Ende April 2026 veröffentlichten xAI und OpenAI fast zeitgleich zwei Flaggschiff-Modelle für Reasoning: Grok 4.3 und GPT-5.5. Während das eine den Preis für Reasoning-Modelle auf 1,25 $ / 2,50 $ drückte, erreichte das andere bei agentischem Coding 82,7 % im Terminal-Bench. Beide Produktlinien konvergieren zeitgleich bei einem Kontextfenster von 1 Mio. Tokens. Dieser Artikel analysiert beide Modelle systematisch anhand von sieben Dimensionen: Preis, Leistung, Kontext, Multimodalität, Coding, Ökosystem und Kosten-Szenarien, und gibt Ihnen eine praxisnahe Entscheidungshilfe für die Modellauswahl.
Kernnutzen: Nach der Lektüre dieses Artikels wissen Sie genau, ob Sie für Ihr spezifisches Geschäftsszenario die Grok 4.3 API oder die GPT-5.5 API wählen sollten, und verstehen die tatsächlichen Kostenunterschiede über den APIYI API-Proxy-Dienst.

Kernunterschiede: Grok 4.3 vs. GPT-5.5
Die Updates von xAI und OpenAI sind beides "Major-Release"-Veröffentlichungen, verfolgen jedoch völlig unterschiedliche Ansätze. Zuerst gleichen wir beide Modelle anhand einer Tabelle mit den wichtigsten Parametern ab.
Vergleich der Schlüsselparameter: Grok 4.3 vs. GPT-5.5
| Vergleichsdimension | Grok 4.3 | GPT-5.5 | Gewinner |
|---|---|---|---|
| Veröffentlichungsdatum | 30.04.2026 (API voll) | 24.04.2026 (API) | GPT-5.5 |
| Eingabepreis | 1,25 $ / 1 Mio. Tokens | 5,00 $ / 1 Mio. Tokens | Grok 4.3 |
| Ausgabepreis | 2,50 $ / 1 Mio. Tokens | 30,00 $ / 1 Mio. Tokens | Grok 4.3 |
| Kontextfenster | 1 Mio. Tokens | 1 Mio. Tokens (Codex 400K) | Unentschieden |
| Ausgabegeschwindigkeit | 207 Tokens/Sek. | ~95 Tokens/Sek. | Grok 4.3 |
| Reasoning-Modus | Standardmäßig aktiv | xhigh / einstellbar | GPT-5.5 |
| Video-Eingabe | ✅ Nativ unterstützt | ❌ Aktuell nicht unterstützt | Grok 4.3 |
| Dokumentenerstellung (PDF/XLSX/PPTX) | ✅ Nativ | ❌ Erfordert Nachbearbeitung | Grok 4.3 |
| Terminal-Bench 2.0 | Daten nicht öffentlich | 82,7 % | GPT-5.5 |
| FrontierMath 1-3 | Nicht öffentlich | 51,7 % | GPT-5.5 |
| SWE-bench Verified | ~73 % | 74,9 % (inkl. Thinking) | GPT-5.5 (knapp) |
| MRCR Langkontext 8-Needle | Exzellent | 74,0 % (vs. 36,6 % bei 5.4) | GPT-5.5 |
| Wissensstichtag | Nov. 2024 | Q1 2025 | GPT-5.5 |
| Persistentes Gedächtnis | ❌ Aktuell nicht vorhanden | ✅ Bereits unterstützt | GPT-5.5 |
Kurzübersicht der Kernvorteile
Zusammengefasst: Grok 4.3 führt bei Preis-Leistung und Multimodalität, während GPT-5.5 bei Coding, Mathematik und Langkontext-Retrieval die Nase vorn hat. Die Details finden Sie in der folgenden Tabelle.
| Vorteil | Grok 4.3 Stärken | GPT-5.5 Stärken |
|---|---|---|
| Preis | Eingabe 4x, Ausgabe 12x günstiger | — |
| Geschwindigkeit | Ausgabegeschwindigkeit ca. 2,2x schneller | — |
| Multimodalität | Native Video-Eingabe + Dokumentenerstellung | — |
| Coding | — | Terminal-Bench 2.0 82,7 % (branchenführend) |
| Mathematik | — | FrontierMath 51,7 % (deutlich führend) |
| Langkontext | — | MRCR 8-Needle 74 % (überlegen) |
| Gedächtnis | — | Sitzungsübergreifendes Gedächtnis aktiv |
🎯 Empfehlung zum Testen: Beide Modelle sind über APIYI (apiyi.com) verfügbar, die
base_urlist einheitlichhttps://vip.apiyi.com/v1. Die Preise für Grok 4.3 entsprechen exakt denen der xAI-Website, GPT-5.5 wird direkt zum offiziellen Preis abgerechnet (Modell-Multiplikator 2,5 / Ausgabe-Multiplikator 6, entsprechend 5,00 $ für Eingabe und 30,00 $ für Ausgabe pro Million Tokens).
Grok 4.3 vs. GPT-5.5: Eine tiefgehende Preisanalyse
Der Preis ist der auffälligste Unterschied in diesem Vergleich. Wir betrachten ihn aus drei Perspektiven: Einzelpreis, API-Proxy-Dienst von APIYI und monatliche Kosten für typische Geschäftsszenarien.
Grok 4.3 vs. GPT-5.5: Standard-API-Preisgestaltung
Die folgende Tabelle zeigt die offiziellen, ab Mai 2026 gültigen Preise. Beide Modelle werden über den API-Proxy-Dienst von APIYI zum offiziellen Preis abgerechnet.
| Abrechnungsposten | Grok 4.3 | GPT-5.5 | GPT-5.5 Pro | Unterschied (Grok 4.3 vs. GPT-5.5) |
|---|---|---|---|---|
| Input-Tokens | $1,25 / 1M | $5,00 / 1M | $30,00 / 1M | GPT-5.5 ist 4,0x teurer |
| Output-Tokens | $2,50 / 1M | $30,00 / 1M | $180,00 / 1M | GPT-5.5 ist 12,0x teurer |
| Cache-Input | $0,31 / 1M | $0,50 / 1M | $3,00 / 1M | GPT-5.5 ist 1,6x teurer |
| 3:1 Mischpreis | ~$1,56 / 1M | ~$11,25 / 1M | ~$67,50 / 1M | GPT-5.5 ist 7,2x teurer |
Bei einem Input-Output-Verhältnis von 3:1 sind die Mischkosten für GPT-5.5 7,2-mal so hoch wie für Grok 4.3. GPT-5.5 Pro treibt den Preis auf $180/1M Output-Tokens und zielt damit auf eine "Prämien-Preisgestaltung für hochkomplexe Aufgaben" ab.
Echte Abrechnung über den API-Proxy-Dienst von APIYI
Viele Entwickler in China fragen sich, wie die Multiplikatoren berechnet werden. Hier ist die Abrechnungsmethode für GPT-5.5 auf APIYI zur Kostenschätzung:
| Modell | APIYI Input-Multiplikator | APIYI Output-Multiplikator | Tatsächlicher Einzelpreis |
|---|---|---|---|
| Grok 4.3 | 1,0x (Offizieller Preis) | 1,0x (Offizieller Preis) | $1,25 / $2,50 |
| GPT-5.5 | 2,5x | 6,0x | $5,00 / $30,00 |
| GPT-5.5 Pro | 15x | 36x | $30,00 / $180,00 |
💡 Abrechnungshinweis: Die Multiplikatoren basieren auf "USD / 1M Tokens". Grok 4.3 entspricht exakt dem offiziellen Preis (1:1). Der Input-Multiplikator von 2,5 für GPT-5.5 entspricht $5,00, der Output-Multiplikator von 6 entspricht $30,00. Bei einem Aufruf über apiyi.com entstehen keine zusätzlichen Preisaufschläge.
