Die offizielle Ankündigung von xAI ist soeben eingetroffen: 8 ältere Grok-Modelle werden am 15. Mai 2026 um 12:00 Uhr PT offiziell in den Ruhestand versetzt. Anfragen werden automatisch auf grok-4.3 umgeleitet, wobei jedoch die Preisgestaltung der neuen Modelle gilt. Dieser Artikel erläutert kurz und bündig, welche Auswirkungen dies auf KI-Entwickler und Unternehmenskunden hat.
Kernnutzen: In 3 Minuten alles Wichtige über die Liste der auslaufenden Grok-Modelle, Umleitungsregeln, Kostenänderungen und die notwendige Anpassung Ihres Codes bei der Nutzung von APIYI erfahren.

Grok-Modell-Ruhestand: Die wichtigsten Informationen auf einen Blick
xAI hat in den Migrationsdokumenten einen klaren Zeitplan und den Umfang der Auswirkungen veröffentlicht. Bei diesem Ruhestand handelt es sich nicht um die Bereinigung einiger weniger Nischenmodelle, sondern um eine umfassende Maßnahme, die die wichtigsten Reasoning-, Standard-, Code- und Bilderzeugungsmodelle der letzten sechs Monate betrifft. Für Teams, die in ihrer Produktionsumgebung langfristig auf diese Slugs angewiesen sind, ist der 15. Mai die harte Deadline für die Code-Umstellung.
| Information | Details |
|---|---|
| Datum | 15.05.2026, 12:00 PT |
| Herausgeber | xAI (docs.x.ai) |
| Anzahl der Modelle | 8 |
| Ziel der Umleitung | grok-4.3 / grok-imagine-image-quality |
| Preis neues Modell | $1,25 / 1M Input, $2,50 / 1M Output |
| Kontextfenster | 1.000.000 Token |
| Quelle | docs.x.ai/developers/migration/may-15-retirement |
Detaillierte Liste der auslaufenden Grok-Modelle
