开关,它会在 Playwright 层拦截越界访问,避免 Agent 误入钓鱼站点,是生产环境的"安全带"。
如果你希望让 Agent 跑得更稳,下面这张工程实践清单可以直接照搬到生产环境。
| 实践 | 做法 | 收益 |
|---|---|---|
| 截图分辨率 | image_detail = original 保留 10.24M 像素 |
密集表单识别率提升 |
| 任务拆分 | 浏览交给 GPT-5.5,结构化清洗交给更便宜模型 | 单任务综合成本下降 30%+ |
| 缓存前缀 | 系统提示、工具描述前置,触发缓存计费 0.1x | 重复运行成本下降 60%+ |
| 失败回放 | 保存每步截图与动作 JSON | 便于人工复核与回归 |
| 域名白名单 | allowed_domains + blocked_domains 双向限制 |
防止 Agent 误入风险站点 |
GPT-5.5 browser-use 常见问题
Q1:GPT-5.5 browser-use 和 ChatGPT Agent 是同一件事吗?
不完全是。ChatGPT Agent 是 OpenAI 面向终端用户的产品形态,背后默认使用 GPT-5.x 的 computer use 能力。GPT-5.5 browser-use 则是开发者侧的 API 能力,可以接入自己的 Agent 框架。两者技术底座一致,控制粒度不同。
Q2:要不要继续用 browser-use 开源库?
要。GPT-5.5 提供的是"大脑",而 browser-use(或类似的 Skyvern、Playwright 自研封装)提供的是"手脚"。在自有业务里,开源库还能帮你做 cookies 持久化、并发会话、反爬策略,与 GPT-5.5 是互补关系。
Q3:GPT-5.5 调用浏览器的成本高吗?
逐步骤计费的成本主要来自高分辨率截图。建议在 API易 apiyi.com 上开启缓存计费 0.1x,把系统提示、工具说明、操作手册做成可缓存的前缀,长跑场景能显著降本。配合 reasoning effort 分级,整体单任务成本可压到原来的 30%~40%。
Q4:浏览器 Agent 的安全风险怎么控制?
至少做三件事:在 browser-use 层启用 allowed_domains 和 blocked_domains、在 LLM 层对关键动作(提交、付款、发送)加二次确认、在审计层保存每步截图与动作日志。GPT-5.5 自身也会在高风险动作前主动询问,但你不能完全依赖模型。
Q5:GPT-5.5 适合做完全无人值守的 Agent 吗?
视场景而定。数据采集、UI 回归、内部 SaaS 操作这类"路径可枚举"的任务,已经具备 24/7 无人值守的可行性;涉及金融交易、对外发布、合同签署等高风险动作,仍建议保留"人在回路"。我们建议通过 API易 apiyi.com 的统一日志面板长期观察 Agent 表现,再决定哪些环节可以撤掉人工。
Q6:在中国境内调用 GPT-5.5 browser-use 稳定吗?
直接调用官方接口可能受到网络环境影响。通过 API易 apiyi.com 调用 GPT-5.5 可以解决境内网络抖动问题,平台已稳定运行,长跑 Agent 任务不易中断。
Q7:GPT-5.5 和 Claude Opus 4.7 在 Agent 上怎么选?
两者各有侧重。GPT-5.5 在浏览器原生 computer use(OSWorld 78.7%)上略胜,Claude Opus 4.7 在代码类 SWE-Bench 上更强。理性做法是同时接入两套模型,按任务类型路由。API易 apiyi.com 支持在同一账号下调用主流模型,便于做 AB 评测。
GPT-5.5 browser-use 核心要点
- GPT-5.5 把 computer use 做成原生能力,截图、推理、动作输出在单次前向中完成,链路更短。
- 在 OSWorld-Verified 上拿下 78.7%,Terminal-Bench 2.0 拿下 82.7%,Agent 任务通过率显著提升。
- 高分辨率截图(最高 10.24M 像素)让密集表单、长表格、代码编辑器场景的识别准确率大幅改善。
- 五档 reasoning effort(none → xhigh)允许 Agent 在每一步动作上单独控费,长跑任务更经济。
- 与 browser-use、Playwright 等开源库组合使用,是当前最成熟的"大脑 + 手脚"实践。
- 通过 API易 apiyi.com 调用 GPT-5.5 可以享受缓存计费 0.1x,并解决境内访问的稳定性问题。
- 高风险动作仍建议保留人在回路,GPT-5.5 的能力是把人工占比从 80% 降到 20%,而不是 0%。
总结
GPT-5.5 的 browser-use 能力之所以重要,并不在于它刷新了几个 benchmark,而在于它把"让模型操作浏览器"这件事,从需要拼装多个组件的工程难题,变成了一个开箱即用的原生 API。对于想做 Agent 的团队来说,这意味着可以把更多精力放在场景设计与人机交互上,而不是花在调通截图、解析 DOM、拼接动作的脏活上。换句话说,过去 Agent 团队 70% 的工程量花在浏览器适配,30% 花在业务设计;GPT-5.5 之后,这个比例有机会反过来。
如果你正打算把 Agent 从 Demo 推到生产,建议先在 API易 apiyi.com 上开通 GPT-5.5 调用,配合 browser-use 库跑一个小场景试水。平台已稳定支持 GPT-5.5,缓存计费 0.1x 能把长跑成本压到很低,是当前国内验证浏览器 Agent 想法最顺手的路径之一。
— APIYI 技术团队,更多 AI 模型实战教程见 API易 apiyi.com