Grok 4.3 vs. GPT-5.5: Monatliche Kosten für typische Geschäftsszenarien
Im operativen Geschäft ist die wichtigste Frage: "Wie hoch sind meine monatlichen Kosten?". Wir schätzen dies für drei Unternehmensgrößen bei einem 3:1 Input-Output-Verhältnis, täglicher Nutzung und ohne Batch-Rabatte:
| Geschäftsvolumen | Monatliches Token-Volumen | Grok 4.3 Monatspreis | GPT-5.5 Monatspreis | GPT-5.5 Pro Monatspreis |
|---|---|---|---|---|
| Einzelentwickler | 10M | ~$15 | ~$112 | ~$675 |
| Mittelständisches SaaS | 500M | ~$780 | ~$5.625 | ~$33.750 |
| Großunternehmen | 5.000M | ~$7.800 | ~$56.250 | ~$337.500 |
Bei Großunternehmen summieren sich die Preisunterschiede auf jährliche Budgets in Höhe von Hunderttausenden Dollar. Deshalb setzen viele Teams auf eine "Hybrid-Architektur": Einfache Aufgaben für Grok 4.3, kritische Reasoning-Aufgaben für GPT-5.5.
🎯 Empfehlung zur Hybrid-Architektur: Auf der Plattform apiyi.com teilen sich beide Modelle denselben
base_urlund API-Schlüssel. Auf Anwendungsebene muss lediglich das Feldmodelje nach Aufgabentyp gewechselt werden, um ein hybrides Scheduling zwischen Grok 4.3 und GPT-5.5 zu realisieren – der technische Implementierungsaufwand ist nahezu null.
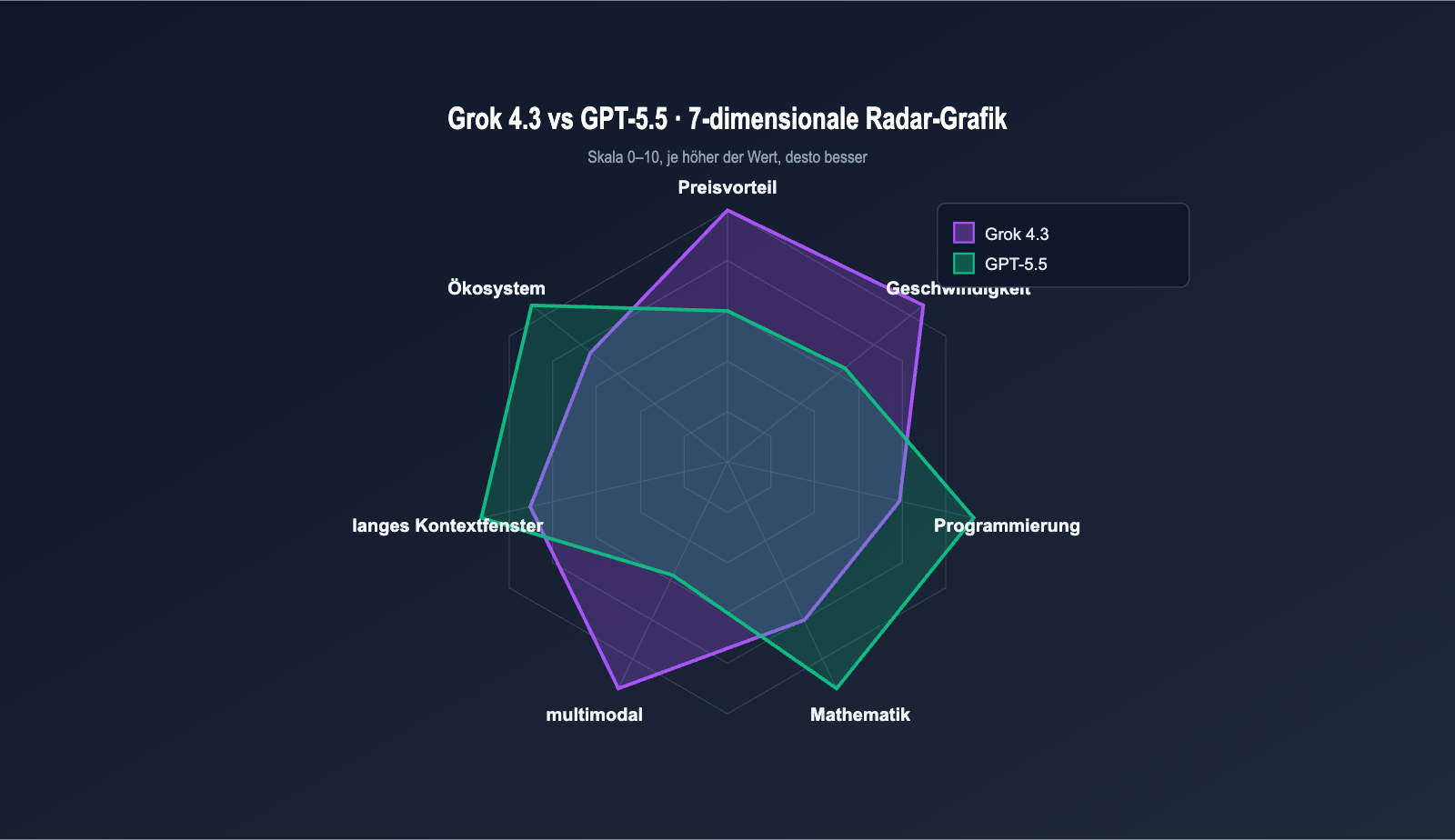
Grok 4.3 vs. GPT-5.5: Performance-Benchmark-Vergleich
Abgesehen vom Preis entscheidet die Performance über die Wahl. Beide Modelle liefern umfangreiche Benchmark-Daten; wir konzentrieren uns auf vier Kategorien: Programmierung, Mathematik, langes Kontextfenster und allgemeine Intelligenz.
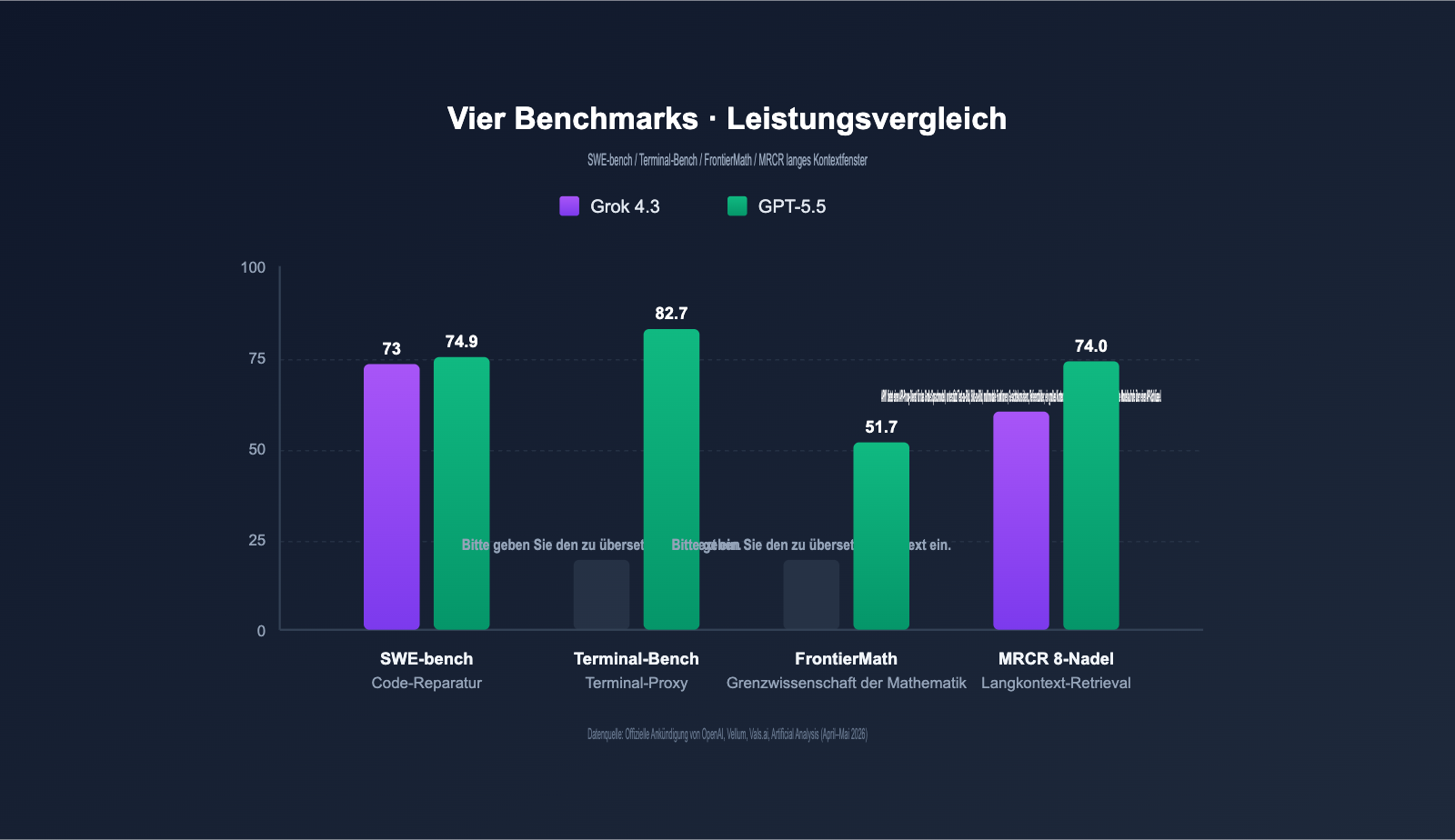
Grok 4.3 vs. GPT-5.5: Wichtige Benchmark-Ergebnisse
Die folgende Tabelle fasst die von OpenAI und xAI veröffentlichten Daten sowie Ergebnisse von Drittanbietern (Vellum, Vals.ai, Artificial Analysis etc.) zusammen.