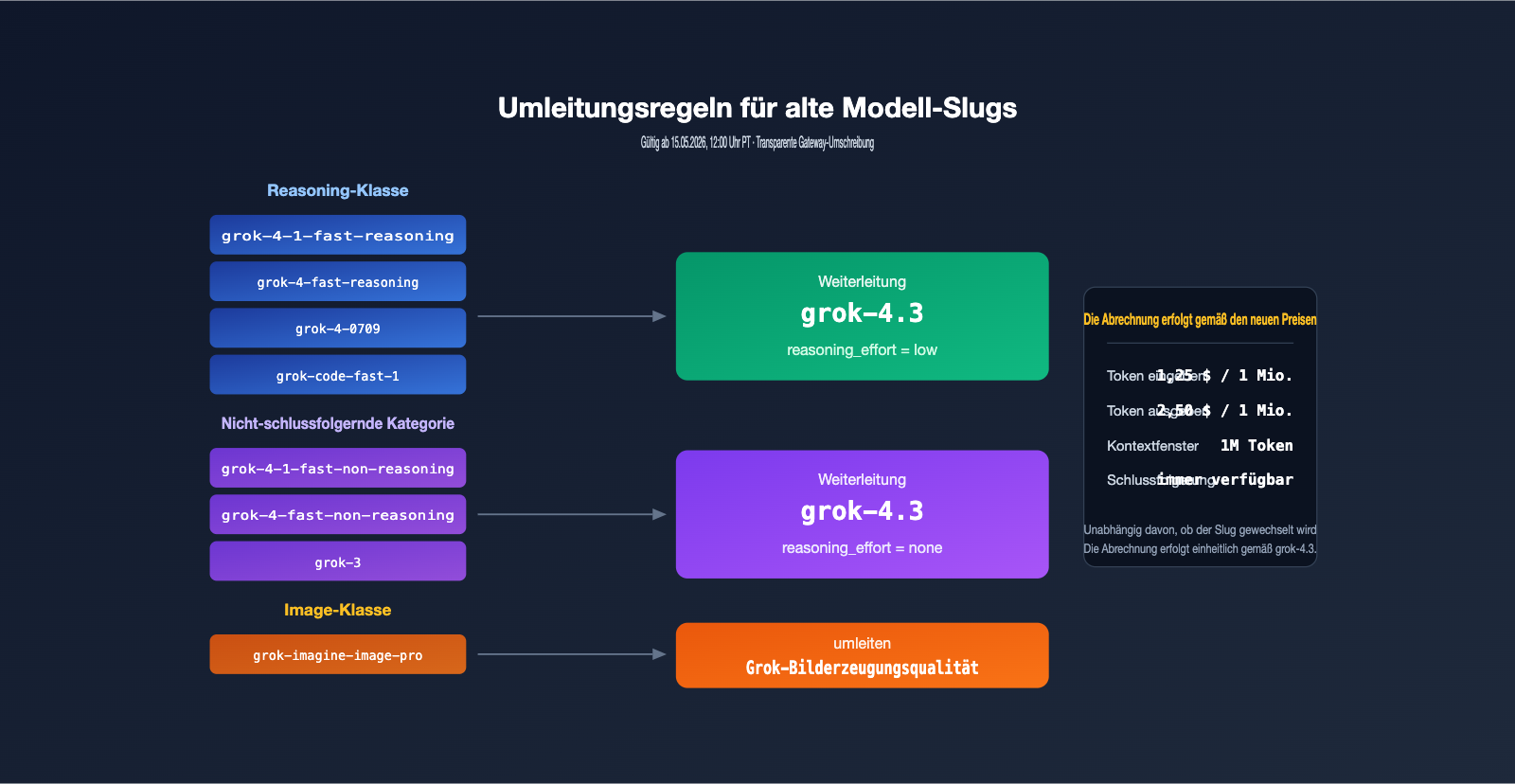
Die 8 Modelle, die in den Ruhestand gehen, decken vier typische Arbeitslasten ab: Die fast-reasoning-Serie (einschließlich grok-4-1-fast-reasoning, grok-4-fast-reasoning) für hohen Durchsatz; die fast-non-reasoning-Serie (einschließlich grok-4-1-fast-non-reasoning, grok-4-fast-non-reasoning) für geringe Latenz; grok-4-0709 und grok-3 als frühere Flaggschiff-Modelle; sowie grok-code-fast-1 und grok-imagine-image-pro für Code- und Bilderzeugung.
| Modell-Slug | Kategorie | Typische Anwendung | Umleitungsziel |
|---|---|---|---|
| grok-4-1-fast-reasoning | Reasoning | Hoher Durchsatz | grok-4.3 (low effort) |
| grok-4-1-fast-non-reasoning | Non-Reasoning | Geringe Latenz | grok-4.3 (none effort) |
| grok-4-fast-reasoning | Reasoning | Schnelles Reasoning | grok-4.3 (low effort) |
| grok-4-fast-non-reasoning | Non-Reasoning | Echtzeit-Dialog | grok-4.3 (none effort) |
| grok-4-0709 | Reasoning | Flaggschiff | grok-4.3 (low effort) |
| grok-code-fast-1 | Coding | Intelligente Codierung | grok-4.3 (low effort) |
| grok-3 | Non-Reasoning | Produktion | grok-4.3 (none effort) |
| grok-imagine-image-pro | Bild | Hochwertige Bilder | grok-imagine-image-quality |
Laut offizieller Dokumentation werden alle Reasoning-Modelle durch grok-4.3 mit "low reasoning effort" bedient, während alle Non-Reasoning-Modelle auf "none effort" umgestellt werden, um sicherzustellen, dass die Latenz so nah wie möglich am ursprünglichen Modell bleibt. Anfragen zur Bilderzeugung werden vollständig auf grok-imagine-image-quality umgestellt.