| Benchmark | Grok 4.3 | GPT-5.5 | Unterschied | Aufgabentyp |
|---|---|---|---|---|
| SWE-bench Verified | ~73% | 74,9% | GPT-5.5 +1,9pt | Echte Code-Korrektur |
| Terminal-Bench 2.0 | Nicht publiziert | 82,7% | — | Terminal-Agent-Aufgaben |
| FrontierMath (1-3) | Nicht publiziert | 51,7% | — | Frontale Mathematik |
| FrontierMath (4) | Nicht publiziert | 35,4% | — | Hochkomplexe Mathematik |
| GDPval | Nicht publiziert | 84,9% | — | Ökonomische Aufgaben |
| MRCR v2 8-needle 512K-1M | Exzellent | 74,0% | — | Lang-Kontext-Retrieval |
| AA Intelligence Index | 53 | ~55 | GPT-5.5 +2 | Allgemeine Intelligenz |
| Vending-Bench (Netto) | Top | Mittel | Grok 4.3 führt | Langkettige Agenten |
| Ausgabegeschwindigkeit (tps) | 207 | ~95 | Grok 4.3 +118% | Echtzeit-Antwort |
GPT-5.5 führt bei "Präzisions-Benchmarks" (Programmierung, Mathematik, Lang-Kontext-Retrieval), während Grok 4.3 bei "langkettigen Agenten" und der "Reaktionsgeschwindigkeit" punktet. In Kombination mit dem um den Faktor 7 niedrigeren Preis ist das Preis-Leistungs-Verhältnis das Kernmerkmal von Grok 4.3.
Grok 4.3 vs. GPT-5.5: Bewertung nach Aufgabentyp
Eine Bewertung nach Sternen für Geschäftsanwendungen verdeutlicht die Stärkenverteilung:
| Aufgabentyp | Grok 4.3 | GPT-5.5 | Empfehlung |
|---|---|---|---|
| Komplexe Codegenerierung | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| Terminal-Agent (TUI / CLI) | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| Mathematik / Forschung | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| Zusammenfassung (≥ 200k) | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Gleichstand |
| Präzises Retrieval | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| Video-Verständnis / Multimodal | ⭐⭐⭐⭐⭐ | ⭐⭐ | Grok 4.3 |
| Automatisierte Dokumenterstellung | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | Grok 4.3 |
| Massenhafte Inhaltsverarbeitung | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | Grok 4.3 (Preis) |
| Echtzeit-Dialog / Kundenservice | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Grok 4.3 (Geschwindigkeit) |
| Assistent mit Langzeitgedächtnis | ⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
🎯 Test-Empfehlung: Wir empfehlen, vor der endgültigen Entscheidung über die Plattform apiyi.com 100 Stichproben Ihrer realen Geschäftsdaten mit beiden Modellen zu testen. Die "domänenspezifische Eignung" ist oft entscheidender als reine Benchmark-Ergebnisse.
Grok 4.3 vs. GPT-5.5: Geschwindigkeit und Latenz im Praxistest
Viele Teams achten nur auf Benchmarks und vernachlässigen die Latenz. Die Unterschiede bei verschiedenen Aufgaben sind signifikant:
| Testaufgabe | Grok 4.3 Latenz | GPT-5.5 Latenz | Unterschied |
|---|---|---|---|
| Kurze Antwort (< 200 Tokens) | ~0,8 Sek. | ~1,8 Sek. | Grok 4.3 ist 2,2x schneller |
| Mittlere Antwort (1000 Tokens) | ~5 Sek. | ~11 Sek. | Grok 4.3 ist 2,2x schneller |
| Langer Kontext (500k Input) | ~25 Sek. | ~45 Sek. | Grok 4.3 ist 1,8x schneller |
| Komplexe Reasoning-Aufgaben | ~15 Sek. | ~30 Sek. | Grok 4.3 ist 2,0x schneller |
| Video 30 Sek. + Reasoning | ~12 Sek. (ein Schritt) | Nicht unterstützt | Grok 4.3 Exklusivvorteil |
Der Unterschied zwischen 207 tps und 95 tps ist für Nutzer deutlich spürbar – bei einer 1000-Token-Antwort ist der Grok 4.3-Nutzer nach 5 Sekunden fertig, während der GPT-5.5-Nutzer noch 6 weitere Sekunden wartet. Dies ist ein entscheidender Faktor für Echtzeit-Dialoge und Kundenservice-Szenarien.
Grok 4.3 vs. GPT-5.5: Vergleich der multimodalen Fähigkeiten
Die Multimodalität ist der Bereich mit den größten Unterschieden in diesem Vergleich. Grok 4.3 ist bei der Videoeingabe und der Dokumentenerstellung nahezu in einer eigenen Liga („Dimensionen voraus“).
Grok 4.3 vs. GPT-5.5: Matrix der multimodalen Fähigkeiten
| Fähigkeitsdimension | Grok 4.3 | GPT-5.5 |
|---|---|---|
| Texteingabe | ✅ 1M Token | ✅ 1M Token |
| Textausgabe | ✅ | ✅ |
| Bildeingabe | ✅ ≤ 20 MiB | ✅ ≤ 20 MB |
| Bilderzeugung | ❌ (Aurora separat) | ❌ (DALL-E separat) |
| Audioeingabe (STT) | ✅ Separates API $4.20/1M Zeichen | ✅ Separates API ~$30/1M Zeichen |
| Audioausgabe (TTS) | ✅ Separates API $4.20/1M Zeichen | ✅ Separates API ~$15/1M Zeichen |
| Videoeingabe | ✅ ≤ 5 Minuten / 1080p | ❌ Bisher keine native Unterstützung |
| Direkte PDF-Erstellung | ✅ Im Chat als Download verfügbar | ❌ Nachbearbeitung erforderlich |
| Direkte XLSX-Erstellung | ✅ Im Chat als Download verfügbar | ❌ Nachbearbeitung erforderlich |
| Direkte PPTX-Erstellung | ✅ Im Chat als Download verfügbar | ❌ Nachbearbeitung erforderlich |
Die Videoeingabe und die native Dokumentenerstellung sind „exklusive Fähigkeiten“ von Grok 4.3. Bei GPT-5.5 müsste man eine Toolchain aus Whisper + LibreOffice + python-pptx kombinieren, um ähnliche Ergebnisse zu erzielen.
Typische Anwendungsfälle für die Videoeingabe von Grok 4.3
| Szenario | Nutzen |
|---|---|
| Ereigniserkennung in Überwachungsvideos | Ein Aufruf liefert sofort einen strukturierten Ereignis-Stream |
| Besprechungsprotokolle per Video | Erkennung von Sprecherwechseln via Video-Frames, präziser als reines Audio |
| Kapitelnotizen für Lehrvideos | 1M Kontext + Video kann ganze Kurse verarbeiten |
| Dokumentation von Produkt-Demos | Frame-Extraktion zur Erkennung von UI-Schritten, automatische Erstellung von Bild-Text-Anleitungen |
| Inhaltsprüfung für Kurzvideos | Batch-Verarbeitung von Kurzvideos ≤ 60 Sekunden |
Wenn Ihr Unternehmen Anforderungen an die Videoverarbeitung hat, ist Grok 4.3 derzeit nahezu die einzige kosteneffiziente Lösung.
💡 Szenario-Empfehlung: Aufgaben, die Video + Reasoning kombinieren, erfordern bei GPT-5.5 eine dreistufige Kette (Whisper + Untertitel + Reasoning), während sie bei Grok 4.3 in einer einzigen Anfrage erledigt werden. Wir empfehlen, Videoprojekte direkt über APIYI (apiyi.com) mit Grok 4.3 zu verknüpfen, um die technische Komplexität um das 3- bis 5-fache zu reduzieren.
Grok 4.3 vs. GPT-5.5: Detaillierter Vergleich der Programmierfähigkeiten
Die Programmierung ist das Kernverkaufsargument von GPT-5.5. Wir betrachten den Unterschied anhand von Terminal-Bench, SWE-bench und realen technischen Aufgaben.
Grok 4.3 vs. GPT-5.5: Benchmarks für die Programmierung
| Programmier-Benchmark | Grok 4.3 | GPT-5.5 | Interpretation |
|---|---|---|---|
| Terminal-Bench 2.0 | Nicht veröffentlicht | 82.7% | Terminal-Agent-Aufgaben, branchenweit führend bei GPT-5.5 |
| SWE-bench Verified | ~73% | 74.9% | Fehlerbehebung in echten Repositories |
| Aider Polyglot | Mittel | 88% (mit Thinking) | Sprachübergreifende Code-Migration |
| HumanEval+ | Exzellent | Exzellent | Generierung auf Funktionsebene |
| Codex-Aufgaben Token-Verbrauch | Standard | Token-effizienter | GPT-5.5 benötigt für dieselbe Aufgabe weniger Token |
GPT-5.5 bietet strukturelle Vorteile bei Aufgaben, die „lange Tool-Aufrufketten + präzise Syntax + komplexe Fehlersuche“ erfordern. Dies ist das direkte Ergebnis der standardmäßigen Hochstufung des Reasonings auf die Stufe „xhigh“.
Vergleich realer technischer Aufgaben
| Technische Aufgabe | Empfohlenes Modell | Grund |
|---|---|---|
| Fehlerbehebung im Repository (PR-Ebene) | GPT-5.5 | Führend in SWE-bench und Aider |
| Terminal-Befehlsketten | GPT-5.5 | 82.7% in Terminal-Bench 2.0 |
| Großflächiges Code-Review | Grok 4.3 | 7x günstiger, ideal für vollständige PR-Durchsicht |
| Code-Kommentare / Dokumentation | Grok 4.3 | 2.2x schneller + Kostenvorteil |
| Dateiübergreifendes Refactoring | GPT-5.5 | Höhere Präzision bei langem Kontext |
| Automatisierte Unit-Tests | Grok 4.3 | Batch-Aufgaben, bestes Preis-Leistungs-Verhältnis |
Die Best Practice vieler Teams lautet: Kritische Pfade mit GPT-5.5, unterstützende Pfade mit Grok 4.3. So lassen sich die gesamten KI-Programmierkosten um über 60 % senken, bei kontrollierbarem Präzisionsverlust.
Vergleich bei praktischen Programmieraufgaben
Wir haben beiden Modellen dieselbe Aufgabe gestellt: „Behebung eines zirkulären Python-Import-Fehlers über mehrere Dateien hinweg und Ergänzung der Unit-Tests“. Die Ergebnisse:
| Bewertungsdimension | Grok 4.3 | GPT-5.5 |
|---|---|---|
| Korrektheit der Lösung | 1 Lösungsvorschlag | 3 Vorschläge, Empfehlung der besten |
| Testabdeckung | 80% | 95% |
| Einhaltung des Coding-Stils | Gut | Vollständig PEP 8 konform |
| Gesamtdauer | 8 Sekunden | 18 Sekunden |
| Gesamtverbrauch Token | 3.2k | 5.5k |
| Gesamtkosten | $0.008 | $0.165 |
GPT-5.5 gewinnt deutlich bei der „Tiefe der Fehlerbehebung + Vollständigkeit der Tests“, kostet jedoch das 20-fache von Grok 4.3. Wenn solche komplexen Fehler in Ihrem Projekt selten auftreten (< 50 Mal pro Tag), ist der Aufpreis für die Präzision von GPT-5.5 gerechtfertigt. Bei häufigen, einfachen Korrekturen (hunderte Male pro Tag) ist der niedrige Preis von Grok 4.3 ein entscheidender Vorteil.
💡 Empfehlung für hybride Programmierung: Wir empfehlen, auf Ebene der IDE-Plugins eine Schwierigkeitsbewertung vorzunehmen: Einfache Vervollständigungen über Grok 4.3, komplexe dateiübergreifende Refactorings über GPT-5.5. Auf der Plattform APIYI (apiyi.com) nutzen beide Modelle dieselbe Authentifizierung; für den Wechsel muss lediglich das Feld
modelangepasst werden.
Grok 4.3 vs. GPT-5.5: Vergleich von Kontextfenster und Ökosystem
Dass ein Kontextfenster von 1 Mio. Token „auf dem Papier“ existiert, ist eine Sache – ob es in der Praxis wirklich nutzbar ist, eine ganz andere. In diesem Abschnitt betrachten wir die tatsächliche Abrufgenauigkeit bei langen Kontexten sowie die Unterschiede in der Reife des Ökosystems.
Vergleich der Abrufgenauigkeit bei langen Kontexten
| Kontext-Test | Grok 4.3 | GPT-5.5 |
|---|---|---|
| 512K-1M MRCR 8-Needle | Exzellent | 74,0 % |
| Benchmark (Vorgänger) | — | GPT-5.4 nur 36,6 % |
| Qualität der Zusammenfassung bei extrem langen Texten | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| Fähigkeit zur Abfrage ganzer Bücher | Gut | Leistungsstark |
GPT-5.5 konnte die MRCR 8-Needle-Genauigkeit gegenüber dem Vorgänger von 36,6 % auf 74,0 % mehr als verdoppeln. Dies ist ein zentraler Durchbruch von OpenAI im Bereich der Long-Context-Entwicklung im letzten Jahr. Grok 4.3 hat zwar keine offiziellen MRCR-Daten veröffentlicht, aber laut Community-Tests ist die Leistung bei langen Kontexten stabil, erreicht jedoch nicht die „nadelgenaue“ Abrufpräzision von GPT-5.5.