Analyse der Umleitungsregeln für die Außerbetriebnahme des Grok-Modells
Nach dem 15. Mai, 12:00 Uhr PT, führen alte Slugs nicht sofort zu einem 404-Fehler. Stattdessen werden sie vom Gateway transparent auf grok-4.3 umgeleitet. Dieser „sanfte Übergang“ ist zwar sehr benutzerfreundlich für die Kompatibilität, birgt jedoch eine potenzielle Kostenfalle: Viele Teams gehen davon aus, dass „eine erfolgreiche Anfrage“ bedeutet, dass alles in Ordnung ist, nur um dann bei der monatlichen Abrechnung festzustellen, dass die Stückpreise unbemerkt gestiegen sind.
Änderungen im Reasoning-Verhalten bei der Außerbetriebnahme des Grok-Modells
Der größte Unterschied zwischen grok-4.3 und der alten fast-reasoning-Serie liegt im „Always-on Reasoning“-Design. grok-4.3 macht das Schlussfolgern (Chain-of-Thought) vom optionalen Schalter zum Standardverhalten des Modells. Entwickler können zwischen den Stufen low, medium und high für die Intensität wählen, eine Option zum vollständigen Deaktivieren gibt es nicht. Die alten fast-non-reasoning-Modelle übersprangen den Schlussfolgerungsprozess direkt; die umgeleitete none-Einstellung sorgt zwar dafür, dass grok-4.3 das ursprüngliche „Direktantwort“-Erlebnis simuliert, verbraucht in der tatsächlichen Kette jedoch weiterhin eine geringe Menge an internen Reasoning-Tokens.
Es ist wichtig zu beachten, dass xAI diesmal keinen „Kompatibilitätsmodus-Parameter“ auf SDK-Ebene bereitgestellt hat. Das bedeutet, dass Code, in dem model="grok-4-fast-reasoning" fest kodiert ist, zwar weiterhin funktioniert, aber die Intensität des Schlussfolgerns nicht präzise gesteuert werden kann. Wenn Ihr Unternehmen empfindlich auf Latenz und Konsistenz reagiert, müssen Sie das Feld reasoning_effort explizit übergeben, da Sie sonst nur die Standardeinstellung erhalten und das Verhalten des alten Modells nicht reproduzieren können.
Für Echtzeitanwendungen, die auf maximale Reaktionsgeschwindigkeit angewiesen sind, empfehlen wir, die Latenzunterschiede der beiden effort-Stufen über den API-Proxy-Dienst APIYI (apiyi.com) zu testen, bevor Sie entscheiden, ob Sie das Prompt-Design auf Ihrer Seite anpassen. Nach der Umstellung auf eine einheitliche Schnittstelle können Sie mit demselben Code schnell den Durchsatz und die Latenz bis zum ersten Zeichen (Time to First Token) bei verschiedenen reasoning effort-Stufen vergleichen, ohne zusätzliche Parameter ändern zu müssen.
Änderungen bei den Bildmodellen nach der Außerbetriebnahme von Grok
grok-imagine-image-pro war das von xAI in den letzten sechs Monaten bevorzugte Modell für die Bilderzeugung, das vor allem auf hochauflösende Ergebnisse ausgelegt war. Mit der Umstellung auf grok-imagine-image-quality gibt es bei dem neuen Modell weitere Optimierungen hinsichtlich Bilddetails und der Einhaltung der Eingabeaufforderung, allerdings haben sich auch die Kosten pro Bild und die Latenzeigenschaften geändert.
🎯 Migrationshinweis: Wir empfehlen Projekten, die derzeit grok-imagine-image-pro verwenden, umgehend eine Regressionstest-Runde in einer Sandbox-Umgebung mit den gängigen Eingabeaufforderungen durchzuführen. Vergleichen Sie die Bildunterschiede, die Generierungsgeschwindigkeit und die Kosten pro Bild zwischen dem neuen und dem alten Modell, um zu vermeiden, dass Ihre Anwendung direkt und ungeplant umgestellt wird.
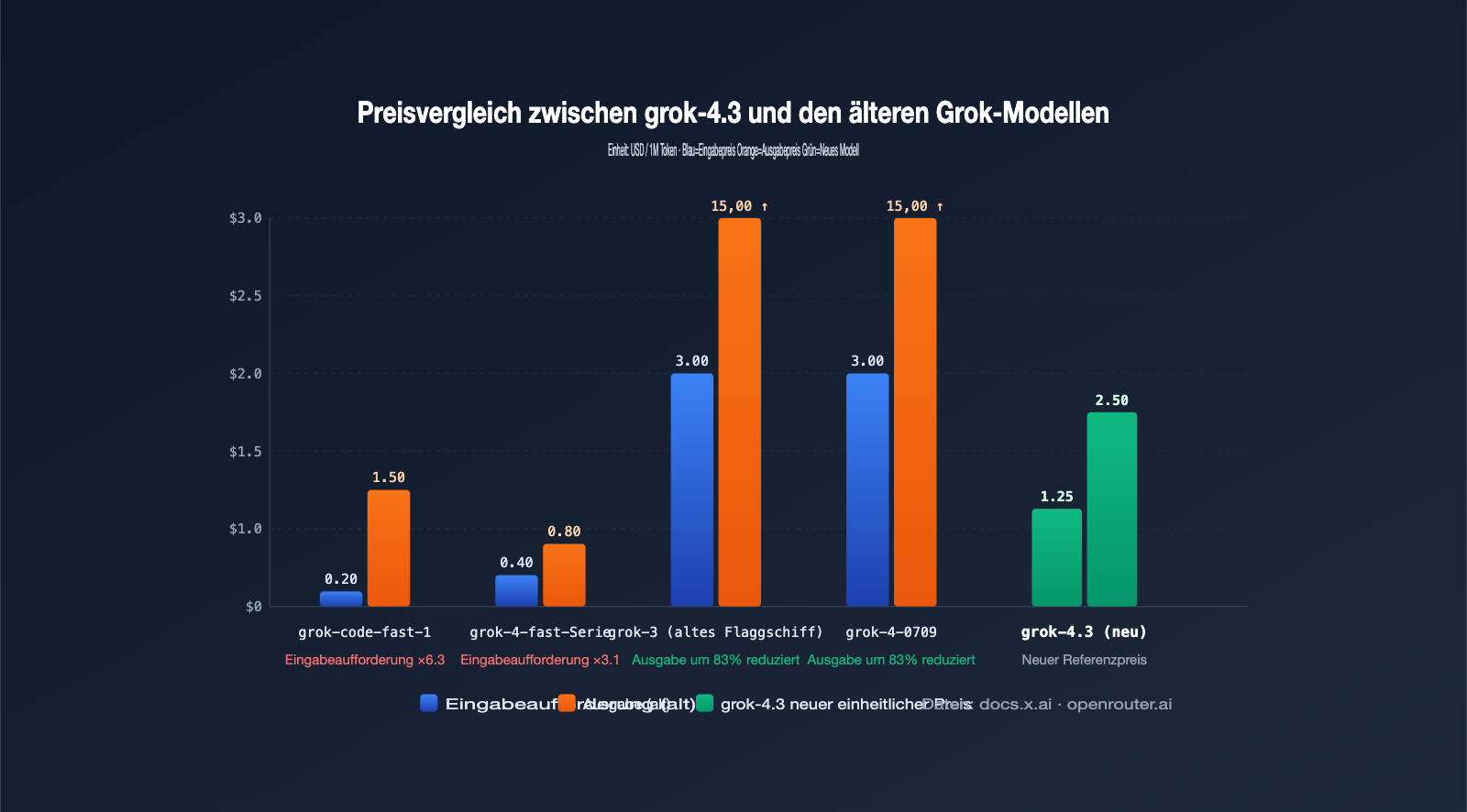
Die Kostenentwicklung ist ein entscheidender, aber oft unterschätzter Aspekt der aktuellen Ankündigung zur Außerbetriebnahme. Der Einheitspreis von grok-4.3 liegt bei 1,25 $ pro 1 Mio. Eingabe-Token und 2,50 $ pro 1 Mio. Ausgabe-Token. Für Teams, die bereits grok-4-0709 oder grok-3 nutzen, ist dies kaum spürbar. Für Projekte, die jedoch auf die günstigen Varianten wie fast-reasoning, fast-non-reasoning und grok-code-fast-1 angewiesen waren, bedeutet dies einen deutlichen Preisanstieg.