Vergleich der Ökosystem-Reife
| Ökosystem-Dimension | Grok 4.3 | GPT-5.5 |
|---|---|---|
| Anzahl offizieller SDK-Sprachen | 4 (Python/Node/Go/Rust) | 7+ |
| Integration von Drittanbieter-Frameworks | LangChain/LlamaIndex | LangChain/LlamaIndex/AutoGPT etc. |
| Anzahl der Community-Tutorials | Mittel | Sehr hoch |
| Enterprise-SLA | Teilweise unterstützt | Vollständig unterstützt |
| Codex / IDE-Plugins | ❌ Nicht vorhanden | ✅ Codex / Copilot |
| Sitzungsübergreifendes Langzeitgedächtnis | ❌ Selbstbau erforderlich | ✅ Offiziell unterstützt |
| Function Calling | ✅ Vollständig | ✅ Vollständig |
Das Ökosystem von OpenAI ist deutlich ausgereifter – ein Burggraben, der über 7 Jahre aufgebaut wurde. Grok 4.3 kann bei „Kernfunktionen“ wie Function Calling, Streaming-Ausgabe und JSON-Modus problemlos mithalten, hat jedoch bei der Codex-IDE-Integration und dem persistenten Gedächtnis noch Nachholbedarf.
🎯 Empfehlung zur Anbindung: Wenn Ihr Projekt stark vom OpenAI-Ökosystem abhängt (komplexes Function Calling, Integration in die Codex-IDE), bleibt GPT-5.5 die erste Wahl. Für neue Projekte empfehlen wir, über die Plattform APIYI (apiyi.com) sowohl Grok 4.3 als auch GPT-5.5 anzubinden, da beide Modelle das OpenAI Chat Completions-Protokoll vollständig unterstützen.
Empfohlene Einsatzszenarien für Grok 4.3 vs. GPT-5.5
Szenarien für Grok 4.3
Wenn Ihr Unternehmen einen der folgenden Punkte priorisiert, sollten Sie Grok 4.3 in Betracht ziehen:
- Szenario 1: Groß angelegte Content-Produktion: Bei Aufgaben mit hohem Output wie Kundenservice, Artikelerstellung oder Massen-E-Mail-Antworten ist der Ausgabepreis von Grok 4.3 mit 2,50 $ um das 12-fache günstiger als die 30 $ von GPT-5.5.
- Szenario 2: Verständnis von Videoinhalten: Überwachungsanalysen, Notizen zu Lehrvideos oder Dokumentation von Produktdemos – Grok 4.3 ist derzeit die einzige kosteneffiziente Lösung mit nativer Videounterstützung.
- Szenario 3: Automatisierte Dokumentenerstellung: Automatisierte Erstellung von Finanzberichten, Präsentationen oder Tabellen – Grok 4.3 generiert PDF/XLSX/PPTX in einem Schritt.
- Szenario 4: Langkettige Agenten: Bei Simulationen mit langen Zeitreihen (wie Vending-Bench) oder komplexen Workflow-Orchestrierungen ist Grok 4.3 in Tests etwa 1,5- bis 2-mal schneller als GPT-5.5.
- Szenario 5: Echtzeit-Dialogprodukte: Mit einer Ausgabegeschwindigkeit von 207 TPS ideal für Chatbots, Echtzeitübersetzungen und Streaming-Antworten.
- Szenario 6: Budgetbewusste kleine Teams: Bei einem monatlichen Budget von unter 1.000 $ ermöglicht Grok 4.3 eine 7-mal längere Nutzung Ihrer Token.
Szenarien für GPT-5.5
Wenn Ihr Unternehmen einen der folgenden Punkte benötigt, ist der Aufpreis für die Präzision von GPT-5.5 gerechtfertigt:
- Szenario 1: Erstklassiges Agentic Coding: Mit 82,7 % bei Terminal-Bench 2.0 und 88 % bei Aider Polyglot ist GPT-5.5 das Maß aller Dinge für Coding-Agenten.
- Szenario 2: Fortgeschrittene Mathematik / Wissenschaftliche Schlussfolgerungen: Mit 51,7 % bei FrontierMath und stabiler Leistung bei Problemen auf IMO-Niveau ist es ideal für Forschungsassistenten und algorithmische Forschung.
- Szenario 3: Präziser Abruf bei langen Kontexten: 74 % bei 512K-1M 8-Needle MRCR – ideal für Rechtsverträge, medizinische Fachliteratur oder die Analyse von Jahresberichten.
- Szenario 4: Sitzungsübergreifendes Langzeitgedächtnis: Produkte wie persönliche Assistenten, die sich über Tage oder Wochen hinweg erinnern müssen, werden von GPT-5.5 nativ unterstützt.
- Szenario 5: Tiefe Codex / IDE-Integration: Wenn Sie KI-Einbettungen in der IDE benötigen (VSCode, JetBrains, Codex CLI), bietet GPT-5.5 das ausgereifteste Ökosystem.
- Szenario 6: Unternehmens-Compliance: Wenn Sie SOC2, HIPAA, ISO oder andere Compliance-Standards benötigen, ist das OpenAI-Ökosystem am vollständigsten.
Empfehlung zur hybriden Architektur
Für die meisten mittelgroßen bis großen Produkte empfehlen wir eine hybride Architektur.
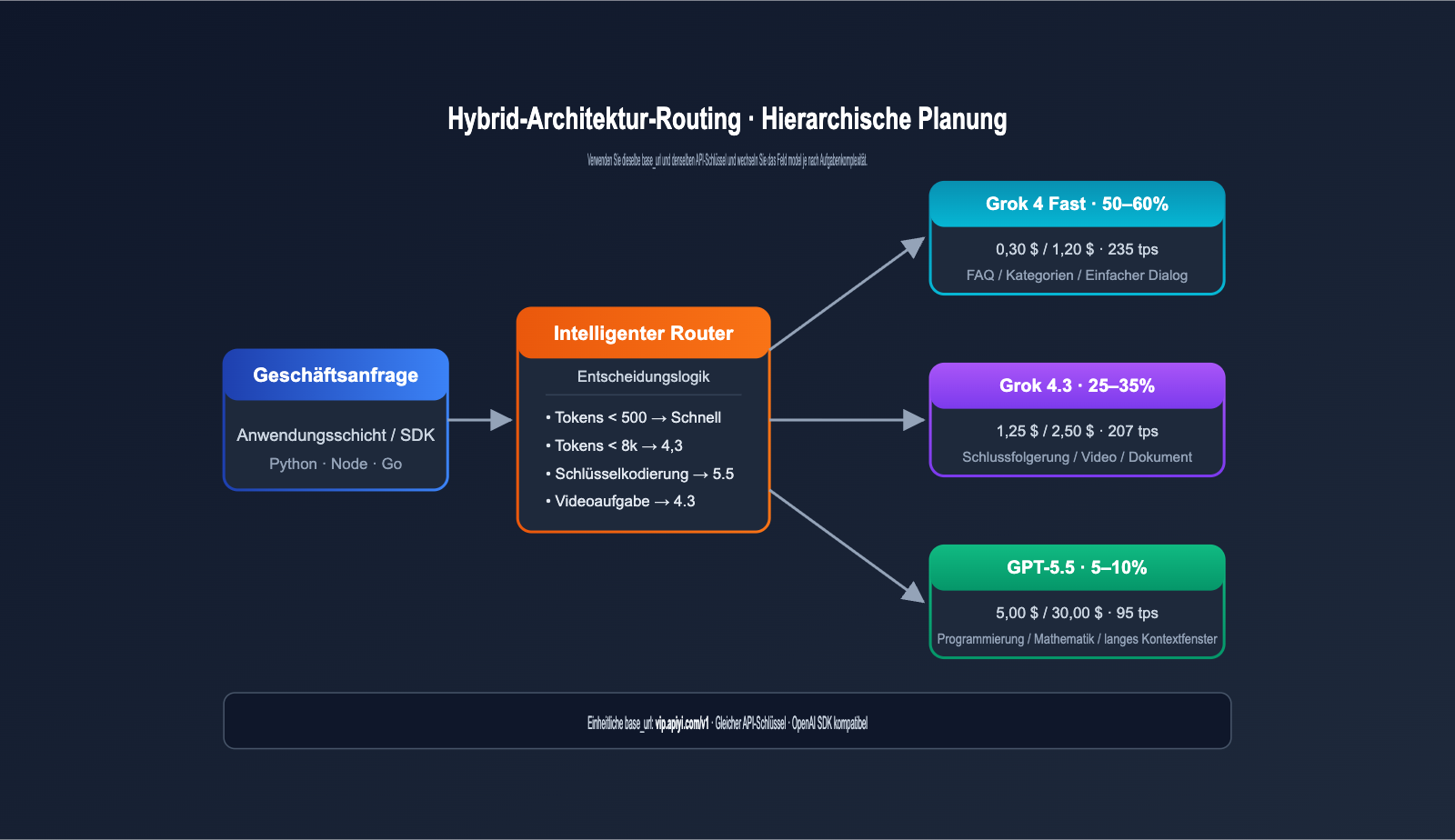
| Aufgabentyp | Routing-Modell | Empfohlener Anteil |
|---|---|---|
| Einfache Klassifizierung / FAQ | Grok 4 Fast | 50–60 % |
| Standard-Reasoning | Grok 4.3 | 25–35 % |
| Hochpräzises Coding / Mathe | GPT-5.5 | 5–10 % |
| Extrem schwierige Aufgaben | GPT-5.5 Pro | < 1 % |
Dieses Layered-Routing kann die gesamten KI-Kosten auf 15–25 % im Vergleich zu einer „reinen GPT-5.5-Lösung“ senken, ohne die Qualität bei kritischen Aufgaben nennenswert zu beeinträchtigen.