5 wichtige Kostenänderungen durch die Grok-Modell-Außerbetriebnahme
Die folgende Tabelle fasst die 5 kritischsten Kostenpunkte zusammen, auf die Entwickler nach dem 15. Mai stoßen werden. Wir empfehlen einen Abgleich vor der Migration.
| Kostenfaktor | Verhalten altes Modell | Verhalten grok-4.3 | Risikostufe |
|---|---|---|---|
| Eingabepreis | fast-Serie meist < 0,5 $/1M | Einheitlich 1,25 $/1M | Hoch |
| Ausgabepreis | grok-code-fast-1 nur 1,50 $/1M | Einheitlich 2,50 $/1M | Hoch |
| Reasoning-Token | Bei manchen Modellen nicht berechnet | Reasoning-Token werden zum Ausgabepreis abgerechnet | Mittel |
| Kontextfenster | 256K~512K | 1M volle Abrechnung | Mittel |
| Cache & Tool-Aufrufe | Unterschiedliche Preismodelle | 0,20 $/1M Prompt-Cache + Tool-Aufrufe pro Nutzung | Niedrig |
Besonders wichtig: grok-4.3 ist standardmäßig auf always-on reasoning eingestellt. Selbst bei der Einstellung low effort verbraucht jede Anfrage mehr Reasoning-Token als das alte fast-non-reasoning-Modell. Da diese nach dem Ausgabepreis abgerechnet werden, ist dies der am leichtesten zu übersehende „versteckte Preisanstieg“ auf der monatlichen Abrechnung. In internen Tests haben wir beobachtet, dass bei identischen kurzen Prompt-Anfragen nach dem Wechsel auf grok-4.3 (low effort) die Anzahl der Ausgabe-Token um 20 % bis 35 % steigt. Das bedeutet: Selbst bei gleichbleibenden Stückpreisen klettert die monatliche Rechnung nach oben.
Ein Beispiel: Ein typischer Kundenservice-Agent mit 1 Million Aufrufen pro Tag (800 Eingabe- + 400 Ausgabe-Token) kostete mit grok-4-fast-non-reasoning etwa 4.000 $ pro Monat. Bei gleicher Last unter grok-4.3 steigen die Kosten allein durch die offiziellen Preise auf ca. 13.500 $. Zusammen mit dem Mehrverbrauch an Reasoning-Token nähert sich die Rechnung 17.000 $. Diese Größenordnung erfordert eine formelle Budgetprüfung durch die Finanzabteilung vor dem 15. Mai.
Ein weiterer unterschätzter Kostenfaktor ist die Anpassung der Prompts. Das Reasoning-Verhalten von grok-4.3 neigt dazu, „schrittweise zu schlussfolgern, bevor eine Antwort gegeben wird“. Prompt-Vorlagen, die für grok-3 optimiert waren, führen nun oft zu „langatmigen Ausgaben ohne Fazit am Anfang“. Um den alten Stil („direkte Antwort + kurzes Fazit“) wiederherzustellen, muss entweder die Ausgabestruktur per System-Prompt erzwungen oder der reasoning effort auf none gesetzt werden. Beides erfordert zusätzlichen Zeitaufwand für Regressionstests und die Iteration der Prompt-Bibliothek.
💰 Kostenkontrolle: Wir empfehlen, während der Migrationsphase das Anfrage-Log-Dashboard von APIYI (apiyi.com) zu nutzen, um den Token-Verbrauch nach Modell-Slug zu analysieren. So lässt sich je nach Szenario entscheiden, ob ein Wechsel auf medium effort zur Qualitätssteigerung oder none effort zur Kostenkontrolle sinnvoll ist.
Analyse der Auswirkungen der Grok-Modell-Stilllegung
Auswirkungen auf Entwickler
Die massenhafte Stilllegung betrifft vor allem Nutzer von grok-code-fast-1 am stärksten, da dieses Modell bisher mit einem Preis von 0,20 $ / 1,50 $ und einem Score von 80,0 % auf dem LiveCodeBench ein exzellentes Preis-Leistungs-Verhältnis bot. Mit dem Wechsel auf grok-4.3 verdoppelt sich der Stückpreis direkt. Teams müssen nun ihre Kostenbudgets für häufige Aufgaben wie Code-Vervollständigung, PR-Reviews und Agenten-Orchestrierung neu bewerten. Die bisher bewährte Kombination aus „Inline-Vervollständigung + Abruf langer Kontexte“ muss möglicherweise in mehrere Schritte unterteilt werden, um den Token-Verbrauch zu kontrollieren.
Für Nutzer von Agenten-Frameworks, die sich auf die fast-Serie für Entscheidungen bei Tool-Aufrufen verlassen haben, ändert sich ebenfalls einiges. grok-4.3 bietet zwar stärkere Fähigkeiten bei Tool-Aufrufen, weist jedoch eine etwas höhere Latenz bis zum ersten Zeichen (Time-to-First-Token) auf. Entwickler sollten daher Timeouts, Wiederholungsversuche (Retries) und Parallelitätsparameter neu optimieren. Wir empfehlen, zunächst in der Staging-Umgebung von APIYI (apiyi.com) Regressionstests durchzuführen, um sicherzustellen, dass Erfolgsraten und Latenzverteilungen im akzeptablen Bereich liegen, bevor die vollständige Umstellung erfolgt.
Auswirkungen auf Unternehmenskunden
Für Unternehmenskunden stehen Service Level Agreements (SLA) und Compliance im Vordergrund. Das Upgrade auf grok-4.3 deckt alle Szenarien der bisherigen acht Modelle ab und vereinfacht die Modellauswahl. Dies ist für die Unternehmensführung (Modell-Registry, Auditierung, Sicherheits-Compliance) durchaus positiv. Finanzabteilungen müssen jedoch bestehende Budgets und Rabattregeln überprüfen – insbesondere monatliche Token-Pakete und Commit-Rabattvereinbarungen könnten durch die vereinheitlichte Preisgestaltung hinfällig werden. Auch die IT-Betriebsteams sollten ihre Alarm-Schwellenwerte aktualisieren, um unerwartete Kostensteigerungen bei der Mai-Abrechnung ohne Vorwarnung zu vermeiden.
Für Szenarien mit modellübergreifenden Aufrufen empfehlen wir, Grok, Claude, GPT und andere Modelle in einer einheitlichen Kostenübersicht zu aggregieren. Durch eine Zuordnung nach Abteilungen oder Geschäftsbereichen lassen sich die Auswirkungen häufiger Modell-Iterationen auf das Budget besser abfedern. Die aktuelle Stilllegung erinnert Unternehmen zudem daran, dass das Risiko einer Anbieterbindung nicht nur in Lieferausfällen besteht, sondern auch in den versteckten Kosten, die entstehen, wenn „hinter demselben Slug heimlich die Engine ausgetauscht wird“.
Auswirkungen auf die Branche
Dass xAI gleich acht Modelle auf einmal in den Ruhestand schickt, signalisiert, dass die Kombination aus „Always-on Reasoning + 1M Kontext“ bei grok-4.3 als universell genug angesehen wird, um Schlussfolgerungen, Dialoge, Code-Generierung und Tool-Aufrufe gleichermaßen zu bewältigen. Dies entspricht dem Trend von Claude und OpenAI, „Reasoning-Modelle“ und „Instruct-Modelle“ schrittweise zu vereinheitlichen. Dies zeigt, dass die Kommerzialisierung von Großem Sprachmodell in eine Phase eintritt, in der ein „einzelnes Flaggschiff alles abdeckt“. Die Modellmatrix für Entwickler wird schlanker, während die Leistungsgrenzen und die Preiselastizität einzelner Modelle zunehmen.