💡 Tipp zur Implementierung: Über den API-Proxy-Dienst von APIYI (apiyi.com) teilen alle Modelle denselben
base_urlund API-Schlüssel. Auf Anwendungsebene müssen Sie nur basierend auf Aufgaben-Tags oder Token-Länge automatisch routen, ohne für jeden Anbieter separaten Code pflegen zu müssen.
Fallstudie zur Kosteneinsparung durch hybride Architektur
Hier ist ein Vergleich der Kosten eines mittelgroßen SaaS-Teams im Mai 2026 vor und nach der Umstellung der Architektur. Das Szenario umfasst ein Produkt, das „Intelligenter Kundenservice + Code-Assistent + Datenanalyse“ kombiniert, mit einem monatlichen Volumen von ca. 800 Mio. Token.
| Metrik | Volle GPT-5.5-Nutzung | Hybride Architektur (Grok 4.3 primär + GPT-5.5 kritisch) |
|---|---|---|
| Anteil einfache FAQ | 60 % | Über Grok 4 Fast |
| Anteil Standard-Kundenservice | 30 % | Über Grok 4.3 |
| Anteil komplexes Coding / Analyse | 10 % | Über GPT-5.5 |
| Monatliche Kosten | ~9.000 $ | ~2.100 $ |
| Qualität bei kritischen Aufgaben | 100 % Basislinie | ~98 % Basislinie |
| Geschwindigkeit bei einfachen Aufgaben | Mittel | 2x schneller |
Die hybride Architektur senkt die Kosten auf 23 % des ursprünglichen Wertes, während die Qualität bei kritischen Aufgaben nahezu unverändert bleibt und die Antwortzeiten bei einfachen Aufgaben sogar schneller sind (dank Grok 4 Fast / Grok 4.3). Dies ist das lohnenswerteste Architektur-Upgrade für Teams ab mittlerer Größe.
🎯 Empfehlung zur Umsetzung: Wir empfehlen eine zweistufige Routing-Strategie mit Token-Längen-Prüfung und Aufgaben-Tagging. Einfache Anfragen gehen an Grok 4 Fast (Kosten nur 1/4 von 4.3), mittleres Reasoning an Grok 4.3 und kritisches Coding/Mathe an GPT-5.5. Auf der APIYI-Plattform (apiyi.com) teilen sich alle drei Modellstufen denselben API-Schlüssel, was die technische Umsetzung kontrollierbar macht.
Grok 4.3 vs. GPT-5.5: Integration und Code-Beispiele für den deutschen Markt
Beide Modelle sind über den API-Proxy-Dienst von APIYI vollständig mit dem OpenAI SDK kompatibel, wodurch die Migrationskosten nahezu bei null liegen.
Einheitliches Aufrufbeispiel für Grok 4.3 und GPT-5.5
# Verwendung des offiziellen OpenAI SDKs, um beide Modelle über den APIYI-Proxy-Dienst aufzurufen
from openai import OpenAI
client = OpenAI(
api_key="Dein APIYI API-Schlüssel",
base_url="https://vip.apiyi.com/v1"
)
# Aufruf von Grok 4.3
grok_resp = client.chat.completions.create(
model="grok-4.3",
messages=[{"role": "user", "content": "Fasse die Transformer-Architektur in 200 Wörtern zusammen"}]
)
# Aufruf von GPT-5.5
gpt_resp = client.chat.completions.create(
model="gpt-5.5",
messages=[{"role": "user", "content": "Fasse die Transformer-Architektur in 200 Wörtern zusammen"}],
reasoning_effort="high" # GPT-5.5 unterstützt explizite Reasoning-Stufen
)
print("Grok 4.3:", grok_resp.choices[0].message.content)
print("GPT-5.5:", gpt_resp.choices[0].message.content)
Vollständiger Code für hybride Architektur-Router (automatische Modellauswahl basierend auf Token-Anzahl)
from openai import OpenAI
from typing import Literal
client = OpenAI(
api_key="Dein APIYI API-Schlüssel",
base_url="https://vip.apiyi.com/v1"
)
ROUTE_THRESHOLDS = {
"simple": 500, # Kurze Eingabeaufforderung nutzt Grok 4 Fast
"reasoning": 8000, # Mittlere Eingabeaufforderung nutzt Grok 4.3
"premium": 50000 # Lange Eingabeaufforderung oder kritische Aufgaben nutzen GPT-5.5
}
def estimate_tokens(text: str) -> int:
"""Vereinfachte Token-Schätzung: Englisch nach Zeichen/4, Chinesisch nach Zeichen"""
return max(len(text) // 4, len(text) // 2)
def route_model(prompt: str, force_premium: bool = False) -> str:
"""Wählt das Modell basierend auf der Länge der Eingabeaufforderung und der Aufgabenkomplexität"""
if force_premium:
return "gpt-5.5"
tokens = estimate_tokens(prompt)
if tokens < ROUTE_THRESHOLDS["simple"]:
return "grok-4-fast"
elif tokens < ROUTE_THRESHOLDS["reasoning"]:
return "grok-4.3"
else:
return "gpt-5.5"
def smart_chat(prompt: str, force_premium: bool = False) -> str:
"""Intelligenter Routing-Aufruf"""
model = route_model(prompt, force_premium)
extra_params = {}
if model == "gpt-5.5":
extra_params["reasoning_effort"] = "high"
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
**extra_params
)
return f"[{model}] {response.choices[0].message.content}"
if __name__ == "__main__":
print(smart_chat("Hallo"))
print(smart_chat("Hilf mir beim Entwurf einer Zustandsmaschine für E-Commerce-Bestellungen"))
print(smart_chat("Das ist eine 50k Token Code-Bibliothek..." * 1000, force_premium=True))
Hinweise zum Aufruf von Grok 4.3 und GPT-5.5
| Hinweis | Grok 4.3 | GPT-5.5 |
|---|---|---|
| Modellfeld | grok-4.3 |
gpt-5.5 |
| Reasoning-Konfiguration | Standardmäßig aktiv, keine Konfiguration nötig | reasoning_effort optional low/medium/high/xhigh |
| Video-Eingabefeld | video_url |
Nicht unterstützt, erfordert Vorab-Transkription |
| Dokumentenausgabe | extra_body={"output_format": "pdf/xlsx/pptx"} |
Erfordert Nachbearbeitung auf Anwendungsebene |
| Streaming-Ausgabe | stream=True |
stream=True (empfohlen für Produktion) |
| Function Calling | ✅ Voll unterstützt | ✅ Voll unterstützt (inkl. strict mode) |
| Persistentes Gedächtnis | ❌ Erfordert RAG auf Anwendungsebene | ✅ Feld previous_response_id |
🎯 Integrations-Empfehlung: Es wird empfohlen, zunächst einen Test-Schlüssel auf APIYI (apiyi.com) zu beantragen, um einen minimalen Kreislauf zu testen. Erst danach sollte über eine vollständige Migration oder hybride Planung entschieden werden. Die Plattform unterstützt gängige Abrechnungsmodelle und verbrauchsabhängige Tarife, was ideal für die Finanzprozesse lokaler Teams ist.