Ein weiterer Trend ist, dass „Reasoning standardmäßig aktiviert + Effort-Stufen“ zum neuen Industriestandard werden. Dieses Design überlässt die Abwägung zwischen Latenz und Kosten den Entwicklern, setzt jedoch voraus, dass SDKs und Monitoring-Plattformen das effort-Feld nativ unterstützen. Für API-Proxy-Dienste und Aggregationsplattformen wird das Lifecycle-Management von Modellen zu einer neuen Kernkompetenz. APIYI (apiyi.com) hat die Migrationsdokumentation für Grok bereits in der Konsole aktualisiert und Benachrichtigungen für betroffene Slugs versendet, um Entwicklern den Übergang zu erleichtern.
APIYI: Hinweise zur Synchronisierung der Stilllegung
Um mit der offiziellen Strategie von xAI konform zu gehen und Abrechnungsfehler zu vermeiden, hat APIYI (apiyi.com) einen Stilllegungsplan erstellt, der einen reibungslosen Übergang für Nutzer bietet, die noch alte Slugs verwenden. Die Konsole erstellt eine Statistik über die Anzahl der Aufrufe und den Kostenanteil jedes stillgelegten Slugs der letzten 30 Tage, damit Teamleiter vor der Migration einen klaren Überblick über die betroffenen Geschäftsmodule erhalten.
| Phase | Zeitraum | APIYI-Aktion |
|---|---|---|
| Warnphase | Vor dem 15.05.2026 | Banner-Hinweis in der Konsole, E-Mail an betroffene Konten |
| Umleitungsphase | Ab 15.05.2026, 12:00 PT | Alte Slugs werden automatisch auf grok-4.3 umgeleitet; Antwort-Header markiert als deprecated |
| Vollständige Stilllegung | Gemäß xAI-Zeitplan | Entfernung der alten Slugs aus der Konsole |
Entwickler müssen die base_url nicht ändern; es reicht aus, das Feld model in den Anfrageparametern auf grok-4.3 zu aktualisieren. Falls in Ihrer Anwendung sowohl Reasoning- als auch Non-Reasoning-Aufrufe existieren, empfehlen wir, im SDK-Wrapper eine effort-Konfigurationsoption hinzuzufügen, um bei Lasttests und A/B-Experimenten eine einheitliche Steuerung zu ermöglichen. Ein vollständiges Beispiel für den Aufruf finden Sie hier:
import openai
# Initialisierung des Clients mit APIYI-Konfiguration
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="grok-4.3",
messages=[
{"role": "user", "content": "Erkläre 'always-on reasoning' in 200 Wörtern"}
],
extra_body={"reasoning_effort": "low"}
)
print(response.choices[0].message.content)
Node.js / TypeScript Version anzeigen
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.APIYI_KEY,
baseURL: "https://api.apiyi.com/v1",
});
const completion = await client.chat.completions.create({
model: "grok-4.3",
messages: [{ role: "user", content: "Fasse die wichtigsten Punkte zur Migration auf grok-4.3 zusammen" }],
// @ts-expect-error xAI extra Feld
reasoning_effort: "low",
});
console.log(completion.choices[0].message.content);
🚀 Migrationsempfehlung: Wir empfehlen, vor der Migration über das „Modellvergleich“-Panel von APIYI (apiyi.com) dieselbe Eingabeaufforderung sowohl an
grok-4.3als auch an das bisherige Modell zu senden. Vergleichen Sie die Antwortqualität und die Latenz bis zum ersten Zeichen, um die optimale Einstellung für denreasoning effortzu bestimmen.
Häufig gestellte Fragen
Q1: Können alte Slugs nach dem 15. Mai weiterhin für Modellaufrufe verwendet werden?
Ja, aber das tatsächlich ausgeführte Modell ist grok-4.3, und die Abrechnung erfolgt zu den neuen Preisen von grok-4.3 ($1,25/$2,50). Es wird empfohlen, das Feld model im Code so schnell wie möglich auf grok-4.3 zu aktualisieren, um unerwartete Erhöhungen der monatlichen Abrechnung zu vermeiden.
Q2: Ist grok-code-fast-1 nach der Migration weiterhin für die Code-Vervollständigung geeignet?
grok-4.3 erzielt in LiveCodeBench und SWE-bench bessere Ergebnisse als grok-code-fast-1 und bietet insgesamt stärkere Programmierfähigkeiten, weist jedoch eine höhere Latenz und einen höheren Einzelpreis auf. Es wird empfohlen, die P95-Latenz und den durchschnittlichen Token-Verbrauch pro PR anhand realer Geschäftsbeispiele zu testen, bevor entschieden wird, ob es weiterhin für die Inline-Code-Vervollständigung geeignet ist.
Q3: Muss ich für die APIYI-Plattform einen neuen API-Schlüssel beantragen?
Nein, der bestehende APIYI-Schlüssel ist direkt mit neuen Modellen wie grok-4.3 kompatibel und die base_url bleibt unverändert. Sie müssen lediglich den Modellnamen im Request-Body anpassen. Die vollständige Modellliste und deren Status können im APIYI-Dashboard unter apiyi.com eingesehen werden.
Q4: Was muss bei der Migration des Bilderzeugungsmodells grok-imagine-image-pro beachtet werden?
Anfragen werden auf grok-imagine-image-quality umgeleitet; Bildstil, Sampling-Seed und Standardparameter unterscheiden sich. Wir empfehlen, historische Eingabeaufforderungen zunächst in einer Sandbox-Umgebung zu testen, um die Stabilität der Ergebnisse sicherzustellen, bevor sie produktiv geschaltet werden, um plötzliche Änderungen bei der Bilderzeugung in Ihrer Anwendung zu vermeiden.
Zusammenfassung
xAI nimmt acht Hauptmodelle, darunter fast-reasoning, fast-non-reasoning, grok-code-fast-1, grok-3 und grok-imagine-image-pro, aus dem Betrieb und stellt ab dem 15. Mai, 12:00 Uhr PT, einheitlich auf grok-4.3 und grok-imagine-image-quality um. Der technische Aufwand für die Migration ist gering, doch die Änderungen bei den Einzelpreisen und der Abrechnung der Reasoning-Token haben erhebliche Auswirkungen auf kostenintensive Anwendungen. Wir empfehlen, drei Schritte priorisiert durchzuführen: Aktualisierung des model-Feldes im Produktionscode auf grok-4.3, explizite Übergabe von reasoning_effort zur Steuerung von Latenz und Kosten sowie eine End-to-End-Kostenkalkulation mit realen Geschäftsdaten.
Unser Rat: Nutzen Sie dieses Modell-Upgrade als Gelegenheit zur Optimierung. Vergleichen Sie auf APIYI (apiyi.com) Latenz und Kosten verschiedener Modelle wie grok-4.3, Claude und GPT. Stellen Sie Ihre Modellauswahl von „dem Rhythmus des Anbieters folgen“ auf „ausrichtung an Geschäftskennzahlen“ um. Langfristig ist dies stabiler und ermöglicht es Ihnen, bei zukünftigen Ankündigungen zur Außerbetriebnahme von Modellen die Umstellungskosten auf wenige Stunden zu begrenzen.
Autor: APIYI Team — APIYI apiyi.com, der API-Proxy-Dienst für Großes Sprachmodell auf Unternehmensebene, unterstützt die einheitliche Anbindung gängiger Modelle wie Grok, Claude, GPT und Gemini.