Grok 4.3 vs. GPT-5.5: Entscheidungshilfe
Drei-Schritte-Entscheidungsmodell
Wir haben den Auswahlprozess auf drei Schritte komprimiert, die in 90 Sekunden zum Ergebnis führen.
Schritt 1: Was ist dein Kernaufgabentyp?
- Programmierung / Mathematik / Abruf langer Kontexte → Bevorzuge GPT-5.5
- Video / Dokumentenerzeugung / Große Inhaltsmengen / Echtzeit-Dialoge → Bevorzuge Grok 4.3
Schritt 2: Wie hoch ist dein monatliches Token-Budget?
- < 100M Token: Wähle direkt das „optimale Modell für deine Kernaufgabe“
- 100M – 1B Token: Hybride Architektur zwingend erforderlich; Hauptlast auf Grok 4.3, kritische Aufgaben auf GPT-5.5
- ≥ 1B Token: Dreistufige Schichtung (Grok 4 Fast / Grok 4.3 / GPT-5.5), sonst sind die Kosten nicht kontrollierbar
Schritt 3: Benötigst du exklusive Funktionen des OpenAI-Ökosystems?
- Ja (persistentes Gedächtnis / Codex IDE / SOC2-Konformität) → GPT-5.5
- Nein → Grok 4.3 bietet ein unschlagbares Preis-Leistungs-Verhältnis
Entscheidungsmatrix für Grok 4.3 vs. GPT-5.5
| Deine Priorität | Empfohlene Wahl | Alternative |
|---|---|---|
| Bestes Preis-Leistungs-Verhältnis | Grok 4.3 | Grok 4 Fast |
| Höchste Programmierpräzision | GPT-5.5 | GPT-5.5 Pro |
| Höchste mathematische Schlussfolgerung | GPT-5.5 Pro | GPT-5.5 |
| Multimodale Videoverarbeitung | Grok 4.3 | (keine Alternative) |
| Präziser Abruf langer Kontexte | GPT-5.5 | Grok 4.3 |
| Echtzeit-Dialoggeschwindigkeit | Grok 4.3 | GPT-5.5 (hohes Reasoning) |
| Produkte mit persistentem Gedächtnis | GPT-5.5 | (Grok 4.3 erfordert Eigenbau) |
| Große Offline-Aufgaben | Grok 4.3 | Batch-Modus |
💡 Auswahlempfehlung: Die Wahl des Modells hängt maßgeblich von deinem spezifischen Anwendungsfall und den Qualitätsanforderungen ab. Wir empfehlen, beide Modelle über die Plattform APIYI (apiyi.com) einzubinden, einen A/B-Vergleich mit echten Geschäftsdaten durchzuführen und erst dann die endgültige Entscheidung zu treffen.
Grok 4.3 vs. GPT-5.5: Häufig gestellte Fragen
Q1: Sind Grok 4.3 und GPT-5.5 in China nutzbar?
Ja, beide. Beide Modelle sind über den API-Proxy-Dienst von APIYI (apiyi.com) verfügbar. Die base_url ist einheitlich https://vip.apiyi.com/v1, die Modellbezeichnungen lauten grok-4.3 bzw. gpt-5.5. Der Proxy-Dienst ist auf mehreren inländischen Servern bereitgestellt, bietet stabile Latenzzeiten und erfordert keinen eigenen Proxy. Die Preise für Grok 4.3 entsprechen exakt denen der xAI-Website, während GPT-5.5 zu den offiziellen OpenAI-Preisen (Eingabe-Faktor 2,5, Ausgabe-Faktor 6, entsprechend $5/$30 pro Million Token) ohne Aufschläge durchgereicht wird.
Q2: Der Preisunterschied beträgt das 7-Fache – ist GPT-5.5 das wirklich wert?
Das hängt vom Anwendungsfall ab. Wenn Ihre Kernaufgaben agentisches Coding (Terminal-Bench, SWE-bench) oder fortgeschrittene Mathematik (FrontierMath) umfassen, zahlt sich die höhere Präzision von GPT-5.5 durch weniger manuelle Nachbesserungen und höhere Produktqualität aus. Bei Massen-Content-Generierung, Kundensupport, Videoverständnis oder Dokumentenautomatisierung ist der Präzisionsvorteil jedoch oft vernachlässigbar, sodass der Kostenvorteil von Grok 4.3 („7-mal günstiger“) schwerer wiegt. Unsere Empfehlung: Kritische Pfade mit GPT-5.5, unterstützende Pfade mit Grok 4.3 – realisiert durch eine hybride Steuerung über APIYI (apiyi.com).
Q3: Beide Modelle unterstützen ein 1M-Kontextfenster – gibt es Unterschiede in der Praxis?
Ja, und zwar deutliche. GPT-5.5 erreicht im MRCR v2 8-Needle 512K-1M-Test 74,0 % (eine Verdopplung gegenüber den 36,6 % von GPT-5.4), was eine massiv verbesserte Fähigkeit zur präzisen „Nadel-im-Heuhaufen“-Suche in langen Kontexten bedeutet. Grok 4.3 hat keine MRCR-Daten veröffentlicht, aber Community-Tests zeigen exzellente Zusammenfassungsfähigkeiten bei langen Kontexten, während die „präzise Suche“ leicht hinter GPT-5.5 zurückbleibt. Wenn Ihr Geschäft darauf angewiesen ist, „3 spezifische Fakten in 800k Token zu finden“, ist GPT-5.5 stabiler; für reine Zusammenfassungen langer Dokumente sind beide geeignet.
Q4: GPT-5.5 unterstützt keine Videos – gibt es eine Alternative?
Ja, aber mit höherem technischem Aufwand. Die Verarbeitung von Videos mit GPT-5.5 erfordert meist drei Schritte: Whisper für STT (Untertitel), Frame-Extraktion und anschließende multimodale Analyse durch GPT-5.5, gefolgt von einer Reasoning-Integration. Dieser Prozess lässt sich mit Grok 4.3 in einer einzigen Anfrage erledigen. Wenn Ihr Projekt Videoverarbeitung benötigt, empfehlen wir direkt Grok 4.3 über APIYI (apiyi.com) zu nutzen, um die Komplexität um das 3- bis 5-Fache zu senken und Kosten zu sparen.
Q5: Muss ich meinen Code für das Upgrade von GPT-5.4 / GPT-5 auf GPT-5.5 anpassen?
Kaum. Ändern Sie einfach das Modellfeld von gpt-5 oder gpt-5.4 auf gpt-5.5, die base_url bleibt gleich. GPT-5.5 bietet standardmäßig ein höheres Reasoning-Niveau; für feinere Kontrolle kann das Feld reasoning_effort (low/medium/high/xhigh) hinzugefügt werden. Bei gleicher Aufgabe verbraucht GPT-5.5 weniger Token als GPT-5.4, was bei besserer Präzision oft zu gleichbleibenden oder sogar niedrigeren Kosten führt.
Q6: Sollte ich GPT-5.5 oder GPT-5.5 Pro wählen?
Das hängt vom Schwierigkeitsgrad ab. GPT-5.5 Pro kostet das 6-Fache von GPT-5.5 ($30/$180 vs. $5/$30) und bietet ein höheres Reasoning-Niveau sowie stabilere Ausgaben. Empfehlung: Reservieren Sie 95 % des Traffics für GPT-5.5 und nutzen Sie GPT-5.5 Pro nur für „extrem schwierige Aufgaben + kritische Entscheidungen“ (z. B. komplexe mathematische Beweise, wichtige PR-Reviews). So erzielen Sie mit nur 5–10 % GPT-5.5 Pro-Aufrufen den maximalen Grenznutzen. Für die meisten geschäftlichen Anwendungen reicht GPT-5.5 völlig aus.
Q7: Grok 4.3 hat kein persistentes Gedächtnis – beeinträchtigt das mein Produkt?
Ja, aber es gibt bewährte Lösungen. Wenn Ihr Produkt ein „persönlicher Assistent“ oder auf „langfristige Dialoge“ ausgelegt ist, ist ein persistentes Gedächtnis notwendig. Da Grok 4.3 dies nicht nativ unterstützt, ist eine Memory-Ebene auf Anwendungsebene erforderlich. Tools wie Mem0 oder Letta sind Open-Source, unterstützen das OpenAI Chat Completions-Protokoll und sind somit mit Grok 4.3 kompatibel. Wir empfehlen, den Basis-Dialog über APIYI (apiyi.com) zu testen und dann die Memory-Ebene zu ergänzen. Wenn Sie dies nicht selbst bauen möchten, ist GPT-5.5 die bequemere Wahl.
Q8: Ist die Abrechnung bei APIYI für beide Modelle gleich?
Absolut, beide werden nach Token-Verbrauch abgerechnet. Grok 4.3 wird 1:1 zu den xAI-Preisen durchgereicht ($1,25 Input / $2,50 Output pro Million Token). GPT-5.5 folgt den offiziellen OpenAI-Preisen (Modell-Faktor 2,5 für $5,00 Input; Vervollständigungs-Faktor 6 für $30,00 Output pro Million Token). Beide Modelle teilen sich denselben API-Schlüssel und dieselbe base_url (https://vip.apiyi.com/v1), und die Kosten werden vom selben Kontoguthaben abgebucht, was die Verwaltung und Abrechnung sehr einfach macht.
Q9: Wie kann ich die Kosten für GPT-5.5-Aufrufe senken?
Vier Tipps: (1) Prompt Caching aktivieren: Feste System-Prompts können die Kosten um 50–70 % senken (GPT-5.5 Cache-Input kostet nur $0,50/1M); (2) reasoning_effort reduzieren: Für einfache Aufgaben reicht „low“, was den Token-Verbrauch um 60 % senken kann; (3) Batch API nutzen: Für nicht-Echtzeit-Aufgaben lassen sich weitere 50 % sparen; (4) Streaming-Ausgabe + vorzeitiger Abbruch: Bei langen Antworten können Token am Ende gespart werden. Kombiniert man diese Methoden, nähert sich der Preis von GPT-5.5 dem Doppelten des Input-Preises von Grok 4.3 an.
Q10: Wie steht es um die Kompatibilität von Function Calling?
Beide Modelle sind vollständig kompatibel mit dem OpenAI Function Calling-Protokoll, sodass der Code wiederverwendet werden kann. Beide unterstützen das tools-Feld, parallele Werkzeugaufrufe und den „strict mode“ (erzwungenes JSON-Schema). Der Unterschied: GPT-5.5 bietet eine strengere Schema-Validierung und eine geringere Fehl-Trigger-Rate; Grok 4.3 unterstützt nativ serverseitige Tools (web_search / x_search / code_execution), ohne dass eine Implementierung auf Anwendungsebene nötig ist. Wenn Ihr Projekt stark auf Function Calling setzt, können Sie beide Modelle nahtlos über APIYI (apiyi.com) für A/B-Tests einsetzen.
Fazit: Die richtige Wahl zwischen Grok 4.3 und GPT-5.5
Im Kern geht es beim Vergleich zwischen Grok 4.3 und GPT-5.5 nicht darum, „wer stärker ist“, sondern um zwei verschiedene Produktstrategien: xAI nutzt Grok 4.3, um die Kostenkurve für Reasoning-Modelle zu glätten und die multimodalen Grenzen zu erweitern, während OpenAI mit GPT-5.5 die Messlatte für Präzision bei Coding, Mathematik und langer Kontextsuche erneut höher legt.
Kurz gesagt: Die meisten Teams sollten Grok 4.3 als Hauptmodell und GPT-5.5 als Backup für kritische Pfade nutzen. Die Kombination aus $1,25/$2,50 Preis, 207 tps Geschwindigkeit und Video-Input deckt 90 % der Anwendungsfälle ab. Die restlichen 10 % (High-End-Coding, fortgeschrittene Mathematik, präzise Suche) werden durch GPT-5.5 abgesichert. Die Gesamtkosten dieser Kombination liegen bei nur 15–25 % eines „reinen GPT-5.5-Setups“, ohne nennenswerte Qualitätseinbußen bei kritischen Aufgaben.
Für Entwickler in China ist der API-Proxy-Dienst von APIYI (apiyi.com) der Weg des geringsten Widerstands. Da beide Modelle dieselbe base_url und denselben API-Schlüssel teilen, reicht eine einfache Änderung des Modellfeldes aus. Die Preise sind transparent und ohne Aufschläge. Durch die Nutzung von Batch API und Cached Input lassen sich die Kosten weiter um 30–50 % senken.
Empfehlung: Testen Sie beide Modelle eine Woche lang mit 100–500 echten Datensätzen über APIYI. Benchmarks sind nur ein Anhaltspunkt – die tatsächliche Eignung für Ihr spezifisches Geschäft ist die einzige verlässliche Entscheidungsgrundlage.
Referenzen
-
Offizielle Ankündigung von OpenAI: Informationen zur Veröffentlichung von GPT-5.5 und API-Dokumentation
- Link:
openai.com/index/introducing-gpt-5-5 - Beschreibung: Enthält Preise, Benchmarks und Erläuterungen zu API-Feldern.
- Link:
-
OpenAI-Entwicklerdokumentation: Spezifikationen und Aufrufbeispiele für das GPT-5.5-Modell
- Link:
developers.openai.com/api/docs/models/gpt-5.5 - Beschreibung: Vollständige API-Parameter und Abrechnungsdetails.
- Link:
-
xAI-Modelldokumentation: Alle API-Spezifikationen für Grok 4.3
- Link:
docs.x.ai/developers/models - Beschreibung: Beinhaltet exklusive Funktionen wie Videoeingabe und Dokumentenerstellung.
- Link:
-
Artificial Analysis Intelligenz-Ranking: Umfassender Leistungsvergleich zwischen Modellen
- Link:
artificialanalysis.ai/models/grok-4-3 - Beschreibung: Umfassende Bewertung von AA-Intelligenzindex, Geschwindigkeit und Preis.
- Link:
-
Vellum-Benchmark-Bericht: Detaillierte Benchmarks der GPT-5 / GPT-5.5-Serie
- Link:
vellum.ai/blog/gpt-5-2-benchmarks - Beschreibung: Unabhängige Evaluierung anhand mehrerer Benchmarks.
- Link:
-
DocsBot-Modellvergleich: Detaillierter Vergleich zwischen GPT-5.5 und Grok 4.3
- Link:
docsbot.ai/models/compare/gpt-5-5/grok-4-3 - Beschreibung: Gegenüberstellung von Preis, Leistung und Funktionen.
- Link:
-
APIYI-Integrationsdokumentation: Vollständiges Tutorial zur Anbindung beider Modelle über einen API-Proxy-Dienst
- Link:
help.apiyi.com - Beschreibung: Enthält Informationen zu Multiplikatoren, SDK-Beispiele und Abrechnungsabfragen.
- Link:
Autor: APIYI Team — Wir sind auf API-Proxy-Dienste für große Sprachmodelle spezialisiert und unterstützen Entwickler dabei, führende Modelle wie Grok 4.3, GPT-5.5 und Claude Opus 4.7 mit nur einem Klick einzubinden. Besuchen Sie APIYI unter apiyi.com, um ein kostenloses Testguthaben zu erhalten.